
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Обучение нейронной сети
Обучение нейронной сети – это процесс представления нейронной сети некоторых данных и изменение весовых коэффициентов w связей сети для лучшего приближения к желаемой функции.
Для того, чтобы нейронная сети была способна выполнить поставленную задачу, ее необходимо обучить (см. рис. 1). Существует два основных типа обучения:
- контролируемое (с учителем); неконтролируемое (без учителя).
Контролируемое обучение. Процесс обучения с учителем или контролируемое обучение представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети. Затем вычисляется ошибка обучения (training error):
![]()
![]() ,
,
где![]()
![]() - желательный выход,
- желательный выход,![]()
![]() - реальный выход, N – размерность выходного вектора y.
- реальный выход, N – размерность выходного вектора y.
Ошибка обучения является показателем точности настройки модели на обучающем множестве, может использоваться в качестве условия остановки обучения.
После этого происходит изменение весовых коэффициентов связей внутри сети в зависимости от выбранного алгоритма. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
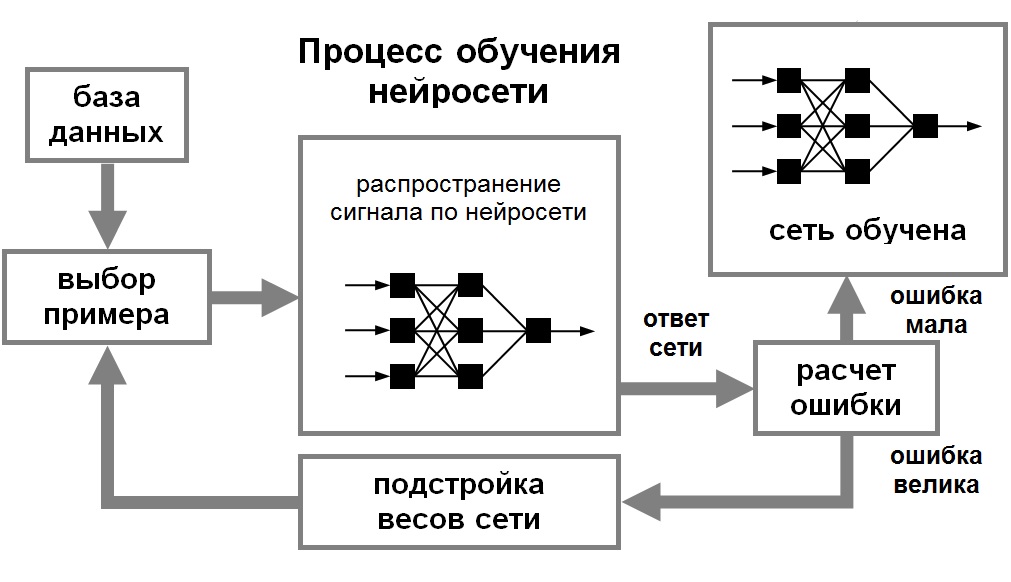
Рисунок 1. Процесс обучения нейронной сети.
Неконтролируемое обучение. При обучении без учителя обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети так, чтобы получались согласованные выходные векторы, т. е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход вектора из данного класса даст определенный выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Это не является серьезной проблемой. Обычно не сложно идентифицировать связь между входом и выходом, установленную сетью.
Для обучения нейронных сетей без учителя применяются сигнальные метод обучения Хебба и Ойя (http://pca. narod. ru/lecture3.htm).
Математически процесс обучения можно описать следующим образом. В процессе функционирования нейронная сеть формирует выходной сигнал Y, реализуя некоторую функцию Y = G(X). Если архитектура сети задана, то вид функции G определяется значениями синаптических весов и смещений сети.
Пусть решением некоторой задачи является функция Y = F(X), заданная параметрами входных-выходных данных (X1, Y1), (X2, Y2), …, (XN, YN), для которых Yk = F(Xk) (k = 1, 2, …, N).
Обучение состоит в поиске (синтезе) функции G, близкой к F в рамках некоторой функции ошибки E.
Если выбрано множество обучающих примеров – пар (XN, YN) (где k = 1, 2, …, N) и способ вычисления функции ошибки E, то обучение нейронной сети превращается в задачу многомерной оптимизации, имеющую очень большую размерность, при этом, поскольку функция E может иметь произвольный вид обучение в общем случае – многоэкстремальная невыпуклая задача оптимизации.
Для решения этой задачи могут использоваться следующие (итерационные) алгоритмы:
алгоритмы локальной оптимизации с вычислением частных производных первого порядка:- градиентный алгоритм (метод наискорейшего спуска), методы с одномерной и двумерной оптимизацией целевой функции в направлении антиградиента, метод сопряженных градиентов, методы, учитывающие направление антиградиента на нескольких шагах алгоритма;
- метод Ньютона, методы оптимизации с разреженными матрицами Гессе, квазиньютоновские методы, метод Гаусса-Ньютона, метод Левенберга-Марквардта и др.;
- поиск в случайном направлении, имитация отжига, метод Монте-Карло (численный метод статистических испытаний);
Эпоха. Алгоритм обучения нейронной сети является итеративным, его шаги называют эпохами или циклами.
Эпоха – это одна итерация в процессе обучения, включающая предъявление всех примеров из обучающего множества и, возможно, проверку качества обучения на контрольном множестве. Как правило, для эффективной работы нейронной сети требуется много эпох в десятки тысяч раз.
Функции активации
Одним из важнейших аспектов нейронных сетей является функция активации (activation function), которая привносит в сеть нелинейность, делая их универсальными аппроксиматорами функций.
Функция активации — это способ нормализации входных данных. То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном диапазоне.
Если обозначить функцию активации как f, выходной сигнал Y нейрона зависит от вектора входных значений [X1, X2, …, Xn] и вектора весовых коэффициентов [W1, W2, …, Wn] следующим образом:
Y = f (X1*W1 + X2*W2 + … + Xn*Wn)
Функций активации достаточно много, поэтому мы рассмотрим самые основные:
- Линейная; Пороговая; Cигмоид; Гиперболический тангенс; Rectified linear unit (ReLU).
Главные их отличия — это диапазон значений и скорость обработки.
Линейная функция
Простейшей из функций активации. Представленная следующей формулой:
![]()
Выход такой же, как и вход. Функция определена в диапазоне (-∞, +∞). На рисунке 2 показана графическая интерпретация:

Рисунок 2. Линейная функция активации.
Пороговая функция активации
Это простая кусочно-линейная функция, которая часто используется в нейронных сетях. Результат принимает значение 0 для отрицательного аргумента и 1 для положительного аргумента.
![]()
Данный тип функции активации полезен для бинарных схем. К примеру, для случая бинарной классификации. Графическая интерпретация представлена ниже на рисунке 3:
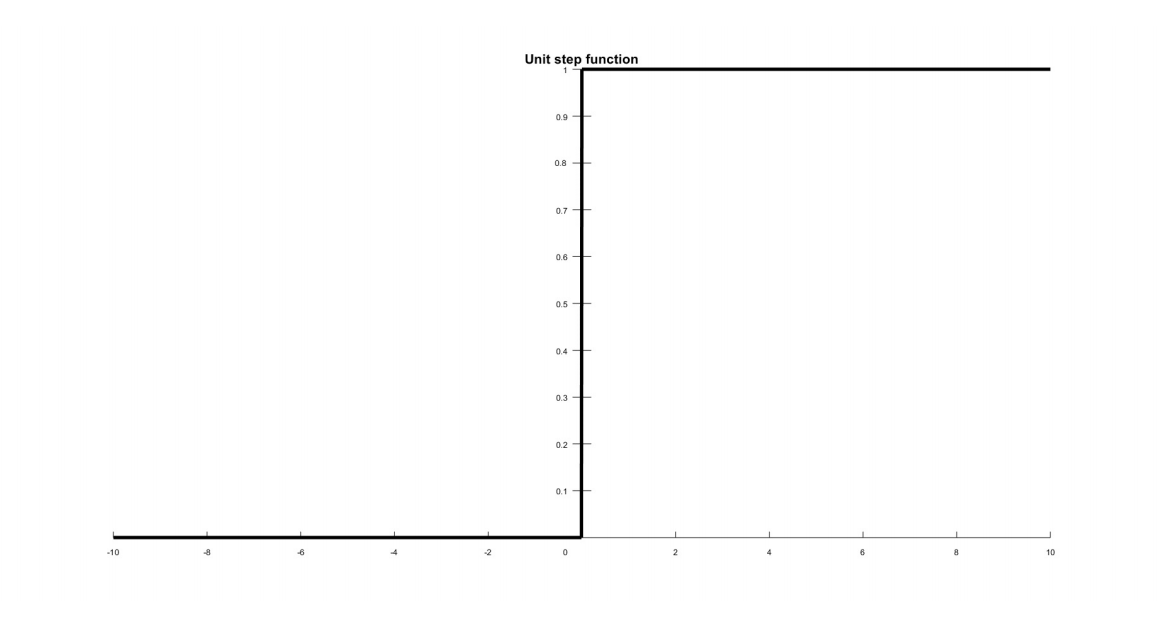
Рисунок 3. Пороговая функция активации
Сигмоид
Монотонно возрастающая всюду дифференцируемая S-образная нелинейная функция. Является очень распространенной функцией активации. Благодаря такой функции можно добиться непрерывного выходного значения в диапазоне (0,1). Кроме того, она легко дифференцируема, что позволяет упростить обучение сети по методу обратного распространения ошибки.
Сигмоид позволяет усиливать слабые сигналы и не насыщаться от сильных сигналов. Примером сигмоидальной функции активации может служить логистическая функция, задаваемая следующей формулой:
![]()
На рисунке 4 показана сигмовидная кривая:
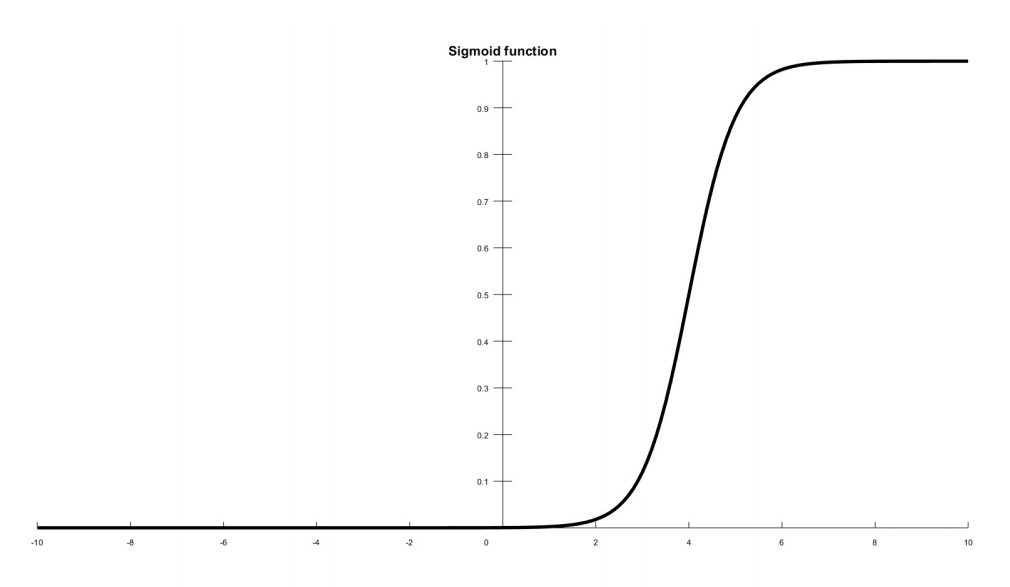
Рисунок 4. Сигмоидальная функция активации
Гиперболический тангенс
Другой популярной и широко используемой функцией активации является функция tanh (гиперболический тангенс). Отличается от рассмотренной выше логистической кривой тем, что его область значений лежит в интервале (-1;1). оба графика отличаются лишь масштабом осей. Формула гиперболического тангенса:
![]()
На рисунке 5 показана функция активации гиперболического тангенса:

Рисунок 5. Функция активации гиперболического тангенса.
Rectified linear unit ReLU
Rectified linear unit (ReLU) или «выпрямитель» (rectifier, по аналогии с однополупериодным выпрямителем в электротехнике) является наиболее часто используемой функцией активации с 2015 года. Это простое условие и имеет преимущества перед другими функциями. Функция определяется следующей формулой:
![]()
![]()
На рисунке 6 показана функция активации ReLU:
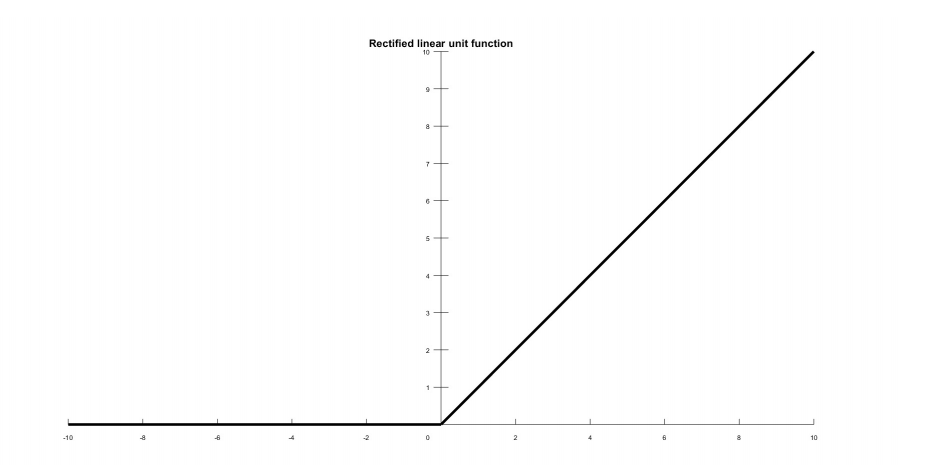
Рисунок 6. Функция активации ReLU.
Диапазон вывода от 0 до +∞. ReLU активно используются в глубоких нейронных сетях для задач компьютерного зрении и распознавании речи.
Какую функцию активации использовать?
Учитывая, что нейронные сети должны поддерживать нелинейность и сложность, используемая функция активации должна быть достаточно надежной и удовлетворять следующим требованиям:
- Функция активации должна быть дифференцируема. Это необходимо для алгоритма обратного распространения ошибки (backpropagation), который будет рассмотрен в последующих главах. Простота и скорость в обработке; Выход должен быть центрирован относительно нуля (также для backpropagation).
Сигмоид являлась наиболее часто используемой функцией активации, но она утратила свою популярностью, Недостатки:
- Вычисления занимают много времени и сложны, т. к. используется логистическая модель; Приводит к исчезновению градиентов (в алгоритме backpropagation) в случае, если значение выходного значения близко к 0 или 1. Никакие сигналы не будут проходить через данные нейроны; Медленно сходится (под сходимостью понимают существование конечного предела числовой последовательности); Выход сигмоиды не центрирован относительно нуля. Это свойство является нежелательным, поскольку нейроны в последующих слоях будут получать значения, которые не центрированы относительно нуля, что оказывает влияние на динамику градиентного спуска (gradient descent).
Эти недостатки решаются ReLU. ReLU прост и быстрее в обработке. Он не имеет проблемы с исчезновением градиента и показал значительные улучшения по сравнению с сигмовидными функциями. Данная функция активации является наиболее для нейронных сетей.
ReLU используется для скрытых слоев, тогда как выходной уровень может использовать функцию softmax для задач классификации и линейную функцию для регрессионных задач.
Подробнее о функции softmax:
http:///2017/03/07/difference-between-softmax-function-and-sigmoid-function/
Ссылки на источники:
http://datareview. info/article/eto-nuzhno-znat-klyuchevyie-rekomendatsii-po-glubokomu-obucheniyu-chast-2/
http://www. frolov-lib. ru/books/hi/ch04.html
https://www. monographies. ru/ru/book/section? id=2465
http://www. aiportal. ru/articles/neural-networks/activation-function. html
http://statsoft. ru/home/textbook/modules/stneunet. html
https://ru. wikipedia. org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%B1%D1%80%D0%B0%D1%82%D0%BD%D0%BE%D0%B3%D0%BE_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F_%D0%BE%D1%88%D0%B8%D0%B1%D0%BA%D0%B8
http:///theory/240-algoritmy-obucheniya-iskusstvennykh-nejronnykh-setej
https://basegroup. ru/community/glossary/error
https://www. intuit. ru/studies/courses/6/6/lecture/178?page=4
Функция softmax:
http:///2017/03/07/difference-between-softmax-function-and-sigmoid-function/
Сходимость:
https://dic. academic. ru/dic. nsf/bse/137420/%D0%A1%D1%85%D0%BE%D0%B4%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D1%8C
