
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Регрессионный анализ
Регрессионный анализ устанавливает формы зависимости между случайной величиной Y (зависимой) и значениями одной или нескольких переменных величин (независимых), причем значения последних считаются точно заданными. Такая зависимость обычно определяется некоторой математической моделью (уравнением регрессии), содержащей несколько неизвестных параметров. В ходе регрессионного анализа на основании выборочных данных находят оценки этих параметров, определяются статистические ошибки оценок или границы доверительных интервалов и проверяется соответствие (адекватность) принятой математической модели экспериментальным данным.
В линейном регрессионном анализе связь между случайными величинами предполагается линейной. В самом простом случае в парной линейной регрессионной модели имеются две переменные Х и Y. И требуется по n парам наблюдений (X1, Y1), (X2, Y2), ..., (Xn, Yn) построить (подобрать) прямую линию, называемую линией регрессии, которая «наилучшим образом» приближает наблюдаемые значения. Уравнение этой линии y=аx+b является регрессионным уравнением. С помощью регрессионного уравнения можно предсказать ожидаемое значение зависимой величины y, соответствующее заданному значению независимой переменной x
В случае, когда рассматривается зависимость между одной зависимой переменной Y и несколькими независимыми X1, X2, ..., Xm, говорят о множественной линейной регрессии.
В этом случае регрессионное уравнение имеет вид
y = a0+a1x1+a2x2+…+amxm,
где a0, a1, a2, …, am – требующие определения коэффициенты регрессии.
Коэффициенты уравнения регрессии определяются при помощи метода наименьших квадратов,( один из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным. Метод основан на минимизации суммы квадратов остатков регрессии) добиваясь минимально возможной суммы квадратов расхождений реальных значений переменной Y и вычисленных по регрессионному уравнению. Таким образом, например, уравнение линейной регрессии может быть построено даже в том случае, когда линейная корреляционная связь отсутствует.
Мерой эффективности регрессионной модели является коэффициент детерминации R2 (R-квадрат). Коэффициент детерминации может принимать значения между 0 и 1 определяет, с какой степенью точности полученное регрессионное уравнение описывает (аппроксимирует. Аппроксимация - приближенное выражение некоторых величин или объектов через другие более простые величины или объекты) исходные данные. Исследуется также значимость регрессионной модели с помощью F-критерия (Фишера) и достоверность отличия коэффициентов a0, a1, a2, …, am от нуля проверяется с помощью критерия Стьюдента.
В Excel экспериментальные данные аппроксимируются линейным уравнением до 16 порядка:
y = a0+a1x1+a2x2+…+a16x16
Полную информацию об уравнении линейной регрессии дает функция ЛИНЕЙН. Кроме того, могут быть использованы функции НАКЛОН и ОТРЕЗОК для получения параметров регрессионного уравнения и функция ТЕНДЕНЦИЯ и ПРЕДСКАЗ для получения предсказанных значений Y в требуемых точках (для парной регрессии).
Рассмотрим подробно применение функции
ЛИНЕЙН(известные_y, [известные_x], [константа], [статистика]):
известные_у – диапазон известных значений зависимого параметра Y. В парном регрессионном анализе может иметь любую форму; в множественном должен быть строкой либо столбцом;
известные_х – диапазон известных значений одного или нескольких независимых параметров. Должен иметь ту же форму, что и диапазон Y (для нескольких параметров – соответственно несколько столбцов или строк);
константа – логический аргумент. Если исходя из практического смысла задачи регрессионного анализа необходимо, чтобы линия регрессии проходила через начало координат, то есть свободный коэффициент был равен 0, значение этого аргумента следует положить равным 0 (или «ложь»). Если значение положено 1 (или «истина») или опущено, то свободный коэффициент вычисляется обычным образом;
статистика – логический аргумент. Если значение положено 1 (или «истина»), то дополнительно возвращается регрессионная статистика (см таблицу 5.2), используемая для оценки эффективности и значимости модели.
В общем случае для парной регрессии y=аx+b результат применения функции ЛИНЕЙН имеет вид:
Табл.5.2.Выводной диапазон функции ЛИНЕЙН для парного регрессионного анализа
Коэффициент а | Коэффициент b |
Стандартная ошибка коэффициента а | Стандартная ошибка коэффициента b |
Коэффициент детерминации R2 | Стандартная ошибка для оценки y |
Значение F-статистики | Число степеней свободы k2 |
Регрессионная сумма квадратов | Остаточная сумма квадратов |
В случае множественного регрессионного анализа для уравнения y=a0+a1x1+a2x2+…+amxm в первой строке выводятся коэффициенты am,…,a1,а0, во второй – стандартные ошибки для этих коэффициентов. В 3-5 строках за исключением первых двух столбцов, заполненных регрессионной статистикой, будет получено значение #Н/Д.
Вводить функцию ЛИНЕЙН следует как формулу массива, выделив вначале массив нужного размера для результата (m+1 столбец и 5 строк, если требуется регрессионная статистика) и завершив ввод формулы нажатием CTRL+SHIFT+ENTER.
Оценка значимости полученной регрессионной модели проводится следующим образом:
- F-статистика используется для того, чтобы определить, является ли наблюдаемая связь зависимой и независимых переменных случайной. Критическое значение F-критерия рассчитывается при помощи функции FРАСПОБР(α;k1;k2), где k2-полученное число степеней свободы, k1=n-1-k2. Если значение F-статистики выше критического, то регрессионная модель в целом значима.
Можно также определить вероятность случайного получения высокого значения F-статистики при помощи функции FРАСП(F;k1;k2)
- T-статистика позволяет оценить значимость каждого полученного коэффициента наклона. Для этого следует разделить коэф. наклона на станд. ошибку и сравнить полученное значение t-статистики с критическим, найденным по формуле СТЬЮДРАСПОБР(α;k2). Если значение t-статистики меньше критического, то соответствующий коэффициент может считаться нулевым, а это означает, что влияние соответствующей независимой переменной на зависимую переменную недостоверно, и эта независимая переменная может быть исключена из уравнения.
Функцию ЛИНЕЙН можно использовать также для аппроксимации по методу наименьших квадратов с помощью других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Так, для получения парной квадратичной регрессионной модели следует вычислить квадраты значений аргумента Х и построить линейную регрессионную модель с аргументами Х и Х2. Однако надо помнить, что чем выше степень полиномиального регрессионного уравнения, тем выше его точность (коэффициент детерминации) и тем меньше значимость при небольшом объеме выборки. Необходимо иметь хотя бы 5-6 известных пар данных на каждый определяемый коэффициент уравнения регрессии.
Для вычисления коэффициентов экспоненциальной регрессии в Excel существует функция ЛГРФПРИБЛ. Функция РОСТ для экспоненциальной регрессии позволяет получить значения Y в требуемых точках и имеет тот же смысл, что и функция ПРЕДСКАЗ для линейной регрессии.
Если полученное уравнение регрессии оказалось значимо, его используют для прогнозирования значения зависимого признака Y при конкретных значениях независимых признаков Xi. Прогноз будет тем точнее, чем выше коэффициент детерминации.
Кроме того, уравнение парной линейной регрессии (даже незначимое) используется для определения корреляционного отношения, характеризующего тесноту криволинейной корреляционной связи, если доказано отсутствие линейной корреляции:
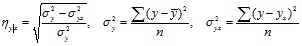 ,
,
где yx – «выровненные» значения y, вычисленные по уравнению линейной регрессии,
![]() - дисперсия выборки Y (вычисляется в Excel при помощи функции ДИСПР).
- дисперсия выборки Y (вычисляется в Excel при помощи функции ДИСПР).
Статистическая значимость отличия корреляционного отношения от нуля проверяется с помощью критерия
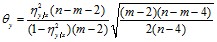 .
.
При равенстве истинного корреляционного отношения нулю величина ![]() распределена нормально с математическим ожиданием 0 и дисперсией 1, что позволяет определять критические значения
распределена нормально с математическим ожиданием 0 и дисперсией 1, что позволяет определять критические значения ![]() для заданных доверительных вероятностей по таблицам нормального распределения. Если расчетное значение
для заданных доверительных вероятностей по таблицам нормального распределения. Если расчетное значение ![]() превышает критическое, гипотеза об отсутствии корреляционной связи отвергается.
превышает критическое, гипотеза об отсутствии корреляционной связи отвергается.
Следует отметить, что корреляционное отношение несимметрично, гипотеза о наличии криволинейной корреляционной связи проверяется и по ![]() .
.
Для вычисления корреляционного отношения значимость уравнения регрессии не важна, поэтому если коэффициент линейной корреляции статистически не значим, коэффициенты уравнения парной линейной регрессии можно определить просто при помощи функций НАКЛОН (коэффициент а) и ОТРЕЗОК (коэффициент b).
