
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вводные данные
(Необходимо дописать, что все данные приблизительные, так как взяты из открытых источников):
Данные под звездочками - Это пункты, которые необходимо отслеживать от проверки к проверки, т. е. данные которые выводятся с * Запоминаются до следующей проверки, после проверки, строится график. А так же мы можем работать с этими данными и сравнивать их между собой. Данные по одному сайту обновляются не ранее чем через 3 дня (Срок обновления, я бы заложил, что бы его можно было поменять, так как пока точно не представляю как лучше сделать)
Данные под двумя звездочками - Это пункты необходимо отслеживать от проверки к проверки, НО эти данные не строятся в график, а только сообщают об изменение, т. е. если относительно предыдущий проверки произошли изменения, ТО об этом идет извещение, если нет, то ничего не происходит
Данные с плюсиком - Данный символ обозначает, что мы проверяем не одну страницу сайта, а несколько, от 2 и выше на данный параметр
Кол-во страниц Яндекс* - Данный показатель забираем по такой ссылке: host:fedek. ru | host:www. fedek. ru Вместо сайта подставляем необходимый сайт. После чего берем данные, которые я показал на скрине

Рис 1.
Кол-во страниц Google* - Тут два варианта высчитывать данные, хотелось бы оценить 2 варианта.
1 вариант:
В поиске вбиваем выражение: site:fedek. ru (Где меняем сайт на необходимый)
После чего берем данные, что на скрине ниже
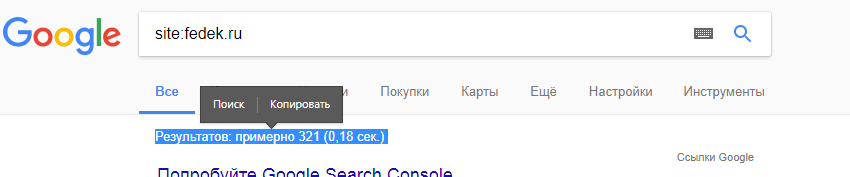
2 Вариант:
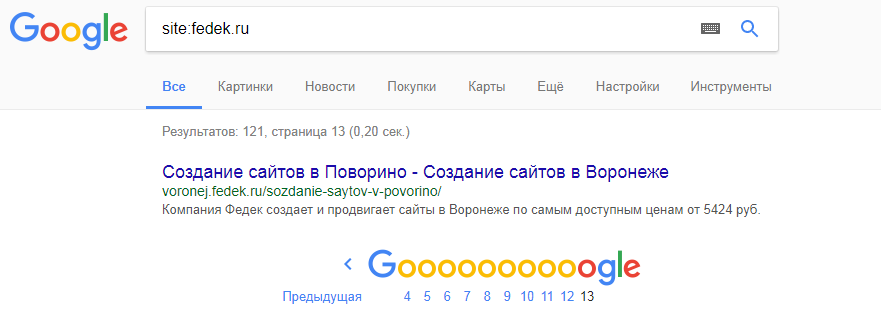
В поиске вбиваем выражение: site:fedek. ru (Где меняем сайт на необходимый)
После чего доходим до последней странице и смотрим, сколько там ответов затем, по формуле 10*(На кол-во страниц - 1) + Кол-во ответов на последней странице
Яндекс ТИЦ* - Данный показатель брать вот по такой системе https://yandex. ru/yaca/cy/ch/milano-home. ru То что выделено красным меняется на необходимый сайт. Забираем полученные данные, а именно ТИЦ сайта.
Яндекс Rank - Данный показатель рассчитывается на основе ТИЦ, ниже приведены данные для расчета
- тИЦ 0-10 rank=1 тИЦ 10-20 rank=2 тИЦ 30-150 rank=3 тИЦ 160-600 rank=4 тИЦ 650-3000 rank=5 тИЦ 3100-81000 rank=6
Так же мы должны сделать проверку данных и вывести аналитические данные. Т. е. данные об ошибках
Список возможных ошибок:
1.Большая разница между индексируемыми страницами в Яндексе и Гугле
Если разница между страницами больше 30% - 50% - 80%, то выводим ошибку, и пишем текст
2.Большое падение страниц с последней проверки в Яндексе или Гугле
Если падение на 30%-50% - 80%, то выводим ошибку и пишем текст. При чем учитываем любую из поисковых систем. Если в двух поисковых системах, то выводим 2 ошибки.
3.Большое падение ТИЦ с последней проверки
Если есть падение ТИЦ, более чем на 20 пунктов, то выводим сообщение с предупреждением.
Скрытые вводные данные:
- IP Местоположение сервера Датацентр Возраст домена Кодировка Технологии (Как на PR-CY) Проверка сайта на вирусы Склейка домена Система статистики
Технические данные сайта:
1.Размер Html страницы** - Смотрим HTML страницы размер, и если он превышает определенный заданный лимит, то выводим ошибку, если нет, то выводим просто текст
2.Кол-во внутрених ссылок**+ - В данном случае тут 2 метода, и я предполагаю, что второй намного сложнее, НО интереснее узнать цену
1 Метод - Берется страница и считается кол-во ссылок на странице, которые ведут внутри сайта
2 Метод - Берется страница и считается кол-во ссылок на странице, которые ведут внутри сайта, затем берется произвольная другая страница, и считаются там ссылки, после чего ссылки сравниваются и те которые повторяются, считаются сквозными
3.Внешние ссылки** - Проверяются ссылки, которые ведут с сайта на другие сайты. Так же желательно рассчитать 2 метода, по такому же принципу как выше.
Из отличий, необходима проверка на то индексируемая или нет ссылка. Неиндексируемой будет считаться ссылка имеющая тег rel nofollow
Поэтому мы находим все ссылки и выводим число и сами ссылки. Затем находим индексируемые ссылки и пишем число и помечаем из общего списка ссылки, которые индексируются.
4.Наличие микроразметки** - Необходимо проверить наличие двух типов микроразметки и вывести информацию о наличие или отсутствие данных микроразметок
Микроразметка Open Graph
Микроразметка Schema. org
5.SSL** - Проверка на наличие сертификата SSL (Безопасного соединения). Необходимо проверить открытие сайта по протоколу https
Так же проверяется при нахождение SSL наличие редиректов с обычного соединения
Так же проверяется при нахождение SSL адреса ссылок, что бы не использовали обычное соединение, т. е. через исходный код идет поиск наличия ссылок на обычное соединение
6.Наличие Robots. txt** - Проверяется наличие файла robots. txt
При наличие идет проверка:
- Директивы host Директивы Sitemap Наличие хотя бы одного disallow
Проверка на открытость сайта к индексированию
7.Наличие карты сайта** - Проверяем наличие карты сайта. Используем стандартный адрес sitemap. xml или данные из файла robots. txt
8.Фавикон** - Проверяем наличия файла Фавикон, а так же выводим саму миниатюру, которая размещена на сайте
9.404 страница** - Нами вводится заранее несуществующая страница и смотрим страницу. Должна быть 404 страница. Так же проверяем код ответа данной страницы
10.Скорость загрузки сайта (данные с пейдж спид)** - Данные берем с пейдж спид и выводим в таком виде
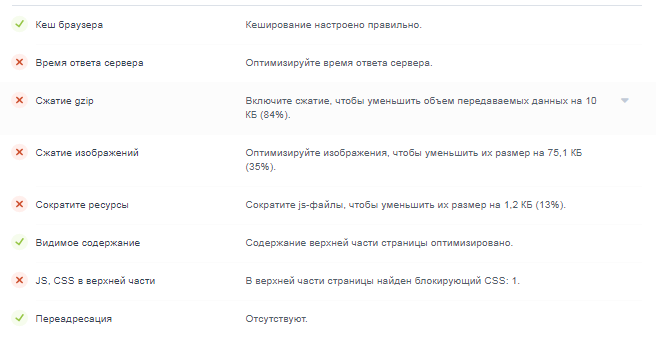
11.Мобильность** - Данный пункт не знаю, откуда можно брать, НО он нужен
12.Редирект с www на без www** с index. html и index. php - Проверка, что бы при запросе www сайта, был настроен редирект на сайт без www или наоборот. Так же проверяем редиректы с index. html и index. php - Должна быть или 404 страница или редирект на главную страницу сайта
13.Битые ссылки**+ - Это ссылки, которые ведут на 404 ошибку. Это долгий процесс их поиска, так как надо обойти каждую ссылку, поэтому надо придумать может затяжной процесс? Т. е. данные выводить или присылать на почту через время, или при следующем анализе
14.ЧПУ страниц - ЧПУ - это ЧЕловекоПонятный URL Данный пункт не считается за ошибку, необходимо проверить в каком виде заполнены URL у страниц. ЧПУ выглядит следующим образом: http://credit-samara. info/ipoteka-doks/
15.Код ответа Главной страницы**+ - Проверяем код ответа главной страницы. Код ответа главной страницы должен быть 200, если он не такой, то выводим ошибку.
Проверка индексируемых страниц - Смотрим, какие данные попадают в поиск Яндекса и Гугла
Текстовые данные:
1.Title**+
- Наличие пустого Title Длиный или короткий title более 160 символов и короче 15 символов Наличие ключевого слова в title
Выводим сам Title
2.Description**+
- Пустой description Отсутствуют description description короче 40 символов и длиннее 320 символов description дублируется внутри сайта Использование в description набор букв, грамматических ошибок
3.Размер текста\Кол-во слов**+ - Выводим размер текста и кол-во слов на странице
4.h1**+ - Выводим, что в нем распологается
- H1 – более одного раза на странице H1 короче 15 символов или длиннее 110 символов H1, присутствуют другие теги внутри тега Пустой тег, т. е. тег присутствует, но в нем ничего не располагается. <h1></h1>
5.h2-h6**+ - Выводим в табилцу что в тегах распологается
h2 более 3 раз на странице
6.Процент вхождения ключевого слова и вхождение его в тайтл и мета данные - Вот тут не знаю как определять, но системы определяют самое частое употребляемое слово
7.Наличие картинки и ее оптимизации тег alt и title
10.Тошнота**+ - Определяем процент тошноты на странице
12. Использование нежелательных символов+: \ / ; * желательно что бы их мы могли задавать в мета данных сайта Title Description h1
Внешние факторы:
Берем данные из Яндекс Вебмастера (Ссылки) Выкачиваем и загружаем к нам на сайт
По ссылкам определяется "Траст" и выдается значение на сколько все хорошо
