


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа №1. Задание.
1. Создать базу данных, моделирующую некую предметную область по выбору бригады.
Б. д. должна включать следующие категории таблиц:
1. Справочники.
2. Сущности
3. Факты.
Должно быть создано несколько таблиц (не меньше 2-х) каждой из категорий.
Таблица справочник включает столбцы – идентификатор и имя.
Таблица сущностей – идентификатор, некоторое количество строковых столбцов, ссылки на справочники.
Таблица фактов – идентификатор, ссылки на таблицы сущностей, некоторое количество строковых и числовых столбцов.
Для столбцов идентификаторов должны быть созданы индексы.
Количество строк в таблицах справочниках – до 10. Количество строк в таблицах сущностей и фактах - от 100 до 1000.
В отчет привести описания таблиц и sql-операторы их создания.
2. Для созданных таблиц подготовить запросы:
- Получения количества строк из таблицы сущностей, сгруппированных по значениям справочников. Получения подмножества строк из одной таблицы сущностей, с количеством соответствующих строк из другой таблицы сущностей. Для подготовленных запросов привести их планы и статистику выполнения. Собрать статистику данных для таблиц составляющих запросы. Привести основные значения статистики данных. Проверить изменились ли после сбора статистики данных планы выполнения. С помощью подсказок изменить планы выполнения предыдущих запросов. Привести измененные планы и количество логических чтений для них.
Указания к выполнению.
Первоначально нужно настроить соединение в sqldeveloper:
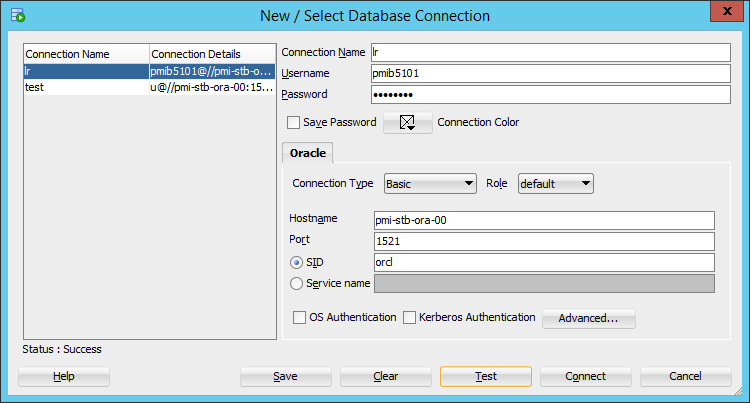
В качестве имени пользователя указать бригадный логин без дефиса.
Hostname – pmi-stb-ora-00
SID – orcl
2. Заполнение таблиц данными.
2.1 Создание генерируемого значения идентификатора таблицы.
Для таблицы t, со столбцом идентификатором id, создается объект последовательность
create sequence T_SEQ increment by 1 nocache;
и триггер на вставку:
CREATE OR REPLACE TRIGGER T_TRIGGER BEFORE INSERT ON T FOR EACH ROW
begin
select T_SEQ. nextval into :new. id from dual;
end;
2.2 Генерация данных для заполнения таблиц.
Если значения таблиц справочников могут быть заполнены вручную, по причине небольшого их количества, то для таблиц сущностей и фактов/связей необходима процедура генерации, способная заполнить их необходимым количеством строк.
Общий вид сценария заполнения для таблицы tab, включающей в себя ссылки на таблицы tab1 и tab2 столбец name типа varchar2(32) и столбец num типа number;
declare
N number;
n_tab1 number; --кол-во строк в таблице tab1
n_tab2 number; --кол-во строк в таблице tab2
v_id_tab1 number;
v_id_tab2 number;
v_name varchar2(32);
v_num number;
begin
N := нужное количество строк;
select count(*) into n_tab1 from tab1;
…
for i in 1..N
loop
v_id_tab1 := dbms_random. value(1, n_tab1);
v_id_tab2 := dbms_random. value(1, n_tab2);
v_name := dbms_random. string(‘l’,32);
….
insert into tab(id_tab1,id_tab2,name, num)
values v_id_tab1,v_id_tab2,v_name, v_num;
end loop;
commit;
end;
Пакет dbms_random –
https://docs. /cd/E18283_01/appdev.112/e16760/d_random. htm
3. Получение планов и статистики выполнения запроса
Просмотр плана выполнения средствами среды sqldeveloperЧтобы получить план выполнения запроса нужно для выделенного запроса нажать F10 или выбрать «Explain plan»
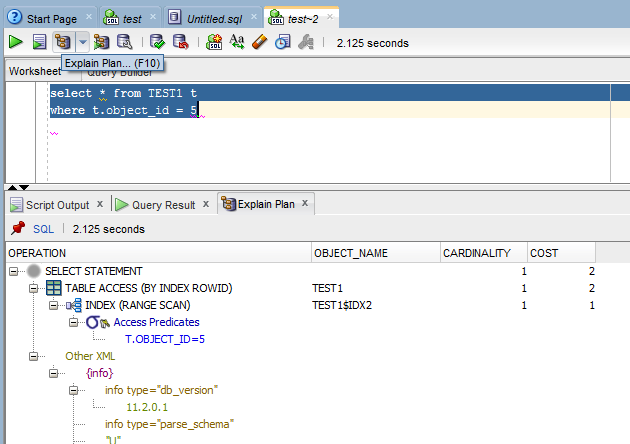
Средства oracle sql и pl/sql
Чтобы получить план выполнения запроса в текстовом виде, например, таком:
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 97 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST1 | 1 | 97 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | TEST1$IDX2 | 1 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."OBJECT_ID"=TO_NUMBER(:Y))
используется sql-оператор
explain plan for текст sql-запроса, для которого нужно получить план
затем выполнение запроса:
select * from table(dbms_xplan. display).
При выполнении explain plan можно указать идентификатор плана, для дальнейшего получения и таблицу для сохранения плана выполнения.
explain plan
set statement_id = 'идентификатор'
into таблица для сохранения
for текст sql-запроса
Полное описание оператора explain plan приведено в
https://docs. /cd/E11882_01/server.112/e41084/statements_9010.htm
и
https://docs. /cd/E11882_01/server.112/e41573/ex_plan. htm
При вызове dbms_xplan. display могут передаваться следующие необязательные параметры:
table_name – имя таблицы, в которой хранится подготовленный план выполнения, (указанное в explain plan).
statement_id – идентификатор плана (указанный в explain plan).
format – определяет набор выводимой информации, возможные значения:
- BASIC: минимальная необходимая информация. TYPICAL: значение по умолчанию. SERIAL: аналогично TYPICAL но не выводится информация о параллельном выполнении запроса, даже если оно имеет место. ALL: полный набор информации
filter_preds – условия фильтрации строк из таблицы хранения плана.
type – тип представления плана, по умолчанию – TEXT (текстовый), другие возможные значения - 'ACTIVE', 'HTML', 'XML'.
Полное описание пакета:
http://docs. /cd/E11882_01/appdev.112/e40758/d_xplan. htm#ARPLS378
3.3 Статистика выполнения запроса
Для получения статистики выполнения запроса в sqldeveloper, используется команда autotrace (F6)
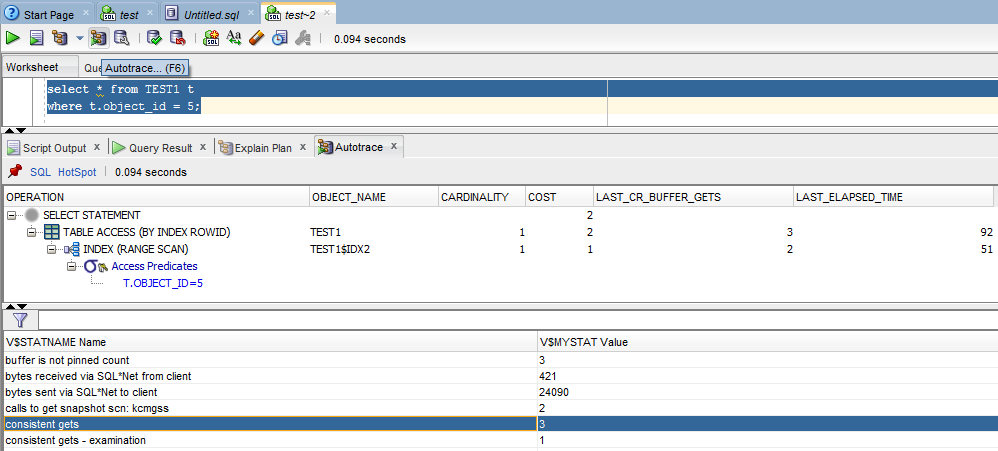
Для анализа выполнения запроса, особый интерес представляет статистика выполнения
session logical reads – количество чтений блоков из оперативной памяти
4. Статистика данных и ее сбор.
Статистика данных является ключевым фактором при построении плана выполнения запроса.
4.1 Просмотр существующей статистики данных
Значения статистики данных можно получить из представлений словаря данных dba/all/user_tables для таблиц и dba/all/user_indexes для индексов.
Поля со значениями статистики данных в представлении USER_TABLES
NUM_ROWS | Число строк |
BLOCKS | Число занятых блоков |
CHAIN_CNT | Число строк, находящихся более чем в одном блоке |
AVG_ROW_LEN | Средний размер строки данных в байтах |
Поля со значениями статистики данных в представлении USER_TABLES
BLEVEL | Количество уровней в B*-дереве индекса |
LEAF_BLOCKS | Число листовых блоков индекса |
DISTINCT_KEYS | Количество различных значений в проиндексированном столбце (столбцах). Для уникальных индексов равно числу строк в проиндексированной таблице |
AVG_LEAF_BLOCKS_PER_KEY | Среднее число листовых блоков, в которых встречается одно и тоже значение ключа индекса. Для уникальных индексов эта величина равна 1. |
AVG_DATA_BLOCKS_PER_KEY | Среднее количество блоков данных таблицы, соответствующих одному значению ключа индекса. |
CLUSTERING_FACTOR | Фактор кластеризации, характеризует соответствие упорядоченности строк в таблице упорядоченности значений индекса. Если значение фактора кластеризации приближается к количеству блоков таблицы, то это означает, очень хорошее соответствие упорядоченности, и ссылки из листового блока индекса будут, скорее всего, вести в один блок данных таблицы. Если значение фактора кластеризации приближается к количеству строк, то строки расположены в блоках таблицы случайно по отношению к значениям индекса. И ссылки из одного листового блока индекса будут указывать на различные блоки данных проиндексированной таблицы. |
4.2 Сбор статистики данных
Сбор статистики для отдельной таблицы:
begin
dbms_stats. gather_table_stats (
ownname => ‘схема’,
tabname => ‘таблица’,
cascade => TRUE/FALSE
);
end;
/
Параметр cascade определяет, нужно ли собирать статистику для всех индексов таблицы. Для сбора статистики отдельного индекса используется процедура dbms_stats. gather_index_stats.
Для сбора статистики по всем таблицам схемы:
dbms_stats. gather_schema_stats.
Подробнее о сборе статистики и остальных процедурах пакета dbms_stats:
http://docs. /cd/E11882_01/appdev.112/e40758/d_stats. htm#ARPLS059
5. Подсказки оптимизатору
Общий способ применения:
select
/*+ подсказки*/
остальной текст запроса
Некоторые подсказки, необходимые для выполнения:
5.1 Выбор способа доступа к строкам таблицам
full – использовать полное сканирование всех блоков таблицы.
Пример:
select
/*+ full(t)*/
t.*
from tab t
where t. id = 1;
Если в запросе для таблицы указывается псевдоним, то в подсказке также указывается псевдоним, а не имя таблицы.
index – использование определенного индекса для доступа к таблице.
Пример:
select
/*+ index(t tab$idx)*/
t.*
from tab t
where t. id = 1;
no_index – указание не использовать определенный индекс (при этом другие, не указанные в no_index могут использоваться).
5.2 Выбор способа соединения таблиц
ordered – порядок выполнения соединения таблиц должен соответствовать порядку их следования в запросе.
leading – указание начинать соединение таблиц в запросе начиная с указанных
Пример:
select /*+ leading(e j) */ *
from employees e, departments d, job_history j
where e. department_id = d. department_id
and e. hire_date = j. start_date;
use_nl – использовать соединение методом вложенных циклов
Пример:
select
/*+ use_nl(l h) */
h. customer_id, l. unit_price
from orders
join order_items l on l. order_id = h. order_id;
Дается указание использовать соединение методом вложенных циклов, где orders – внешняя таблица, а order_items – внутренняя.
Аналогично, use_hash – использовать для указанных в подсказке таблиц соединение хэширования, use_merge – соединение сортировки и слияния.
Подсказки no_use_nl, no_use_hash, no_use_merge – не использовать соответствующие методы соединения.
Полный список подсказок:
https://docs. /cd/E11882_01/server.112/e41084/sql_elements006.htm#SQLRF00219
