Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
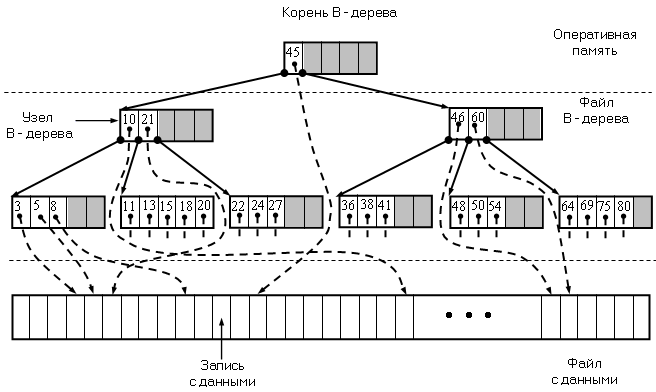
Плотный индексный файл
Плотный индексный файл
Плотный индексный файл предполагает размещение записей в файле в произвольном порядке и создание другого файла с индексами, с помощью которого будут отыскиваться требуемые записи. Этот дополнительный файл называется плотным индексом.
Плотный индекс состоит из индексов (k, р), где р - указатель на запись с ключом k в основном файле. Все индексы в индексном файле отсортированы по значению ключа.
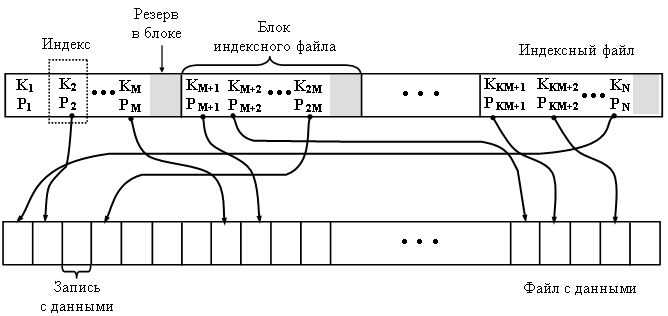
Ki – ключ записи для поиска, K1 ![]() K2
K2 ![]() · · ·
· · · ![]() KN,
KN,
Pi – файловый указатель на запись с данными,
M – количество индексов в блоке индексного файла,
N - количество записей в файле с данными.
Индексный файл разделен на блоки для блочного доступа. В каждом блоке выделен резерв для новых индексов при добавлении в файл с данными новых записей. Разбиение файла с данными на блоки не обязательно, поскольку индекс каждой записи фиксируется в плотном индексе и можно выполнять прямой доступ к записи по файловому указателю записи, считанному из индексного файла
При использовании такой организации плотный индекс служит для поиска в основном файле записи с заданным ключом. Благодаря упорядоченности ключей, в индексном файле можно организовать двоичный поиск блока с заданным ключом, что существенно сокращает число обращений к индексному файлу по сравнению с полным перебором всех блоков индекса.
При добавлении новой записи она может быть размещена в конце файла с данными или по месту удаленной ранее записи (если записи в файле с данными не закреплены). Индекс новой записи размещается в соответствующем блоке плотного индекса с соблюдением упорядоченности ключей индексов. Для этого методом двоичного поиска отыскивается соответствующий блок и в него записывается индекс новой записи.
При вставке нового индекса может возникнуть переполнение блока индексного файла, когда резерв для новых индексов в блоке исчерпан. В этом случае необходима перестройка индексного файла, заключающаяся в вытеснении части индексов в последующий блок или расщеплении переполненного блока. Расщепление выполняется путем создания нового блока индексного файла и вставки его вслед за переполненным блоком. Часть индексов переносится из переполненного блока в новый блок индекса.
Чтобы удалить запись, прежде выполняется двоичный поиск по ключу блока индексом записи и затем запись удаляется из файла с данными во месту. указанному файловым указателем индекса. По месту записи устанавливается бит удаления и удаляется соответствующий индекс в плотном индексе (возможно, также устанавливая бит удаления индекса). Файловый указатель удаленной записи можно зафиксировать во вспомогательной структуре для того чтобы разместить на этом месте новую запись при выполнении операции включения.
 Разреженный индексный файл
Разреженный индексный файл
Еще одним распространенным способом организации индексного файла является поддержание файла с данными в отсортированном по значениям ключей порядке. Чтобы облегчить процедуру поиска, можно создать второй файл, называемый разреженным индексом, который состоит из пар (k, p), где k-значение ключа, а p-файловый указатель блока, в котором значение ключа первой записи равняется k. Этот разреженный индекс также отсортирован по значениям ключей.

Ki – минимальный ключ поиска в блоке записей с данными, K1 ![]() K2
K2 ![]() ···
··· ![]() KN,
KN,
Pi – файловый указатель на блок записей с данными,
M – количество индексов в блоке индексного файла,
N - количество записей в файле с данными.
Чтобы отыскать запись с заданным ключом k, надо сначала просмотреть индексный файл, отыскивая в нем индекс (k, p). В действительности отыскивается блок индекса с наибольшим ключом x таким, что x![]() k и далее в считанном по индексу блоке файла с данными находится запись с ключом k.
k и далее в считанном по индексу блоке файла с данными находится запись с ключом k.
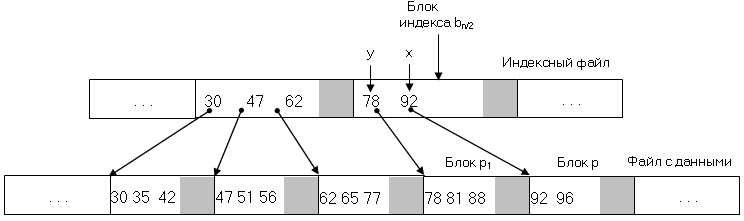
Разработано несколько стратегий просмотра индексного файла. Простейшим из них является линейный поиск. Индексный файл по блокам читается с самого начала, пока в очередном блоке не встретится индекс (k, p) или (x, p), причем x > k. В последнем случае у предыдущего индекса (y, p1) должно быть y < k, и если запись с ключом k действительно существует, то она находится в блоке p1. Линейный поиск годится лишь для небольших индексных файлов. Более эффективным методом является двоичный поиск.. Допустим, индексный файл хранится в блоках b1,b2, . . , bn. Чтобы отыскать значение ключа k, берется средний блок bn/2 и ключ k сравнивается со значением ключа в первом индексе данного блока. Если ключ k меньше, чем ключ в первом индексе, то продолжается двоичный поиск нужного блока среди блоков b1 . . bn/2-1. Если ключ k больше ключа в первом индексе блока bn/2, то выполняется поиск в блоке bn/2 ключа x > k и чтение блока p1 из файла данных для дальнейшего поиска записи с ключом k в считанном блоке. Если ключ k больше ключа в первом индексе блока bn/2+1 , то продолжается двоичный поиск нужного блока индекса среди блоков bn/2+1 . . bn. При использовании двоичного поиска нужно проверить лишь log2(n+1) блоков индексного файла.
Пример: поиск записи с ключом 81.
Чтобы создать индексированный файл, в файле с данными записи сортируются по значениям их ключей, а затем распределяются по блокам в возрастающем порядке ключей. В каждый блок можно упаковать столько записей, сколько туда помещается. Однако в каждом блоке можно оставить место для дополнительных записей, которые могут вставляться туда впоследствии. Преимущество такого подхода заключается в том, что вероятность переполнения блока, куда вставляются новые записи, в этом случае оказывается ниже (иначе надо будет обращаться к смежным блокам). После распределения записей по блокам создается индексный файл: просматривается по очереди каждый блок в файле с данными и первый ключ каждого блока записывается в очередной блок индексного файла. Подобно тому, как это сделано в основном файле, в блоках индексного файла можно оставить резерв на количество индексов для последующего роста.
Допустим, что есть отсортированный файл записей, хранящихся в блоках b1,b2, . . ,bn. Чтобы вставить в этот отсортированный файл новую запись, используется индексный файл, с помощью которого определяется, какой блок bi должен содержать новую запись. Если новая запись умещается в блок bi, она туда помещается в правильной последовательности. Если новая запись становится первой записью в блоке bi, тогда выполняется корректировка индексного файла.
Если новая запись не умещается в блок bi, то можно применить одну из нескольких стратегий. Простейшая из них заключается в том, чтобы перейти на блок bi+1 (который можно найти с помощью индексного файла) и узнать, можно ли последнюю запись bi переместить в начало bi+1. Если можно, последняя запись из bi перемещается в bi+1 , а новую запись можно затем вставить на подходящее место в bi. В этом случае нужно скорректировать индекс в индексном файле для bi+1 и, возможно, для bi.
Если блок bi+1 так же заполнен или если bi является последним блоком, то в конец файла с данными записывается новый блок. Новая запись вставляется в этот новый блок, который должен размещаться вслед за блоком bi. Затем индекс нового блока записывается в соответствующий блок индексного файла. В новый блок файла с данными можно перенести некоторую часть записей из переполненного блока bi, восстановив тем самым резервное место в блоке bi.
При добавлении индексов новых блоков в индексный файл также может произойти переполнение какого либо блока индексного файла. в этом случае выполняется перестройка индексного файла, подобная перестройке плотного индексного файла.
Внешние деревья поиска.
Для хранения таблиц во внешней памяти можно использовать древовидные структуры В - дерево и В+ - дерево, которые особенно удачно подходят для представления внешней памяти и стали стандартным способом организации индексных файлов в системах баз данных.
Обобщением дерева двоичного поиска является m - арное дерево, в котором каждый узел имеет не более m сыновей. Так же, как и для деревьев двоичного поиска, считается, что выполняется следующее условие: если n1 и n2 являются двумя сыновьями одного узла и n1 находится слева от n2, тогда все потомки узла n1 оказываются меньше потомков узла n2.
Однако в данном случае существует проблема хранения узлов в файлах, когда файлы хранятся в виде блоков внешней памяти. Правильным применением идеи разветвленного дерева является представление об узлах как о физических блоках на диске. Внутренний узел содержит указатели на свои m сыновей, а так же m-1 ключевых значений, которые разделяют потомков этих сыновей. Листья так же являются блоками. Эти блоки содержат файловые указатели на записи файла с данными.
Использование m - арного дерева поиска значительно сокращает число обращений к блокам и время поиска записи по сравнению с деревом двоичного поиска, состоящего из n узлов.
Однако нельзя сделать m сколько угодно большим, поскольку, чем больше m, тем больше должен быть размер блока. Считывание и обработка более крупного блока занимает больше времени, поэтому существует оптимальное значение m, которое позволяет минимизировать время, требующееся для просмотра внешнего m - арного дерева поиска. На практике значение, близкое к такому минимуму, получается для довольно широкого диапазона величин m.
В-дерево
Б-дерево – сбалансированное дерево, удобное для хранения информации на дисках [1-4]. Характерным для Б-дерева является его малая высота h. Представление информации во внешней памяти в виде Б-дерева стало стандартным способом в системах баз данных.
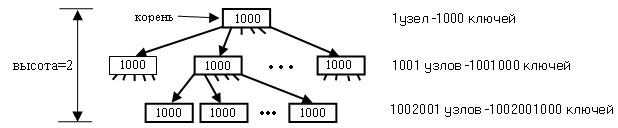
В Б-дереве узел может иметь много сыновей, на практике до тысячи. Количество сыновей (максимальное) определяет степень Б-дерева. Узлы Б-дерева содержат не один элемент, а группу элементов с суммарным объемом в один блок файла, который обычно по размеру соответствует одному сектору диска. Чтобы уменьшить количество операций чтения-записи на диск при поиске элемента в Б-дереве, нужно максимально уменьшить его высоту. Для этого степень Б-дерева делается максимальной. Типичная степень узла – (50-2000). Она зависит от соотношения размера сектора и размера отдельного элемента. Например, Б-дерево степени 1000 и высоты 2 может хранить более миллиарда ключей.
Общая схема обработки отдельных узлов B - дерева выглядит так:
1. . . .
2. x ← указатель на какой-либо узел
3. Disk_Read(x)
4. обработка и изменение узла х
5. Disk_Wirte(x)
6. операции, которые только используют узел х, но не изменяют его
7. . . .
Узел-корень дерева обычно всегда хранится в ОП, для доступа к остальным ключам требуется всего 2 операции чтения с диска.
Представление Б-дерева
Как и в других деревьях, данные и ключи хранятся в узлах дерева. Обычно данные представлены в виде файлового указателя на запись в файле с данными. При перемещении в B - дереве ключа вместе с ключом перемещается и указатель.
В отличие от 2-3 дерева ключи и дополнительная информация размещается не только в листьях, но и во внутренних узлах дерева. Хотя возможна организация Б-деревьев, в которых дополнительная информация хранится только в листьях, а во внутренних узлах – только ключи и указатели на сыновей (B+ - дерево). Это экономит память во внутренних узлах и позволяет увеличить их степень при том же размере сектора.
Узел B - дерева хранит:
| n[x] – текущее количество ключей, хранящихся в узле, |
| сами ключи в неубывающем порядке key1[x] ≤ key2[x] ≤ . . . ≤ keyn[x][x], |
| n[x] указателей на записи в файле с данными d1[x], d2[x], . . . , dn[x][x], |
| булевский признак leaf[x], истинный, если узел – лист, |
| n[x]+1 указателей p1[x], p2[x], . . . ,pn[x]+1[x] на сыновей. У листьев эти поля не определены. |
Узел х, хранящий n[x] ключей, имеет n[x]+1 сыновей. Хранящиеся в х ключи key1[x], . . . , keyn[x][x] служат границами, разделяющими всех потомков узла на n[x]+1 групп. За каждую группу отвечает один из сыновей х - pi[x]. Алгоритм поиска в Б-дереве сравнивает искомый ключ с границами в узле х и выбирает один из n[x]+1 путей для дальнейшего поиска.
Все листья находятся на одной глубине, равной высоте дерева h.
Число ключей, хранящихся в одном узле, ограничено сверху и снизу единым для Б-дерева числом t, где t – минимальная степень дерева (t ≥ 2).
Каждый узел, кроме корня содержит минимум t - 1 ключей и t сыновей. Если дерево не пусто, то в корне должен храниться хотя бы один ключ. В узле хранится не более 2t - 1 ключей, и внутренний узел имеет не более 2t сыновей. Узел, хранящий 2t - 1 ключей, называется полным.
Если t=2, то у каждого внутреннего узла может быть 2, 3 или 4 сына и такое дерево называется 2-3-4 деревом.
Высота B - дерева оценивается формулой ![]() , где n - число индексов в B - дереве.
, где n - число индексов в B - дереве.
То есть, временная сложность операций для Б-дерева оценивается как O(logt n).
Операции для Б-дерева
Считаем, что корень дерева всегда находится в оперативной памяти и операция Disk_Read для корня не выполняется. Но когда корень изменяется, его нужно сохранять на диске.
Все узлы, передаваемые операциям, как входные параметры, уже считаны с диска.
Поиск в Б-дереве
Рассмотрим рекурсивную операцию B_Tree_Search, параметрами которой является указатель х на корень поддерева и ключ k искомого элемента. Операция вызывается первоначально для корня дерева B_Tree_Search(root[T], k). При нахождении в дереве элемента с заданным ключом операция возвращает пару (y, i), где у – узел Б-дерева, i – порядковый номер указателя, для которого keyi [y]=k. Иначе операция возвращает nil.
B_Tree_Search(x, k)
1. i ← 1
2. while i ≤ n[x] and k > keyi [x]
3. do i ← i+1
4. if i ≤ n[x] and k = keyi [x]
5. then return di
6. if leaf [x] = TRUE
7. then return nil
8. else Disk_Read (pi [x])
9. return B_Tree_Search (pi [x], k)
При проходе по Б-дереву число обращений к диску O (logt n).
Создание пустого Б-дерева
Чтобы построить дерево, сначала создается пустое дерево с помощью операции B_Tree_Create, а затем в него включаются элементы с помощью операции B_Tree_Insert. Обе эти операции используют вспомогательную операцию Allocate_Node, которая выделяет на диске место для нового узла. Эта операция занимает O(1) времени и не использует операцию Disk_Read.
B_Tree_Create(T)
1. x ← Allocate_Node()
2. leaf [x] ← TRUE
3. n[x] ← 0
4. Disk_Write (x)
5. root[T] ← x
Операция требует O (1) времени, так как выполняется одно обращение к диску.
Операция расщепления узла Б-дерева
Ключевым моментом добавления элемента в дерево является разбиение полного узла y с 2t - 1 ключами на два узла, имеющие по t - 1 элементов в каждом. При этом ключ-медиана отправляется к родителю узла y – x. Этот ключ становится разделителем двух полученных узлов. Ключ-медиана вставляется в упорядоченное множество ключей узла х.
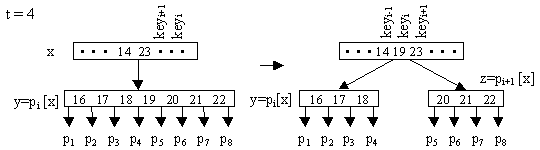
Элементы с большими, чем медиана ключами, переходят в новый узел z. Входными параметрами операции является неполный узел х, индекс i и полный узел y (y = pi [x]).
B_Tree_Split (x, i, y)
1 z ← Allocate_Node( )
2 leaf [z] ← leaf [y]
3 n [z] ← t – 1
4 for j ← 1 to t – 1
5 do keyj [z] ← keyj+1 [y]
6 dj [z] ← dj+1 [y]
7 if not leaf [y]
8 then for j←1 to t
9 do pj [z] ← pj+1 [y]
10 n [y] ← t -1
11 for j ← n [x] +1 down to i+1
12 do pj+1 [x] ← pj [x]
13 pj+1 [x] ← z
14 for j ← n [x] down to i
15 do keyj+1 [x] ← keyj [x]
16 dj+1 [x] ← dj [x]
17 keyi [x] ← keyt [y]
18 di [x] ← dt [y]
19 n [x] ← n [x+1]
20 Disk_Write [x]
21 Disk_Write [y]
22 Disk_Write [z]
Добавление элемента в Б-дерево
Входными параметрами функции включения в B - дерево - T являются ключ k и файловый указатель на запись в файле с данными - d. Операция при включении проходит по одному из путей поиска от корня к месту включения, которое является листом B - дерева. Для этого требуется время O(th)=O(t logt n) и O(h) = O(logt n) обращений к диску. На пути поиска встречающиеся полные узлы расщепляются с помощью операции B_Tree_Split.
B_Tree_Insert (T, k, d )
1 r ← root [T]
2 if n [r] = 2t –1
3 then
4 s ← Allocate_Node( )
5 root ← s
6 leaf [s] ← FALSE
7 n [s] ← 0
8 p1 [s] ← r
9 B_Tree_Split (s, 1, r)
10 B_Tree_Insert_Nonfull (s, k, d)
11 else B_Tree_Insert_Nonfull (r, k, d)
Точкой роста Б-дерева является не лист, а корень.
Новый корень содержит ключ-медиану старого корня.
Сделав корень неполным (или он не был таковым с самого начала), мы вызываем операцию B_Tree_Insert_Nonfull (x, k, d), которая добавляет индекс (k, d) в поддерево с корнем в неполном узле х. Это рекурсивная операция.
B_Tree_Insert_Nonfull (x, k, d)
1 i ← n [x]
2 if leaf [x] = TRUE
3 then while i ≥ 1 and k < keyi [x]
4 do keyi+1 [x] ← keyi [x]
5 di+1 [x] ← di [x]
6 i ← i –1
7 keyi+1 [x] ← k
8 di+1 [x] ← d
9 n [x]← n [x]+1
10 Disk_Write [x]
11 else while i ≥ 1 and k< keyi [x]
12 do i ← i –1
13 i ← i+1
14 Disk_Read (pi [x])
15 if n[p[x]] = 2t – 1
16 then B_Tree_Split (x, i, pi [x])
17 if k> keyi [x]
18 then i ← i+1
19 B_Tree_ Insert_Nonfull (pi [x], k, d)
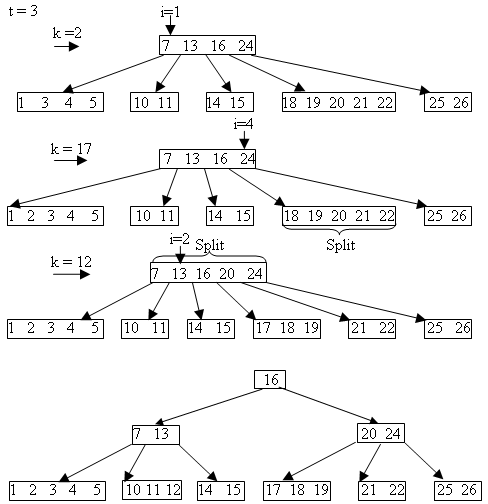
Пример включения в B - дерево элементов с ключами 2, 17, 12: