Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Практическая работа 6. Основы статистического анализа
Цель работы - закрепить навыки выполнения основных операций статистического анализа данных.
Задание 1
По таблице, содержащей данные о среднегодовой стоимостью основных производственных фондов (ОПФ) и выпуском валовой продукции в сопоставимых ценах для 30 заводов, выполнить:
Выбрать из таблицы 1 номера заводов для выполнения задания. Выбрать из таблицы 2 данные, соответствующие номерам заводов для Вашего варианта. Произвести группировку заводов по среднегодовой стоимости ОПФ и построить гистограмму и кумуляту распределения, применив инструмент «Гистограмма» из Пакета анализа Excel без указания диапазона карманов. Пример – Упражнение 1. Вычислить основные статистические характеристики и определить доверительный интервал для выборочной средней двумя способами: посредством стандартных функций Excel и с помощью инструмента «Описательная статистика» » из Пакета анализа Excel. Пример – Упражнение 2. Оценить степень связи между двумя признаками: Среднегодовая стоимость ОПФ и Валовая продукция, вычислив значение линейного коэффициента корреляции. Использовать два метода: функция КОРРЕЛ и инструмент Корреляция из Пакета анализа Excel. Пример – Упражнение 3.Варианты заданий
Таблица 1
Номер варианта | Номера заводов | Номер варианта | Номера заводов |
1 | 1-30 | 6 | 26-55 |
2 | 6-35 | 7 | 31-60 |
3 | 11-40 | 8 | 36-65 |
4 | 16-45 | 9 | 41-70 |
5 | 21-50 | 10 | 46-75 |
Таблица 2
Номер завода | Среднегодовая стоимость ОПФ, млн. руб. | Валовая продукция, млн. руб. |
6,9 | 10,0 | |
8,9 | 12,0 | |
3,0 | 3,5 | |
5,7 | 4,5 | |
3,7 | 3,4 | |
5,6 | 8,8 | |
4,5 | 3,5 | |
7,1 | 9,6 | |
2,5 | 2,6 | |
10,0 | 13,9 | |
6,5 | 6,8 | |
7,5 | 9,9 | |
7,1 | 9,6 | |
8,3 | 10,8 | |
5,6 | 8,9 | |
4,5 | 7,0 | |
6,1 | 8,0 | |
3,0 | 2,5 | |
6,9 | 9,2 | |
6,5 | 6,9 | |
4,1 | 4,3 | |
4,1 | 4,4 | |
4,2 | 6,0 | |
4,1 | 7,5 | |
5,6 | 8,9 | |
3,4 | 3,5 | |
3,1 | 3,3 | |
3,5 | 3,5 | |
4,1 | 4,5 | |
5,8 | 7,5 | |
5,2 | 6,9 | |
3,8 | 4,3 | |
4,1 | 5,9 | |
5,6 | 4,8 | |
4,5 | 5,8 | |
4,2 | 4,6 | |
6,1 | 8,4 | |
6,5 | 7,3 | |
2,0 | 2,1 | |
6,4 | 7,8 | |
4,0 | 4,2 | |
8,0 | 10,6 | |
5,1 | 5,8 | |
4,9 | 5,3 | |
4,3 | 4,9 | |
5,8 | 6,0 | |
7,2 | 10,4 | |
6,6 | 6,9 | |
3,0 | 3,5 | |
6,7 | 7,2 | |
4,0 | 4,2 | |
8,0 | 10,4 | |
5,1 | 5,8 | |
4,9 | 5,3 | |
6,3 | 8,0 | |
7,5 | 9,4 | |
6,6 | 11,2 | |
3,3 | 3,4 | |
6,7 | 7,0 | |
3,4 | 2,0 | |
3,3 | 3,3 | |
3,9 | 5,4 | |
4,1 | 5,0 | |
5,9 | 7,0 | |
6,4 | 7,9 | |
3,9 | 6,4 | |
5,6 | 4,6 | |
3,5 | 4,1 | |
3,0 | 3,8 | |
5,4 | 8,5 | |
2,0 | 1,8 | |
4,5 | 4,6 | |
4,8 | 5,2 | |
5,9 | 9,0 | |
7,2 | 8,6 |
Упражнение 1. Построение выборочной функции распределения
Для построения выборочных функций распределения в Excel используют инструмент Гистограмма из Пакета анализа. При этом весь диапазон изменения случайной величины разбивают на интервалы равной ширины, называемые карманами. Число карманов обычно 5-15. Вычисляется число попаданий значений случайной величины в каждый карман. По ним вычисляются статистические (относительные) частоты - отношение числа попаданий в карман m к общему числу испытаний n (m/n), по которым и строится гистограмма.
Пример. Построим выборочное распределение по данным о продажах товара за 2 месяца (табл. 1).
Разместим данные в диапазоне A3:E14.
Здесь же разместим диапазон карманов – граничных значений. При подсчете в карман включаются значения на правой границе интервала и не включаются значения на левой границе. В нашем случае данные будут группироваться в интервалы 0-170, 171-175, 176-180, ..., 226-230.
Карманы для разбиения разместим в ячейках G2:G14.
Таблица 1
Дневные продажи | Карманы | ||||
выборка за 2 месяца | 170 | ||||
174 | 206 | 176 | 208 | 211 | 175 |
202 | 200 | 197 | 209 | 192 | 180 |
191 | 195 | 201 | 200 | 208 | 185 |
209 | 178 | 202 | 195 | 210 | 190 |
202 | 187 | 203 | 212 | 227 | 195 |
199 | 197 | 203 | 206 | 230 | 200 |
196 | 190 | 190 | 217 | 203 | 205 |
181 | 190 | 204 | 214 | 197 | 210 |
209 | 223 | 199 | 201 | 194 | 215 |
211 | 199 | 196 | 189 | 195 | 220 |
191 | 188 | 184 | 199 | 210 | 225 |
182 | 170 | 203 | 193 | 180 | 230 |
Построим выборочное распределение дневных продаж с помощью инструмента Гистограмма из Пакета анализа Microsoft Excel (вызов через меню Данные - Анализ данных). На рис. 1 показано заполнение параметров диалогового окна инструмента Гистограмма.
Входной интервал $А$3:$Е$14 - это диапазон исследуемых данных;
Интервал карманов $G$2:$G$14 - это границы, в которые группируются входные данные;
Выходной интервал $I$1 – это ячейка, начиная с которой будет выведен результат.
Установим также флажки Вывод графика и Интегральный процент.
Флажок Интегральный процент устанавливают, если надо вычислить проценты частот с накоплением и вывести график интегральных процентов (кумуляту).
Результат работы инструмента показан на рис. 2.

Рис. 1

Рис. 2
Примечание. Интервал карманов можно не задавать. В этом случае программа выполнит разбиение на своё усмотрение.
Упражнение 2. Расчет основных статистических характеристик и определение доверительного интервала для выборочной средней
При обработке случайных выборок в первую очередь вычисляют их числовые параметры, характеризующие тенденции, разброс и изменчивость данных. Их можно рассчитывать как с помощью стандартных функций, так и с применением инструмента Описательная статистика из Пакета анализа, который позволяет получить единый статистический отчет по всем характеристикам входных данных.
Применим инструмент Описательная статистика к выборке, представленной в табл. 1. Для этого скопируем данные выборки на Лист 2 электронной таблицы и разместим их в столбце A (рис. 4).
Выберем инструмент Описательная статистика через меню Данные - Анализ данных. На рис. 3 показано заполнение параметров инструмента.
Входной интервал $А$1:$А$61 – это диапазон анализируемых данных. Здесь данные выборки расположены по столбцам, поэтому установлен переключатель По столбцам. Флажок Метки в первой строке установлен для вывода в результирующей таблице заголовка «Дневные продажи».
Выходной интервал $C$1 – это ячейка, начиная с которой будет выведен результат.
Установим также флажок Итоговая статистика – в выходном интервале для каждого столбца будут рассчитаны все статистические показатели.
Поле Уровень надежности позволяет установить требуемый уровень доверительной вероятности; по умолчанию 95%, что соответствует уровню значимости 0.05. Результат работы инструмента показан на рис. 4 в столбцах С и D.
Произведём расчёты основных статистических показателей, используя соответствующие статистические функции. Результаты расчётов показаны на рис. 4 в столбце Е.
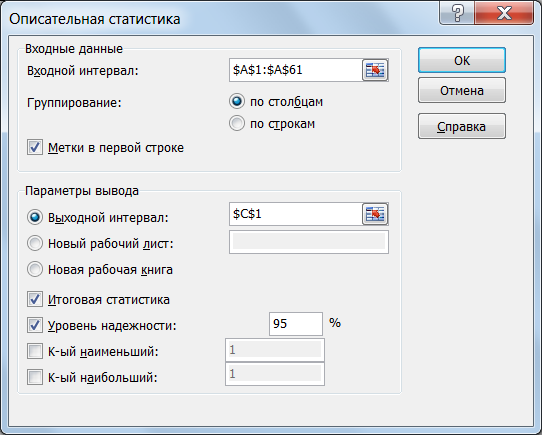
Рис. 3
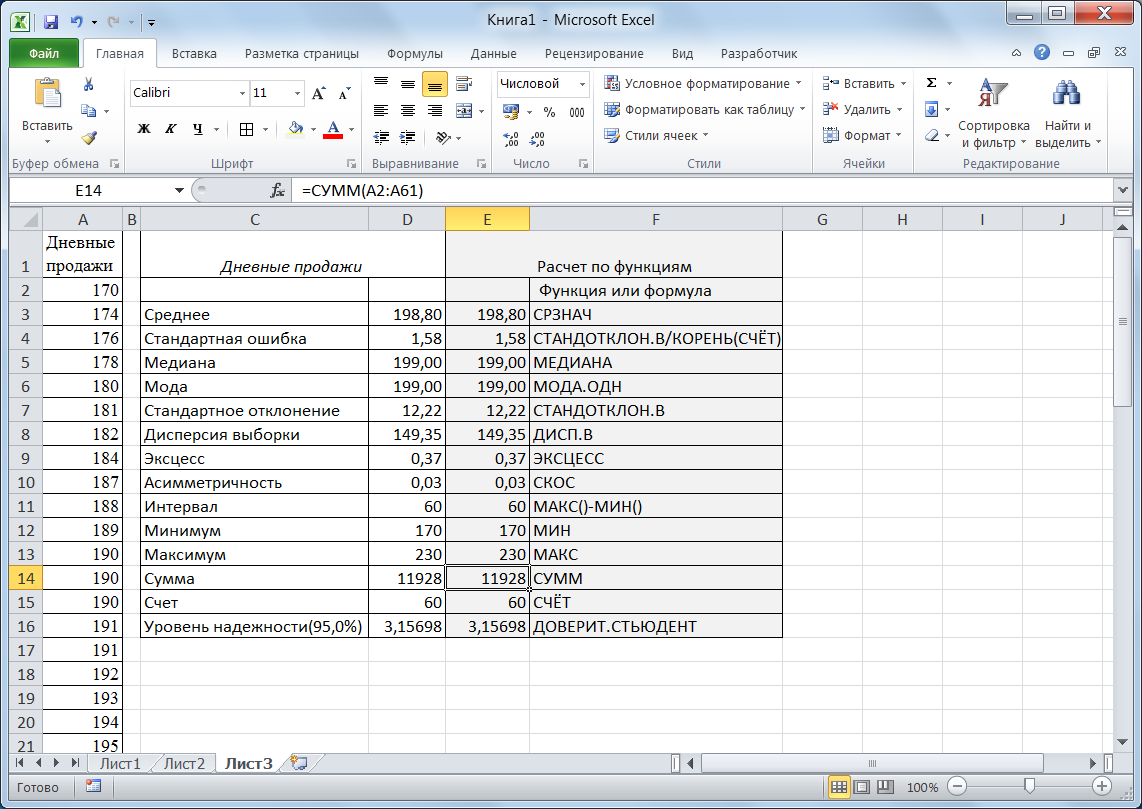
Рис. 4
Важная характеристика выборки – среднее значение – обычно не совпадает со средним генеральной совокупности. Поэтому актуальным является определение доверительного интервала для среднего значения генеральной совокупности.
Инструмент Описательная статистика вычисляет предельную ошибку выборочной средней: на рис. 4 она равна 3,15698. Округлив до 2-х знаков после запятой, получим значение 3,16. Таким образом, можно утверждать, что в 95% случаев значение генеральной средней попадёт в интервал [192,8-3,16; 192,8+3,16]=[189,64; 195,96].
Функция ДОВЕРИТ. СТЬЮДЕНТ также вычисляет предельную ошибку выборочной средней по заданному уровню значимости, стандартному отклонению и числу значений в выборке. В нашем случае формула имеет вид: =ДОВЕРИТ. СТЬЮДЕНТ(0,05;D7;D15).
Упражнение 3. Корреляция
Степень связи двух выборок (случайных величин X и Y) оценивается коэффициентом корреляции R. Коэффициент корреляции R принимает значения от –1 до 1. Если R=0 – зависимости нет, R>0 – зависимость прямо пропорциональная, R<0 – зависимость обратно пропорциональная.
Функция Excel КОРРЕЛ и инструмент Корреляция Пакета анализа MS Excel вычисляет степень линейной взаимозависимости между выборками.
Если коэффициент корреляции |R|>0.6, то линейную зависимость между выборками считают выявленной, при |R|<0.4 – не выявленной.
Пример. Определим степень взаимосвязи между доходом семьи и числом посещений супермаркета в месяц – рис. 5. Здесь же показан результат функции
КОРРЕЛ(A2:A12;B2:B12)= –0.981225708.
Это значение говорит о высокой степени обратной линейной зависимости между рассматриваемыми признаками.
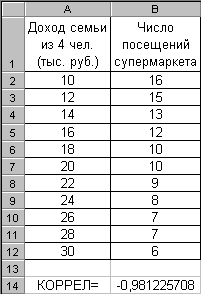
Рис. 5
Теперь добавим третий параметр – среднюю сумму одной покупки (рис. 6) и применим инструмент Корреляция: меню Данные - Анализ данных…. Параметры заполним как на рис. 7.
Результат показан в правой части рис. 6: в ячейках E1:H4 вычислена корреляционная матрица, на пересечении столбцов и строк которой записаны коэффициенты корреляции между параметрами (столбцами).
В результате анализа выявлены:
- сильная степень обратной линейной зависимости между столбцом 1 и столбцом 2
(R= –0,9812257); сильная степень прямой линейной зависимости между столбцом 1 и столбцом 3 (R= 0,99497); сильная степень обратной линейной зависимости между столбцом 2 и столбцом 3
(R= –0,982206);

Рис. 6
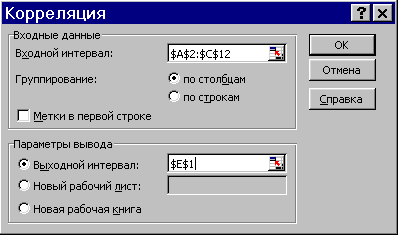
Рис. 7
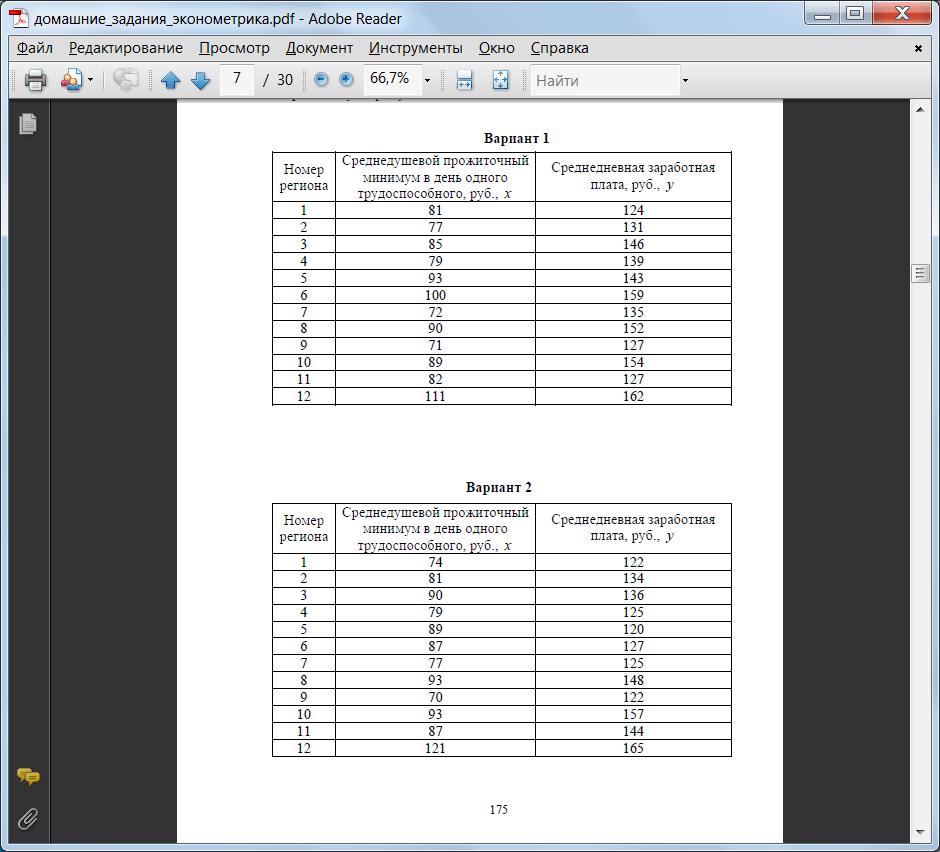
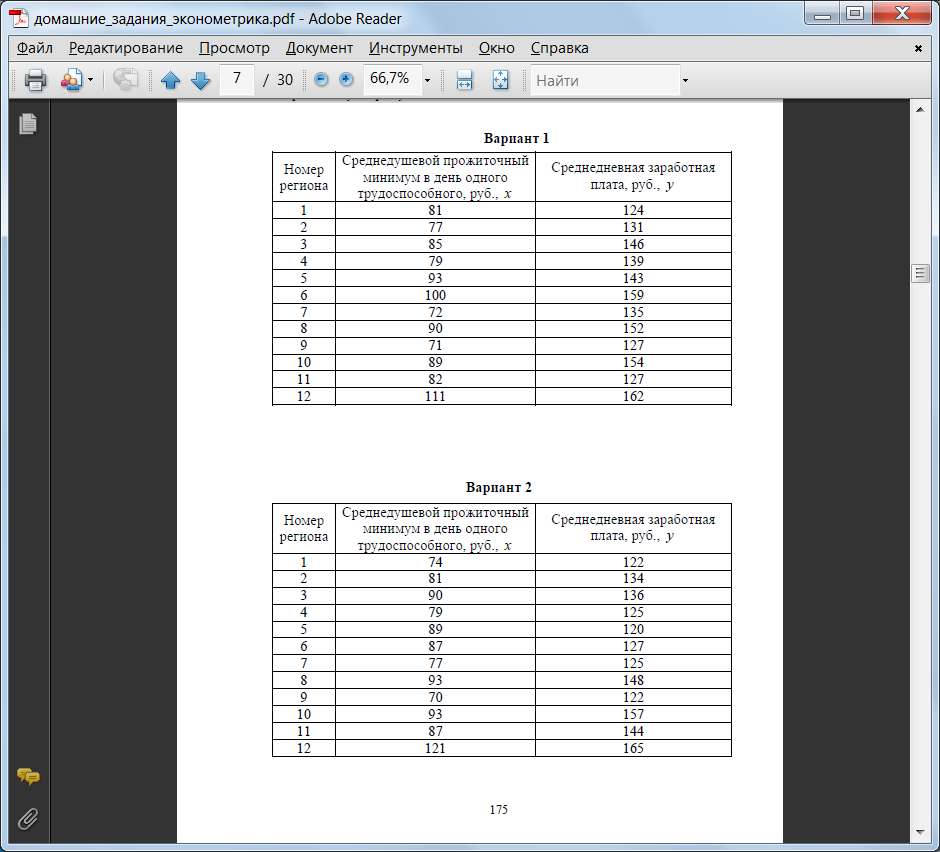
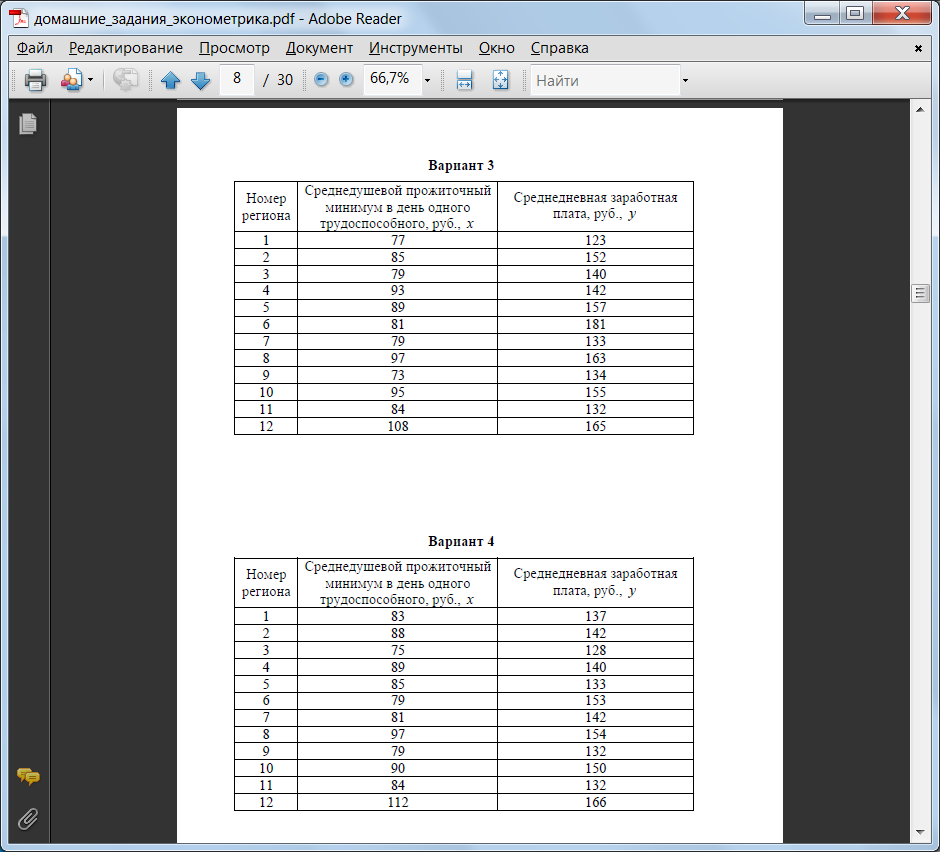
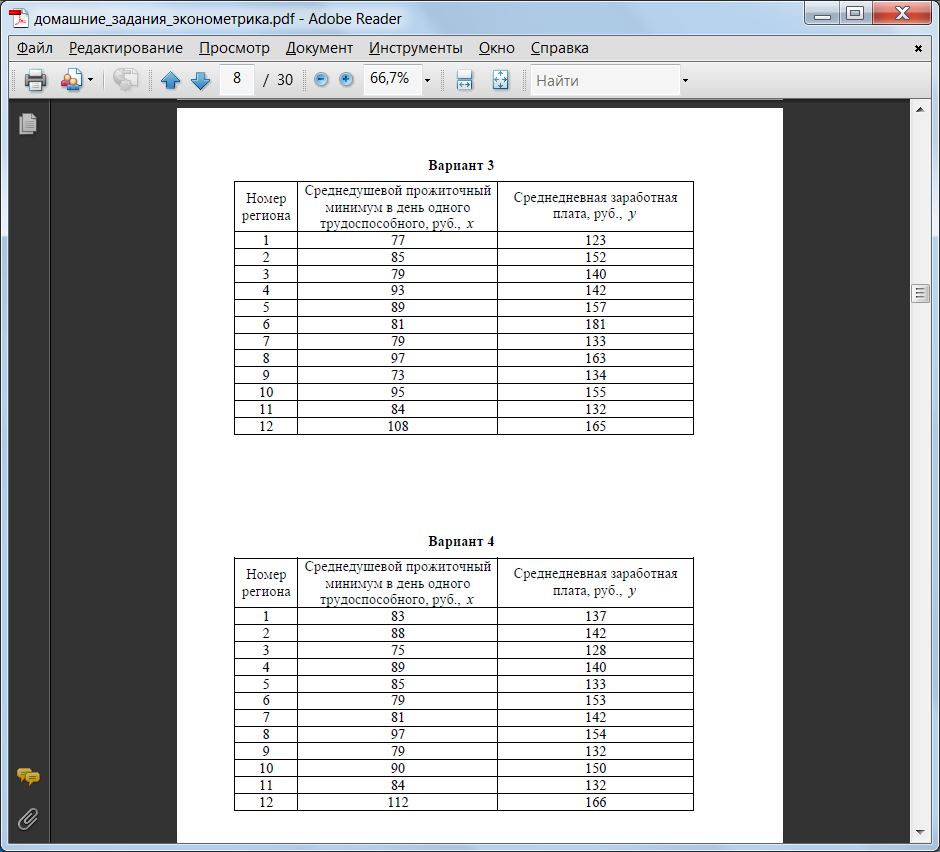
Задание 2
По выборочным данным вычислить линейный коэффициент корреляции тремя способами:- по формуле (1); с помощью стандартной функции КОРРЕЛ; с помощью инструмента «Корреляция» из Пакета анализа Excel.
- по формулам (2); графическим способом, построив линию тренда на диаграмме с показом уравнения регрессии; использовать встроенную функцию ЛИНЕЙН; использовать встроенные функции НАКЛОН (вычисляет коэффициент a) и ОТРЕЗОК (вычисляет коэффициент b); использовать инструмент «Регрессия» из Пакета анализа.
Краткие теоретические сведения
Для оценки степени взаимосвязи величин X и Y, измеренных в количественных шкалах, используется линейный коэффициент корреляции (коэффициент Пирсона), предполагающий, что выборки X и Y распределены по нормальному закону. Линейный коэффициент корреляции можно рассчитать по формуле:
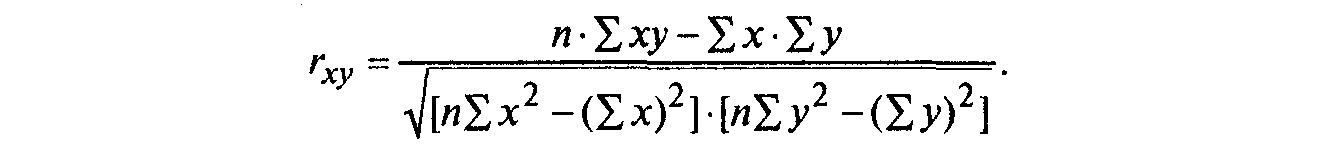 (1)
(1)
где х – наблюдаемые значения выборки X,
y – наблюдаемые значения выборки Y;
Коэффициент корреляции изменяется от –1 до 1. Знак коэффициента корреляции важен для интерпретации полученной связи (прямая или обратная связь).
Цель регрессионного анализа – определить количественные связи между зависимыми случайными величинами. Одна из этих величин полагается зависимой и называется откликом, другие – независимые, называются факторами. Для установления степени зависимости между откликом и факторами используется коэффициент корреляции.
Если коэффициент корреляции по абсолютной величине близок к единице, то для построения зависимости используется линейная модель. Для других случаев используются более сложные нелинейные модели (например, полиномиальные и экспоненциальные). В данной работе будем рассматривать линейную модель.
В случае парной регрессии уравнение линейной регрессии имеет вид Y = a+bX, где
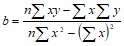
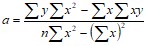 (2)
(2)
В среде MS Excel для нахождения модели регрессии (т. е. коэффициентов a и b) можно использовать несколько способов:
- использовать встроенную функцию ЛИНЕЙН; графический способ – построение линии тренда на диаграмме с показом уравнения регрессии; инструмент Регрессия из Пакета анализа; использовать встроенные функции НАКЛОН (вычисляет коэффициент a) и ОТРЕЗОК (вычисляет коэффициент b).
Пример выполнения задания
По 10 Интернет-магазинам были определены затраты на рекламную раскрутку сайтов и количество покупателей, воспользовавшихся после ее проведения услугами каждого магазина (рис. 1). Выполнить пункты задания 1 – 4 задания 2.
Ход выполнения задания
Создадим таблицу согласно рис. 1.
Рис. 1
Рассчитаем коэффициент корреляции, используя формулу (1), функцию КОРРЕЛ из категории Статистические, инструмент Корреляция из Пакета анализа Excel (рис. 2).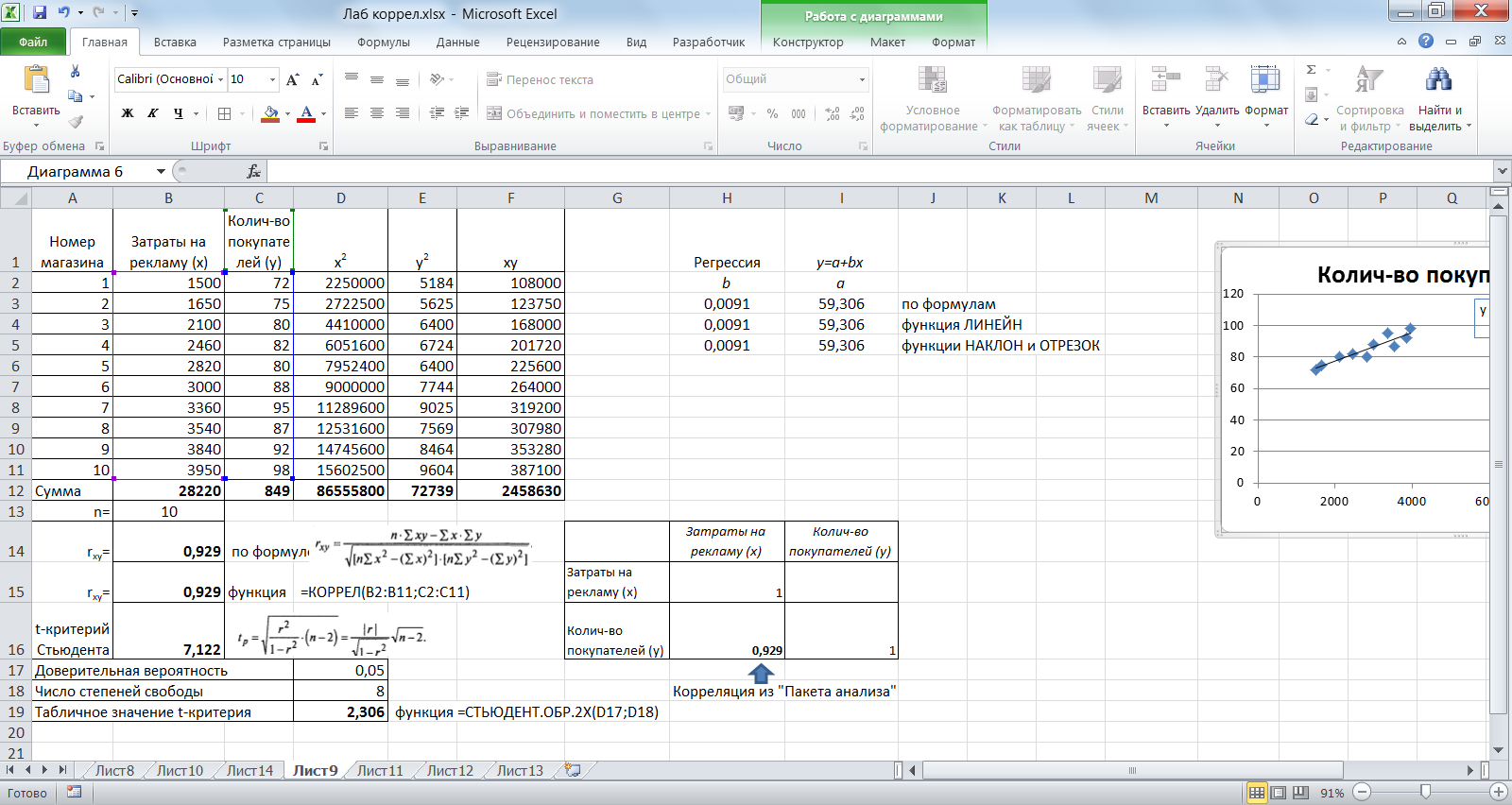
Рис. 2
Общий вид функцииКОРЕЛЛ:
КОРРЕЛ (<массив 1>;<массив 2>), где
<массив 1> – ссылка на диапазон ячеек первой выборки (X);
<массив 2> – ссылка на диапазон ячеек второй выборки (Y).
Вычислим значение t-критерия Стьюдента. Определим табличное значение t-критерия Стьюдента, используя стандартную функцию СТЬЮДЕНТ. ОБР.2Х.Поскольку вычисленное значение оказалось больше критического, с вероятностью 0,95 можно говорить о тесной связи между исследуемыми признаками.
Так как значение коэффициента корреляции близко к 1, можно использовать линейную модель парной регрессии Y = a+bX.
Определим значения коэффициентов a и b разными способами (рис. 3).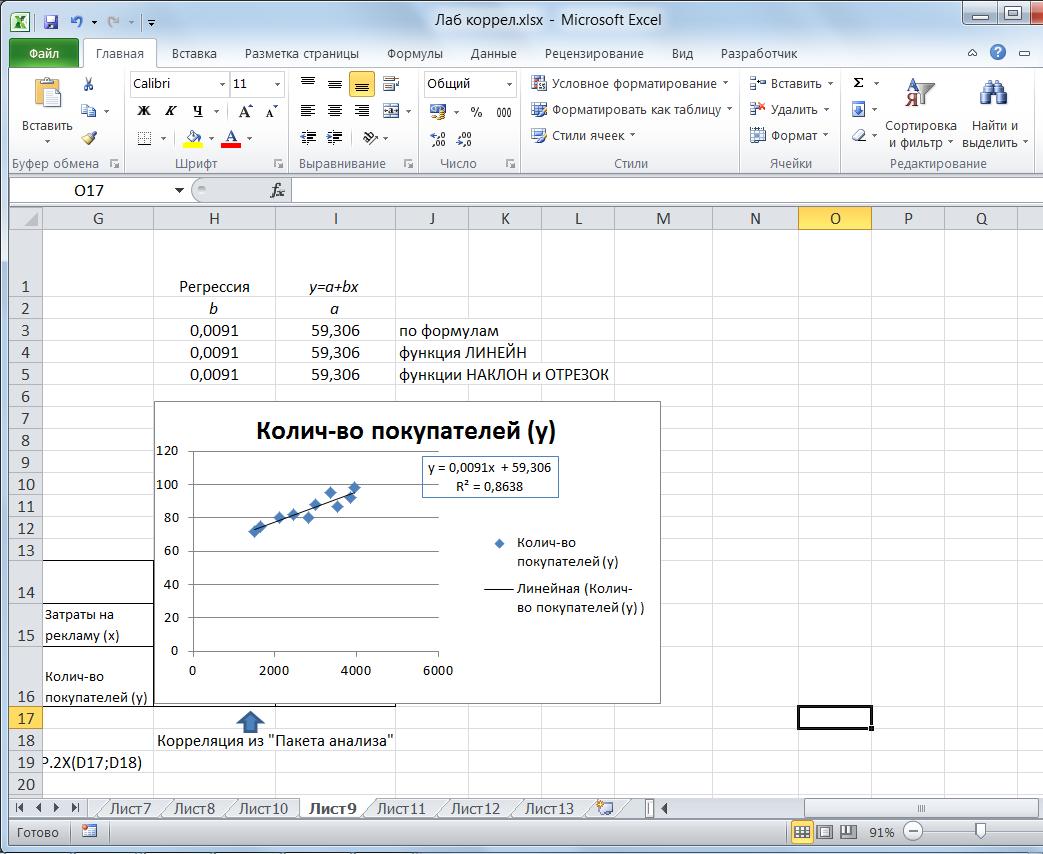
Рис. 3
5.1. В ячейках H3 и I3 выполнен расчет коэффициентов по формулам.
5.2. В ячейках H4 и I4 выполнен расчет коэффициентов с помощью функции ЛИНЕЙН. Для ввода формул нужно выделить обе ячейки, выбрать функцию ЛИНЕЙН из категории Статистические, указать аргументы функции (столбцы значений X и Y), закрыть окно ввода аргументов нажатием клавиш SHIFT+CTRL+ENTER. Таким образом формула вводится как формула массива.
5.3. В ячейках H5 и I5 выполнен расчет коэффициентов с помощью функций ОТРЕЗОК и НАКЛОН. Изучите синтаксис функций с помощью справочной системы.
5.4. Для получения уравнения регрессии графическим методом построим корреляционное поле переменных X (затраты на продвижение) и Y (количество покупателей).
- Выделим диапазон ячеек В2:С11, запустим мастер диаграмм и выберем тип диаграммы – Точечная. Добавим линию тренда на точечный график. Для этого необходимо открыть контекстное меню щелчком правой кнопки мыши по любому из маркеров точечной диаграммы и выбрать пункт «Добавить линию тренда». Линия тренда – графическое представление направления изменения ряда данных. Выбираем тип тренда «Линейный», который используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением: Y = a+ bX, где a – угол наклона (в радианах) и b – координата пересечения оси Y. На вкладке Параметры устанавливаем флажки «Показать уравнение на диаграмме» и «Поместить на диаграмму величину достоверности аппроксимации R2». Щелкаем по кнопке ОК.
R2 – это число от 0 до 1, которое отражает близость линии тренда к фактическим данным. Линия тренда наиболее соответствует действительности, когда значение близко к 1.
5.5. Используем инструмент Регрессия из Пакета анализа. Диалоговое окно с заданием параметров применения инструмента показано на рис. 4.
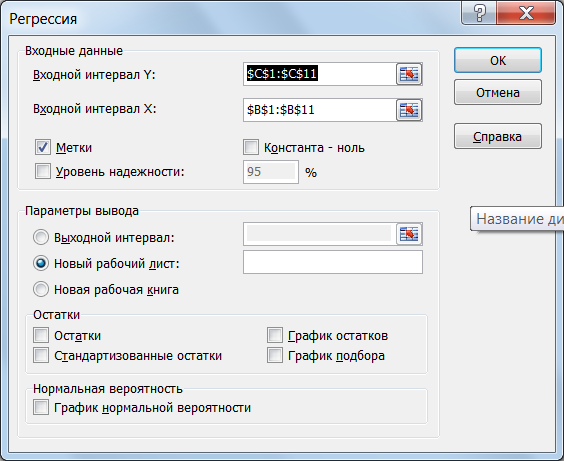
Рис. 4
Результаты выводятся в виде таблицы (рис. 5). Коэффициенты уравнения регрессии выделены на рисунке жирным шрифтом.
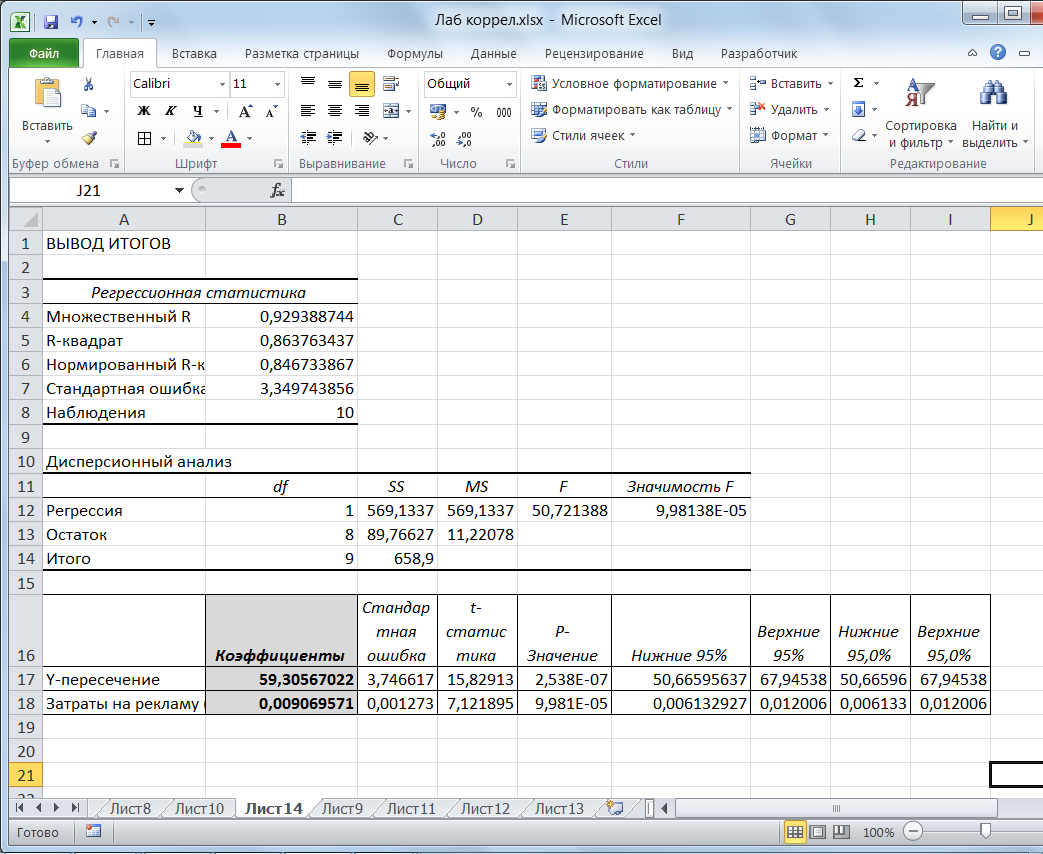
Рис. 5
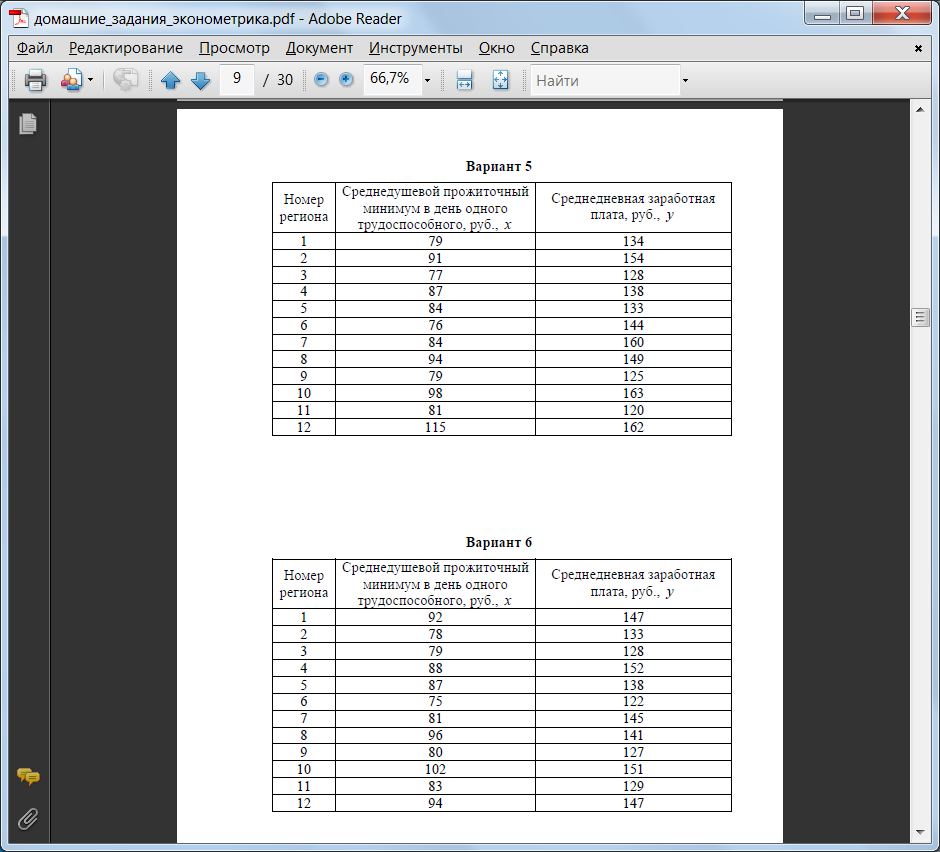
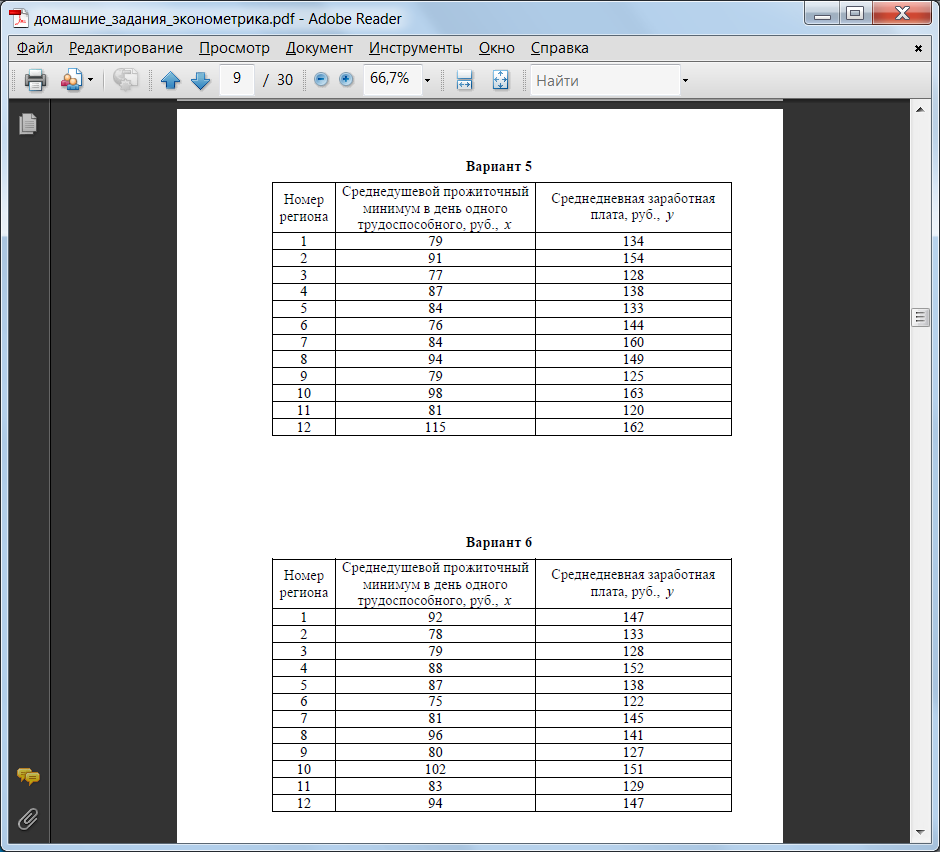
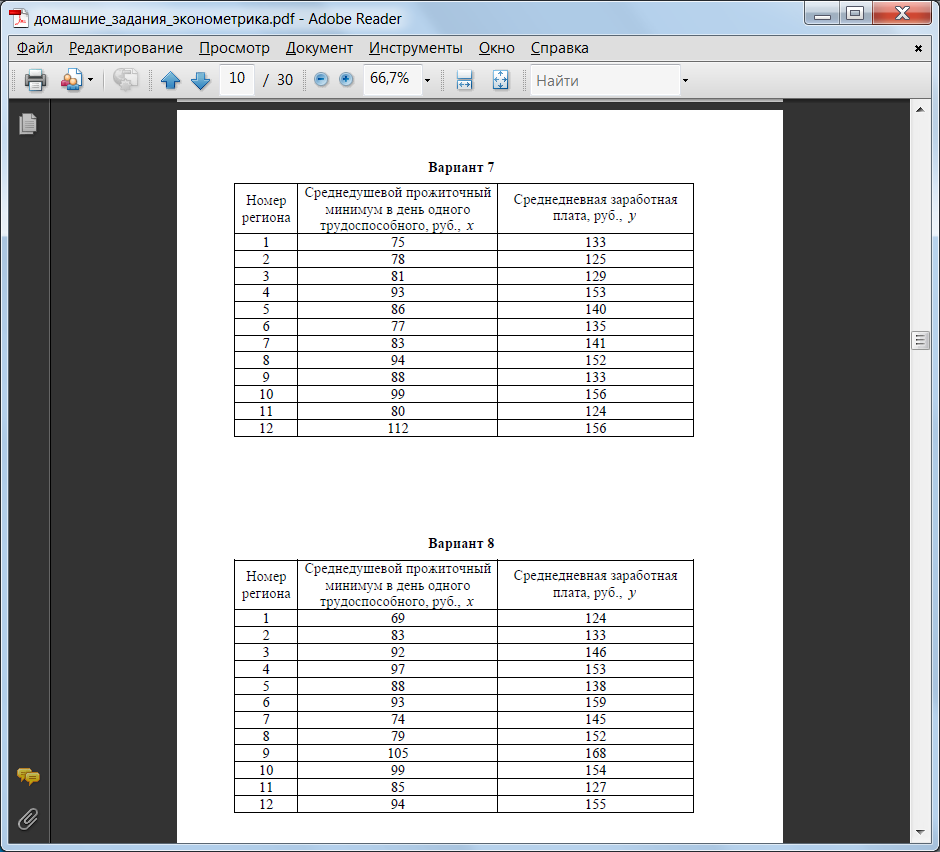
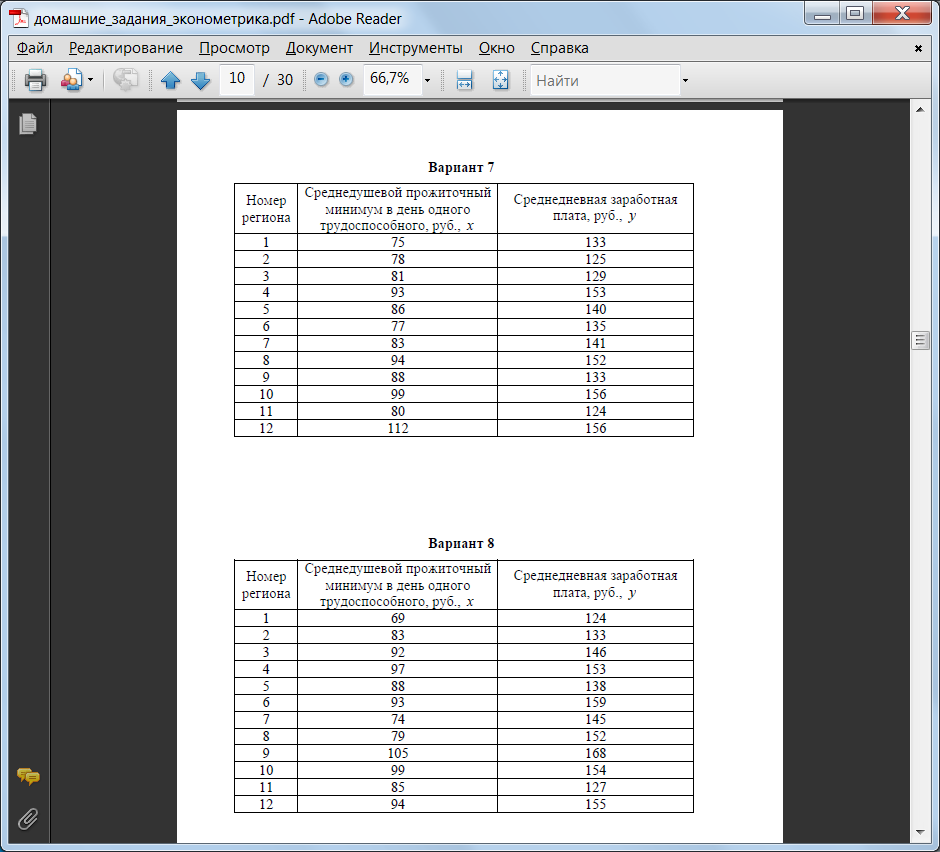
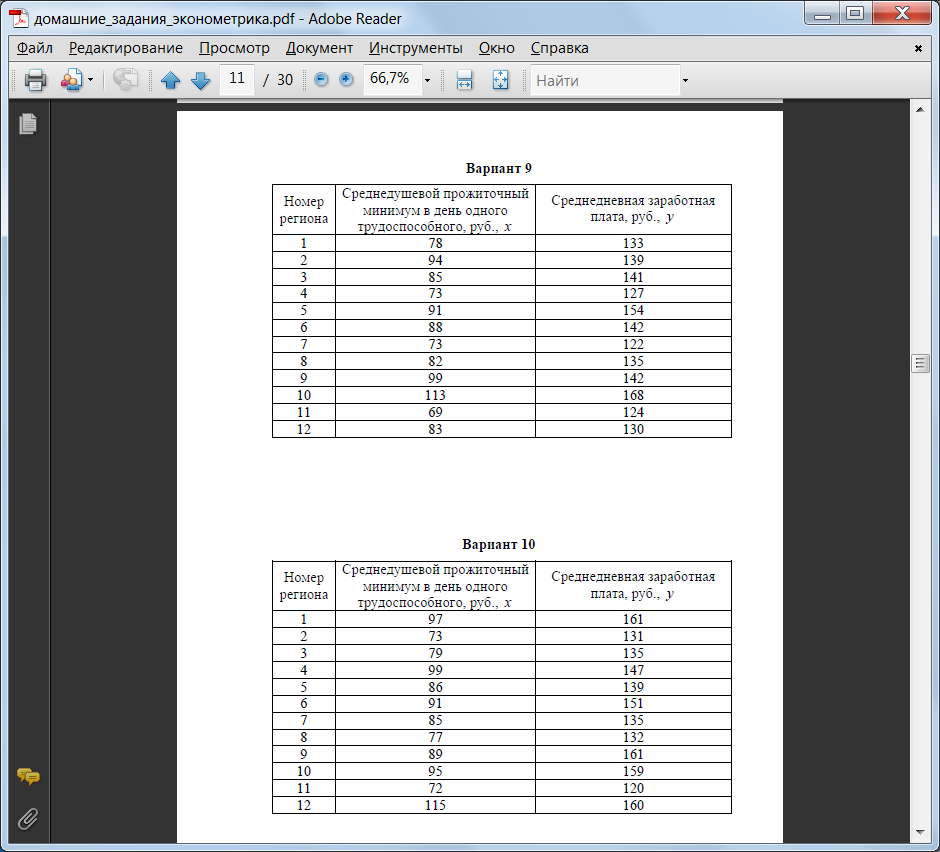
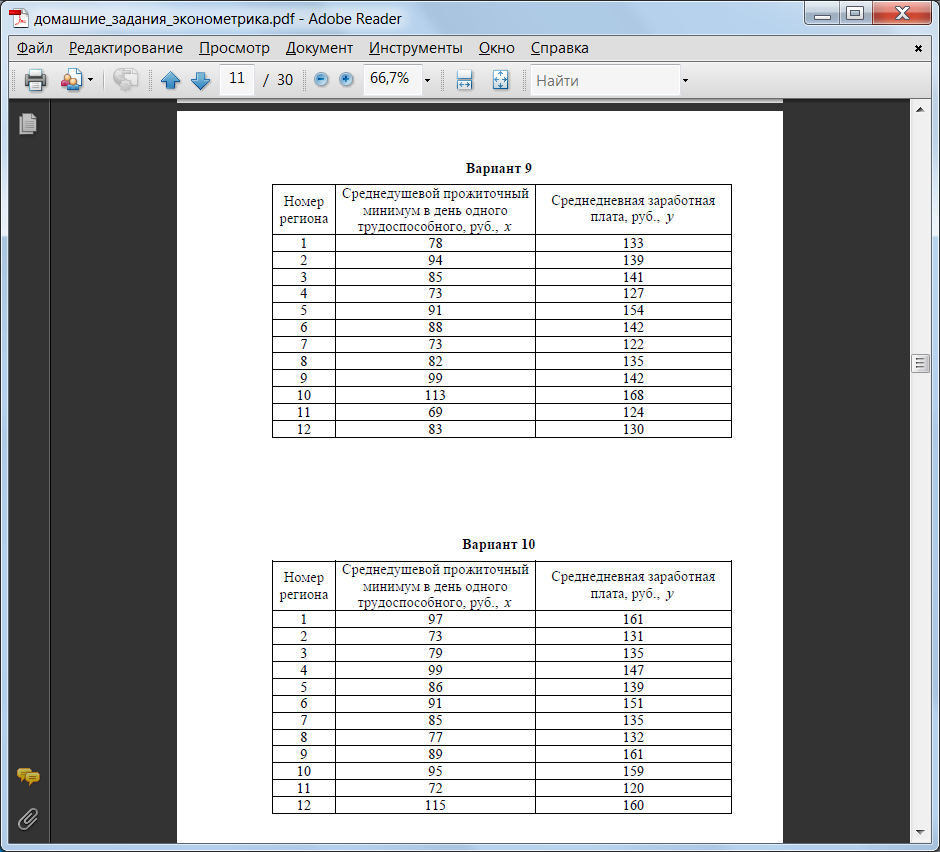
Варианты заданий