Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Практическая работа к занятию 1
Задание 1. Пример 1. имеются данные о количественном составе 60 семей.
2 | 4 | 5 | 6 | 5 | 2 | 3 | 4 | 1 | 4 | 3 | 3 |
4 | 3 | 3 | 4 | 4 | 4 | 4 | 5 | 5 | 3 | 4 | 1 |
3 | 4 | 3 | 5 | 4 | 3 | 5 | 3 | 3 | 2 | 3 | 4 |
6 | 5 | 4 | 4 | 4 | 2 | 3 | 4 | 4 | 6 | 5 | 1 |
5 | 2 | 6 | 2 | 3 | 3 | 4 | 5 | 4 | 4 | 6 | 4 |
Построить вариационный ряд и полигон распределения
Решение.
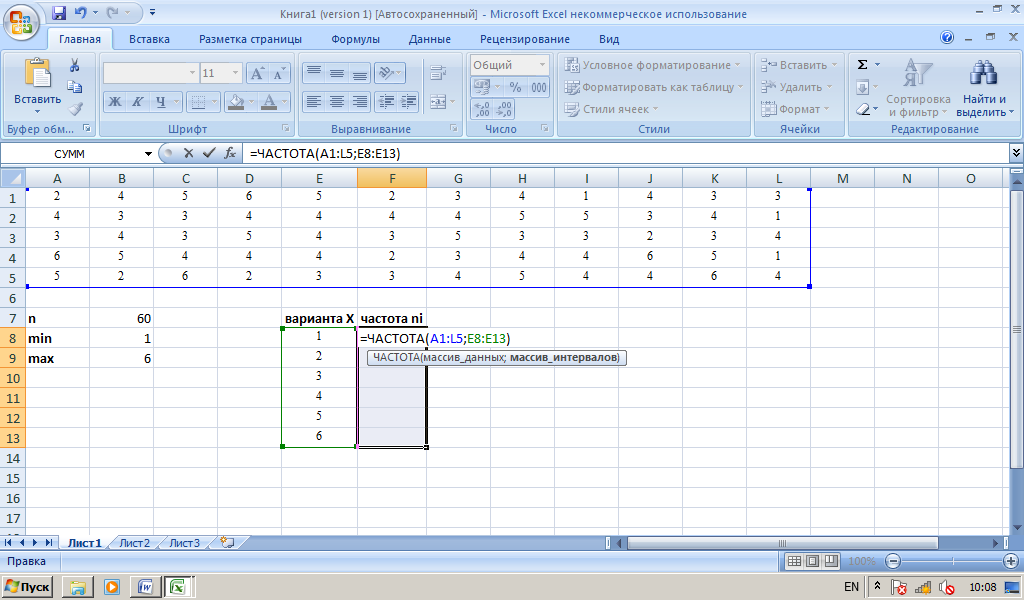
Откроем таблицы Excel. Введем массив данных в диапазон А1:L5..
Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5).
Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17. Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17)
Рис.1.2 Пример 1. Построение вариационного ряда
Для контроля вычислим сумму частот при помощи функции СУММ (значок функции Σ в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон: выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа - в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот

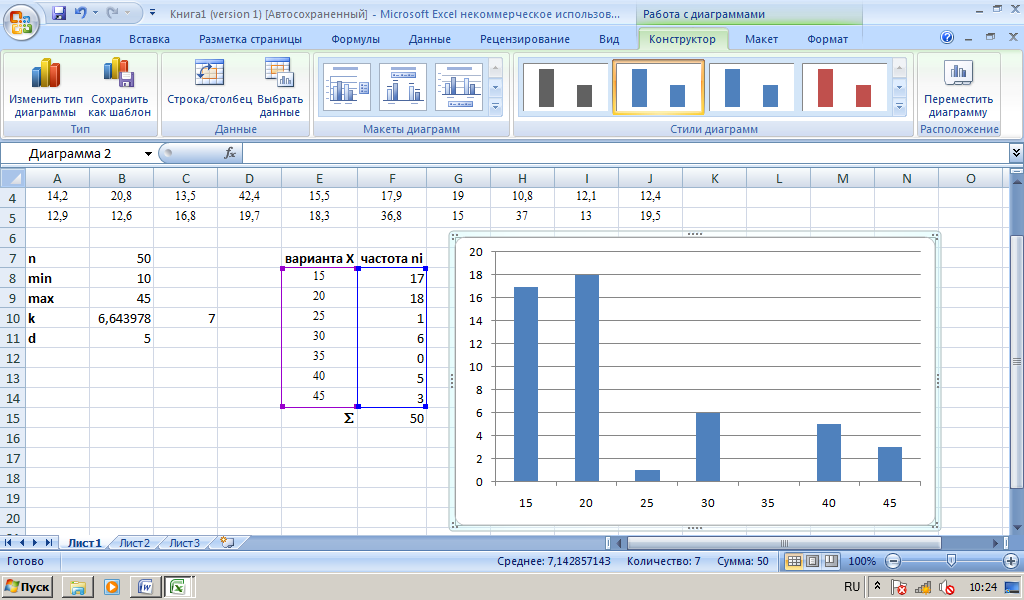
Задание2. Пример 2. Имеются данные о выбросах загрязняющих веществ из 50 источников:
10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Составить равноинтервальный ряд, построить гистограмму
Решение
Преходим на следующий лист.
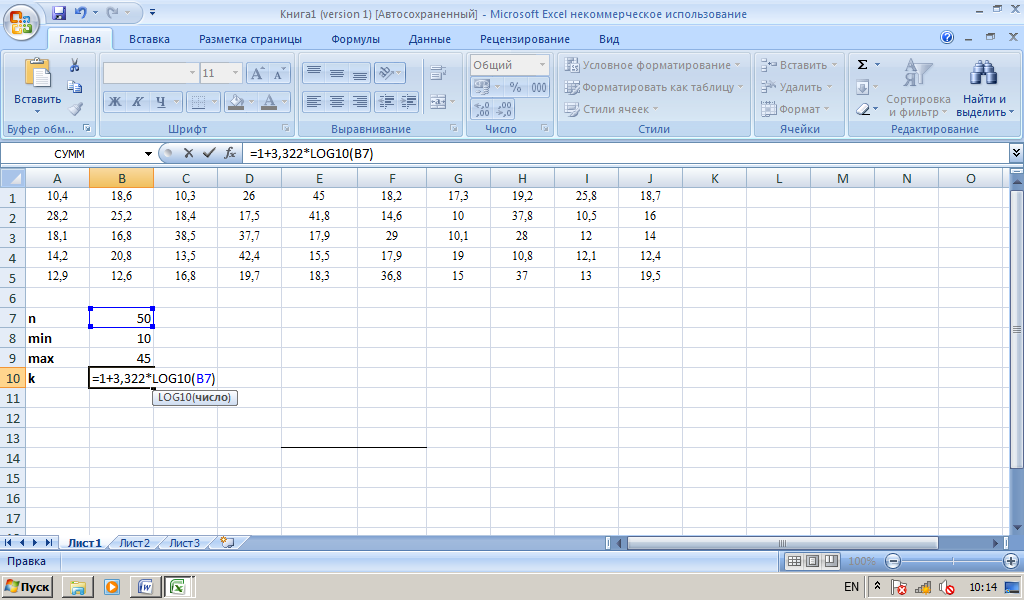
Внесем массив данных в лист Excel, он займет диапазон А1:J5.
Определим объем выборки n, минимальное и максимальное значения в выборке.
Поскольку теперь требуется не дискретный, а интервальный ряд, и число интервалов в задаче не задано, вычислим число интервалов k по формуле Стерджесса. Для этого в ячейку В10 введем формулу =1+3,322*LOG10(B7).
Рис.1.4. Пример 2. Построение равноинтервального ряда
Полученное значение не является целым, оно равно примерно 6,64. Поскольку при k=7 длина интервалов будет выражаться целым числом (в отличие от случая k=6) выберем k=7, введя это значение в ячейку С10. Длину интервала d вычислим в ячейке В11, введя формулу =(В9-В8)/С10.
Зададим массив интервалов, указывая для каждого из 7 интервалов верхнюю границу. Для этого в ячейке Е8 вычислим верхнюю границу первого интервала, введя формулу =B8+B11; в ячейке Е9 верхнюю границу второго интервала, введя формулу =E8+B11. Для вычисления оставшихся значений верхних границ интервалов зафиксируем номер ячейки В11 в введенной формуле при помощи знака $, так что формула в ячейке Е9 примет вид =E8+B$11, и скопируем содержимое ячейки Е9 в ячейки Е10-Е14. Последнее полученное значение равно вычисленному ранее в ячейке В9 максимальному значению в выборке. 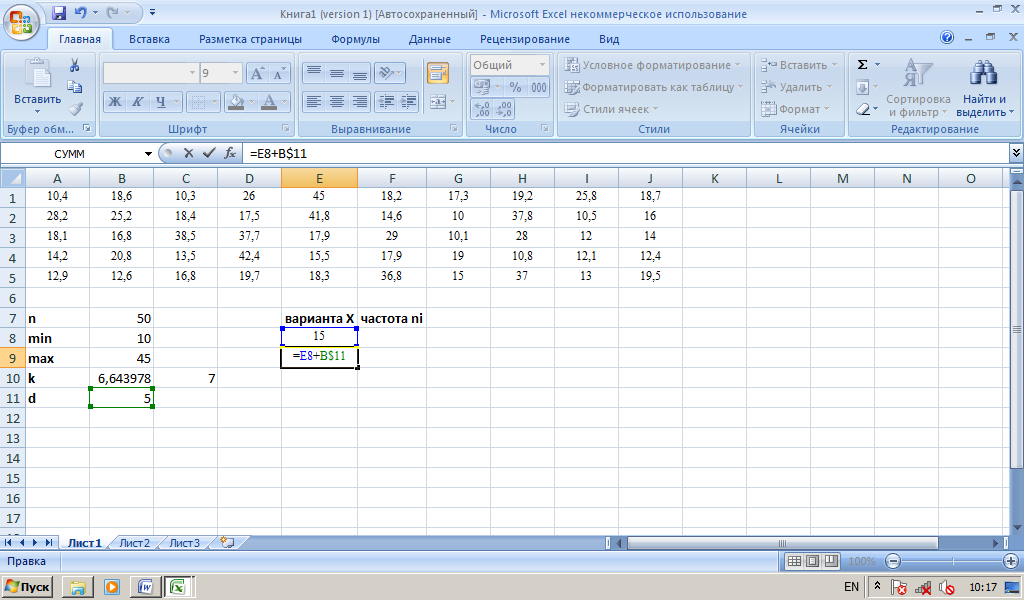
Рис.1.5. Пример 2. Построение равноинтервального ряда
Теперь заполним массив «карманов» при помощи функции ЧАСТОТА, как это было сделано в примере 1.
Рис.1.6. Пример 2. Построение равноинтервального ряда

По полученному вариационном ряду построим гистограмму: выделим столбец частот и выберем на вкладке «Вставка» «Гистограмма». Получив гистограмму, изменим в ней подписи горизонтальной оси на значения в диапазоне интервалов.
Рис.1.8. Пример 2. Построение гистограммы
Числовые характеристики выборки
Средние величины
Средняя величина представляет собой обобщенную количественную характеристику признака в статистической совокупности в конкретных условиях места и времени, она имеет ту же размерность, что и признак у единиц совокупности. Средние величины исчисляются для характеристики уровня цен, заработной платы, численности населения, выбросов загрязняющих веществ и т. п. Средняя величина должна характеризовать качественно однородную совокупность и исчисляться по данным большого числа единиц совокупности, то есть отображать массовые явления.
Применяются две категории средних: степенные средние и структурные средние.
Степенные средние дают обобщающую характеристику совокупности и являются абстрактными величинами, полученными расчетным путем. Обозначаются средние обычно через ![]() . В дальнейшем это обозначение мы будем использовать для генеральной средней, а выборочную среднюю будем обозначать
. В дальнейшем это обозначение мы будем использовать для генеральной средней, а выборочную среднюю будем обозначать ![]() . Выбор средней осуществляется в зависимости от задачи и вида исходных данных. Наиболее часто используется средняя арифметическая, которая является точечной оценкой математического ожидания распределения изучаемого признака как случайной величины.
. Выбор средней осуществляется в зависимости от задачи и вида исходных данных. Наиболее часто используется средняя арифметическая, которая является точечной оценкой математического ожидания распределения изучаемого признака как случайной величины.
Средние величины могут быть вычислены как по выборке (простая средняя), так и по вариационному ряду (взвешенная средняя) в зависимости от вида исходной информации
Таблица 1.1. Виды средних величин
Формула средней | Наименование средней | |||
Арифметическая | Гармоническая | Геометрическая | Квадратическая | |
Простая (по выборке) |
|
|
|
|
в Excel | СРЗНАЧ(массив) | СРГАРМ(массив) | СРГЕОМ(массив) | КОРЕНЬ((СУММКВ(массив)/n) |
Взвешенная (по ВР) |
|
|
|
|
в Excel | Вычисляются с применением функции СУММПРОИЗВ(массив1;массив2) |
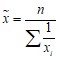
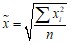
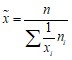
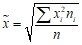
Для вычисления средней в интервальном ряду нужно перейти к дискретному ряду, заменив интервал его средним значением.
Степенные средние не отражают всех особенностей совокупности, они могут быть различными для одинаковых совокупностей или иметь одинаковое значение для совокупности с различным строением.
Структурные средние используются для более полной характеристики совокупности:
Мода – это варианта с наибольшей частотой (Мо);
Медиана – это варианта, делящая совокупность на две равные части (Ме).
Для нахождения моды и медианы по выборке в Excel используются соответственно функции МОДА(массив данных) и МЕДИАНА (массив данных).
В дискретном ВР модой является значение, соответствующее наибольшей частоте, медианой - то значение варианты, для которого накопленная частота впервые превышает половину объема выборки.
Для интервального ряда моду вычисляют по формуле:
![]() ,
,
где xMo – нижняя граница модального интервала, fMo – частота модального интервала, fMo-1 – частота интервала, предшествующего модальному, fMo+1 – частота интервала, следующего за модальным.
Медиана для интервального вариационного ряда вычисляется по формуле:
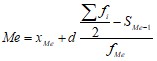 ,
,
где xMе – нижняя граница медианного интервала (в котором накопленная частота превышает половину объема выборки), d – величина интервала, fMе – частота медианного интервала, SMe-1 – накопленная частота интервала, предшествующего медианному.
Показатели вариации
Чтобы дать представление о величине варьирующего признака, недостаточно вычислить средний показатель. Необходим показатель, характеризующий вариацию признака.
Вариация – это изменение значения признака у отдельных единиц совокупности. Вариация обусловлена действием различных факторов на развитие отдельных единиц совокупности. Чем более разнообразно условие, тем больше его вариация.
Наиболее простой характеристикой вариации признака является размах вариации:
R=xmax – xmin,
где xmax – наибольшее, xmin – наименьшее значения в выборке.
В Excel размах вычисляется при помощи формулы:
МАКС(массив данных)-МИН(массив данных)
Недостаток размаха вариации в том, что он не отражает отклонений всех значений признака.
Для измерения отклонения каждой варианты от средней величины в ряду распределения или в группировке применяется среднее линейное отклонение:
![]() (простое);
(простое); 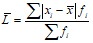 (взвешенное).
(взвешенное).
В Excel для вычисления по выборке используют функцию
СРОТКЛ(массив данных).
Среднее линейное отклонение показывает, на сколько в среднем каждое значение признака отклоняется от средней величины. Эта величина измеряется в тех же единицах, в которых даны статистические показатели. Среднее линейное отклонение дает обобщенную характеристику степени колеблемости признаков совокупности.
Наибольшее применение в практике статистических работ находит показатель – дисперсия признака или квадрат среднего квадратического отклонения.
![]() (простая);
(простая);
В Excel дисперсия выборки вычисляется при помощи функции
ДИСПР(массив данных)
Корень квадратный из дисперсии представляет среднее квадратическое отклонение или стандартное отклонение ![]() .
.
Для вычисления в Excel существует функция
СТАНДОТКЛОН(массив данных)
Среднее квадратическое отклонение дает обобщенную характеристику признака совокупности и показывает во сколько раз в среднем колеблется величина признака совокупности. Среднее квадратическое отклонение является мерой надежности средней величины: чем оно меньше, тем точнее средняя арифметическая.
Сопоставление линейных или среднеквадратических отклонений по признакам совокупности дает возможность определить статистическую однородность совокупности: чем меньше размер, тем совокупность более однородна.
Для сравнения вариации в разных совокупностях рассчитываются относительные показатели вариации:
Коэффициент вариации: ![]() . Коэффициент вариации позволяет судить об однородности совокупности:
. Коэффициент вариации позволяет судить об однородности совокупности:
– 17% – абсолютно однородная;
– 17–33% – достаточно однородная;
– 35–40% – недостаточно однородная;
– 40–60% – это говорит о большой колеблемости совокупности.
Коэффициент осцилляции: ![]() . Отражает относительную колеблемость крайних значений признака вокруг средней.
. Отражает относительную колеблемость крайних значений признака вокруг средней.
Линейный коэффициент вариации: ![]() . Характеризует долю усредненного значения абсолютного отклонения от средней величины.
. Характеризует долю усредненного значения абсолютного отклонения от средней величины.
Кроме того, для сравнения гистограммы или полигона вариационного ряда с нормальным распределением, вычисляют коэффициент асимметрии и эксцесс:
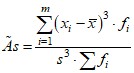 ,
, 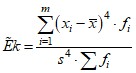 .
.
В Excel эти характеристики по выборке вычисляются соответственно функциями
СКОС(массив данных) и ЭКСЦЕСС(массив данных).
Лабораторная работа № 3. Проверка статистических гипотез.(часть1)
Практическое задание
Проверка гипотез о законе распределения
Для оценки соответствия имеющихся экспериментальных данных нормальному закону распределения целесообразно совместное использование графических и статистических методов.
Графический метод позволяет выдвигать гипотезу о виде распределения, давать визуальную ориентировочную оценку расхождения или совпадений распределений.
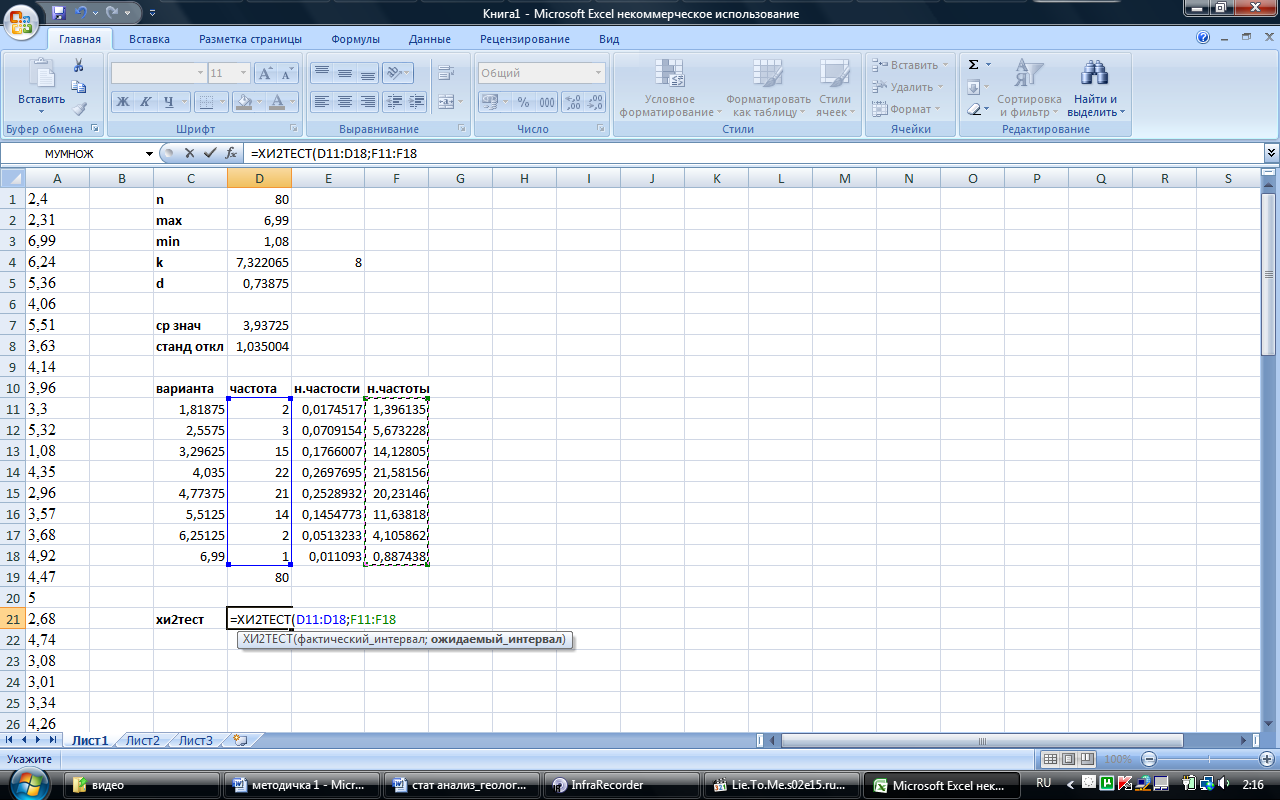
Наиболее убедительные результаты дает использование критериев согласия. Здесь нулевая гипотеза Н0 представляет собой утверждение о том, что распределение генеральной совокупности, из которой получена выборка, не отличается от нормального. Среди критериев согласия большое распространение получил непараметрический критерий ч2 (хи-квадрат). Он основан на сравнении эмпирических частот интервалов группировки с теоретическими (ожидаемыми) частотами, рассчитанными по формулам нормального распределения. Для его применения желательно иметь не менее 40 выборочных данных, сгруппированных не менее чем в 7 интервалов, в каждом из которых находится хотя бы 5 наблюдений.
В Excel критерий хи-квадрат реализован в функции ХИ2ТЕСТ(фактический_интервал;ожидаемый_интервал), аргументами которой являются диапазон экспериментальных частот и диапазон теоретических частот для соответствующих интервалов. Функция ХИ2ТЕСТ вычисляет вероятность совпадения наблюдаемых (фактических) значений и теоретических (гипотетических) значений. Если вычисленная вероятность ниже уровня значимости (0,05), то нулевая гипотеза отвергается и утверждается, что наблюдаемые значения не соответствуют нормальному закону распределения. Если вычисленная вероятность близка к 1, то можно говорить о высокой степени соответствия экспериментальных данных нормальному закону распределения.
Теоретические частоты вычисляются при помощи функции НОРМРАСП(х;среднее;станд_откл;интегральная). Здесь среднее – математическое ожидание теоретического распределения, в данном случае совпадает с выборочным средним; станд_откл – среднее квадратическое отклонение теоретического распределения, в данном случае берется оценка по выборочным данным; интегральная – логическое значение, следует поставить 1 чтобы получить интегральную функцию распределения. Для получения вероятности попадания гипотетического значения из нормально распределенной совокупности в интервал [х1;х2], следует вычислить разность между значением функции при х=х1 и х=х2. Для получения теоретических частот надо умножить вероятности на объем выборки.
Пример 3.1. Проверить соответствие выборочных данных эмпирического распределения содержания Na2O в 1 и 2 гранитных интрузиях (см. табл.) нормальному закону распределения, используя пакет Excel.
Табл.3.1. Содержание оксидов в пробах 1 гранитной интрузии
№ п/п | Na2O | K2O | № п/п | Na2O | K2O | № п/п | Na2O | K2O | № п/п | Na2O | K2O | № п/п | Na2O | K2O |
1 | 2,40 | 3,60 | 17 | 3,68 | 3,20 | 33 | 5,30 | 3,60 | 49 | 4,01 | 3,58 | 65 | 5,55 | 4,58 |
2 | 2,31 | 3,75 | 18 | 4,92 | 0,95 | 34 | 3,00 | 3,24 | 50 | 1,49 | 2,57 | 66 | 4,59 | 4,09 |
3 | 6,99 | 3,30 | 19 | 4,47 | 1,26 | 35 | 3,94 | 4,22 | 51 | 3,55 | 2,86 | 67 | 4,34 | 3,45 |
4 | 6,24 | 4,46 | 20 | 5,00 | 3,86 | 36 | 3,46 | 2,54 | 52 | 3,67 | 2,27 | 68 | 3,22 | 2,54 |
5 | 5,36 | 2,84 | 21 | 2,68 | 2,79 | 37 | 3,23 | 4,29 | 53 | 3,40 | 4,05 | 69 | 2,82 | 3,96 |
6 | 4,06 | 1,42 | 22 | 4,74 | 4,42 | 38 | 3,32 | 3,54 | 54 | 4,38 | 5,04 | 70 | 4,90 | 2,51 |
7 | 5,51 | 3,52 | 23 | 3,08 | 2,88 | 39 | 4,41 | 1,34 | 55 | 4,39 | 3,12 | 71 | 5,08 | 3,22 |
8 | 3,63 | 2,10 | 24 | 3,01 | 2,75 | 40 | 2,79 | 3,66 | 56 | 4,53 | 1,38 | 72 | 3,80 | 2,68 |
9 | 4,14 | 3,41 | 25 | 3,34 | 1,37 | 41 | 4,32 | 3,36 | 57 | 4,34 | 4,38 | 73 | 4,62 | 4,10 |
10 | 3,96 | 3,30 | 26 | 4,26 | 2,88 | 42 | 2,91 | 3,01 | 58 | 2,65 | 2,61 | 74 | 4,67 | 4,21 |
11 | 3,30 | 1,44 | 27 | 3,16 | 1,86 | 43 | 4,90 | 3,11 | 59 | 5,12 | 3,65 | 75 | 3,45 | 2,85 |
12 | 5,32 | 4,38 | 28 | 3,35 | 1,67 | 44 | 5,03 | 4,30 | 60 | 4,70 | 2,71 | 76 | 4,91 | 1,30 |
13 | 1,08 | 1,15 | 29 | 4,21 | 1,60 | 45 | 2,70 | 2,43 | 61 | 2,83 | 3,19 | 77 | 3,22 | 1,96 |
14 | 4,35 | 4,97 | 30 | 4,14 | 2,87 | 46 | 3,34 | 1,82 | 62 | 4,26 | 3,78 | 78 | 4,31 | 4,62 |
15 | 2,96 | 2,07 | 31 | 2,04 | 2,90 | 47 | 5,31 | 2,48 | 63 | 3,48 | 3,19 | 79 | 5,16 | 4,05 |
16 | 3,57 | 3,71 | 32 | 3,69 | 3,42 | 48 | 3,57 | 3,84 | 64 | 3,72 | 2,74 | 80 | 3,34 | 3,09 |
Табл.3.2. Содержание оксидов в пробах 2 гранитной интрузии
№ п/п | Na2O | K2O | № п/п | Na2O | K2O | № п/п | Na2O | K2O | № п/п | Na2O | K2O | № п/п | Na2O | K2O |
1 | 4,34 | 3,73 | 17 | 2,11 | 1,12 | 33 | 3,16 | 2,69 | 49 | 4,25 | 3,75 | 65 | 6,20 | 2,66 |
2 | 4,82 | 4,16 | 18 | 4,14 | 2,75 | 34 | 4,80 | 3,60 | 50 | 3,62 | 2,78 | 66 | 5,30 | 3,51 |
3 | 5,13 | 2,50 | 19 | 4,63 | 2,68 | 35 | 5,22 | 2,78 | 51 | 4,35 | 1,47 | 67 | 3,09 | 3,00 |
4 | 3,34 | 4,01 | 20 | 4,69 | 3,86 | 36 | 4,69 | 3,74 | 52 | 3,71 | 1,02 | 68 | 2,41 | 1,72 |
5 | 4,64 | 5,88 | 21 | 4,29 | 2,74 | 37 | 3,00 | 0,98 | 53 | 3,12 | 3,78 | 69 | 4,28 | 1,31 |
6 | 2,56 | 3,20 | 22 | 3,95 | 0,17 | 38 | 2,08 | 2,36 | 54 | 3,94 | 3,31 | 70 | 3,27 | 2,01 |
7 | 4,00 | 1,73 | 23 | 3,04 | 3,95 | 39 | 5,00 | 2,30 | 55 | 4,76 | 3,48 | 71 | 3,55 | 1,64 |
8 | 5,42 | 4,26 | 24 | 3,92 | 2,03 | 40 | 2,64 | 3,48 | 56 | 5,44 | 0,43 | 72 | 4,34 | 2,18 |
9 | 3,46 | 2,72 | 25 | 4,02 | 1,31 | 41 | 5,00 | 1,81 | 57 | 4,84 | 2,61 | 73 | 3,34 | 2,85 |
10 | 5,24 | 4,71 | 26 | 3,90 | 2,44 | 42 | 2,98 | 4,30 | 58 | 4,63 | 0,17 | 74 | 3,59 | 2,17 |
11 | 3,33 | 3,58 | 27 | 5,30 | 2,37 | 43 | 4,09 | 1,81 | 59 | 3,56 | 3,36 | 75 | 4,28 | 2,19 |
12 | 4,44 | 3,24 | 28 | 3,86 | 1,89 | 44 | 3,24 | 2,34 | 60 | 2,78 | 1,26 | 76 | 4,90 | 1,66 |
13 | 4,83 | 3,08 | 29 | 4,04 | 1,27 | 45 | 4,12 | 4,19 | 61 | 2,99 | 2,91 | 77 | 4,80 | 3,50 |
14 | 5,30 | 2,15 | 30 | 3,16 | 3,52 | 46 | 4,48 | 3,41 | 62 | 4,88 | 3,08 | 78 | 4,84 | 2,68 |
15 | 2,90 | 2,50 | 31 | 4,86 | 2,43 | 47 | 2,51 | 3,16 | 63 | 5,02 | 2,62 | 79 | 2,84 | 2,57 |
16 | 3,54 | 3,44 | 32 | 4,08 | 3,47 | 48 | 4,06 | 2,37 | 64 | 3,16 | 2,10 | 80 | 2,78 | 4,05 |
.
Решение
Откроем таблицы Excel и перенесем данные по содержанию Na2O из первой таблицы в столбец А. Данные займут диапазон А1:А80 Построим равноинтервальный ряд (как в примере 1.2). Значение, вычисленное по формуле Стерджесса, равно 7,322; выберем число интервалов k=8 (выбор обусловлен более удобным значением длины интервала). Кроме того, вычислим выборочное среднее значение при помощи функции СРЗНАЧ и оценку генерального среднего квадратического (стандартного) отклонения, использовав сочетание функций КОРЕНЬ(ДИСП).
Теперь вычислим теоретические частости попадания нормально распределенной величины в карманы построенного интервального ряда. Для первого интервала вычислим разность значений функции нормального распределения в верхней границе интервала, указанной в ячейке С11, и в нижней, равной минимальному значению в выборке и указанному в ячейке D3. Таким образом, в ячейке Е11 надо ввести формулу
=НОРМРАСП(C11;D7;D8;1)-НОРМРАСП(D3;D7;D8;1)
Аналогично, для следующего интервала в ячейке Е12 введем формулу
=НОРМРАСП(C12;D7;D8;1)-НОРМРАСП(С11;D7;D8;1).
Чтобы для следующих интервалов не набирать формулу заново, зафиксируем в последней набранной формуле ячейки D7 и D8 при помощи значка $ и скопируем ее содержимое в ячейки Е13-Е18, «потянув» за правый нижний уголок ячейки Е12:
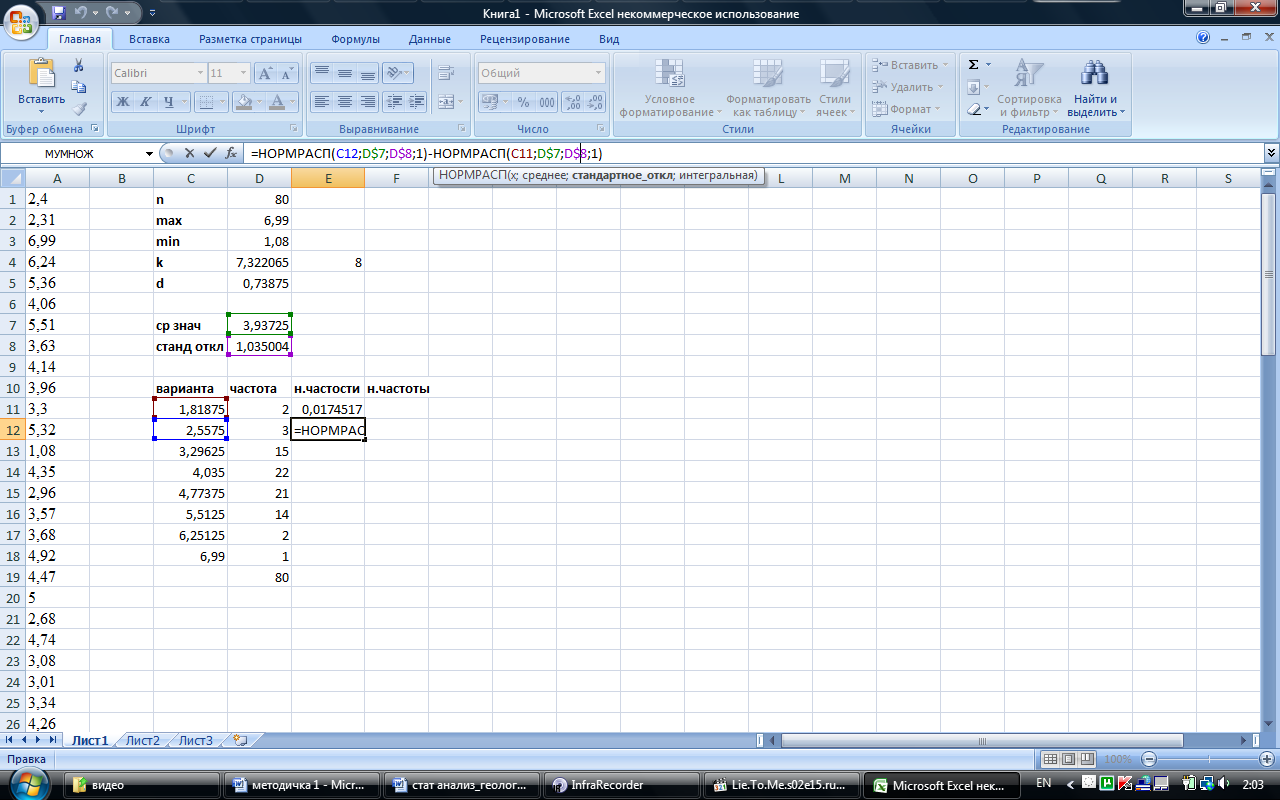
Чтобы получить теоретические частоты, умножим частости на объем выборки. В ячейке F11 введем =E11*80 и «растянем» результат на диапазон F11:F18. Заметим что, поскольку теоретически нормально распределенный признак может принимать любые действительные значения, сумма теоретических частот для данных интервалов будет меньше объема выборки.
И наконец, вычислим значение функции ХИ2ТЕСТ применительно к массивам частот в ячейке D21:
Полученное значение 0,86 означает, что оснований отвергнуть гипотезу о нормальности распределения нет, поскольку значение больше уровня значимости 0,05. Более того, степень соответствия нормальному закону довольно велика.