
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ВСЕРОССИЙСКИЙ КОНКУРС
ИССЛЕДОВАТЕЛЬСКИХ РАБОТ УЧАЩИХСЯ
Дерзание - Юниор
Пермский край, Пермь
Информатика и информационные технологии
Распознавание компьютером руко-печатного текста
Ельчанинова Анна,
НОУ "Гимназия им. М. И. Пинаевой",
8 класс.
,
НОУ "Гимназия им. М. И. Пинаевой",
учитель информатики.
Пермь, 2015
Оглавление
Ведение 3
Задачи: 3
Краткий обзор источников 3
Виды распознаваемых текстов 4
Тексты в памяти компьютера 4
Программы для работы с текстами 5
Этапы работы программы OCR 5
Распознавание конкретного символа 6
Проблемы программ распознавания текста 7
Практическая работа по распознаванию текста 8
Выводы 10
Список литературы 11
Приложение 1. 12
Ведение
Каждый год девятый и одиннадцатый классы пишут государственные экзамены. В каждом экзамене есть задания, на которые нужно дать краткий ответ в письменной форме. Для этого ученик должен записать нужную информацию в экзаменационном бланке печатными буквами, причем буквы должны соответствовать приведённым в начале теста образцам. Все знают, какие проблемы испытывают педагоги, пытаясь разобрать наш почерк при проверке тетрадей. Экзаменационный бланк проверяет компьютер. Как же он решает эту задачу? Мне стало интересно, как компьютер распознаёт текст и почему так важно писать символы по образцу.
Цель работы:
- Понять, как компьютер распознаёт руко-печатный текст и выяснить, почему так важно писать символы по образцу..
Задачи:
- изучить литературу по теме; узнать принцип работы программ по распознаванию текста; выполнить практическую работу по распознаванию текста; выявить проблемы при распознавании текста программой; сделать выводы.
Краткий обзор источников
В основе работы лежат следующие материалы:
- Книга Пети Ж.-П. "О чём размышляет роботы?", в которой рассматриваются общие вопросы, связанные с распознаванием образов электронно - вычислительными машинами. Статья "Оптическое распознавание символов (OCR)", написанная на основе материала книги и др. "Обработка и анализ изображений в задачах машинного зрения", в которой рассматриваются конкретные способы распознавания отдельных символов, связанные с распознаванием проблемы, а также основные принципы работы систем OCR.
Виды распознаваемых текстов
Все тексты можно разделить на три категории: печатные, рукописные и руко-печатные. Распознавание рукописного текста - самая сложная из этих трёх задач, так как количество возможных вариантов начертания любой буквы или цифры практически бесконечно. Чтобы облегчить компьютеру задачу распознавания, в экзаменационных бланках ответов используется руко-печатный текст, то есть текст, написанный от руки печатными символами. Кроме того, в бланке ответов приведены образцы начертания букв и цифр.
Текст как картинка

При сканировании бланка ответов получается не текст, а растровая картинка, состоящая из отдельных точек - пикселей.
Полученный электронный образ документа хранится в сформированном файле, где все точки рисунка описываются именно как точки на плоскости, каждая со своими координатами, цветом и другими атрибутами. В таком файле и текст, и цифры, и другие элементы изображения записаны одинаково - как графические изображения, состоящие из точек.
Тексты в памяти компьютера
Тексты в памяти компьютера хранятся в виде двоичных кодов. Каждому из 256 знаков компьютерного алфавита соответствует определенный двоичный код. Существует специальная таблица кодировки, которая устанавливает соответствие между двоичными кодами и символами.
Значит, для того, чтоб перевести растровое изображение в текст, нужно на картинке выделить участок, соответствующих одному знаку, распознать этот знак, и записать его в текстовый файл в виде двоичного кода знака.
Для перевода растрового изображения в символы текста используются специальные программы. Первые такие программы были разработаны в первой половине XX века и использовались для чтения кредитных карт и для работы с чеками.
Программы для работы с текстами
Программы преобразуют графические образы цифр и букв в нужный формат хранения. Они, последовательно обрабатывая электронный графический образ документа, состоящий из точек, распознают, определяют, что это за конкретная очередная буква или цифра документа, что за слово. Процесс называется оптическим распознаванием символов, или по-английски OCR — Optical Character Recognition, а сами программы — OCR-программами.
Этапы работы программы OCR [3]
Осуществляется выделение текстовых областей, строк и разбиение связных текстовых строк на отдельные знакоместа, каждое из которых соответствует одному текстовому символу. Символы, представленные в виде двумерных матриц пикселов, подвергаются сглаживанию, фильтрации с целью устранения шумов, нормализации размера, а также другим преобразованиям с целью выделения характерных признаков, используемых впоследствии для их распознавания. Алгоритм распознавания делает предположение, какому из символов, хранящихся в памяти программы, соответствует рассматриваемая область. Программа OCR хранит данные о символах в виде эталонов, с которыми сравнивается выделенный объект. Наиболее подходящий эталон и будет соответствовать искомому символу.В современных алгоритмах процесс распознавания основан на выдвижении и проверке гипотез. На основе общих признаков программа выдвигает некоторое количество гипотез о том, что может быть на изображении. Затем эти гипотезы целенаправленно проверяются. Если какой-то признак в изображении отсутствует, проверка этой гипотезы сразу прекращается, ограничивая перебор вариантов на ранних стадиях. Одновременно с выдвижением гипотез об отдельных символах программа выдвигает гипотезы и о целых словах.
Для окончательной проверки правильности гипотез о целых словах используется словарь.
Распознавание конкретного символа
Различные методы распознавания основаны на непосредственном сравнении изображений тестового и эталонного символов. При этом вычисляется степень сходства между образом и каждым из эталонов. Рассмотрим один из методов.
Метод зон [4] предполагает разделение площади рамки, объемлющий символ, на области и последующее использование плотностей точек в различных областях в качестве набора характерных признаков.


На правом рисунке показано эталонное изображение символа R, а на левом рисунке - реальное изображение символа R, полученное путем сканирования изображения документа. На обоих изображениях приводятся разбиение на зоны и подсчитывают пиксельные веса каждой зоны. Программа сравнивает степень совпадения плотности в каждой зоне распознаваемого символа с значениями плотности в соответствующей зоне для каждого из эталонных символов. Затем программа определяет знак, имеющий наименьшее отклонение от эталона по всем зонам и сохраняет его в виде двоичного кода.
Проблемы программ распознавания текста
Имеется ряд существенных проблем, связанных с распознаванием рукописных и печатных символов. Наиболее важные из них следующие:
- Разнообразие форм начертания символов. При этом различные символы могут обладать сходными очертаниями. Например, "6" и "б", "S" и "5", "Z" и "2", "G" и "6", "8" и "В". искажение изображений символов; вариации размеров и масштаба символов.
Затрудняет распознавание:
- Низкое качество документов, полученных при ксерокопировании, или по факсу. Наличие шумов: "слипание" соседних символов, пятна и ложные точки на фоне вблизи символов и т. д. Шрифт с декоративными элементами, с засечками, потому что буквы трудно отделить друг от друга. Надписи, сделанные на цветном фоне с плавно изменяющимися цветами и интенсивностью, предохраняющие документ от подделки.
Для улучшения условий распознавания выполняется предварительная обработка отсканированного образа.
Основные виды предварительной обработки, используемые в OCR-программах:
- предварительное преобразование серого или цветного изображения исходного документа в чёрно-белое; удаление пустых страниц многостраничного документа; разделение двойных страниц, если отсканирован сразу весь разворот книги; очистка изображения удалением случайного “мусора” — излишних точек на поле документа, особенно вблизи границ символов; цифровое увеличение изображения; автоматический поворот страниц, вошедших в сканер не той стороной; обрезка “черноты” по краям документа, размер которого оказался меньше поля сканера, и т. д.
Практическая работа по распознаванию текста
Для того, чтоб понять как работают программы по распознаванию текста, мы решили выполнить практическую работу по распознаванию. Для этого мы попросили нескольких учеников гимназии написать свое имя и фамилию руко-печатными буквами. Надписи выполнялись на белом листе бумаге и на бумаге в клетку черной гелиевой ручкой.
Для распознавания была использована программа Abby Fine Reader - система оптического распознавания символов, разработанная российской компанией ABBYY. Программа поддерживает распознавание текста на 190 языках и имеет встроенную проверку орфографии для 48 из них.
Использовалось 2 режима сканирования:
- с разрешением 300 dpi с разрешением 600 dpi.
Результаты сканирования и распознавания представлены в приложении 1.
Результаты сканирования показали:
Программа испытывает значительные трудности при распознавании руко-печатного текста в исполнении наших учеников. Качество распознавания текста с разрешением 600 dpi и разрешением 300 dpi существенно не отличаются. Попытки улучшить качество изображения в программе Adobe Photoshop - повышение контраста, удаление лишних точек - существенного влияния на качество изображений не оказали, т. к. тексты изначально были достаточно контрастные. Самые значительные проблемы программа испытывала с распознаванием почерка Ани Ельчаниновой и Насти Юговой. Распознавание было затруднено в следующих случаях:- разный наклон букв в пределах одной надписи; наклон всей надписи влево; разный размер букв в пределах одного слова; отступление в написании букв от нормы.
Выводы
Программы распознавания текста выполняют распознавание, сравнивая предложенное начертание символов с эталонным.
Для правильного распознавания необходимо, чтоб символы как можно точнее соответствовали образцу.
Программа с высокой степенью точности распознает текст, написанный с соблюдением требований написания символов.
Большую роль играет контрастность текста, поэтому так важно заполнять поле для ответов чёрной ручкой.
Все проблемы распознавания, возникшие в процессе работы, были связаны с особенностями почерка учеников, в не с работой программы.
Список литературы
Abby Fine Reader. Официальный сайт компании.[Электронный ресурс] – Режим доступа: http://www. abbyy. ru/finereader– Загл. с экрана. (11.10.2014). Пети Ж.-П. О чём размышляет роботы?: Пер. с франц.-М.: "Мир", 1987. Оптическое распознавание символов (OCR). [Электронный ресурс] //Wiki - техническое зрение. – Режим доступа: http://wiki. technicalvision. ru/index. php, – Загл. с экрана. (11.11.2014). ехнологии оптического распознавания текстов [Электронный ресурс]// Газета "Электронный офис".-10.1996. – Режим доступа: http://travin. msk. ru/arc/OCR. html– Загл. с экрана. (27.11.2014).Приложение 1.

Пример распознавания текста. Разрешение 300 dpi, белая бумага.
E/V>MMAuuobAv
ГО Q А. cTArC^%
И AbWHCicASf т4 ЛЈ КС^Иг^М
Артём ПоггоВ
Апкин Рус/\/1К
Б^ЛОНОГР^
Hp/l/tUM Jill it ИТ А
McKDB Иш
Пример распознавания текста. Разрешение 600 dpi, белая бумага.
ЈГлъчал\ииоъ/V /Xu^j
ю,
Самарин Егончик.
/1ле*ц^бд /КАйТАси?
ИлЬКМПсАЗ /1ле(сСЛиЛРА
Артём flciroB
Апкин Pyc/UK
Лоногс?^
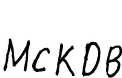
![]()
^АРА/\ШХо
Пример распознавания текста. Разрешение 300 dpi, клетчатая бумага.
K? r о BA y<f~ A - C - T~Ј-C - ^
f\uu\F4
^П|\?цН ^Vop 14 К &Obft
/нАстДси *
ИЛЫЛЧСЛЛ-* ^A^ftG/VMriP#
ЛрТЁЯ Пс? Г70/3 4тКщ-1
^у<^ЛАЦ
'Белок o'roL
Станислав
Jkh та Уо*л CLtuЈ0
КРАМсКоВ Шн
Пример распознавания текста. Разрешение 600 dpi, клетчатая бумага.
K? r О E>A Д-U - А&ГА-С
^NbMkUUUQtb-k Ј\ицрч
^ ^П|\?чН ^-vop ИХ
Ли*рМ ^-Ofe/V •/нАСТДси?
Илылчас/и
ЛрТЁЯ Пс? Г7С7/3
.. 4пкцН 'В'^АН
БглоногоЈ СгаНиСД<А^ hub Г
/ /д^л еииЧ-р
КРАмсКоВ ИШ
Пример распознавания текста. Разрешение 600 dpi, белая бумага.

\1млА, ииЦоН b\UuA El ЛЬ 4A liul-ioqA
Ельчанино&а Анна
ЕЕлЬЧЛНШЪА А
