

Для оценки результатов работы алгоритмов мы определили свою функцию стоимости разбиения на кластеры, алгоритм вычисления которой приведен ниже.
Алгоритм вычисления ![]()
![]() :
:
- Для каждого автора
- Выбираются «материнские кластеры» – кластеры наименьшего размера
среди тех, что содержат наибольшее количество рукописей автора.
- Ищется кластер
- Среди материнских кластеров ищется
![]()
На рисунке 7 представлен пример разбиения входного множества документов на четыре кластера. Каждый документ схематично помечен номером и цветом, которые обозначают автора. Тогда для разбиения, представленного, на рисунке 7 значение Cost функции будет равно 0.36.
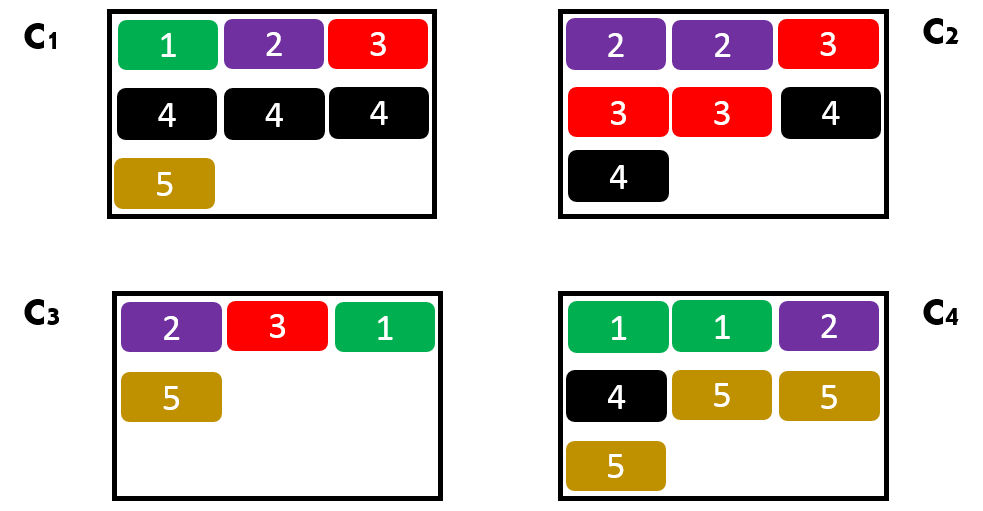
Рисунок 7. Пример разбиения входного множества документов на кластеры.
Был проведен ряд экспериментов для каждого алгоритма кластеризации, упомянутого выше. Каждый эксперимент определялся следующими параметрами:
Параметр ![]()
![]() был равен
был равен ![]()
![]() в алгоритмах
в алгоритмах ![]()
![]() - means, PAM. Online k-Means и
- means, PAM. Online k-Means и
DBSCAN определяют ![]()
![]() во время работы. Во время тестов алгоритма DBSCAN несколько дополнительных параметров должны были быть заданы. Алгоритм DBSCAN параметризуется двумя величинами, которые обозначаются как
во время работы. Во время тестов алгоритма DBSCAN несколько дополнительных параметров должны были быть заданы. Алгоритм DBSCAN параметризуется двумя величинами, которые обозначаются как ![]()
![]() и
и ![]()
![]() . Во время экспериментов
. Во время экспериментов ![]()
![]() был определен на основе максимального сходства между графами, а параметр
был определен на основе максимального сходства между графами, а параметр ![]()
![]() был взят из диапазона
был взят из диапазона ![]()
![]() . База данных KHAT была взята как источник отсканированных арабографических рукописных документов. Во время экспериментов параметр
. База данных KHAT была взята как источник отсканированных арабографических рукописных документов. Во время экспериментов параметр ![]()
![]() был приравнен к 3, 10 и 20. Число извлекаемых особенностей
был приравнен к 3, 10 и 20. Число извлекаемых особенностей ![]()
![]() было положено равным 15, 32, 64. Каждый писатель во время экспериментов имел в среднем 12 строк текста. Для алгоритма online k-means все тексты обрабатывались в произвольном порядке. Кластеризация производилась несколько раз. Результаты экспериментов с представлены в таблице 2.
было положено равным 15, 32, 64. Каждый писатель во время экспериментов имел в среднем 12 строк текста. Для алгоритма online k-means все тексты обрабатывались в произвольном порядке. Кластеризация производилась несколько раз. Результаты экспериментов с представлены в таблице 2.
Authors | Features | K-Means | Online K-Means | PAM | DBSCAN |
3 | 15 | 33 | 33 | 60 | 33 |
3 | 32 | 66 | 33 | 60 | 33 |
3 | 64 | 66 | 50 | 66 | 66 |
10 | 15 | 10 | 10 | 55 | 33 |
10 | 32 | 20 | 20 | 65 | 40 |
10 | 64 | 20 | 25 | 65 | 55 |
20 | 15 | 5 | 5 | 45 | 12 |
20 | 32 | 8 | 5 | 53 | 20 |
20 | 64 | 10 | 8 | 55 | 25 |
Таблица 2. Результаты экспериментов с кластеризацией
На трех кластерах алгоритм k-means показал 99 процентную точность. Как видно, точность кластеризации сильно зависит от числа извлекаемых особенностей. Online
k-means и DBSCAN показали приличные результаты, учитывая, что параметр ![]()
![]() не использовался в процессе кластеризации.
не использовался в процессе кластеризации.
Заключение
В результате проделанной работы была реализована система для автоматической идентификации автора арабографического рукописного документа по почерку его создателя. Система использовала алгоритм, в основе которого лежал алгоритм, предложенный для идентификации автора персидских рукописей, который в своей работе[5] описали B. Helli и E. Moghaddam. Система была реализована на языке программирования Python с использованием оптимизированных библиотек. Была проведена настройка системы для работы с арабографическими рукописными документами. В качестве данных для тестирования была взята база данных KHAT, которая содержала заранее сегментированные на строки рукописи тысячи авторов. Были проведен ряд тестов для анализа работы алгоритма для решения задачи классификации арабографических рукописных документов. Алгоритм показал достойные результаты на арабографических рукописных текстах при наличии достаточного количества тренировочных данных и небольшого числа авторов. Также в систему была добавлена функциональность кластеризации входного множества документов с использованием алгоритмов кластеризации K-Means, Online K-Means, PAM, DBSCAN. Был произведен ряд экспериментов для установления точности используемого алгоритма при решении задачи кластеризации. Эксперименты показали, что алгоритм может быть пригоден для использования при кластеризации документов лишь небольшого числа авторов с использованием алгоритмов кластеризации PAM.
Так как при числе авторов, превышающем 20, точность алгоритма значительно ухудшалась, не было проведено тестов с большим объемом данных. Поэтому в качестве возможных улучшений точности реализованной системы можно рассматривать:
- Использование особенностей другого типа Использование большего числа данных для каждого автора
Список литературы
[1] H. E.S. Said, T. N. Tan, K. D. Baker “Personal identification based on
Handwriting”, Pattern Recognition, Vol. 33(1), 2000.
[2] Imran Siddiqi, Nicole Vincent “Text independent writer recognition using
redundant writing patterns with contour-based orientation and curvature
features”, Pattern Recognition, Vol 43(11), 2010.
[3] Sameh M. Awaida, Sabri A. Mahmoud “Writer identification of Arabic
text using statistical and structural features”, Cybernetics and Systems:
An International Journal, Vol. 44(1), 2013.
[4] B. Helli, M. E. Moghaddam “A text-independent Persian writer identification
based on feature relation graph (FRG)”, Pattern Recognition, 2010.
[5] S. A. Mahmoud, I. Ahmad, M. Alshayeb, W. G. Al-Khatib, M. T.
Parvez, G. A. Fink, V. Margner, and H. EL Abed KHATT: Arabic Offline
Handwritten Text Database, In Proceedings of the 13th International
Conference on Frontiers in Handwriting Recognition (ICFHR 2012),
Bari, Italy, 2012, pp. 447-452, IEEE Computer Society.
[6] V. Shiv Naga Prasad and Justin Domke “Gabor filter visualization”, Technical Report, University of Maryland, 2005.
[7] P. Fuller “Gabor filter for scientists and engineers”, URL:
/gabor-filter-image-processing-for-scientists-and-engineers-part-6/
[8] OpenCV library, URL: opencv. org
[9] NumPy library, URL: numpy. org
[10] NetworkX library, URL: networkx. github. io
[11] K. Teknomo “K-Means Clustering Tutorials”, 2007, URL: people. \kardi\ tutorial\kMean\
[12] A. King “Online k-Means Clustering of Nonstationary Data”, 2012
[13] A. P. Reynolds, G. Richards and V. J. Rayward-Smith “The Application
of K-medoids and PAM to the Clustering of Rules”, Lecture Notes in
Computer Science, Vol. 3177, 2004
[14] Martin Ester, Hans-Peter Kriegel, Jrg Sander, Xiaowei Xu “A Density-
Based Algorithm for Discovering Clusters in Large Spatial Databases
with Noise”, AAAI Press, 1996.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
