
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Типы данных
Существует понятие базовые типы данных (base data types) – в противоположность пользовательским типам данных, которые может создавать пользователь.
Замечание по поводу префикса n (char – nchar, varchar – nvarchar). Префикс n означает, что символы будут храниться не в кодировке, заданной для базы данных (которая по умолчанию – если явно не меняли – совпадает с кодировкой операционной системы), а в кодировке Unicode. В России по умолчанию используется кодировка Windows 1251 (на 1 символ приходится 1 байт, т. е. алфавит ограничен 255-ю символами: русские, английские буквы, цифры, знаки препинания и некоторое количество прочих; греческих, французских и пр. нет). Кодировка Unicode позволяет хранить практически произвольные символы (отводится 2 байта, т. е. 65536 различных символов), но при этом на один символ приходится фактически 2 байта. Соответственно, если не планируется работать с экзотическими символами, лучше не указывать префикс n, чтобы не расходовать напрасно место.
Перечислим основные базовые типы данных:
char | Символьный тип данных, длина фиксирована. Если определен размер 20, будет сохранено ровно 20 символов. Если текст содержит меньше символов, он будет дополнен пробелами справа. Например, если в колонку char (10) ввести «aaa», текст будет сохранен как «aaa ». Обычно не самый удобный в работе тип данных. Используется, например, для номера счета в банке (номер счета всегда имеет одну и ту же длину) или в том случае, когда текст используется как идентификатор. |
nchar | Аналогично char, но символы хранятся в кодировке Unicode. |
varchar | Аналогично char, хранит символьные данные. Разница в том, что может содержать переменное число символов вплоть до верхней границы, указанной при создании. Например, если тип определен как varchar(50) , столбец может содержать данные длиной до 50 символов. Тем не менее, если ввести строку длиной 3 символа, только они будут сохранены (в отличие от char, дополнения пробелами не происходит). Данный тип идеально подходит для хранения имен, фамилий и т. п. – в общем, используется гораздо чаще, чем char. Максимально возможная длина, которую можно указать при создании столбца, – 8 000 characters, т. е. нельзя, например, определить столбец как varchar (10 000). Если определить столбец, не указывая размер – varchar()—это эквивалентно varchar(1). Можно также задать тип как varchar(max) – в случае, если в какой-то строке длина может оказаться больше 8 000. |
nvarchar | Аналогично varchar, но символы хранятся в кодировке Unicode. |
text – не исп.! | Данный тип может хранить данные длиннее 8 000 символов. Предупреждение! Не используйте данный тип, т. к. в будущих версиях он будет удален! Указывайте varchar(max). |
ntext – не исп.! | Аналогично text, но символы хранятся в кодировке Unicode. Вместо него используйте nvarchar(max). |
image – не исп.! | image похож на тип text, но предназначен для хранения бинарных данных (любого размера), не только изображений, как можно подумать из названия, но музыки, фильмов и т. п. Будет удален в следующих версиях, поэтому используйте varbinary(max). |
int | Предназначен для хранения целых чисел от –2,147,483,648 до 2,147,483,647. |
bigint | Целые числа от –9,223,372,036,854,775,808 до 9,223,372,036,854,775,807. Соответственно, занимает больше места, чем int. |
smallint | Целые числа от –32,768 до 32,767. |
tinyint | От 0 до 255. |
decimal/ numeric | Оба типа хранят данные одной и той же точности и диапазона. Диапазон – примерно от -1038 до + 1038. Ограничение заключается в том, что в хранимом числе может быть в целом, справа и слева от запятой, 38 цифр максимум. Условно говоря, число хранится так: 38 цифр + число, которое указывает смещение запятой. Соответственно, чем больше точность (чем больше запятых справа от запятой), тем меньше цифр может быть слева от запятой. Очень важное замечание! Тип хранит числа в десятичном виде, поэтому никакой потери точности не происходит (при хранении чисел в виде float / real числа хранятся в двоичном виде; как вы знаете, при переводе «нецелых» десятичных чисел в двоичное число может измениться, сохраниться неточно). Вообще говоря, тип decimal / numeric – предпочтительный способ хранения десятичных чисел. |
float | Хранятся вещественные числа от –1.79E+308 до 1.79E+308 в двоичном виде. Возможна потеря точности при сохранении числа. Основное достоинство – т. к. хранится в двоичном виде, операции производятся быстрее. |
real | Аналогично float, но меньше диапазон и точность (зато и места занимают меньше): от –3.40E+38 до 3.40E+38 |
money | Хранит числа, у которых до 4 десятичных знаков. Если нужно больше 4-х десятичных знаков, необходимо выбрать другой тип. Знак валюты не хранится – фактически хранится только число. Называется денежным, т. к. задача хранить такие числа (до 4-х десятичных знаков) часто возникает в финансовых расчетах. Диапазон – от 922,337,203,685,477.5808 до 922,337,203,685,477.5807. |
smallmoney | Аналогично типу money, но диапазон меньше – от –214,748.3648 до 214,748.3647 |
date | Хранит дату от 1 января 1-го года до 31 декабря 9999 года. Формат YYYY-MM-DD. В предыдущих версиях SQL Server данного типа не было, был только тип datetime, хранящий и дату, и время. Соответственно, когда надо было хранить дату, выбирали тип datetime и хранили лишнюю информацию. Более того, нельзя было быть уверенным, что хранится в колонке типа datetime: только дата, только время или дата и время. Сейчас появился отдельный тип, и, если надо хранить только дату, используют его. |
datetime | Хранит дату и время с 1 января 1753 года до 31 декабря 9999 года. Если в колонку, определенную как datetime, поместить только дату, время будет установлено 12:00:00 (по умолчанию). Формат YYYY-MM-DD hh:mm:ss (обратите внимание – от больших величин к меньшим: год, месяц, день, час, минута, секунда). |
datetime2 | Аналогично datetime, но может хранить доли секунды для большей точности. Диапазон – от 1 января 1-го года до 31 декабря 9999 года. Формат YYYY-MM-DD hh:mm:ss[.nnnnnnn]. |
smalldatetime | Аналогично datetime, но диапазон от 1 января 1990 года до 6 июня 2079 года. |
datetimeoffset | Тип datetime хранит дату и время, не учитывая часовой пояс. Соответственно, если с одной и той же базой работают пользователи из разных регионов и, например, вносят 13:00 – один в Москве, другой в Тюмени – в базе будет храниться одно и то же значение, хотя должно быть разное, ведь события произошли в разное время – одно по тюменскому времени, другое по московскому. Можно, конечно, заставить пользователей вводить время в едином формате (скажем, всегда вводить московское время или время по Гринвичу – это время в Лондоне и исторически используется как «единое земное время»). Можно также программно добавлять или отнимать часы в отличие от того, где находится пользователь. Но есть способ проще – использовать тип datetimeoffset, который позволяет указать не только сохраняемое значение даты и времени, но и смещение часового пояса. Работа с этим типом удобно организована во многих средах, и задача программиста заметно упрощается. Говорят, что дата и время хранятся как значение Coordinated Universal Time (UTC). Формат: YYYY-MM-DD hh:mm:ss[.nnnnnnn] [+|-]hh:mm, где hh:mm – смещение времени. Например, у нас (как все видели в настройках Windows) время смещено относительно Гринвича на +5, т. е. у нас на 5 часов больше времени, чем в Лондоне. Если нужно сохранить время 13:00 сегодняшнего дня, оно будет сохранено в глобальной базе как 2009-09-19 13:00:00 +05:00. |
time | Хранит только время, формат hh:mm:ss[.nnnnnnn]. Аналогично типу date, данный тип был введен в SQL Server 2008. |
hierarchyid | Тип предназначен для работы с иерархиями, использует. NET. Данный тип говорит, где в иерархии находится данная строка. |
geometry | Позволяет хранить географическую информацию (геометрию) для «плоской земли». Можно хранить точку, кривую, многоугольник. |
geography | Позволяет хранить географическую информацию (геометрию) для «круглой земли». Современные СУБД позволяют работать с географическими данными и поддерживают специальные типы, чтобы было удобней работать, но, как правило, этим пользуются не «простые» разработчики, а разработчики ГИС (геоинформационных систем). |
rowversion | Данный тип используется для столбцов, для которых данные генерируются SQL Server (программист в данном столбце ничего не меняет). Значение в rowversion будет уникальным для всей базы данных. Каждый раз, когда меняется значение в строке, меняется значение rowversion, чтобы учесть время модификации (точнее, момент времени). rowversion часто называют timestamp – можно встретить в предыдущих версиях SQL Server. |
uniqueidentifier | Содержит Globally Unique Identifier (GUID) – глобально уникальный идентификатор. Генерируется с использованием уникальной информации от сетевой карты, идентификатора процессора и даты со временем. Если сетевой карты нет, генерируется по информации компьютера. Это достаточно длинное число, и вероятность повторения настолько мала, что можно считать сгенерированное число уникальным в мире – отсюда такое название. |
binary | Данные в двоичном формате. Используется главным образом для хранения флагов или комбинаций флагов. Данные будут ровно такого размера, как указан. Например, для каждой записи необходимо хранить 3 флага. 011 будет означать, что первый признак не установлен, второй и третий – установлены. В столбце будет храниться 3 (перевели из двоичной системы в десятичную). |
varbinary | Аналогично binary, но размер может меняться вплоть до указанного максимума (аналогично char и varchar). Максимум – 8 000 символов, но varbinary(max) может хранить больше. |
bit | Хранит 0 или 1. Обычно используется для хранения true (1) или false (0). |
xml | Для хранения данных XML. Позволяет в дальнейшем специальным образом обрабатывать данные. |
Программные типы данных
cursor | Данные могут храниться в памяти в использование структуры, называемой курсор. Курсор похож на таблицу, т. к. есть столбцы и строки. Используется для просмотра одной строки в единицу времени. Курсоры используются, например, при просмотре данных по запросу «вернуть студентов 373-й и 374-й группы» – формируется структура в памяти и ее данные просматриваются с использованием курсора. |
table | Тип похож на обычную таблицу. Похож и на курсор, но можно просматривать не по одной строке в единицу времени, а как набор, множество. |
sql_variant | Позволяет помещать произвольный тип данных. Может использоваться как программно, так и как тип данных колонки. На самом деле, не факт, что его следует использовать, т. к. строгая типизация – очень часто способ избежать ошибок. |
При создании столбцов можно задать значение по умолчанию (default value) – это значение, которое будет вставляться при вставке строки, у которой в данном столбце ничего не задано. Если при вставке строки значение для данного столбца задано, оно и будет вставлено.
Дополнительные опции
Можно заставить SQL Server генерировать последовательные значения. Для этого используется опция Identity в свойствах столбца. При этом используется некоторая начальная точка – seed (в дословном переводе – семя). Также задается Increment (увеличение) – то, на сколько будет увеличиваться значение для каждой новой строки.
Обычно пользователь не может вставлять значение в данный столбец. Тем не менее, если изменить опцию IDENTITY_INSERT базы данных на ON, пользователю будет это позволено (команда SET IDENTITY_INSERT ON).
Столбцы можно определить как NULL (могут быть пустые значения) или NOT NULL (не может быть пустых значений). В дизайнере для этого есть специальный столбец Allow Nulls. Очень важная опция! По поводу каждого столбца надо думать, обязательно его заполнять или нет, и исходя из этого указывать данный признак. Не заполнить его – ошибка. Если значение обязательно (NOT NULL), а при вставке значение для столбца не указано и при этом не задано значение по умолчанию, возникнет ошибка.
Для хранения больших данных (изображений, текстов и т. п.) есть следующие альтернативы:
- Хранить в виде файла на файловой системе, а в SQL Server хранить только путь; Хранить в таблице в виде бинарного большого объекта (binary large object – BLOB), указав тип как varbinary(max), что позволит хранить файл до 2 Гб (примерно). Для текста это будет тип varchar(max) и название CLOB – character large object. Использовать опции, как указано выше (varbinary), но при этом данные будут храниться не в таблице, а отдельно. Это ускорит работу по сравнению с вариантом хранения в таблице, и при этом более удобно, чем 1-й вариант. Необходимо указать тип данных (varbinary(max)) вместе с параметром FILESTREAM плюс включить эту опцию в БД, вызвав хранимую процедуру sp_filestream_configure.
Рекомендация. Не используйте пробелы, русские буквы и прочие «неанглийские» символы в названиях объектов базы данных, хотя SQL Server и позволяет это делать. Вместо пробелов слова можно разделять так: CustomerId или customer_id (лучше 1-й вариант).
При создании таблиц в SSMS, чтобы значения столбца автоматически увеличивались, необходимо раскрыть узел «Identity Specification» и указать необходимые параметры:

Для столбца типа date в качестве значения по умолчанию может быть удобно указать GETDATE() – функция, которая возвращает сегодняшнюю дату.
При работе с таблицей внизу показываются свойства столбцов, справа – свойства всей таблицы. Чтобы увидеть свойства всей таблицы, выберите View, Properties Window. Будет показано следующее окно:
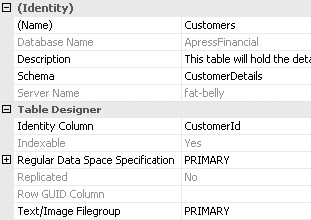
Здесь сразу же можно указать (Name) – имя таблицы, описание – Description (описание полезно давать и каждому столбцу, а для курсовой и домашних заданий – обязательное требование). Еще одна важнейшая вещь – схема (Schema).
Схема (Schema) – способ группировки объектов. В старых версиях SQL Server приходилось задавать владельца для каждого объекта, а затем, если пользователь менялся, – менять владельца у каждого объекта. Позже появился более удобный способ. Задается схема, у схемы есть владелец, и таблицы относятся к схеме (схемы задаются в папке Security базы данных). Если необходимо сменить пользователя, меняется пользователь у схемы – и все!
Чтобы создать таблицу при помощи CREATE TABLE …, имя схемы указывается перед именем таблицы:
CREATE TABLE[schema_name].table_name
Можно даже указать имя базы:
CREATE TABLE [database_name].[schema_name].table_name
Это позволяет создать таблицу в другой базе (другой вариант – вначале выполнить USE <имя базы>).
Таблицу можно создать, выполнив код в Query Editor – мы это делали. Код можно создать с помощью шаблона. Список шаблонов можно увидеть, выбрав View, Template Explorer, далее развернув, например, Table, Create Table. Значения параметров можно подставить, нажав на кнопку «Specify Values for Template Parameters» (последняя кнопка в строке, где есть и кнопка выполнения запроса).
Мы поступали по-другому: щелкали правой кнопкой по таблице, Script table as и далее меняли скрипт. Шаблоны хранятся здесь: C:\Program Files\Microsoft SQL Server\100\Tools\Binn\VSShell\Common7\IDE\SqlWorkbenchProjectItems\Sql.
Сценарий. Была создана таблица и к ней решили добавить столбец. Который не может быть пустым. Но его не получится сразу же добавить, т. к. уже имеющиеся строки будут нарушать ограничение! Один из вариантов – добавить столбец, который может содержать NULL, затем заполнить значениями и, наконец, исправить, чтобы столбец не мог содержать NULL.
Первичный ключ можно задать, используя соответствующую кнопку на панели инструментов либо из контекстного меню. Далее в режиме Design можно нажать кнопку «Manage Indexes and Keys».
Связи
Важнейший момент – создание связей между таблицами. В режиме Design необходимо воспользоваться контекстным меню и нажать «Relationships» или нажать одноименную кнопку на панели инструментов. Откроется следующее окно:
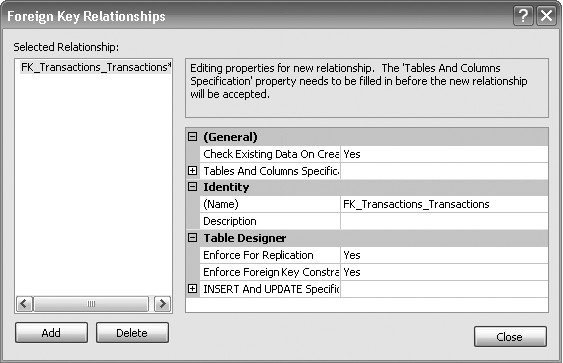
Самое важное – узел «Tables And Columns Specification» – указание таблиц и столбцов. Они указываются для каждой связи, выбранной в списке слева.
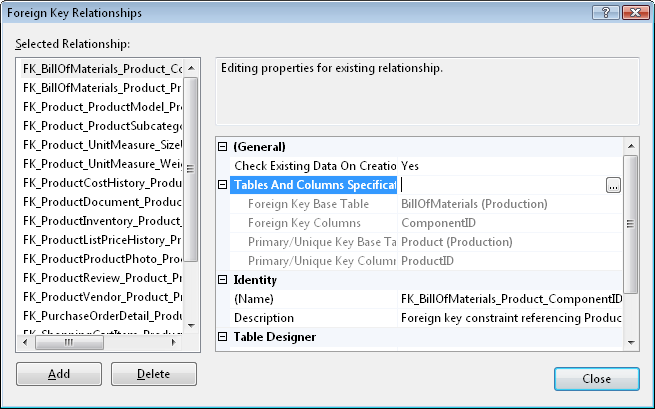
Справа от узла можно нажать кнопку с многоточием, откроется отдельное окно (так несоклько удобней):
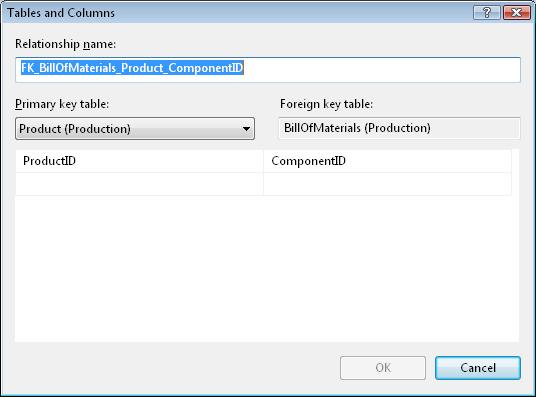
Вверху задается имя связи – удобно задать «понятное» имя.
В столбце «Primary key table» задается имя таблицы, в которой для данной связи находится первичный ключ, и поле, в котором данный первичный ключ определен. Еще раз: для данной связи описывается таблица, на которую ссылаются. В столбце «Foreign key table» задается имя таблицы и столбец, которые ссылаются на таблицу с первичный ключом, т. е. задается таблица с внешним ключом.
Еще раз внимательно посмотрите на диалоговое окно. «Тонкий» момент заключается в том, что мы должны находиться в режиме Design для таблицы, которая ссылается, т. е. для таблицы с внешним ключом! Поменять таблицу с внешним ключом нельзя.
Когда указано самое главное – какие таблицы по каким полям связаны, можно указать некоторые дополнительные вещи для связи.
«Check Existing Data on Creation» (проверить существующие данные при создании). Если указать «Да», существующие данные будут проверены. Предположим, мы добавляем связь между студентами и группами. Уже заведены студенты, и у некоторых из них, возможно, указаны группы, которых не существует. Если мы укажем «Yes» – проверить – то SQL Server проверит, найдет ошибку и не создаст связь. Что делать? Есть 2 варианта:
Исправить данные для студентов, у которых указана несуществующая группа (или создать группы) и заново создать связь. Указать «No», тогда данные не будут проверены и связь создастся. Но ведь есть нарушения! Поэтому по-хорошему, «обезопасившись» от того, что могут появиться еще неправильные данные (ведь далее связь будет проверяться), идем и исправляем данные. Можно создать связь, но временно отключить ее! Скажем, мы не хотим заново указывать таблицы, поля и т. п. Поэтому в поле «Enfoce Foreign Key Constraint» (включить ограничение внешнего ключа) указываем «No», связь создается, но не работает. Затем исправляем данные и включаем связь.И еще одна важнейшая вещь – узел «INSERT and UPDATE Specification»:
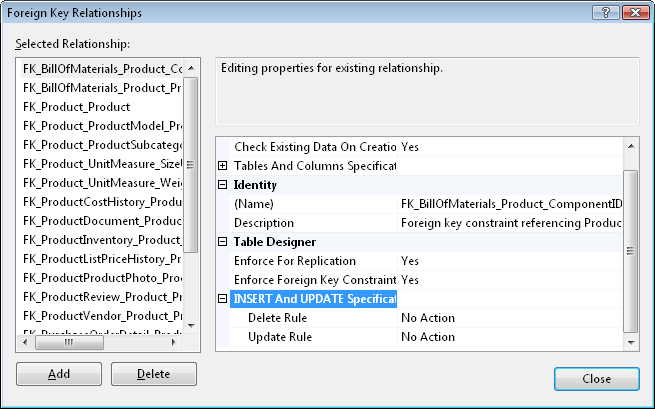
Рассмотрим следующую ситуацию. В таблице студентов Students есть поле GroupId, которое является внешним ключом: оно ссылается на поле GroupId в таблице Groups. Мы определили связь между таблицами по этому полю. Записи таблицы Students ссылаются на записи таблицы Groups. Теперь необходимо решить вопрос: что будет происходить, если удаляется группа? Ведь имеются студенты, которые ссылаются на данную группу. Что должно произойти с записями студентов? Просто удалить группу нельзя: это будет нарушение связи, связи как раз для того и определяются, чтобы не возникало такой ситуации, когда записи ссылаются «в никуда». Что будет происходить при удалении записи из главной таблицы (таблицы с первичным ключом) – выбирается в поле Delete Rule.
Итак, варианты значений:
- No Action (Нет действия) – действие не предпринимается. Соответственно, раз запрещена ситуация, когда ссылаются записи «в никуда», запись из главной таблицы, если на нее ссылаются (а ведь могут и не ссылаться на нее) не удаляется, а возникает ошибка. В сообщении об ошибке сказано, что нельзя удалить запись, раз на нее ссылаются. Cascade (каскадное удаление). Запись из главной таблицы (группа) удаляется, и удаляются все записи (студенты), которые на нее ссылаются. Ограничение не нарушается. При этом возможна следующая ситуация: удаляется группа; удаляются студенты, которые на нее ссылаются; на студентов ссылаются, скажем, их оценки, и они тоже удаляются (если стоит каскадное удаление), т. е. одно удаление вызвало целый каскад (увеличивающийся) удалений – отсюда и название. Set Null (установить NULL). В ссылающуюся таблицу (Students) в поле устанавливается Null, а группа удаляется. Сработает только в том случае, если в данном поле может быть Null. Если же Null быть не может, возникнет ошибка. Set Default (установить значение по умолчанию). В ссылающуюся таблицу (Students) в поле устанавливается значение по умолчанию. Сработает только в том случае, если для поля было задано значение по умолчанию, иначе будет выдана ошибка.
