

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
- возможность агрегирования, то есть простого или «взвешанного» суммирования значений некоторых признаков.
Нас далее будет интересовать такая постановка задачи, при которой происходит выбор информативных признаков из имеющихся признаков (selection). Если каждый из M объектов из рассматриваемого множества A, описывается набором характеристик Х={X1,…,Xj,…,XN}, то через P(X) обозначим множество всех подмножеств X, их будет 2N. Тогда задачу выбора системы информативных признаков при заданном функционале качества Qf запишем следующим образом:
![]() . (1.3)
. (1.3)
Конкретный вид функционала качества выбранных признаков зависит от специфики решаемой задачи и опирается на один из возможных критериев:
- критерий автоинформативности, обеспечивающий максимальное сохранение информации, содержащейся в исходной выборке, относительно самих исходных признаков;
- критерий внешней информативности, нацеленный на максимальное выжимание из исходной выборки информации, относящейся к некоему внешнему результирующему признаку (имени класса в задаче распознавания, прогнозируемому признаку в задаче регрессионного анализа).
Автоинформативность обычно оценивается:
- через дисперсии признаков, так как в некоторых случаях исследователя интересуют в первую очередь лишь те признаки, которые обнаруживают наибольшую изменчивость при переходе от одного объекта к другому;
- через величину искажения геометрической структуры в новом подпространстве относительно исходного пространства;
- через корреляцию, позволяющую определять группу (класс) исходных признаков через один или несколько информативных с достаточной степенью точности;
- через энтропию, позволяющую оценивать, насколько распределение значений того или иного признака близко к равномерному (в случае если область допустимых значений признака является интервалом).
Примерами оценок внешней информативности в задаче распознавания образов являются:
- величина попарного различия между законами распределения вероятностей вектора информативных признаков в распознаваемых классах (оно может оцениваться через расстояние Махаланобиса, расстояние Кульбака и другими методами);
- критерий Фишера [10].
Еще один фактор, который может учитываться при построении функционала качества - это затраты на измерение и хранение признаков N1. В некоторых задачах, когда измерение каждого признака для нового объекта требует дорогостоящих экспериментов, эта составляющая N1 может играть важную роль в итоговом функционале качества Qf.
В англоязычной литературе алгоритмы выбора признаков делятся на два класса - фильтрующие (filters) и оберточные (wrappers) [46].
Фильтрующие подходы оценивают информативность каждого признака, используя только исходную таблицу данных и не учитывая, каким алгоритмом будет решаться основная задача (достигаться основная цель).
Оберточные алгоритмы [44] используют алгоритм достижения основной цели для того, чтобы оценить качество каждого признака (подмножества признаков). В случае, например, если основной целью является построение решающего правила, алгоритм обучения (распознавания) запускается на каждом анализируемом признаковом подпространстве и в качестве информативности используется надежность распознавания. Этот класс алгоритмов в нашей терминологии уже относится к алгоритмам комбинированного типа, о которых более подробно речь пойдет ниже.
Для выбора информативной системы признаков оба подхода обычно используют комбинаторный поиск в пространстве всевозможных подмножеств признаков. В нем используются различные эвристики, как например последовательный прямой и обратный поиск [48], комбинация прямого и обратного поиска, реализованные в алгоритме AdDel [15], поиск гранул (beam search) и двунаправленный поиск [55], ближайший наилучший (best first) [59] и генетические алгоритмы [56]. Также существуют подходы, использующие теорию нечетких множеств [52].
1.2. Задачи распознавания образов комбинированного типа
Итак, мы сформулировали несколько основных типов задач, хорошо разработанных и решаемых уже на протяжении многих лет. Однако в реальной практике довольно часто встречаются задачи, которые нельзя отнести к одному из этих типов. Они представляют собой некоторую смесь основных. Частные случаи таких комбинированных задач описываются в литературе как имеющие самостоятельную ценность, и для их решения предлагаются конкретные подходы. Некоторые задачи комбинированного типа были только сформулированы [16], однако сколь-нибудь общих подходов к их решению до сих пор не существует. В данной главе мы попытаемся кратко изложить суть всех возможных задач распознавания образов комбинированного типа.
1.2.1. Построение решающего правила + выбор признаков (DX)
При решении задачи построения решающего правила в классической формулировке предполагается, что обучающая выборка А является представительной. Обычно под представительностью выборки подразумевают следующее:
· Объекты, содержащиеся в выборке, достаточно полно характеризуют стратегию природы, в соответствии с которой они были порождены,
· Признаки, используемые для описания объектов выборки, информативны.
Однако в реальных задачах эксперты часто не могут точно указать, какие из признаков окажутся важными и информативными для распознавания целевого признака, какие же никак не связаны с ним и будут только ухудшать результаты. В подобной ситуации имеет смысл решать задачу комбинированного типа – построение решающего правила с одновременным выбором информативной подсистемы признаков.
В общем виде для некоторой обучающей выборки А задача DX может быть записана следующим образом:
 (1.4)
(1.4)
Здесь Qfr – обобщенный критерий качества решения задачи DX, величина которого в самом общем случае зависит как от информативности выбранной системы признаков, так и надежности построенного решающего правила.
Эта задача известна давно. В [44] она формулируется как задача выбора системы признаков, обеспечивающей построение классификатора наилучшего качества. В работе [41] демонстрируется, что добавление процедуры выбора признаков улучшает качество создаваемого решающего правила в случае использования статистических методов. Так же показывается, что даже алгоритмы, в которых процесс построения решающего правила совмещен с выбором информативных признаков, например, деревья решений, оказываются неустойчивыми при наличии в обучающей выборке шумящих признаков. Поэтому добавление процедуры выбора информативной системы признаков позволяет улучшить не только скорость работы непосредственно на этапе построения правил-деревьев, но и их надежность [57].
Ключевым в этой задаче является понятие релевантности признака. Существуют различные формальные определения этого понятия. Например, в [40] при известной стратегии природы в случае дискретного распределения признак Xi считается релевантным целевому признаку Y, если для некоторого значения этого признака ωi, такого, что P{Xi=ωi}>0, P{Y=τ|Xi=ωi}¹ P{Y=τ}. В зависимости от того, как определяется релевантность и как она оценивается, зависит вид критерия качества Qfr.
Чаще всего такая задача DX решается в самом упрощенном виде. Сначала на основании некоторых гипотез строится информативная система признаков и лишь потом в пространстве этих признаков запускается процедура построения решающего правила. Основанием для признания системы информативной может служить, например, большое расстояние между функциями распределения в пространстве этих признаков для разных образов, или изменение зависимости между признаками от образа к образу. То есть, значение качества Qf(p,A) системы признаков p не зависит от последующего выбора решающего правила d. Таким образом
Qfr(p, d, А)=Qr(d, Ap*), где 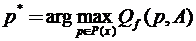 .
.
Здесь Ap* - проекция обучающей выборки на информативное подпространство p*, Qr(d, Ap*) - надежность решающего правила d в этом признаковом подпространстве. Алгоритмы, решающие задачу в таком виде, в англоязычной литературе называются фильтрующими. Примером алгоритма, реализующего фильтрующий подход, может служить алгоритм RELIEF [43]. В нем каждому признаку (признаковому подпространству) в процессе работы алгоритма приписывается определенный вес (соответствующий его информативности). Веса же вычисляются на основе того, насколько близкими или далекими для каждого объекта выборки оказались ближайший представитель «своего» образа и ближайший представитель «чужого» образа в исследуемом подпространстве. Другие виды фильтрующих алгоритмов описаны [34, 45]. Естественно, что во всех фильтрующих алгоритмах необходимо учитывать, насколько технология отбора признаков и критерий качества системы признаков согласуется с методикой распознавания, используемой в дальнейшем. Наилучшая система признаков, выбранная для построения дерева решений, может отличаться от наилучшей системы признаков, выбранной для построения линейных разделяющих границ.
В классе оберточных алгоритмов [44] подобная согласованность обеспечивается автоматически. В процессе выбора информативной системы признаков используется непосредственно сам алгоритм выбора(построения) решающего правила из заданного класса. Надежность решающего правила, построенного на некотором подпространстве, сама по себе и является мерой информативности этого подпространства.
Этот же подход применим в случае, когда затраты на измерение признаков соизмеримы с потерями на ошибках распознавания. В подобной ситуации при решении задачи распознавания реально должна минимизироваться не ошибка распознавания, а некоторая функция потерь. Эта функция зависит как непосредственно от качества распознавания, так и от «стоимости» измерения признаков, необходимых для распознавания с помощью построенного решающего правила. В таком случае выбор информативной системы признаков и решающего правила должен проводиться параллельно. Фильтрующие алгоритмы здесь оказываются неприменимыми.
1.2.2. Таксономия+выбор признаков (SX)
Довольно часто при формулировке задачи таксономии (группировки объектов по похожести свойств) эксперт не может указать фиксированный набор признаков, который нужно использовать для нее. Более того, жесткая фиксация этого набора может привести к ухудшению качества таксономии, не позволит проявиться некоторым свойствам, которые потеряются во множестве шумящих неинформативных признаков. В такой ситуации необходимо решать задачу комбинированного типа, когда одновременно ведется поиск оптимального варианта таксономии (S) и оптимального набора признаков (X), по которым осуществляется эта таксономия. В самом общем виде без конкретизации вида критерия Qft качества эта задача может быть записана так:
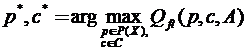 . (1.5)
. (1.5)
В [2] частный случай задачи (5) упоминается как задача сжатия массивов обрабатываемой и хранимой информации. Однако в ней функционал качества имеет более простой вид :
Qft (p, с, A) = Qt(с, Ap*) , где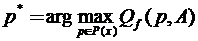 .
.
Здесь Ap* - проекция исходного множества объектов А в подпространство p*, признанное информативным с точки зрения некоторого критерия информативности Qf, а Qt(с, Ap*)- качество таксономии с в этом признаковом подпространстве. Такой взгляд на задачу позволяет для ее решения применять методы классификации, сокращающие объем выборки, и методы снижения размерности, уменьшающие количество описывающих признаков, независимо друг от друга.
Другой частный случай задачи (1.5) возникает когда информативными считаются те признаки, в пространстве которых анализируемое множество объектов A хорошо разбивается на изолированные классы. Тогда мера информативности системы признаков р определяется следующим образом:
![]() ,
,
где Ap – проекция исходного множества объектов в подпространство p. В такой ситуации уже не удается разбить исходную задачу на две задачи основных типов, чтобы решать их независимо. В самом общем случае для ее решения приходится привлекать алгоритмы направленного перебора подпространств признаков и в каждом из них решать задачу таксономии.
Если для задачи выбора системы информативных признаков с одновременным распознаванием DX разработано большое количество методов, то работ, посвященных решению задачи SX гораздо меньше. Конечно, здесь применимы методы фильтрации, в которых при оценке качества той или иной подсистемы признаков метки классов не используются. К ним относятся методы, измеряющие похожесть признаков для определения их избыточности, используя взаимную информативность [54] или индекс максимального сжатия информации [50]. Кроме того, существует ряд работ, посвященных выбору признаков для таксономии, при решении этой задачи в статистической постановке, с помощью оценки максимального правдоподобия. Так в [37, 46] для оценки качества таксономии в различных признаковых подпространствах используется нормализованное логарифмическое правдоподобие и разделимость кластеров.
Оберточные методы также могут быть приспособлены для выбора признаков в задаче таксономии. Так, например, с помощью генетических алгоритмов отыскивается информативное подпространство признаков в кластеризации методом k-Means [42]. Здесь одновременно оптимизируется несколько эвристических критериев качества таксономии таких как среднее внутреннее расстояние в таксонах, среднее расстояние между таксонами, количество таксонов и количество признаков. При этом отслеживается выполнимость условия о том, что создаваемая таксономия должна содержать небольшое число таксонов в пространстве малой размерности.
1.2.3. Таксономия+построение решающего правила (SD)
В общем случае, когда решается задача самообучения, имеет смысл не только разбивать объекты на группы, но и описывать их с помощью некоторого решающего правил, которое позволит в дальнейшем эффективно классифицировать новые объекты. Часто сам вид критерия качества таксономии позволяет четко зафиксировать – какой тип решающих правил будет наиболее эффективен для распознавания построенных классов. Более того, в некоторых широко известных алгоритмах таксономии решающее правило строится непосредственно в процессе таксономии. Так, например, в случае использования алгоритма k-Means, последующее распознавание может осуществляться с опорой на центры таксонов. Новый объект относится к тому таксону, центр которого оказывается ближайшим к нему. При использовании EM-алгоритма [36] в процессе построения разбиения вычисляются параметры распределений для построенных классов. Это дает возможность построить Байесово решающее правило для распознавания данной классификации.
Однако далеко не все из существующих алгоритмов таксономии обладают такими свойствами. Например, в алгоритме FOREL [15] использование центров построенных таксонов в качестве эталонов для распознавания новых объектов в отличии от алгоритма k-Means окажется неэффективным. В этом случае становится осмысленной более сложная задача - одновременное решение задачи таксономии и задачи построения решающей функции. Ищется такой вариант, группировки объектов с* и такой вид решающего правила d*, которые совместно обеспечивают максимальное значение обобщенного критерия качества Qrt, зависящего как от меры компактности полученных образов, так и от простоты их описания с точки зрения решающих правил:
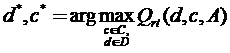 . (1.6)
. (1.6)
Для этого типа комбинированных задач можно выделить несколько интересных частных случаев использования. Например, опора на результаты таксономии позволяет использовать информацию, содержащуюся не только в обучающей выборке A, но и в распознаваемой (контрольной) для построения решающего правила. Это используется в алгоритме ТРФ [15].
Так же имеет смысл решать комбинированную задачу, когда есть основания предполагать, что обучающая выборка в задаче распознавания образов может содержать ошибки, выбросы. Использование методов таксономии в этом случае позволит оценить компактность исходных образов и выявить ошибки – объекты нарушающие ее наиболее сильно. Фильтрация такого рода выбросов может повысить надежность и устойчивость создаваемых решающих правил.
1.2.4. Таксономия+распознавание+выбор признаков (SDX)
В наиболее общем случае при анализе новой выборки А одновременно должны решаться все три основные задачи распознавания образов: выбираться такое подпространство признаков, такое разбиение на таксоны в нем и такое описание этих таксонов, чтобы некоторый комбинированный критерий качества Qrft достигал своего максимального значения. В общем случае этот критерий качества зависит от компактности полученных таксонов, простоты и надежности решающего правила, описывающего их, и затрат на измерение и хранение признаков, необходимых для дальнейшего использования полученного разбиения. Оптимизационная задача выглядит следующим образом:
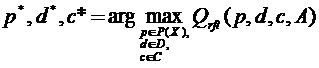 . (1.7)
. (1.7)
Эту задачу можно считать наиболее общей задачей распознавания образов. В ее рамках перед исследователем оказывается набор данных единой природы (из ограниченной предметной области), представленный в виде таблицы «объект-свойство». При этом относительно представленного набора известно лишь одно – он достаточно полно отражает многообразие объектов этой природы (предметной области) и многообразие признаков, их описывающих. Задачей же исследователя является структуризация этого возможно избыточного набора информации, представление его в виде, удобном для дальнейшего анализа и использования человеком.
Также задача SDX может рассматриваться как задача построения решающего правила в случае, если для описания выборки могут использоваться неинформативные признаки, а среди объектов выборки могут встречаться выбросы или ошибки в данных. Но в критерии качества Qrft при этом основной упор должен делаться на том, насколько решения всех трех задач S, D и X согласуются с исходным разбиением выборки на классы.
Один из вариантов решения задачи SDX описан в [22]. Здесь логические решающие правила использовались для построения таксономии. Действительно, в процессе работы алгоритма для описания таксонов создавались коньюнкции, в которые входили только информативные признаки. И эти же коньюнкции могли использоваться для дальнейшего распознавания объектов – отнесения их к тому или иному таксону. Однако в рамках этого подхода задача построения решающего правила решалась лишь частично, так как описывающие таксоны логические правила покрывали только часть пространства признаков, причем наилучшим считалось разбиение, в котором это покрытие было минимальным возможным. Поэтому значительная доля новых объектов могла оказаться за пределами границ таксонов и быть нераспознанной.
Выводы по первой главе
1. Для всех задач распознавания образов основных типов разработан широкий спектр методов их решения, как эвристических, так и статистических. Особенностью этих методов является то, что для их корректной работы необходимо, чтобы выполнялся ряд дополнительных требований к анализируемой выборке. На практике же далеко не всегда имеется возможность утверждать, что решаемая задача удовлетворяет этим требованиям. В связи с этим процесс решения задач распознавания образов во многом остается творческим, а результат зависит, как от умения исследователя подобрать подходящий метод исследования, так и от способности эксперта предметной области сформировать представительный набор объектов и признаков для обучения.
2. Задачи комбинированного типа возникают тогда, когда появляется необходимость одновременно и согласованно решать несколько задач основных типов для одной и той же выборки. Обычно такого рода задачи возникают при анализе массивов данных, непредставительных с точки зрения классической теории распознавания. В таких массивах среди описывающих признаков могут присутствовать неинформативные, объектов обучающей выборки может быть недостаточно для обнаружения скрытой закономерности, среди них могут присутствовать «выбросы». Другими словами, переход к задачам комбинированного типа позволяет смягчать требования к исходной обучающей выборке и учитывать возможные неточности в ней.
3. Задачи комбинированного типа лучше согласовываются с человеческими принципами восприятия и анализа информации, так как в реальной жизни распознающей системе под названием «человек» обычно приходится решать задачи классификации, группировки и выбора признаков одновременно.
4. Хотя термин «задача комбинированного типа» известен с 70-х годов, эту область нельзя назвать тщательно проработанной. Если задачей DX занималось и занимается большое количество исследователей, то задача SX решается, в основном, в статистической постановке, когда выбор признаков осуществляется после фиксации вероятностной модели рассматриваемой выборки с точностью до нескольких параметров. Что касается наиболее сложной и интересной задачи комбинированного типа – задачи SDX, то серьезных исследований, касающихся методов ее решения, очень немного. В данной работе рассматриваются все типы задач комбинированного типа, очерчивается область их применения. Каждая конкретная задача более точно формулируется, предлагаются алгоритмы ее решения, приводятся примеры работы этих алгоритмов и сравнение их эффективности с эффективностью общепризнанных методов на примерах реальных прикладных и модельных задач.
Глава 2. Функция конкурентного сходства в задаче DX
Многообразие существующих методов решения задач распознавания образов во многом объясняется тем фактом, что в основе различных методов лежат различные дополнительные гипотезы о природе анализируемой выборки. В рамках статистического подхода эти гипотезы могут касаться типов распределения, которому подчиняется исследуемый материал, независимости описывающих признаков, независимости объектов обучающей выборки. Наиболее популярными гипотезами, используемыми в эвристических алгоритмах, являются гипотезы унимодальной компактности, полимодальной компактности, локальной компактности [15]. Но помимо них могут использоваться и более сильные гипотезы, к примеру, гипотеза о линейной разделимости образов, об их сферической форме или о покоординатной разделимости образов [9]. В связи с этим при решении задач комбинированного типа для решения задач основных типов, из которых они состоят, целесообразно использовать единый подход, опирающийся на одну и ту же базовую гипотезу. Так, например, если при решении задачи SD строятся таксоны сложной формы с помощью алгоритма KRAB [15], то для их описания не стоит использовать линейные решающие правила. Все тонкости структуры таксонов, уловленные KRAB-ом, настроенным на анализ локальных изменений поведения выборки, могут быть потеряны из-за огрубления картины. В этой ситуации целесообразнее применять один из алгоритмов, создающих кусочно-линейное решающее правило, например, STOLP [15]. А если линейная разделимость классов является обязательным условием, то на этапе построения классификации можно использовать, например, алгоритм k-Means [42], изначально настроенный на формирование линейно разделимых таксонов.
В качестве единого базиса для решения различных задач распознавания образов в данной работе используется метод оценки близости между объектами, основанный на функции конкурентного сходства (FRiS-функции). Ее использование позволяет нам строить внутренне непротиворечивые и эффективные алгоритмы для решения задач комбинированного типа DX (распознавания с одновременным выбором информативной системы признаков), SD (таксономии с одновременным построением решающего правила) и даже SDX (таксономии с одновременным построением решающего правила в пространстве наиболее информативных признаков). Результаты, полученные в процессе исследования FRiS-функций и их применимости при решении задач распознавания образов как простого, так и комбинированного типа, приводятся далее.
2.1. Функция конкурентного сходства
Во многих задачах анализа данных используется понятие «похожести», «близости», «сходства». На меру «сходства» объекта с образом так или иначе опираются все правила распознавания. В группы по «похожести» объединяются объекты при таксономии. На данный момент наиболее распространенным является подход, когда в качестве меры похожести двух объектов используется расстояние между ними, измеренное в некоторой информативной системе признаков. Однако, даже самый поверхностный анализ человеческих представлений о сходстве показывает, что понятие это относительно и не может определяться без учета контекста. Так Москва и Новосибирск окажутся «близкими», если сравнивать расстояние между ними с расстоянием от Москвы до Солнца, и «далекими», если рассматривать два объекта, находящихся в пределах Садового кольца. Именно поэтому при вычислении меры похожести двух объектов оправданным является рассмотрение конкурентной ситуации. Например, в правиле ближайшего соседа (kNN) решение о принадлежности объекта z к первому образу принимается не в том случае, когда расстояние r1 до этого образа «мало», а когда оно меньше расстояния r2 до ближайшего конкурирующего образа.
Таким образом, для адекватной оценки меры похожести объекта z на первый образ, нужно знать расстояние не только до этого образа, но и до ближайшего конкурента, и сравнивать эти величины. В данной работе в качестве меры конкурентного сходства, измеренной в абсолютной шкале, будет использоваться нормированная величина:
F1/2 = (r2-r1)/(r2+r1). (2.1)
Именно ее мы называем функцией конкурентного сходства или FRiS-функцией (от Function of Rival Similarity).
Предложенная функция конкурентного сходства хорошо согласуется с механизмами восприятия сходства и различия, которыми пользуется человек. Значения этой функции меняются в пределах от +1 до -1. Если контрольный объект z совпадает с эталоном первого образа, то r1=0 и F1/2 =1, а F2/1 = -1. Это говорит об абсолютном сходстве объекта z с эталоном первого образа и о максимальном его отличии от эталона второго образа. При расстояниях r1=r2 значения F1/2 = F2/1 = 0, что указывает на границу между образами.
Теперь дадим более строгое определение FRiS-функции для произвольного числа классов k. Рассмотрим обучающую выборку А, состоящую из M объектов, описанных множеством из N признаков. Все объекты разделены на k классов. Каждый класс τ описывается набором из lt эталонных образцов (столпов) ![]() . Соответственно, вся обучающая выборка А описывается набором столпов
. Соответственно, вся обучающая выборка А описывается набором столпов  . В общем случае Sτ может состоять как из реальных объектов выборки A так и из искусственно сгенерированных эталонов классов. Мы будем рассматривать только случай SτÍA. Для объекта a из обучающей выборки A, относящегося к классу τ определим r1(a,S)=
. В общем случае Sτ может состоять как из реальных объектов выборки A так и из искусственно сгенерированных эталонов классов. Мы будем рассматривать только случай SτÍA. Для объекта a из обучающей выборки A, относящегося к классу τ определим r1(a,S)=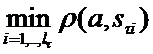 – расстояние до ближайшего столпа «своего» образа, а r2(a,S)=
– расстояние до ближайшего столпа «своего» образа, а r2(a,S)=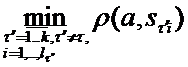 – расстояние до ближайшего столпа образа-конкурента. Тогда функция конкурентного сходства объекта a со своим классом по аналогии с (2.1) вычисляется по формуле:
– расстояние до ближайшего столпа образа-конкурента. Тогда функция конкурентного сходства объекта a со своим классом по аналогии с (2.1) вычисляется по формуле:
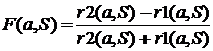
Если мы найдем среднее значение FRiS-функции при фиксированном наборе столпов S по всей выборке, то полученная величина:
=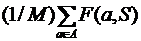 (2.2)
(2.2)
характеризует, насколько полно этот набора столпов описывает выборку. Чем ближе значение к единице, тем более подробное и точное описание выборки у нас имеется.
2.2. Реальная и случайная информативность в задаче DX
Задача комбинированного типа DX решается в области распознавания образов довольно давно. Однако статистически обоснованные методы разработаны лишь для класса «хороших» задач. В случае же их использования для задач, в которых число объектов невелико и меньше числа описывающих признаков, не существует однозначного ответа на вопрос, насколько выбранные подсистемы окажутся эффективными при распознавании контрольной выборки. Еще в 1933 году опубликовал работу [18], в которой обратил внимание на трудности, связанные с решением проблемы выбора подмножества информативных предикторов при построении регрессионных уравнений для случая, когда количество потенциальных предикторов сравнимо или превышает количество наблюдаемых объектов. Действительно, с ростом числа описывающих характеристик при фиксированном числе объектов, для которых эти характеристики измерены, повышается вероятность возникновения псевдозависимостей между частью этих характеристик и целевым признаком, выполняющихся только на обучающей выборке. В результате, в искомую систему могут попасть шумящие, неинформативные признаки, что приведет к серьезным ошибкам при распознавании контрольной выборки.
Аналогичные проблемы возникают и при решении задачи DX, SX и других задач, связанных с выбором информативной подсистемы признаков для каких бы то ни было целей. Особенно актуальной становится эта проблема в связи с появлением большого числа плохо обусловленных задач, например в генетике, где число признаков (десятки тысяч) на порядки больше числа анализируемых объектов (десятки). В следующих параграфах рассматривается эффект «псевдоинформативности» в задаче DX и предлагаются варианты снижения его влияния.
2.2.1. Эффект «псевдоинформативности» в задаче DX
В качестве наглядной иллюстрации эффекта «псевдоинформативности» рассмотрим реальную задачу из генетики, в которой требовалось построить решающее правило, позволяющее отличить образ «здоровых людей» от образа «раковых больных» [63]. В ней исходные данные представляли собой таблицу из 74 объектов (50 здоровых и 24 больных пациентов) и 822 генетических признаков. Была проверена индивидуальная информативность каждого признака в отдельности и всех пар признаков, и затем было выбрано 100 самых информативных признаков и 100 самых информативных пар признаков. В качестве меры информативности системы признаков использовалась доля правильно распознанных объектов U в этой системе признаков, оцениваемая в процессе скользящего экзамена (методом One-Leave-Out). Суть этого метода заключается в том, что каждый объект поочередно исключается из обучающей выборки и распознается с опорой на оставшиеся объекты. В качестве решающего правила в данной серии экспериментов применялось правило ближайшего соседа. Количество ошибок при распознавании 74 объектов обучающей выборки по каждому из 100 отдельных признаков изменялось от 16 до 26. Ошибки для каждой из 100 лучших пар признаков были в пределах от 9 до 14.
Чтобы оценить, насколько обнаруженные признаки реально информативны (содержат информацию, способную восстановит значение целевого признака), аналогичный эксперимент был повторен для сгенерированной случайной таблицы (все описывающие признаки были равномерно распределены и не коррелированны с целевым) размера 74x822, объекты в которой были случайно разделены на два образа - с 50 и 24 объектами. Оказалось, что в этой таблице нашлось 100 самых информативных признаков, которые распознают выборку с такими же ошибками - от 16 до лучших пар случайных признаков дали несколько иной результат – от 10 до 16 ошибок. На Рис. 2.1 показана надежность распознавания случайных и реальных объектов по 100 лучшим отдельным признакам случайной и реальной таблиц (ряд 1), а также по 100 лучшим отдельным парам признаков случайной таблицы (ряд 2) и реальной таблицы (ряд 3).
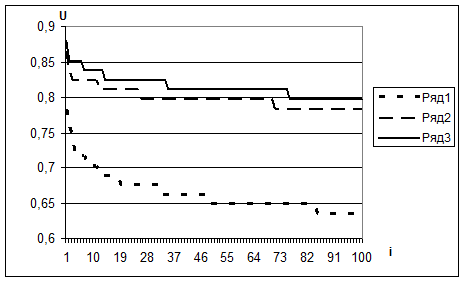
Рис. 2.1. Надежность распознавания обучающей выборки по случайным и реальным данным.
Таким образом, стало очевидно, что построенные при решении этой задачи системы признаков с большой степенью вероятности могла состоять из неинформативных «шумящих» признаков. Малый объем выборки не позволяет разделить ее на обучающую и контрольную, и проверить качество получаемых систем признаков на независимых данных. Целью наших дальнейших исследований стал более детальный анализ эффекта «псевдоинформативности» и поиск способов борьбы с ним [67].
Из этих результатов видно, что при большом количестве признаков N и малом числе объектов M в число наиболее информативных могут попадать с большой вероятностью случайные шумящие признаки. Ясно, что эта вероятность будет увеличиваться с ростом размерности выбираемого подпространства n (n<N) и снижением отношения числа объектов M к размерности исходного пространства N. Для оценки характера связи между вероятностью обнаружения «псевдозависимостей» и параметрами N, M и n было проделанно несколько серий машинных экспериментов со случайными таблицами разных размеров.
В первой из них размерность исходного пространства признаков N оставалась неизменной (N=2000) и значения всех признаков подчинялись равномерному закону. Менялось лишь число объектов M в выборке, последовательно принимая значения M=75, 100 и 150. В сгенерированных в соответствии с этими условиями выборках все объекты случайным образом делились на два класса (по 50% объектов в каждом классе). Таким способом обеспечивалось отсутствие каких бы то ни было закономерных связей между описывающими и целевым признаками. Затем для этих задач алгоритмом AdDel [15] отыскивались системы «информативных» признаков, призванные обеспечить максимально высокое качество распознавания. В качестве критерия информативности здесь, как и в первом эксперименте использовалась доля правильно распознанных объектов U, оцениваемая в режиме скользящего экзамена. Размерность n найденных подсистем признаков варьировалась от 1 до 22. Усредненные по 10 экспериментам для каждого значения M результаты представлены на Рис. 2.2. Здесь по оси абсцисс откладывается размерность n выбранной подсистемы, а по оси ординат ее качество U. Три кривым соответствуют исходным таблицам данных с параметрами N=2000, M=75 (обозначаемые 75х2000), M=100 (обозначаемые 100х2000), M=150 (обозначаемые 150х2000).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
