

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
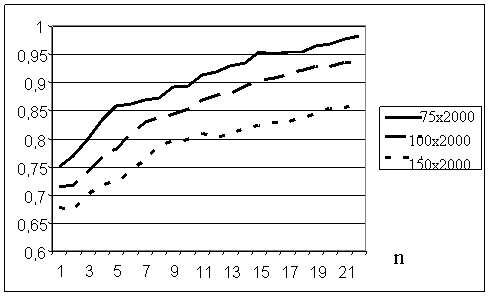

Рис. 2.2. Зависимость информативности подпространства признаков от количества объектов в выборке при случайной обучающей выборке.
В аналогичных экспериментах оценивалось влияние размерности исходного пространства N на величину информативности получаемых псевдоинформативных подсистем разной размерности n исходного пространства и при числе объектов M=75. Результаты их представлены на Рис. 2.3. Как и в предыдущем случае по оси абсцисс откладывается размерность n выбранной подсистемы, а по оси ординат их качество U. Кривые качества соответствуют размерностям задачи M=75, N=2000 (обозначена на графике 75x2000), M=75, N=500 (обозначена на графике 75x500), M=75, N=100 (обозначена на графике 75x100), M=75, N=25 (обозначена на графике 75x25), M=75, N=10 (обозначена на графике 75x10).
Полученные результаты подтверждают естественное предположение о том, что вероятность обнаружения псевдоинформативных подсистем признаков тем больше, чем больше отношение N/M размерности пространства к объему выборки. Кроме того, становится очевидным, что надежность распознавания, оцениваемая скользящим экзаменом, в подобных задачах оказывается статистически неустойчивой. Для некоторых подсистем признаков на этапе обучения она достигает единицы, однако, очевидно, что реальная надежность правила ближайшего соседа для данной сгенерированной задачи составляет 0.5.
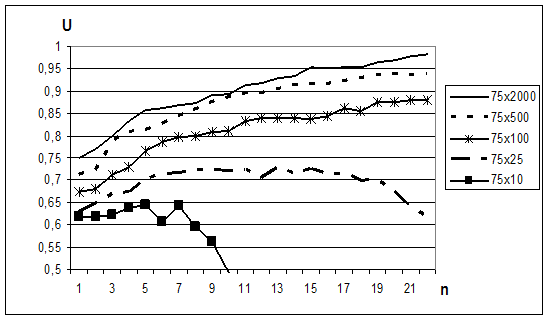
Рис. 2.3. Зависимость информативности подпространства признаков от размерности исходного пространства при случайной обучающей выборке.
Обратим теперь внимание на следующий вопрос: какой критерий информативности признака наиболее эффективно будет защищать нас от случайного выбора?
2.2.2. Сравнение критериев информативности
В описанных выше экспериментах, как и в большинстве существующих методов, оценкой информативности подсистем на этапе обучения служила доля U правильно распознанных объектов обучающей выборки в режиме скользящего экзамена. Теперь в качестве оценки информативности рассмотрим среднее значение функции конкурентного сходства, вычисленное по формуле (2.2) для случая, когда все объекты выборки считаются ее столпами (когда в качестве r1 берется расстояние до ближайшего объекта «своего» образа, а в качестве r2 – расстояние до ближайшего объекта из образа «конкурента»). Эта величина, обозначаемая далее за FS, позволяет оценить, насколько отделены друг от друга образы в пространстве описывающих признаков. Действительно, проведенный анализ поведения функции конкурентного сходства в разных подсистемах, которые обеспечивают одинаковое число ошибок на обучающей выборке, показал, что они могут существенно различаться значениями этой функции F у всех M объектов обучающей выборки. Те объекты, которые располагаются в тесном окружении своих объектов и значительно удалены от объектов других образов, имеют более высокое значение функции F, чем периферийные объекты, близкие к другим образам. Следовательно, по величине F, которую получает контрольный объект z, включаемый в тот или иной образ, можно судить о правильности такого решения. Соответственно, если просуммировать значения F по всем объектам, то полученная величина будет характеризовать среднюю удаленность объектов обучающей выборки от граничных линий, на которых F=0. Оказалось, что подсистемы, дававшие наименьшее число ошибок, не всегда имели наибольшее значение величины Fs.
Еще один критерий Q, который предположительно позволяет выбирать информативные подсистемы признаков, вытекает из предложения Фишера [10] оценивать информативность признаковых систем по величине, пропорциональной квадрату расстояний между математическими ожиданиями образов m1 и m2, деленному на сумму их дисперсий ![]() и
и ![]() :
:
![]() .
.
В качестве оценочного значения математического ожидания образа использовались координаты центра тяжести его объектов, а в качестве дисперсий – средний квадрат расстояний от объектов образа до его центра тяжести.
Четвертая из рассматриваемых нами мер информативности интересна тем, что в ней, также как и в функции конкурентного сходства, для вычисления информативности признакового подпространства используются расстояния от каждого объекта a обучающей выборки до ближайшего «своего» r1(а) и ближайшего «конкурента» r2(а) в этом подпространстве. Этот метод вычисления информативности используется в семействе алгоритмов RELIEF [53] и часто упоминается в англоязычных источниках. Непосредственно критерий информативности признаков (W) выглядит следующим образом:
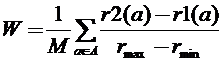 .
.
В нем, как и в случае FRiS-функций, в числителе располагается разница расстояний до ближайшего конкурента и ближайшего своего. А для формирования нормировочного коэффициента в знаменателе используется минимальное расстояние rmin между объектами выборки в анализируемом подпространстве и соответствующее максимальное расстояние rmax между объектов выборки.
Эти четыре критерия информативности – доля правильно распознанных объектов обучающей выборки U, среднее значение функции конкурентного сходства Fs, критерий Фишера Q и RELIEF критерий W- сравнивались в следующей серии экспериментов. Исходные данные каждой модельной задачи содержали информацию о 200 объектах двух образов (по 100 объектов каждого образа), описанных в 100-мерном пространстве. Признаки генерировались так, чтобы около 30 из них были в той или иной степени информативными (имелась закономерная связь между ними и целевым признаком). Остальные же генерировались датчиком случайных чисел и были заведомо неинформативными. На полученной таблице алгоритмом AdDel выбирались наиболее информативные подсистемы размерности n (от 1 до 22). При этом для обучения бралось по 35 объектов каждого образа. На контроль предъявлялись остальные 130 объектов.
Надежность распознавания P контрольной выборки в зависимости от размерности выбранной подсистемы признаков при использовании критериев U, Fs, Q и W, усредненная по 40 независимым экспериментам, показана на Рис. 2.4. Из него видно, что признаки, выбранные по критерию Q и W, лучше выбранных по критерию ошибок U, но хуже выбранных по функции принадлежности FS . Это можно объяснить тем, что меры W, Q и FS меньше зависят от характеристик отдельных пограничных объектов, чем мера U. В свою очередь, мера Фишера Q ориентирована на разделение нормальных распределений с помощью линейных решающих функций, в то время, как мера FS адаптируется к особенностям распределения обучающей выборки и соответствует более мощной кусочно-линейной разделяющей границе. А в критерии W в отличии от критерия FS более грубая нормировка не позволяет приспособиться к каждой конкретной ситуации.
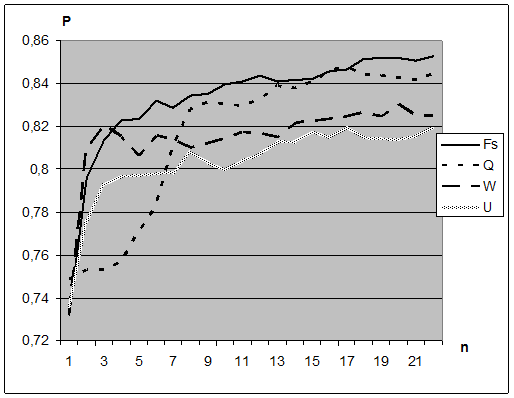
Рис. 2.4. Результаты выбора подсистем признаков при использовании четырех критериев информативности.
В другом эксперименте критерии U и Fs исследовались на устойчивость к помехам. Для этого исходная серия задач (таблиц), сформированная в процессе предыдущего эксперимента, искажалась нормальными шумами разной интенсивности и при каждом уровне шума (дисперсия которого менялась от 0,05 до 0,3) выбирались наилучшие подсистемы по этим критериям. Для каждого уровня шума было проделано по 10 экспериментов, усредненные результаты которых представлены на Рис. 2.5. По оси абсцисс идет нарастание уровня зашумленности выборки, по оси ординат – доля правильно распознанных объектов выборки в выбранном информативном подпространстве. При этом жирными линиями изображены графики надежности выбранных подсистем на контроле, тонкими – на обучении.
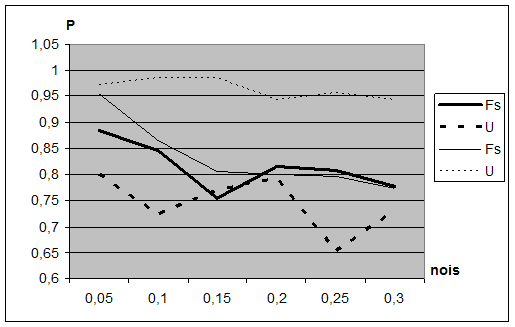
Рис. 2.5. Результаты обучения и распознавания по критериям U и Fs при разных уровнях шумов. Тонкие линии – обучение, жирные – контроль.
Нетрудно заметить, что критерий, основанный на FRiS-функции, Fs более устойчив, чем критерий U. Результаты на контроле показывают высокую степень корреляции критерия Fs с результатами, полученными на обучении. Это также свидетельствует высоких прогностических свойствах этого критерия.
2.2.3. Оценка «неслучайности» выбранных подсистем
Итак, в предыдущих параграфах было установлено, что критерий информативности, основанный на функции конкурентного сходства, позволяет лучше бороться с эффектом «псевдоинформативности» и строить более устойчивые решения, чем прочие критерии. Однако, исследователя, решающего конкретные задачи, интересует не только то, насколько один метод лучше другого, одна выбранная система информативнее другой. Не менее важным оказывается ответ на вопрос, насколько выбранной системе можно доверять (не доверять) в целом. Ведь каким эффективным бы ни был метод, он не может выбрать реально информативную подсистему в задаче, где все признаки случайны.
Для контроля получаемых результатов вне зависимости от используемого критерия выбора признаков имеет смысл сравнивать их с результатами работы того же алгоритма на случайных таблицах. Если информативность систем, выбранных на случайной таблице, окажется сравнимой с результатами, полученными на реальных данных, то уровень доверия к подобным результатам резко падает.
Данная методика работает не всегда. Например, если в качестве критерия информативности использовать долю правильно распознанных объектов U, то во многих задачах даже на случайных подсистемах эта величина может достигать своего максимума, что делает всякое сравнение бессмысленным. Однако, благодаря устойчивости FRiS-функции максимальные значения Fs, достигаемые на случайных данных, оказываются относительно невелики. Поэтому среднее значение FRiS-функции может быть использовано для оценки реальной информативности найденной системы таким способом. Более подробно эта процедура описана ниже:
1. Определяется значение Fs для наилучшей подсистемы Y*, состоящей
из n* признаков, выбранных по обучающей таблице N´M.
2. Формируется серия случайных таблиц с такими же значениями N и M и теми же законами распределения признаков. Для этого значения каждого признака внутри выборки перемешивается случайным образом.
3. По всем таким таблицам находится диапазон изменений значения [min_Fs, max_Fs] для «лучших» подсистем той же размерности n* в «худшем» случае, соответствующем полному отсутствию закономерных связей между признаками.
4. Если величина Fs для исходной таблицы попадает в пределы значений [min_Fs, max_Fs] для случайных таблиц, то можно считать, что выбранные признаки Y* «псевдоинформативны». Они не отражают закономерных связей с целевой характеристикой. Доверяться решениям, которые будут получены по этим подсистемам на контрольной выборке, нельзя.
Кроме того, по расстоянию между значением критерия Fs подсистемы, выбранной по реальной таблице, и границами «случайного коридора», полученного на наборе случайных таблиц того же размера, можно судить о «неслучайности» выбранных подсистем.
Для иллюстрации эффективности этой методики посмотрим, как располагаются значения ![]() относительно «случайного коридора» для задач, искаженных шумами разно степени интенсивности. На Рис. 2.6 изображены результаты для двух задач – с низким уровнем шумов и высоким. В случае высокого уровня шумов и, как следствие, ослабления связей между признаками, значения функции конкурентного сходства для выбранных «информативных» подсистем, изображенные жирной линией, оказались в рамках «случайного коридора», обозначенного пунктиром. Это свидетельствует о изначальной некорректности задачи и невозможности обнаружить закономерные связи и построить адекватное решающее правило. При низком уровне шумов эти значения располагались значительно выше, что подтверждает высокую реальную информативность систем признаков, полученных при решении этой задачи.
относительно «случайного коридора» для задач, искаженных шумами разно степени интенсивности. На Рис. 2.6 изображены результаты для двух задач – с низким уровнем шумов и высоким. В случае высокого уровня шумов и, как следствие, ослабления связей между признаками, значения функции конкурентного сходства для выбранных «информативных» подсистем, изображенные жирной линией, оказались в рамках «случайного коридора», обозначенного пунктиром. Это свидетельствует о изначальной некорректности задачи и невозможности обнаружить закономерные связи и построить адекватное решающее правило. При низком уровне шумов эти значения располагались значительно выше, что подтверждает высокую реальную информативность систем признаков, полученных при решении этой задачи.
Предложенная методика является одним из вариантов решения проблемы Колмогорова [75].
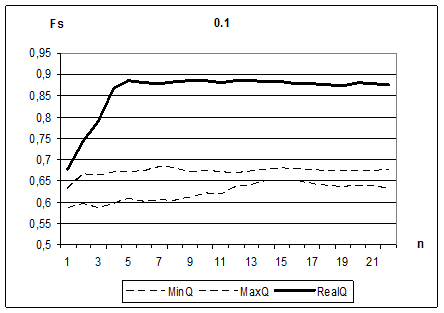
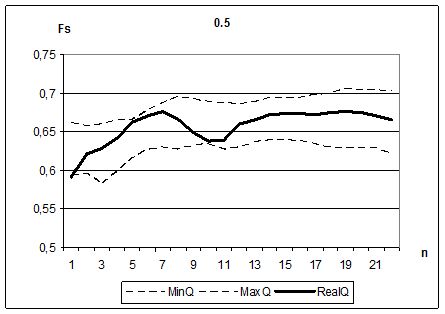
Рис. 2.6. Определение степени доверия к построенным системам признаков, для задач с разными уровнями шума (низкий – сверху, высокий – снизу).
2.2.4. Проверка на реальных данных
Для подтверждения преимуществ критерия Fs перед критерием U на реальных задачах был проведен эксперимент со спектральными данными. Обучающая выборка состояла из двух образов по 25 объектов, выбранных случайно из таблицы реальных спектральных данных двух классов веществ. Из исходного множества 1024 спектральных характеристик формировались два списка из 46 наиболее информативных «вторичных» признаков в виде неперекрывающихся участков спектра. Один список включал в свой состав признаки, отобранные по критерию U , а второй – по критерию Fs. Затем всем n признакам каждого списка в отдельности предъявлялись для распознавания 200 контрольных объектов (по 100 объектов каждого образа). Надежность распознавания по каждому из 46 наиболее информативных признаков представлена на рис. 2.7. Верхняя кривая соответствует выбору по критерию Fs, нижняя – по U.
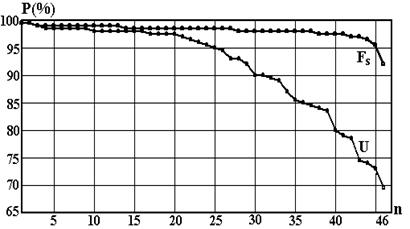
Рис. 2.7. Надежность P распознавания контрольной выборки по каждому из 46 наиболее информативных признаков, упорядоченных по информативности.
Эти результаты также подтверждают преимущество выбора признаков по среднему значению функции принадлежности Fs по сравнению с широко распространенным выбором по числу правильно распознанных объектов обучающей выборки U.
2.3. Целесообразность и эффективность применения аппарата FRiS-функций в задаче DX
В экспериментах, описанных выше, было установлено, что с помощью FRiS функций удается выбирать подсистемы признаков, которые обеспечивают лучшее качество распознавания контрольной выборки, по сравнению с системами, выбранными с помощью других критериев информативности. Этот раздел будет посвящен анализу того, насколько применение функций конкурентного сходства позволяет улучшить качество распознавания выборки в задаче DX. Другими словами, основное внимание здесь будет уделено описанию алгоритма построения решающего правила, основанного на использовании FRiS-функции и проверке того, насколько он оказывается эффективным в сочетании с методом выбора признаков, так же основанном на использовании FRiS-функций.
2.3.1 Построение решающего правила алгоритмом FRiS-Stolp
В экспериментах, описанных выше, для распознавания использовалось самое простое решающее правило – правило ближайшего соседа. При этом все объекты обучающей выборки признавались существенными для распознавания, и близость к любому из них могла стать определяющей при принятии решения о принадлежности нового объекта к тому или иному образу. Однако, для более быстрого и надежного принятия решений в некоторых задачах бывает целесообразно перейти от рассмотрения всего множества объектов обучающей выборки к некоторому его представительному подмножеству. Для этого из обучающей выборки в каждом из образов необходимо выбрать набор объектов-эталонов (столпов), находящихся в зонах сгущения этого образа, сходство с которыми и будет затем использоваться для распознавания контрольных объектов.
Идея выделения объектов выборки, информативных для последующего распознавания, не нова. Она, к примеру, реализуется и в известном методе SVM [35], и одной из его модификаций - алгоритме STOLP [15]. Однако, в качестве опорных векторов (аналога столпов) эти алгоритмы выбирают объекты с наиболее высоким индивидуальным риском быть неправильно распознанными. Такие столпы обычно располагаются в области пересечения образов и защищают самих себя. Тот факт, что они могут использоваться в качестве эталонов при распознавании других объектов обучающей выборки, является, по существу, побочным. Сколько объектов защищает данный опорный вектор, и хорошо ли он их защищает, никак не влияет на процесс выбора опорных векторов. Поэтому для поставленной нами задачи - выбирать столпы из наиболее представительных объектов образов, располагающихся в зонах с высоким содержанием объектов этого образа - такой подход оказывается неприменимым. Требуется новый алгоритм выбора столпов, который выдавал бы решения, адаптированные к ситуации. Например, если распределения унимодальны, столпы должны располагаться в центрах тяжести образов. Если распределения полимодальны и образы линейно не разделимы, столпы должны стоять в центрах мод. С ростом сложности распределения число столпов k будет увеличиваться.
Алгоритм FRiS-Stolp [70], использующий в процессе работы функции конкурентного сходства, обладает именно такими свойствами. Он нацелен на выбор минимального числа столпов, которые защищают не только самих себя, но обеспечивают заданную надежность защиты всех остальных объектов обучающей выборки. Первыми выбираются столпы, защищающие максимально возможное количество объектов с заданной надежностью. По этой причине при нормальных распределениях в первую очередь будут выбраны столпы, расположенные в точках математического ожидания.
Решающее правило d, создаваемое алгоритмом FRiS-Stolps, реализуется набором столпов 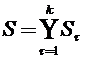 , где
, где 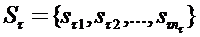 - подмножество столпов, являющихся эталонами для образа τ. Величина , вычисленная по формуле (2.2) является мерой качества для набора столпов S. Чем больше , тем более подробное и точное описание выборки A у нас имеется, тем больше похожи объекты на «свои» столпы, тем выше надежность решающего правила d. Предлагаемый ниже алгоритм нацелен на максимизацию данной величины при условии, что искомый набор столпов S должен содержать тот минимум столпов, который необходим для безошибочного распознавания всех объектов обучающей выборки.
- подмножество столпов, являющихся эталонами для образа τ. Величина , вычисленная по формуле (2.2) является мерой качества для набора столпов S. Чем больше , тем более подробное и точное описание выборки A у нас имеется, тем больше похожи объекты на «свои» столпы, тем выше надежность решающего правила d. Предлагаемый ниже алгоритм нацелен на максимизацию данной величины при условии, что искомый набор столпов S должен содержать тот минимум столпов, который необходим для безошибочного распознавания всех объектов обучающей выборки.
Опишем этот алгоритм.
1. Решается задача распознавания «первый образ против всех остальных». Проверяется вариант, при котором первый случайно выбранный объект ai является единственным столпом первого образа, а все другие образы в качестве столпов имеют все свои объекты. Для всех объектов aj¹ai первого образа находится расстояние r1j до своего столпа ai и расстояние r2j до ближайшего объекта чужого образа. По этим расстояниям вычисляется значение FRiS-функции для каждого объекта aj первого образа. Находим те mi объектов первого образа, для которых значение функций конкурентного сходства F, вычисленное по формуле (2.1), выше заданного порога F*, например, F*=0. По этим mi объектам вычисляем суммарное значение FRiS-функции Fi, которое характеризует пригодность объекта ai на роль столпа.
2. Аналогичную процедуру повторяем, назначая в качестве столпа все М объектов первого образа по очереди.
3. Находим объект ai с максимальным значением Fi и объявляем его первым столпом s11 первого кластера A11 первого образа.
4. Исключаем из первого образа mi объектов, входящих в первый кластер.
5. Для остальных объектов первого образа находим следующего столпа повторением пп 1- 4.
6. Процесс останавливается, если все объекты первого образа оказались включенными в свои кластеры.
7. Восстанавливаем все объекты первого образа.
8. Повторяем пп.1-7 для всех остальных образов.
На этом шаге заканчивается первый этап поиска столпов. Каждый столп sij защищает подмножество объектов mij своего кластера Aij i-го образа. Однако столпы были выбраны в условиях, когда им противостояли все объекты конкурирующих образов. Теперь образы представлены только своими столпами. Возможно, что в этих новых условиях некоторые (периферийные в своем кластере) объекты получили бы большее значение F, если бы у них была возможность присоединиться не к первому, а к одному из последующих столпов. Предоставим объектам такую возможность. Для этого восстанавливаем все объекты обучающей выборки и распознаем их принадлежность к кластерам в условиях, когда функция принадлежности определяется по нормированным расстояниям до ближайшего своего и ближайшего чужого столпов.
Если состав некоторого кластера Aij изменился, то среди его объектов нужно повторить поиск объекта, назначение которого столпом обеспечит максимум среднего значения функции конкурентного сходства F, как это делалось в п.1. Отличие будет состоять в том, что в соревновании участвуют только объекты этого кластера, и кандидат в столпы будет конкурировать со столпами чужих образов.
После завершения всех этих процедур вычисляется среднее значение функций конкурентного сходства всех объектов обучающей выборки со своими столпами. Эта величина может служить мерой качества обучения.
Процесс распознавания контрольных объектов по решающему правилу d, соответствующему выбранной системе столпов S, очень прост. Решение принимается в пользу образа, функция конкурентного сходства объекта с которым оказывается максимальной. Тот же результат распознавания мы получили бы, если бы принимали решение в пользу образа, расстояние до столпа которого оказалось минимальным. Но величина F оказалась полезной для того, чтобы получить ответ на простой и важный вопрос: «Если некоторый объект z распознан в качестве представителя образа i, то какова достоверность этого конкретного решения?»
2.3.2. Оценка надежности распознавания конкретных объектов
Для некоторых алгоритмов распознавания существуют методики оценки надежности построенного решающего правила и средней ожидаемой ошибки распознавания при его использовании. Методики же, позволяющие рассчитать надежность распознавания для конкретных объектов в случае выборок, подчиняющихся неизвестным законам распределения, в настоящее время, практически, не существует. Да и далеко не все подходы к построению решающих правил, особенно в классе эмпирических, принципиально позволяют это делать. Одним из преимуществ FRiS-функций и решающих правил, основанных на их использовании, является возможность создавать методики оценки надежности распознавания индивидуальных объектов. Это обеспечивается наличием статистически значимой связи между значением функции конкурентного сходства, вычисленной для конкретного объекта, и надежностью его распознавания (вероятностью правильного распознавания). Для выявления характера этой связи использовалась серия модельных и нескольких реальных задач. В каждой из них методом Cross Validation восстанавливалась зависимость G между величиной FRiS-функции для произвольного объекта a (обозначим ее через Fa) и вероятностью ошибочного распознавания этого объекта (обозначаемой через Era). Для этого выполнялась следующая процедура:
1. Исходная обучающая выборка А случайным образом делилась на две равномощные подвыборки: Ast и Acn. На объектах из Ast алгоритмом FRiS-Stolp строился набор столпов, по которым распознавались объекты из Acn. Для каждого объекта ai из Acn фиксировался результат распознавания («правильно»-«ошибка») и величина Fai для него.
2. Шаг 1 повторялся до тех пор, пока не была набрана достаточная статистика для определения доли ошибочно распознанных объектов для небольших диапазонов изменения FRiS-функции.
3. Интервал изменения значений функции конкурентного сходства для контрольных объектов [0,1] делился на равные по длине подинтервалы [0,F1)È[F1,F2)È…È[Fn-1,1] и все объекты для которых был известен и результат распознавания и величина FRiS-функции распределялись между ними. Объект a относился к интервалу i, если FaÎ[Fi-1,Fi). Для каждого интервала вычислялась доля Eri ошибочно распознанных объектов относительно общего числа объектов, попавших в него. Полученная в результате кусочно-линейная функция и была использована в качестве оценки зависимости G между величиной FRiS-функции Fa и вероятностью ошибочного распознавания Era.
Недостатком данной методики является то, что в случае использования равномерной сетки (Fi+1-Fi=1/n) количество объектов в разных подинтервалах может сильно различаться. Например, в случае пересекающихся и близко располагающихся образов наибольшая статистика набирается для величин FRiS-функции близких к 0, и лишь у незначительной части объектов значение FRiS-функции оказывается больше 0.5. Поэтому статистическая обоснованность и, соответственно, степень доверия к величинам Eri при разных i может сильно разниться. С этим можно бороться, используя неравномерные сетки и располагая узловые точки таким образом, чтобы в каждый интервал попадало равное количество объектов. Но даже в случае равномерных сеток эффект недостаточной надежности оценок на некоторых интервалах оказывается несущественным для практических целей. Характер распределения объектов по подинтервалам в зависимости от величины функции конкурентного сходства сохраняется при переходе от обучающей выборки к контрольной. Поэтому большинство объектов попадут именно в те интервалы изменения значений FRiS-функции, для которых собрана достаточная статистика и оценки надежности точны.
Далее описывается серия экспериментов, призванная установить, насколько зависимость G универсальна для разного рода задач. На Рис. 2.8 приводится вид зависимостей G для серии задач, имеющих сходную природу (два образа представлены унимодальными распределениями), но отличающихся друг от друга средней ошибкой распознавания (что достигается изменением расстояния между центрами мод конкурирующих образов при фиксированных матрицах ковариаций). Величина средней ошибки для каждой задачи указана в качестве имени кривой, соответствующей ей на графике.
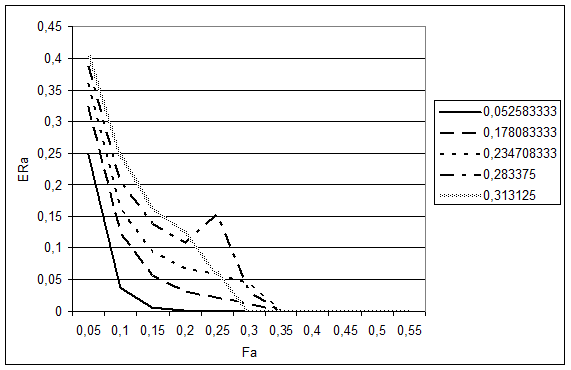
Рис. 2.8. Виды зависимости G между величиной FRiS-функции Fa и вероятностью ошибочного распознавания Era объекта а для серии задач.
Так как с увеличением значения Fa надежность построенной зависимости понижается, в правой части графиков могут появляться случайные всплески, пики, интерес же представляют в первую очередь их левые части, где построенная зависимость статистически надежна. Нетрудно заметить, что с учетом погрешностей приближения, все эти кривые имеют похожую форму. При этом, чем выше средняя ошибка распознавания для задачи, тем выше поднимается график зависимости G для нее, относительно остальных задач.
В следующем эксперименте, результаты которого представлены на Рис. 2.9, были вычислены аналогичные зависимости для двух задач с одинаковой средней ошибкой распознавания, но имеющие разную природу. Одна из них - модельная, с унимодальными распределениями, отмеченная на графике меткой gen. Другая - реальная, являющая собой набор плохо обусловленных данных с неизвестными законами распределений - отмечена на графике меткой spec.
На графике видно, что хотя и эти зависимости также имеют сходную динамику, но точного совпадения нет. И хотя средняя надежность распознавания одинакова, объектов с высокими значениями FRiS-функции в реальной задаче больше.
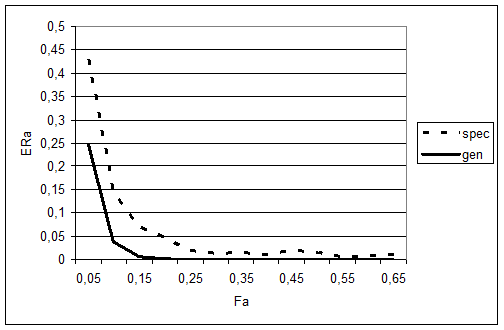
Рис. 2.9. Вид зависимости G между величиной FRiS-функции Fa и вероятностью ошибочного распознавания Era объекта а для двух задач различной природы.
Таким образом, единой универсальной зависимости между значением функции конкурентного сходства объекта и ожидаемой надежностью его распознавания построить не удалось. Однако далее будет предложена методика построения этой зависимости для каждой конкретной задачи, проиллюстрированная на примере конкретной прикладной плохо обусловленной реальной задачи из области геологии.
Исходная выборка А, в этой задаче состояла из 600 объектов в 1024-мерном пространстве, принадлежащих двум классам (по 300 объектов в классе). Для оценки применимости методики выборка делилась на обучающую A1 (по 100 объектов на класс) и контрольную A2 (по 200 объектов на класс). Методом Cross Validation на обучающей выборке A1 оценивалась средняя величина ошибки распознавания Ers, а также строилась зависимость G1 между величиной FRiS-функции Fa и вероятностью ошибочного распознавания Era для произвольного объекта a. Затем по обучающей выборке A1 алгоритмом FRiS-Stolp строился набор столпов, по которым распознавалась вся контрольная выборка A2. Для объектов контрольной выборки строился более грубый аналог этой зависимости G2 доли ошибок Er при разных значения FRiS-функций F.
На Рис. 2.10 приводится сравнение этой зависимости G2, которую можно рассматривать как реально существующую, c зависимостью G1, восстановленной на основе достаточно небольшой обучающей выборки, состоящей из 200 объектов. Чем более похожи эти кривые, тем более точными являются наши прогнозы надежности распознавания.
Также для сравнения на Рис. 2.10 приводится величина aver_err, которая в качестве оценки вероятности ошибочного распознавания объекта использует величину средней вероятности ошибки Ers, вычисленной методом Cross Validation.
Чтобы получить количественные характеристики надежности построенной зависимости G1 для предсказания вероятности ошибочного распознавания объектов контрольной выборки, можно использовать следующую величину:
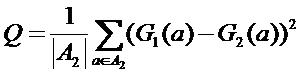 .
.
Чем меньше эта величина, тем ближе построенная при обучении зависимость к контрольной. В описываемом эксперименте Q(G1)=5,28. Для сравнения качество Q(aver_error)=15,18, то есть практически в три раза хуже.
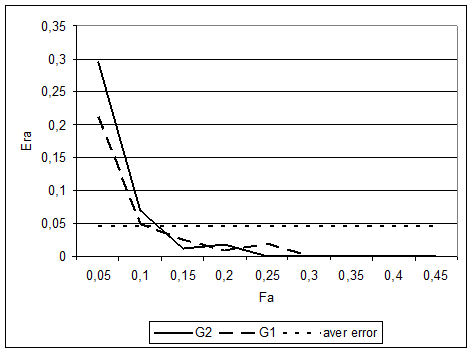
Рис. 2.10. Сравнение зависимости G1, построенной на обучающей выборке с аналогичной зависимостью G2, построенной на контрольной выборке.
Таким образом, показано, что построенная на обучающей выборке зависимость между Fa и Era с высокой надежностью прогнозирует вероятность ошибочного распознавания конкретных объектов контрольной выборки и эти оценки намного точнее, чем оценки «в среднем» по всей выборке. Это еще один довод в пользу использования FRiS-функции в процессе решения задачи построения решающего правила
2.3.3. Алгоритм FRiS-Agent в задаче DX
В начале этой главы нами было продемонстрировано, что функции конкурентного сходства являются эффективным инструментом выбора информативной системы признаков при фиксированном решающем правиле. Также был предложен алгоритм построения решающего правила, основанный на использовании FRiS-функции, и также обладающий рядом преимуществ перед существующими аналогами. Теперь же будет рассматриваться методика решения задачи DX (одновременного выбора системы признаков и построения решающего правила), основанная на использовании FRiS-функций.
Здесь вновь решающее правило представляется в виде набора эталонных объектов образов S, а целью задачи является отыскание такого набора эталонов S* и такого подпространства признаков Y*ÎP(X), чтобы среднее значение функции конкурентного сходства, вычисленное в этом подпространстве с опорой на этот набор столпов, было максимальным. Критерий качества Qfr в формальной постановке задачи в этом случае будет выглядеть следующим образом:
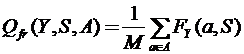 ,
,
где FY(a,S)- величина функции конкурентного сходства объекта а с набором столпов S в подпространстве Y. А сама экстремальная задача выглядит так:
 . (2.3)
. (2.3)
Разложим исходную задачу (2.3) с оптимизацией по двум параметрам на две задачи.
![]() ,
,
где 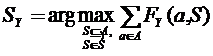
Во второй из них мы в фиксированном пространстве Y строим набор столпов SY минимальной мощности, который обеспечивает нас достаточно полным описанием выборки и позволяет распознавать все обучающие объекты безошибочно.
Алгоритм, отыскивающий приближенные решения этой экстремальной задачи, называется FRiS-Agent и состоит в следующем. С помощью алгоритма AdDel осуществляется направленный поиск системы информативных признаков Y, обеспечивающей максимальное значение среднему значению FRiS-функции, вычисленной с опорой на множество эталонных объектов SY. В свою очередь выбор столпов в фиксированном подпространстве Y осуществляется алгоритмом FRiS-Stolp.
В итоге среднее значение FRiS-функции максимизируется как за счет выбора столпов, так и за счет выбора признаков. Благодаря этому можно предположить, что полученный алгоритм, обеспечит высокое качество распознавания контрольных объектов и окажется лучше существующих альтернатив, в том числе и своего более простого аналога, в котором вычисление FRiS-функции в критерии качества системы признаков осуществляется с опорой на все объекты выборки. Для проверки этой гипотезы, генерировалась серия задач. Каждая из этих задач обладала тем свойством, что количество объектов в обучающей выборке было меньше числа описывающих признаков, и решалась четырьмя разными методами:
1. правило ближайшего соседа (NN),
2. правило ближайшего соседа с выбором информативной системы признаков по критерию минимума ошибок (NN+ U ),

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
