

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Устойчивость к ошибкам
Методы этой группы ставят своей целью обеспечить функционирование программной системы при наличии в ней ошибок. Они разбиваются на три подгруппы: динамическая избыточность, методы отступления и методы изоляции ошибок.
1. Истоки концепции динамической избыточности лежат в проектировании аппаратного обеспечения. Один из подходов к динамической избыточности — метод голосования. Данные обрабатываются Независимо несколькими идентичными устройствами, и результаты сравниваются. Если большинство устройств выработало одинаковый результат, этот результат и считается правильным. И опять, вследствие особой природы ошибок в программном обеспечении ошибка, имеющаяся в копии программного модуля, будет также присутствовать во всех других его копиях, поэтому идея голосования здесь, видимо, неприемлема. Предлагаемый иногда подход к решению этой проблемы состоит в том, чтобы иметь несколько неидентичных копий модуля. Это значит, что все копии выполняют одну и ту же функцию, но либо реализуют различные алгоритмы, либо созданы разными разработчиками. Этот подход бесперспективен по следующим причинам. Часто трудно получить существенно разные версии модуля, выполняющие одинаковые функции. Кроме того, возникает необходимость в дополнительном программном обеспечении для организации выполнения этих версий параллельно или последовательно и сравнения результатов. Это дополнительное программное обеспечение повышает уровень сложности системы, что, конечно, противоречит основной идее предупреждения ошибок — стремиться в первую очередь минимизировать сложность. Второй подход к динамической избыточности — выполнять эти „Запасные копии только тогда, когда результаты, полученные с помощью основной копии, признаны неправильными. Если это происходит, система автоматически вызывает запасную копию. Если и ее результаты неправильны, вызывается другая запасная копия и т. д. Хотя Ранделл [1] дает набросок хорошего метода реализации такого подхода, этот подход страдает большинством перечисленных ранее недостатков. Кроме того, вполне вероятно, что если ресурсы при работе над проектом фиксированы, то при реализации «запасных» версий проектированию и тестированию будет уделено меньше внимания, чем можно было бы уделить, если бы реализовывалась лишь одна копия и динамическая избыточность не использовалась.
2. Вторая подгруппа методов обеспечения устойчивости к ошибкам называется методами отступления или сокращенного обслуживания. Эти методы приемлемы обычно лишь тогда, когда для системы программного обеспечения важно благопристойно закончить работу. Например, если ошибка оказывается в системе, управляющей технологическими процессами, и в результате эта система выходит из строя, то может быть загружен и выполнен особый фрагмент программы, призванный подстраховать систему и обеспечить безаварийное завершение всех управляемых системой процессов. Аналогичные средства часто необходимы в операционных системах. Если операционная система обнаруживает, что она вот-вот выйдет из строя, она может загрузить аварийный фрагмент, ответственный за оповещение пользователей у терминалов о предстоящем сбое и за сохранение всех критических для системы данных.
3. Последняя подгруппа — методы изоляции ошибок. Основная их идея — не дать последствиям ошибки выйти за пределы как можно меньшей части системы программного обеспечения, так чтобы если ошибка возникнет, то не вся система оказалась неработоспособной; отключаются лишь отдельные функции в системе либо некоторые ее пользователи. Например, во многих операционных системах изолируются ошибки отдельных пользователей, так что сбой влияет лишь на некоторое подмножество пользователей, а система в целом продолжает функционировать. В телефонных переключательных системах для восстановления после ошибки, чтобы не рисковать выходом из строя всей системы, просто разрывают телефонную связь. Другие методы изоляции ошибок связаны с защитой каждой из программ в системе от ошибок других программ. Ошибка в прикладной программе, выполняемой под управлением операционной системы, должна оказывать влияние только на эту программу. Она не должна сказываться на операционной системе или других программах, функционирующих в этой системе.
Из этих трех подгрупп методов обеспечения устойчивости к ошибкам только третья, изоляция ошибок, применима для большинства систем программного обеспечения.
Важное обстоятельство, касающееся всех четырех подходов, состоит в том, что обнаружение, исправление ошибок и устойчивость к ошибкам в некотором отношении противоположны методам предупреждения ошибок. В частности, обнаружение, исправление и устойчивость требуют дополнительных функций от самого программного обеспечения. Тем самым не только увеличивается сложность готовой системы, но и появляется возможность внести новые ошибки при реализации этих функций. Как правило, все рассматриваемые методы предупреждения и многие методы обнаружения ошибок применимы к любому программному проекту. Методы исправления ошибок и обеспечения устойчивости применяются не очень широко. Это, однако, зависит от области приложения. Если рассматривается, скажем, система реального времени, то ясно, что она должна сохранить работоспособность и при наличии ошибок, а тогда могут оказаться желательными и методы исправления и обеспечения устойчивости. К системам такого типа относятся телефонные переключательные системы, системы управления технологическими процессами, аэрокосмические и авиационные диспетчерские системы и операционные системы широкого назначения.
Предупреждение ошибок | Обнаружение ошибок | Исправление ошибок | Устойчивость к ошибкам | |
Принципы | Гл. 5,6,8 | Нет | Нет | Нет |
Методы | Гл. 7,8,9 | Гл..7, 8 | Гл. 7 | Гл.7 |
Рис. 3.1. Соответствие между главами и методами обеспечения надежности |
На рис. 3.1 указано соответствие между этими методами и главами книги. Принципы — это не зависимые от области приложения стратегии обеспечения надежности программных систем. Рассматриваются принципы проектирования системы, программы, модуля, направленные на предупреждение ошибок. Для остальных трех категорий принципы неизвестны. Методы — это более мелкие, обычно зависящие от области приложения тактические средства. Главы, в которых обсуждаются методы для всех четырех категорий, указаны на рис. 3.1.
Вопрос № 5. Принципы построения интегрированной среды BC++Builder (ВС++)
Интегрированная среда разработки BC++Builder (IDE) объединяет конструктор форм, инспектор объектов, палитру компонентов, Менеджер проектов и полностью интегрированные редактор кода и отладчик — основные инструменты, обеспечивающие полный контроль над кодом и ресурсами.
После запуска BC++Builder, на экране представлено четыре элемента. Наверху находится главное окно. Оно содержит обычную линейку меню, инструментальную панель (слева) и палитру компонентов (многостраничная панель справа).
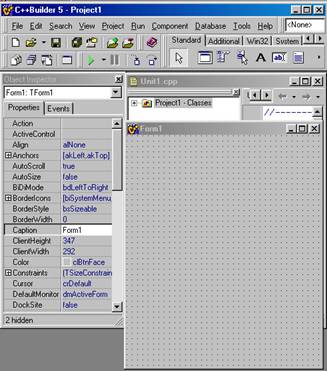
Правее инспектора объектов располагается конструктор форм. При запуске C++Builder конструктор отображает пустую форму. Форма — это центральный элемент визуального программирования. Она может представлять главное окно программы, дочернее окно, диалоговую панель. На ней вы размещаете различные элементы управления, называемые визуальными компонентами. Существуют также и невизуальные компоненты, например, таймеры и компоненты связи с базами данных. В инспекторе объектов вы сопоставляете событиям компонентов написанные вами процедуры обработки. Это, по существу, есть визуальное программирование, базирующееся на компонентной модели.
Наконец, под конструктором форм находится окно редактора кода.
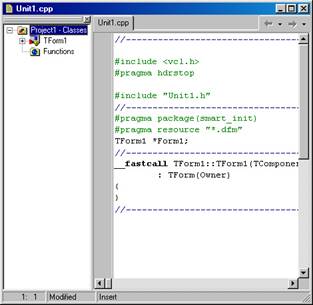
Редактор кода
Окно редактора кода, является основным рабочим инструментом программиста. Его функции не ограничиваются редактированием исходного текста программы.
Практически все инструментальные окна C++Builder являются стыкуемыми окнами. Такая панель может быть плавающей, а может быть состыкована с другим окном в одном из пяти его портов стыковки: либо вдоль какой-либо стороны окна, либо по центру. Если стыковка производится вдоль стороны окна, получается что-нибудь подобное показанному на рис. 2.2. В случае стыковки по центру окно становится многостраничным, с закладками, позволяющими переключаться между страницами.
При первоначальном запуске C++Builder к левой стороне редактора кода пристыковано окно обозревателя классов. Это не просто инструмент просмотра структуры классов т. к. можно использовать его с большой выгодой, поскольку он позволяет автоматически вводить в описание класса новые элементы (функции, данные и свойства).
В редакторе можно открывать сразу несколько файлов исходного кода. При этом он также становится многостраничным окном с закладками. Надписи на закладках отражают имена файлов.
Расширенный Менеджер проектов (Advanced Project Manager) берет на себя рутину управления большими и сложными проектами, объединенными в группы, предоставляя разработчику свободу выбора формата составляющих файлов: CPP, PAS, DLL, LIB, RES и OBJ. Реализована возможность разработки нескольких проектов одновременно: например, одного для исполняемого EXE-кода, а другого — для динамически подгружаемой библиотеки DLL. Таким образом, полнофункциональные результирующие приложения можно получать в более короткие сроки.
Механизмы двунаправленной разработки (Two-Way-Tools) обеспечивают контроль кода посредством гибкого, интегрированного и синхронизированного взаимодействия между инструментами визуального проектирования и Редактором кода.
Конструирование способом “перетаскивания” (drag-and-drop) позволяет создавать приложение простым перетаскиванием захваченных мышью визуальных компонентов — из Палитры на форму приложения. Инспектор объектов предоставляет возможность оперировать свойствами и событиями компонентов, автоматически создавая заготовки функций обработки событий, которые наполняются кодом и редактируются в процессе разработки.
Свойства, методы и события — это именно те элементы языка, которые обеспечивают ускоренную разработку приложений в рамках объектно-ориентированного программирования. Свойства позволяют легко устанавливать разнообразные характеристики компонентов. Методы производят определенные, иногда довольно сложные, операции над объектом. События связывают воздействия пользователя на объекты с кодами реакции на эти воздействия. События возникают при простом нажатии кнопок или в результате таких специфических изменений состояния объектов, как обновление информации в базах данных. Работая совместно, свойства, методы и события образуют среду быстрого и интуитивно понятного программирования для Windows. Чистый и доступный код приложений, который C++Builder строит на основе компонентной модели, исключает скрытые и трудные в отладке макросы.
Испытание прототипа позволяет без труда переходить к полностью функциональному, профессионально оформленному программному продукту, действуя в пределах единой интегрированной среды. Чтобы удостовериться, что программа производит ожидаемые результаты, раньше приходилось многократно проходить по циклу “редактирование — компиляция — компоновка — прогон — отладка”, непроизводительно расходуя время. C++Builder объединяет последовательные этапы разработки в единый производственный процесс. В результате удается строить приложения, базирующиеся на текущих требованиях заказчика, вместе с тем гибкие настолько, чтобы быстро адаптировать их к новым запросам.
Средства интегрированной отладки существенно облегчают этот самый утомительный этап разработки. Особенно трудно “разминировать” распределенные системы (часть логики реализована программой на другом компьютере) и многопоточные приложения (различные ветви выполняются одновременно). Одна мысль, что придется отыскивать ошибки в подобных комплексах, способна заставить программиста не рисковать и придерживаться традиционных подходов при проектировании. Только C++Builder позволяет уверенно использовать современные технологии, предоставляя все необходимое для процесса отладки. Встроенный отладчик низкого уровня View CPU дает возможность проникнуть в специфику работы вашего приложения еще глубже, на уровне ассемблерных команд.
Открытые инструменты API могут быть непосредственно интегрированы в визуальную среду системы. Например, вы сможете подключить привычный текстовый редактор или создать собственного мастера для автоматизации повторяющихся процедур.
Расширенная математическая библиотека содержит дополнительные унифицированные функции статистических и финансовых вычислений.
Вопрос № 6. Динамически распределяемая память (ДРП). Типы организации данных в ДРП (списки).
В традиционных языках программирования, таких как Си, Фортран, Паскаль, существуют три вида памяти: статическая, стековая и динамическая. Конечно, с физической точки зрения никаких различных видов памяти нет: оперативная память - это массив байтов, каждый байт имеет адрес, начиная с нуля. Когда говорится о видах памяти, имеются в виду способы организации работы с ней, включая выделение и освобождение памяти, а также методы доступа.
Статическая память
Статическая память выделяется еще до начала работы программы, на стадии компиляции и сборки. Статические переменные имеют фиксированный адрес, известный до запуска программы и не изменяющийся в процессе ее работы. Статические переменные создаются и инициализируются до входа в функцию main, с которой начинается выполнение программы.
Существует два типа статических переменных:
- глобальные переменные - это переменные, определенные вне функций, в описании которых отсутствует слово static. Обычно описания глобальных переменных, включающие слово extern, выносятся в заголовочные файлы (h-файлы). Слово extern означает, что переменная описывается, но не создается в данной точке программы. Определения глобальных переменных, т. е. описания без слова extern, помещаются в файлы реализации (c-файлы или cpp-файлы). статические переменные - это переменные, в описании которых присутствует слово static. Как правило, статические переменные описываются вне функций. Такие статические переменные во всем подобны глобальным, с одним исключением: область видимости статической переменной ограничена одним файлом, внутри которого она определена, - и, более того, ее можно использовать только после ее описания, т. е. ниже по тексту. По этой причине описания статических переменных обычно выносятся в начало файла. В отличие от глобальных переменных, статические переменные никогда не описываются в h-файлах (модификаторы extern и static конфликтуют между собой).
Стековая, или локальная, память
Локальные, или стековые, переменные - это переменные, описанные внутри функции. Память для таких переменных выделяется в аппаратном стеке. Память выделяется в момент входа в функцию или блок и освобождается в момент выхода из функции или блока. При этом захват и освобождение памяти происходят практически мгновенно, т. к. компьютер только изменяет регистр, содержащий адрес вершины стека.
Динамическая память, или куча
Помимо статической и стековой памяти, существует еще практически неограниченный ресурс памяти, которая называется динамическая, или куча (heap). В этом случае память под величины отводится во время выполнения программы. Программа может захватывать участки динамической памяти нужного размера. После использования ранее захваченный участок динамической памяти следует освободить.
Под динамическую память отводится пространство виртуальной памяти процесса между статической памятью и стеком. Обычно стек располагается в старших адресах виртуальной памяти и растет в сторону уменьшения адресов. Программа и константные данные размещаются в младших адресах, выше располагаются статические переменные. Пространство выше статических переменных и ниже стека занимает динамическая память:
адрес | содержимое памяти |
0 4 8 | код программы и данные, защищенные от изменения |
... | статические переменные программы |
динамическая память | |
max. адрес (232-4) | стек ↑ |
Структура динамической памяти автоматически поддерживается исполняющей системой языка Си или C++. Динамическая память состоит из захваченных и свободных сегментов, каждому из которых предшествует описатель сегмента. При выполнении запроса на захват памяти исполняющая система производит поиск свободного сегмента достаточного размера и захватывает в нем отрезок требуемой длины. При освобождении сегмента памяти он помечается как свободный, при необходимости несколько подряд идущих свободных сегментов объединяются.
Динамически распределяемые области памяти весьма удобны при создании множества небольших блоков данных. Связанными списками и деревьями проще мани пулировать, используя именно ДРП, а не виртуальную память или файлы, проецируемые в память. Преимущество динамически распределяемой памяти в том, что она позволяет игнорировать гранулярность выделения памяти и размер страниц и сосредотачиваться непосредственно на своей задаче. Недостаток — выделение и освобождение блоков памяти проходит медленнее, чем при использовании других механизмов, и, кроме того, теряется прямой контроль над передачей физической памяти и ее возвратом системе.
ДРП — это регион зарезервированного адресного пространства. Первоначально большей его части физическая память не передается. По мере того, как программа занимает эту область под данные, специальный диспетчер, управляющий ДРП, постранично передаст ей физическую память (из страничного файла). А при освобождении блоков в ДРП диспетчер возвращает системе соответствующие страницы физической памяти.
Динамические структуры данных: списки
Использование динамических величин предоставляет программисту ряд дополнительных возможностей. Во-первых, подключение динамической памяти позволяет увеличить объем обрабатываемых данных. Во-вторых, если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации. В-третьих, использование динамической памяти позволяет создавать структуры данных переменного размера.
Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного типа. Величины, имеющие ссылочный тип, называют указателями.
Указатель содержит адрес поля в динамической памяти, хранящего величину определенного типа. Сам указатель располагается в статической памяти.
Адрес величины — это номер первого байта поля памяти, в котором располагается величина. Размер поля однозначно определяется типом.
Сами динамические величины не требуют описания в программе, поскольку во время компиляции память под них не выделяется. Во время компиляции память выделяется только под статические величины. Указатели — это статические величины, поэтому они требуют описания.
Следует отчетливо понимать, что работа с динамическими данными замедляет выполнение программы, поскольку доступ к величине происходит в два шага: сначала ищется указатель, затем по нему — величина.
Списки
В динамической памяти можно создать структуру данных переменного размера.
Например:
В процессе физического эксперимента многократно снимаются показания прибора (допустим, термометра) и записываются в компьютерную память для дальнейшей обработки. Заранее неизвестно, сколько будет произведено измерений.
Если для обработки таких данных не использовать внешнюю память (файлы), то разумно расположить их в динамической памяти. Во-первых, динамическая память позволяет хранить больший объем информации, чем статическая. А во-вторых, в динамической памяти эти числа можно организовать в связанный список, который не требует предварительного указания количества чисел, подобно массиву. Связанный список схематически выглядит так:
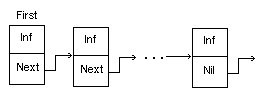
Здесь Inf — информационная часть звена списка (величина любого простого или структурированного типа, кроме файлового), Next — указатель на следующее звено списка; First — указатель на заглавное звено списка.
Согласно определению, список располагается в динамически распределяемой памяти, в статической памяти хранится лишь указатель на заглавное звено. Структура, в отличие от массива, является действительно динамической: звенья создаются и удаляются по мере необходимости, в процессе выполнения программы.
Для объявления списка сделано исключение: указатель на звено списка объявляется раньше, чем само звено.
Если указатель ссылается только на следующее звено списка (как показано на рисунке и в объявленной выше структуре), то такой список называют однонаправленным, если на следующее и предыдущее звенья — двунаправленным списком. Если указатель в последнем звене ссылается на заглавное звено списка, то такой список называется кольцевым. Кольцевыми могут быть и однонаправленные, и двунаправленные списки.
Типовые операции над списками:
- добавление звена в начало списка; удаление звена из начала списка; добавление звена в произвольное место списка, отличное от начала (например, после звена, указатель на которое задан); удаление звена из произвольного места списка, отличного от начала (например, после звена, указатель на которое задан); проверка, пуст ли список; очистка списка; печать списка.
Вопрос №7. Основы традиционного программирования. Определение подпрограммы-функции. Рекурсии
Традиционная технология программирования формировалась на заре вычислительной техники, когда в распоряжении пользователей были ограниченные ресурсы ЭВМ, а разработчик программ был в то же время и главным ее пользователем. В этих условиях главное внимание обращалось на получение эффективных программ в смысле оптимального использования ресурсов ЭВМ.
Для создания "хорошей" программы появляется необходимость придерживаться определенных принципов или определенной дисциплины программирования. Значительный прогресс в области программирования достигается с использованием так называемого структурного программирования.
Методология структурного программирования появилась как следствие возрастания сложности решаемых на компьютерах задач и соответственного усложнения программного обеспечения. В 70-е годы XX века объёмы и сложность программ достигли такого уровня, что «интуитивная» разработка программ, которая была нормой в более раннее время, перестала удовлетворять потребностям практики. Программы становились слишком сложными, чтобы их можно было нормально сопровождать, поэтому потребовалась какая-то систематизация процесса разработки и структуры программ.
Наиболее сильной критике со стороны разработчиков структурного подхода к программирования подвергся оператор GOTO (оператор безусловного перехода), имеющийся почти во всех языках программирования. Использование произвольных переходов в тексте программы приводит к получению запутанных, плохо структурированных программ, по тексту которых практически невозможно понять порядок исполнения и взаимозависимость фрагментов.
Следование принципам структурного программирования сделало тексты программ, даже довольно крупных, нормально читаемыми. Серьёзно облегчилось понимание программ, появилась возможность разработки программ в нормальном промышленном режиме, когда программу может без особых затруднений понять не только её автор, но и другие программисты. Это позволило разрабатывать достаточно крупные для того времени программные комплексы силами коллективов разработчиков, и сопровождать эти комплексы в течение многих лет, даже в условиях неизбежной ротации кадров.
Методология структурной разработки программного обеспечения была признана «самой сильной формализацией 70-х годов». Перечислим некоторые достоинства структурного программирования:
Структурное программирование — методология разработки программного обеспечения, предложенная в 70-х года XX века Дейкстрой и разработанная и дополненная Виртом.
В соответствии с данной методологией любая программа представляет собой структуру, построенную из трёх типов базовых конструкций:
· последовательное исполнение — однократное выполнение операций в том порядке, в котором они записаны в тексте программы;
· ветвление — однократное выполнение одной из двух или более операций, в зависимости от выполнения некоторого заданного условия;
· цикл — многократное исполнение одной и той же операции до тех пор, пока выполняется некоторое заданное условие (условие продолжения цикла).
В программе базовые конструкции могут быть вложены друг в друга произвольным образом, но никаких других средств управления последовательностью выполнения операций не предусматривается.
Повторяющиеся фрагменты программы (либо не повторяющиеся, но представляющие собой логически целостные вычислительные блоки) могут оформляться в виде так называемых подпрограмм (процедур или функций). В этом случае в тексте основной программы вместо помещённого в подпрограмму фрагмента вставляется инструкция вызова подпрограммы. При выполнении такой инструкции выполняется вызванная подпрограмма, после чего исполнение программы продолжается со следующей за командой вызова подпрограммы инструкции.
Разработка программы ведётся пошагово, методом «сверху вниз». Сначала пишется текст основной программы, в котором вместо каждого связного логического фрагмента текста вставляется вызов подпрограммы, которая будет выполнять этот фрагмент. Вместо настоящих, работающих подпрограмм, в программу вставляются «заглушки», которые ничего не делают. Полученная программа проверяется и отлаживается. После того, как программист убедится, что подпрограммы вызываются в правильной последовательности (то есть общая структура программы верна), подпрограммы-заглушки последовательно заменяются на реально работающие, причём разработка каждой подпрограммы ведётся тем же методом, что и основной программы. Разработка заканчивается тогда, когда не останется ни одной «затычки», которая не была бы удалена. Такая последовательность гарантирует, что на каждом этапе разработки программист одновременно имеет дело с обозримым и понятным ему множеством фрагментов и может быть уверен, что общая структура всех более высоких уровней программы верна. При сопровождении и внесении изменений в программу выясняется, в какие именно процедуры нужно внести изменения, и они вносятся, не затрагивая непосредственно не связанные с ними части программы. Это позволяет гарантировать, что при внесении изменений и исправлении ошибок не выйдет из строя какая-то часть программы, находящаяся в данный момент вне зоны внимания программиста.
Подпрограмма (от англ. subprogram) — поименованная или иным образом идентифицированная часть компьютерной программы, содержащая описание определённого набора действий. Подпрограмма может быть многократно вызвана из разных частей программы. В языках программирования для оформления и использования подпрограмм существуют специальные синтаксические средства.
Подпрограммы изначально появились как средство оптимизации программ по объёму занимаемой памяти — они позволили не повторять в программе идентичные блоки кода, а описывать их однократно и вызывать по мере необходимости. К настоящему времени данная функция подпрограмм стала вспомогательной, главное их назначение — структуризация программы с целью удобства её понимания и сопровождения.
Назначение параметров подпрограмм
Подпрограмма обычно имеет доступ к объектам данных, описанным в основной программе (по крайней мере, к некоторым из них), поэтому для того, чтобы передать в подпрограмму обрабатываемые данные, их достаточно присвоить, например, глобальным переменным. Но такой путь не особенно удобен и чреват ошибками.
Для обеспечения контролируемой передачи параметров в подпрограмму и возврата результатов из неё используется механизм параметров. Параметры описываются при описании подпрограммы (в её заголовке) и могут использоваться внутри процедуры аналогично переменным, описанным в ней. При вызове процедуры значения каждого из параметров указываются в команде вызова (обычно после имени вызываемой подпрограммы).
В языках программирования высокого уровня используется два типа подпрограмм: процедуры и функции.
Функция — это подпрограмма специального вида, которая, кроме получения параметров, выполнения действий и передачи результатов работы через параметры имеет ещё одну возможность — она может возвращать результат. Вызов функции является, с точки зрения языка программирования, выражением, он может использоваться в других выражениях или в качестве правой части присваивания.
Процедура — это любая подпрограмма, которая не является функцией.
Подпрограммы, входящие в состав классов в объектных языках программирования, обычно называются методами. Этим термином называют любые подпрограммы-члены класса, как функции, так и процедуры; когда требуется уточнение, говорят о методах-процедурах или методах-функциях.
Рекурсия — метод определения класса объектов или методов предварительным заданием одного или нескольких (обычно простых) его базовых случаев или методов, а затем заданием на их основе правила построения определяемого класса.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
