

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Другими словами, рекурсия — частичное определение объекта через себя, определение объекта с использованием ранее определённых. Рекурсия используется, когда можно выделить самоподобие задачи.
В программировании рекурсия — вызов функции или процедуры из неё же самой (обычно с другими значениями входных параметров), непосредственно или через другие функции (например, функция А вызывает функцию B, а функция B — функцию A). Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
Мощь рекурсивного определения объекта в том, что такое конечное определение способно описывать бесконечно большое число объектов. С помощью рекурсивной программы же возможно описать бесконечное вычисление, причём без явных повторений частей программы.
Имеется специальный тип рекурсии, называемый «хвостовой рекурсией». Интерпретаторы и компиляторы функциональных языков программирования, поддерживающие оптимизацию кода (исходного и/или исполняемого), выполняют хвостовую рекурсию в ограниченном объёме памяти при помощи итераций.
Следует избегать избыточной глубины рекурсии, так как это может вызвать переполнение стека вызовов.
Вопрос № 8. Основы объектно-ориентированного программирования (ООП). Определение класса.
Концепция ООП возникла в середине 80-х годов. Главная ее идея в том, что программное приложение, как и окружающий нас мир, должно состоять из объектов, обладающих собственными свойствами и поведением. ООП объединяет исполняемый код программы и ее данные в объекты, что упрощает создание сложных программных приложений. Например, можно организовать коллективную работу над проектом, где каждый участник создает собственный класс объектов, который становится доступным другим участникам проекта.
При объектно-ориентированном подходе программные задачи распределяются между объектами программы. Объект - это некоторая уникальная единица имеющая свои данные и функции, эти данные обрабатывающие. Объекты обладают определенным набором свойств, методов и способностью реагировать на события (нажатие кнопок мыши, интервалы времени и т. д.). В отличие от процедурного программирования, где порядок выполнения операторов программы определяется порядком их следования и командами управления, в ООП порядок выполнения процедур и функций определяется, прежде всего, событиями.
Чтобы проект можно было считать объектно-ориентированным, объекты должны удовлетворять некоторым требованиям. Этими требованиями являются: инкапсуляция, наследование и полиморфизм.
- Инкапсуляция — означает, что объекты скрывают детали своей работы. Инкапсуляция позволяет разработчику объекта изменять внутренние принципы его функционирования, не оказывая никакого влияния на пользователя объекта. Этот принцип реализуется, в основном, за счет применения описаний Private (закрытые или приватные данные, нелоступные извне) и Public (открытые или публичные данными). Наследование — означает, что новый объект можно определить на основе уже существующих объектов, при этом он будет содержать все свойства и методы родительского. Наследование полезно, когда требуется создать новый объект, обладающий дополнительными свойствами по сравнению со старым. Полиморфизм — многие объекты могут иметь одноименные методы, которые могут выполнять разные действия для разных объектов. Например, оператор "+" для числовых величин выполняет сложение, а для текстовых — склеивание.
В ООП центральным является понятие класса. Класс – это шаблон, по которому создаются объекты определенного типа. Класс объединяет в себе данные и методы их обработки.
Объекты — это экземпляры определенного класса. Например, кнопки или текстовые поля, устанавливаемые на форме являются экземплярами соответствующих стандартных классов. В принципе, как объект можно представить любой тип данных. Например целое число можно представить как объект, а тип целые числа как класс.
В программировании, свойства объекта так и называются - свойства. А способы извлечения содержимого, применимые к объекту - это методы. В программировании с помощью свойств мы работаем с внутренними данными, читаем и устанавливаем значения, а методы - это те действия, которые может выполнять сам объект.
Свойство объекта неизменяемое в процессе его существования называется статическим свойством и одинаково для всех экземпляров класса. Не статическое свойство - это содержимое, которое можно легко извлечь и заменить.
В программировании - статическое свойство принадлежит всем объектам и, например, если мы изменяем статическое свойство одного объекта, оно меняется для всех (на самом деле это свойство "определено и существует" в единичном экземпляре и используется всеми объектами одного типа, то есть порожденных из одного класса).
Создать собственный класс можно с помощью модуля класса. Модуль класса состоит из элементов трех типов: свойств, методов, событий, оформляемых в виде описаний, процедур и функций внутри контейнера — модуля. У модуля класса нет собственного пользовательского интерфейса — формы, однако он может использовать контейнер формы, для чего должен содержать соответствующие методы.
Элементы управления — это объекты, используемые при разработке пользовательского интерфейса.
Классы.
ОО-метод основан на понятии класса. Класс - элемент ПО, описывающий абстрактный тип данных и его частичную или полную реализацию. Абстрактный тип данных - множество объектов, определяемое списком компонентов - операций, применимых к этим объектам, и их свойств.
Классы как модули.
Объектная ориентация - в первую очередь архитектурная техника: она в основном затрагивает модульную структуру системы.
Здесь опять велика роль классов. Класс описывает не только тип объектов, но и модульную единицу. В чистом ОО-подходе: классы должны быть единственным видом модулей.
В частности, исчезает понятие главной программы, а подпрограммы не существуют как независимые модульные единицы (они могут появляться только как часть классов).
Классы как типы.
Понятие класса достаточно мощное, чтобы избежать необходимости любого другого механизма типизации: каждый тип должен быть основан на классе.
Даже базовые типы, такие как INTEGER и REAL, можно рассматривать как классы; обычно такие классы являются встроенными.
Вычисления, основанные на компонентах.
В ОО-вычислениях существует только один базовый вычислительный механизм. Есть некоторый объект, всегда являющийся экземпляром некоторого класса, и вычисление состоит в том, что данный объект вызывает некоторый компонент этого класса. Например, для показа окна на экране вызывается компонент display объекта, представляющего окно, - экземпляра класса WINDOW.
Базисные типы рассматриваются как предопределенные классы, и основные операции (например, сложение чисел) рассматриваются как специальные предопределенные случаи вызова компонентов - общий механизм вычислений: вызов компонента должен быть основным механизмом вычисления.
Класс, содержащий вызов компонента класса C, называют клиентом класса С.
Скрытие информации.
При создании класса зачастую в него приходится включать компонент, необходимый только для внутренних целей, являющийся частью реализации класса, но не его интерфейса.
Механизм, делающий определенные компоненты недоступными для клиентов, называется скрытием информации.
Автор класса должен иметь возможность указать, что компонент доступен: всем клиентам, ни одному клиенту или избранным клиентам.
Прямое следствие этого правила - строгая ограниченность взаимодействия классов. В частности, хороший ОО-язык не должен включать понятие глобальной переменной. Классы обмениваются информацией исключительно через вызовы компонентов и механизм наследования.
Вопрос № 9. Трансляторы. Этапы трансляции. Генерация кода.
Транслятор - обслуживающая программа, преобразующая исходную программу, предоставленную на входном языке программирования, в рабочую программу, представленную на объектном языке.
Приведенное определение относится ко всем разновидностям транслирующих программ. Однако у каждой из таких программ могут иметься свои особенности по организации процесса трансляции.
Ассемблер - системная обслуживающая программа, которая преобразует символические конструкции в команды машинного языка. Специфической чертой ассемблеров является то, что они осуществляют дословную трансляцию одной символической команды в одну машинную. Таким образом, язык ассемблера (еще называется автокодом) предназначен для облегчения восприятия системы команд компьютера и ускорения программирования в этой системе команд.
Компилятор - это обслуживающая программа, выполняющая трансляцию на машинный язык программы, записанной на исходном языке программирования. Также как и ассемблер, компилятор обеспечивает преобразование программы с одного языка на другой (чаще всего, в язык конкретного компьютера). Вместе с тем, команды исходного языка значительно отличаются по организации и мощности от команд машинного языка. Существуют языки, в которых одна команда исходного языка транслируется в 7-10 машинных команд. Однако есть и такие языки, в которых каждой команде может соответствовать 100 и более машинных команд (например, Пролог).
Интерпретатор - программа или устройство, осуществляющее пооператорную трансляцию и выполнение исходной программы. В отличие от компилятора, интерпретатор не порождает на выходе программу на машинном языке. Распознав команду исходного языка, он тут же выполняет ее. Как в компиляторах, так и в интерпретаторах используются одинаковые методы анализа исходного текста программы. Но интерпретатор позволяет начать обработку данных после написания даже одной команды. Это делает процесс разработки и отладки программ более гибким.
Общие особенности языков программирования и трансляторов.
Языки программирования достаточно сильно отличаются друг от друга по назначению, структуре, семантической сложности, методам реализации. Это накладывает свои специфические особенности на разработку конкретных трансляторов.
Вместе с тем, все языки программирования обладают рядом общих характеристик и параметров. Эта общность определяет и схожие для всех языков принципы организации трансляторов.
Языки программирования предназначены для облегчения программирования. Поэтому их операторы и структуры данных более мощные, чем в машинных языках. Для повышения наглядности программ вместо числовых кодов используются символические или графические представления конструкций языка, более удобные для их восприятия человеком. Для любого языка определяется:- Множество символов, которые можно использовать для записи правильных программ (алфавит), основные элементы. Множество правильных программ (синтаксис). "Смысл" каждой правильной программы (семантика).
Обобщенная структура транслятора.
Учитывая схожесть компилятора и интерпретатора, рассмотрим этапы, существующие в компиляторе. В нем выделяются:
Этап лексического анализа. Этап синтаксического анализа, состоящий из:- распознавания синтаксической структуры; семантического разбора, в процессе которого осуществляется работа с таблицами, порождение промежуточного семантического представления или объектной модели языка.
- семантический анализ компонент промежуточного представления или объектной модели языка; перевод промежуточного представления или объектной модели в объектный код.
Наряду с основными этапами процесса трансляции возможны также дополнительные этапы:
2а. Этап исследования и оптимизации промежуточного представления, состоящий из:
2а.1. анализа корректности промежуточного представления;
2а.2. оптимизации промежуточного представления.
3а. Этап оптимизации объектного кода.
 Интерпретатор отличается тем, что этап генерации кода обычно заменяется этапом эмуляции элементов промежуточного представления или объектной модели языка. Кроме того, в интерпретаторе обычно не проводится оптимизация промежуточного представления, а сразу же осуществляется его эмуляция.
Интерпретатор отличается тем, что этап генерации кода обычно заменяется этапом эмуляции элементов промежуточного представления или объектной модели языка. Кроме того, в интерпретаторе обычно не проводится оптимизация промежуточного представления, а сразу же осуществляется его эмуляция.
Кроме этого можно выделить единый для всех этапов процесс анализа и исправление ошибок, существующих в обрабатываемом исходном тексте программы.
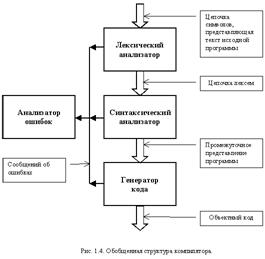
Обобщенная структура компилятора, учитывающая существующие в нем этапы, представлена на рис. 1.4.
Он состоит из лексического анализатора, синтаксического анализатора, генератора кода, анализатора ошибок.
Лексический анализатор (известен также как сканер) осуществляет чтение входной цепочки символов и их группировку в элементарные конструкции, называемые лексемами. Каждая лексема имеет класс и значение. Обычно претендентами на роль лексем выступают элементарные конструкции языка, например, идентификатор, действительное число, комментарий. Полученные лексемы передаются синтаксическому анализатору.
Синтаксис - совокупность правил некоторого языка, определяющих формирование его элементов. Иначе говоря, это совокупность правил образования семантически значимых последовательностей символов в данном языке. Синтаксис задается с помощью правил, которые описывают понятия некоторого языка. Примерами понятий являются: переменная, выражение, оператор, процедура. Последовательность понятий и их допустимое использование в правилах определяет синтаксически правильные структуры, образующие программы. Именно иерархия объектов, а не то, как они взаимодействуют между собой, определяются через синтаксис. Например, оператор может встречаться только в процедуре, а выражение в операторе, переменная может состоять из имени и необязательных индексов и т. д. Синтаксис не связан с такими явлениями в программе как "переход на несуществующую метку" или "переменная с данным именем не определена". Этим занимается семантика.
Семантика - правила и условия, определяющие соотношения между элементами языка и их смысловыми значениями, а также интерпретацию содержательного значения синтаксических конструкций языка. Объекты языка программирования не только размещаются в тексте в соответствии с некоторой иерархией, но и дополнительно связаны между собой посредством других понятий, образующих разнообразные ассоциации. Например, переменная, для которой синтаксис определяет допустимое местоположение только в описаниях и некоторых операторах, обладает определенным типом, может использоваться с ограниченным множеством операций, имеет адрес, размер и должна быть описана до того, как будет использоваться в программе.
Синтаксический анализатор - компонента компилятора, осуществляющая проверку исходных операторов на соответствие синтаксическим правилам и семантике данного языка программирования. Несмотря на название, анализатор занимается проверкой и синтаксиса, и семантики. Он состоит из нескольких блоков, каждый из которых решает свои задачи.
Синтаксический анализатор осуществляет разбор исходной программы, используя поступающие лексемы, построение синтаксической структуры программы и семантический анализ с формированием объектной модели языка. Объектная модель представляет синтаксическую структуру, дополненную семантическими связями между существующими понятиями. Этими связями могут быть:
- ссылки на переменные, типы данных и имена процедур, размещаемые в таблицах имен; связи, определяющие последовательность выполнения команд; связи, определяющие вложенность элементов объектной модели языка и другие.
Анализатор ошибок получает информацию об ошибках, возникающих в различных блоках транслятора. Используя полученную информацию, он формирует сообщения пользователю. Кроме этого, данный блок может попытаться исправить ошибку, чтобы продолжить разбор дальше. На него также возлагаются действия, связанные с корректным завершением программы в случае, когда дальнейшую трансляцию продолжать невозможно.
Генератор кода строит код объектной машины на основе анализа объектной модели или промежуточного представления. Построение кода сопровождается дополнительным семантическим анализом, связанным с необходимостью преобразования обобщенных команд в коды конкретной вычислительной машины. На этапе такого анализа окончательно определяется возможность преобразования, и выбираются эффективные варианты. Сама генерация кода является перекодировкой одних команд в другие.
Транслитератор.
Несмотря на то, что лексический анализатор обрабатывает входную цепочку, удобнее на его вход подавать не просто отдельные символы, а символы, сгруппированные по категориям. Поэтому, перед лексическим анализатором осуществляется дополнительная обработка, сопоставляющая с каждым символом его класс, что позволяет сканеру манипулировать единым понятием для целой группы символов, иногда достаточно большой. Устройство, осуществляющее сопоставление класса с каждым отдельным символом, называется транслитератором. Наиболее типичными классами символов являются:
- буква - класс, с которым сопоставляется множество букв, причем необязательно только одного алфавита; цифра - множество символов, относящихся к цифрам, чаще всего от 0 до 9; разделитель - пробел, перевод строки, возврат каретки перевод формата; игнорируемый - может встречаться во входном потоке, но игнорируется и поэтому просто отфильтровывается из него (например, невидимый код звукового сигнала и другие аналогичные коды); запрещенный - символы, который не относятся к алфавиту языка, но встречается во входной цепочке; прочие - символы, не вошедшие ни в одну из определенных категорий.
Варианты взаимодействия блоков транслятора.
Организация процессов трансляции, определяющая реализацию основных фаз, может осуществляться различным образом. Это определяется различными вариантами взаимодействия блоков транслятора: лексического анализатора, синтаксического анализатора и генератора кода. Несмотря на одинаковый конечный результат, различные варианты взаимодействия блоков транслятора обеспечивают различные варианты хранения промежуточных данных. Можно выделить два основных варианта взаимодействия блоков транслятора:
- многопроходную организацию, при которой каждая из фаз является независимым процессом, передающим управление следующей фазе только после окончания полной обработки своих данных; однопроходную организацию, при которой все фазы представляют единый процесс и передают друг другу данные небольшими фрагментами.
На основе двух основных вариантов можно также создавать их разнообразные сочетания.
Вопрос № 10. Лексический, синтаксический и семантический анализаторы транслятора.
Транслятор - обслуживающая программа, преобразующая исходную программу, предоставленную на входном языке программирования, в рабочую программу, представленную на объектном языке.
Компиляция - преобразование объектов (данных и операций над ними) с входного языка в объекты на другом языке для всей программы в целом с последующим выполнением полученной программы в виде отдельного шага.
Интерпретация - анализ отдельного объекта на входном языке с одновременным выполнением (интерпретацией).
Лексика языка программирования - это правила «правописания слов» программы, таких как идентификаторы, константы, служебные слова, комментарии. Лексический анализ разбивает текст программы на указанные элементы. Особенность любой лексики – её элементы представляют собой регулярные линейные последовательности символов. Например, идентификатор - это произвольная последовательность букв, цифр и символа "_", начинающаяся с буквы или "_".
Синтаксис языка программирования - это правила составления предложений языка из отдельных слов. Такими предложениями являются операции, операторы, определения функций и переменных. Особенностью синтаксиса является принцип вложенности (рекурсивность) правил построения предложений. Это значит, что элемент синтаксиса языка в своем определении прямо или косвенно в одной из его частей содержит сам себя. Например, в определении оператора цикла телом цикла является оператор, частным случаем которого является все тот же оператор цикла.
Семантика языка программирования - это смысл, который закладывается в каждую конструкцию языка. Семантический анализ - это проверка смысловой правильности конструкции. Например, если мы в выражении используем переменную, то она должна быть определена ранее по тексту программы, а из этого определения может быть получен ее тип. Исходя из типа переменной, можно говорит о допустимости операции с данной переменной.
Первая фаза трансляции – лексический анализ. Лексема — последовательность допустимых символов языка программирования, имеющая смысл для транслятора. Транслятор рассматривает программу как последовательность лексем. На этапе лексического анализа исходный текст программы «нарезается» на лексемы – последовательности входных символов (литер), допускающие альтернативу (выбор), повторение и взаимное пересечение в процессе распознавания не более чем на заданную глубину. Элементами лексики являются идентификаторы, константы, строки, комментарии, одно - и многосимвольные знаки операций и т. п.. Механизм распознавания базируется на простых системах распознавания, имеющих всего одну единицу памяти (текущее состояние) и табличное описание правил поведения (конечный автомат). Результат классификации лексем (классы лексем) является входной информацией для синтаксического анализатора (класс лексемы называется на входе синтаксического анализатора символом). Значения лексем поступают на вход семантического анализатора в виде первичного заполнения семантических таблиц.
Перед тем, как построить синтаксический анализатор, разбирающий значения выражений, необходимо иметь несколько вариантов разбиения строки, содержащей выражение, на составляющие части. Например, выражение
А*В-(W+10)
содержит компоненты "А", "*", "В", "-", "(", "W", "+", "10" и ")". Каждый компонент представляет собой неделимый элемент выражения. Такой компонент или независимая часть выражения называется лексемой.
Синтаксический анализ является центральным элементом транслятора. Во-первых, потому что синтаксис характеризует элементы, относящиеся к структуре программы: описания и определения данных, функций, классов и других элементов программы, операторы, выражения – это все синтаксические элементы разных уровней. Кроме того, вся программа представляет собой одно синтаксическое целое. Задачей синтаксического анализа является построение структуры – синтаксического дерева, отражающего взаимное расположение всех синтаксических элементов программы (их порядка следования, повторяемости, вложенности, приоритетов). Средством описания синтаксиса являются формальные грамматики, а их свойства используются для построения распознавателей, базирующихся на табличном описании правил их поведения в сочетании со стековой памятью (магазинные автоматы).
Синтактический анализатор выражений, преобразует числовые выражения, такие как (10-X)/23, в такую форму, чтобы компьютер мог понять ее и вычислить.
Числовые выражения могут строится из следующих элементов:
- числа
- операторы + - / * ^ % = () <> ; ,
- скобки
- переменные
Символ '^' означает экспоненту, а символ '=' используется как оператор присваивания, а также как знак равенства в операциях сравнения. Элементы выражения можно комбинировать согласно правилам алгебры.
Примеры выражений:
*14/6
a+b-c
10^5
a=7-b
Символы '=', '>', '<', ',', ';' являются операторами, они не могут использоватся в выражениях функций, конструкциях и операторах присваивания.
В процессе работы синтаксический анализатор присваивает операторам следующие приоритеты:
высший ()
^
* / %
+ -
низший =
Операторы равного приоритета выполняются слева направо.
Лексический и синтаксический анализ являются формализованными компонентами языка, как с точки зрения их описания (конечные автоматы и формальные грамматики), так и с точки зрения проектирования распознавателей для них (для чего используются известные методы и алгоритмы).
Заключительная фаза трансляции – семантический анализ, а также фаза синтеза – генерация кода (оптимизация) или интерпретация - привязаны к синтаксису (и, соответственно, к синтаксическому анализатору), поскольку интерпретируют «смысловое» содержание и правила преобразования (или исполнения) элементарных синтаксических единиц, выделенных синтаксическим анализатором. Особенностью семантического анализа является то, что он менее привязан к структуре программы: семантика одного и того же объекта программы может определяться синтаксически не связанными элементами программы. Во-вторых, семантический анализ не формализуем, поскольку семантика программы представляется в процессе трансляции уникальной структурой данных, содержащей описания множеств объектов языка, определенных в программе, их свойств и взаимосвязей (семантические таблицы). Работа с такими таблицами производится через и семантические процедуры, соответствующие элементам синтаксиса (правила грамматики), которые также разрабатываются содержательным образом, не имея под собой формальной основы.
Вопрос №11. Языки программирования. Определение. Классификация. Формальные грамматики.
Язык программирования это знаковая систем для записи алгоритмов. Смысл появления такого языка – оснащенный набор вычислительных формул дополнительной информации, превращает данный набор в алгоритм.
Язык программирования служит двум связанным между собой целям: он дает программисту аппарат для задания действий, которые должны быть выполнены, и формирует концепции, которыми пользуется программист, размышляя о том, что делать. Первой цели идеально отвечает язык, который настолько "близок к машине", что всеми основными машинными аспектами можно легко и просто оперировать достаточно очевидным для программиста образом. Второй цели идеально отвечает язык, который настолько "близок к решаемой задаче", чтобы концепции ее решения можно было выражать прямо и коротко.
Связь между языком, на котором мы думаем/программируем, и задачами и решениями, которые мы можем представлять в своем воображении, очень близка. По этой причине ограничивать свойства языка только целями исключения ошибок программиста в лучшем случае опасно. Как и в случае с естественными языками, есть огромная польза быть, по крайней мере, двуязычным. Язык предоставляет программисту набор концептуальных инструментов, если они не отвечают задаче, то их просто игнорируют. Например, серьезные ограничения концепции указателя заставляют программиста применять вектора и целую арифметику, чтобы реализовать структуры, указатели и т. п. Хорошее проектирование и отсутствие ошибок не может гарантироваться чисто за счет языковых средств.
Может показаться удивительным, но конкретный компьютер способен работать с программами, написанными на его родном машинном языке. Существует почти столько же разных машинных языков, сколько и компьютеров, но все они суть разновидности одной идей простые операции производятся со скоростью молнии на двоичных числах.
Персональные компьютеры IBM используют машинный язык микропроцессоров семейства 8086, т. к. их аппаратная часть основывается именно на данных микропроцессорах.
Существуют различные классификации языков программирования.
По наиболее распространенной классификации все языки программирования делят на языки низкого, высокого и сверхвысокого уровня.
В группу языков низкого уровня входят машинные языки и языки символического кодирования: (Автокод, Ассемблер). Операторы этого языка – это те же машинные команды, но записанные мнемоническими кодами, а в качестве операндов используются не конкретные адреса, а символические имена. Все языки низкого уровня ориентированы на определенный тип компьютера, т. е. являются машинно-зависимыми. Машинно-ориентированные языки – это языки, наборы операторов и изобразительные средства которых существенно зависят от особенностей ЭВМ (внутреннего языка, структуры памяти и т. д.).
Следующую, существенно более многочисленную группу составляют языки программирования высокого уровня. Это Фортран, Алгол, Кобол, Паскаль, Бейсик, Си, Пролог и т. д. Эти языки машинно-независимы, т. к. они ориентированы не на систему команд той или иной ЭВМ, а на систему операндов, характерных для записи определенного класса алгоритмов. Однако программы, написанные на языках высокого уровня, занимают больше памяти и медленнее выполняются, чем программы на машинных языках.
К языкам сверхвысокого уровня можно отнести лишь Алгол-68 и APL. Повышение уровня этих языков произошло за счет введения сверхмощных операций и операторов.
Другая классификация делит языки на вычислительные и языки символьной обработки. К первому типу относят Фортран, Паскаль, Алгол, Бейсик, Си, ко второму типу - Лисп, Пролог, Снобол и др.
В современном мире можно выделить два основных направления развития языков программирования: процедурное и непроцедурное.
Процедурное программирование возникло на заре вычислительной техники и получило широкое распространение. В процедурных языках программа явно описывает действия, которые необходимо выполнить, а результат задается только способом получения его при помощи некоторой процедуры, которая представляет собой определенную последовательность действий.
Среди процедурных языков выделяют в свою очередь структурные и операционные языки. В структурных языках одним оператором записываются целые алгоритмические структуры: ветвления, циклы и т. д. В операционных языках для этого используются несколько операций. Широко распространены следующие структурные языки: Паскаль, Си, Ада, ПЛ/1. Среди операционных известны Фортран, Бейсик, Фокал.
Непроцедрное (декларативное) программирование появилось в начале 70-х годов 20 века, но стремительное его развитие началось в 80-е годы, когда был разработан японский проект создания ЭВМ пятого поколения, целью которого явилась подготовка почвы для создания интеллектуальных машин. К непроцедурному программированию относятся функциональные и логические языки.
В функциональных языках программа описывает вычисление некоторой функции. Обычно эта функция задается как композиция других, более простых, те в свою очередь разлагаются на еще более простые и т. д. Один из основных элементов в функциональных языках - рекурсия, то есть вычисление значения функции через значение этой же функции от других элементов. Присваивания и циклов в классических функциональных языках нет.
В логических языках программа вообще не описывает действий. Она задает данные и соотношения между ними. После этого системе можно задавать вопросы. Машина перебирает известные и заданные в программе данные и находит ответ на вопрос. Порядок перебора не описывается в программе, а неявно задается самим языком. Классическим языком логического программирования считается Пролог. Построение логической программы вообще не требует алгоритмического мышления, программа описывает статические отношения объектов, а динамика находится в механизме перебора и скрыта от программиста.
Можно выделить еще один класс языков программирования - объектно-ориентированные языки высокого уровня. На таких языках не описывают подробной последовательности действий для решения задачи, хотя они содержат элементы процедурного программирования. Объектно-ориентированные языки, благодаря богатому пользовательскому интерфейсу, предлагают человеку решить задачу в удобной для него форме. Примером такого языка может служить язык программирования визуального общения Object Pascal.
Языки описания сценариев, такие как Perl, Python, Rexx, Tcl и языки оболочек UNIX, предполагают стиль программирования, весьма отличный от характерного для языков системного уровня. Они предназначаются не для написания приложения с нуля, а для комбинирования компонентов, набор которых создается заранее при помощи других языков. Развитие и рост популярности Internet также способствовали распространению языков описания сценариев. Так, для написания сценариев широко употребляется язык Perl, а среди разработчиков Web-страниц популярен JavaScript.
Формальные языки и грамматики
Пользуясь аналогией с естественным языком, формальный язык можно представить как множество предложений, построенных по определенным правилам. Способ построения предложений формального языка и правила построения могут быть определены с помощью формальных грамматик. При этом множество правил построения называют схемой грамматики, а порядок построения определяется с помощью понятия вывода. Как правило, с помощью правил грамматики можно строить различные выводы, результатом которых являются правила предложений языка. Поэтому формальные грамматики часто называют порождающими грамматиками, а вывод – процессом порождения.
Первичными и самыми простыми понятиями, необходимыми для определения формального языка и грамматики, являются понятия алфавита и слова в алфавите.
Конечное множество символов, неделимых в данном рассмотрении, называется словарем или алфавитом, а символы, входящие в множество, - буквами алфавита.
Например, алфавит A = {a, b, c, +, !} содержит 5 букв, а алфавит B = {00, 01, 10, 11} содержит 4 буквы, каждая из которых состоит из двух символов.
Последовательность букв алфавита называется словом или цепочкой в этом алфавите. Число букв, входящих в слово, называется его длиной.
Например, в алфавите A слово a=ab++c имеет длину l(a) = 5, а слово b= в алфавите B имеет длину l(b) = 4.
Если задан алфавит A, то обозначим A* множество всевозможных цепочек, которые могут быть построены из букв алфавита A. При этом предполагается, что пустая цепочка, которую обозначим знаком $, также входит в множество A*. Пустая цепочка – это цепочка, не содержащая ни одной буквы. Присоединение к некоторой цепочке a пустой цепочки, справа или слева от от нее, не изменяет цепочку a.
a $ = $ a = a
Для определения множества всевозможных цепочек, построенных из символов алфавита А, которое не содержит пустой цепочки, используют обозначение А+.
Формальной грамматикой Г называется следующая совокупность четырех объектов:
Г = { VТ, VA, <I>, R },
где VT - терминальный алфавит (словарь); буквы этого алфавита называются терминальными символами; из них строятся цепочки, порождаемые грамматикой;
для обозначения букв терминального словаря, которые называют также терминальными символами, в дальнейшем условимся использовать строчные буквы латинского алфавита;
VA - нетерминальный, вспомогательный алфавит (словарь); буквы этого алфавита используются при построении цепочек; они могут входить в промежуточные цепочки, но не должны входить в результат построения;
условимся для обозначения нетерминальных символов использовать идентификаторы, состоящие из прописных букв латинского алфавита и заключенные в угловые скобки;
<I> - начальный символ или аксиома грамматики <I> Î VA.
R - множество правил вывода или порождающих правил вида a ® b, где a и b - цепочки, построенные из букв алфавита VТ È VA, который называют полным алфавитом (словарем) грамматики Г.
В множество правил грамматики могут также входить правила с пустой правой частью вида <Е> ® . Чтобы избежать неопределенности из-за отсутствия символа в правой части правила, условимся использовать символ пустой цепочки, записывая такое правило в виде <Е> ® $.
Типы формальных грамматик
В теории формальных языков выделяются 4 типа грамматик, которым соответствуют 4 типа языков. Эти грамматики выделяются путем наложения ограничений на правила грамматики.
Грамматики типа 0, которые называют грамматиками общего вида, не имеют никаких ограничений на правила порождения. Любое правило
r = h ® y
может быть построено с использованием произвольных цепочек (Vт Va)*. Например,
<T> <W> ® <W> <T> или x <A> b <C> <D> ® x <H> <D>.
Грамматики типа 1, которые называют также контекстно-зависимыми грамматиками, не допускают использования любых правил. Правила вывода в таких грамматиках должны иметь вид:
c1 <A> c2 ® c1 w c2,
где c1, c2 - цепочки, возможно пустые, из множества (Vт È Va)*, символ <А> Î Va и цепочка ω Î (Vт È Va)*. Цепочки c1 и c2 остаются неизменными при применении правила, поэтому их называют контекстом (соответственно левым и правым), а грамматику - контекстно зависимой.
Грамматики типа 1 значительно удобнее на практике, чем грамматики типа 0, поскольку в левой части правила заменяется всегда один нетерминальный символ, который можно связать с некоторым синтаксическим понятием, в то время как в грамматике типа 0 можно заменять сразу несколько символов, в том числе и терминальных.
Например, грамматика:
Г1.5:
VТ = {a, b, c, d}, VА = {<I>, <A>, <B>}
R = { <I> ® a <A> <I>,
<A> <I> ® <A> <A> <I>,
<A> <A> <A> ® <A> <B> <A>,
<A> ® b,
b <B> <A> ® b c d <A>,
b <I> ® b a }
является контекстно-зависимой, поскольку второе и шестое правила имеют непустой левый контекст, а третье и пятое правила содержат оба контекста. Вывод в такой грамматике может иметь вид:
<I> Þ a<A><I> Þ a<A><A><I> Þ ab<A><I> Þ abb<I> Þ abba.
Грамматики типа 2 называют контектно-свободными и бесконтекстными грамматиками ( КС-грамматики или Б-грамматики). Правила вывода таких грамматик имеют вид:
<A> ® a,
где <A> Î VА и a Î (VТ È VА)*.
Очевидно, что эти правила получаются из правил грамматики типа 1 при условии c1 = c2 = $. Поскольку контекстные условия отсутствуют, то правила КС-грамматик получаются проще, чем правила грамматик типа 1. Именно такие грамматики используются для описания языков программирования. Примером КС-грамматики может служить следующая грамматика:
Г1.6: VТ= {a, b}, VА = {<I>},
R = { <I> ® a<I>a,
<I> ® b<I>b,
<I> ® aa,
<I> ® bb}.
Эта грамматика порождает язык, который состоит из цепочек, каждая из которых в свою очередь состоит из двух частей, цепочки b Î VТ* и зеркального отображения этой цепочки b'.
L( Г1.6 ) = { b b' | b ÎVТ+},
где VТ+ - это множество VТ* без пустой цепочки. С помощью правил этой грамматики может быть построена, например, следующая цепочка:
<I> Þ a<I>a Þ ab<I>ba Þ aba<I>aba Þ ababbaba.
Грамматики типа 3 называют автоматными грамматиками (А - грамматиками). Правила вывода в таких грамматиках имеют вид:
<A> ® a или <A> ® a <B> или <A> ® <B> a,
где a Î VТ, и <A>, <B> Î VА, причем грамматика может иметь только правила вида <A> ® a <B> - правосторонние правила, либо только вида <A> ® <B> a - левосторонние правила.
Примерами автоматных грамматик могут служить правосторонняя грамматика Г1.7 и левосторонняя грамматика Г1.8
Г1.7: VТ = {a, b}, VА = {<I>, <A>},
R = { <I> ® a <I>,
<I> ® a <A>,
<A> ® b <A>,
<A> ® b <Z>,
<Z> ® $ }.
Г1.8:
VТ= {a, b}, VА = {<I>, <A>},
R = { <I> ® <A> b,
<A> ® <A> b,
<A> ® <Z> a,
<Z> ® <Z> a,
<Z> ® $ }.
Эти грамматики прождают один и тот же язык. Если обозначать цепочки, состоящие из k одинаковых символов x как xk, например x4 = xxxx, то порождаемый этими грамматиками язык можно определить следующим образом:
L(Г1.8) = { anbm | n,m > 0}.
Классификация языков может быть построена в соответствии с типом грамматик, порождающих язык. Один и тот же язык может быть задан различными грамматиками, которые могут быть грамматиками разных типов. Поэтому тип языка определяют по типу той грамматики, которая не может быть представлена грамматикой типа k+1.
Например, если грамматика типа 2 содержит правило вида
<А> ® a1 a2 <B> a3 a4,
то преобразовать ее в автоматную грамматику нельзя. Следовательно, язык, порождаемый такой грамматикой, относится к языкам типа 2. Если же схема грамматики типа 2 содержит правила вида
<А> ® a1 a2 a3 a4 <B>,
то, как будет показано в следующей главе, такую грамматику можно преобразовать к грамматике типа 3 и, следовательно, язык, порожденный этой грамматикой, является языком типа 3.
Если обозначить множество языков типа k выражением {Lтипаk}, то отношение между множеством языков различных типов можно определить с помощью следующего включения:
{ L типа3 } Ì { L типа2 } Ì{ L типа1 } Ì { L типа0}.
При этом доказано, что существуют языки типа 0, не являющиеся языками типа 1, языки типа 2, не являющиеся языками типа 1, и языки типа 3, не являющиея языками типа 2.
Учитывая, что наибольшее практическое применение находят грамматики типа 2 и типа 3, дальнейшее изложение посвящается рассмотрению именно этих типов грамматик.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
