
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
,
Институт прикладной физики РАН, Нижний Новгород
Научно-исследовательский радиофизический институт, Нижний Новгород
aka. *****@***com
ПОСЛЕДОВАТЕЛЬНЫЙ АЛГОРИТМ ОБУЧЕНИЯ
ЯДРОВЫХ КЛАССИФИКАТОРОВ
НА ОПОРНЫХ ВЕКТОРАХ
Предложен алгоритм построения ядровых классификаторов, решение которого сходится к решению известной машины опорных векторов ![]() . Скорость работы алгоритма выше, а количество опорных векторов – меньше, чем у известных реализаций
. Скорость работы алгоритма выше, а количество опорных векторов – меньше, чем у известных реализаций 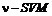 . Подход оптимизирует размещение пары параллельных решающих гиперплоскостей в многомерном пространстве признаков по обучающим данным в реальном времени. По ориентации гиперплоскостей и величине зазора между ними строится двухпороговый тернарный классификатор.
. Подход оптимизирует размещение пары параллельных решающих гиперплоскостей в многомерном пространстве признаков по обучающим данным в реальном времени. По ориентации гиперплоскостей и величине зазора между ними строится двухпороговый тернарный классификатор.
Ключевые слова: классификация, машина опорных векторов, последовательный алгоритм
Введение
Машина опорных векторов (SVM) обеспечивает построение оптимальной нелинейной разделяющей гиперплоскости в многомерном признаковом пространстве. SVM и его модификации, такие, как , в сравнении с нейросетевыми алгоритмами классификации показывают качественно более высокие результаты в целом ряде приложений [1]. Однако вариант плохо подходит для последовательного обучения на потоке обучающих примеров, когда приемлемую ошибку классификации требуется обеспечивать при жестких ограничениях на время обучения, а также на ресурсы вычислительных систем по быстродействию и памяти.
Основные подходы к построению последовательных алгоритмов SVM изложены в работах [2,3]. Идея последовательных алгоритмов SVM заключается в использовании шагов введения и выведения входных векторов во множество опорных векторов, формирующих решение. В работе [4] предложен простой и быстрый геометрический алгоритм последовательного поиска граничных векторов и формирования линейной классифицирующей гиперплоскости. Другие методы направлены на сокращение количества опорных векторов с некоторой потерей в качестве решения [5].
В настоящей работе предлагается новый вариант последовательного алгоритма SVM, позволяющий проводить дообучение классификатора. Показана также эквивалентность формулировки с задачей [6] и приведены экспериментальные результаты их сравнения.
Предлагаемый здесь алгоритм не только обеспечивает эффективное разделение пространства признаков на классы, но и дает важную количественную характеристику степени перекрытия разделяемых классов – долю обучающих примеров, попадающих в зазор между двумя гиперплоскостями. Этот параметр позволяет сравнивать между собой различные варианты наборов признаков по их эффективности в отношении разделения двух рассматриваемых классов.
Машина опорных векторов
Пусть имеется набор объектов обучающей выборки ![]() и соответствующий им набор меток
и соответствующий им набор меток 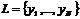 , где
, где ![]() – прецедент пространства X, в котором задано скалярное произведение,
– прецедент пространства X, в котором задано скалярное произведение, ![]() метка класса. Гиперплоскость в пространстве X может быть представлена как:
метка класса. Гиперплоскость в пространстве X может быть представлена как:
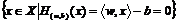 ,
,
где ![]() , а параметры
, а параметры ![]() задают гиперплоскость в пространстве X. При заданной нормали
задают гиперплоскость в пространстве X. При заданной нормали ![]() найдется пара гиперплоскостей
найдется пара гиперплоскостей ![]() , таких что:
, таких что:
| (1) | |
где |
Рис. 1. Геометрическая интерпретация на плоскости классифицирующей гиперплоскости и зазора |
|

Существуют интуитивные и теоретически подкрепленные основания полагать, что больший зазор гиперплоскостей увеличивает обобщающую способность классификатора [7]. Согласно этим аргументам оптимальную разделяющую гиперплоскость следует выбирать по максимальной величине зазора гиперплоскостей 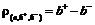 . Для поиска параметров гиперплоскостей с максимальным зазором, а также с учетом ошибок в измерениях и метках классов, может быть сформулирована следующая оптимизационная задача:
. Для поиска параметров гиперплоскостей с максимальным зазором, а также с учетом ошибок в измерениях и метках классов, может быть сформулирована следующая оптимизационная задача:
| (2) |
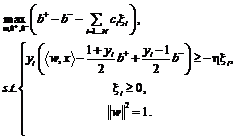
Задача (2) является задачей нелинейного программирования. Здесь ![]() – параметры регуляризации, xI – корректирующие коэффициенты для минимизации ошибки измерений [8]. Для решения задачи удобно использовать двойственную оптимизационную задачу, эквивалентную исходной, которая может быть записана в виде:
– параметры регуляризации, xI – корректирующие коэффициенты для минимизации ошибки измерений [8]. Для решения задачи удобно использовать двойственную оптимизационную задачу, эквивалентную исходной, которая может быть записана в виде:
| (3) |

здесь ![]() – скалярное произведение в пространстве
– скалярное произведение в пространстве ![]() , известное как ядровая функция
, известное как ядровая функция ![]() . Относительно параметров регуляции
. Относительно параметров регуляции ![]() справедлива следующая теорема:
справедлива следующая теорема:
Теорема (Свойства параметра h для классификации).
1. h является верхней оценкой на долю ошибок обучения (без учета зазора);
2. h является нижней оценкой на долю опорных векторов при нормировочном условии 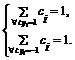
Связь между задачей (3) и широко известным методом n-SVM можно сформулировать в виде следующей теоремы:
Теорема (Об эквивалентности). Если метод n-SVM приводит к такому решению, что ![]() , то это решение совпадает с решением задачи (3) при условии равенства h = n.
, то это решение совпадает с решением задачи (3) при условии равенства h = n.
Решающая функция
В классической формулировке двухклассовой задачи классификации требуется отыскать решающую функцию ![]() . В двойственной постановке функция принятия решения принимает вид:
. В двойственной постановке функция принятия решения принимает вид:
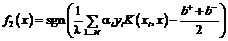 , (4)
, (4)
параметры ![]() определяются из условия дополняющей нежесткости Куна–Таккера (ККТ) [9].
определяются из условия дополняющей нежесткости Куна–Таккера (ККТ) [9].
Случай линейно разделимых данных, а также случай слабого пересечения классов достаточно редко встречается в практических задачах. Напротив, более интересен случай частичной вложенности множеств объектов разных классов в пространстве признаков Х, которому соответствует отрицательная величина зазора гиперплоскостей. В некоторых задачах более разумно использовать тернарные функции принятия решения ![]() :
:
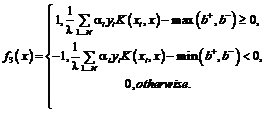 (5)
(5)
Объекты, попавшие в зазор, считаются неизвестными. Ошибка зазора формально есть: 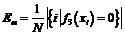 . Для оценки качества тернарного классификатора более удобно использовать эффективность классификатора, определяемую как:
. Для оценки качества тернарного классификатора более удобно использовать эффективность классификатора, определяемую как: 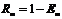 , где
, где ![]() – ошибка зазора.
– ошибка зазора.
Метод последовательной оптимизации
Наиболее оптимальные результаты решения проблем квадратичного программирования, с вычислительной точки зрения, показал метод последовательной оптимизации (SMO) [9]. Алгоритм, построенный на модификации этого метода, был разработан для решения задачи (3). Алгоритм основан на идее последовательной оптимизации параметров задачи (3) для каждого, вновь добавленного, объекта xk. Можно выделить три основных шага алгоритма:
· Insert: добавление объекта во множество опорных векторов 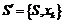 ;
;
· Solve: поиск t-квартета [11,12] и формирование для него оптимального решения;
· Remove: удаление объекта из множества S с минимальным градиентом при коэффициенте ![]()
Здесь t-квартет – четверка объектов, для которых справедливо 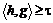 ,
, ![]() , где
, где 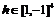 – направление поиска,
– направление поиска, ![]() – градиент функционала, а t – регулирующий допуск [11,12].
– градиент функционала, а t – регулирующий допуск [11,12].
Алгоритм последовательного обучения OnSVM
Алгоритм OnSVM состоит из последовательно выполняемых процедур: Init() – инициализация первичной модели границы из случайных опорных векторов; Process()– потоковая оптимизация примеров объектов, включая поиск оптимального решения и удаления опорных векторов; Finalize()- пост-оптимизация.
Алгоритм OnSvm
Init() Repeat at least 4 times { Fetch an example k; Run Insert(k); }
| Process() Repeat a predefined number of times { Fetch an example k; Insert(k); Solve(); Remove(); } | Finalize() Repeat while { Solve(); } Remove(); |
Процедура финализации формирует окончательную модель границы классификации с ошибкой решения оптимизационной задачи не более чем d.
Рассмотренный алгоритм основан на простом и эффективном методе SMO. Вопрос сходимости этого метода в его обобщенной формулировке (GSMO) подробно рассмотрен в работе [13]. Легко убедиться, что алгоритм OnSVM является алгоритмом GSMO и удовлетворяет условиям теоремы о сходимости. Для любого заданного положительного ![]() , алгоритм сходится за конечное число шагов k.
, алгоритм сходится за конечное число шагов k.
Вычислительный эксперимент
Апробация предложенного алгоритма была проведена на базе данных MINIST ручного начертания цифр, доступной на сайте http://ftp. ics. uci. edu/pub/machine-learning-databases/. Задача классификации была в отделении каждой цифры от всех остальных цифр в наборе 0-9, данные разделялись на тренировочную и тестовую группы в соотношении 2:1. В экспериментах использовались данные Optdigits[1] и Pendigits[2], на которых предложенный здесь алгоритм 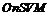 сравнивался с известной ранее реализацией
сравнивался с известной ранее реализацией ![]() -SVM из открытой библиотеки машинного обучения LIBSVM 3.10 при ядровой функции гауссова типа
-SVM из открытой библиотеки машинного обучения LIBSVM 3.10 при ядровой функции гауссова типа 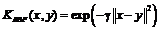 . Использованы значения параметров
. Использованы значения параметров ![]() .
.
В табл. 1 приведены результаты сравнения алгоритмов ![]() и
и ![]() на базе Pendigits, здесь <Num> – класс распознавания; <nSV> – количество опорных векторов, <nSV Max> – пиковое количество опорных векторов на эпохе обучения; <
на базе Pendigits, здесь <Num> – класс распознавания; <nSV> – количество опорных векторов, <nSV Max> – пиковое количество опорных векторов на эпохе обучения; <![]() > – ошибка классификации на тестовых примерах в режиме бинарного классификатора (4); <
> – ошибка классификации на тестовых примерах в режиме бинарного классификатора (4); <![]() > – ошибка тернарного классификатора (5); <
> – ошибка тернарного классификатора (5); <![]() > – эффективность тернарного классификатора.
> – эффективность тернарного классификатора.
В табл. 1 приведены также величины ошибок распознавания в режиме тернарного классификатора (5). Возрастание обобщающей способности алгоритма в этом режиме работы классификатора может значительно повышаться за счет ухудшения эффективности классификатора – уменьшения количества примеров, по которым классификатор принимает решение о присвоении метки класса.
Таблица 1
Сравнительные результаты работы алгоритма для набора Pendigits
Num | OnSVM | LIBSVM | |||||
nSV | nSV Max | Е2, % | Е3, % | R3, % | nSV | Е2, % | |
0 | 1036 | 1046 | 0,60 | 0,00 | 74,80 | 1267 | 0,60 |
1 | 963 | 991 | 0,40 | 0,00 | 71,40 | 1267 | 0,34 |
2 | 1168 | 1285 | 0,11 | 0,00 | 79,54 | 1143 | 0,11 |
3 | 827 | 959 | 0,28 | 0,03 | 86,00 | 872 | 0,28 |
4 | 957 | 979 | 0,34 | 0,00 | 75,85 | 1218 | 0,37 |
5 | 884 | 906 | 0,48 | 0,00 | 74,70 | 1157 | 0,43 |
6 | 858 | 880 | 0,17 | 0,00 | 75,73 | 1186 | 0,14 |
7 | 934 | 966 | 1,03 | 0,00 | 73,10 | 1186 | 1,03 |
8 | 1117 | 1126 | 0,11 | 0,00 | 73,79 | 1354 | 0,11 |
9 | 1032 | 1046 | 0,49 | 0,08 | 72,73 | 1291 | 0,51 |
Total | 978.1 | 1018.4 | 0.4 | 0.01 | 75.76 | 1149.1 | 0.39 |
Параметр <nSV Max> позволяет оценить максимальный объем памяти, необходимый для кеширования ядровой матрицы. Кеширование ядровых функций значительно ускоряет процесс обучения, но размер памяти, требующийся для кеша, пропорционален квадрату количества обучаемых векторов. В алгоритме OnSVM необходимый размер памяти пропорционален параметру <nSV Max>. В проведенных вычислительных экспериментах этот параметр не отличался от общего количества опорных векторов более чем на 5%.
На рис. 2 и 3 показаны результаты усреднения измерений параметров 10-ти классификаторов на наборе данных Pendigits для каждой из цифр. Рис. 2 показывает зависимость количества опорных векторов от параметра h в сравнении с реализацией LIBSVM и зависимость ошибки ![]() от h рассматриваемых алгоритмов. Рис. 3 показывает зависимости ошибки Е2 и эффективности R3 от параметра h.
от h рассматриваемых алгоритмов. Рис. 3 показывает зависимости ошибки Е2 и эффективности R3 от параметра h.
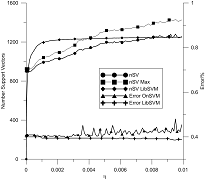
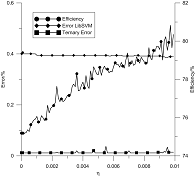
Рис. 2. Количество поддерживающих векторов и ошибки систем OnSVM и LIBSVM в зависимости от параметра h | Рис. 3. Зависимость эффективности и уровня ошибок от параметра h |
Заключение и выводы
Проведенное исследование позволяет заключить следующее:
1. Решение алгоритма OnSVM сходится к решению n-SVM и позволяет достичь приемлемого качества решения за один проход по обучающим примерам.
2. Количество опорных векторов в решении алгоритма OnSVM в среднем меньше чем у точного решения SVM, при эквивалентном качестве.
3. Результаты работы бинарных классификаторов для алгоритмов OnSVM и LIBSVM оказываются достаточно близки, при этом использование тернарного классификатора в алгоритме OnSVM существенно уменьшает ошибки распознавания при незначительном падении эффективности.
4. Поскольку при кешировании значений ядровой матрицы рост требуемой памяти пропорционален квадрату числа обучающих векторов, то предложенный последовательный алгоритм нуждается в меньшем количестве памяти, при тех же временных затратах.
Список литературы
1. Cristianini N., J. Shawe-Taylor J., An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods. //Cambridge University Press, 2000.
2. Cauwenberghs G., Poggio T. Incremental and decremental support vector machine learning //Advances in Neural Information Processing Systems, 2000. Р. 409–415.
3. Bordes A., Ertekin S., Weston J., Bottou L. Fast kernel classifiers with online and active learning // Journal of Machine Learning Research, 2005. v. 6. Р. 1579–1619.
4. Roobaert, D.: DirectSVM: A Simple Support Vector Machine Perceptron.//VLSI Signal Processing, 2002. Р. 147-156.
5. Orabona F., Castellini C., Caputo B., Jie L., Sandini G. On-line independent support vector machines //Pattern Recognition, 2010, Т. 43. Р..
6. Schoelkopf B., Smola A. New Support Vector Algorithms //NeuroCOLT Technical Report NC2-TR, 1998.
7. Vapnik V. Estimation of Dependences Based on Empirical Data. Springer-Verlag, Berlin, 1982.
8. Н (ред.). Алгоритмы и программы восстановления зависимостей. М.: Физматлит, 1984.
9. Platt J. Fast training of support vector machines using sequential minimal optimization. //Scholkopf B., Burges C. J. C., Smola A. J., editors, Advances in Kernel Methods – Support Vector Learning, pages 185–208, Cambridge, MA, 1999. MIT Press.
10., X. Метод коллективного распознавания. М.: Энергоиздат, 1981.
11.Chang C.-C., Lin C.-J. LIBSVM: a library for support vector machines. //Technical report, Computer Science and Information Engineering, National Taiwan University, . http://www. csie. ntu. edu. tw/_cjlin/libsvm.
12.Collobert R., Bengio S.. SVMTorch: Support vector machines for large-scale regression problems. //Journal of Machine Learning Research, 2001, 1:143–160.
135. Keerthi S. S., Gilbert E. G. Convergence of a generalized SMO algorithm for SVM classifier design.// Machine Learning, 2002, 46:351–360.
[1] ftp://ftp. ics. uci. edu/pub/machine-learning-databases/optdigits/
[2] ftp://ftp. ics. uci. edu/pub/machine-learning-databases/pendigits/
