

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Почти во всех машинных приложениях множество объектов должно быть размещено в соответствии с некоторым заранее определенным порядком. Например, расположить данные по алфавиту или по возрастанию номеров.
Пусть имена x1, …, xn заданы в виде таблицы. Каждое имя xi принимает значение из пространства имен, на котором определен линейный порядок. Далее мы считаем, что никакие 2 имени не имеют одинаковых значений, т. е. любые xi, xj обладают тем свойством, что если i ¹ j, то либо xi предшествует xj, либо наоборот [3].
Ограничение xi ¹ xj при i ¹ j упрощает анализ без потери общности, т. е. корректность идей и алгоритмов не нарушается. Цель сортировки состоит в том, чтобы выполнить перестановку 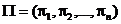 , для которой
, для которой ![]() .
.
В задачах частичной сортировки требуется извлечь либо частичную информацию о П (например, pi для нескольких значений i), либо полностью определить П по заданной частичной информации о ней (так обстоит дело при слиянии двух упорядоченных таблиц).С каждой записью xi в последовательности x1, …, xn сопоставим некоторый ключ ‘k’. Ключом обычно является некоторое поле внутри записи. Говорят, что файл отсортирован по ключу, если для i < j следует, что ki предшествует kj при некоторой упорядоченной последовательности по ключам. В качестве примера рассмотрим телефонный справочник. Файл состоит из всех строчек этого справочника. Каждая строчка является записью. Ключом, по которому отсортирован этот файл, является поле фамилия в записи. Каждая запись содержит также поле для адреса и номера телефона.
Сортировка может быть классифицирована как внутренняя, если записи, которые сортируются, находятся в оперативной памяти, или как внешняя, если некоторые из записей, которые сортируются, находятся во вспомогательной внешней памяти.
Вполне возможно, что две записи в некотором файле имеют одинаковый ключ. Метод сортировки называется устойчивым, если для всех записей i и j таких, что k(i) = k(j), выполняется условие, что в отсортированном файле xi предшествует xj, если xi предшествует xj в первоначальном файле.
Сортировка выполняется или над самими записями или над указателями этих записей, которые содержатся во вспомогательной таблице.
Пример.
а) первоначальный файл б) отсортированный файл
ключ | информация | ключ | информация | |
4 | DDD | 1 | AAA | |
2 | BBB | 2 | BBB | |
1 | AAA | 3 | CCC | |
5 | EEE | 4 | DDD | |
3 | CCC | 5 | EEE |
Рис. 2.3.1. Сортировка записей





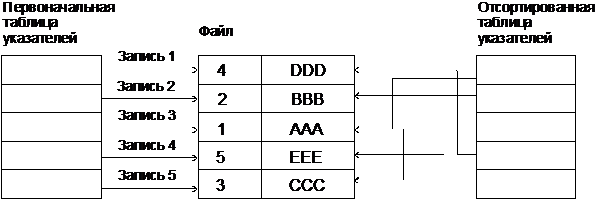 |
Предположим, что объем данных, помещенных в каждую из записей файла, такой большой, что перемещение самих записей является нецелесообразным. В этом случае может быть использована вспомогательная таблица указателей.
Рис. 2.3.2. Сортировка, использующая вспомогательную таблицу указателей
Так что вместо перемещения самих данных перемещаются эти указатели. Это называется сортировкой таблицы адресов.
Из-за взаимосвязи между сортировкой и поиском первым вопросом, который стоит, является вопрос о необходимости сортировки. Иногда при непосредственном поиске конкретного элемента в некотором множестве элементов затрачивается меньше работы, чем при сортировке данного множества и извлечении из него после сортировки необходимого элемента. С другой стороны, если в целях извлечения конкретных элементов требуется частое использование данного файла, то сортировка целесообразна. Она дает эффективность за счет того, что расходы (ресурсы, время) на следующие один за другим поиски могут существенно превысить расходы на выполнение разовой сортировки файла и последующего извлечения элементов из него. Программист должен принять соответствующее решение — выполнять сортировку или нет. Кроме того, программист помимо решения, что сортировать, должен выбрать как сортировать, т. е. метод сортировки. В настоящее время не существует метода сортировки, который бы во всем превосходил остальные.
Внутренняя сортировка
Существует, по крайней мере, пять широко известных способов, применяемых в алгоритмах внутренней сортировки.
1. Вставка. На i-м этапе i-е имя помещается на надлежащее место c i-1 уже отсортированными именами.
2. Обмен. Два имени, расположение которых не соответствует порядку, меняются местами (обмен). Эта процедура повторяется, пока существуют такие пары.
3. Выбор. На i-м этапе из неотсортированных имен выбирается i-е наибольшее (наименьшее) имя и помещается на соответствующее место.
4. Распределение. Имена распределяются по группам, и содержимое групп затем объединяется таким образом, чтобы частично отсортировать таблицу; процесс повторяется до тех пор, пока таблица не будет отсортирована полностью.
5. Слияние. Таблица делится на подтаблицы, которые сортируются по отдельности и затем сливаются в одну.
Эти классы нельзя назвать ни взаимоисключающими, ни исчерпывающими. Они
удобны для классификации алгоритмов сортировки. В рассматриваемых алгоритмах имена образуют последовательность x1, …, xn. Значением xi является любое текущее имя i позиции последовательности. В каждом из рассматриваемых алгоритмов будем считать, что имена нужно сортировать на месте, т. е. перемещение имен должно происходить внутри последовательности x1, …, xn. При этом существует одна или две дополнительные ячейки, в которых временно размещается значение имени.
Ограничение «сортировка на месте» основано на предположении, что число имен настолько велико, что во время сортировки не допускается перенос их в другую область памяти.
Сравнение эффективности алгоритмов сортировки
Чтобы получить некоторое представление об ожидаемой эффективности, рассмотрим задачу сортировки с теоретической точки зрения.
Один из способов оценки эффективности алгоритмов сортировки состоит в подсчете числа сравнений имен ‘xi: xj’ за время сортировки. Эта характеристика не всегда является определяющей, но для большинства алгоритмов она является хорошей мерой производимой работы. Будем рассматривать алгоритмы, основанные на абстрактном линейном упорядочении пространства имен: для любой пары имен xi, xj при i ¹ j либо xi < xj, либо xi > xj.
Любой такой алгоритм можно представить в виде расширенного бинарного дерева решений, в котором каждый внутренний узел соответствует сравнению имен, и каждый лист (внешний узел) — исходу алгоритма. Это дерево можно рассматривать как блок-схему алгоритма сортировки, в котором все циклы «размотаны» и показаны только сравнения имен.
Пример. Рассмотрим сортировку элементов массива {x1, x2, x3} с использованием бинарного дерева.
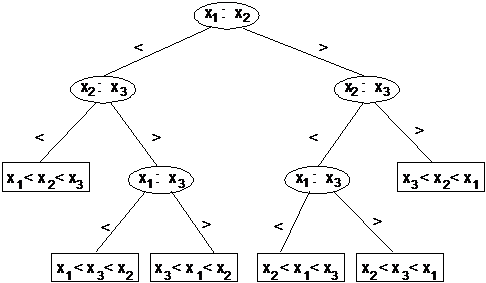
Рис. 2.3.3. Бинарное дерево решений для сортировки трех имен
В любом таком дереве решений каждая перестановка определяет единственный путь от корня к листу. Листья, соответствующие разным перестановкам, должны быть разными. Тогда ясно, что в дереве решений для сортировки n имен должно быть по крайней мере n! листьев (n! — количество перестановок из n).
Заметим, что высота дерева решений h равна числу сравнений, требующихся алгоритму в наихудшем случае.
Поскольку бинарное дерево высоты h может иметь не больше 2h листьев, заключаем что
т. к.
Таким образом, любой алгоритм сортировки, основанный на сравнении имен, в наихудшем случае потребует не меньше n lg n сравнений.
Длина внешних путей дерева решений равна сумме всех расстояний от корня до листьев, деление ее на n! дает среднее число сравнений для соответствующего алгоритма.
Простая сортировка вставками
На этапе j имя xj вставляется на свое правильное место среди x1, x2, …, xn. При вставке xj временно размещается в ячейке X и просматриваются имена xj-1, xj-2, …, x1. Они сравниваются с Х и сдвигаются вправо, если обнаруживается, что они больше Х. Имеется фиктивное имя x0, значение которого –¥ служит для остановки просмотра слева.
| x0 – ¥ for j = 2 to n do | i j – 1 X xj while X < xi do xi+1 X | xi+1 xi i i – 1 |
| |||
x0 | x1 | x2 | x3 | x4 | x5 | ||
– ¥ |
| 7 | 2 | 4 | 6 | j=2 | |
– ¥ |
| 8 | 2 | 4 | 6 | j=3 | |
– ¥ | 2 |
| 8 | 4 | 6 | j=4 | |
– ¥ | 2 | 4 |
| 8 | 6 | j=5 | |
– ¥ | 2 | 4 | 6 | 7 | 8 | ||
Рис. 2.3.4. Простая сортировка вставками для пяти имен.
Пунктирные вертикальные линии разделяют уже отсортированную часть таблицы от еще не отсортированной.
Приведем программную реализацию алгоритма на основе языка С++.
#include "stdafx. h"
#include <math. h>
#include <iostream>
using namespace std;
#include <conio. h>
void main ()
{
int A[20],X; //Х - временное хранение выносимой переменной
int i, n,j, FLAG, k=1; // k - число проходов, необходимых для сортировки
cout<<"Enter the ize of dimension A[] , n= ";
cin>>n;
cout<<"\n Enter items of dimension: \n";
for(i=1;i<n;i++) cin>>A[i];
while(k<n)
{
A[0]=-1;
FLAG=0;
// FLAG=1 признак наличия в цикле вставки Х в найденное место
for(i=1;i<n;i++)
{
if(FLAG==1) break; // проход завершен, Х найден
if(A[i]<A[i-1])
{
X=A[i];
A[i]=A[i-1];
for(j=i-2;j>=0;j--)
{
if((A[j]<X)&&(FLAG==0))
{
A[j+1]=X;
FLAG=1;
j=-1;
}
if(A[j]>X)A[j+1]=A[j]; //сдвиг вправо
}
}
}
if(FLAG==0) break;
// выход из цикла, т. к. массив чисел уже отсортирован
k++;
}
cout<<"\n Result: \n";
for(i=1;i<=n;i++) cout<<A[i]<<" ";
_getch();
}
Быстрая сортировка Хоара. Сортировка методом пузырька
Основная идея, на которой базируется метод быстрой сортировки Хоара, состоит в том, чтобы взять одну из записей, скажем R1, и передвинуть ее на то место, которое она должна занять после сортировки, скажем в позицию S.
В поиске этой окончательной позиции придется несколько перекомпоновать и остальные записи таким образом, чтобы слева от позиции S не оказалось ни одной записи с большим ключом, а с права — с меньшим. В результате последовательность окажется разбитой таким образом, что исходная задача сортировки всего массива записей будет сведена к задачам независимой сортировки пары массивов R1… Rs-1 и Rs+1… RN меньшей длины.
Предположим, что нам даны n элементов. Их нужно рассортировать по возрастанию. Выберем средний элемент. Обозначим его через Х. Разобьем массив на 2 части. Зафиксируем средний элемент. Сначала поменяем местами самый левый и самый правый элементы, для которых характерно, что левый элемент больше правого элемента. Так постепенно продвигаемся с двух концов к середине.
4418 67 — 1 проход
ai<X X aj >X
 |
18 5506— 2 проход
ai<X Х aj>X
![]()
![]() 55 44 67
55 44 67
<X Х >X
В результате массив разделился на 2 части, левую и правую — с ключами, меньшими и большими Х соответственно. Для продолжения сортировки применим выше изложенный алгоритм к первой и второй частям и т. д.
Приведем программную реализацию алгоритма Хоара на языке С++.
#include "stdafx. h"
#include <math. h>
#include <iostream>
using namespace std;
int n;
void xoor(int*,int, int, int);
main()
{
int A[40],i; // Инициализация
cout<<"Input n= \n";
cin>>n;
cout<<" Enter items of array A:\n";
for(i=0;i<=n-1;i++) scanf("%d",&A[i]);
xoor(A,0,n-1,n);
cout<<" Selected array A: \n";
for(i=0;i<=n-1;i++)printf(" %d ",A[i]);
return 0;
}
// РЕКУРСИЯ
void xoor(int* A, int m, int l, int n)
{
int i, j=l, k=0,p, X=A[(m+l)/2];
for(i=m;i<=(l+m)/2;i++)
{
if(((A[i]>X) && (A[j]<=X))||(A[i]> A[j]))
{
p=A[j];
A[j]=A[i];
A[i]=p;
xoor(A, m,l, n);
}
else i--;
j--;
if(j==(l+m)/2)
{
i++;
j=l;
}
}
for(i=0;i<=n-1;i++)
{
if(A[i]<A[i+1])k=k+1;
}
if(k==n) return;
if (m<(l-1)) // сортировка правой части от m до l
{
m=(l+m)/2;
xoor(A, m,l, n);
}
else // сортировка левой части от l/2 элемента до m
{
l=m;
m=l/2;
if(l!=0)xoor(A, m,l, n);
}
}
Сортировка «методом пузырька»
Идея, лежащая в основе сортировки «методом пузырька» заключается в следующем. Файл просматривается несколько раз последовательно. Каждый просмотр состоит из сравнения каждого элемента xi файла со следующим за ним элементом xi+1 и «обмена» (транспозиции) этих элементов, если они располагаются не в нужном порядке [3].
Например, задан файл 25, 57, 48, 37, 12, 92, 86, 33. Требуется отсортировать записи, расположив их по возрастанию значений элементов файла. Действия сортировки оформим в виде таблицы.
Итерация | Файл |
| 25, 57, 48, 37, 12, 92, 86, 33 |
1 | 25, 48, 37, 12, 57, 86, 33, 92 |
2 | 25, 37, 12, 48, 57, 33, 86, 92 |
3 |
|
4 |
|
5 | 12, 25, 33, 37, 48, 57, 86, 92 |
Эффективность «метода пузырька» считается следующим образом. Имеется в худшем случае n–1 просмотров файла и n–1 сравнений в каждом просмотре. Таким, образом, общее число сравнений равно (n–1) (n–1) = n2 – 2n +1, что составляет »n2.
Единственным плюсом «метода пузырька» является то, что для такой сортировки требуется мало дополнительного пространства (одна дополнительная запись для временного хранения той записи, для которой выполняется транспозиция, и несколько простых целых переменных).
Сортировка методом «турнира с выбыванием»
Действия метода отражают процесс разыгрывания некоторого турнира, где его участники состязаются друг с другом для определения наилучшего игрока. Эта сортировка также называется сортировкой посредством выбора из дерева. Рассмотрим некоторый турнир в виде дерева [3].
 |
Такое дерево можно понимать следующим образом: Кейс играла в турнире с Гейл и проиграла, т. е. победила Гейл и ее имя помещается в узел дерева и т. д. То есть на представленном дереве показан турнир, в котором победила Гейл. А кто занял 2-е место? А 3-е место? Решение на основе просмотра дерева от листьев к корню позволяет сделать вывод, что 2-е место заняла Пэт, а Джордж с Фрэнком поделили 3-е место, т. е. Гейл выиграла 3 игры, а Пэт выиграла 2 игры, а Джорд с Фрэнком выиграли по 1 игре.
Рассмотрим тот же подход, но уже к сортировке чисел. Каждому первоначальному элементу приписывается некоторый узел с листом в некотором бинарном дереве. Это дерево строится снизу вверх от узлов с листьями до корня следующим образом. Выберем 2 узла с листьями и положим, что они являются сыновьями некоторого заново созданного узла, представляющего отца. Содержимое узла, являющееся отцом, устанавливается равным наибольшему из чисел, представляющих его сыновей.
Этот процесс повторяется до тех пор, пока не останется один лист или их совсем не останется. Если останется один лист, то этот узел надо переместить вверх на следующий уровень. Теперь этот процесс надо повторить с заново созданными узлами до тех пор, пока самое большое число не будет помещено в узел, являющийся корнем бинарного дерева, чьи листья содержат все числа из первоначального файла. Содержимое этого узла может быть затем выведено как самый большой элемент и т. д. пока не будут выведены все первоначальные элементы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
