

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вставка в индексно-последовательную таблицу является более трудной, поскольку между двумя уже существующими элементами таблицы может не быть свободного места, что приводит к необходимости сдвигать большое число элементов таблицы. Однако, если некоторый недалеко расположенный элемент в таблице был отмечен флагом как удаленный, то необходимо сдвинуть только часть элементов и поверх удаленного элемента может быть записана новая информация. Это в свою очередь может привести к необходимости изменения индекса, если элемент, на который указывал некоторый элемент индекса, был сдвинут.
В общем случае, когда инициализируется некоторая таблица, по всей таблице расставляются пустые записи, чтобы оставить место для вставок. Другой подход состоит в том, чтобы в некотором другом месте иметь некоторую область переполнения, а вставляемые записи связывать между собой. Однако для этого потребуется дополнительное поле указателя в каждой записи первоначальной таблицы. Возможное решение этой проблемы состоит в том, чтобы иметь только один указатель после каждой группы записей. Таким образом, если вставляется новая запись в соответствующее ей место, то все записи после вставленной сдвигаются на одну позицию. Если последняя запись данной группы попадает за пределы отведенной области, то она должна помещаться в область, на которую указывает указатель группы свободных ячеек.
Бинарный поиск
Наиболее эффективным методом поиска в упорядоченном массиве без использования вспомогательных индексов или таблиц является бинарный поиск. Упрощенно этот метод состоит в том, что аргумент сравнивается с ключом среднего элемента таблицы. Если они равны, то поиск успешно закончился. В противном случае поиск должен быть осуществлен аналогичным образом в верхней или нижней половине таблицы [3].
Известно, что бинарный поиск наилучшим образом может быть определен рекурсивно. Однако большие накладные расходы, связанные с рекурсией (память, время), делают ее неподходящей для использования в практических ситуациях, в которых эффективность является главным фактором. Рассмотрим не рекурсивную версию алгоритма бинарного поиска:
low=l; hi=n; search = 0;
while (low<=hi)
{
mid=(low + hi)/2;
if (key= = k[mid])
{
search = mid;
cout<<”Элемент найден. Его номер=”<< mid;
return 0;
}
else
{
if ( key<k[mid]) hi =mid-1;
else low = mid+1;
}
}
Каждое сравнение в бинарном поиске уменьшает число возможных кандидатов сравнения в 2 раза. Таким образом, максимальное число сравнений ключа, которые будут сделаны, составляет приблизительно log2n, т. е. алгоритм бинарного поиска имеет порядок O(log2n).
Отметим, что бинарный поиск может быть использован вместе с индексно-последовательной организацией таблицы и вместо последовательного поиска по индексу может быть использован бинарный поиск. Бинарный поиск может быть также использован при поиске в основной таблице, когда идентифицированы две граничные записи. Бинарный поиск практически бесполезен в ситуациях, где имеется много вставок или удалений.
Сбалансированные деревья (AVL-деревья)
Для удобства определим высоту пустого дерева как 0.
Баланс некоторого узла в дереве определяется как высота его левого поддерева минус высота его правого поддерева.
Сбалансированным бинарным деревом (деревом AVL) является такое бинарное дерево, у которого абсолютное значение баланса каждого узла £1.
 |
Рис. 2.4.3. Сбалансированное бинарное дерево
Поиск по дереву
Ранее мы рассматривали построение бинарного дерева, в котором все левосторонние потомки некоторого узла с ключом key имели ключи, которые < key, а все правосторонние потомки имели ключи >= key [3].
Прохождение такого бинарного дерева в симметричном порядке дает файл, упорядоченный по возрастанию значения ключа. Такое дерево может быть использовано для бинарного поиска. Алгоритм поиска ключа key в бинарном дереве представляется следующим образом. Предполагаем, что каждый узел дерева содержит четыре поля: поле k, в котором хранится значение ключа данной записи; поле r, в котором хранится сама запись; поля left и right, которые являются указателями на поддеревья:
class item
{
public:
item *left; item *right ;
int k; char r;
};
void main()
{
item * p; // создается объект р
item * search=NULL;
…
while( p!=NULL)
{
if (p->k==key) search=p;
if( p->k>key) p=p->left;
if (p->k<key) p=p->right;
}
Отметим, что бинарный поиск фактически использует отсортированный массив как некоторое неявное дерево бинарного поиска. Средний элемент этого массива можно представить как корень такого дерева. Левую (верхнюю) половину массива (все те элементы, которые меньше чем средний элемент) можно рассматривать как левое поддерево, а правую (нижнюю) половину (все те элементы, которые больше чем средний элемент) можно рассматривать как правое поддерево.
Отсортированный массив может быть получен из дерева бинарного поиска при помощи прохождения этого дерева в симметричном порядке и вставки каждого элемента последовательно в некоторый массив по мере того, как он встречается в дереве. С другой стороны, для некоторого заданного отсортированного массива можно построить несколько соответствующих ему деревьев бинарного поиска. Рассматривая средний элемент массива как корень некоторого дерева и рассматривая рекурсивно оставшиеся элементы как левые и правые поддеревья, мы получим некоторое относительно сбалансированное дерево бинарного поиска (рис. 2.4.4). Рассматривая первый элемент массива в качестве корня дерева, а каждый последующий элемент как правого сына его предшественника, мы получим сильно разбалансированное дерево (рис. 2.4.5).
Преимущество использования дерева бинарного поиска перед отсортированным массивом заключается в том, что структура дерева позволяет выполнять эффективно операции поиска, вставки и удаления.
30 | a1 |
47 | a2 |
86 | a3 |
95 | a4 |
115 | a5 |
130 | a6 |
138 | a7 |
159 | a8 |
166 | a9 |
184 | a10 |
206 | a11 |
212 | a12 |
219 | a13 |
224 | a14 |
237 | a15 |
258 | a16 |
296 | a17 |
307 | a18 |
314 | a19 |
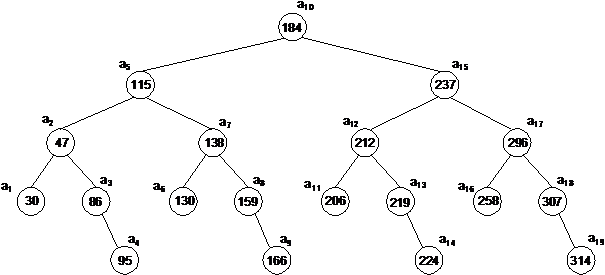 |
Рис. 2.4.4
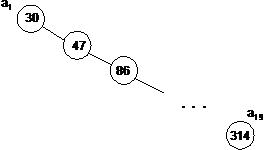 |
Рис. 2.4.5
Вставка в дерево бинарного поиска
Рассмотрим алгоритм организации поиска по некоторому бинарному дереву со вставкой новых записей в такое дерево, если поиск неудачен.
 |
{часть программы}
class item
{
public:
char name;
int k;
item * left; // указатели
item *right;
item(char, item *, item *, int ); // конструктор
~item(); // деструктор
};
class tree
{
public:
tree * g; // указатель на начало прохода дерева
};
…
void main()
{
tree *p= new tree;; // создается объект - дерево
int search=0; // 1 — признак нахождения ключа
item *l,r; // указатели левого и правого полей
item *q,p;
…
q= NULL; // q — указатель на отца, если он существует
p=g; // g — указатель на начало прохождения дерева
while( p!=NULL)
{
if (key==p->k) search=1;
else
{
q:=p;
if( key<p->k ) p=p->left;
else p=p->right;
}
}
if (search==1)
{
cout<<”ключ найден\n”;
return;
}
else
{
сout<<”ключ не найден\n”;
// вставка информации с ключом
item *v=new item(rec, l,r, key);
v->name=rec; // rec - запись
v->k=key;
if (q==nil) // дерево было пусто изначально
*tree==v;
else // дерево не было пусто
{
if( key<q->k)
{
v->left=q->left;
q->left=v;
}
else
{
v->right=q->right;
q->right=v;
}
}
}
…
Отметим, что после того, как будет вставлена некоторая новая запись, данное дерево сохранит то свойство, что при прохождении его в симметричном порядке получится отсортированный массив.
Удаление из дерева бинарного поиска
При удалении необходимо рассмотреть три случая [3]:
1. Если удаляемый узел не имеет сыновей, то он удаляется без дальнейшей настройки дерева (рис. 4.6 (а)).
2. Если удаляемый узел имеет только одно поддерево, то его единственный сын может быть помещен вверх, чтобы занять его место (рис. 2.4.6 (б)).
3. Если удаляемый узел p имеет два поддерева, то его приемник s в симметричном порядке (или его предшественник в симметричном порядке) должен занять его место. Потомок в симметричном порядке не может иметь левого поддерева (поскольку, если бы он имел его, левый потомок был бы приемником p в симметричном порядке). Таким образом, правый сын элемента s может быть перемещен вверх, чтобы занять место s (рис. 4.6 (в)).
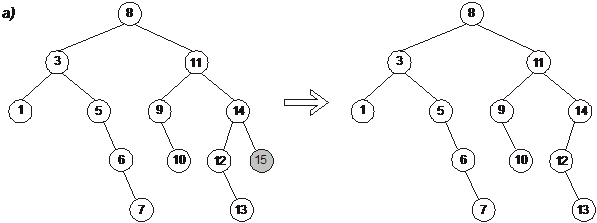
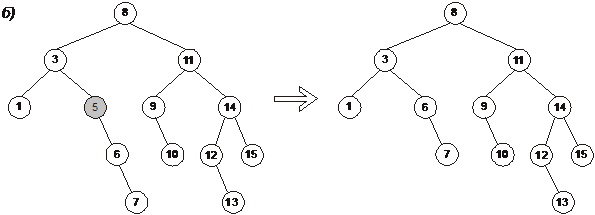
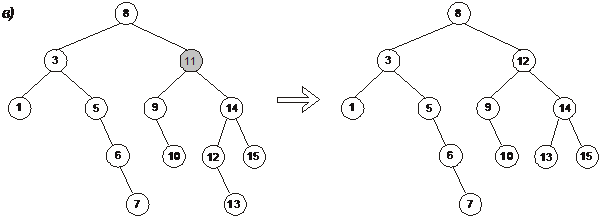
Рис. 2.4.6. Удаление узлов из дерева бинарного поиска
а — удаление узла с ключом 15;
б — удаление узла с ключом 5;
в — удаление узла с ключом 11
В приводимом ниже алгоритме дерево остается неизменным, если в нем не существует узла с ключом key.
…
p=tree;
q=NULL;
// Поиск узла с ключом key. Установить p так, чтобы оно указывало
// на данный узел, а q — на его отца, если он существует
while( (p!=NULL) && (p->k!=key))
{
q=p;
if( key<p->k) p=p->left;
else p=p->right;
}
if (p==NULL)
{
cout<<”такого ключа нет в дереве. Дерево остается не измененным \n”;
return;
}
// Установить в переменную v узел, который заменит p.
// Удаляемый узел имеет максимум одного сына
if (p->left==NULL) v=p->right;
else (if p->right==NULL) v=p->left;
else // узел p имеет двух сыновей
// Установить в v преемника p в симметричном порядке,
// а в переменную t — отца переменной v
t=p;
v=p->right;
s=v->left; // s — левый сын v
while (s!=NULL)
{
t=v;
v=s;
s=v->left;
}
// В этот момент переменная v является преемником узла p
// в симметричном порядке
if (t!=p)
// p является отцом переменной v, и v=t->left.
// Удалить узел v из его текущей позиции и заменить его на правого сына узла v
t->left=v->right;
// настроить сыновей v так, чтобы они были сыновьями p
v->right=p->right;
v->left=p->left;
// вставить узел v в позицию, которую ранее занимал узел p
if (q==NULL) // узел p был корнем дерева
tree=v;
else if( p==q->left) q->left=v;
else q->right=v;
delete v;
…
Хеширование
Мы рассматривали методы поиска. Очевидно, что эффективными из них являются те, которые минимизируют число сравнений ключей друг с другом. В идеале желательно иметь такую организацию таблиц, при которой не было бы ненужных сравнений.
Рассмотрим возможность такой организации. Если каждый ключ должен быть извлечен за один доступ, то положение записи внутри такой таблицы может зависеть только от данного ключа. Оно не может зависеть от расположения других ключей, как это имеет место в дереве [3].
Наиболее эффективным способом организации такой таблицы является массив, где каждая запись хранится по некоторому конкретному смещению по отношению к базовому адресу таблицы. Если ключи записей являются целыми числами, то сами ключи могут использоваться как индексы в массиве. До трех цифр ключа такой подход применим, но если ключ должен состоять из 7 цифр. Как быть в этом случае? Необходим некоторый метод преобразования ключа в какое-либо целое число внутри ограниченного диапазона. В идеале в одно и то же число не должны преобразовываться два различных ключа. К сожалению, такого идеального метода не существует.
Рассмотрим подходы, которые приближаются к идеальному. Вернемся к задаче поиска по ключу, состоящему из 7 цифр. Если использовать массив для записей, то в качестве индекса записи в этом массиве попробуем использовать три последние цифры.
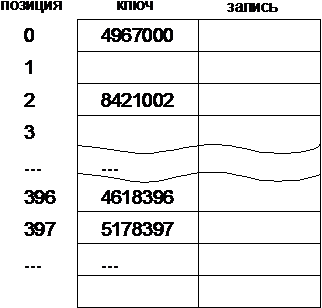
Рис. 2.4.7. Записи, хранящиеся в массиве
Такой подход целесообразен, когда в массиве не более 1000 записей. Функция, которая трансформирует ключ в некоторый индекс таблицы, называется хеш-функцией. Если h — хеш-функция, а key — некоторый ключ, то h(key) — значение хеш-функции от ключа key и является индексом, по которому должна быть размещенна запись с ключом key. Если обозначить остаток от деления x на y как mod(x,y), то хеш-функция для вышеприведенного примера есть h(key) = mod(key, 1000). Значения, которые выдает функция h, должны покрывать все множество индексов в таблице.
Этот метод имеет один недостаток. Предположим, что существуют два ключа k1 и k2 такие, что h(k1) = h(k2). Когда запись с ключом k1 вводится в таблицу, она вставляется в позицию h(k1). Но когда хешируется ключ k2, получаемая позиция является той же позицией, в которой хранится запись с ключом k1. Ясно, что две записи не могут занимать одну и ту же позицию. Такая ситуация называется коллизией при хешировании или столкновением. В примере рассмотренном выше коллизия при хешировании произойдет, если в таблицу будет добавлена запись с ключом 0596396. Далее рассмотрим возможности, как найти выход из такой ситуации. Следует отметить, что хорошей функцией является такая функция, которая минимизирует коллизии и распределяет записи равномерно по всей таблице. Поэтому желательно иметь массив размером больше, чем число реальных записей. Отметим, что определенная хеш – функция используется для заполнения информационной таблицы и по ней же потом идет поиск и, при необходимости, вставка данных.
Разрешение коллизий при хешировании методом открытой адресации
Вернемся к вопросу возникшей коллизии при вставке записи с ключом 0596396 в имеющийся массив записей и с хеш-функцией mod(key, 1000).
Самым простым способом разрешения возникшей коллизии является помещение записи 0596396 в следующую свободную позицию в массиве. Например, если ячейка свободна, то можно поместить запись туда. Этот метод называется линейным опробованием, и он является примером некоторого общего метода разрешения коллизий при хешировании, который называется повторным хешированием или открытой адресацией. В общем случае функция повторного хеширования rh воспринимает один индекс в массиве и выдает другой индекс. Если ячейка массива h(key) уже занята некоторой записью с другим ключом, то функция rh применяется к значению h(key) для того, чтобы найти другую ячейку, куда может быть помещена эта запись. Если ячейка rh(h(key)) также занята, то хеширование выполняется еще раз и проверяется ячейка rh(rh(h(key))). Этот процесс продолжается до тех пор, пока не будет найдена пустая ячейка [3].
Например, если h(key) = mod(key,1000), то в качестве rh функции можно взять функцию mod(i+1,1000), т. е. повторное хеширование какого-либо индекса есть следующая последовательная позиция в данном массиве, за исключением того случая, что повторное хеширование 999 дает 0.
Любая функция rh(i) = mod(i+c, m), где с — константа, такая что c и m являются взаимно простыми числами (т. е. они одновременно не могут делиться нацело ни на какое число, кроме 1), выдает последовательные значения, которые распространяются на всю таблицу.
Рассмотрим ситуацию, возникающую при повторном хешировании, которая называется скучиванием.
 |
Рис. 2.4.8
Обратимся к Рис. 2.4.8, из которого видно, что помещение записи в позицию 994 в пять раз вероятнее, чем в позицию 401. Это происходит из-за того, что любая запись, чей ключ хешируется в позиции 990–994 будет помещена в 994, а в позицию 401 будет помещена только та запись, чей ключ хешируется в эту позицию. Это явление, при котором два ключа конкурируют друг с другом при повторных хешированиях называется скучиванием.
Одним из способов исключения скучивания является использование двойного хеширования, которое состоит в использовании двух хеш-функций: h1(key) и h2(key). Функция h1(key), называемая первичной хеш-функцией, используется первой при определении позиции, в которую должна быть помещена запись. Если эта позиция занята, то последовательно используется функция повторного хеширования
rh(i) = mod(i+ h2(key), m)
до тех пор, пока не будет найдена пустая позиция. Записи с ключами key1 и key2 не будут соревноваться за одну и ту же позицию, если h2(key1) ¹ h2(key2).
Другой метод разрешения коллизий при хешировании называется методом цепочек. Он представляет собой организацию связанного списка из всех записей, чьи ключи хешируются в одну и ту же позицию. Предположим, что хеш-функция выдает значения в диапазоне от 0 до m-1. Тогда описывается некоторый массив, например, bucket, размера m. Элемент bucket(i) указывает на список всех записей, чьи ключи хешируются в i. При поиске записи осуществляется доступ к указателю списка, который занимает позицию i в массиве bucket. Если запись не найдена, то она вставляется в конец списка. Обратимся к Рис. 4.9, на котором показан метод цепочек. Предположим, что имеются 14 элементов, хеш-функция равна mod(key, 10). Ключи представлены в таком порядке:
75
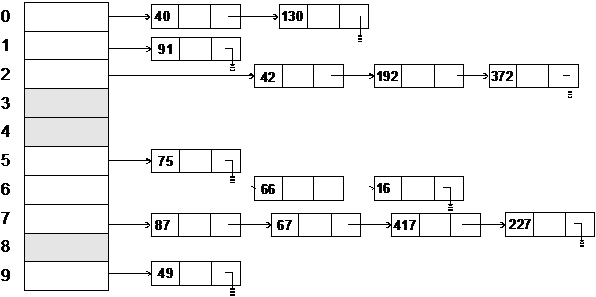 |
Рис. 2.4.9. Разрешение коллизий при хешировании методом цепочек
Выбор хеш-функции
Обратимся к вопросу, как выбрать хорошую хеш-функцию. Ясно, что она должна создавать как можно меньше коллизий при хешировании, т. е. она должна равномерно распределять ключи на имеющиеся индексы в массиве. Наиболее известная хеш-функция (которую мы использовали в вышеизложенных примерах) использует метод деления, при котором некоторый целый ключ делится на размер таблицы и остаток от деления берется в качестве значения хеш-функции. Она обозначается h(key)=mod(key, m). Предположим, что m равно 1000 и что все ключи оканчиваются на 3 одинаковые цифры (например, последние три цифры номера изделия означают номер завода-изготовителя). Тогда остаток от деления на 1000 для всех ключей будет одинаков, т. е. возникнут коллизии при хешировании для всех записей, кроме первой. Ясно, что при таком наборе ключей допуска должна использоваться другая хеш-функция [3].
Рассмотрим другой способ назначения хеш-функции. Он называется метод середины квадрата. В этом методе ключ умножается сам на себя и в качестве индекса используются несколько средних цифр этого квадрата. Если данный квадрат рассматривать как десятичное число, то размер таблицы должен быть некоторой степенью 10, а если он рассматривается как двоичное число, то размер таблицы должен быть степенью 2.
Следующий метод хеширования — метод свертки. В этом методе ключ разбивается на несколько сегментов, над которыми выполняется операция сложения для формирования хеш-функции.
Например, предположим, что внутреннее представление некоторого ключа в виде последовательности разрядов имеет вид и для индекса отводится 5 разрядов. Над тремя последовательностями разрядов 01011, 10010 и 10110 выполняется операция сложения, что дает 01111 или двоичное представление числа 15.
Имеется много других хеш-функций, каждая из которых имеет свои преимущества и недостатки в зависимости от набора хешируемых ключей.
Если ключи не являются числами, то они должны быть преобразованы в целые числа перед применением описанных выше хеш-функций. Для этого имеется несколько способов. Например, для строки символов в качестве двоичного числа может интерпретироваться внутреннее двоичное представление кода каждого символа. Недостатком этого является то, что для большинства ЭВМ двоичное представление букв и цифр очень похоже друг на друга. Если ключи состоят только их одних букв, то индекс каждой буквы в алфавите может использоваться для создания некоторого целого числа. Так, первая буква алфавита (А) представится цифрами 01, а 14-я буква (N) представляется цифрами 14. Ключ “Hello” представляется целым числом . Когда существует некоторое целое представление строки символов, то для сведения его к приемлемому размеру может быть использован метод свертки или середины квадрата.
2.5. Объектно-ориентированное программирование
Введение в ООП
Объектно-ориентированное программирование - это новый подход к программированию [4]. В ходе эволюции вычислительной техники и соответствующих операционных сред разрабатывались каждый раз более мощные методы программирования, чем предыдущие. Не останавливаясь на самых ранних методах программирования, сразу перейдем к анализу методов программирования, использующих языки высокого уровня. Язык программирования, легко понимаемый в коротких программах, становился плохо читаемым и неуправляемым, когда дело касалось больших программ. Избавление от неструктурированных программ пришло после изобретения в 1960 году языков структурного программирования. К ним относятся языки Алгол, Паскаль, и Си. Структурное программирование подразумевает точно обозначенные управляющие структуры, программные блоки, отсутствие или, по крайней мере, минимальное использование операторов GOTO, автономные подпрограммы, в которых поддерживается рекурсия и локальные переменные.
Сутью структурного программирования является возможность разбиения программы на составляющие ее элементы. Используя структурное программирование, средний программист может создавать и поддерживать программы свыше 50000 строк длиной. Но и это оказалось недостаточным на современном этапе. Чтобы писать более сложные программы, необходим был новый подход к программированию. В итоге были разработаны принципы объектно-ориентированного программирования (ООП). ООП аккумулирует лучшие идеи, воплощенные в структурном программировании и сочетает их с мощными новыми концепциями, которые позволяют оптимально организовывать программы. разложить проблему на связанные между собой задачи. Каждая проблема становится самостоятельным объектом, содержащим свои собственные коды и данные. В этом случае вся процедура в целом упрощается, и программист получает возможность оперировать с гораздо большими по объему программами. Все языки ООП, включая С++, основаны на трех основополагающих концепциях, называемых инкапсуляцией, полиморфизмом и наследованием. Рассмотрим эти концепции.
Инкапсуляция
Инкапсуляция - это механизм, который объединяет данные и код, и защищает и то и другое от внешнего вмешательства или неправильного использования. В ООП код и данные могут быть объединены вместе; в этом случае говорят, что создается так называемый «черный ящик». Все необходимые данные и коды находятся внутри его, то есть создается объект. Другими словами, объект - это то, что поддерживает инкапсуляцию. Внутри объекта коды и данные могут быть закрытыми (private) или открытыми (public). По умолчанию действует принцип private. Закрытые коды или данные недоступны для тех частей программы, которые существуют вне объекта. В случае public коды и данные доступны для всех частей программы. Характерной чертой является ситуация, когда открытая часть объекта используется для того, чтобы обеспечить контролируемый интерфейс с его закрытой частью. Рассмотрим такое важное понятие как класс.
Класс - это механизм для создания объектов. Синтаксис описания класса на С++ похож на синтаксис описания структуры.
class имя класса {
закрытые функции и переменные класса
public:
открытые функции и переменные класса
} список объектов;
В описании класса список объектов не является обязательным. Функции и переменные, объявленные внутри класса, становятся членами этого класса. По умолчанию, все функции и переменные, объявленные в классе, становятся закрытыми для этого класса. Все функции и переменные, объявленные после слова public, доступны как для членов класса, так и для любой другой части программы, в которой содержится класс.
Пример. В качестве простого примера рассмотрим программу, в которой используется myclass, описанный в тексте для задания значения a для объектов ob1и ob2 и вывода на экран этих значений для каждого объекта:
# include <iostream. h>
class myclass {
int a; // закрыто вне myclass
public:
void set_a(int num); // член - функция
int get_a(); // член - функция
};
void myclass:: set_a(int num)
{
a = num;
}
int myclass:: get_a()
{
return a;
}
main()

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
