
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Задачи таксономии возникают в самых различных отраслях науки и техники. Например, в экономике, для проведения сравнительного анализа эффективности функционирования промыш-ленных объектов, возникает задача такого подразделения анализируемой совокупности предприя-тий на группы (классы), при которой в каждую группу попадали бы предприятия, в некотором смысле подобные друг другу (скажем, с точки зрения фондовооруженности, объема валовой продукции, численности работающих и т. п.). В информатике при построении банков данных различного назначения (документов, текстов, деталей, нормативов, норм и т. п.), которые назовем объектами, для обеспечения эффективности информационно-поисковых систем, предназначенных для извлечения по запросам нужной информации из банков, также возникает задача подразделения исходного множества объектов на некоторое количество таксонов (кластеров), в пределах которых объекты в каком-то смысле близки друг другу.
Процедура самообучения при неизвестном числе классов. Рассмотрим, как может быть организована процедура самообучения, когда число классов неизвестно. Пусть выбрано признаковое пространство, описываемое вектором ![]() Даны некоторая совокупность объектов ω1 ..., ωl, и значения векторов
Даны некоторая совокупность объектов ω1 ..., ωl, и значения векторов 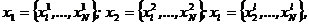 которыми описываются эти объекты.
которыми описываются эти объекты.
Обозначим P(Ωi) вероятность появления объекта класса Ωi, a fi(x) — условную плотность распределения значений признаков внутри Ωi-го класса. Хотя функции P(Ωi) и fi(х) неизвестны, однако относительно совместной плотности распределения вероятностей
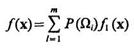 (3.51)
(3.51)
естественно предположить, что конструктор системы распознавания так определил условия, на основе которых в результате самообучения будет осуществлена классификация объектов, что «центрам» классов в признаковом пространстве соответствуют существенные максимумы функции f(x). Именно поэтому цель самообучения — на основе показов векторов х1 ..., xl и заданных условий объединения объектов в классы определить совместную плотность распределения, найти ее существенные максимумы, а следовательно, и «центры» классов и тем самым их число m.
Для решения задачи воспользуемся алгоритмами обучения, основанными на методе стохастической аппроксимации. Положим, что искомая совместная плотность распределения может быть аппроксимирована конечным набором ортонормированных функций jj(х):
![]() (3.52)
(3.52)
Если обозначить f(x) функцию истинной плотности распределения, то функционал
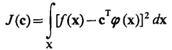 (3.53)
(3.53)
будет характеризовать квадратичную меру уклонения искомой плотности распределения от истинной. Задача состоит в том, чтобы найти такое оптимальное значение вектора с = с°, которое минимизирует функционал
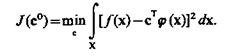 (3.54)
(3.54)
В силу того, что компоненты вектор-функции j(х) ортонормированы, оптимальное значение вектора с
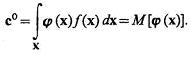 (3.55)
(3.55)
Таким образом, оптимальное значение вектора с0 равно математическому ожиданию вектор-функции j(х), значения реализаций которой могут быть получены на основании априорной информации — величин компонентов векторов х1 ..., хl.
Для определения с0 воспользуемся алгоритмом обучения. Тогда
![]() (3.56)
(3.56)
Если положить g[n] = 1/n, обеспечивающим минимум дисперсии оценки с при любом фиксированном значении n, то
![]() (3.57)
(3.57)
Найдя значение с0 и подставив его в (3.55), определим функцию (х, с0). Ее анализ и выявление существенных максимумов позволяют определить число классов, к которым могут быть отнесены объекты изучаемой совокупности. Это обеспечивает возможность решения задачи, состоящей в определении границ классов.
Изложенный способ построения самообучающейся системы распознавания, основанный на методе стохастической аппроксимации, носит достаточно общий, универсальный характер, однако его реализация в реальных условиях сопряжена с известными затруднениями. В то же время на практике для решения задач таксономии используются сравнительно несложные методы, основанные на измерении меры сходства, заданной расстоянием в признаковом пространстве
х = {х1 ..., хN} между парами объектов ωk, ωl,k, l =1, ..., n.
Для определения расстояния между объектами wk и wl может быть использовано соотношение
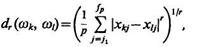
где хkj и хlj — значения j-го признака у k-го и l-го объекта, соответственно; {xj1 ..., xjp} Î {х1 ..., xN} — подмножество признаков, используемое для вычисления расстояния; r — целое положительное число.
Чаще используется метрика, основанная на понятии эвклидово расстояние. Для выделения кластеров необходимо задать пороги. Если d(ωk, ωl)<dпop, то объекты ωk, ωl заключаются в один кластер.
В общем случае, когда значимость признаков с точки зрения их вклада в классификацию различна и, кроме того, признаки статистически зависимы, то для формирования кластеров пользуются обобщенным (взвешенным) расстоянием Махаланобиса
![]()
где хk и xl — значения признаков объектов wk и w, соответственно, используемые при кластеризации; К — ковариационная матрица; L — симметричная неотрицательно-определенная матрица весовых коэффициентов, которая чаще всего выбирается диагональной.
Для разбиения исходного множества объектов на кластеры может быть использована после-довательность действий, имеющих такую геометрическую интерпретацию.
1. Производится нумерация объектов, например, в порядке возрастания значения какого-либо признака (рис. 3.1). На рисунке в целях наглядности признаковое пространство ограничено признаками x1 и x2.
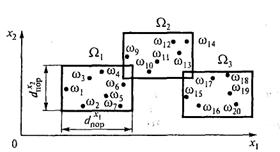
Рис. 3.1. Нумерация объектов
2. Проводятся линии, параллельные осям, из точки, соответствующей объекту ω1 и на них откладываются значения порогов ![]() пор и
пор и ![]() пор. Из концов полученных отрезков проводятся линии, параллельные осям. Так формируется первый кластер — класс объектов Ω1.
пор. Из концов полученных отрезков проводятся линии, параллельные осям. Так формируется первый кластер — класс объектов Ω1.
3. Выполняется та же последовательность операций применительно к точке, соответствующей ближайшему к классу Ω1 объекту (в данном случае ω9), при этом формируется новый кластер — класс объектов Ω2 и т. д. Естественно, что приведенному «геометрическому» описанию алгоритма таксономии соответствует и «алгебраическое» описание, позволяющее его программно реализовать на ЭВМ.
4. ВЕРОЯТНОСТНЫЕ СИСТЕМЫ РАСПОЗНАВАНИЯ
ОБЪЕКТОВ И ЯВЛЕНИЙ
Анализ характера задачи распознавания объектов или явлений в случае, когда характер признаков вероятностный, т. е. когда между признаками объектов и классами, к которым они могут быть отнесены, существуют вероятностные связи, показал, что построение алгоритмов распознавания может быть основано на результатах теории статистических решений. При полной исходной априорной информации эти результаты могут быть использованы непосредственно. При неполной исходной информации эти результаты могут быть использованы лишь путем реализации процедуры обучения или самообучения.
4.1. Некоторые сведения из теории статистических решений
Рассмотрим основные результаты теории статистических решений на следующем примере. Пусть совокупность объектов подразделена на классы Ω1 и Ω2, а для характеристики объектов используется признак х. Известны описания классов — условные плотности распределения вероятностей f1(х) и f2(х) значений признака объектов классов Ω1 и Ω2, а также априорные вероятности P(Ω1) и Р(Ω2) появления объектов. В результате эксперимента определено значение признака х00 распознаваемого объекта (рис. 4.1).
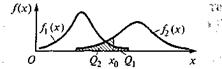
Рис. 4.1. Определение значения признака х00 распознаваемого объекта
Чтобы определить, к какому классу отнести объект, обозначим х0 некоторое, пока неопре-деленное значение признака х и условимся о следующем правиле принятия решений: если измеренное значение признака у распознаваемого объекта х0>х0, то объект будем относить к классу Ω2, если х0£х0,— к классу Ω1 Если объект относится к классу Ω1 а его считают объектом класса Ω2, то совершена ошибка — ошибка первого рода, условная вероятность которой
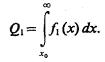 (4.1)
(4.1)
По терминологии теории статистических решений, ошибочно выбрана гипотеза Н2, в то время как справедлива гипотеза Н1. Наоборот, если справедлива гипотеза Н2, а отдано предпочтение гипотезе Нх, то совершена ошибка второго рода, условная вероятность которой
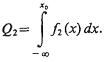 (4.2)
(4.2)
По терминологии теории статистических решений, ошибочно выбрана гипотеза Н1 в то время как справедлива гипотеза Н2.
В некоторых приложениях теории статистических решений вероятность ошибки первого рода называют вероятностью ложной тревоги, а вероятность ошибки второго рода — вероятностью пропуска цели.
Пусть значения признака х у объекта в каждом классе подчинены нормальным законам распределения с математическими ожиданиями m1 и m2 и среднеквадратичными отклонениями s1 и s2, соответственно:
![]() (4.3)
(4.3)
![]() (4.4)
(4.4)
Если в (4.1) подставить (4.3), то условная вероятность ошибки первого рода
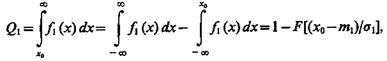 (4.5)
(4.5)
где ![]() — функция Лапласа.
— функция Лапласа.
Если в (4.1) подставить (4.4), то условная вероятность ошибки второго рода
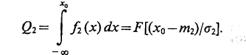 (4.6)
(4.6)
Условные вероятности правильных решений при справедливости гипотез Н1 и Н2, соответственно
![]() (4.7)
(4.7)
![]() (4.8)
(4.8)
В теории статистических решений D1 — размер испытаний, a D2 = 1 — Q2 — мощность испытаний.
В (4.5) и (4.6) при интегрировании функций f1(х) и f2(х) в пределах — ¥ — х0 произведена замена (х0-m)/s на t, которая приводит к интегралам вида
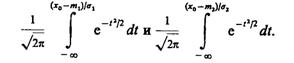
Для вычисления этих интегралов, поскольку они не выражаются через элементарные функции, пользуются таблицами специальных функций:
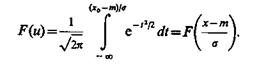 (4.9)
(4.9)
Соображения, которыми следует руководствоваться при выборе значения признака х0 (при разделении пространства признака х на два полупространства: R1 и R2), должны учитывать потери, сопряженные с правильными и ошибочными решениями. Функции потерь, характеризующие потери при совершении ошибок первого и второго рода, а также потери правильных решений, образуют в данном случае платежную матрицу вида
![]() (4.10)
(4.10)
где с11 и с22, с12 и с21 — потери, связанные соответственно с правильными решениями и ошибками первого и второго рода.
Средний риск при многократном распознавании неизвестных объектов равен сумме потерь, связанных с неправильными и правильными решениями, с учетом вероятностей их появления и априорных вероятностей поступления на вход системы распознавания объектов классов Ω1 и Ω2.
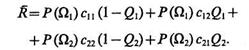 (4.11)
(4.11)
Подставив в (4.11) выражения (4.1) и (4.2), получим
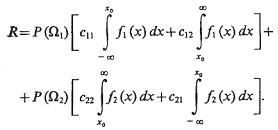 (4.12)
(4.12)
Системы распознавания — системы многократного действия. Поэтому необходимо, чтобы выбор значения х0 был осуществлен с учетом того, что R минимален. Для определения значения х0, при котором средний риск минимален, продифференцируем R по х и приравняем производную нулю, положив х=х0:
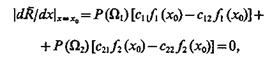 (4.13)
(4.13)
откуда
![]() (4.14)
(4.14)
Отношение условных плотностей распределения f2(x)/f1(x) = l(х) называют коэффициентом правдоподобия или отношением правдоподобия. Правая часть (4.14)
(4.15)
определяет собой пороговое (критическое) значение коэффициента правдоподобия.
Определим значение х0 при условии, что значения признака х у объектов, относящихся к классам Ω1 и Ω2, подчинены нормальным законам распределения N1 (x, m1, s1) и N2 (x, m2, s2) соответственно. Для этого подставим в (4.14) значения f1(x) и f2(х), определяемые (4.3) и (4.4), т. е. 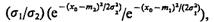 откуда
откуда
![]() (4.16)
(4.16)
Решая (4.16) относительно х0, получим
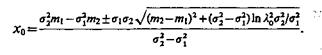 (4.17)
(4.17)
В частном случае, когда s1 = s2 = s, из (4.16) находим
![]() (4.18)
(4.18)
И если c11=с22 = 0, c12 = c21 и P(Ωl) = P(Ω2), то
![]() (4.19)
(4.19)
Значение х0 позволяет оптимальным образом (в смысле минимума среднего риска) разделить признаковое пространство на области R1 и R2. Область R1 состоит из х£х0, для которых l(х) £l0, а область R2 — из х > х0, для которых l(х) > l0. Поэтому решение об отнесении объекта к классу Ω следует принимать, если значение коэффициента правдоподобия меньше его критического значения, а решение об отнесении объекта к классу Ω2 — при противоположной ситуации. В общем случае, когда число классов m > 2, а объекты описываются набором признаков x1, ..., xN или вектором х = {х1 ..., хN}, отношение правдоподобия между классами Ωk и Ωl будет xkl=fk(x)/fl(x), k, l=1, ..., m, платежная матрица имеет вид (1.7), а величина R равна:
![]()
Из условия минимума значения среднего риска уравнение границы в многомерном пространстве признаков между областями Dk и Di, соответствующими классам Ωk и Ωl, будет
![]() (4.20)
(4.20)
Если полагать сkk=сll=0, a ckl=clk=l, то
![]() (4.21)
(4.21)
или
![]() (4.22)
(4.22)
Пусть fi(х) = ехр[0,5(х-mi)TKi-1(х-mi)]/[(2π)1/2Ki1/2], i=l, .... m,— функция плотности многомерного нормального закона распределения со средним вектором mi, и ковариационной матрицей Кi.
Тогда уравнение границы
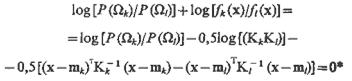 (4.23)
(4.23)
Если Kk=Kl = K, то
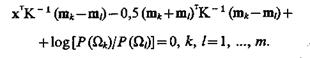 (4.24)
(4.24)
Уравнение (4.24) — уравнение гиперплоскости, разделяющей с точки зрения минимальных средств потерь наилучшим образом многомерное признаковое пространство на области, соответствующие классам Ωk и Ωl, k, l =1, ..., m.
4.2. Критерий Байеса
Критерий Байеса — правило, в соответствии с которым стратегия решений выбирается таким образом, чтобы обеспечить минимум среднего риска. Применение критерия Байеса целесо-образно в случае, когда система распознавания многократно осуществляет распознавание неизвестных объектов или явлений в условиях неизменного признакового пространства, при стабильном описании классов и неизменной платежной матрице.
Минимум риска, усредненного по множеству решений задачи распознавания неизвестных объектов, обеспечивается тогда, когда решения о принадлежности объектов классу Ω1 и Ω2 принимаются в соответствии со следующим правилом: если измеренное значение признака у данного объекта расположено в области R1 то объект относится к классу Ω1 если в области R2 — к классу Ω2.
Стратегию, основанную на этом правиле, называют байесовской стратегией, а минимальный средний риск — байесовским риском.
Использование другой стратегии, отличной от байесовской, сопряжено с увеличением среднего риска. Пусть, например, используется некоторая стратегия А, в соответствии с которой решение о принадлежности объекта классу Ω1 принимается тогда, когда измеренное значение признака х=х0<хА, и классу Ω2, когда х=х0>хА (рис. 4.2).
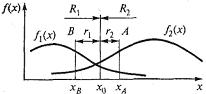
Рис. 4.2. Пороговые значения признака x.
Разность среднего риска ![]() А при подобной стратегии и байесовского риска
А при подобной стратегии и байесовского риска ![]() min в предположении, что с11=c22 = 0, c12 = c1 и с21 = с2, составит
min в предположении, что с11=c22 = 0, c12 = c1 и с21 = с2, составит
|
|
|
|
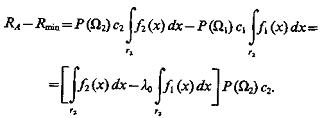 (4.25)
(4.25)
В области r2ÎR2 f2 (x)>l0f1(x). Значит, ![]() A—
A—![]() min>0, т. е.
min>0, т. е. ![]() A>
A>![]() min
min
При выборе стратегии В, в соответствии с которой принимается решение о принадлежности объекта классу Ω1 если х<хB, и классу Ω2, если х>хB, разность средних рисков подобной и байесовской стратегии
|
|
|
|
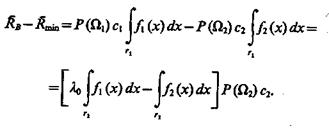 (4.26)
(4.26)
В области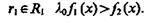 Значит,
Значит, ![]() B —
B — ![]() min > 0, т. е.
min > 0, т. е. ![]() B >
B > ![]() min.
min.
Байесовская стратегия может быть описана также следующим образом. Пусть в результате опыта установлено, что значение признака у распознаваемого объекта ω составляет величину
х = х0. Тогда условная вероятность принадлежности объекта классу Ω1 (условная вероятность первой гипотезы в соответствии с теоремой гипотез или формулой Байеса)
![]() (4.27)
(4.27)
а условная вероятность принадлежности объекта классу Ω2 (условная вероятность второй гипотезы)
![]() (4.28)
(4.28)
где ![]() — совместная плотность распределения вероятностей значений признака х по классам, в свою очередь величины
— совместная плотность распределения вероятностей значений признака х по классам, в свою очередь величины![]() — апостериорные вероятности, принадлежности распознаваемого объекта классам Ω1 и Ω2, соответственно.
— апостериорные вероятности, принадлежности распознаваемого объекта классам Ω1 и Ω2, соответственно.
Условные риски, связанные с решениями ωÎΩ1 и ωÎΩ2, соответственно
![]() (4.29)
(4.29)
Система распознавания, основанная на байесовской стратегии, должна решать задачу с минимальным условным риском. Это значит, что предпочтение решению ωÎΩ1 следует отдавать тогда, когда ![]() Подставим в это выражение значения
Подставим в это выражение значения 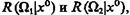 определяемые (4.29). Тогда неравенства
определяемые (4.29). Тогда неравенства ![]() или
или ![]() определят, в каких условиях необходимо принять решение о том, что ωÎΩ1.
определят, в каких условиях необходимо принять решение о том, что ωÎΩ1.
Таким образом, байесовский подход к решению задачи распознавания состоит в вычислении условных апостериорных вероятностей и принятии решения на основании сравнения их значений. Именно такой подход обеспечивает минимум среднего риска и минимум ошибочных решений.
Если число классов больше двух и равно т, то апостериорная вероятность отнесения объекта к Ω-му классу будет
![]() (4.30)
(4.30)
Когда объект характеризуется N признаками xj, j=1, ..., N и признаки распознаваемого объекта приняли значения x1 = x01; х2 = х02; ...; xN=x0N, вероятность того, что при осуществлении события aN=(x01, x02, ..., х0N) объект относится к i-му классу, равна
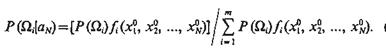 (4.31)
(4.31)
Рассмотрим другую форму записи байесовского критерия отнесения объекта к соответствующему классу. Пусть имеются классы Ω1 и Ω2. Априорные вероятности появления объектов этих классов соответственно P(Ω1) и Р(Ω2), с11 = с22 = 0, cl2 = c1 и с21 = с2. Известны также многомерные условные плотности распределения вероятностей значений признаков f1 (х1 ..., xN) и f2(х1..., xN) по классам. Тогда условные вероятности ошибок первого и второго рода соответственно
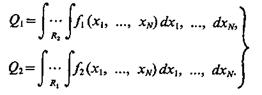 (4.32)
(4.32)
Средний риск
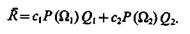 (4.33)
(4.33)
Так как интеграл от плотности вероятности по областям R1 и R2 равен единице, то
![]()
откуда
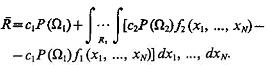 (4.34)
(4.34)
Задача состоит в том, чтобы минимизировать значение среднего риска. Для этого необходимо так выбрать области R1 и R2, чтобы интеграл в (4.34) принял наибольшее отрицательное значение. Это достигается тогда, когда подынтегральное выражение принимает наибольшее отрицательное значение и вне области R1 не существует такой области, где подынтегральное выражение отрицательно, т. е. с2Р(Ω2)f2(х1 ..., xN) – c1P(Ω1)f1(х1 ..., xN)<0. Отсюда следует уже известное решающее правило. Распознаваемый объект ω, признаки которого, как установлено в результате проведения экспериментов, равны xl = x01, х2 = х02, ..., xN=x0N, относится к классу Ω1 если
![]() (4.35)
(4.35)
где ![]() — пороговое значение коэффициента правдоподобия.
— пороговое значение коэффициента правдоподобия.
4.3. Минимаксный критерий
При построении систем распознавания возможны такие ситуации, когда априорные вероятности появления объектов соответствующих классов неизвестны. Минимизировать значение среднего риска принятия решений на основе байесовской стратегии в этом случае не представляется возможным. Применительно к этой ситуации рационально использовать минимаксный критерий – критерий, который минимизирует максимально возможное значение среднего риска.
Минимаксная стратегия состоит в том, что решение о принадлежности неизвестного объекта соответствующему классу принимается на основе байесовской стратегии, соответствующей такому значению P(Ω1), при котором средний риск максимален. Покажем преимущество минимаксной стратегии по сравнению с другими возможными стратегиями в условиях, когда неизвестны значения Р(Ωi), i=1, ..., m.
При наличии классов Ω1 и Ω2 байесовский риск с учетом того, что P(Ω2) = 1 —P(Ω1), c11 = c22 = 0, a c12 = c1 и с21 = с2, равен
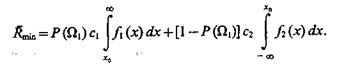 (4.36)
(4.36)
Построим график функции ![]() min =f[Р (Ω1)], помня при этом, что при P(Ω1) = 0 и P(Ω1)=l
min =f[Р (Ω1)], помня при этом, что при P(Ω1) = 0 и P(Ω1)=l![]() min = 0 (рис. 4.3).
min = 0 (рис. 4.3).
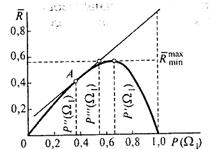
Рис. 4.3. График функции ![]() min =f[Р (Ω1)]
min =f[Р (Ω1)]
Пусть ![]() min достигает своего наибольшего значения при P(Ωl)=P¢(Ω1). Этот риск представляет собой максимальное значение минимального байесовского риска (обозначим его
min достигает своего наибольшего значения при P(Ωl)=P¢(Ω1). Этот риск представляет собой максимальное значение минимального байесовского риска (обозначим его ![]()
![]() ). Применение минимаксного критерия означает, что при отсутствии данных относительно априор-ных вероятностей появления объектов следует ориентироваться на P(Ωl)=P¢(Ω1).
). Применение минимаксного критерия означает, что при отсутствии данных относительно априор-ных вероятностей появления объектов следует ориентироваться на P(Ωl)=P¢(Ω1).
Средние потери при P(Ωl)=P¢(Ω1) определяются касательной к кривой ![]() = f[P(Ωl)] в точке, соответствующей P¢(Ω1):
= f[P(Ωl)] в точке, соответствующей P¢(Ω1):
![]() (4.37)
(4.37)
где Q¢1 = Q1 [Р¢ (Ω1)] и Q¢2 = Q2 [P¢ (Ω1)] — ошибки первого и второго рода при априорной вероятности P(Ωl)=P¢(Ω1).
Так как при P¢(Ω1) средние потери достигают максимума, то касательная, определяемая (4.37), параллельна оси абсцисс и значит средние потери неизменны в условиях, когда действительное значение P(Ω1) отличается от выбранного значения P¢(Ω1).
Минимаксная стратегия обеспечивает то, что при P(Ω1)< P¢(Ω1) и P(Ω1)> P¢(Ω1), средние потери не будут превышать максимального значения минимальных средних (байесовских) потерь.
Рассмотрим, к каким результатам приводит выбор другого значения P(Ω1), отличного от P¢(Ω1). Положим, что выбрано значение P²(Ω1). Средние потери в этом случае описываются уравнением касательной к кривой ![]() = f[P(Ω1)] в точке А:
= f[P(Ω1)] в точке А:
![]() (4.38)
(4.38)
где ![]() ошибки первого и второго рода при априорной вероятности P(Ω1)=P²(Ω1).
ошибки первого и второго рода при априорной вероятности P(Ω1)=P²(Ω1).
Так как байесовская стратегия обеспечивает минимальный средний риск, то кривая, определяемая (4.36), лежит ниже прямой для всех значений P(Ω1)¹P²(Ω1).
Рассматриваемая стратегия приводит к следующему. Положим, сделано предположение, что априорная вероятность равна P²(Ω1). Тогда если априорная вероятность на интервале 0 — P²¢(Ω1) отлична от P²(Ω1), то средний риск будет меньше, чем при минимаксной стратегии.
Но если P(Ω1)> P²(Ω1), то потери возрастают, достигая чрезмерных значений. Выбор минимаксной стратегии гарантирует от подобных потерь.
Для определения алгоритма принятия решения, соответствующего минимаксной стратегии, продифференцируем (4.36) по Р(Ω1) и приравняем производную нулю. В результате получим
![]() (4.39)
(4.39)
Это соотношение, представляющее собой равенство условных значений средних рисков при ошибках первого и второго рода, позволяет определить х0 и построить следующий алгоритм классификации: если измеренное значение признака х у объекта ω равно х0, то ωÎΩ1 если х=х0£х0, и ωÎΩ2, если х=х0>х0.
Минимаксная стратегия, предлагающая значение P(Ω1) полагать равным P¢(Ω1), приводит к следующему пороговому значению коэффициента правдоподобия:
![]() (4.40)
(4.40)
Определение l¢0 позволяет записать алгоритм классификации так: ωÎΩ1 если l(x)£l¢0, и ωÎΩ2 если l(х)> l¢0.
Если с1 = с2 то, как следует из (4.38), минимаксная стратегия приводит к равенству условных вероятностей ошибок первого и второго рода.
В заключение заметим, что минимаксная стратегия есть байесовская стратегия для наихудших значений априорных вероятностей, дающая хотя и осторожное, но гарантированное значение среднего риска.
4.4. Критерий Неймана — Пирсона
При построении некоторых систем распознавания могут быть неизвестны не только априорные вероятности появления объектов соответствующих классов, но и платежная матрица.
В подобных системах для построения алгоритма классификации целесообразно воспользоваться критерием Неймана—Пирсона, суть которого состоит в следующем. Исходя из того, какие решения принимаются на основании результатов распознавания неизвестных объектов, определяется допустимое (заданное) значение условной вероятности ошибки первого рода, затем определяется такая граница между классами, придерживаясь которой удается добиться минимума условной вероятности ошибки второго рода.
Пусть из каких-либо соображений принято решение, что допустимая условная вероятность ошибки первого рода не должна превышать некоторой постоянной величины А, т. е. Q1£A.
Требуется определить решение х0 задачи 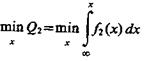 при ограничении вида
при ограничении вида 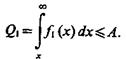 Очевидно, что решение х0 удовлетворяет уравнению
Очевидно, что решение х0 удовлетворяет уравнению 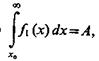 так как при выборе другого значения х¢0>х0 условная вероятность ошибок второго рода Q2 возрастает. Выбрать же х¢0<х0 нельзя по условиям задачи.
так как при выборе другого значения х¢0>х0 условная вероятность ошибок второго рода Q2 возрастает. Выбрать же х¢0<х0 нельзя по условиям задачи.
В заключение рассмотрим геометрическую интерпретацию названных критериев. Для этого в координатах D2 = 1 — Q2 и Q1 построим рабочую характеристику (рис. 4.4), заметив, что когда
Q1 = 0, то Q2=1 и D2=0, и, наоборот, при Q1 = l Q2 = 0 и D2=l. Так как
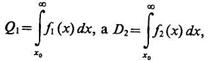
то, продифференцировав D2 пo Q1 получим
![]()
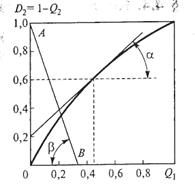
Рис. 4.4. Рабочая характеристика в координатах D2 и Q1
Но ¶D2/¶Q1 есть тангенс угла наклона касательной к рабочей характеристике при l=l0. Поэтому для определения Q1 и D2 на основе применения критерия Байеса на рабочей характеристике найдем точку, касательная в которой имеет наклон, равный l0=P(Ωl)c1/P(Ω2)c2, т. е. tga = A0. Теперь ордината этой точки определяет условную вероятность правильного решения, а абсцисса — условную вероятность ошибки первого рода.
Для определения Q1 и D2 на основе использования минимаксного критерия необходимо учесть, что производная от среднего риска по априорной вероятности P(Ω1) в точке его максимума равна нулю. Так как `R=c11P(Ωl)(1— Ql) + cl2P(Ωl)Ql + c22[l-P(Ω1)]D2 + c21[l-P(Ω1)](l-D2), то ¶R/¶P(Ωl) = c11(l-Ql)+ c12Q1—c22D2 — c21(1 - D2)=0. В координатах Q1 и D2 — это уравнение прямой. Если с11 = с22, то
![]() (4.41)
(4.41)
с угловым коэффициентом g = tgb=(c11— c12)/(c21 — с22).
Проведем на графике (см. рис. 4.4) эту прямую АВ. Координаты точки пересечения прямой с рабочей характеристикой определяют условные вероятности Q1 и D2=l–Q2 в условиях применения минимаксного критерия. Тангенс угла наклона касательной в этой точке равен l0.
4.5. Процедура последовательных решений

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
