
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Ранее предполагалось, что решение о принадлежности распознаваемого объекта ω соответствующему классу Ωi, i=l, ..., m, принимается после измерения всей совокупности признаков этого объекта х1 ..., xN. Однако возможен и другой подход к решению этой задачи: после измерения каждого очередного признака x1;x1, х2; х1, х2, х3 и т. д. включается алгоритм распознавания и решается задача распознавания на основе данных об измеренных к текущему моменту признаках неизвестного объекта. При этом в зависимости от результатов сравнения полученного решения с некоторыми установленными заранее границами либо измеряется очередной признак объекта ω, либо прекращается дальнейшее накопление информации об этом объекте. Такая процедура решения задачи распознавания, называемая последовательной, обязана своим возникновением одному из разделов статистики — последовательному анализу.
Последовательное и многократное решение задачи распознавания с использованием на каждом шаге все возрастающего числа измеренных признаков особенно целесообразно в случаях, когда определение признаков сопряжено с затратами на проведение экспериментов, процесс накопления экспериментальных данных требует затрат значительного количества времени, проведение экспериментов сопряжено с определенным риском (например, при постановке медицинского диагноза), объекты ряда классов из их общей совокупности надежно распознаются по ограниченному количеству признаков.
Рассмотрим суть последовательной процедуры распознавания. Пусть множество объектов подразделено на классы Ω1 и Ω2, рабочий словарь содержит признаки х1 ..., xN и функции условной плотности распределения вероятностей будут fi(x1); fi(x1, х2); ...; fi(x1 ..., xN), i=l, 2.
Допустим, что проведена серия, состоящая из n экспериментов, в результате которых определены признаки х1 ..., хn (n<N). Сопоставим отношения n-мерных функций условных плотностей распределения вероятностей ln=f1(x1, ..., хn)/f2(х1 ..., хn) с величинами А и В. При этом будем полагать следующее: если ln³А, то проведение экспериментов прекращается и принимается решение о том, что ωÎΩ1 если ln£B, то проведение экспериментов также прекращается и принимается решение о том, что ωÎΩ2; если В<ln <А, то принимается решение, что эксперименты необходимо продолжить и определяется очередной (n + 1)-й признак распознаваемого объекта.
Постоянные А и В, называемые верхним и нижним порогами, могут быть определены из таких соображений. Пусть после измерения n признаков ln =А, тогда, обозначив xn={x1, ..., хn}, получим f1(хn)=Аf2хn или
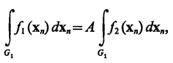 (4.42)
(4.42)
где G1 — область пространства признаков, соответствующая классу Ω1.
Согласно определению условной вероятности ошибок первого Q1 и второго Q2 рода (4.42), можно записать так: l — Q1=AQ2. Аналогичные рассуждения приводят к соотношению Q1 = B(l — Q2). Отсюда в общем случае
![]() (4.43)
(4.43)
Таким образом, для определения порогов А и В необходимо задаться допустимыми значе-ниями ошибок первого и второго рода.
Рассмотрим, как определяются границы двух классов (m=2), описываемых гауссовыми функциями плотности с математическими ожиданиями m1 и m2 и дисперсией s2. При этом будем оперировать не отношением правдоподобия, а его логарифмом. Тогда
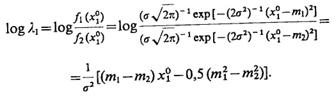
 (4.44)
(4.44)
Сравним
![]()
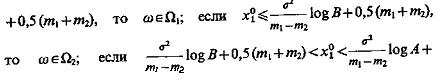
![]()
то следует определить признак х2. Предполагая, что признаки х1 и х2 независимы и равны х1 = х01 и х1=х02, логарифм отношения вероятностей
![]() (4.45)
(4.45)
Если![]()
![]()
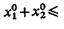
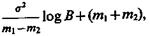 то
то 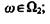 если
если 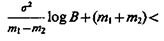
![]() то следует определить признак х3.
то следует определить признак х3.
В общем случае, полагая, что признаки хj, j= 1,..., n, статистически независимы и равны
х1 = х01, ..., хn=х0n, получим
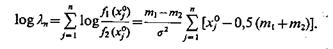 (4.46)
(4.46)
Если ![]() то
то![]() ; если
; если ![]()
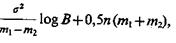 то
то ![]() если
если 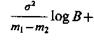
![]() то необходимо произвести определение (n+1)-го признака.
то необходимо произвести определение (n+1)-го признака.
Если число классов m>2, то последовательная процедура состоит в следующем. Исходя из того, какие решения будут приниматься после распознавания неизвестных объектов, задаются допустимые значения вероятностей правильных (еii) и ошибочных (еiq) решений, что позволяет определить значения порогов для каждого класса, т. е. ![]() i=1, ... m; q¹i. Пусть в результате проведения некоторой совокупности экспериментов определен вектор признаков х0n = {х01, ..., х0n) распознаваемого объекта и рассчитаны отношения вероятностей для каждого класса
i=1, ... m; q¹i. Пусть в результате проведения некоторой совокупности экспериментов определен вектор признаков х0n = {х01, ..., х0n) распознаваемого объекта и рассчитаны отношения вероятностей для каждого класса![]() Сопоставим
Сопоставим 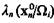 с соответствующим порогом А (Ωi), i= 1, ..., m. Если
с соответствующим порогом А (Ωi), i= 1, ..., m. Если ![]() то принимается решение о том, что ωÎΩi. Если наличие апостериорной информации о найденных признаках объекта не позволяет исключить все классы, кроме одного, то проводится следующий эксперимент с целью определения признака хn+1. После этого определяется ln+1 (x0n+1/Ω1) и производится его сравнение с порогом А (Ωi). Если при этом вновь не удается установить, что распознаваемый объект относится именно к данному классу, то принимается решение провести очередной эксперимент с целью определения признака хn+2.
то принимается решение о том, что ωÎΩi. Если наличие апостериорной информации о найденных признаках объекта не позволяет исключить все классы, кроме одного, то проводится следующий эксперимент с целью определения признака хn+1. После этого определяется ln+1 (x0n+1/Ω1) и производится его сравнение с порогом А (Ωi). Если при этом вновь не удается установить, что распознаваемый объект относится именно к данному классу, то принимается решение провести очередной эксперимент с целью определения признака хn+2.
Подобная процедура последовательного нахождения признаков, определения на каждом шаге коэффициента правдоподобия l1(x01|Ωi), ..., ln(x01|Ωi) и сопоставления его с порогом А(Ω1) проводится до тех пор, пока последовательным исключением всех классов, к которым распознаваемый объект не относится, кроме искомого, не удается принять решение о принадлежности объекта именно к этому классу.
4.6. Регуляризация задачи распознавания
В соответствии со стратегией Байеса, если у распознаваемого объекта ω измеренное значение признака х = х0 , то
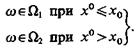 (4.47)
(4.47)
Хотя решение задачи х=х0 и обеспечивает минимум среднего (байесовского) риска, т. е. 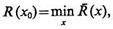 такое решающее правило (4.47) при наличии ошибок измерения является неустойчивым.
такое решающее правило (4.47) при наличии ошибок измерения является неустойчивым.
Если значение признака х измеряется с некоторой точностью dх, то для диапазона его изменения (х0—dх, х0+dх) решение, принятое по измеренному значению х=х0 (выбранный класс), может отличаться от того, которое соответствует истинному значению признака х. Поэтому область значений признака (х0—dх, х0+dх) может быть названа областью неустойчивости стратегии минимизации среднего риска (стратегии Байеса). Величина dх имеет вполне опреде-ленный физический смысл. В качестве dх можно рассматривать, например, среднеквадратичную или максимальную ошибку измерения.
Общий подход к некорректным задачам, имеющим неустойчивые решения, предложенный академиком , состоит в их регуляции, т. е. в таком изменении постановки, при котором вновь полученная задача является приближенной к исходной и обладает свойством устойчивости. Применительно к рассматриваемой задаче распознавания этот подход можно реализовать следующим образом.
Трансформируем решающее правило (4.47) так, что в пределах зоны неустойчивости (х0 — dх, х + dх) алгоритм отказывается от принятия решения. Если у объекта ω измеренное значение признака х-х0, то
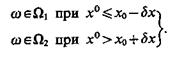 (4.48)
(4.48)
Использование такого алгоритма распознавания исключает неустойчивые решения задачи за счет того, что появляются такие значения признака х=х0±dх, в пределах которых алгоритм распоз-навания не дает ответа на вопрос о том, к какому классу следует отнести распознаваемый объект.
Регуляризация задачи распознавания приводит к тому, что ошибки первого и второго рода уменьшаются:
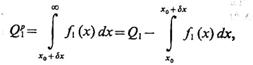 (4.49)
(4.49)
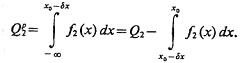 (4.50)
(4.50)
Уменьшается регуляризованное значение среднего байесовского риска:
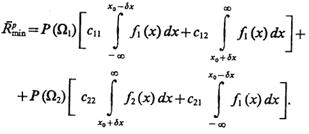 (4.51)
(4.51)
При этом
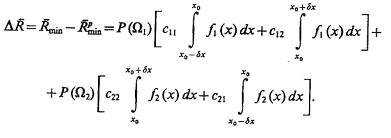 (4.52)
(4.52)
Оценим вероятность отказа системы от установления класса, к которому можно отнести распознаваемый объект. Искомая вероятность отказа
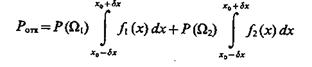 (4.53)
(4.53)
зависит непосредственно от точности измерения признака распознаваемого объекта.
Если функции плотности f1(х) и f2(х) подчинены нормальным законам распределения N(m1, d1) и N(m2, d2), то Qp1 и Qp2 равны:
![]() (4.54)
(4.54)
![]() (4.55)
(4.55)
где F[×] — функция Лапласа.
Вероятность отказа системы от распознавания
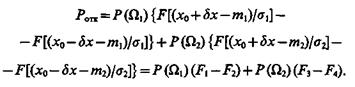 (4.56)
(4.56)
При построении систем распознавания нужно стремиться по возможности минимизировать область неустойчивости стратегии Байеса, т. е. минимизировать диапазон значений признаков, в пределах которого система распознавания не обеспечивает решений. Это может быть достигнуто за счет уменьшения величин dxj, j=l, ..., N. Однако в общем случае это сопряжено с увеличением расходов ресурсов, величина которых не может быть безгранична. Возникает вопрос: точность какого (каких) измерителя следует в первую очередь повышать?
Информативность признаков — величина не абсолютная, а условная, поэтому ответа на поставленный вопрос, по-видимому, не существует. Однако эвристическая рекомендация прикладного характера может состоять в следующем. Прежде всего необходимо найти наиболее информативный признак рабочего словаря признаков в предположении, что он определяется на первой стадии экспериментов. Целесообразно обеспечить максимально возможную точность измерения этого признака (например хl, l =1, ..., N). Далее следует определить такой признак хk, k=1,..., N, k¹l, измерение которого вносит в систему распознавания наибольшее количество информации в предположении, что на предыдущем шаге определен признак хl т. е.
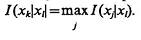
В этом уравнении количество информации подсчитывают при всех возможных значениях признаков хk, xl, хj; k, l, j=1, ..., N, k¹l ¹j. Затем процедура повторяется, т. е. определяют
![]()
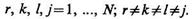
Как правило, определение уже нескольких признаков оказывается достаточным для решения интересующего нас вопроса. Именно между измерителями, предназначенными для определения признаков хl, хk, хr, целесообразно распределить основную часть ресурсов, предназначенных для аппаратурного обеспечения системы распознавания, повысить их точностные характеристики, а значит, уменьшить области неустойчивых решений задачи распознавания при использовании именно этих признаков.
В тех ситуациях, когда при разработке системы распознавания нет выбора в применении тех или других измерителей, предназначенных для определения конкретных признаков, следует крайне внимательно относиться к вопросу о предпочтении использования того или иного признака. Важно проводить детальный анализ ситуаций путем моделирования работы системы. При наличии альтернатив (например, признак хk информативнее xl, но ошибка измерения хk больше ошибки измерения признака xl) можно оценить, какое решение представляется более рациональным: использовать признак хk или xl, а может быть, и тот и другой. В связи с отсутствием в настоящее время формального решения этой задачи интересующий нас ответ может быть получен только путем моделирования ситуаций.
4.7. Задача селекции объектов и явлений
В процессе анализа и изучения различных объектов и явлений часто возникает задача селекции (от лат. selectio — выбор, отбор). Так, при анализе потоков элементарных частиц неоднократно приходится решать задачи отбора, селекции именно данной частицы; в химических смесях — молекул конкретного вещества или элемента; при исследованиях биологических образований — клеток, обладающих определенными свойствами, и т. п. Особую роль приобрели задачи селекции в биотехнологии и генной инженерии в современных системах вооружений.
Принято считать, что задачу селекции можно решать последовательно, применяя алгоритмы распознавания к объектам наблюдаемого множества. Это действительно так, если признаки наблюдаемых объектов измеряются без ошибок, а соответствующие различным классам области значений признаков не пересекаются. Однако в статистической постановке решения такого рода оказываются не оптимальными по критерию минимума среднего риска. Более того, при любом правиле проведения разделяющих границ между областями значений признаков всегда возможны такие ситуации, когда в область пространства, соответствующую объектам селектируемого класса, либо не попадает ни одна реализация, либо попадает более одной. В этих случаях принятие опре-деленного решения невозможно. Это означает, что решающие правила, обычно применяемые при распознавании, в задачах селекции решающими в собственном смысле этого слова не являются.
Мы рассмотрели задачу распознавания. В статистической трактовке она формулируется следующим образом: при известных распределениях значений признаков объектов различных классов и априорных вероятностях появлений этих объектов необходимо по измеренным значе-ниям признаков наблюдаемого объекта принять решение о том, к какому классу он относится.
Задачу селекции можно сформулировать так: при известных отличиях между распре-делениями значений признаков объектов различных классов и составе конкретной выборки объектов по измеренным значениям признаков всех наблюдаемых объектов принять решение о том, какой именно из этих объектов относится к интересующему классу. Уже в самой постановке задачи селекции имеются следующие особенности:
а) известны не сами распределения значений признаков, а соотношение между этими распределениями. Например, объект интересующего нас класса по геометрическим размерам превосходит объекты других классов; решение задачи селекции оказывается возможным и тогда, когда известно только распределение значений признаков для интересующего нас класса и даже тогда, когда ни одно из этих распределений априори неизвестно, однако постулируется сам факт существования таких отличий;
б) известны не статистические свойства генеральной совокупности объектов, характери-зуемые априорными вероятностями появления объектов различных классов, а состав конкретной выборки наблюдаемых объектов;
в) решения принимают не по каждому объекту в отдельности, а по выборке в целом на основе всей совокупности информации.
Постановку задачи селекции рассмотрим сначала применительно к простейшей, довольно распространенной на практике ситуации, когда в выборке из n объектов находится ровно один объект первого класса, который и надлежит отселектировать, а все остальные (n—1) объекты относятся к нулевому фоновому классу.
Предположим, что плотности распределения значений признака х первого f1(х) и нулевого f0(х) классов известны. В ходе дальнейшего анализа уточним, какого рода априорная информация необходима для решения задачи селекции, и проведем некоторые обобщения первоначальной постановки.
Пусть в результате измерения значений признака х для каждого из n объектов получены значения xi где i — номер объекта (i=1, ..., n). При наличии этой информации проверяемые статистические гипотезы сформулируем следующим образом: гипотеза Hi состоит в том, что именно i-й объект относится к первому классу и, следовательно, все остальные объекты относятся к нулевому классу. Задача синтеза алгоритма селекции состоит в том, чтобы определить наилучшее с точки зрения некоторого критерия эффективности решающее правило, в соответствии с которым следует принимать одну из гипотез Нi.
При распознавании в качестве критериев эффективности обычно рассматривают условные вероятности ошибочных решений. Так, в двухальтернативном варианте — это ошибки первого и второго рода. Например, при решении задачи обнаружения это «пропуск цели», если она есть, и «ложная тревога», когда цели нет. В общем случае при числе альтернатив n количество видов ошибочных решений составляет n (n — 1). При селекции правильное и все виды ошибочных решений образуют полную группу несовместных событий, причем, какой именно из объектов фоновой группы принять в качестве истинного объекта, существенного значения не имеет. Вероятности правильного и всех видов ошибочных решений в сумме составляют единицу. Отсюда следует, что полный апостериорный средний риск при любом соотношении между стоимостями правильного и ошибочных решений будет минимальным, если решения в пользу той или иной из гипотез приняты по критерию максимума апостериорной вероятности.
Рассмотрим задачу синтеза алгоритмов селекции.
Плотность вероятности получения выборки ![]() {х1, ..., хi, ..., хn} при условии, что гипотеза Hi верна, можно представить в виде
{х1, ..., хi, ..., хn} при условии, что гипотеза Hi верна, можно представить в виде
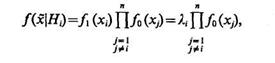 (4.57)
(4.57)
где li=f1(xi)/f0(xi) — отношение правдоподобия.
Апостериорную вероятность гипотезы Hi при условии получения выборки ![]() ‚ рассчитывают по формуле Байеса:
‚ рассчитывают по формуле Байеса:
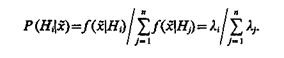 (4.58)
(4.58)
Если решения принимают по критерию максимума апостериорной вероятности, то решающее правило имеет вид
![]() (4.59)
(4.59)
Это правило в отличие от решающего правила, применяемого при распознавании, пороговым не является.
В более общем случае, когда наблюдателю известны априорные вероятности Рi гипотез Hi решающее правило имеет вид:
![]() (4.60)
(4.60)
Приведем два примера применения правила (4.59). Пусть измеренные значения признака х для обоих классов объектов распределены по нормальному или экспоненциальному закону, т. е.
![]() (4.61)
(4.61)
или
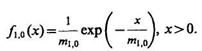 (4.62)
(4.62)
Тогда с точностью до независящих от х сомножителей
![]()
или
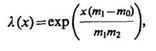
соответственно.
Если m1>m0, то из-за монотонности экспоненциальной функции
![]() (4.63)
(4.63)
Это означает, что для решения задачи селекции достаточно располагать сведениями о соотношении между математическими ожиданиями распределений (4.61) или (4.62), а вид этих распределений и даже некоторые их параметры (например, s2) существенного значения не имеют.
Иногда для решения задачи селекции достаточно располагать данными о параметрах распределения признаков только одного из классов — селектируемого.
Пусть, как и ранее,
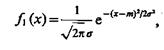
а математическое ожидание значений признака х для объектов фонового класса отличается от m на Dm>0 в большую или меньшую сторону, причем оба эти случая равновероятны. Это позволяет рассматривать f0 (х) как смесь двух соответствующих распределений, т. е.
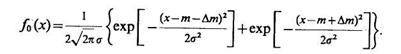
Тогда с точностью до независящих от х множителей
![]()
откуда из-за монотонности зависимости функции гиперболический косинус от модуля ее аргумента следует решающее правило вида
![]() (4.64)
(4.64)
При этом параметры Dm и s2 существенного значения не имеют.
Решение задачи селекции оказывается возможным даже тогда, когда вообще отсутствуют какие бы то ни было априорные сведения о виде и параметрах распределений f1(х) и f0(х). Постулируется лишь сам факт существования отличий между ними. Если провести ранжировку выборки ![]() {х1 ..., xi..., хn} в порядке возрастания значений xi то при m1>m0 в соответствии с правилом (4.59) наиболее вероятной будет гипотеза Нn, а при m1<m0 — гипотеза Н1. Можно показать, что из двух гипотез Нn и Н1 более вероятна та, для которой измеренное значение признака х дальше отстоит от центра рассеяния остальных элементов выборки. Соответствующее этому случаю решающее правило имеет вид
{х1 ..., xi..., хn} в порядке возрастания значений xi то при m1>m0 в соответствии с правилом (4.59) наиболее вероятной будет гипотеза Нn, а при m1<m0 — гипотеза Н1. Можно показать, что из двух гипотез Нn и Н1 более вероятна та, для которой измеренное значение признака х дальше отстоит от центра рассеяния остальных элементов выборки. Соответствующее этому случаю решающее правило имеет вид
![]() (4.65)
(4.65)
Решение задачи селекции при наличии столь малых априорных сведений оказалось возможным благодаря тому, что имелась информация о составе конкретной выборки наблюдаемых объектов.
Рассмотренная методология синтеза алгоритмов селекции допускает обобщение, когда число объектов, которые следует отселектировать от фоновых, больше 1, и задается не детерминиро-ванно, а соответствующим распределением вероятности.
Характер статистических решающих правил при селекции определяет методологию оценки эффективности. Адекватным математическим аппаратом оценки эффективности селекции является теория порядковых статистик.
Вычислим вероятность Фn-1(х) того, что все (n—1) случайных величин с плотностью распределения f0(x) окажутся меньше некоторого значения х¢. Если 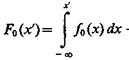 — функция распределения, то
— функция распределения, то
![]() (4.66)
(4.66)
Это следует непосредственно из определения функции распределения. Заметим, что Фn-1(х¢) представляет собой функцию распределения наибольшей из (n—1) случайных величин, распреде-ленных по закону f0(x), т. е. функцию распределения так называемой наибольшей порядковой статистики.
При использовании решающего правила (4.59) правильное решение по селекции будет принято в том случае, если случайная величина х с плотностью распределения f0(х) окажется больше случайной величины х', распределенной по закону (4.66). Вероятность этого события
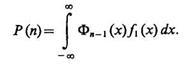 (4.67)
(4.67)
Для распределений вида (4.62) в результате вычислений по формуле (4.67) имеем
![]() (4.68)
(4.68)
где Г(х) — гамма-функция.
Проверить это можно методом математической индукции.
При m0/m1®1 распределения f0(х) и f1(x) сближаются между собой, селекция становится невозможной и Р(n)®1/n. При m1/m0®0 отличия между указанными распределениями становятся существенными Р(n)®1. Эти факты согласуются с интуитивно ожидаемыми результатами.
Для распределений вида (4.61) при n = 2 по формуле (4.67) имеем
![]()
где
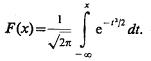
В справедливости последнего результата можно убедиться, рассматривая случайную величи-ну z=y—x=y + (—х), где у и х имеют плотности распределения:
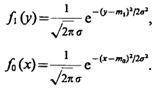
Тогда распределение величины z является композицией распределений f1(у) и f0(х) и, следовательно, имеет плотность распределения
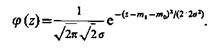
Правильное решение по селекции будет принято при условии z>0, т. е.
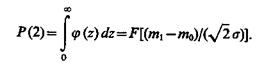
Заметим, что в этих же условиях при использовании критерия идеального наблюдателя вероятность правильного распознавания
![]()
откуда Ррасп<Р(2).
Применяя рассмотренный метод для вероятности правильной селекции, получим следующее выражение:
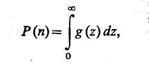
где z=y-x;
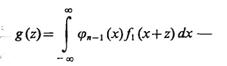 (4.69)
(4.69)
композиция распределений f1(y) и jn-1(—x); jn-1(x)=Фn-1 (х) — плотность распределения наибольшей порядковой статистики в выборке объема (n— 1) из распределения f0(x).
Математическое ожидание `z и дисперсию D{z} величины z рассчитаем по формулам:
![]() (4.70)
(4.70)
![]() (4.71)
(4.71)
Само распределение g(z) мало отличается от нормального.
В (4.70) и (4.71) mn-1 и S2n-1— математическое ожидание и дисперсия наибольшей порядковой статистики в выборке объема (n—1) из распределения с плотностью ![]()
Значения параметров mn и S2n приведены в табл. 4.1.
Таблица 4.1
Значения параметров mn и S2n

При сделанных допущениях
![]() (4.72)
(4.72)
Результаты расчетов, проведенных по точной (4.69) и приближенной (4.72) формулам, приведены в табл. 4.2.
Таблица 4.2
Результаты расчетов
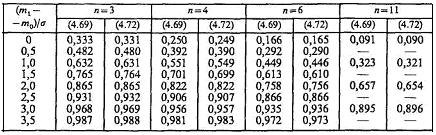
Сопоставление этих результатов показывает, что абсолютная погрешность вычислений по формуле (4.72) не превышает 3 • 10-3. Этого вполне достаточно для практических приложений.
В заключение отметим, что общей методологической основой распознавания и селекции является теория статистических решений. Однако формальное применение методов теории распознавания к решению задач селекции неправомерно и логически противоречиво. Отличия между этими задачами касаются практически всех сторон процесса решения: постановки задачи, способов задания априорной информации, формулируемых статистических гипотез, применяемых решающих правил, критериев эффективности и методов ее оценки.
ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
1. Составьте логическую схему базы знаний по теме юниты:
2. На какие три класса подразделяются системы распознавания, если в качестве принци-па классификации избрать количество первоначальной априорной информации?
Класс 1.__________________________________________________________________________
Класс 2.__________________________________________________________________________
Класс 3.__________________________________________________________________________
3. Используя такие фундаментальные понятия теории распознавания, как «априорный словарь признаков», «оптимальный алфавит классов», «рабочий словарь признаков» и «реша-ющее правило», сформулируйте общую постановку проблемы распознавания объектов или явлений:
______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
4. Установите соответствие между типами систем распознавания и их характеристиками:
Типы систем распознавания | Характеристика систем распознавания |
Детерминированные системы | В этих системах для построения алгоритмов распознавания используются логические методы распознавания, основанные на дискретном анализе и базирующемся на нем исчислении высказываний. |
Вероятностные системы | В этих системах для построения алгоритмов распознавания используются специальные грамматики, порождающие языки, состоящие из предложений, каждое из которых описывает объекты, принадлежащие конкретному классу. |
Логические системы | В этих системах для построения алгоритмов распознавания используются «геометрические» меры близости, основанные на измерении расстояний между распознаваемым объектом и эталонами классов. |
Структурные (лингвистические) системы | В данных системах для построения алгоритмов распознавания используются вероятностные методы распознавания, основанные на теории статистических решений. |
5. В вероятностных системах распознавания, наряду с другими, используется процедура последовательных решений. В чем смысл этой процедуры и в каких условиях эффективно ее применение?
_________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
ГЛОССАРИЙ
№ п/п | Новое понятие | Содержание |
1 | 2 | 3 |
1 | Алгоритмы распознавания | алгоритмы, основанные на сравнении той или другой меры близости или меры сходства распознаваемого объекта с каж-дым классом |
2 | Алфавит классов | некоторая совокупность объектов или явлений, разбитая на ряд классов в соответствии с выбранным принципом классификации |
3 | Вероятностные признаки | признаки, случайные значения которых распределены по всем классам объектов |
4 | Вероятностные системы | системы, в которых для построения алгоритмов распознавания используются вероятностные методы распознавания, основанные на теории статистических решений |
5 | Детерминированные признаки | признаки, принимающие конкретные числовые значения |
6 | Детерминированные системы | системы, в которых для построения алгоритмов распознавания используются «геометрические» меры близости, основанные на измерении расстояний между распознаваемым объектом и эталонами классов |
7 | Комбинированные системы | системы, в которых для построения алгоритмов распознавания используется специально разработанный метод вычисления оценок (АВО) |
8 | Критерий Байеса | правило, в соответствии с которым стратегия решений выби-рается таким образом, чтобы обеспечить минимум среднего риска |
9 | Логические признаки | элементарные высказывания, принимающие два значения истинности («да», «нет» или «истина», «ложь») с полной определенностью |
10 | Логические системы | системы, в которых для построения алгоритмов распознавания используются логические методы распознавания, основанные на дискретном анализе и базирующемся на нем исчислении высказываний |
11 | Минимаксный критерий | критерий, который минимизирует максимально возможное значение среднего риска |
12 | Многоуровневые сложные системы распознавания | системы, в которых апостериорная информация о признаках распознаваемых объектов определяется на основе косвенных измерений |
13 | Обучающиеся системы | системы, в которых первоначальной априорной информации достаточно для того, чтобы определить априорный алфавит классов и построить априорный словарь признаков |
14 | Одноуровневые сложные системы распознавания | системы, в которых апостериорная информация о признаках распознаваемых объектов определяется прямыми измере-ниями непосредственно на основе обработки результатов экспериментов |
15 | Процесс распознавания | процесс, состоящий в том, что система распознавания на ос-новании сопоставления апостериорной информации относи-тельно каждого поступившего на вход системы объекта или явления с априорным описанием классов принимает решение о принадлежности этого объекта (явления) к одному из классов |
16 | Распознавание объектов | задача преобразования входной информации, в качестве кото-рой уместно рассматривать некоторые парамеры, признаки рас-познаваемых образов, в выходную, представляющую собой зак-лючение о том, к какому классу относится распознаваемый образ |
1 | 2 | 3 |
17 | Решающее правило | правило, которое каждому объекту ставит в соответствие определенное наименование класса |
18 | Самообучающиеся системы | системы, в которых первоначальной априорной информации достаточно лишь для определения словаря признаков, но недостаточно для проведения классификации объектов |
19 | Системы без обучения | системы, в которых первоначальной априорной информации достаточно для того, чтобы определить априорный алфавит классов, построить априорный словарь признаков и на основе непосредственной обработки исходных данных произвести описание каждого класса на языке этих признаков |
20 | Системы распознавания | сложные динамические системы, состоящие в общем случае из коллективов подготовленных специалистов и совокупности технических средств получения и переработки информации и предназначенных для решения на основе специально сконструированных алгоритмов задач распознавания соответ-ствующих объектов и явлений |
21 | Словарь признаков | словарь, на языке которого описывается каждый класс объекта |
22 | Структурные (лингвистические) признаки | непроизводные элементы (символы) структуры объекта; иначе эти элементы называют терминалы |
23 | Структурные (лингвистические) системы | системы, в которых для построения алгоритмов распознавания используются специальные грамматики, порождающие языки, состоящие из предложений, каждое из которых описывает объекты, принадлежащие конкретному классу |
23 | () | специалист в области вычислительной математики и математи-ческой физики, академик по Отделению математики (1966 г.) |
24 | Экспертная система распознавания | система, представляющая собой совокупность знаний эксперта или группы экспертов в данной конкретной предметной области |
МЕТОДЫ РАСПОЗНАВАНИЯ
ГЛАВА 1
ОБЩАЯ ПОСТАНОВКА ПРОБЛЕМЫ РАСПОЗНАВАНИЯ.
ВЕРОЯТНОСТНЫЕ СИСТЕМЫ РАСПОЗНАВАНИЯ
* Полужирным шрифтом выделены новые понятия, которые необходимо усвоить. Знание этих понятий будет проверяться при тестировании.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
