

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Глава 7.
Параллельные алгоритмы.
7.1 Основные понятия параллельных алгоритмов.
Объединение нескольких вычислительных систем в общую систему распределенной обработки данных позволяет реализовать эффективные алгоритмы решения трудных задач (с экспоненциальной, факториальной сложностью). При этом возникают две проблемы:
1) управление и планирование вычислений по нескольким задачам для мультипроцессорных систем с различной архитектурой
2) построение быстрого алгоритма решения одной задачи на мультипроцессорной ЭВМ, что подразумевает распараллеливание исходного последовательного алгоритма её решения.
Если задачу нельзя решить с помощью последовательного алгоритма, разработанного одним из эффективных методов, то прибегают к распараллеливанию алгоритма с целью увеличения его быстродействия.
Распараллеливание (десеквенция) – преобразование последовательного алгоритма в эквивалентный ему параллельный алгоритм, соответствующий архитектуре какой-либо мультипроцессорной ЭВМ.
Примеры задач, в которых используется распараллеливание:
1) Одновременное выполнение операций ввода/вывода.
2) Формирование и обнуление массива.
3) Арифметические и логические операции над векторами и матрицами.
4) Одновременное отслеживание ветвей в различных узлах дерева.
5) Конвейерная обработка.
6) Решение СЛАУ большого порядка.
7) Параллельная сортировка.
8) Поиск максимума/минимума функции.
Наиболее желательными (даже скорее обязательными) признаками параллельных алгоритмов и программ являются:
- параллелизм, маштабируемость, локальность, модульность.
Параллелизм указывает на способность выполнения множества действий одновременно, что существенно для программ выполняющихся на нескольких процессорах.
Маштабируемость - другой важнейший признак параллельной программы, который требует гибкости программы по отношению к изменению числа процессоров, поскольку наиболее вероятно, что их число будет постоянно увеличиваться в большинстве параллельных сред и систем.
Локальность характеризует необходимость того, чтобы доступ к локальным данным был более частым, чем доступ к удаленным данным. Важность этого свойства определяется отношением стоимостей удаленного и локального обращений к памяти. Оно является ключом к повышению эффективности программ на архитектурах с распределенной памятью.
Модульность отражает степепь разложения сложных объектов на более простые компоненты. В параллельных вычислениях это такой же важный аспект разработки программ, как и в последовательных вычислениях.
Процессы и нити. Будем понимать под процессом последовательность действий, составляющих некоторое вычисление, которая характеризуется:
- сопоставленной ему программой/подпрограммой, то есть упорядоченной последовательностью операций, реализующих действия, которые должны осуществляться процессом; содержимым соответствующей ему памяти, то есть множеством данных, которыми этот процесс может манипулировать; дескриптором процесса, то есть совокупностью сведений, определяющих состояние ресурсов, предоставленных процессу.
Имеется так же большое число уточнений вида процесса, режима и условий работы процесса: последовательный процесс, параллельный процесс, пакетный процесс, интерактивный процесс, независимый процесс, взаимодействующий процесс и т. д.
Будем различать, где это необходимо, полновесные и легковесные процессы.
Полновесные процессы (tasks - задачи) - это процессы, выполняющиеся внутри защищенных участков памяти операционной системы, то есть имеющие собственные виртуальные адресные пространства для статических и динамических данных. В мультипрограммной среде управление такими процессами тесно связанно с управлением и защитой памяти, поэтому переключение процессора с выполнения одного процесса на выполнение другого является дорогой операцией.
Легковесные процессы (threads - нити), называемые еще сопроцессами, не имеют собственных защищенных областей памяти. Они работают в мультипрограммном режиме одновременно с активировавшей их задачей и используют ее виртуальное адресное пространство, в котором им при создании выделяется участок памяти под динамические данные (стек), то есть они могут обладать собственными локальными данными. Сопроцесс описывается как обычная функция, которая может использовать статические данные программы.
Каналы. Понятие канала используется для описания событий, называемых взаимодействиями, которые состоят в передаче сообщений между процессами. Каналы используются для передачи сообщений в одном направлении и только между двумя процессами. Канал, используемый процессом только для вывода сообщений, называется выходным каналом этого процесса, а используемый только для ввода - входным каналом.
Итак, канал - это однонаправленная двухточечная (соединяющая только два процесса) "коммуникационная линия", позволяющая процессам обмениваться данными. Операции обмена сообщениями достаточно продолжительные по времени операции, поэтому в разных моделях, системах используются разные типы поведения операций приема/передачи сообщений. Различают следующие виды каналов:
- Синхронные.
Отправив сообщение, передающий процесс ожидает от принимающего подтверждение о приеме сообщения прежде, чем послать следующее сообщение, т. е. принимающий процесс не выполняется, пока не получит данные, а передающий - пока не получит подтверждение о приеме данных. Асинхронно/синхронные.
Операция передачи сообщения асинхронная - она завершается сразу (сообщение копируется в некоторый буфер, а затем пересылается одновременно с работой процесса-отправителя), не ожидая того, когда данные будут получены приемником.
Операция приема сообщения синхронная: она блокирует процесс до момента поступления сообщения. Асинхронные.
Обе операция асинхронные, то есть они завершаются сразу. Операция передачи сообщения работает, как и в предыдущем случае. Операция приема сообщения, обычно, возвращает некоторые значения, указывающие на то, как завершилась операция - было или нет принято сообщение.
В некоторых реализациях операции обмена сообщениями активируют сопроцессы, которые принимают/отправляют сообщения, используя временные буфера и соответствующие синхронные операции. В этом случае имеется ещї синхронизирующая операции, которая блокирует процесс до тех пор, пока не завершатся все инициированные операции канала.
При работе с каналами необходимо следить за тем, чтобы не случилась блокировка взаимодействующих процессов (дедлок). Например, процесс A не может передать сообщение процессу B, поскольку процесс B ждет, когда процесс A примет сообщение от него. Это одна из простейших ситуаций, в более сложных случаях циклические зависимости могут охватывать много процессов, причем появление дедлока может завесить от данных.
Семафоры - средство управления процессами. Семафоры традиционно использовались для синхронизации процессов, обращающихся к разделяемым данным. Каждый процесс должен исключать для всех других процессов возможность одновременно с ним обращаться к этим данным (взаимоисключение). Когда процесс обращается к разделяемым данным, говорят, что он находится в своем критическом участке.
Для решения задачи синхронизации необходимо, в случае если один процесс находится в критическом участке, исключить возможность вхождения для других процессов в их критические участки. Хотя бы для тех, которые обращаются к тем же самым разделяемым данным. Когда процесс выходит из своего критического участка, то одному из остальных процессов, ожидающих входа в свои критические участки, должно быть разрешено продолжить работу.
Процессы должны как можно быстрее проходить свои критические участки и не должны в этот период блокироваться. Если процесс, находящийся в своем критическом участке, завершается (возможно, аварийно), то необходимо, чтобы некоторый другой процесс мог отменить режим взаимоисключения, предоставляя другим процессам возможность продолжить выполнение и войти в свои критические участки.
Семафор - это защищенная переменная, значение которой можно опрашивать и менять только при помощи специальных операций wait и signal и операции инициализации init. Двоичные семафоры могут принимать только значения 0 и 1. Семафоры со счетчиками могут принимать неотрицательные целые значения.
Операция wait(s) над семафором s состоит в следующем: если s > 0 то s:=s-1 иначе (ожидать на s), а операция signal(s) заключается в том, что: если (имеются процессы, которые ожидают на s), то (разрешить одному из них продолжить работу), иначе s:=s+1.
Операции являются неделимыми. Критические участки процессов обрамляются операциями wait(s) и signal(s). Если одновременно несколько процессов попытаются выполнить операцию wait(s), то это будет разрешено только одному из них, а остальным придется ждать.
Семафоры со счетчиками используются, если некоторые ресурс выделяется из множества идентичных ресурсов. При инициализации такого семафора в его счетчике указывается число элементов множества. Каждая операция wait(s) уменьшает значения счетчика семафора s на 1, показывая, что некоторому процессу выделен один ресурс из множества. Каждая операция signal(s) увеличивает значение счетчика на 1, показывая, что процесс возвратил ресурс во множество. Если операция wait(s) выполняется, когда в счетчике содержится нуль (больше нет ресурсов), то соответствующий процесс ожидает, пока во множество не будет возвращен освободившийся ресурс, то есть пока не будет выполнена операция signal.
Сложность ПА оценивается гипотезой Минского: параллельные вычислительные системы, выполняющие последовательную программу под множеством исходных данных размера N, дают прирост производительности по крайней мере на показатель 1/log(N). Сложность полученного параллельного алгоритма (ПА) дает выигрыш как минимум на порядок по сравнению с последовательным алгоритмом.
Однако при распараллеливании задач есть ряд «подводных камней»:
1) Во многих случаях ПА дает малый прирост производительности (быстродействия), поэтому проще применить эффективные методы построения быстрых последовательных алгоритмов для однопроцессорных универсальных ЭВМ, чем распараллеливать задачу для многопроцессорных специальных ЭВМ.
Кроме того, выбор средств разработки ПА весьма ограничен, а полученный параллельный код менее оптимизирован, чем для последовательных ЭВМ на этапе компиляции.
2) Быстрые последовательные алгоритмы во многих случаях дают более высокое быстродействие, чем ПА, построенные на основе прямого алгоритма решения задачи, а распараллеливание быстрого последовательного алгоритма является сложной задачей.
3) Для разработки ПА необходимо разбить задачу на независимые подзадачи с объединением результатов подзадач на последнем этапе. Этот процесс не поддается отладке, и быстродействие всего алгоритма сильно зависит от размеров подзадач и последнего этапа. В лучшем случае подзадачи должны быть маленьких и одинаковых размеров.
В качестве рекомендаций при построении параллельных алгоритмов следует учитывать:
· Распараллеливание полезно только в том случае, если все попытки создать быстрый последовательный алгоритм решения задачи оказались неудачными.
· При распараллеливании используйте балансировку при разбиении задачи на подзадачи и избегайте рекурсий.
Рассмотрим примеры параллельных алгоритмов.
Пример 1:
ПА отыскания минимального остовного дерева.
 Если одновременно выбрать для каждой вершины связанное с ней ребро с минимальным весом, то в остовном дереве возникнут замкнутые циклы, а это недопустимо.
Если одновременно выбрать для каждой вершины связанное с ней ребро с минимальным весом, то в остовном дереве возникнут замкнутые циклы, а это недопустимо.
V1: (V1, V2)
V2: (V2, V4)
V3: (V3, V2)
V4: (V4, V1)
V5: (V5, V4)
V6: (V6, V2)
 Однако если выбрать для каждой вершины Vi ребро наименьшего веса, которое идентично вершине Vj (j¹i) с наименьшим индексом j, то исключается возможность циклов.
Однако если выбрать для каждой вершины Vi ребро наименьшего веса, которое идентично вершине Vj (j¹i) с наименьшим индексом j, то исключается возможность циклов.
Это условие позволяет найти остовное дерево минимального веса за один шаг ПА. Однако при большом числе вершин рассмотренный алгоритм не настолько быстрый. Модификация этого алгоритма, предложенная Соллином, более эффективна. При этом сложность задачи уменьшается с O(N2) до O(log2N).
Пример 2:
Задача сортировки массива из N целых чисел.
Pi –процессоры (i=1…N).
P1 P2 P3 P4 P5 P6 P7 P8
6 | 3 | 7 | 2 | 8 | 4 | 1 | 5 |
|
3 | 6 | 2 | 7 | 4 | 8 | 1 | 5 |
¯ ¯
3 | 2 | 6 | 4 | 7 | 1 | 8 | 5 |
2 | 3 | 4 | 6 | 1 | 7 | 5 | 8 |
¯ ¯
2 | 3 | 4 | 1 | 6 | 5 | 7 | 8 |
2 | 3 | 1 | 4 | 5 | 6 | 7 | 8 |
¯ ¯
2 | 1 | 3 | 4 | 5 | 6 | 7 | 8 |
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
¯ ¯
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
Шаг 0: присваиваются исходные значения
M=0, t=0 (М – критерий остановки алгоритма).
Шаг 1: Do Through шаг 3
while M¹2
else Stop
Шаг 2: If t=четное Then сравнить (I2k, I2k-1) для (P2k, P2k-1), " K=1, 2, …, N/2
If I2k<I2k-1 then
I2k®P2k-1
I2k-1®P2k
Шаг 3: If была перестановка Then M=0
Else M=M+1
t=t+1
Этот алгоритм сортировки упорядочивает массив из N чисел за N+1 шагов в реальном масштабе времени, производя на каждой итерации N/2 операций сравнения, что требует время порядка O(N2).
7.2 Модели параллельных вычислений
Параллельное программирование представляет дополнительные источники сложности - необходимо явно управлять работой тысяч процессоров, координировать миллионы межпроцессорных взаимодействий. Для того решить задачу на параллельном компьютере, необходимо распределить вычисления между процессорами системы, так чтобы каждый процессор был занят решением части задачи. Кроме того, желательно, чтобы как можно меньший объем данных пересылался между процессорами, поскольку коммуникации значительно больше медленные операции, чем вычисления. Часто, возникают конфликты между степенью распараллеливания и объемом коммуникаций, то есть чем между большим числом процессоров распределена задача, тем больший объем данных необходимо пересылать между ними. Среда параллельного программирования должна обеспечивать адекватное управление распределением и коммуникациями данных.
Из-за сложности параллельных компьютеров и их существенного отличия от традиционных однопроцессорных компьютеров нельзя просто воспользоваться традиционными языками программирования и ожидать получения хорошей производительности. Рассмотрим основные модели параллельного программирования, их абстракции адекватные и полезные в параллельном программировании:
Процесс/канал (Process/Channel)
В этой модели программы состоят из одного или более процессов, распределенных по процессорам. Процессы выполняются одновременно, их число может измениться в течение времени выполнения программы. Процессы обмениваются данными через каналы, которые представляют собой однонаправленные коммуникационные линии, соединяющие только два процесса. Каналы можно создавать и удалять.
Обмен сообщениями (Message Passing)
В этой модели программы, возможно различные, написанные на традиционном последовательном языке исполняются процессорами компьютера. Каждая программа имеют доступ к памяти исполняющего еї процессора. Программы обмениваются между собой данными, используя подпрограммы приема/передачи данных некоторой коммуникационной системы. Программы, использующие обмен сообщениями, могут выполняться только на MIMD компьютерах.
Параллелизм данных (Data Parallel)
В этой модели единственная программа задает распределение данных между всеми процессорами компьютера и операции над ними. Распределяемыми данными обычно являются массивы. Как правило, языки программирования, поддерживающие данную модель, допускают операции над массивами, позволяют использовать в выражениях целые массивы, вырезки из массивов. Распараллеливание операций над массивами, циклов обработки массивов позволяет увеличить производительность программы. Компилятор отвечает за генерацию кода, осуществляющего распределение элементов массивов и вычислений между процессорами. Каждый процессор отвечает за то подмножество элементов массива, которое расположено в его локальной памяти. Программы с параллелизмом данных могут быть оттранслированы и исполнены как на MIMD, так и на SIMD компьютерах.
Общей памяти (Shared Memory)
В этой модели все процессы совместно используют общее адресное пространство. Процессы асинхронно обращаются к общей памяти как с запросами на чтение, так и с запросами на запись, что создает проблемы при выборе момента, когда можно будет поместить данные в память, когда можно будет удалить их. Для управления доступом к общей памяти используются стандартные механизмы синхронизации - семафоры и блокировки процессов.
Модель процесс/канал характеризуется следующими свойствами:
1. Параллельное вычисление состоит из одного или более одновременно исполняющихся процессов, число которых может изменяться в течение времени выполнения программы.
2. Процесс - это последовательная программа с локальными данными. Процесс имеет входные и выходные порты, которые служит интерфейсом к среде процесса.
3. В дополнение к обычным операциям процесс может выполнять следующие действия: послать сообщение через выходной порт, получить сообщение из входного порта, создать новый процесс и завершить процесс.
4. Посылающаяся операция асинхронная - она завершается сразу, не ожидая того, когда данные будут получены. Получающаяся операция синхронная: она блокирует процесс до момента поступления сообщения.
5. Пары из входного и выходного портов соединяются очередями сообщений, называемыми каналами (channels). Каналы можно создавать и удалять. Ссылки на каналы (порты) можно включать в сообщения, так что связность может измениться динамически.
6. Процессы можно распределять по физическим процессорам произвольным способами, причем используемое отображение (распределение) не воздействует на семантику программы. В частности, множество процессов можно отобразить на одиночный процессор.
Понятие процесса позволяет говорить о местоположении данных: данные, содержащихся в локальной памяти процесса - расположены ``близко ", другие данные ``удалены". Понятие канала обеспечивает механизм для указания того, что для того, чтобы продолжить вычисление одному процессу требуются данные другого процесса (зависимость по данным).
Модель обмен сообщениями (message passing) является наиболее широко используемой моделью параллельного программирования. Программы этой модели, подобно программам модели процесс/канал, создают множество процессов, с каждым из которых ассоциированы локальные данные. Каждый процесс идентифицируется уникальным именем. Процессы взаимодействуют, посылая и получая сообщения. В этом отношение модель обмен сообщениями является разновидностью модели процесс/канал и отличается только механизмом, используемым при передаче данных. Например, вместо отправки сообщения в канал "channel 2" можно послать сообщение процессу "process 3".
Модель обмен сообщениями не накладывает ограничений ни на динамическое создание процессов, ни на выполнение нескольких процессов одним процессором, ни на использование разных программ для разных процессов. Просто, формальные описания систем обмена сообщениями не рассматривают вопросы, связанные с манипулированием процессами, Однако, при реализации таких систем приходится принимать какое-либо решение в этом отношении. На практике сложилось так, что большинство систем обмена сообщениями при запуске параллельной программы создает фиксированное число идентичных процессов и не позволяет создавать и разрушать процессы в течение работы программы.
В таких системах каждый процесс выполняет одну и ту же программу (параметризованную относительно идентификатора либо процесса, либо процессора), но работает с разными данными, поэтому о таких системах говорят, что они реализуют SPMD (single program multiple data - одна программа много данных) модель программирования. SPMD модель приемлема и достаточно удобна для широкого диапазона приложений параллельного программирования, но она затрудняет разработку некоторых типов параллельных алгоритмов.
Модель параллелизм данных также является часто используемой моделью параллельного программирования. Название модели происходит оттого, что она эксплуатирует параллелизм, который заключается в применении одной и той же операции к множеству элементов структур данных. Например, "умножить все элементы массива M на значение x", или "снизить цену автомобилей со сроком эксплуатации более 5-ти лет". Программа с параллелизмом данных состоит из последовательностей подобных операций. Поскольку операции над каждым элементом данных можно рассматривать как независимые процессы, то степень детализации таких вычислений очень велика, а понятие "локальности" (распределения по процессам) данных отсутствует. Следовательно, компиляторы языков с параллелизмом данных часто требуют, чтобы программист предоставил информацию относительно того, как данные должны быть распределены между процессорами, другими словами, как программа должны быть разбита на процессы. Компилятор транслирует программу с параллелизмом данных в SPMD программу, генерируя коммуникационный код автоматически.
Модель общая память. Здесь все процессы совместно используют общее адресное пространство, к которому они асинхронно обращаются с запросами на чтение и запись. В таких моделях для управления доступом к общей памяти используются всевозможные механизмы синхронизации типа семафоров и блокировок процессов. Преимущество этой модели с точки зрения программирования состоит в том, что понятие собственности данных (монопольного владения данными) отсутствует, следовательно, не нужно явно задавать обмен данными между производителями и потребителями. Эта модель, с одной стороны, упрощает разработку программы, но, с другой стороны, затрудняет понимание и управление локальностью данных, написание детерминированных программ. В основном эта модель используется при программировании для архитектур с общедоступной памятью.
7.3 Средства распараллеливания алгоритмов.
Современные суперЭВМ в большинстве являются параллельными системами, поэтому важной задачей является стандартизация методов распараллеливания алгоритмов и программ. Известно, что параллельные системы строятся либо с разделяемой памятью, либо с общей памятью. Для систем 1-го типа существует стандарт распараллеливания MPI. Здесь задача распараллеливания сводится к разделению на подзадачи меньших размеров с обменом сообщениями между ними. Для систем 2-го типа разработан стандарт OpenMP. В этом случае задачи легче поддаются распараллеливанию, и нет необходимости в дополнительной пересылке данных.
Существует несколько видов средств распараллеливания.
1) Autotasking – это автоматическое распараллеливание с помощью компиляторов последовательного кода, написанного на языке С и Fortran.
Здесь программист не заботится о распараллеливании и пишет обычный последовательный код. Компилятор сам распознает присущий программе параллелизм и организует ее выполнение в виде нескольких процессов (нитей) одновременно на разных микропроцессорах.
Кроме того, компилятор распознает типовые операции (умножение матриц) и генерирует обращение к специальным библиотекам быстрых подпрограмм для параллельных систем, написанных на Ассемблере.
1) Macrotasking – это программный код, который вносится в программу вручную. Его называют кодированием с явным вызовом нитей.
2) Microtasking – это автораспараллеливание с указанием директив. Директивы указывают компилятору на параллельный код, скрываемый в операторах циклов, ввода/вывода и отдельных фрагментах программы.
В первом случае проследить связь операндов по ходу работы программы, которые могли бы выполнятся параллельно, очень трудно. Следовательно, здесь возможен либо динамический параллелизм небольшой последовательности команд, реализуемый на уровне ядра микропроцессора, либо статический параллелизм, заключающийся в создании параллельного объектного модуля лишь один раз на этапе компиляции.
Недостаток статического параллелизма заключается в том, что невозможно учесть динамику изменения операндов и работу программы в диалоговом режиме.
Второй подход является очень трудоемким, т. к. требует создания больших программ на языке Ассемблера с учетом архитектуры мультипроцессорной системы, системы команд и особенностей распараллеливания.
В основном используются системы третьего типа. Для них существует несколько стандартизированных способов распараллеливания, основанных на общем наборе директив.
Стандарт OpenMP не ограничивается только набором директив, а определяет API, включающий набор библиотек времени выполнения RTL, переменные окружения, задающие число параллельных процессоров и способы их работы.
В основе OpenMP лежит модуль fork/join (WWW. OpenMP. Org).
Последний фрагмент программы в fork/join выполняется одновременно всеми параллельными процессорами с возможностью вложенности параллелизма.
Ключи, указываемые в директивах, определяют атрибуты данных, действующие во время выполнения текущей параллельной конструкции.
Переменные, определяющие данные, задаются областью видимости Shared. Такие переменные разделяются всеми параллельными процессорами. В операторах циклов, выполняемых параллельно для любого процессора, организуется свой счетчик цикла с областью видимости правил.
Переменные, объявляемые как Private, при входе в параллельную конструкцию является неопределенными для любого процессора.
C$OMP Parallel [ключ, ключ, …]
блок операторов
C$OMP End Parallel [NOWAIT]
Флаг NOWAIT определяет синхронизацию процесса.
В качестве ключей могут использоваться спецификации данных и оператор условия If.
Распределение подзадач между процессорами задается с помощью одной из 2-х конструкций.
1. C$OMP Do [ключи]
тело цикла
C$OMP End Do
Ключи бывают следующие:
ü Private;
ü Shared;
ü Reduction;
ü Ordered;
ü Schedule.
1) Schedule указывает способ планирования выполнения цикла, объявляется вместе с параметрами:
Schedule (тип, М)
Типы могут быть:
- Static – операции, которые будут распараллеливаться статически.
- Dynamic – операции будут распараллеливаться динамически порциями по М итераций. Т. о. если какой-либо процессор заканчивает свою работу, то ему выделяют следующую порцию.
- Guided – размер порций экспоненциально уменьшается для каждой новой порции, выдаваемой процессору.
- Runtime – тип планирования, т. е. значение переменной М задается во время выполнения программы.
2) Reduction позволяет организовать параллельное выполнение цикла с вычислением суммы значений функции.
Например:
C$OMP Parallel Do Reduction (+ Sum)
C$OMP Private (x)
Do i=1,N
x=a(i)
sum=sum + F(x)
End Do
C$OMP End Parallel Do
2. Если фрагмент программы не содержит циклов, то для распределения работы между процессорами используется другая директива:
C$OMP Sections [ключи]
C$OMP Section
блок операторов
[C$OMP Section
блок операторов]
…
C$OMP End Sections
Это позволяет выполнять параллельно несколькими процессорами обычный линейный участок программы, разбитый на секции.
Кроме того, может использоваться также следующая директива:
C$OMP Single
…
C$OMP End Single
Single образует некоторый участок внутри параллельной конструкции, который выполняется одним процессором.
Для синхронизации параллельных процессов используются директивы
C$OMP Barrier
C$OMP Atomic,
которые исключают одновременную запись несколькими процессорами в одну и ту же ячейку памяти.
Существует также директива
C$OMP Ordered
…
C$OMP End Ordered,
которая задает блок операторов, которые обязательно выполняются последовательно.
В разработке данного стандарта приняли участие IBM, HP, Gray Research, Intel, SGI. Пример подобного компьютера – MIPS pro 7.21 (SGI).
7.4. Методы распараллеливания алгоритмов
Существует много методов распараллеливания, из которых наиболее известными являются:
· Метод К-схем (гиперплоскостей)
· Динамические методы распараллеливания доступа к памяти
· Метод параллелепипедов и метод пирамид для распараллеливания циклических участков программ
Распараллеливание проводится в два этапа:
1) Фиксация в какой-либо машинно-независимой форме, например в форме информационного графа, параллелизма задачи.
2) Генерация программы с параллельной структурой согласно архитектуре мультипроцессорной ЭВМ.
При распараллеливании алгоритма на первом шаге выделяют информационную и управляющую компоненты. Первая определяет базис системы обработки данных, то есть требуемую память под переменные, совокупность операторов и их взаимосвязи. Вторая задаёт порядок выполнения операторов без привязки к данным.
Определим Mi как множество ячеек памяти под переменные, Fi – множество операторов обработки данных. Для каждого оператора определены множества входных IN(Fi) и выходных OUT(Fi) переменных, образующие информационный базис.
Вычислительный процесс над информационным базисом P(M, F) есть конечная или бесконечная последовательность операторов Fi.
Требуется для заданной схемы последовательных операторов S(M, F) построить эквивалентную схему S’(M, F) обеспечивающую параллельное выполнение всех или части операторов.
Распараллеливанию подвергаются три типа фрагментов программы:
1. линейный участок (последовательность операторов)
2. условные операторы
3. циклы
1. Линейный участок
Пример 1. Пусть задан линейный фрагмент программы в виде К – схемы.
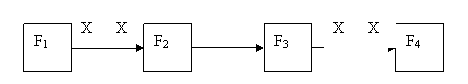

Здесь X – ячейка памяти для хранения значения переменной X.
Можно преобразовать последовательную схему в эквивалентную параллельную схему введя дополнительную переменную Y и тем самым устранить конкуренцию за общую ячейку памяти, мешающую параллельному выполнению этого фрагмента программы.
|
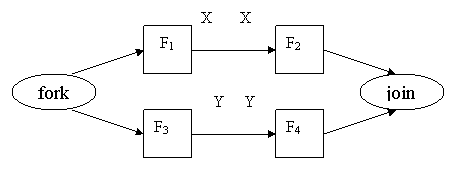

Здесь операторы F1 и F2, а также F3 и F4 связаны между собой и по данным, и по управлению. А между операторами F2 и F3 есть связь только по управлению, то есть результат выполнения оператора F2 никак не влияет на работу оператора F3 .
Зависимость по данным означает, что результат выполнения предыдущего оператора в программе является одновременно входным операндом для текущего оператора, выполнение которого не возможно до тех пор, пока не определён результат работы предыдущего оператора.
Зависимость по управлению означает то, что программист определил в программе последовательность написания операторов, хотя они могут не зависеть между собой по данным.
В мультипроцессорной системе обработки данных произвольный оператор Fi в последовательном фрагменте программы назначается на выполнение сразу же как только станет ясна неизбежность его выполнения.
2. Условный оператор
Для оператора условия
If P then A else B.
операторам A и B не будет разрешено выполнение, пока не будет известен результат проверки условия P, в обычной последовательной программе. В случае распараллеливания операторы A и B выполняются либо раньше, либо одновременно с проверкой условия P, после чего не нужный результат отбрасывается, то есть для достижения большего быстродействия требуются затраты вычислительных ресурсов. Здесь произвольный оператор Fi назначается на выполнение как только появляется ненулевая вероятность того, что результат его работы потребуется в дальнейших вычислениях. Связь между операторами P,A и B является логической.
Пример 2. Задана K – схема, соответствующая условному оператору программы.


Здесь оператор F2 логически зависит от оператора F1, как по данным, так и по управлению. Оператор F3 не зависит от операторов F1, и F2 по данным, но зависит по управлению.
Связь из-за конкуренции возникает если операторы используют одну и ту же ячейку памяти для своей работы, и их непоследовательное выполнение может уничтожить (затереть) нужную информацию.
Так в примере 2 оператор F3 не может выполняться раньше чем F2, так как затирает информацию в ячейке памяти X, в случае если вычислительный процесс пойдет через F2.
Связь из-за дестабилизации данных возникает при использовании различными фрагментами программы одних и тех же каналов связи, как в ниже приведенном примере К -схемы.
![]()


Пример 3. Пусть дан фрагмент последовательной программы в виде К – схемы.
Требуется построить К – схему эквивалентного параллельного алгоритма.
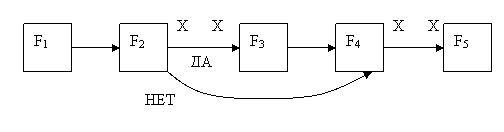

Эта схема может быть преобразована к эквивалентной с учетом распараллеливания.
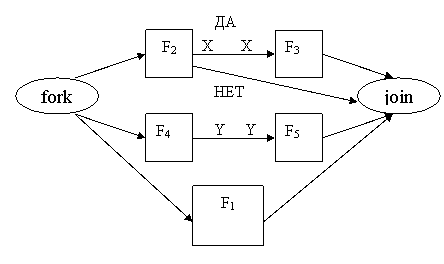

Оператор может быть выполнен, только если на его входе определены все данные, согласно принципу упреждения. Хотя в последствии может оказаться, что результаты его работы не потребуются в дальнейшем.
В следующем примере распараллеливание достигается за счет снятия логической зависимости и зависимости из-за дестабилизации данных.
Пример 4. Дана К-схема последовательного алгоритма.
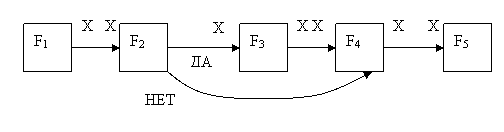
Результат распараллеливания представлен на следующей схеме.
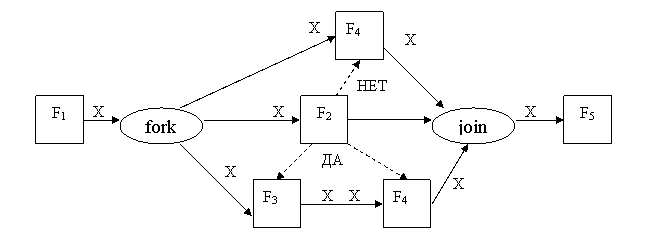

Пунктирные стрелки на этой схеме означают, что при выборе соответствующей альтернативы оператор F2 отменяет выполнение оператора F4 или пары операторов F3 и F4, а также результаты их работы, если они уже были вычислены.
При распараллеливании исследуются не только связи между операторами, но и внутриоператорные связи. Рассмотрим это на следующем примере.
Пример 5. Задана функция
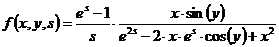
Вычислить значение функции при заданных аргументах X,Y,S. При вычислении учесть ошибку деления на ноль при S=0. Если знаменатель второго множителя равен нулю, то вычислить значение функции F(2X, Y,S).
Пусть операции x2, cos(y), sin(y), es выполняются вызовом стандартных функций, то есть рассматриваются как элементарные действия. Пример исполняемой чати простой последовательной программы вычисления значения функции может выглядеть так.
Program Fun;
Var s, x,y, t,u, v,w, z : real;
Begin
Read(s, x,y);
If s=0 then begin write(‘Деление на ноль); exit; end;
t:=exp(s);
w:=(t-1)/s;
5: u:=sqr(t)+sqr(x);
v:=2*x*t;
t:=cos(y);
u:=u-v*t;
if u=0 then begin x:=2*x; goto 5; end;
t:=sin(y);
z:=w*t*x/u;
write(z);
End.
В этой программе для уменьшения числа промежуточных переменных используется экономия памяти, поскольку в ячейке t хранятся различные значения в разные моменты времени.
Построим параллельную схему алгоритма, руководствуясь схемой:
1. Расщепляем программу, исключая переход по метке, на линейно-независимые участки. Таких участков будет пять.
2. Строим таблицу отношений (связей) между участками.
3. Из таблицы формируем подмножества операторов. Для каждого подмножества организуется своя очередь.
4. Строим таблицу потактового совмещения взаимно независимых операторов.
В результате получаем, что время выполнения последовательной программы составит 18 единиц, а параллельной программы 15 единиц, но требует использования трех процессоров для выполнения трех параллельных нитей вычислений. Тогда выигрыш по быстродействию составит всего 20%.
Экономия памяти под переменные в обычной последовательной программе создает конкуренцию из-за дестабилизации данных при распараллеливании, которую можно устранить, если ввести две новые промежуточные переменные M, N. Тогда фрагмент программы с их использованием будет выглядеть:
...
M:=cos(y);
U:=u-v*M;
If u=0 then...
N:=sin(y);
Z:=w*x*N/u;
...
В этом случае время выполнения параллельной программы составит 13 единиц, что обеспечивает выигрыш по быстродействию 40%.
3. Распараллеливание циклов.
Циклы являются основными структурами со скрытым параллелизмом. Особенно это касается вложенных циклов.
FOR I1=1 TO R1 DO [PARALLEL]
...
FOR In=1 TO Rn DO [PARALLEL]
{тело цикла} T(I1,I2,...,In).
Здесь тело цикла повторяется 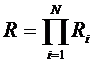 раз при разных сочетаниях индексов.
раз при разных сочетаниях индексов.
Основное условие распараллеливания циклов – это отсутствие условных и безусловных выходов из цикла во внешнюю область программы.
Если учитывать ещё связи в операторах тела цикла по переменным – счетчикам циклов, то можно достичь высокой степени распараллеливания.
Различают четыре типа циклов:
1. «скаляр-скаляр». 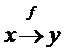
В теле цикла отсутствуют переменные (массивы), зависящие от индекса счетчика цикла. Таким образом, цикл эквивалентен либо некоторой ациклической линейной последовательности конструкций операторов, либо задаёт рекурсию сложной операции.
WHILE P DO x=f(x) END.
Для повышения быстродействия такого цикла используют сдваивание:
WHILE P DO x=f(f(x)) END.
Выигрыш достигается за счёт того, что сдвоенная функция f(f(x))вычисляется, как правило, быстрее, чем вызов унарной функции два раза.
Например, задана функция f(x)=a*x+b. Вычисление значения функции требует по одной операции умножения и сложения. Тогда два вызова функции требуют по две операции умножения и сложения. После операции сдваивания получаем:
f(f(x))=a*(a*x+b)+b=(a*a*x)+(a*b)+b,
что требует трёх операций умножения и двух сложений. Однако, при распараллеливании вычисления слагаемых (a*a*x) и (a*b)выполняются параллельными нитями за один шаг, обеспечивая повышение быстродействия программы.
2. «скаляр-вектор». 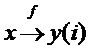 .
.
В цикле на основе некоторой скалярной информации генерируются элементы массива, где i– индекс элемента.
WHILE P DO x(i)=f(x(i-1); i=i+1 END.
3. «вктор-скаляр». 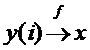 . В цикле выполняются редуцирующие действия над массивом, например, нахождение суммы элементов.
. В цикле выполняются редуцирующие действия над массивом, например, нахождение суммы элементов.
4. «вектор-вектор». 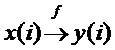 . В цикле выполняется преобразование элементов одного массива в элементы другого массива, например, сортировка.
. В цикле выполняется преобразование элементов одного массива в элементы другого массива, например, сортировка.
Может оказаться, что тело параллельного цикла T(i) также является циклом, но последовательным, то есть в каждой параллельной ветви исполняется некоторая параллельная последовательность операций.
Например,
FOR i=1 TO 16 DO x(i)=x(6*i-27).
В этом цикле производится выборка элементов массива. Здесь все операции цикла нельзя выполнить параллельно, так как между ними есть скрытая связь. Цикл можно разбить на кортежи операций, выполняемые параллельными нитями.
кортеж 1 | кортеж 2 | кортеж 3 | кортеж 4 |
x(1)=x(-21) | x(5)=x(3) | x(9)=x(27) | x(13)=x(51) |
x(2)=x(-15) | x(6)=x(9) | x(10)=x(33) | x(14)=x(57) |
x(3)=x(-9) | x(7)=x(15) | x(11)=x(39) | x(15)=x(63) |
x(4)=x(-3) | x(8)=x(21) | x(12)=x(45) | x(16)=x(69) |
Тогда, порядок вычислений можно задать вложенными циклами:
FOR i=1 TO 4 DO [PARALLEL]
FOR j=4*(i-1) TO 4*i DO
x(j)=x(6*j-27).
Здесь внешний цикл запускает параллельные нити для внутреннего цикла.
Следует учитывать, что быстродействие параллельной программы также как и последовательной зависит от того, как написана программа. Существует ряд простых способов повышения быстродействия программ.
1. Учёт времени выполнения операций внутри микропроцессора. Так операции сложения и вычитания выполняются быстрее, чем операции умножения, деления и обращения к стандартным подпрограммам. Тогда по возможности нужно использовать такие быстрые операции при вычислении значений выражений.
2*x→x+x (2*i+j)*0,5→(i+0,5*j) SQR(x) →x*x 2*x→shl(x)
Операции сдвига (shl, shr) выполняются быстрее, чем операции умножения.
2. Исключение повторных вычислений за счет введения промежуточных переменных. Например, при расчёте корней квадратного уравнения.
3. Исключение циклов.
Рассмотрим пример
For i:=1 To 1000 Do A[i]:=0;
For i:=1 To 1000 Do
For j:=1 To 10 Do
A[i]:=A[i]+C[i, j];
Этот фрагмент можно переписать так
For i:=1 To 1000 Do
Begin
x:=C[i,1];
For j:=2 To 10 Do A[i]:=x;
x:=x+C[i, j];
end;
Здесь выигрыш достигается, во-первых, за счет уменьшения количества циклов, а во-вторых, за счет того, что с введением временной переменной X уменьшено количество операций вычисления адресов элементов массива.
4. Развёртывание циклов. Этот приём является обратным к распараллеливанию.
Пример:
For i:=1 To 1000 Do
For i:=1 To 3 Do
A[i]:=A[i]+C[i, j];
Можно переписать этот фрагмент так
For i:=1 To 1000 Do
A[i]:=A[i]+C[i,1]+ C[i,2]+ C[i,3];
Однако применение указанных методов повышения быстродействия программ часто приводит к тому, что исчезает прозрачность программы и нарушаются принципы структурного программирования.
