
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Л. Г. КОМАРЦОВА, И. В.КОВАЛЕВ
Калужский филиал МГТУ им.
РЕДУКЦИЯ БАЗЫ ЗНАНИЙ С ИСПОЛЬЗОВАНИЕМ
ГЕНЕТИЧЕСКОГО АЛГОРИТМА
Рассмотрены проблемы устранения избыточности нечетких баз знаний на основе генетического алгоритма.
Одним из центральных моментов при формировании баз знаний (БЗ) в интеллектуальных системах является проблема устранения их избыточности для повышения достоверности вывода и сокращения времени просмотра правил при выводе.
Минимизация БЗ может быть поставлена как комбинаторная оптимизационная задача для одновременного достижения двух целей: минимизации ошибки распознавания и числа правил "IF … THEN" в БЗ.
Для выбора из всей совокупности правил Pall некоторого подмножества ![]() , которое будет определять классификацию образов с допустимой ошибкой, используем генетический алгоритм (ГА). С помощью ГА решение сформулированной выше проблемы применительно к нечеткой БЗ можно представить следующим образом:
, которое будет определять классификацию образов с допустимой ошибкой, используем генетический алгоритм (ГА). С помощью ГА решение сформулированной выше проблемы применительно к нечеткой БЗ можно представить следующим образом:
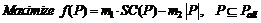 , (1)
, (1)
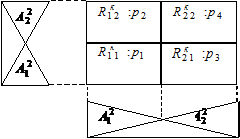 |
где SC(P) -число правильно распознаваемых примеров из P;
На рис. 1 представлено нечеткое разделение примеров для k=2; при этом метки нечетких правил соответствуют определенным нечетким подпространствам; pi представляет i - е cгенерированное правило.
Рис.1. Генерация нечетких правил IF-THEN для k=2
Формат представления нечетких правил:
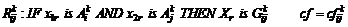 ,
,
где k- число нечетких интервалов по каждой координате, Rijk - метка нечеткого правила, Gijk - консеквент (один из M классов), ![]() - степень уверенности нечеткого правила IF … THEN, Aik и Ajk - нечеткие множества с треугольными функциями принадлежности
- степень уверенности нечеткого правила IF … THEN, Aik и Ajk - нечеткие множества с треугольными функциями принадлежности
Особенности применения ГА для редукции правил БЗ заключаются в следующем.
1. Кодирование хромосом.
Общее число сгенерированных правил для нечеткой БЗ определяется как: ![]() где L - число нечетких интервалов разбиения для входных переменных. Тогда каждому возможному решению, множеству правил
где L - число нечетких интервалов разбиения для входных переменных. Тогда каждому возможному решению, множеству правил ![]() ,будет соответствовать строка p1p2…pN, а каждое pr определяется как:
,будет соответствовать строка p1p2…pN, а каждое pr определяется как:

Поскольку фиктивное правило не участвует в классификации примеров, то положим pr=0.
2. Функция фитнесса определяется формулой (1), при этом берется наибольшее положительное значение: Fit(P)=max{f(P), 0}.
3. Генетические операторы: a) селекция: равновероятностный выбор пар хромосом для скрещивания, поскольку информация заранее не структурирована; b) кроссинговер: на первых этапах работы алгоритма – «дальнее родство» с последующим переходом на одноточечный; c) мутация: хромосомная (на первых этапах) с переходом на генную, которая применяется с заданной вероятностью к каждому биту битовой строки путем выполнения операции ![]() ; d) отбор: элитный, при котором лучшая хромосома (с наибольшей функцией фитнесса) текущей популяции сохраняется во всех следующих поколениях.
; d) отбор: элитный, при котором лучшая хромосома (с наибольшей функцией фитнесса) текущей популяции сохраняется во всех следующих поколениях.
Как показали проведенные эксперименты, коэффициент сокращения базы знаний во многом определяется параметрами ГА, поэтому требуются дальнейшие исследования.
