

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
C В нашей таблице в указанном диапазоне находятся 20 значений из 30, что составляет 66,7% от совокупности. Отличный результат! Честное слово, сам не ожидал!
Разобраться, является ли распределение нормальным, можно также с использованием медианы и процентилей (персентилей). Медиана – значение, которое делит распределение пополам: половина значений больше медианы, половина - меньше. Медиану можно также считать 50-м процентилем. Соответственно, 25-й и 75-й процентили отсекают от распределения по одной четвертой части наиболее низких и высоких значений [1].
При нормальном распределении отмечается определенное соотношение между процентилями и числом стандартных отклонений от среднего значения:
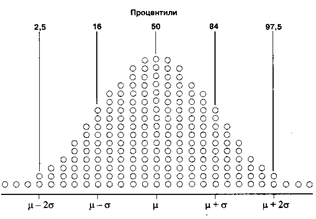
Если соответствие между процентилями и стандартными отклонениями от среднего значения не слишком отличается от приведенных на рисунке, то распределение близко к нормальному и при его описании можно использовать параметры распределения.
☼ Обращаем внимание: Для описания данных с асимметричным распределением необходимо использовать не среднее значение и стандартное отклонение, а медиану и процентили (обычно рассчитываются 25-й и 75-й процентили). В качестве границ нормы лабораторных показателей часто используют 5-й и 95-й процентили [1].
3. А зачем нам, собственно, все это нужно было считать?
Итак, мы выбрали данные, предположили их соответствие нормальному распределению, рассчитали среднее значение и стандартное отклонение. Что дальше?
По существу, с использованием этих двух чисел теперь могут проводиться дальнейшие статистические исследования – сравнение с другими группами (например, с донорами-женщинами) или динамическое наблюдение (например, влияние на уровень гемоглобина частоты и объема кроводач).
В качестве анонса следующего шага статистического анализа - сравнения двух групп данных - приводим следующую информацию. В той же лаборатории за такой же период времени (с 14 по 17 февраля 2005 г.) проведено определение гемоглобина у 21 женщины – донора крови и ее компонентов. Диапазон значений – от 120 до 139 г/л. Параметры распределения: среднее значение - 127,29; стандартное отклонение – 6,21 г/л (ошибка среднего – 1,35).
В качестве примера умышленно взят случай, где выводы заранее известны. И все-таки: являются ли обнаруженные различия с группой доноров-мужчин статистически значимыми? Как рассчитать широко применяемый в медицинских исследованиях критерий Стьюдента для выборок различного объема и правильно оценить полученный результат? Как избежать некоторых распространенных ошибок в использовании критерия Стьюдента? Ответы на эти и некоторые другие вопросы – в следующем выпуске Бюллетеня.
Особые слова восхищения – доктору Гланцу, профессору медицины Калифорнийского университета (Сан-Франциско), за увлекательнейшую книгу «Медико-биологическая статистика».
Литература:
1. Медико-биологическая статистика. /Пер. с англ.- // - М., Практика, 1998. – 459 с.
2. Качество клинических лабораторных исследований. Новые горизонты и ориентиры. /Под ред. // - М., 2002, - 304 с.
3. Макарова в Excel: Учебное пособие. /, //-М.,Финансы и статистика, 2002. – 368 с.
4. Реброва анализ медицинских данных. Применение пакета прикладных программ STATISTICA. / - М., МедиаСфера, 2003. – 312 с.
Статистический анализ лабораторных данных
/шаг второй: сравнение двух групп с использованием критерия Стьюдента/
, к. м.н., заведующий клинико-диагностической лабораторией БУЗ УР «Первая республиканская клиническая больница МЗ УР», главный специалист по клинической лабораторной диагностике Министерства здравоохранения Удмуртской Республики
Чтобы правильно задать вопрос, нужно знать большую часть ответа.
- Р. Шекли
В предыдущем выпуске журнала мы описали с использованием параметров нормального распределения две группы данных – реальные результаты определения концентрации гемоглобина у доноров крови и ее компонентов в дежурной лаборатории ГУЗ «1РКБ» с 14 по 17 февраля 2005 г. Систематизируем (размещаем в формате таблицы) полученную ранее информацию:
Концентрация гемоглобина у доноров
Мужчины | Женщины | |
Число обследованных (n) | 30 | 21 |
Диапазон значений (г/л) | 120 – 139 | |
Среднее значение (M) | 147,13 | 127,29 |
Стандартная ошибка среднего (m) | 1,56 | 1,35 |
Стандартное отклонение (s) | 8,54 | 6,21 |
Примечание: Результаты расчетов в таблице (M, m, s) приведены с избыточным числом значащих цифр. Рекомендуется отображать значения этих параметров с той же точностью, что и исходные данные [5]. Например, если гемоглобин измерялся с точностью до разряда единиц, то данные в формате M ± m должны выглядеть как 147 ± 2 г/л. Тем не менее, признаюсь, не смог себя заставить отказаться от знаков после запятой. Оставалось пожалеть, что в качестве примера был выбрана концентрация гемоглобина, а не количество эритроцитов. ☺☺☺
![]() Приведенные в таблице данные не противоречат общеизвестной истине о более высоких значениях гемоглобина у мужчин. В то же время, у некоторых женщин концентрация гемоглобина выше, чем у некоторых мужчин (см. диапазон значений)!!!
Приведенные в таблице данные не противоречат общеизвестной истине о более высоких значениях гемоглобина у мужчин. В то же время, у некоторых женщин концентрация гемоглобина выше, чем у некоторых мужчин (см. диапазон значений)!!!
Теперь, приведя в действие все имеющиеся в наличии запасы собственного скептицизма, мы можем высказать предположение, что на самом деле концентрация гемоглобина не связана с полом, а полученные различия – всего лишь игра случая. Взяв результаты определения гемоглобина за следующие три дня, мы, возможно, получим совершенно противоположную картину.
☼ По существу, сейчас мы сформулировали «нулевую гипотезу» - предположение, что те или иные факторы не оказывают никакого влияния на исследуемую величину, а наблюдаемые различия между группами носят случайный характер. Собственно, дальнейший статистический анализ при сравнении двух групп данных как раз и заключается в опровержении нулевой гипотезы.
Обычно нулевая гипотеза (Н0) формулируется таким образом, чтобы она была противоположна той научной идее (ее называют альтернативной гипотезой Н1), которая и послужила поводом для проведения исследования. Например, хотим доказать, что вегетарианская диета приводит к снижению холестерина – в качестве нулевой гипотезы рассматриваем утверждение, что уровень холестерина не зависит от диеты.
Для проверки (подтверждения или опровержения) нулевой гипотезы используются статистические критерии - методы оценки статистической значимости различий, лидером по уровню популярности среди которых является критерий Стьюдента ( t ). Кстати, критерием называют не только метод статистического анализа, но и ту величину, которая получается в результате его применения.
Расчет критерия Стьюдента
Наиболее простая формула расчета критерия Стьюдента выглядит так:
![]()
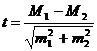
(в числителе – разность средних значений двух групп, в знаменателе – квадратный корень из суммы квадратов стандартных ошибок этих средних)
Таким образом, все данные, необходимые для расчета, есть в нашей таблице. Существуют и другие варианты этой формулы, например, с использованием числа наблюдений и стандартных отклонений:
![]()
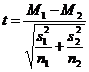
(в знаменателе – квадратный корень из суммы квадратов стандартных отклонений, деленных на число наблюдений в соответствующей группе)
Обе приведенные формулы предельно просты и доступны для применения даже «в походных условиях» - при отсутствии какой-либо вычислительной техники. Достаточно блокнота и карандаша. Но, строго говоря, применение обеих формул можно считать корректным только в случае равных по численности групп. В реальной жизни исследователь часто работает с произвольными выборками – то есть с неодинаковым числом наблюдений (n) в каждой группе.
Рассматриваем «правильную» формулу. Напомним, что мы проверяем нулевую гипотезу, подразумевающую, что обе группы данных – случайные выборки из одной совокупности. В этом случае из двух квадратов стандартных отклонений s12 и s22 (NB!!! – квадрат любого стандартного отклонения – то есть величина s2 – называется дисперсией) мы должны рассчитать объединенную оценку дисперсии для двух групп данных [1]:
![]()
![]()
Теперь, зная объединенную оценку дисперсии s2 для двух произвольных выборок, рассчитываем «полноценный» критерий Стьюдента:
![]()
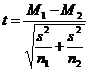
(в знаменателе – квадратный корень из суммы отношений объединенной оценки дисперсии {формула 3} к числу наблюдений в каждой группе)
Возвращаемся к нашей таблице с результатами определения гемоглобина. Поскольку группы неравнозначны по объему (n1=30; n2=21), рассчитываем объединенную оценку дисперсии {формула 3}:
![]()
![]()
(стандартные отклонения s1=8,54 и s2=6,21 также взяты из нашей таблицы)
Заключительный аккорд {формула 4}:
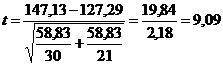
PМожно считать, мы пришли к очередному «промежуточному финишу» - критерий мы рассчитали (t = 9,09), но теперь требуется правильно его оценить.
Интерпретация результатов
Принцип оценки критерия: Чем ближе к нулю полученный результат (т. е. наблюдается маленькая разность средних в числителе дроби, при большой стандартной ошибке этой разности, вычисляемой в знаменателе), тем больше вероятность нулевой гипотезы. И наоборот, чем выше полученное значение t, тем больше оснований отвергнуть нулевую гипотезу и считать, что различия статистически значимы. Значение критерия, начиная с которого мы отвергаем нулевую гипотезу, называется критическим значением tα [1].
Далее, чтобы определиться с критическим значением для сравнения конкретных групп, придется разобраться еще с несколькими терминами статистического анализа.
Итак, смысл наших расчетов - отклонить (или принять) нулевую гипотезу. Но если исследователь на основании статистического критерия отклоняет нулевую гипотезу там, где она на самом деле верна, то есть находит различия там, где их нет, принято говорить об ошибке первого рода (α-ошибке). Максимально допустимая вероятность ошибочно отвергнуть нулевую гипотезу называется уровнем значимости и обозначается греческим символом α («альфа») [5].
Уровень значимости формально может задаваться непосредственно исследователем, но надо учитывать, что в медицинских исследованиях традиционно считается достаточной, чтобы вероятность α-ошибки не превышала 5% (записывается как α = 0,05). Соответственно, чем меньше уровень значимости, тем выше критическое значение tα.
Уменьшая α, например, до 0,01 мы уменьшаем вероятность найти несуществующие различия до 1%. В свою очередь, слишком низкий уровень значимости (и, следовательно, слишком высокое критическое значение!) приводит к риску не найти различий там, где они есть - ошибочно подтвердить нулевую гипотезу. В этом случае речь идет об ошибке второго рода (β-ошибке).
Другим фактором, влияющим на критическое значение, является число наблюдений в группах. Чем больше объем выборок, тем меньше критическое значение tα. Объясняется это тем, что в больших выборках параметры распределения меньше зависят от случайных отклонений и точнее представляют исходную совокупность данных [1].
Величину, отражающую объем выборок и влияющую на критическое значение, называют числом степеней свободы и обозначают греческой буквой ν («ню»):
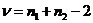
Таким образом, мы готовы назвать оба фактора, влияющих на критическое значение. В нашем примере с гемоглобином у доноров, принимаем уровень значимости α = 0,05 (не будем без особой необходимости изменять традициям) и рассчитываем число степеней свободы ν = 30 + 21 – 2 = 49.
Формулы для расчета критических значений достаточно сложны, поэтому принято пользоваться готовыми таблицами. Приводим фрагмент таблицы [6] с наиболее актуальными значениями α и ν. Двусторонний вариант таблицы предназначен для оценки как положительных, так и отрицательных значений t (например, расчетные значения t = 2,1 и t = -2,1 будут оцениваться как одинаковые).
Критические значения t
/двусторонний вариант/
Уровень значимости α | |||
ν | 0,05 | 0,01 | 0,001 |
15 | 2,131 | 2,947 | 4,073 |
16 | 2,120 | 2,921 | 4,015 |
17 | 2,110 | 2,898 | 3,965 |
18 | 2,101 | 2,878 | 3,922 |
19 | 2,093 | 2,861 | 3,883 |
20 | 2,086 | 2,845 | 3,850 |
21 | 2,080 | 2,831 | 3,819 |
22 | 2,074 | 2,819 | 3,792 |
23 | 2,069 | 2,807 | 3,768 |
24 | 2,064 | 2,797 | 3,745 |
25 | 2,060 | 2,787 | 3,725 |
26 | 2,056 | 2,779 | 3,707 |
27 | 2,052 | 2,771 | 3,690 |
28 | 2,048 | 2,763 | 3,674 |
29 | 2,045 | 2,756 | 3,659 |
30 | 2,042 | 2,750 | 3,646 |
31 | 2,040 | 2,744 | 3,633 |
32 | 2,037 | 2,738 | 3,622 |
33 | 2,035 | 2,733 | 3,611 |
34 | 2,032 | 2,728 | 3,601 |
35 | 2,030 | 2,724 | 3,591 |
36 | 2,028 | 2,719 | 3,582 |
37 | 2,026 | 2,715 | 3,574 |
38 | 2,024 | 2,712 | 3,566 |
39 | 2,023 | 2,708 | 3,558 |
40 | 2,021 | 2,704 | 3,551 |
42 | 2,018 | 2,698 | 3,538 |
44 | 2,015 | 2,692 | 3,526 |
46 | 2,013 | 2,687 | 3,515 |
48 | 2,011 | 2,682 | 3,505 |
50 | 2,009 | 2,678 | 3,496 |
60 | 2,000 | 2,660 | 3,460 |
70 | 1,994 | 2,648 | 3,435 |
80 | 1,990 | 2,639 | 3,416 |
90 | 1,987 | 2,632 | 3,402 |
100 | 1,984 | 2,626 | 3,390 |
200 | 1,972 | 2,601 | 3,340 |
∞ | 1,960 | 2,576 | 3,290 |
Находим в таблице строку с определенным для наших групп числом степеней свободы (при его отсутствии берется ближайшее меньшее значение – в нашем случае 48 вместо 49). Определяем, что при уровне значимости α = 0,05 критическое значение критерия Стьюдента составляет t = 2,011.
Следовательно, все значения t > 2,011, полученные в тесте {формулы 1, 2 или 4}, позволяют отказаться от нулевой гипотезы и признать различия между группами как статистически значимые. В примере с концентрацией гемоглобина у доноров мы ранее получили t = 9,09 для разности средних в мужской и женской группе, что с большим запасом превышает критическое значение даже для уровня значимости α = 0,001. Какие выводы мы имеем право сделать теперь?
Последний штрих: указываем p
Для завершения анализа нужна еще одна характеристика, которая как раз и фигурирует в большинстве научных работ – p! Дело в том, что кроме критерия Стьюдента существует довольно много других статистических критериев для оценки значимости различий. Способы расчета и критические значения каждый раз будут разные, но выводы в любом случае будут отражать вероятность справедливости нулевой гипотезы. Универсальное обозначение этой вероятности – латинский символ p. Если формулировать совсем коротко, p – это вероятность ошибки. Точнее, речь идет о вероятности ошибочно отклонить нулевую гипотезу об отсутствии различий, то есть о вероятности α-ошибки!
Например, если полученный t оказывается ниже критического значения для α=0,05, в принятой системе обозначений это записывается как p>0,05. Другими словами, вероятность справедливости нулевой гипотезы в этом случае превышает 5%, что не позволяет считать различия статистически значимыми. В случае, когда t превышает критическое значение для α=0,05, (но остается меньше критического значения для α=0,01), результат записывается как p<0,05.
☼ Обращаем внимание: в отличие от уровня значимости α, который задается исследователем, вероятность ошибки p – характеристика реальных результатов относительно заданного заранее уровня значимости.
B Что же касается наших доноров, вероятность справедливости нулевой гипотезы о независимости от пола концентрации гемоглобина составляет менее 0,1%, то есть p<0,001, что соответствует максимально высокой оценке значимости различий.
? Дополнительные замечания:
1. Не следует вместо термина «статистически значимые» использовать популярное выражение «достоверные», имеющее в статистике другое значение, а именно - соответствие структуры исследования поставленным научным задачам, правильность сбора и анализа данных и т. д. [5].
2. Критерий Стьюдента очень популярен. Тем не менее, надо учитывать, что для его применения значения признаков в каждой из сравниваемых групп должны иметь распределение, близкое к нормальному, а их дисперсии приблизительно равны [1,2,5].
3. Критерий Стьюдента предназначен для сравнения только двух групп, а не нескольких групп попарно. В случае использования критерия Стьюдента для множественных сравнений (то есть сравнения более двух групп) требуется введение поправки Бонферрони, либо применение других критериев, например, Ньюмена-Кейлса или Даннета [1].
Литература:
1. Медико-биологическая статистика. /Пер. с англ.- // - М., Практика, 1998. – 459 с.
2. Кулаичев и средства анализа данных в среде Windows. STADIA 6.0 –М.: Информатика и компьютеры, 19с.
3. Макарова в Excel: Учебное пособие. /, //-М.,Финансы и статистика, 2002. – 368 с.
4. Нименья . - СПб.: Издательский дом «Нева»; М.: ОЛМА-ПРЕСС, 2003. – 160 с.
5. Реброва анализ медицинских данных. Применение пакета прикладных программ STATISTICA. / - М., МедиаСфера, 2003. – 312 с.
6. Zar J. H. Biostatistical analysis (2 ed.). Prentice-Hall, Englewood Cliffs, N. J., 1984.
Статистический анализ лабораторных данных
/шаг третий: доверительный интервал против критерия Стьюдента?/
, к. м.н., заведующий клинико-диагностической лабораторией БУЗ УР «Первая республиканская клиническая больница МЗ УР», главный специалист по клинической лабораторной диагностике Министерства здравоохранения Удмуртской Республики
Если что-либо делается неправильно достаточно часто, оно становится правильным.
- закон Мерфи
Стьюдент (Student) – псевдоним одного из основоположников теории статистических оценок и проверки гипотез, английского математика и статистика Уильяма Госсета (William Sealy Gosset, 1876 – 1937), доказавшего, что оценка расхождения между средним значением малой выборки и средним значением генеральной совокупности подчиняется особому закону распределения, где для определения пределов ошибки может быть использован t-критерий.
В предыдущем выпуске журнала, используя критерий Стьюдента, мы выяснили (а точнее, подтвердили общеизвестный факт), что отличия средних значений концентрации гемоглобина в двух реальных группах доноров (мужчин и женщин) являются статистически значимыми. Кроме того, было установлено, что вероятность ошибки нашего заключения составляет менее 0,1% (p<0,001). Или, другими словами, с вероятностью ошибки менее 0,1% мы отклонили нулевую гипотезу о равенстве средних значений концентрации гемоглобина в группах мужчин и женщин.
Казалось бы, научная задача выполнена: исследование можно заканчивать и бодро рапортовать миру о полученных результатах. Тем не менее, к числу наиболее распространенных ошибок в медицинской статистике, наряду с некорректным использованием критерия Стьюдента (например, при отсутствии нормального распределения данных, либо при очень широко распространенном попарном сравнении более двух групп данных), относится подмена понятий «статистически значимый» и «клинически значимый». А это, сожалению, далеко не одно и то же! LLL
~ К сожалению, собственно критерий Стьюдента не позволяет характеризовать величину выявленных различий. Даже очень малые различия средних значений (M1 - M2) при большой численности групп могут оказаться статистически значимыми [1]:
, где 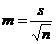
(чем больше число наблюдений - n, тем меньше становится стандартная ошибка среднего - m, следовательно, выше критерий Стьюдента - t )
☺ Как в таких случаях иногда пишут в научных статьях и диссертациях, различия являются «высоко достоверными», хотя речь идет о разности средних, сопоставимой с аналитической или биологической вариацией исследуемого показателя [1].
Характеристикой, которая дополняет и даже (в определенной степени) заменяет суждение «значимо-незначимо», является доверительный интервал. Смысл доверительного интервала в том, что не зная точного значения какой-либо величины, мы все-таки можем с заданной вероятностью указать интервал, в котором эта величина находится [1].
Таким образом, доверительный интервал (ДИ) – интервал значений, рассчитанный для какого-либо параметра по выборке и с определенной вероятностью (например, 95%) включающий истинное значение этого параметра во всей генеральной совокупности [2].
☼ Обращаем внимание: в современной научной медицинской литературе представление результатов исследования с использованием доверительных интервалов получает все большее распространение, а в ряде зарубежных изданий представление ДИ для основных результатов исследований становится обязательным требованием [2].
Доверительный интервал может быть построен для самых разных величин – например, для средних значений и для их разности; для доли значений (положительных, отрицательных) и для разности этих долей. Более того – доверительный интервал может быть рассчитан даже для ожидаемых значений измеряемого признака, что часто используется при определении границ нормы для лабораторных показателей [1].
В общих чертах, построение доверительных интервалов строится на тех же математических принципах, что и проверка статистических гипотез с использованием критериев [2], поэтому для работы понадобятся те же самые параметры описательной статистики, что и при вычислении критерия Стьюдента. Для удобства повторяем таблицу.
Концентрация гемоглобина у доноров
Мужчины | Женщины | |
Число обследованных (n) | 30 | 21 |
Диапазон значений (г/л) | 120 – 139 | |
Среднее значение (M) | 147,13 | 127,29 |
Стандартная ошибка среднего (m) | 1,56 | 1,35 |
Стандартное отклонение (s) | 8,54 | 6,21 |
Оценка t-критерия для разности средних | ||
t-критерий (критерий Стьюдента) для разности средних | 9,09 | |
Критическое значение t для α=0,05 и ν=49 (из таблицы) | 2,01 | |
Вероятность ошибки p | <0,001 | |
I. Построение доверительного интервала для разности средних
Если разность выборочных средних обозначается как M1 - M2, разность истинных средних генеральных совокупностей обозначим, как µ1-µ2. Теперь необходимо найти верхнее и нижнее предельные значения, между которыми и будет с заданной вероятностью находиться величина µ1-µ2. В медицинских исследованиях наиболее часто вычисляется 95% доверительный интервал, что соответствует уровню значимости α=0,05.
Не вдаваясь в математические подробности движения от формулы критерия Стьюдента к формуле границ ДИ, приводим пошаговый алгоритм расчета верхней и нижней границы. ☼ Обращаем внимание: практически все необходимые результаты для первых трех шагов мы уже получали ранее при работе над критерием Стьюдента (!):
1. Находим разность выборочных средних:
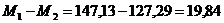
2. Считаем число степеней свободы («ню»), затем в таблице критических значений для критерия Стьюдента берем значение tα, где α принимается равным 0,05:
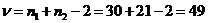
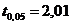 для
для ![]()
3. Вычисляем объединенную оценку дисперсии s2, а затем стандартную ошибку разности средних sM1-M2:
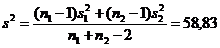
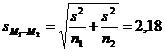
4. Находим произведение значения tα и стандартной ошибки разности sM1-M2:
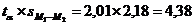
5. Заканчиваем построение 95% доверительного интервала для разности средних, определяя верхнюю и нижнюю границы:
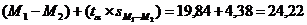
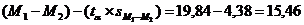
P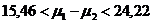
Смысл последнего выражения можно выразить так: наши выборочные данные позволяют с 95% надежностью (то есть в 95 из каждых 100 случайных выборок из генеральной совокупности) утверждать, что истинное среднее значение концентрации гемоглобина у доноров крови мужского пола выше аналогичного показателя у доноров-женщин на величину от 15,46 до 24,22 г/л.
Таким образом, благодаря доверительному интервалу мы не просто констатируем статистическую значимость различий между средними значениями гемоглобина в двух группах доноров, но и указываем величину выявленных различий. В случае необходимости несложно пересчитать границы доверительного интервала с другой степенью надежности: в приведенных выше формулах изменится только одна величина – tα. Так, для 99% доверительного интервала t0,01 = 2,68. Следовательно, интервал возможных значений разности средних будет немного шире – от 14,00 до 25,68 г/л.
II. Проверка гипотез с помощью доверительных интервалов
Итак, сообщая миру о статистически значимых различиях, где p<0,001, имеет смысл указать еще и доверительный интервал для разности средних, дающий возможность судить о величине различий. В этом случае мы сможем вовремя заметить, что статистическая значимость обнаружена всего лишь благодаря большому объему выборки, тогда как клиническая значимость исследования осталась весьма сомнительной. LLL
Более того, доверительные интервалы вполне могут заменить статистические критерии и при оценке статистической значимости различий. Дело в том, что истинная разность средних может находиться в любой точке доверительного интервала. Поэтому, если полученный при работе с выборками доверительный интервал содержит нулевое значение, это значит, что истинная разность средних также может быть равна нулю. Следовательно, мы не имеем оснований отвергнуть нулевую гипотезу. В свою очередь, если доверительный интервал не содержит нуля, мы можем с заданной уверенностью отказаться от нулевой гипотезы и считать различия статистически значимыми [1].
Вообще, существует несколько несложных правил [2] интерпретации доверительных интервалов с точки зрения проверки статистических гипотез:
? 1. Если ДИ для разности средних включает ноль, то следует считать, что различия между группами по анализируемому признаку отсутствуют;
? 2. Если 95% ДИ не включает ноль, то следует считать, что различие между группами существует при уровне статистической значимости 0,05;
? 3. Если ДИ включает как клинически значимые, так и клинически незначимые значения, то результаты недостаточно точны для того, чтобы сделать определенный вывод.
C Как видим, в случае с нашими донорами доверительный интервал не содержит не только нулевого значения, но и клинически незначимых чисел. То есть мы достаточно уверенно можем говорить как о статистической, так и клинической значимости выявленных различий.
Заключение
В настоящее время применяются оба подхода к сравнению двух групп по количественному признаку: путем проверки статистических гипотез и с использованием доверительных интервалов. Эти два подхода дают ответы на различные вопросы: в первом случае – «В какой степени можно быть уверенным, что различия между генеральными совокупностями действительно существуют?», во втором – «Насколько велики различия генеральных совокупностей?» [2].
Оба подхода основаны на одних и тех же допущениях и статистических принципах, поэтому скорее не конкурируют, а дополняют друг друга. Тем не менее, значение подхода с построением доверительных интервалов все более возрастает. Знакомясь с работой, содержащей лишь средние значения, стандартные ошибки средних и число наблюдений, мы можем самостоятельно рассчитать доверительный интервал, чтобы понять, имеет исследование сугубо академическую, либо еще и практическую ценность [1].
Литература:
1. Медико-биологическая статистика. /Пер. с англ.- // - М., Практика, 1998. – 459 с.
2. Реброва анализ медицинских данных. Применение пакета прикладных программ STATISTICA. / - М., МедиаСфера, 2003. – 312 с.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 |
