

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Статистический анализ лабораторных данных
, к. м.н., заведующий клинико-диагностической лабораторией БУЗ УР «Первая республиканская клиническая больница МЗ УР», главный специалист по клинической лабораторной диагностике Министерства здравоохранения Удмуртской Республики
Вместо эпиграфа:
Правила этой Игры нельзя выучить иначе чем обычным, предписанным путем, на который уходят годы, да ведь никто из посвященных и не заинтересован в том, чтоб правила эти можно было выучить с большой легкостью. – Г. Гессе
 Результаты лабораторных исследований - излюбленный объект для статистической обработки в научных трудах по самым различным медицинским специальностям. Парадокс заключается в том, что сами врачи клинико-диагностических лабораторий к статистическому анализу лабораторных данных почти не проявляют интереса. Похоже, золотой песок и самородки будут и дальше (кстати, вполне заслуженно) доставаться энергичным искателям, а не пассивным «хозяевам территории».☺☺☺
Результаты лабораторных исследований - излюбленный объект для статистической обработки в научных трудах по самым различным медицинским специальностям. Парадокс заключается в том, что сами врачи клинико-диагностических лабораторий к статистическому анализу лабораторных данных почти не проявляют интереса. Похоже, золотой песок и самородки будут и дальше (кстати, вполне заслуженно) доставаться энергичным искателям, а не пассивным «хозяевам территории».☺☺☺
Тем не менее, наша новая рубрика – это попытка убедить коллег, что медицинская статистика – увлекательный поиск закономерностей в окружающем море информации – может быть понятна и доступна многим. А ответ на вопрос «Где взять данные для анализа?» невероятно прост: в обычном лабораторном журнале! Для начала работы нужна только идея: что и с чем будем сравнивать.
Сразу же стоит заметить, что обещание дать исчерпывающие сведения о методах статистического анализа в коротких журнальных статьях выглядело бы, по меньшей мере, наивным. Такая цель нами и не ставится. Те специалисты, что действительно заинтересуются статистическим анализом, могут затем обратиться к серьезной литературе.
Шаг первый: описание данных.
Основными задачами статистического анализа в большинстве случаев являются:
1. Описание группы (групп) данных с расчетом параметров распределения;
2. сравнение (с учетом параметров распределения) нескольких групп данных [4].
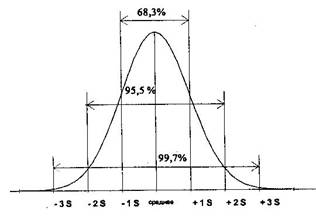
Компактным описанием данных «занимается» описательная статистика, в фундаменте которой лежит понятие «нормальное распределение» [1].
Нормальное (гауссово) распределение признака встречается очень часто: если некая величина (например, концентрация гемоглобина крови) отклоняется от среднего значения под действием множества слабых, независимых друг от друга факторов (поступление и потери железа, интенсивность эритропоэза и время жизни эритроцитов и т. д.).
Итак, если значения интересующего нас признака у большинства объектов близки к их среднему и с равной вероятностью отклоняются от него в большую или меньшую сторону, распределение называется нормальным (гауссовым) [1,2]. Для описания такого распределения используются параметры:
1. среднее значение (М);
2. стандартное отклонение (s).
Далее осторожно перейдем к практике. Выписываем из лабораторного журнала реальные лабораторные данные: результаты определения концентрации гемоглобина у 30 взрослых мужчин – доноров крови и ее компонентов (исследования были выполнены с 14 по 17 февраля 2005 г. в дежурной лаборатории нашего учреждения).
Алгоритм расчета параметров распределения:
1. Размещаем полученные данные в таблице в виде вертикальной колонки;
Рассчитываем среднее арифметическое имеющихся данных: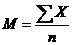
(сумму значений концентрации гемоглобина делим на число проб)
3. Вторую колонку заполняем отклонениями данных от среднего значения:
![]()
(из каждого значения вычитается среднее арифметическое)
4. В третью колонку таблицы вносим квадраты полученных отклонений:
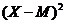
5. Рассчитываем стандартное отклонение (среднее квадратическое отклонение)
![]()
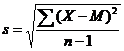
(сумму квадратов отклонений делим на величину [число проб минус единица] и извлекаем квадратный корень)
Далее в таблице отражена схема расчета. В третьей колонке среднее значение для удобства вычислений (и восприятия) округлено до целого числа. В данном примере это практически не влияет на величину стандартного отклонения.
№ | X | (X-M) | (X-M)2 |
1 | 148 | 1 | 1 |
2 | 139 | -8 | 64 |
3 | 133 | -14 | 196 |
4 | 151 | 4 | 16 |
5 | 147 | 0 | 0 |
6 | 147 | 0 | 0 |
7 | 145 | -2 | 4 |
8 | 151 | 4 | 16 |
9 | 138 | -9 | 81 |
10 | 144 | -3 | 9 |
11 | 162 | 15 | 225 |
12 | 148 | 1 | 1 |
13 | 145 | -2 | 4 |
14 | 130 | -17 | 289 |
15 | 155 | 8 | 64 |
16 | 136 | -11 | 121 |
17 | 151 | 4 | 16 |
18 | 157 | 10 | 100 |
19 | 154 | 7 | 49 |
20 | 144 | -3 | 9 |
21 | 136 | -11 | 121 |
22 | 159 | 12 | 144 |
23 | 142 | -5 | 25 |
24 | 136 | -11 | 121 |
25 | 154 | 7 | 49 |
26 | 153 | 6 | 36 |
27 | 165 | 18 | 324 |
28 | 149 | 2 | 4 |
29 | 151 | 4 | 16 |
30 | 144 | -3 | 9 |
∑ X | 4414 | ∑ (X-M)2 | 2114 |
n | 30 | n-1 | 29 |
M | 147,13 | s | 8,54 |
Таким образом, в результате несложных расчетов получаем два основных параметра – среднее значение и стандартное отклонение, характеризующие распределение признака в совокупности данных (в нашем случае – значения концентрации гемоглобина у доноров-мужчин).
Полученные результаты мы можем записать в формате M ± s, в нашем примере это: 147,13 ± 8,54 г/л. В современной литературе все чаще рекомендуют использовать другой формат записи данных: M(s), то есть 147,13 (8,54) г/л [4].
☼ Обращаем внимание: Среднее значение и стандартное отклонение измеряются в тех же единицах, что и исходные данные (в частности, для гемоглобина крови – г/л) [1].
А сейчас о проблемах:
1. Не путаем стандартное отклонение и стандартную ошибку среднего!
К сожалению, в большинстве научных работ полученные нами данные выглядели бы так: M ± m, в цифрах это 147,13 ± 1,56 г/л.
Что такое и откуда берется m – стандартная ошибка среднего? В большинстве случаев мы имеем дело не с генеральной совокупностью, а со случайной выборкой. Если мы возьмем для статистического анализа результаты определения гемоглобина за другие дни и у других доноров, среднее значение будет несколько отличаться от той величины, которую мы только что получили.
Но распределение средних значений различных выборок тоже подчиняется закону Гаусса!!! Стандартная ошибка среднего отражает диапазон значений, в котором должно находиться среднее значение при использовании других выборочных данных. В нашем примере это значит, что приблизительно в 70% случаев среднее значение любой случайной выборки будет находиться в диапазоне от 145,57 до 148,69 г/л.
Для расчета стандартной ошибки среднего используется простая формула:
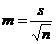
(стандартное отклонение делится на квадратный корень из числа наблюдений)
Авторы научных работ предпочитают указывать вместо стандартного отклонения стандартную ошибку среднего, которая имеет заведомо меньшую величину: в таком виде результаты вызывают большее доверие. Следует учитывать, что при достаточно большом числе наблюдений (n) стандартная ошибка среднего будет стремиться к минимальным, (близким к нулю) значениям даже при большом стандартном отклонении! [1] LLL
Собственно, в этом нет ничего «незаконного»: если вместе со стандартной ошибкой приводятся сведения о числе наблюдений, любой желающий может быстро вычислить стандартное отклонение:
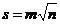
(стандартная ошибка среднего умножается на квадратный корень из числа наблюдений)
N Проблема заключается в том, что стандартная ошибка отражает только точность оценки среднего и не дает наглядного представления о разбросе данных [1].
Таким образом, описывая совокупность данных, рекомендуется приводить значение стандартного отклонения. Или, как минимум, указывать вместе со стандартной ошибкой число наблюдений.
2. Можно ли считать данное распределение нормальным?
Насколько правомерно использование параметров нормального распределения для описания конкретной совокупности данных?
Пакет анализа данных MS Excel позволяет построить из любого ряда данных гистограмму распределения значений, автоматически рассчитывая оптимальный «интервал карманов» [3]. Ниже представлено графическое распределение значений концентрации гемоглобина у наших доноров:
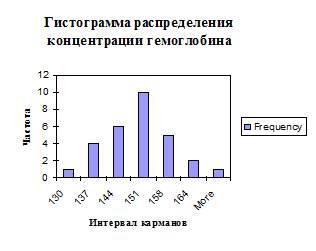 Разумеется, реальная гистограмма из 30 значений не является такой «гладкой» и симметричной, как на рисунке с классической функцией Гаусса (см. начало статьи). Но, чем большее число наблюдений будет в нашем исследовании, тем ближе получится график функции к «идеальному» виду.
Разумеется, реальная гистограмма из 30 значений не является такой «гладкой» и симметричной, как на рисунке с классической функцией Гаусса (см. начало статьи). Но, чем большее число наблюдений будет в нашем исследовании, тем ближе получится график функции к «идеальному» виду.
Любопытства ради, проверим справедливость закона нормального распределения Гаусса на наших данных. При нормальном распределении признака приблизительно 68,3% всех значений гемоглобина крови должны находиться в пределах одного стандартного отклонения от среднего значения, то есть в диапазоне от 139 до 155 г/л [2].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 |
