
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
О некоторой схеме распознавания на основе признакового подобия объектов.
Алгоритм построения дерева распознавания.
Аннотация
В статье излагается методика построения дерева распознавания объектов, заданных конечным числом целочисленных признаков. При создании распознающей схемы используется понятие алгебраической информативности признаков. Приводится пример набора признаков, построенных на топологических характеристиках «обедненных» растровых объектов и выбранных по соображениям наибольшей информативности.
Введение
Достаточно распространенной схемой распознавания каких-либо объектов на основе признаков является следующая схема:
Имеется база обучения и функция, отображающая множество объектов в пространство признаков. Другими словами каждому объекту можно сопоставить некоторый вектор признаков.
Имеется распознающая функция, т. е. функция, отображающая пространство признаков в некоторый алфавит.
Под деревом распознавания (в дальнейшем, просто деревом) будет пониматься граф, состоящий из двух типов узлов: узлов ветвления и терминальных узлов. Каждый узел ветвления имеет один вход из некоторого другого узла ветвления. Исключение составляет единственный “корневой” узел, на вход которого приходит образец для распознавания. Узел ветвления имеет несколько выходов к узлам следующего уровня. Терминальный узел также имеет один вход, а на выходе дает коллекцию альтернатив вместе с их вероятностными оценками. Построение дерева распознавания производится на основе некоторой базы распознанных образцов ( обучающей базы ). В число признаков обязательно включен код идентификации объекта ( код образца ). С каждым узлом дерева можно отождествить некоторое подмножество базы, а именно, те и только те образцы базы, которые при распознавании пройдут через данный узел. С этой точки зрения дереву соответствует последовательность разбиений базы и построение очередного узла дерева сводится к тому, что для данного подмножества М базы требуется произвести очередное подразбиение. В статье описывается одна из возможных схем создания такого разбиения, основанная на понятии информационной матрицы и матрицы переходов (см. [1], стр. 30), построенных для двух слов, одним из которых является набор значений рассматриваемого признака, а вторым алфавит, представленный в подмножестве М. Выбор признака, используемого при построении матрицы переходов происходит из соображений максимума информативности ([1], стр. 11) этого признака на базе М. В приложении 2 приводится пример признаков, расчитываемых для утоньшенного растра распознаваемых букв. Приведенные в приложении 2 признаки, а также геометрические понятия, используемые для расчета признаков предложенны . .
Квантование признаков и факторизация алфавита
Простым признаком называется целочисленная функция, определенная на множестве образцов {A}, Xi = Xi(A), A-некоторый образец. Предположим для определенности, что признак X может принимать значения 0, 1, ... , n и 0= m0 < m1 < ... < mk = n, mk+1=n+1, тогда определим новый признак Y(A) = j, если mj <= X(A) < mj+1. Y(A) называется квантованным признаком. Пример простейшего квантования: Y(A) = [X(A)/m], m < n, где квадратными скобками обозначена целая часть числа. Несколько обобщая это понятие, квантованием можно назвать любое разбиение множества значений признака на непересекающиеся подмножества с последующим приписыванием каждому из полученных подмножеств определенных числовых значений. Квантование используется для признаков, принимающих большое количество значений и имеет две цели: это уменьшение размеров матриц переходов и увеличение диапазона “охвата” при распознавании. Как уже отмечалось во введении код образца рассматривается как один из признаков образца и по отношению к нему также может применяться квантование. Квантование этого признака называется факторизацией алфавита базы и оно означает, что мы договариваемся при построении некоторых узлов дерева не различать некоторые группы букв.
Построение сложного признака для очередного узла дерева и ветвление дерева
Пусть задан набор X1, X2 , ... , Xn простых признаков. Наряду с простыми признаками рассматриваются всевозможные прямые произведения признаков. Полученные новые признаки называются сложными, а число простых признаков в такой композиции называется порядком сложного признака.
Описываемая ниже методика построения дерева распознавания основана на последовательном разбиении исходной обучающей базы на подмножества. В каждом этапе разбиения участвует некоторый сложный признак, подобранный именно для данного этапа или, что тоже, для данного подмножества базы. При выборе сложных признаков используется следующая методика. В очередном подмножестве M базы находится «наилучший» сложный признак. Чтобы сократить количество переборов при поиске «наилучшего» признака, предлагается сначала найти простой признак, имеющий максимальную информативность на M. Новая компонента к имеющемуся сложному признаку выбирается так, чтобы полученный сложный признак имел максимальную информативность на M. Останавливается процесс либо по достижению некоторой запланированной информативности, либо по ограничению на порядок сложности признака.
После того, как найден сложный признак, «максимально» информативный на M, рассчитывается матрица переходов значений этого признака в рассматриваемый алфавит (см. Приложение 1). Полученная матрица переходов используется для очередного подразбиения базы или, что тоже, для построения очередного ветвления узла дерева распознавания. Для получения этого подразбиения просматриваются все строки построенной матрицы переходов ( каждая строка этой матрицы соответствует определенному значению сложного признака ) и выбираются те из них, где число ненулевых полей меньше заданного порога ( максимального числа альтернатив ). Например, если в строке i матрицы лишь два не нулевых элемента в столбцах j1, j2 то это значит, что значение сложного признака, отвечающего строке i, определяет только пару букв алфавита, а именно те буквы, которые определяют столбцы j1 и j2 матрицы переходов. Такие строки матрицы назовем терминальными. Каждая терминальная строка имеет определенное значение сложного признака. Множество M рассматриваемого узла разбивается на подмножества, каждое из которых состоит из образцов, имеющих значение рассматриваемого сложного признака соответствующим определенной терминальной строке. Образцы не попавшие в терминальные строки объединяются в одно подмножество. Таким образом, число подмножеств очередного подразбиения (или, что тоже, число ветвлений при переходе к следующему узлу) равно числу терминальных строк плюс один. Подмножества множества M, соответствующие терминальным строкам образуют терминальные узлы и исключаются из дальнейшей обработки. Каждый терминальный узел возвращает коллекцию альтернатив, определяемую ненулевыми ячейками матрицы переходов. На этом этапе построения дерева распознавания вероятностные оценки этим альтернативам не выставляются.
Другой принцип построения дерева основан на построении цепной развертки и факторизации алфавита. В этом случае в очередном подмножестве M базы алфавит, имеющийся в данном подмножестве, выстраивается в виде цепи. При построении цепи используется понятие фактор-расстояния между буквами алфавита для данного признака ( см. Приложение 1). В качестве первого элемента цепи берется произвольная буква A0. Находится минимум расстояния r01 между буквой A0 и ее дополнением. Пусть этот минимум достигается на букве A1, которая становится вторым звеном в цепи. На следующем шаге ищется расстояние r12 между множеством {A0, A1} и его дополнением. В результате этой процедуры мы получим цепь букв и соответствующую последовательность расстояний между звеньями этой цепи. Выбрав самое слабое звено в этой цепи ( максимум rij ) мы разваливаем весь представленный в M алфавит на два подмножества. Эти два подмножества будем рассматривать, как две буквы (произведена факторизация алфавита на два класса). Далее ищется наиболее информативный сложный признак на таком алфавите из двух «букв». Этот признак используется для развала база по схеме, описанной выше.
Установка оценок в коллекциях альтернатив
Одной из важных задач при использовании различных методов распознавания является задача нахождения оценок для альтернатив, возвращаемых тем или другим методом. Для поставки оценок к коллекциям альтернатив, получаемых при прохождении дерева, каждый терминальный узел “паспортизуется”, т. е. узел кроме коллекций альтернатив возвращает номер этого узла. На основании этого можно провести статистическую инвентаризацию полученного дерева. На базе по которой проводилось обучение или на какой-либо другой базе собирается статистика по каждому узлу. Таким образом для каждого узла имеется коллекция альтернатив пришедших в этот узел из рассматриваемой базы, а частотность приходов позволяет выставлять оценку каждой альтернативе.
Приложение 1
Расчет информативности признака
Матрица переходов признака X представлена в таблице 1.
Таблица 1. (Матрица переходов)
А | Б | В | ... | я | ||
a | m00 | m01 | m02 | m0 k-1 | m0 | |
b | m10 | m11 | m12 | m1 k-1 | m1 | |
... | ||||||
z | mr-1 0 | mr-1 1 | mr-1 2 | mr-1 k-1 | mr-1 | |
n0 | n1 | n2 | nk-1 | N |
a, b, ... , z - всевозможные значения рассматриваемого признака X, А, Б,...,Я - алфавит, представленный в данном подмножестве базы (признак Y).
mij - число переходов i - того значения признака X в j - ю букву алфавита (или, что тоже, в j - тое значение признака Y).
Вектора x = (a, b, ... , z) и y = (А, Б, ... , Я) называются словами.
(m0, m1 , ... , mr-1) - композиция слова x, (n0, n1, ... , nk-1) - композиция слова y.
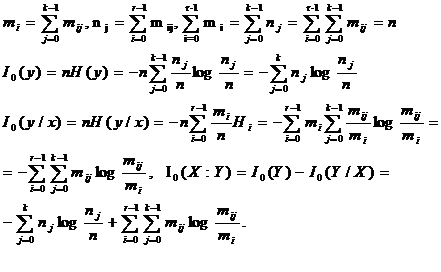
Информативность = (I0(Y) – I0(Y/X))/I0(Y).
Расстояние между двумя признаками.
Используемые при распознавании признаки могут быть оценены с тоски зрения из информативной зависимости. Характеристикой информативной близости признаков служит информационное расстояние между признаками. Это расстояние определяется по формуле r(X, Y) = (I0(X/Y)+I0(Y/X))/2.
Факторизация алфавита и расстояние между буквами
Пример факторизация букв “A” и “B” для признака X. Пусть mij - матрица переходов
Для краткости обозначим: ai = mi0, bi = mi1, n0 = a, n1 = b, Jo - информативность в факторизованном алфавите. Тогда
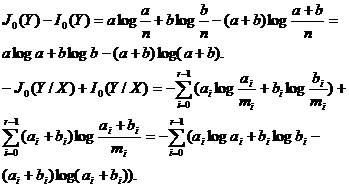
Таким образом
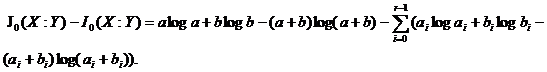
Пронормировав эту разность получим фактор-расстояние между буквами A, B для признака X
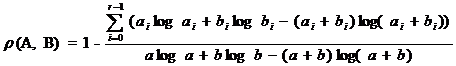
Приложение 2
В данном приложении дано описание геометрических характеристик «скелетированного»
растра изображения "буквы", используемых для расчета признаков образца. Алгоритмы утоньшения в данном приложении не описываются. В результате утоньшения из растра буквы получается "однопиксельный" контур характеризующийся небольшим числом особых точек, расположенных на этом контуре. В дальнейшем этот контур будет называться скелетом буквы. Возможные типы особых точек описываются ниже. Полученные точки естественным образом выстраиваются в циклические графы. Различаются два типа графов или контуров. Черный контур состоит из перечисления номеров особых точек, встречающихся при полном обходе скелета в отрицательном направлении по внешней стороне буквы (область пикселей буквы остается справа). Белые контуры получаются при обходе дырок буквы в отрицательном направлении (область пикселей буквы остается справа). Кроме порядка обхода по каждой особой точке имеется следующая информация:
1.Координаты точки в объемлющей рамке.
2.Индекс точки (определение ниже).
3.Расстояние по контуру до следующей особой точки.
4.Кроме того имеется цепное представление контура и ссылка каждой особой точки на ее место в цепном коде.
Цепной код представляет собой массив направлений движения по контуру, каждое из которых кодируется по следующей схеме
4 | 5 | 6 |
3 | 7 | |
2 | 1 | 0 |
Например, движение по периметру квадрата имеет цепной код 5,7,1,3.
Пример скелетированного растра
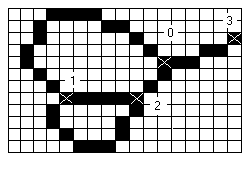
В данном примере четыре особых точки. Черный контур - 0, 3, 0,2, 1. Первый белый контур - 1,2,0. Второй белый контур - 1,2.
Базовые определения
Циклическое представление контура (в дальнейшем кратко "цикл")
Циклическим представлением данного контура называется
однонаправленный циклический список структур (узлов) {num, dist, x,y}, где num - номер особой точки, dist - расстояние по контуру до следующей особой точки, (x, y) - координаты особой точки.
Одноименный узел
Узлы относящиеся к одной и той же точке называются одноименными (имеют одинаковые значения параметра num).
Длина цикла
Сумма длин dist по всем узлам цикла
Расстояние между узлами
r(s, t) = min ( d, l - d), где d - расстояние по циклу от узла s до узла t, l - длина всего цикла.
Величина R(T, S) = r(t2,s0) = r(s2,t0) называется расстоянием между триодами.
Контур или цикл называется черным, если его обход соответствует обходу по внешней стороне растрового образа‚ в противном случае контур или цикл называется белым.
Максимальный черный цикл
Черный цикл максимальной длины.
Индекс особой точки
Особые точки бывают:
индекса 1 ("конец"): имеется лишь один узел в множестве всех черных и белых циклов,
индекса 3 ("триод"): имеется три узла во всех циклах
индекса 4 ("крест"): имеется четыре узла во всех циклах.
Тип триода в цикле
триод имеет тип 1 в цикле, если имеется один узел в цикле (как в греческой букве «тета»),
триод имеет тип 2 в цикле, если имеется два узла в цикле (как в букве "A"),
триод имеет тип 3 в цикле, если имеется три узла в цикле (как в букве "T").
Расстояние между триодами
Даны два триода T и S типа 3 с узлами t0, t1, t2 и s0, s1, s2 перенумерованными в порядке обхода цикла.
Возможно лишь следующее взаимное расположение узлов триодов на цикле (с точностью до циклических перестановок): t0 t1 t2 s0 s1 s2
Связка узла триода
Связкой узла триода (вперед) называется расстояние по циклу от данного узла до ближайшего одноименного узла вперед по циклу.
Мера существенности триода
Мерой существенности триода типа 2, 3 называется минимальная из связок узлов триода по максимальному черному циклу.
Мерой существенности триода типа 1 называется минимум длин белых циклов, в которых лежат узлы триода.
Набор связок триода
Набор p0,p1,p2, где p0 - связка, определяющая меру существенности, p1,p2 - связки следующие за ней по циклу.
определяется для триодов типа 3.
Перемычка между триодами
Перемычкой между триодами T1 и T2 называется величина min ( m1, m2, R(T1,T2)), где m1, m2 - меры существенности триодов, R(T1,T2) - расстояние между триодами.
Асиметрия триода по циклу
Определяется только для триодов типа 3 по формуле
a = min(p0,|p1 - p2|) sign(p1-p2), где p0,p1,p2 - набор связок триода.
Характеристики, используемые для признаков распознавания
Размеры дыр
В качестве признаков используются три "старшие" длины белых циклов нормированные длиной максимального черного цикла c0,c1,c2.
Меры существенности триодов (h0,h1,h2, m0,m1,m2,m3)
В качестве признаков берутся три старшие меры существенности триодов типа 2 максимального черного цикла, нормированные половиной длины этого цикла (h0,h1,h2).
Далее в качестве признаков берутся четыре старшие меры существенности триодов типа 3 максимального черного цикла, нормированные третью длины этого цикла (m0,m1,m2,m3).
Перемычки между триодами (b0,b1,b2)
В качестве признаков берутся три старшие перемычки между триодами максимального черного цикла, нормированные половиной длины этого цикла.
Асиметрии триодов по циклу (a0,a1,a2)
В качестве признаков берутся три старшие асиметрии триодов максимального черного цикла, нормированные третью длины этого цикла.
[1] , Введение в алгебраическую теорию информации, Москва, Наука, 1995.
