
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Различие в поведении пакетов и записей в Ада избегается в объектно-ориентированных языках, расширением понятия типа на процедуры и абстракции данных. В контексте этой дискусси полезно определить объктно-ориентированные языки как расширение процедурных языков ,которые поддерживают типизированные абстракции данных с наследованием. Таким образом мы говорим, что язык объектно-ориентированным, если он удовлетворяет следующим требованиям:
- Он поддерживает объекты и абстракции данных с интерфейсом операций и сокрытием локальной информации.
- Объекты имеют соответствующий объектный тип.
- Типы могут наследовать аттрибуты от супертипов.
Эти требования могут быть суммированы следующим образом:
Объектно-ориентированность= абстракции данных + объектные типы + наследование.
Полезность этого определения может быть проиллюстрирована рассмотрением влияния каждого из этих требований на методологию. Абстракции данных сами по себе предоставляют способ организации данных с соответствующими операциями, что сильно отличается от традиционной методологии процедурных языков. Реализация методологии абстракций данных была одной из главных целей Ады и эта методология описывается в литературе по Ада [83].Однако Ада удовлетворяет только первому из трех условий объектной-ориентированности и интересно рассмотреть влияние типов объектов и наследования на методологию абстракций данных[86].
Требование, что все объекты имеют тип, позволяет им быть первостепенными значениями, поэтому к ним можно обращаться как к структурам данных для вычислений. Требование наследования разрешает определять отношения между типами. Наследование можно рассматривать как механизм структурирования типов, который позволяет свойствам одного или более типов быть использоваными в определениях другого типа. Определение B наследует A может быть представлено как механизм упрощения, который избегает переопределения аттрибутов типа А в определении B. Однако наследование это больше чем упрощение, так как оно влияет на структуру между совокупностью связанных типов, которая может сильно уменбшить сложность определения системы. Это показано на примере объектной иерархии в Smalltalk в [83].
Иерархия объектов в Smalltalk это описание среды программирования Smalltalk. По идее это близко к функцие apply в Лисп, которая описывает интерпретатор языка Лисп, но более сложнее. Она описывает совокупность более 75 связанных объектов системы в терминах иерархии наследования. Объектные типы включают в себя численные объекты, структурированные объекты, объекты ввода-вывода итд. Объектная иерархия выносит свойства общие для всех численных объектов в супертип Number, а свойства присущие всем структурированным объектам – в супертип Collection. Далее свойства общие для численных, структурированных объектов и объектов ввода –вывода выносятся в супертип Object. Таким образом коллекция более 75 объектов, которая составляет среду Smalltalk описана относительно простой структурированной иерархией объектных типов. Упрощение предоставляемое иерархией объектов в повторном использовании суперклассов, чьи аттрибуты совместно используются подклассами присуща коцептуальной расчетливости, достигаемой за счет навязывания связанной структуры коллекции объектных типов.
Объектная иерархия в Smalltalk также замечательна тем, что она иилюстрирует силу полиморфизма. Мы можем определить полиморфную функцию как функцию применимую к значениям более чем одного типа и полимрфизм включения как отношение между типами, которое разрешает применение операций к объектам разных типов связанных включением. Объекты считаются коолекциями таких операций (аттрибутов). Это подчеркивает совместное использование операций операторами разных типов, как главной черты полиморфизма.
Объектная иерархия Smalltalk реализуте полиморфизм, как было сказано выше, заключением всех аттрибутов общих для некоторой совокупности типов в некоторый супертип. Аттрибуты общие для численных типов заключены в супертип Number. Аттрибуты общие для типов-структур заключены в супертип Collection. Аттрибуты общие для всех типов заключены в супертип Object. Таким образом полиморфизм тесно связан с понятием наследования и мы можем сказать, что выразительная сила системы типов зависит в большей степени от полиморфизма, который она использует.
Чтобы закончит дискуссию об эволюции типов в языках программирования мы исследуем механизм типов в ML[84].ML это интерактивный функциональный язык программирования, в котором определения типов пропущенный пользователем, могут быть введены через выводимость типов. Если пользователь вводит “3+4” ,то система ответчает “7:int” , при этом считается значение выражаения и выводятся типы операндов и всего выражения. Если пользователь вводит определение функции “fun f x = x + 1” , то система отвечает “f:int->int”, при этом система считает значение функции и выводит её тип “int->int”.ML поддерживает выводимость типов не только для традиционных типов, но также для параметрических(полиморфных) типов, таких как например функция длины для списков. Если пользователь ввел “fun rec length x = if x = nil then 0 else 1 + length(tail(x));” ,то ML выведет ,что length это функция от списка с элементами произвольного типа, возвращающая integer(length:’a list -> int).Если пользователь затем вводит “length[1;2;3]” ,то система выводит, что length имеет конкретный тип “int list -> int” и потом применяет конкретную функциюк списку integer.
Когда мы говорим, что параметрическая функция применима к списку произвольного типы, мы имеем в виду , этот тип может быть конкретихирован некоторым параметром T и поэтому конкретная функция может быть вызвана для конкретных операндов. Есть важное различие между параметрической функцией length для списков произвольного типа и и специальной функцией для списков типа Int. Функцмм такие как length применимы к спискам произвольных типов, так как они еимеют одинаковое представление параметров, что позволляет конкретизировать тип параметра. Это различие между параметрическими функциями и их конкретными версиями не ясно в языках, таких как ML, так как параметры типов, опускаемые пользователем, автоматически выводятся механизмо выведения типов.
Супертипы в объектно-ориентированных языках, могут быть представлены как параметрические типы, чьи параметры опущены пользователем. Чтобы понять схожесть супертипов и параметрических типов полезно ввести нотацию, где параметры супертипов должны быть явно введены при выделении из супертипа подтипа. Мы увидим ниже, что Fun имеет явные параметры типов как для параметрических типов так и для супертипов, для предоставления единой модели как для параметрического полиморфизма, так и для полиморфизма выделения подтипов.
1.5 Подмножество языка выражения типов.
Когда множество типов языка программирования становится богаче и множество определяемых типов становится бесконечным, то становится полезным определять множество типов при помощи языка выражения типов. Множество выражений типов современного строго типизированного языка это простой подъязык этого языка, тем неменее он не настолько тривиален. Подъязык для выражения типов в общем случае включает базовые типы такие как integer и Boolean и составные типы такие как массивы, записи и процедуры составленные и базовых типов.

Подъязык для определения типов должен быть достаточно богат, чтобы поддерживать типы для всех значений при помощи которых мы будем профодить вычисления и достаточно гибким, чтобы разрешать проверку типов. Одна из целей этой статьи исследовать компромисс между богатством возможностей и удобством использования подъязыка для выражения типов.
Подъязык для выражения типов может быть определен контекстно-свободной грамматкиой. Однако нас интересует не только синтаксис подъязыка, но и его семантика. Поэтому нас интересует какие типы определять и отношения между выражениями типов. Самое сновное отношение между типами это отношение эквивалентности типов. Так же нас интересуют отношения подобности между типами, которые слабее чем отношения эквивалентности, напрмер включение, которое связано с выделением подтипов. Отношения подобности между выражениями типов, которые позволяют выражениям типов определять более чем один тип или быть совместимыми со многимим типами относится к полиморфизму.
Полезность системы типов не только в во множестве типов, которые она может выразить, но также в типах отношений между типами. Возможность выражать отношения между типами включает некоторую возможность вычисления над типами, чтобы определить удовлетворяют ли они нужным требованием. Таие вычисления могкт быть настолько серьезными насколько позволяют их значения. Однако нас интересуют только простые вычислительные отношения, которые представляют единое поведение разделяемое совокупностью типов.
Читатель, которого интересует обсуждение алгортмов для построения языка выражения типов и проверки типов для таких языков как Паскаль и С отправляются читать главу 6 [85] ,которые рассматривают проверку типов для перегрузки, приведения типов и параметрического полиморфизма. Fun добавляет абстрактные типы данных к множеству базовых типов и добавляет подтипы и наслендование к формам полиморфизма, которые поддерживаются.
1.6 Предварительное рассмотрение Fun.
Fun это язык основанный на λ-исчислении, который раширяет λ-исчисление первого порядка, особенностями второго порядка реализованных для моделирования полиморфизма и объектно-ориентированных языков.
Секция 2 рассматривает нетипизированное и типизированное λ-исчисление и разрабатывает базовые элементы для подъязыка выражения типов в Fun. Fun имеет базовые типы bool, int, real , string, структурные типы для организации записей, функций, рекурсивных типов. Это множство типов первого порядка используется как основа для введения параметрических типов, абстрактных типов данных и наследования типов.
Секция 3 быстро обозревает теоретические модели типов связанных с элементами Fun, особенно модели, которые представляют тип как множество значений. Представление типов в виде множеств позволяет определить параметрический полиморфизм как пересечение множеств соответствующих типов и полиморфизм наследования в терминах подмножеств соответствующих типов. Абстракци данных могут быть также определены в терминах операций теории множеств над соответствующими типами.
Секции 4 , 5 и 6 соответственно раширяют λ-исчислении первого порядка квантароми всеобности для реализации параметризированных типов, кванторы существования для реализации абстракций данных и ограниченные кванторы для реализации наследования. Синтаксические расширения для подъязыка выражения типов определенные этими вещами можно суммировать следующим образом.
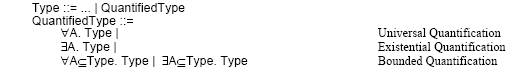
Кванторы всеобности расширяют λ-исчисление параметризированными типами, которые могут быть определены подстановкой некоторых параметров вместо параметров находящихся под знаком квантора. Типы которые стоят под знаком квантора всеобщности являются сами по себе типами первого порядка и могут быть фактическими параметрами в такой подстановке.
Кванторы существования расширяют элементы первого порядка, разрешая срытое представление длядля абстрактных типов данных. Взаимодействие двух квантификаций(всеобщности и существования) проиллюстрирована в секции 5.3 для случая стека универсально квантифицированными типами и экзестенциональноо квантифицированным представлением сокрытия данных.
Fun поддерживает сокрытие информации не только под кванторами существования, но также через структуру let, что способствует сокрытию локальных переменных в стуктуре модуля. Сокрытие при помощи let относится к сокрытию первого порядка, так как включает в себя локальные идентификаторы и соответствующие им значения, тогда как сокрытие с помощью квантора существования относится к сокрытию второго порядка, так как включает в себя сокрытие реализации типа. Отношения между этими двумя формами сокрытия проиллюстрированы в секции 5.2 ,где противопоставляется сокрытие в теле пакета с сокрытием в private частях Ада пакета.
Ограниченная квантификация расширяет λ-исчисление первого порядка предоставляя явные параметры подтипов. Наследование моделируется явным параметрическим выделением подтипа из супертипа, для которых будут исполняться операторы. В объектно-ориентированных языках каждый тип это потенциальный супертип для последующих определенных подтипов и поэтому должны моделировантся при помощи огрниченной квантификации. Ограниченная квантификация предоставляет механизм для объектно-ориентированного полиморфизма, который сильно громоздок для явного использования, но полезен иллюстрации отношения между параметрическим и наследовательным полиморфизмом.
Секция 7 кратко обозревает проверку типов и наследование типов для Fun. Она дополнено приложением перечисляющее все правила вывода.
Секция 8 иерархическую классификацию объектно-ориентированной системы типов. Fun предоставляет более общую систему типов в этой классификации. Отношение Fun к менее общим системам соостветствующих ML, Galileo, Amber и систем типов других языков.
Надеемся, что читателем будет интересно читать о Fun, так же интересно как авторам писать об этом.
2.1 Нетипизированное λ-исчисление
Эволюция от нетипизированного до типизированного множества может быть проиллюстрировано на примере λ-исчисления, в начале разработанного как безтиповой нотации для исследования сущности фуккционального применения операторов к операндам. Выражения в λ-исчислении имеют следующий синтакс(мы будем использовать fun вместо традиционной λ ,чтобы провести соостветствие между нотациями языков программирования)
e::=x переменная это λ-выражение
e::=fun(x)e абстракция e
e::=e(e) аппликация е к е
Функции идентификации и функция successor могут быть поределены в λ-исчислении следующим образом. Мы используем ключевое слово value, чтобы определить новое имя и связать его со значением или функцией.
Value id = fun(x)x функция индентификации
Value succ = fun(x)x + 1 функция successor для integer.
Функция идентификации может быть применена к любому λ-выражению и возвращает всегда λ-выражение. Чтобы определить сложение над целыми в чистом λ-исчислении мы используем представление и определим сложение таким образом, чтобы результате сложения получалось λ-выражение, представляющее. Функция successor может применима только к λ-выражениям, которые представляют целые числа. Инфиксная нотация х+1 это упрощение функциональной нотации +(х)(1).Здесь символы 1 и + ,должны рассматриваться как сокращения выражений для них из чистого λ-исчисления.
Правильность целочисленного сложения не требует предположений о том, что происходит, когда λ-выражение ,представляющее сложение применяется к λ-выражениям, которые не представляют целые числа. Однако если вы хотите, чтобы наша нотация имела хорошую проверку ошибок, желательно определить воздействие сложения на аргументы, которые не являются целыми, как ошибку. Это достигается путем в типизированных языках программирования механизмом проверки типов, который предотвращает возможность операций над объектами неправильных типов.
Проверка типов в λ-исчислении, также как и в обычных языках программирования, имеет тот эффект, что большой класс правильных λ-выражений
в нетипизированном λ-исчислении становится неправильным. Класс выражений с неправильными типами зависит системы типов, которую он принимает и что нежелательно, но может зависеть от алгоритма проверки типов.
Идея оперирования над функциями с помощью λ-выражений, чтобы строить другие функции, может быть проиллюстрирована использованием функции twice, которая имеет следующую форму
value twice = fun(f)fun(y)f(f(y)) - функция twice
Применяя функцию twice к функции successor можно получит функцию, которая будет счистать successor от successor.
twice(succ) -> fun(y) succ(succ(y))
twice(fun(x)x+1) -> fun(fun(x)x+1)((fun(x)x+1)(y))
Обзор представленный выше иллюстрирует, как появляются типы, когда мы определяем нетипизированную нотацию ,такую как λ-исчиление для реализации определенных видов вычислений ,например целочисленной арифметики. В следующей секции мы введем явные типы в λ-мсчисление. Результирующая нотация похожа на функциональную нотацию в традиционных типизированных языках программирования.
2.2 Типизированное λ-исчисление.
Типизированное λ-исчисление это λ-исчисление кроме того, что каждая переменная должна иметь явный тип ,когда она вводится как связная переменная. Поэтому функция successor в типизированном λ-исчислении имеет следующую форму.
value succ = fun (x:int) x+1
Функция twice из целых в целые имеет параметр f ,чей тип int->int и может быть записана следующим образом.
Value twice = fun(f:int->int) fun (y:int)f(f(y))
Эта нотация определяет тип функции, но пропускает определение результирующего типа. Мы можем определить результирующий тип, используя ключевое слово returns.
Value succ= fun(x:int) (returns int)x +1
Однако тип результата может быть определен из формы тела функции х+1.Мы будем опускать результат определения типа в интересах краткости. Механизм выведения типов, который позволяет получить эту информацию во время компиляции обсуждется в более поздних секциях.
Объявления типов реализуются с помощью ключевого слова type. Далее в этой статье, имена типов начинаются с большой буквы, тогда как имена функций и типов - смаленькой.
type IntPair=Int*Int
type IntFun=Int*Int
Объявления типов определяют имена для выражения типа, но они не создают тип. Это также можно сказать, что мы используем структурную эквивалентность типов вместо эквивалентсности имен: два типа эквивалентны, когда они имеют одну и ту же структуру, несмотря на имена.
Тот факт, что значение v имеет тип Т пишется так v:T.
(3;4):IntPair
Succ:IntFun
Нам нужно ввести переменные путем объявления типов в форме vat:T ,так как тип переменной может быть установлен по стрктуре присвоенной переменной. Например, тот факти, что IntPair имеет тип IntPair может быть установлено тем фактом, что (3,4) имеют тип Int*Int, который был объявлен как эквивалентный к Int.
value intPair = (3,4)
Однако, если мы хотим показать тип переменной как чатсь инициализации, то мы можем сделать это при помощи нотации value var:T = value.
value IntPair:IntPair = (3,4)
value succ:Int -> Int = fun(x:Int) x + 1
Локальные переменные могут быть объявлены при помощи конструкции let-in, которая вводит новую инициализированную переменную (после let)в локальную область видимости(после in). Значение констукции это значение жтого выражения.
let a=3 in a+1 возвращает 4
Если мы хотим определить тип ,то мы можем также написать:
let a:Int = 3 in a+1
Конструкция let-in может быть поределена в терминах базисных fun – выражений.
let a:T = M in N = (fun(a:T)N)(M)
2.3 Базовые типы, структурные типы и рекурсия.
Типизированное λ-исчисление обычно расширяется разными базовыми типами и структурными типами. В качестве базовых типов мы будем использовать:
Unit простейший тип из одного элементв ()
Bool с операцией if-then-else
Int c арифметическими операциями и операциями сравнения
Real с арифметическими операциями и операциями сравнения
String конкатенация строк
Структурные типы могут быть построены из базовых типов с помощью конструкторов типов. Конструкторы типов в нашем языке включают в себя однонаправленное отношение (->) ,Декартово произведение (*) , записи, универсальный тип. Пара это элемент типа декартово произведение.
value p= 3;true : Int*Bool
Операци над парами это селекторы первого и второго элемента:
fst(p) возвращает 3
snd(p) возвращает true
Записи это неупорядоченное множество именованных переменных. Тип записи можно определить указывая тип, ассоциированный с каждым полем. Тип запись определяется последовательностью именнованных типов, разделенных запятой и заключенными в фигурные скобки.
Type ARecordType = {a:Int ; b:Bool, c:String }
Запись такого типа может быть создана инициализированием полей записи значениями требуемых типов. Это записано как полседовательность именованных значений разделенных запятыми и заключенные в фигурные скобки.
value r: ARecordType = {a=3;b=true;c=”asd”}
Эти поля должны быть уникальными внутри каждой записи. Единственная операция над записями это выбор поля, определяется указанием после точки имя поля.
r. b вызвращает true.
Так как функции это первостепенные значения, записи в общем случае могут иметь компоненты-функции.
Type FunctionRecordType = {f1:Int -> Int : Real -> Real }
Value functionRecord = {f1=succ, f2 = sin }
Тип запись может быть определена с помощью существующих типов записей и оператора & ,который является оператором конкатенации двух записей.
Type NewFuctionRecordType = FunctionRecordType & {f3:Bool - > Bool}
Это считается хорошим сокращением, вместо того, чтобы писать поля f1 ,f2 ,f3 явно. Это работает только, если в записи не будет дубликатных полей.
Структура данных может быть сделана локальной и private в наборе функций
объявлением let-in. Записи с компонентами функциями в частности удобный способ для достижения этого. В примере private переменная counter совместно используется функциями increment и total.
value counter =
let counter = ref(0)
int {increment = fun(n:Int) count : = count + n,
total = fun() count
}
counter. increment(3)
counter. total() возвращает 3.
Этот пример включает сторонние эффекты, клавное пользо приватных переменных это возможномть приватно их обновлять. Примитив ref возвращает ссылку на объект с возможностью обновления и присвоения ограниченно работают на таких ссылках. Эта общая форма сокрытия информации, которая позволяет обновлять локальное состояние статическую область видимости для ограничения видимости.
Универсальный тип это некоторая форма неупорядоченного множества именнованных типов, которые заключены в квадратные скобки.
Элементы этого типа могут быть Integer, Boolean или String.
value v1=[a=3]
value v2=[b=true]
value v3=[c=”asd”]
Единственная операция на универсальном типе case-выбор. Case-выражение для универсального типа AVariantType имеет следующую форму.
Case variant of
[a=variableof type Int] действие в случае а
[b=variableof type Bool] действие в случае b
[c=variableof type String] действие в случае c
где в каждом случае воодится новая переменная и связывается с соответствующим содержимым варианта. Например ниже приведенная функция определенному элементу типа AVariantType возвращает строку

где вариантная переменная х может быть связана с идентификаторами abInt, aBool, aString в зависимости от случая.
В нетипизированном λ-исчислении возможно выражать рекурсивные операторы и использовать их ,чтобы выражать рекурсивные функции. Однако все вычисления выразимые в λ-исчислении должны завершаться. грубо говоря, тип обычно более сложен чем тип её результата, так как после некотрого числа применений функции мы получаем базовый тип;более того у нас нет незавершенных примитивов).Следовательно рекурсивные определения вводятся как новая концепция примитивов. Функция факториао может быть выражена так:
![]()
Для простоты мы предпологаем, что значения, которые могут быть рекурсивно определены это только функции. Но в конце концов мы вводим рекурсивное оперделение типов. Это позволяет нам, например, определять тип целочисленных списков без использования записей или универсальных типов.
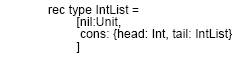
Целочисленный список это либо пустой список, либо соединение целого числа и целочисленного списка.
2. Типы это множества значений
Какое понятие типа наиболее адекватно, то есть могло бы содержать полиморфиз, абстракцию и параметризацию? В предудыщих секциях мы начали описывать ччастную систему типов, предоставляя неформальные правила типизирования для лингвистических конструкций, которые мы использовали. Этих правил достаточно, чтобы описать систему типов на интуитивном уровне, и могут быть легко формалтзованы как система вывода типов.
Хотя нам необязательно обсуждать семантическую теорию типов подробно, но может быть полезным изучит некоторые базовые правила. Эти правила в свою очередь полезны для понимания правил типизирования, в частности касаясь концепции выделения подтипов, которая будет ввелена позже.
Есть множество V всех значений, содержащее простые значения такие как integer, структуры данных, например пары, записи и универсалные типы и функции. Это законченное упорядовачение ,построенное техникой Скотта[Scott, 76], но в первом своем приближении мы можем подумать, что это просто большое множество всех вычислимых типов.
Тип это множество элементов V. Не все подмножества V могут быть правильными типами, они должны подчинятся некоторым техническим свойствам. Подмножества V подчиняющиеся таким свойствам называются идеалами. Поэтому все типы в языках программирования в этом смысле идеалы, мы не дожны много заботиться о подмножествах V, которые не являются идеалами.
Следовательно тип это идеал, который в свою очередь является множеством значений. Более того множество всех идеалов в V, упорядоченных при помощи включения множеств, формируют структуру. Верхшка этой структуры это тип Top(множество всех значений, то есть сама V).В основании структуры – пустое множество(одноэлементное множество).
Фраза имеет тип может интерпретироваться как членство в подходящем множестве. Так как идеалы в V могут перекрываться, то значения могут иметь много типов. Множество типов некотрого данного языка программирования в общем случае это только маленькое подмножество всех идеалов в V. Например любое подмножество целых определяет идеал ,также это делает множество пар с первыи элементом равным 3.Это приветствуется ,так как позволяет языку иметь много систем типов в одной среде. И вы дожны решить какие системы типов кажуться вам интересными в контекскте определенного языка.
Конкретная система типов это совокупность идеалов V, которые обычно определяются языком выражения типов и отображением выражений типов на идеалы. Идеалы в этой коллекции повышены до ранга типов определенного языка. Например, мы можем выбрать целые, пары целых, функции из целых в целые как нашу систему типов. Различные языки будут иметь различные системы типов, но все эти системы типов могут быть построены на вершине множества V.
Мономорфные системы типов это те, в котрых каждое значение принадлежит в большинсвте одному типу (кроме низшего элемента в V, которые принадлжит по определению идеала всем типам).Так как типы это множества, то значение может принадлежать множеству типов. Полиморфная система типов это та, в которой большие и интересные колекции значений принадлежат многим типам. Есть езе области почти мономорфных и почти полиморных систем, поэтому определения не точны, но главное это то, что базовая можель идеалов в V , может объяснить все эти степени полиморфизма.
Так как типы это множества ,подтипы просто соответствуют подмножествам. Более того семантическое свойтсво Т1 это подтип Т2 соответствует математическому условию ![]() в структуре типов. Это дает очент простую интерпретацию поддиапозона типов и наследования, как мы увидим в последующих секциях.
в структуре типов. Это дает очент простую интерпретацию поддиапозона типов и наследования, как мы увидим в последующих секциях.
В конце концов если мы возьмем в качесвте системы типов единственное множество V, мы будеи иметь свободную систему типов, где все значения имеют один и тот же тип. Следовательно мы можем выразхить типипзированные и нетипизированные языки в одном семантическом домене и сравнить их.
Структура типов содержит много особенностей, которые могут быть названы в любом типипзированнном языке. В действительности они включаэт бесчисленное множество особенностей, так как они включают каждое подмножство целых. Цель языка типов это дать программисту возможность именовать эти типы, которрые соостветствуют разным степеням поведения. Чтобы сделать это языки содержат конструкторы типов, включая функции-констукторы типов(например тип T1 -> T2)
Для составления функционального типа Т из типов Т1 и Т2.Эти конструкторы позволяют бесчисленое множество интеренсых типов для конструирования из конечного множество примитивных типов. Однако могут быть интересными и типы, которые не могут быть используя эти конструкторы.
В оставшихся секциях этой статьи мы введем более мощные конструкторы типов, которые позволяют нам говорить о типах соответствующих бесконечным объединением и пересечениям типов в струтктуре типов. В чатстности, универсальная квантификация позволит нам именовать типы, котроые являются бесконечными пересечениями в структуре типов ,тогда как экзистенциональная квантификация позволит именовать нам типы из бесконечных объединений структуры типов. Причина введения универсальной и экзистенциональной квантификации важность результирующих типов в повышении выразительной силы типизированного языка. К счастью эти концепции также математичсеки просты и также, что они относятся к хорошо известным математичсеким конструкциям.
Модель идеалов это не единственная модель типов, которая изучалась. По сравнению с другими денотационными моделями, она имеет преимущество в объяснении простых и полиморфных типов интуитивным способом, терминах множеств значений и позволяет нормально определить наследование. Однако оставляет желать лучшего отнощение к параметризации, которая в некотром смысле не прямая,
так как типы не могут быть значениями и отношение и типовыми операторами, что включает в себя выход за предел модели и рассмотрения функций на идеалах. С точки зрения этих интуитивных преимуществ, мы выбрали модель идеалов, как базовое представление типов, но многое из наших обсуждений должно быть доделано до конца и иногда даже улучшено, если мы выберем другие модели.
Идея типов в качестве параметров полно разработана в λ-исчислении второго порядка. Денотационная модель λ-исчисления второго порядка это модель ретрактов. Здест типы не множества объектов, а специальные функции (называемые ретракты);это может быть интерпретировано как определение множеств объектов. Так как своство этих типов это объекты, модель ретрактов может еще лучше описывать явные пипизированные параметры, тогда как идеалы могут описывать лучше ниявные типипзированные параметры.
4.Универсальная квантификация.
4.1.Универсальная квантификация и шаблоннные функции.
Типизированного λ-исчисления достаточно, чтобы выражать мономорфные функции. Однако это надекуватная модель для полиморных функций. Например, требуется, чтобы функция twice необязательно была ограничена типом из целых в целые, может мы хотим определить эту функцию как полиморфно а ->а для произвольных типов а. Фнукция идентификации может похоже быть огпределена только для конкретных типов, таких как integer:fun(x:Int)x. Мы не можем зафиксировать тот факт, что её форма не зависит ни от какого типа. Мы не можем выразить идею, что функциональная форма будет одинаковой для множества типов и мы должны явно связвать переменные и значения определенного типа во время, когдатакое связование может быть преждевременным.
Тот факт, что данная функциональная форма может быть одинаковой для всх типов может быть выражено с помощью кванторов всеобности. В частности функция идентификации может быть определена как:
![]()
В этом определении id, а это переменная типа, а all[a] предоставляет абстаркцию для а ,чтобы id была функцией для всех типов. Чтобы применить функцтию идентификации к аргументу определенного типа, мы должны сперва представить тип как параметр и затем аргумент данного типа
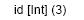
(Мы использовали условие, что параметр типа заключен в квадратные скобки, а аргумент – в круглые)
Мы будем определять функции такие как id, которые требуют параметр тип прежде чем они могут быть применены как шаблонные функции. Id это шаблонная функеция идентификации.
Заметьте, что all это опрератор связывания, такой же как fun и требует сопоставления фактического параметра при применении функции. Однако all[a] служит, чтобы связывать тип, когда как fun(x:a) служит для связывания переменной данного типа.
Хотя типы применимы, но нет предпосылок для манипулирования типами как значениями: типы и значения все еще различны и абстракции типов и применение типов служат для проверки типо, без влияний на время выполнения. В действительности мы можем опутсить информацию о типах в квадратных скобках.

Вот алгоритм проверки типов имеет задачей опознать, что а это свободная переменная типа и переопределить первоначальную информацию all[a] и [Int].Это часть того, что может делать полиморфные проверяльщик типов, похожий на тот, который используется в ML. В действительности ML идет дальше и позволяет программистам опускать даже оставшуюся информацию о типах.
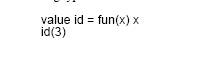
ML имеет механизм выведения типов, который позволяет системе выводить типы как для мономорфных так и для полиморфных выражений, поэтому определения типов опущенные программистом может быть введены системой. Это имееет то преимущество, что программист может использовать сокращения нетипизированного λ –исчисления, тогда как система может переводить нетипизирвоанный вход в полно типизированный вход. Хотя не существует автоматичсеких алгоритмов для выведения типов для мощныз тпипизированных систем ,которые мы готовы рассмотреть. Чтобы сделать понятным что происходит и не зависеть от конкретной технологии проверки типов, мы должны всегда записывать вс. Информацию о типах, чтобы сделать задачу проверки типов тривиальной.
Возвращаясь назад к явному языку, давайте расширим нашу нотацию, чтобы можно было явно говорить о полиморфных функциях. Мы определим тип шаблонной функции от произвольного типа ![]()
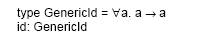
Ниже пример функции, которая принимает параметр произвольного типа.
Функция inst берет в качестве аргумента функцию указанную выше и возвращает два вида её, Integer и Boolean.
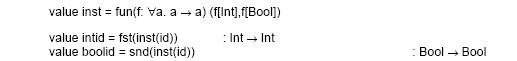
В общем случае параметры функции стоящие под знаком кватнора всеобности наиболее полезны, когда их наддо использовать в разных типах в теле оджной функции, например функция вычисления длины списка передается в качестве параметра и используется на списках разного типа. Чтобы показать некоторую свободу
,которую мы имеем при определении полиморных функций, мы напишем две версии twice, которые различаются в способе передачи параметров. Первая версия twice1 имеет функциональный параметр f универсального типа. Определение

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
