

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сразу следует сделать важное замечание, не относящееся к математике. Убедившись в достаточно большой величине коэффициента корреляции, исследователь может сделать вывод о наличии связи между X и Y. Однако это не дает ему никаких оснований считать, что найденная связь носит причинно-следственный характер. Кроме тех случаев, когда X непосредственно влияет на Y, часто встречаются, например, ситуации, когда некоторый дополнительный фактор Z приводит к синхронному изменению величин X и Y.
Часть 2. Моделирование с использованием случайных чисел.
Генератор случайных чисел.
Моделирование – это замена реального явления или предмета его моделью, правильно описывающей те его свойства, которые анализируются, при этом правильное отображение других свойств не обязательно. Во многих случаях при моделировании реальных явлений используются случайные числа. Генерация случайных чисел требует специальных технических средств, поэтому в компьютерном моделировании, как правило, используются псевдослучайные числа, вычисляемые по определенному алгоритму на основе первого значения, взятого случайным образом.
Один из используемых алгоритмов вычисления псевдослучайных чисел связан с рекуррентной формулой, согласно которой для получения нового псевдослучайного числа: А)предыдущее число, лежащее в диапазоне от 0 до 1, умножается на некоторое не очень маленькое простое число. Б)Затем к нему прибавляется некоторая дробь от 0 до 1. В) После этого целая часть отбрасывается, в результате чего получается новое число, лежащее в диапазоне от 0 до 1.
У каждого из алгоритмов получения псевдослучайных чисел, в том числе и у приведенного выше, есть два недостатка по сравнению с истинно-случайными числами:
1. Рано или поздно в вычислениях будет получено псевдослучайное число, которое уже встречалось. В результате последовательность псевдослучайных чисел будет периодически повторяться. Чем больше величина периода, тем качественнее генератор. В тех случаях, когда необходимо существенно увеличить величину периода, используют вложенные генераторы псевдослучайных чисел: через каждые N чисел (N – число, несколько меньшее ожидаемого периода) «генератор» перезапускают, взяв в качестве исходного значения псевдослучайное число от другого, «внешнего» генератора случайных чисел.
2. Необходимо каждый раз каким-либо образом задавать исходное число (инициализировать генератор случайных чисел). Вариант прямого запоминания некоторого исходного числа в программе приводит к повторению последовательности псевдослучайных чисел от запуска к запуску. Чтобы этого избежать, придумали способ: использовать в качестве исходного число, вычисляемое на основе текущего времени.
![]() Как правило, генератор случайных чисел, предлагаемый в различных программах, дает случайные числа, имеющие равномерное распределение. Функция распределения таких чисел представляет собой прямоугольник: p(x)= 1/(x2-x1) , xÎ[x1,x2] ;
Как правило, генератор случайных чисел, предлагаемый в различных программах, дает случайные числа, имеющие равномерное распределение. Функция распределения таких чисел представляет собой прямоугольник: p(x)= 1/(x2-x1) , xÎ[x1,x2] ;
0, xÏ[x1,x2]
Такие случайные числа могут быть использованы в ряде случаев (например, при моделировании вращения колеса рулетки или времени прихода автобусов на остановку)
Получение случайных чисел с неравномерным распределением.
Отдельной проблемой является генерация случайных чисел, имеющих распределение, отличное от равномерного. Делается это путем вычисления итогового случайного числа по некоторой формуле, в которую входит исходное, равномерно распределенное случайное число. Для важного частного случая – получения случайных чисел, имеющих нормальное распределение – можно использовать стандартную функцию «обратного нормального распределения», включенную, в частности, в набор стандартных функций электронных таблиц Excel. Эта функция использует в качестве аргумента значение, имеющее смысл вероятности (т. е., число Х, взятое на интервале [0,1]). Для этого значения Х вычисляется значение Y, при котором вероятность получения случайного числа y , большего, чем Y, равна Х (Предполагается нормальное распределение чисел y, имеющее среднее значение и стандартное отклонение, которые также задаются как аргументы функции обратного нормального распределения). Очевидно, значения Y могут быть любыми (YÎ[-¥,+¥]). Они и дают нормально распределенные случайные числа.
Другой подход может быть основан на том факте, что неравномерное распределение случайных чисел в природе возникает в результате влияния большого количества случайных факторов, каждый из которых оказывает сравнительно маленькое воздействие на итоговую величину. «Разыграв» при помощи стандартного генератора случайных чисел результат действия каждого из этих факторов, можно получить итоговое значение. В связи с большим количеством вычислений этот способ трудно реализовать, используя электронные таблицы. Однако, быстродействие компьютера позволяет это легко сделать методами программирования.
Рассмотрим пример программы, написанной на языке С. Будем надеяться, что подробное описание отдельных операторов позволит без особого труда понять принципы ее работы людям, знакомым с другими языками программирования.
Цель моделирования в этой программе – набрать и записать в файл серию значений, каждое из которых равно числу «орлов», одновременно выпавших при подбрасывании. В программе отдельно моделируется подбрасывание каждой монеты. Переменная ir принимает случайное значение: если ir=1, считаем, что выпал «орел», если ir=0, то «решка». чего подсчитывается сумма.
Программа представляет собой набор из двух вложенных циклов. Внешний из них определяет число записываемых итоговых значений. Печать итогового значения производится как на экран, так и в файл, предварительно открытый для записи.
Во внутреннем цикле (по переменной j) моделируется подбрасывание каждой монеты, всего xr раз. Программа использует генератор случайных чисел – функцию random(N), дающую целые значения от 0 до N-1. В нашем случае ir=random(2). Для получения итогового значения подсчитывается сумма значений ir.
#include <stdio. h> // указываются библиотеки,
#include <time. h> // содержащие функции,
#include <stdlib. h> // необходимые для работы
int i, j,r, ir, nr, xr; // Определяются целые переменные: i,j – переменные
// цикла, nr,xr – число повторений в соответствующих циклах.
// ir будет содержать рез. подброса каждой монеты, r - сумму
FILE *outfile; // Определяется указатель на файловую переменную
char fileout[50]; // Определяется текстовый массив для ввода имени файла
void main() // Программа на С записана в функцию main( )
{printf("в какой файл записать случайные числа?");
scanf("%s",fileout); //вводим имя файла
outfile=fopen(fileout,"w"); //открываем для записи
printf("Сколько монет подбрасывается каждый раз?");
scanf("%d",&xr); //ввод числа монет
printf("сколько нужно таких случайных значений?");
scanf("%d",&nr); //столько значений
randomize(); //инициализируем генератор случайных чисел
for(i=1;i<=nr;i++) //цикл по i , при каждом проходе записывается сл. число
{ r=0; //обнуление переменной, содержащей сумму
for(j=1;j<=xr;j++) //цикл по j , для каждого j «подбрасывается монета»
{ ir=random(2); // подброс монеты. 0=решка, 1=орёл
r=r+ir; } //добавление к сумме. Закрытие цикла по j .
printf("%d\n",r); // вывод числа на экран
fprintf(outfile,"%d\n",r);} // запись числа в файл, закрытие цикла по j
} //закрываем функцию main( ), а значит, и программу.
Часть 3. Использование электронных таблиц Excel для анализа данных и моделирования.
Использование Excel для автоматических вычислений.
После загрузки Excel пользователь видит экран, разбитый на ячейки (в виде таблицы). Каждая ячейка имеет адрес, задаваемый буквой и числом аналогично известной игре «Морской бой». Например, на приведенном ниже рисунке в ячейке В9 записано число 11. В каждый момент времени одна из ячеек является текущей. Она выделяется рамкой с небольшим черным квадратиком в нижнем правом углу (на рис. это ячейка С4). При наборе на клавиатуре числа или текста изменения вносятся именно в текущую ячейку.
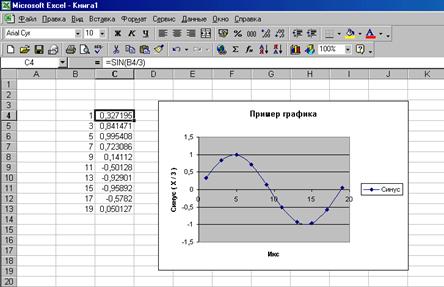 В каждой ячейке может быть записано число, текст или формула. Если Excel может интерпретировать содержимое как число, он считает содержимое числом. При вводе чисел нужно обратить внимание на то, что в качестве разделителя в десятичных дробях следует использовать либо точку, либо запятую в зависимости от установок Windows (панель управления à язык и стандарты à числа). Щелкая по соответствующим иконкам, можно менять разрядность представления чисел в ячейке.
В каждой ячейке может быть записано число, текст или формула. Если Excel может интерпретировать содержимое как число, он считает содержимое числом. При вводе чисел нужно обратить внимание на то, что в качестве разделителя в десятичных дробях следует использовать либо точку, либо запятую в зависимости от установок Windows (панель управления à язык и стандарты à числа). Щелкая по соответствующим иконкам, можно менять разрядность представления чисел в ячейке.
Если содержимое начинается со знака равенства, то компьютер его интерпретирует как формулу. Формулу, записанную в ячейке, можно увидеть в строке формул, если сделать ячейку текущей. В самой ячейке при этом будет отображаться результат вычислений. Формула может содержать числа, адреса других ячеек и функции. Для ввода функции можно воспользоваться иконкой [fx], позволяющей выбрать соответствующую функцию из списка, после чего ввести аргументы функции вручную или с помощью соответствующего мастера. Для удобства и надежности ввода адресов ячеек можно воспользоваться мышкой: при редактировании формулы (сделали ячейку текущей и выбрали нужное место в строке формул) щелчок левой кнопкой мышки по произвольной ячейке приводит к появлению ее адреса в текущем месте строки формул. Наиболее часто используется функция СУММ( ), вычисляющая сумму ячеек в диапазоне, указанном в качестве аргумента. Для быстрого ввода этой функции предусмотрена иконка [S] . Результат всегда записывается в текущую ячейку. В качестве аргументов функции СУММ() Excel по умолчанию предлагает диапазон содержащих числа ячеек, расположенных сверху (или слева) от текущей. Обратите внимание, что диапазон ячеек записывается через двоеточие (например, С4:С13). Еще одна часто используемая функция – функция СРЗНАЧ( ) – вычисляет среднее арифметическое значение аргументов, указанных в скобках. В качестве аргументов могут быть перечислены через запятую числа, адреса отдельных ячеек и диапазоны ячеек.
Если компьютер не может интерпретировать содержимое ни как число, ни как формулу, он считает, что в ячейке записан текст. Если текст превышает размеры ячейки, то он будет виден полностью, только в том случае, если соседние ячейки пустые. Рекомендуется объединять ячейки таким образом, чтобы текст помещался полностью (выделяя левой кнопкой мышки набор ячеек и щелкая по белой иконке со стрелочками). Для наглядности оформления электронной таблицы можно использовать различные форматы шрифта (аналогично работе с MS Word). Также можно использовать выравнивание по центру, по левому или по правому краю.
Кроме содержимого у каждой ячейки существует определенный формат, который в процессе работы также может меняться. К свойствам ячейки, совокупность которых и составляет ее формат, относятся заливка, наличие и вид границ (на рис. … у ячеек никаких границ нет и при печати таблицы никакой разлиновки не будет), а также форма представления содержимого. Например, если в ячейке записано число, то оно может интерпретироваться как обычное число, или как дата, или как доля в процентах, и т. п. Если Вы случайно изменили формат ячейки неправильным образом, то вернуться к исходному виду («общий формат») можно, выбрав пункт меню правка à очистить à форматы .
При каждом переходе в процессе редактирования к другой ячейке (с помощью мышки или клавиш со стрелками, а также при нажатии [Enter]) компьютер автоматически обновляет содержимое всех ячеек. В частности, числа, отображаемые в ячейках, содержащих формулы, автоматически вычисляются в соответствие с обновленными данными, используемыми в этих формулах. Диаграммы и графики, построенные на основе записанных в ячейки данных (см. ниже), также автоматически обновляются. На этом основан наиболее обычный порядок использования Excel: пользователь «программирует» автоматически вычисляемую таблицу, после чего, каждый раз заполняя ее новыми данными, получает необходимые результаты.
Курсор мышки при работе с Excel может быть трех различных видов и, соответственно, пользователь при этом может выполнять различные действия.
1) Чаще всего курсор имеет вид широкого светлого креста. Нажав на левую кнопку мышки и двигая ее, в этом случае можно выделить группу ячеек. Для добавления к группе следующего набора ячеек выделяйте их при нажатой клавише [Ctrl].
2) Если подвести курсор к границе текущей ячейки или выделенной области, курсор принимает вид стрелки. Нажав левую кнопку мышки, можно передвинуть содержимое ячеек на другое место. Обратите внимание, что во всех местах электронной таблицы, где были использованы адреса перемещаемых ячеек, формулы будут автоматически отредактированы таким образом, что никакие значения не изменятся.
3) Если курсор подвести к нижнему правому углу текущей ячейки или выделенной области, то он будет иметь вид маленького черного плюса. В этом режиме происходит копирование ячеек. В зависимости от вида содержимого процесс копирования будет происходить по-разному. Если содержимое представляет собой число или текст, при этом копируется одна ячейка, то происходит обыкновенное копирование. Если взять две последовательные ячейки, заполненные числами, то копирование приводит к заполнению последующих ячеек арифметической прогрессией. Если содержимое представляет собой формулу, то копируется не результат вычислений, а сама формула. При этом адреса ячеек, входящих в нее изменяются следующим образом. При копировании вверх-вниз каждый раз цифровая часть адреса ячеек, входящих в формулу, меняется на соседнее значение. При копировании вправо-влево то же самое происходит с буквенной частью адреса. В тех случаях, когда адрес некоторой ячейки, входящей в формулу, при копировании меняться не должен (например, в ячейке записан некоторый коэффициент) используется абсолютный адрес: перед цифровой, или буквенной, или и той и другой частью адреса ставится символ $ . В этом случае соответствующая компонента адреса останется неизменной.
При работе с данными большого объема удобно использовать несколько электронных «листов» с данными, формулами и диаграммами, объединенных в одну «книгу». «Книга» Excel хранится в одном файле. Переход от листа к листу осуществляется путем выбора соответствующей вкладки, расположенной внизу экрана.
Построение диаграмм и графиков.
Для построения диаграммы или графика в Excel предназначена иконка с изображением нескольких цветных столбиков. Нажатие на нее запускает «мастер диаграмм», предлагающий определить тип диаграммы, отображаемые данные, надписи и т. п. Многие из параметров диаграммы (график – это один из видов диаграммы) компьютер устанавливает по умолчанию. Впоследствии эти параметры можно отредактировать по своему усмотрению.
Перед запуском мастера диаграмм рекомендуется выделить диапазон ячеек, содержащих отображаемые данные. Это поможет избежать ручного ввода этих диапазонов. Следует, однако, обратить внимание, что компьютер по-разному интерпретирует столбцы (строки) выделенных данных для диаграмм различного типа. Нужно всегда внимательно проверять правильность отображения данных.
В процессе построения диаграммы пользователь последовательно проходит 4 шага:
1) Пользователь выбирает тип диаграммы. Наиболее часто используются:
- Столбчатая диаграмма (гистограмма) используется для сопоставления данных, относящихся к различным случаям или вариантам (времени, фирме и т. п.)
- Круговая диаграмма наглядно показывает долю составных частей в целом
- График отображает последовательное изменение данных от случая к случаю. В отличие от математики, по оси абсцисс отображается порядковый номер случая.
- Точечная диаграмма соответствует обычному для математики понятию графика. Можно выбрать варианты, в которых точки соединяются или не соединяются линиями. Линии могут быть сглаженными или ломаными.
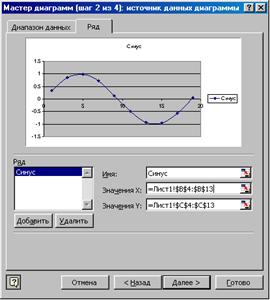
2) Пользователь определяет исходные данные. Сначала указывает (обычно просто подтверждает), что данные расположены в столбцах, либо в строках. Затем определяет (либо просто подтверждает) сами диапазоны отображаемых данных. Они указываются в полях «Значения Х», «Значения Y» для каждого ряда. Щелчок левой кнопкой мыши на цветном квадрате справа от соответствующего поля запускает мастер, дающий возможность определить диапазон данных с помощью мыши. Следует задать имя для каждого ряда (вместо «ряд 1», … , используемых по умолчанию). Именно под этим именем ряды перечисляются в легенде – подписи рядов, обычно расположенной справа от диаграммы. Для некоторых типов диаграмм, отличных от графика или точечной диаграммы, на той же вкладке «ряд» задаются подписи категорий.
3) Пользователь задает текст заголовков и некоторые другие параметры оформления диаграммы. Можно задать «подписи данных», указывающих значения в каждой точке.
4) Пользователь определяет, будет ли диаграмма расположена на том же листе, где отображаемые данные, или для нее будет создан отдельный лист. Первый вариант используется в случае сравнительно небольшого объема данных, в этом случае удобно просматривать, а также распечатывать, данные вместе с диаграммами. Второй случай используется при анализе сложных диаграмм и графиков.
Для последующего редактирования диаграммы пользователь выделяет один из ее элементов – область построения, ось, ряд данных, легенда и т. п. щелчком правой кнопки мыши. Затем выбирается пункт контекстного меню «формат», после чего соответствующему элементу задаются новые свойства. Важные частные случаи - изменение шкалы осей, цвета и вида заливки столбцов, типа соединяющих линий, отображения вертикальной или горизонтальной сетки. При необходимости можно вернуться к каждому из исходных четырех шагов, щелкнув правой кнопкой мышки на свободном поле диаграммы и выбрав соответствующий пункт контекстного меню.
Объединение данных из нескольких файлов. Экспорт данных, записанных в других форматах.
Для переноса данных из одной электронной таблицы в другую можно использовать буфер обмена. Последовательность действий такова:
- Открыть таблицу, содержащую нужные данные.
- Выделить необходимые данные с помощью мышки. Для выделения всего столбца щелкните мышкой по его заглавной букве.
- Скопировать данные в буфер обмена. Это можно сделать, выбрав пункты меню правка à копировать, либо выбрав аналогичный пункт копировать в контекстном меню (щелкнув правой кнопкой по выделенной области) , либо используя иконку с изображением двух листов бумаги. Для копирования в буфер обмена обычно предусмотрена комбинация клавиш [Ctrl]+C.
- Перейти в ту таблицу, куда нужно вставить данные. Сделать текущей ту ячейку, начиная с которой должны размещаться вставляемые данные.
- Выбрать пункты меню правка à вставить, либо выбрать аналогичный пункт вставить в контекстном меню, либо использовать иконку с изображением папки и листа бумаги. Для вставки из буфера обмена обычно предусмотрена комбинация клавиш [Ctrl]+V.
Важно уметь вставить в электронную таблицу для последующей обработки средствами Excel данные, хранящиеся в файлах других форматов. Обычно представляют интерес файлы текстовых форматов, создаваемые в результате использования различных программных средств. Эти файлы как правило имеют символьную кодировку (возможны варианты кодировки Windows или DOS), т. е. устроены аналогично файлам, создаваемым редактором «Блокнот». Естественно, их расширение не обязательно совпадает с. txt.
 При открытии подобного файла (файл à открыть) следует выбрать тип файла «все файлы», после чего в процессе открытия указать, как записаны данные. Сначала (первый шаг) Excel предложит указать кодировку файла и выбрать один из вариантов формата данных: либо «с разделителями», т. е. когда одно значение от другого отделяется некоторым стандартным символом, либо «фиксированной ширины», когда под каждое значение в столбце отводится определенное число позиций. И в том, и в другом случае переход на новую строку в исходном файле будет интерпретироваться как переход к новой строке в электронной таблице. Переход к новому значению будет означать переход к соседней ячейке таблицы.
При открытии подобного файла (файл à открыть) следует выбрать тип файла «все файлы», после чего в процессе открытия указать, как записаны данные. Сначала (первый шаг) Excel предложит указать кодировку файла и выбрать один из вариантов формата данных: либо «с разделителями», т. е. когда одно значение от другого отделяется некоторым стандартным символом, либо «фиксированной ширины», когда под каждое значение в столбце отводится определенное число позиций. И в том, и в другом случае переход на новую строку в исходном файле будет интерпретироваться как переход к новой строке в электронной таблице. Переход к новому значению будет означать переход к соседней ячейке таблицы.
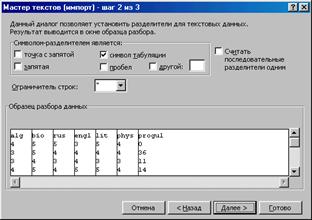 Затем (второй шаг) в зависимости от выбранного формата нужно либо указать символы, используемые в качестве разделителя, либо, смещая соответствующие разделительные линии, определить границы столбцов в исходном файле. И в том, и в другом случае обратите внимание на предварительный просмотр результата. Последний, третий, шаг позволяет определить формат данных для каждого из столбцов и, возможно, пропустить некоторые из них.
Затем (второй шаг) в зависимости от выбранного формата нужно либо указать символы, используемые в качестве разделителя, либо, смещая соответствующие разделительные линии, определить границы столбцов в исходном файле. И в том, и в другом случае обратите внимание на предварительный просмотр результата. Последний, третий, шаг позволяет определить формат данных для каждого из столбцов и, возможно, пропустить некоторые из них.
Нажатие на иконку [готово] завершает операцию, в результате которой данные из файла отображаются в виде электронной таблицы. Эту таблицу можно сохранить в формате Excel. Если в сохранении нет необходимости, можно перенести через буфер обмена нужные данные в уже существующую электронную таблицу, после чего закрыть файл, не внося изменений.
Кроме описанного выше способа можно воспользоваться пунктом меню данные à внешние данные à импорт текстового файла. Далее процедура импорта во многом сходна с вышеописанной. В конце Excel предлагает либо поместить данные на отдельный лист, либа на уже имеющийся.
Функции Excel, наиболее часто используемые в процессе обработки информации.
Функции, предоставляемые электронными таблицами Excel, могут иметь один и более аргументов, помещаемых в скобки и отделяемых при записи точкой с запятой. В качестве аргументов, в зависимости от их назначения, могут использоваться явно заданные числа, адреса отдельных ячеек или диапазоны ячеек. Если указывается диапазон, т. е. записываются через двоеточие адреса двух ячеек, то в качестве аргумента рассматриваются все ячейки между указанными. Во многих случаях в качестве параметра допускается перечисление набора чисел, ячеек и диапазонов через запятую. Используя ту или иную функцию, следует обратить внимание, в каком виде должны быть (могут быть) указаны ее аргументы.
Все функции в Excel разделены на ряд больших групп, к которым относятся:
1) Математические функции, такие, как:
- КОРЕНЬ( ) вычисляет квадратный корень.
- SIN( ), COS( ), TAN( ) – тригонометрические функции.
- ASIN( ), ACOS( ), ATAN( ) – обратные тригонометрические функции.
- ABS( ) вычисляет модуль
- EXP( ) вычисляет экспоненту, т. е. величину ex .
- СТЕПЕНЬ( ) возводит число в степень.
- LN( ), LOG( ) и LOG10( ) – натуральный, произвольный и десятичный логарифмы.
- СУММ( ) и ПРОИЗВЕД( ) вычисляют сумму и произведение содержимого ячеек, указанных в качестве аргумента.
- ОКРУГЛ( ) округляет число до заданного числа знаков. ОТБР( ) отбрасывает дробную часть (всю или частично).
- СЛЧИС( ) генерирует случайное число в диапазоне от 0 до 1. Функция параметров не имеет. Случайные числа распределены равномерно. Значения функции обновляются при любых внесениях изменений в электронную таблицу.
2) Статистические функции, позволяющие легко вычислить многие величины, использующиеся при статистической обработке данных:
- СРЗНАЧ( ) вычисляет среднее значение.
- СТАНДОТКЛОН( ) вычисляет стандартное отклонение
- МИН( ) и МАКС( ) определяют, соответственно, минимальное и максимальное значение.
- НАКЛОН( ) и ОТРЕЗОК( ) вычисляют методом наименьших квадратов параметры k и b прямой y = k*x + b. Эти функции имеют по два аргумента. В качестве первого указываются ячейки (диапазон), содержащие значения Y, а в качестве второго – X
- КОРРЕЛ( ) вычисляет коэффициент корреляции двух рядов данных.
- НОРМРАСП( ) вычисляет значение в точке Х (первый аргумент) нормальной функции распределения, заданного средним значением и стандартным отклонением (второй и третий аргументы). Для получения обычного распределения в качестве четвертого аргумента указывается логическое значение ЛОЖЬ (можно ввести явно словом). Указав значение ИСТИНА, можно получить интегральное нормальное распределение, дающее вероятность получить значение меньше X. Разность между его значениями в точках X1 и X2 дает вероятность получить значение на интервале [X1,X2].
- НОРМОБР( ) вычисляет обратное нормальное распределение (интегральное), то есть определяет значение X, при котором достигается заданная в качестве первого аргумента вероятность получить значение меньше X. Параметры распределения - среднее и стандартное отклонение - задаются вторым и третьим аргументами.
- СЧЕТЕСЛИ( ) подсчитывает непустые ячейки из заданного диапазона (первый аргумент), удовлетворяющие заданному условию (второй аргумент).
- СУММЕСЛИ( ) суммирует значения из ячеек, диапазон которых указан в третьем аргументе в том случае, если соответствующая ячейка из диапазона, указанного в первом аргументе, удовлетворяет условию, записанному во втором аргументе.
3) Логические функции:
- И( ), ИЛИ( ) возвращают значения ИСТИНА или ЛОЖЬ согласно заявленной логической операции над своими аргументами
- НЕ( ) меняет логическое значение на противоположное
- ЕСЛИ( ) принимает в зависимости от истинности или ложности логического выражения одно из указанных значений.
Кроме вышеперечисленных в Excel существует множество других функций. Они позволяют производить более сложные математические расчеты (например, матричные преобразования), проводить статистическую обработку данных при помощи методов, выходящих за рамки этого пособия (с использованием распределений, отличных от нормального, специальных критериев проверки гипотез и т. п.). Также есть группы функций, осуществляющие операции над текстовыми строками, преобразование форматов времени и даты и т. п. При необходимости все эти функции можно использовать, разобравшись самостоятельно.
Часть 4. Практические работы.
В этой части приводятся примеры практических работ по анализу данных с использованием электронных таблиц Microsoft Excel. Подробность описания выбрана таким образом, чтобы учащийся мог выполнить каждую из приведенных работ при условии знания теоретического материала, рассмотренного выше. Автор считает неправильным давать во всех случаях подробные подсказки, указывая конкретные адреса ячеек и вводимые формулы. Ученики, выполняющие работу, должны научиться понимать постановку задачи в её естественном виде, после чего самостоятельно выбирать методы ее решения.
Вычисление и отображение на диаграмме среднего числа пересдач в зависимости от возраста студентов.
В данной работе при помощи электронных таблиц Excel анализируются данные о числе двоек, полученных на экзаменах студентами различного возраста. Требуется вычислить среднее число полученных двоек для каждой возрастной категории и построить график зависимости этого числа от возраста студента.
Порядок выполнения работы:
Ввести в электронную таблицу исходные данные (см. колонки А, В,С на рисунке). Создать колонку возраста студентов (значения от 18 до 22) С использованием функции СЧЁТЕСЛИ( ) вычислить для каждого возраста число студентов, имеющих этот возраст. В качестве первого параметра ввести диапазон ячеек, содержащих возраст каждого студента. Для удобства дальнейшего копирования формулы не забывайте использовать абсолютный адрес. Вторым параметром («условие») указывается значение нужного возраста. В этом случае проверка условия представляет собой проверку совпадения с этим значением. С использованием функции СУММЕСЛИ( ) вычислить для каждого возраста суммарное число двоек, полученных студентами, имеющими этот возраст. Первым параметром этой функции указывается диапазон ячеек, содержащих проверяемый параметр (возраст). В качестве второго параметра задается проверяемое условие – аналогично условию в п.3. Третьим параметром указывается диапазон ячеек, содержащих суммируемые значения (число двоек). Разделив суммарное число двоек на число студентов, вычислить для каждого возраста среднее число полученных двоек. Построить точечную диаграмму, отображающую зависимость среднего числа полученных двоек от возраста студента. Оформить электронную таблицу.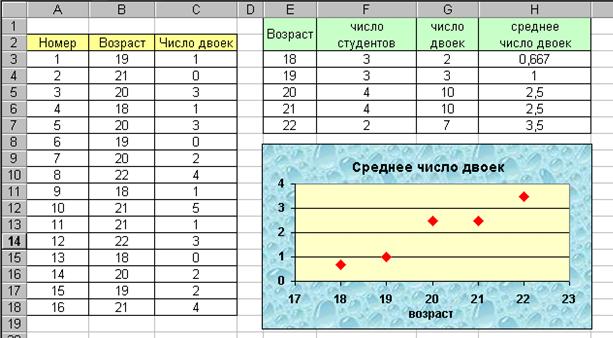
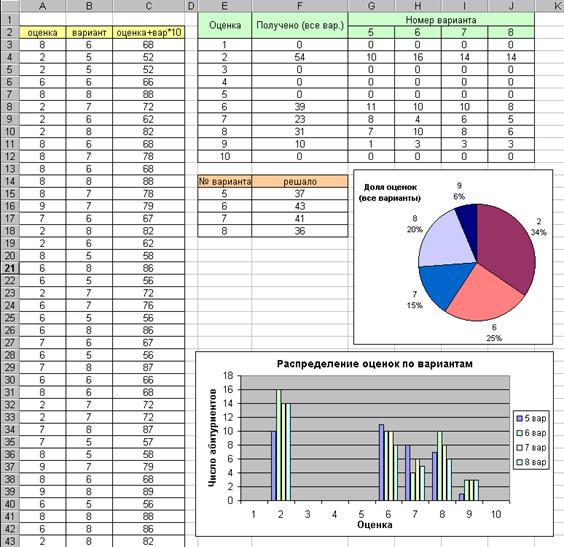
Анализ распределения оценок, полученных н а вступительном экзамене.
Целью практической работы является исследование распределения оценок по вариантам. В качестве данных использованы оценки по математике, полученные абитуриентами на Мехмате МГУ в 2004г. Эти оценки предварительно записаны в отдельном текстовом файле, имя которого следует узнать у преподавателя. Формат записи: оценка по десятибалльной системе, номер варианта. Следует открыть этот файл в Excel как текстовый файл с разделителями, указав в качестве разделителя запятую. После этого, используя копирование в буфер обмена, нужно перенести данные в НОВУЮ электронную таблицу. Файл с исходными данными должен остаться в неизменном виде. Лучше всего закрыть его сразу после переноса данных.
Порядок выполнения работы:
В процессе выполнения работы следует получить следующие таблицы и диаграммы (в заданиях 1-3 можно использовать функцию СЧЁТЕСЛИ( ) ).
1. Определить, сколько всего получено тех или иных оценок (вне зависимости от варианта). Отобразить полученные цифры в таблице и на круговой диаграмме.
2. Выяснить, сколько человек решало тот или иной вариант. Результат отобразить в таблице.
3. Определить, сколько тех или иных оценок получено абитуриентами, решавшими определенный вариант. Для подсчета таких случаев нужно предварительно вычислить колонку кодов ОЦЕНКА+ВАРИАНТ*10 . Подсчитав с помощью функции СЧЁТЕСЛИ( ) число таких комбинаций, можно найти искомые значения. Результат следует отобразить в таблице и на столбчатой диаграмме.
4*. Для каждого варианта вычислить вероятность получения той или иной оценки, разделив число абитуриентов, получивших на этом варианте соответствующую оценку, на общее число абитуриентов, выполнявших данный вариант.
5*. Вычислить среднее значение (функция СРЗНАЧ( )) и стандартное отклонение (функция СТАНДОТКЛОН( ) ) вероятности получения той или иной оценки. Сравнить разброс значений в зависимости от варианта с полученной величиной стандартного отклонения. Сделать выводы.
6*. Вычислить среднее значение и стандартное отклонение числа студентов, выполнявших тот или иной вариант. Сделать выводы.
* Результат выполнения этих пунктов работы на рисунке не показан.
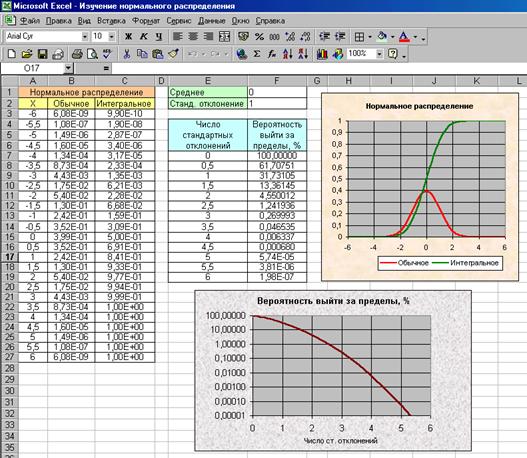
Изучение характеристик нормального распределения.
Как известно, большинство случайных величин, встречающихся в природе, имеют нормальное распределение, плотность которого задается формулой Гаусса. Цель данной работы – создание электронной таблицы, вычисляющей и отображающей графически основные характеристики нормального распределения. В первой части работы создается часть таблицы, показывающая график нормального распределения с заданными средним значением и стандартным отклонением. Кроме «обычного» распределения рассчитывается интегральное распределение, представляющее собой интеграл от нормальной функции распределения в пределах от минус бесконечности до заданного значения Х. Оба варианта вычисляются с помощью функции НОРМРАСП( ). Четвертый, логический, параметр этой функции позволяет выбрать то распределение, которое нужно. Во второй части работы с помощью интегральной функции распределения для различных N рассчитывается вероятность того, что экспериментальное значение будет отличаться от истинного более чем на N стандартных отклонений.
Порядок выполнения работы:
1) Набрать столбец значений Х в пределах от –6 до 6 с шагом 0.5 .
2) Внести значения среднего и стандартного отклонения, определяющие форму нормального распределения, в выбранные для этих величин ячейки (например, значения 0 и 1).
3) Вычислить с помощью функции НОРМРАСП( ) значения обычной и интегральной функции нормального распределения. В качестве параметров указываются значение Х, среднее и стандартное отклонение. В качестве четвертого параметра вводится слово ЛОЖЬ, если требуется обычное распределение и слово ИСТИНА, если требуется интегральное. При копировании формулы используйте абсолютный адрес ячеек, содержащих величины среднего значения и стандартного отклонения.
4) Построить на одном графике обычную и интегральную функции нормального распределения.
5) Изменяя величину среднего значения и стандартного отклонения, убедиться, что они отражают, соответственно, положение максимума и его полуширину на половине высоты.
6) Набрать столбец числа N стандартных отклонений в интервале от 0 до 6 с шагом 0.5 .
7) Для каждого N вычислить в процентах вероятность того, что измеренное значение будет отличаться от истинного более чем на N стандартных отклонений. Для этого использовать формулу:
Р=2*(1 - НОРМРАСП(N, 0, 1, ИСТИНА) ) * 100%
Вместо N в эту формулу следует подставить адрес соответствующей ячейки. Функция НОРМРАСП( ) с указанными параметрами дает вероятность получить в эксперименте значение, меньшее N (отрицательные значения считаются возможными. 1-НОРМРАСП( ) дает вероятность получить значение, большее N. Эту вероятность нужно умножить на 2, чтобы учесть отклонения как в большую, так и в меньшую сторону, и на 100, чтобы выразить вероятность в процентах.
8) Построить график зависимости вычисленной вероятности от N. По оси ординат следует выбрать логарифмическую шкалу, дающую возможность увидеть изменения величины в широких пределах.
9) Оформить электронную таблицу. Пример готовой таблицы показан на рисунке.
Использование случайных чисел для моделирования процесса ожидания автобуса.
В этой работе моделируется процесс ожидания автобусов на остановке. Предполагается, что пассажир, пришедший на остановку, может ехать на одном из трех автобусов: первый ходит 1 раз в 10 минут, второй – 1 раз в 15 минут и третий – 1 раз в 20 минут. Считая распределение моментов времени появления каждого из автобусов равномерным, нужно построить график распределения времени ожидания автобуса (подходит любой из трех). Меняя интервал следования каждого из автобусов, можно проанализировать, как изменится время ожидания, если один из автобусов ходит значительно чаще или значительно реже других.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
