

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ИНФОРМАЦИИ и МОДЕЛИРОВАНИЕ
С ИСПОЛЬЗОВАНИЕМ СЛУЧАЙНЫХ ЧИСЕЛ
Учебное пособие по информатике
для студентов и старшеклассников
Москва, 2004г
 |
С О Д Е Р Ж А Н И Е
Часть 1. Теоретическое рассмотрение методов анализа данных с учетом влияния случайных факторов.
Точность измерений и вычислений ……………………………………………………………………. 2
Ошибки в случае сложных измерений…………………………………………………………………. 2
Вероятность. Функции распределения…………………………………………………………………. 3
Нормальное распределение. Характеристики случайных величин…………………………………... 4
Аппроксимация методом наименьших квадратов……………………………………………………... 5
Проверка наличия линейной зависимости x от y……………………………………………………… 6
Часть 2. Моделирование с использованием случайных чисел.
Генератор случайных чисел…………………………………………………………………………….. 7
Получение случайных чисел с неравномерным распределением……………………………………. 8
Часть 3. Использование электронных таблиц Excel для анализа данных и моделирования.
Использование Excel для автоматических вычислений………………………………………………. 9
Построение диаграмм и графиков……………………………………………………………………… 10
Объединение данных из нескольких файлов. Экспорт данных, записанных в других форматах….. 11
Функции Excel, наиболее часто используемые в процессе обработки информации……………….. 12
Часть 4. Практические работы.
Вычисление и отображение на диаграмме среднего числа
пересдач в зависимости от возраста студентов………………………………….. 14
Анализ распределения оценок, полученных на вступительном экзамене………………………….. 15
Изучение характеристик нормального распределения…………………………………………………16
Использование случайных чисел для моделирования процесса ожидания автобуса………………. 17
Получение и использование в моделировании случайных чисел,
имеющих нормальное распределение…………………………………………….. 18
Определение параметров линейной зависимости методом наименьших квадратов……………….. 19
Проверка существования зависимости успеваемости от посещаемости…………………………….. 20
Приложения.
Оценки по математике, полученные абитуриентами на мехмате МГУ в 2004г…………………… 21
Оценки за полугодие и число уроков, пропущенных учащимися 10-х и 11-х классов……………. 21
Часть 1. Теоретическое рассмотрение методов анализа данных с учетом влияния случайных факторов.
Точность измерений и вычислений.
Любые измерения в естественных науках производятся с некоторой точностью. Так, используя различные методы измерений, расстояние »1км можно определить с точностью до 10м, до 1м, до 10см... В любом случае точность не будет абсолютной. Представляя результат, принято указывать не только саму величину, но и погрешность, с которой она получена: S=1км±10м. или S=1000±10 м.
Кроме абсолютной погрешности, которую обычно обозначают Dх, часто используется относительная погрешность dх=Dх/х. В приведенном выше примере относительная погрешность равна 10м / 1000м = 0.01 = 1%. Отметим, что относительная погрешности – безразмерная величина. Вместо слова «погрешность» часто используется термин «ошибка». Наличие «ошибок» не указывает на промахи экспериментатора, а лишь свидетельствует о конечной точности эксперимента.
В социальных науках также необходимо знать достоверность, с которой сделаны выводы. Например, если в результате опроса в городе А из 10 человек 5 ответили, что поддерживают реформы, а в городе Б – 6 человек из 10, то нет оснований для вывода, что в городах А и Б люди относятся к реформам по-разному. Более правильно говорить, что от 40% до 70% населения городов А и Б поддерживают реформы.
Несмотря на богатые возможности компьютера как вычислительного средства, в численных расчетах на компьютере также присутствуют погрешности. Как правило, они связаны с тем, что действительные числа, представляющие собой бесконечные десятичные дроби, хранятся в памяти компьютера в виде конечных дробей. Для примера оценим, с какой точностью хранится в компьютере действительное число, если под него отводится ячейка размером 4 байта.
Чтобы можно было записывать в одной и той же ячейке как маленькие числа (0.0001), так и большие (1.5´1012), действительные числа хранятся в виде a´10b. В этом случае 1 байт из 4-х можно отвести под порядок (величина b), из оставшихся 24 бит 1 бит будет содержать знак числа, а 23 бита – мантиссу (число а). Т. к. 28=256, то байт порядка может иметь 256 различных состояний. Значит, с учетом знака, число b будет принимать значения в интервале от -127 до 127. Т. к. 223»107, то числа, лежащие в интервале от 0 до 1, могут храниться с точностью до 7 знаков после запятой. Важно то, что в описанном представлении относительная точность (d£10-7) не зависит от величины хранимого в памяти числа.
Несмотря на то, что точность 7 знаков после запятой воспринимается как очень хорошая точность, в некоторых случаях ее недостаточно. Прежде всего, это относится к задачам, в которых требуется суммировать большое количество величин, в частности, к численному интегрированию. Например, точность, полученная в результате суммирования 104 слагаемых, составит всего лишь 3 знака после запятой. В подобных случаях следует использовать ячейки памяти большего размера или применять численные методы решения задачи, использующие меньшее число арифметических операций.
Ошибки в случае сложных измерений.
Для доказательства тех формул, которые будут получены ниже, удобно считать, что величина ошибки Dх означает, что максимальное возможное значение измеряемой величины будет равно х+Dх, а минимальное возможное значение равно х-Dх.
Погрешность суммы и разности. Если есть две измеренные величины x±Dх и y±Dy, то максимально возможное значение их суммы z=x+y равно zmax=x+y+Dх+Dy, минимальное значение zmin= x+y-Dх-Dy. Значит, погрешность величины суммы равна Dz=Dх+Dy. Поскольку для величины разности z=x-y максимальное значение достигается в случае наибольшего уменьшаемого и наименьшего вычитаемого, значит, как и для суммы, zmax=x+y+Dх+Dy. Аналогично, zmin= x+y-Dх-Dy. Поэтому погрешность разности равна сумме погрешностей: Dz=Dх+Dy.
Погрешность произведения. Для рассмотрения погрешности произведения z=xy заметим, что максимальное значение произведения (если сомножители неотрицательны) равно zmax=(x+Dх)(y+Dy). Каждый из сомножителей в скобках представим в виде
xmax=x+Dх=x(1+Dx/x)=x(1+dx) ymax=y+Dy=y(1+Dy/y)=y(1+dy)
тогда, раскрывая скобки, получим:
zmax=xy(1+dx) (1+dy)=xy(1+dx+dx+dxdy) » xy(1+dx+dy)
(Мы воспользовались тем, что в случае малых относительных ошибок их произведение dxdy значительно меньше каждой из них). Сравнивая записи для xmax и zmax, приходим к выводу, что в случае произведения относительные погрешности складываются. dz=dx+dy. Аналогично можно доказать справедливость этой же формулы для частного z=x/y.
Погрешность косвенных измерений. (результат получается из измеренной величины по формуле y=f(x) ). Этот случай лучше всего рассмотреть графически.
 Как видно из рисунка, максимальное и минимальное возможные значения равны f(x+Dx), f(x-Dx). При малых погрешностях можно заменить функцию вблизи рассматриваемой точки х касательной. Тангенс ее наклона определяет величину Dy из показанного на рисунке треугольника: Dy=Dх tg a. Так как тангенс угла наклона касательной равен производной функции y(x), то можно записать
Как видно из рисунка, максимальное и минимальное возможные значения равны f(x+Dx), f(x-Dx). При малых погрешностях можно заменить функцию вблизи рассматриваемой точки х касательной. Тангенс ее наклона определяет величину Dy из показанного на рисунке треугольника: Dy=Dх tg a. Так как тангенс угла наклона касательной равен производной функции y(x), то можно записать ![]() , где
, где ![]() - обозначение производной. Модуль позволяет рассматривать как возрастающие, так и убывающие функции.
- обозначение производной. Модуль позволяет рассматривать как возрастающие, так и убывающие функции.
Если результат вычисляется по формуле, в которую входит несколько непосредственно измеренных величин, то можно провести аналогичные рассуждения, используя понятие функции нескольких переменных. 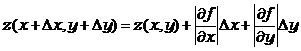 , где использованы так называемые частные производные – производные функции нескольких переменных по одной из них, в то время как другие переменные заменены числовыми значениями. Это применимо в случае независимых измеряемых величин. Кроме того, в случае независимых х и у правомерно заменить сумму модулей квадратичной суммой (дающей несколько меньшее значение):
, где использованы так называемые частные производные – производные функции нескольких переменных по одной из них, в то время как другие переменные заменены числовыми значениями. Это применимо в случае независимых измеряемых величин. Кроме того, в случае независимых х и у правомерно заменить сумму модулей квадратичной суммой (дающей несколько меньшее значение):
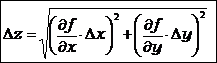
Это и есть основная формула для вычисления погрешностей в случае косвенных измерений. Число измеряемых величин, участвующих в косвенных измерениях, в этой формуле может быть любым. Формулы для погрешностей суммы, разности, произведения и частного следуют из этой формулы (если не использовать квадратичное суммирование) как частные случаи.
ПРИМЕР: Определим плотность вещества, из которого сделан кубик. В результате измерений известно, что ребро равно 10±0.1см, масса равна 800±10г. Плотность вычисляется по формуле: ![]() . Тогда, взяв производные, получим формулу для погрешности:
. Тогда, взяв производные, получим формулу для погрешности:
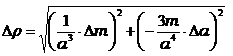 .
.
Подставив значения, получаем:
r=0.8г/см3
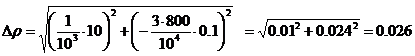 г/см3
г/см3
В итоге результат запишется как r=0.8±0.026 г/см3
Вероятность. Функции распределения.
Любой случайной величине х можно поставить в соответствие множество ее возможных значений (оно называется генеральной совокупностью). Если это множество представляет собой набор отдельных значений, то случайную величину называют дискретной. Для каждого из этих значений хi можно ввести величину p(хi), называемую вероятностью, таким образом, что при увеличении числа опытов отношение числа случаев, когда случайная величина х примет значение хi , к полному числу опытов n стремится к р(хi). Математически это можно записать, используя обозначение предела последовательности:
![]()
Вероятность, что случайная величина будет иметь какое-либо (любое) значение из всех возможных, очевидно, равна 1, поэтому
![]() , где m – число возможных значений дискретной случайной величины. Если вероятность того, что произойдет некоторое событие, равна p, то вероятность того, что оно не произойдет, равна 1-р.
, где m – число возможных значений дискретной случайной величины. Если вероятность того, что произойдет некоторое событие, равна p, то вероятность того, что оно не произойдет, равна 1-р.
Если события независимы, то вероятность того, что произойдут сразу все события, равна произведению вероятностей, что произойдет каждое из них. Если вероятность каждого из нескольких событий мала, то, в качестве некоторого приближения, можно считать, что вероятность того, что произойдет хотя бы одно из событий, равна сумме вероятностей каждого из этих событий. Такое приближение правомерно, если сумма вероятностей оказывается значительно меньше 1.
В науке часто используются непрерывные случайные величины, для которых множество значений представляет собой некоторый интервал (или набор интервалов). Пример: показания вольтметра, измеряющего напряжение в сети.
Для непрерывной случайной величины вводится понятие плотности распределения. Пусть случайная величина принимает значения х. Плотность распределения – это такая функция р(х), что вероятность обнаружить измеренное значение в пределах интервала от a до b выражается интегралом:
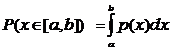
Напомним из математики, что интеграл от функции p(x) (например, записанный выше) представляет собой предел при Dxà0 суммы слагаемых вида p(x)*Dx, где Dx – длина малого промежутка, на которые разбит интервал [a, b]. Наглядная интерпретация интеграла – площадь под кривой p(x) в пределах [a, b].
Поскольку вероятность обнаружить какое-либо (любое) значение равна 1, 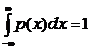 . Это условие называют условием нормировки.
. Это условие называют условием нормировки.
Для эмпирической оценки функции распределения можно провести серию опытов, затем разбить интервал возможных значений на небольшие отрезки и оценить вероятность попадания значения случайной величины в каждый из отрезков как отношение числа благоприятных исходов, при которых получено значение в пределах отрезка [a, b] к полному числу опытов: ![]() Истинное значение плотности вероятности достигается в пределе при увеличении числа опытов и, одновременно с этим, уменьшении длины отрезка вблизи исследуемого значения х :
Истинное значение плотности вероятности достигается в пределе при увеличении числа опытов и, одновременно с этим, уменьшении длины отрезка вблизи исследуемого значения х : ![]()
Нормальное распределение. Характеристики случайных величин.
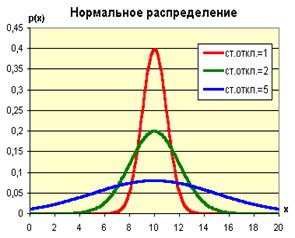 Очень многие случайные величины, встречающиеся в природе, имеют функцию распределения, называемую нормальной (иначе её называют функцией Гаусса). Эта функция имеет вид симметричного колокола с максимумом, совпадающим с истинным значением величины. Математически она выражается как:
Очень многие случайные величины, встречающиеся в природе, имеют функцию распределения, называемую нормальной (иначе её называют функцией Гаусса). Эта функция имеет вид симметричного колокола с максимумом, совпадающим с истинным значением величины. Математически она выражается как: 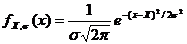 . Построив соответствующий график, можно убедиться, что эта функция имеет максимум при х=Х, а ширина колокола определяется величиной s. Действительно, параметр Х входит в приведенную формулу как некоторая добавка к переменной х, таким образом задавая сдвиг графика по оси абсцисс. Квадрат в показателе функции приводит к симметричной функции распределения, поскольку положительные и отрицательные отклонения (х-Х) приводят к одинаковому результату. Параметр s в показателе степени может быть внесен под квадрат (х-Х). Отсюда видно, что он задает масштаб, насколько сильно отклонения х от Х влияют на значения функции. Нормировочный множитель, стоящий перед экспонентой, необходим чтобы вероятность получения какого-либо (любого) значения была равна 1. При х=Х показатель степени обращается в 0, поэтому высота максимума равна 1/sÖ2p. При достаточно больших отклонениях (х-Х) величина е в отрицательной степени, а значит и вся функция нормального распределения, оказывается близкой к нулю.
. Построив соответствующий график, можно убедиться, что эта функция имеет максимум при х=Х, а ширина колокола определяется величиной s. Действительно, параметр Х входит в приведенную формулу как некоторая добавка к переменной х, таким образом задавая сдвиг графика по оси абсцисс. Квадрат в показателе функции приводит к симметричной функции распределения, поскольку положительные и отрицательные отклонения (х-Х) приводят к одинаковому результату. Параметр s в показателе степени может быть внесен под квадрат (х-Х). Отсюда видно, что он задает масштаб, насколько сильно отклонения х от Х влияют на значения функции. Нормировочный множитель, стоящий перед экспонентой, необходим чтобы вероятность получения какого-либо (любого) значения была равна 1. При х=Х показатель степени обращается в 0, поэтому высота максимума равна 1/sÖ2p. При достаточно больших отклонениях (х-Х) величина е в отрицательной степени, а значит и вся функция нормального распределения, оказывается близкой к нулю.
Параметры Х и s носят названия: «среднее значение» и «стандартное отклонение». Для величины s2 существует свое название: «дисперсия».
Представим себе, что для более точного нахождения истинного значения случайной величины мы провели несколько измерений и получили значения х1,х2,…,хn. Покажем, что наилучшей оценкой истинного значения будет среднее арифметическое измеренных значений. Для этого воспользуемся методом максимального правдоподобия:
Пусть нам нужно определить параметры функции распределения (в данном рассмотрении – истинное значение Х) по набору экспериментальных значений. Будем считать оптимальным такое значение искомого параметра, при котором вероятность получения измеренного набора значений вблизи х1,х2,…,хn (т. е., в пределах Dх от этих значений) максимальна. Если выразить вероятность получения значения х в интервале (х, х+Dх) как произведение функции нормального распределения на ширину интервала, а также учесть, что вероятность получения всей совокупности независимых событий равна произведению вероятностей, то
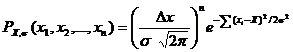 . Для нахождения максимума этой вероятности, продифференцируем эту функцию по Х и приравняем производную к нулю. Как и ожидалось, максимум достигается при
. Для нахождения максимума этой вероятности, продифференцируем эту функцию по Х и приравняем производную к нулю. Как и ожидалось, максимум достигается при ![]() , где n – число измерений. Аналогичным образом, подставив вместо Х среднее арифметическое, дифференцируя функцию вероятности по переменной s и приравнивая производную к нулю, можно получить, что наилучшая оценка ширины распределения – это
, где n – число измерений. Аналогичным образом, подставив вместо Х среднее арифметическое, дифференцируя функцию вероятности по переменной s и приравнивая производную к нулю, можно получить, что наилучшая оценка ширины распределения – это 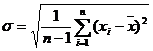 .
.
По этой формуле делается оценка величины стандартного отклонения, определяющего разброс измеряемых значений вблизи истинного значения величины. Взяв интеграл от нормальной функции распределения в интервале от Х-s до Х+s, можно определить, что вероятность получения измеренного значения в пределах Х±s равна 0.68 . В общем случае, результат исследований следует представлять как оценку истинного значения и доверительный интервал, соответствующий значению вероятности, с которой истинное значение лежит внутри этого интервала.
Как правило, в научных исследованиях вывод о наличии какого-либо эффекта делается в том случае, когда измеренная величина выходит за пределы возможных случайных отклонений более чем на 3s, что соответствует вероятности случайной имитации около 0.3%.
Смысл стандартного отклонения состоит в том, что оно выражает точность определения истинного значения в результате одного измерения (т. е. разброс измеряемых значений). Какую же точность дает оценка истинного значения как среднего арифметического нескольких измеренных величин? Воспользовавшись формулой для вычисления ошибки суммы (используя квадратичное сложение), получаем:
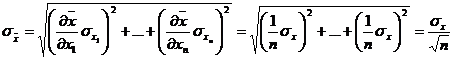
Таким образом, при проведении n измерений точность результата улучшается в ![]() раз.
раз.
Аппроксимация методом наименьших квадратов.
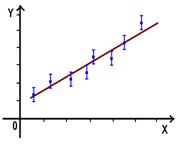 Часто требуется найти форму зависимости одной величины от другой. В простейшем случае предполагается линейная зависимость вида y=ax+b. Результатом измерений служат пары чисел (х, y(х)), при этом можно считать значения х точными, а значения y(x)- имеющими равные погрешности Dy. Рассматриваемую задачу анализа данных можно разделить на две части:
Часто требуется найти форму зависимости одной величины от другой. В простейшем случае предполагается линейная зависимость вида y=ax+b. Результатом измерений служат пары чисел (х, y(х)), при этом можно считать значения х точными, а значения y(x)- имеющими равные погрешности Dy. Рассматриваемую задачу анализа данных можно разделить на две части:
1. Какие коэффициенты a и b наилучшим образом описывают линейную зависимость?
2. Насколько правомерно предположение, что эта зависимость линейна?
Задача определения коэффициентов а и b решается с использованием метода максимального правдоподобия. Предполагая Гауссову форму функции распределения, можно записать формулу для вероятности получения измеренного набора yi в случае предполагаемых коэффициентов a и b. В формулу войдет экспонента с показателем 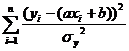 . Очевидно, что максимальная вероятность достигается в том случае, когда сумма квадратов отклонений измеренных значений yi от вычисленных по предполагаемой формуле, минимальна. Вот почему рассматриваемый метод называют методом наименьших квадратов. Опуская процедуру нахождения минимумов путем дифференцирования по переменным a и b, выпишем итоговые формулы:
. Очевидно, что максимальная вероятность достигается в том случае, когда сумма квадратов отклонений измеренных значений yi от вычисленных по предполагаемой формуле, минимальна. Вот почему рассматриваемый метод называют методом наименьших квадратов. Опуская процедуру нахождения минимумов путем дифференцирования по переменным a и b, выпишем итоговые формулы:
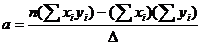 ;
; 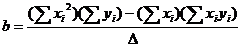 ,
,
где введено обозначение ![]() .
.
Погрешности коэффициентов a и b определяются обычным способом вычисления ошибок в косвенных измерениях, исходя из погрешностей в y1…yn. Можно убедиться, что
 ;
; ![]()
При отсутствии каких-либо сведений о погрешностях sу их можно оценить по формуле:
![]() . Значение 1/(n-2) вместо ожидаемого 1/n появилось перед суммой в связи с тем, что параметры а и b не являются точными, вместо них используются статистические оценки. Действительно, при попытке оценить точность измерения значений yi всего лишь по двум точкам мы получили бы погрешность, равную нулю, в то время как приведенная выше формула указывает на недостаточность информации о точности измерений.
. Значение 1/(n-2) вместо ожидаемого 1/n появилось перед суммой в связи с тем, что параметры а и b не являются точными, вместо них используются статистические оценки. Действительно, при попытке оценить точность измерения значений yi всего лишь по двум точкам мы получили бы погрешность, равную нулю, в то время как приведенная выше формула указывает на недостаточность информации о точности измерений.
Задача аппроксимации данных кривыми другого вида также решается методом наименьших квадратов. В частности, в некоторых случаях можно осуществить математические преобразования искомой зависимости к линейному виду. Так или иначе, наилучшей кривой, описывающей экспериментальные данные, будет та кривая, для которой сумма квадратов отклонений измеренных значений yi от теоретически рассчитанных, минимальна.
Проверка наличия линейной зависимости x от y.
Предположив наличие линейной зависимости x от y, можно вычислить параметры a и b этой зависимости. Однако, следует обосновать утверждение, что зависимость существует и имеет вид линейной функции.
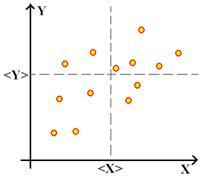 Наличие какой-либо зависимости подтверждает отличие от нуля так называемого смешанного второго момента
Наличие какой-либо зависимости подтверждает отличие от нуля так называемого смешанного второго момента ![]() . Роль этой величины можно понять, глядя на рисунок. В случае, когда существует четко выраженная линейная зависимость, т. е. экспериментальные точки лежат строго на одной прямой, пунктирные прямые <X> и <Y> пересекутся также на этой прямой. В результате все слагаемые, входящие в сумму смешанного второго момента будут положительными, если зависимость Y(X) возрастающая, и, наоборот, отрицательными, если эта зависимость убывающая. При отсутствии какой-либо зависимости, т. е. когда точки на плоскости распределены случайным образом, примерно равное число положительных и отрицательных слагаемых приведет к величине смешанного второго момента, близкой к нулю.
. Роль этой величины можно понять, глядя на рисунок. В случае, когда существует четко выраженная линейная зависимость, т. е. экспериментальные точки лежат строго на одной прямой, пунктирные прямые <X> и <Y> пересекутся также на этой прямой. В результате все слагаемые, входящие в сумму смешанного второго момента будут положительными, если зависимость Y(X) возрастающая, и, наоборот, отрицательными, если эта зависимость убывающая. При отсутствии какой-либо зависимости, т. е. когда точки на плоскости распределены случайным образом, примерно равное число положительных и отрицательных слагаемых приведет к величине смешанного второго момента, близкой к нулю.
Если смешанный второй момент нормировать на произведение стандартных отклонений sх×sу, получим коэффициент корреляции, вычисляемый по формуле:
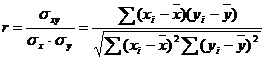
Коэффициент корреляции принимает значения, лежащие в интервале от –1 до 1. Если предположить, что все экспериментальные точки лежат точно на прямой линии, т. е. всегда yi=axi+b, следовательно, ![]() и, вычитая одно из другого,
и, вычитая одно из другого, ![]() . Поэтому в случае точной линейной зависимости
. Поэтому в случае точной линейной зависимости ![]() , причем знак коэффициента корреляции положителен для возрастающей линейной функции y(x).
, причем знак коэффициента корреляции положителен для возрастающей линейной функции y(x).
Если никакой зависимости между x и y нет, то слагаемые суммы, стоящей в числителе, могут иметь положительный и отрицательный знаки с равной вероятностью. Это приводит к тому, что при отсутствии связи между x и y коэффициент корреляции равен нулю.
В реальных случаях исследователь получает некоторое значение коэффициента корреляции r0, лежащее между 0 и 1. Если это значение близко к 1 – он должен сделать вывод о существовании зависимости, если близко к 0 – об её отсутствии. Для определения количественного критерия, которым должен руководствоваться исследователь в своих выводах, он должен определить вероятность, с которой две независимые величины дадут значение r>r0. Эта вероятность зависит не только от r0, но и от числа n экспериментальных точек. Некоторые значения вероятности получить r> r0 приведены в таблице (в процентах):
r0 n | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
3 | 100 | 94 | 87 | 81 | 74 | 67 | 59 | 51 | 41 | 29 | 0 |
6 | 100 | 85 | 70 | 56 | 43 | 31 | 21 | 12 | 6 | 1 | 0 |
10 | 100 | 78 | 58 | 40 | 25 | 14 | 7 | 2 | 0.5 | - | 0 |
20 | 100 | 67 | 40 | 20 | 8 | 2 | 0.5 | 0.1 | - | - | 0 |
50 | 100 | 49 | 16 | 3 | 0.4 | - | - | - | - | - | 0 |
Обратим внимание, что сделать вывод о наличии линейной зависимости по трем точкам практически невозможно – даже значение r=0.9 недостаточно, поскольку вероятность случайной имитации достаточно велика (~30%). Во многих практических случаях требуется значение r>0.7 .

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
