
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Результатом склеивания по гиперплоскостям несравнимости является линейная порядковая шкала с ![]() градациями, где K — число линейных шкал релевантности (запросов), комбинацией которых является рассматриваемая релевантность (запрос), а Ri — число градаций каждой такой шкалы. В i-ю градацию линеаризованной релевантности отобразятся все градации
градациями, где K — число линейных шкал релевантности (запросов), комбинацией которых является рассматриваемая релевантность (запрос), а Ri — число градаций каждой такой шкалы. В i-ю градацию линеаризованной релевантности отобразятся все градации 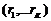 , лежащие на K-мерной шкале в гиперплоскости
, лежащие на K-мерной шкале в гиперплоскости 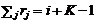 .
.
1 | 2 | 3 | 4 | |||||
1 | 2 | 1 | Ú > | Ú > | Ú > | Ú | ||
1 | Ú > | Ú | 2 | Ú > | Ú > | Ú > | Ú | |
2 | > | 3 | > | > | > | |||
# of grades: R1 = R2 = 2 | # of grades: R1 = 3, R2 = 4 |
| ||||||
Рис. 3. Предпочтения на двумерной шкале комбинированной релевантности
Можно показать, что результат линеаризации комбинированной K-мерной шкалы представим в виде выполняемой в произвольном порядке последовательности операций комбинирования/линеаризации шкал-компонент. Например, можно комбинировать и линеаризовать первые две шкалы-компоненты, затем скомбинировать полученную шкалу с третьей шкалой-компонентой и т. д. Поэтому можно ограничиться рассмотрением операций только над двумя шкалами.
Мы постарались описать механизм комбинирования релевантности. Это психологический механизм. Наша схема дает только максимальное число градаций линеаризованной комбинированной релевантности. Человек в принципе может склеивать смежные градации, скажем, если число градаций слишком велико (например, больше трех), жертвуя условием линеаризации ради актуальной возможности сравнения. В частности, как мы увидим, для (формально) многозначной релевантности пустыми могут оказаться несколько первых градаций, и нет никаких причин, почему бы не склеить их в одну.
3 Конфигурации релевантности
Число документов, относящихся к той или иной градации релевантности линеаризованной конфигурации есть сумма тех элементов матрицы A, которые соответствуют (принадлежат тем же градациям ) объединяемым элементам матрицы P. Именно, число документов, принадлежащих i-й шкале линеаризованной K-мерной релевантности, есть сумма ![]() по всем {
по всем {![]() }, лежащим на гиперплоскости
}, лежащим на гиперплоскости ![]() .
.
Мы описали линеаризацию K-мерной матрицы предпочтений P. Число документов, относящихся к каждой градации линеризованной шкалы, есть сумма по объединяемым в нее градациям K-мерной матрицы распределения A. Если запросы, порождающие R1- и R2-конфигурации независимы, то Aij равно ![]() , где N — общее число документов в базе. В K-мерной комбинированной шкале имеются
, где N — общее число документов в базе. В K-мерной комбинированной шкале имеются ![]() градаций
градаций ![]() . В случае взаимной независимости образующих комбинацию релевантностей ожидаемое значение
. В случае взаимной независимости образующих комбинацию релевантностей ожидаемое значение ![]() равно
равно ![]() .
.
1 | 2 | 3 | 1 | 2 | 3 |
| |||||
1 | n1 | 0 | 0 | 1 | 0 | 0 | n1 |
| |||
2 | 0 | n2 | 0 | 2 | 0 | n2 | 0 |
| |||
3 | 0 | 0 | n30 | 3 | n3 | 0 | 0 |
| |||
| Идентичные запросы. | Противоположные запросы | |||||||||
Рис. 4. Распределения релевантности, порожденной комбинированием двух строго взаимозависимых тернарных релевантностей
В принципе, комбинируемые запросы могут быть зависимы. Предельные случаи зависимости (строгое совпадение и строгая противоположность) представлены на рис. 4. Результатом комбинирования двух строго взаимозависимых 3-значных релевантностей оказываются 5-значные релевантности, имеющие распределения ![]() для положительной зависимости и
для положительной зависимости и  для отрицательной.
для отрицательной.
Например, пусть 5-значная конфигурация комбинируется из двух 3-значных конфигураций, имеющих одинаковые распределения n(1) = n(2) = (1, 2, 100). Если бы они были независимы, результатом было бы 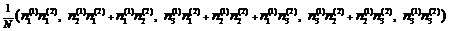 , т. е. порядка (0.01, 0.04, 1.97, 3.88, 97). С другой стороны, если конфигурации строго положительно зависимы, результатом будет распределение (1, 0, 2, 0, 100). Ясно, что результатный вектор очень чувствителен к положительной зависимости, если число документов {
, т. е. порядка (0.01, 0.04, 1.97, 3.88, 97). С другой стороны, если конфигурации строго положительно зависимы, результатом будет распределение (1, 0, 2, 0, 100). Ясно, что результатный вектор очень чувствителен к положительной зависимости, если число документов {![]() } входящих в склейку градаций мало (что характерно для высокорелевантных градаций), и практически нечувствителен, если оно велико (низкорелевантные градации). Кроме того, в случае независимости компонент число высокорелевантных документов, как кажется, убывает чрезмерно быстро с ростом числа градаций комбинированной релевантности.
} входящих в склейку градаций мало (что характерно для высокорелевантных градаций), и практически нечувствителен, если оно велико (низкорелевантные градации). Кроме того, в случае независимости компонент число высокорелевантных документов, как кажется, убывает чрезмерно быстро с ростом числа градаций комбинированной релевантности.
Чтобы, при условии независимости компонент, число наиболее релевантных документов ![]() равнялось хотя бы нескольким, число наболее релевантных документов по каждой из K объединяемых конфигураций {
равнялось хотя бы нескольким, число наболее релевантных документов по каждой из K объединяемых конфигураций {![]() } должно быть порядка
} должно быть порядка 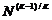 . Тогда если доля наиболее релевантных документов по каждой из K комбинируемых шкал не превышает некоторого l, общее число документов в базе должно быть больше
. Тогда если доля наиболее релевантных документов по каждой из K комбинируемых шкал не превышает некоторого l, общее число документов в базе должно быть больше ![]() . Например, при l=0,001 и K=3 общее число документов в базе должно быть порядка триллиона. Только в этом случае есть надежда, что база содержит хотя бы несколько документов, относящихся к высшей градации комбинированной шкалы. В действительности это не очень неожиданное значение, учитывая, что поисковые машины как раз и имеют базы из нескольких триллионов документов. С другой стороны, разумно допустить возможность некоторой положительной зависимости комбинируемых компонент.
. Например, при l=0,001 и K=3 общее число документов в базе должно быть порядка триллиона. Только в этом случае есть надежда, что база содержит хотя бы несколько документов, относящихся к высшей градации комбинированной шкалы. В действительности это не очень неожиданное значение, учитывая, что поисковые машины как раз и имеют базы из нескольких триллионов документов. С другой стороны, разумно допустить возможность некоторой положительной зависимости комбинируемых компонент.
Вместе с тем, в реальности запрос, являющийся комбинацией строго зависимых запросов, невозможен. Более того, даже нестрогая отрицательная зависимость весьма маловероятна. Тем самым, можно исключить из рассмотрения распределения, полученные комбинированием отрицательно зависимых конфигураций.
Теперь можно формально мотивировать, почему 2-конфигурация недостаточна для получения всех известных распределений релевантности и почему базис должен включать также 3-конфигурации. Дело в том, что комбинируя пару 2-конфигураций, можно получить все 3-конфигурации за исключением одной — T3.1. Это формальная причина. Содержательно же рассмотренные выше 3-конфигурации интерпретируется как неразложимые на более простые.
Поскольку все комбинации двух 2-конфигураций покрываются одной из 3-конфигураций, все разнообразие декомпозиций R-значных релевантностей представимо в виде комбинаций либо (R-1)/2 различных 3-конфигураций (для нечетного R), либо одной 2-конфигурации и R/2–1 3-конфигураций (для четного R). Это, в частности, дает прозрачную рекурсивную процедуру сборки R-конфигураций для произвольного R.
Если поисковый запрос отличается от письма Деду Морозу (а это так, реальные запросы коротки [6]), то он образован не более чем 1–3 базовыми конфигурациями. Тем самым, число градаций комбинированной релевантности обычно не превышает 5–6. На рис. 5 представлены все выводимые из базового набора распределения для 4-, 5- и 6-конфигураций. Некоторые из этих распределений получаются несколькими способами. Как отмечалось, распределения, полученные с использованием конфигурации T3.2, достаточно нетипичны. Поэтому очень важно, что такие распределения (а к их числу относятся, например, 4-2, 5-1, 5-2) также выводимы и без использования T3.2.
Все наборы производных 4-, 5- и 6-конфигураций включают, среди прочих, и тривиальные “экспоненциальные” конфигурации (4-1, 4-3, 5-1, 5-2, 5-5, 6-1, 6-2, 6-3), в том числе, экспоненциальные со сдвигом. Помимо них, набор 4-конфигураций содержит две устойчивые нетривиальные конфигурации, а конфигурация 4-negative достаточно нетипична. Набор 5-конфигураций содержит две нетривиальных конфигурации (5-3 и 5-4, а конфигурация 5-positive в действительности является подвидом 5-3). Набор 6-конфигураций содержит две конфигурации (6-4 и 6-5), нетривиальных в низкорелевантных градациях, и одну нетривиальную (6-positive) в высокорелевантных градациях.
4-1 | | 4-2 | 4-3 | 4positive | 4-negative | |||||||||||||||||||
| | | ||||||||||||||||||||||
| | ~ | | | | ~ | ~ | |||||||||||||||||
~ | ~ | |||||||||||||||||||||||
1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
4–конфигурации, образуемые 2- и 3-конфигурациями

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
