
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
5-1 | | 5-2 | 5-3 | 5-4 | 5-5 | 5positive | ||||||||||||||||||||||||||||
| | | | | | |||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||
| | | ~ | | ~ | | | ~ | ||||||||||||||||||||||||||
~ | Ú | |||||||||||||||||||||||||||||||||
1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
5–конфигурации, образуемые двумя 3-конфигурациями
6-1 | | 6-2 | 6-3 | | 6-4 | 6-5 | 6positive |
| | | | |||||||||||||||||||||||||||||||||||||
| | | | | ||||||||||||||||||||||||||||||||||||
| | | ¯ | | ~ | |||||||||||||||||||||||||||||||||||
| | | | | | ~ | ||||||||||||||||||||||||||||||||||
~ | ||||||||||||||||||||||||||||||||||||||||
1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | 3 | 4 | 5 | 6 |
6– конфигурации, образуемые одной 2- и двумя 3-конфигурациями
Рис. 5. Распределения производных 4-, 5- и 6-конфигураций (‘~’, ‘’ и ‘Ú’ обозначают соответственно однопорядковость, существенный рост и несущественное уменьшение)
Таким образом, большую часть производных распределений составляют экспоненциальные и сдвинутые экспоненциальные. Чем больше R, тем больше эта часть. В то же время, для всех R мы видим конфигурации, в которых число документов, относящихся к соседним градациям релевантности, различается несущественно.
4 Распределения оценок релевантности, соответствующие распределениям комби - нированной релевантности
В отличие от распределений релевантности (считавшейся бинарной), распределения оценок релевантности (на бесконечной шкале) являются традиционным объектом теории поиска информации [1], [10], [12]. Оценки релевантности — это релевантность с точки зрения поисковой машины и они изначально измеряются на многозначной (потенциально бесконечной) шкале (в противном случае польза от поисковых машин оказалась бы очень сомнительной). При этом дескриптивное моделирование распределений оценок основано на допущении о том, что релевантность бинарна, а ее распределение стандартно аппроксимируется фрагментом гауссовской кривой. Однако если число градаций релевантности больше двух, то либо этот факт никак не отражается на распределении оценок релевантности (что не верно), либо приближение этого распределения заметно смещено (что и наблюдается в приближениях распределений оценок). Заметим, что аргументы в пользу нормального приближения распределений оценок больше напоминают чрезмерно вольную популяризацию центральной предельной теоремы и будучи истолкованы буквально означают, что никаких иных распределений кроме гауссовского быть не может.
В то же время нормальное распределение ничем не плохо для описания распределений оценок для одной градации релевантности. Впрочем, в таком качестве оно ничем не лучше большинства унимодальных функций и играет чисто вспомогательную роль.
Механизм линеаризации комбинированной релевантности сходен с — используемыми поисковыми машинами — методами получения невзвешенных оценок релевантности. Оценки релевантности — это своего рода тень истинной релевантности. Если основанная на частотности терминов процедура назначения оценок не улавливает существа запроса, то оценки оказываются чрезвычайно размыты. Так например, долго обсуждаемый в [10] запрос 151 из тестовой коллекции TREC 3, звучит как ‘Coping with overcrowded prisons’, хотя и порождает релевантность, заведомо относящуюся к базовому набору (т. е. с 2–3 градациями), тем не менее соответствующие ему оценки распределены на [0,1] практически равномерно, даже не смотря на то, что как авторы [10] пытаются убедить нас, как хорошо данное распределение описывается нормальным.
|
|
|
|
|
|
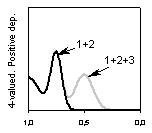
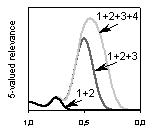
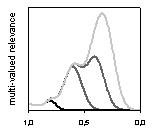
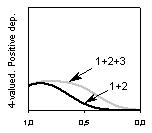
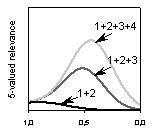
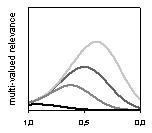
Рис. 6. Кумулятивные (по первым градациям релевантности) распределения оценок релевантности для некоторых конфигураций релевантности
В свете сказанного о том, что гауссовское распределение ничем не плохо для приближения оценок, соответствующих каждой отдельной градации релевантности, мы не стали нарушать традицию и воспользовались именно этим приближением. Как видно из графиков расположенных во второй строке рис. 6, если оценки являются размытой тенью релевантности, кумулятивные распределения оценок относятся к одному типу, действительно напоминающему гауссовское распределение. Напротив, если процедура назначения оценок довольно хорошо улавливает суть запроса (что все-таки не редкость), все кумулятивные распределения имеют “зыбь” в области высоких оценок и гладко убывают в области низкой релевантности.
Таким образом, существует два типа распределений кумулятивных оценок: с (создающими “зыбь”) локальными максимумами для отдельных градаций релевантности и с одним глобальным максимумом.
5 Градации релевантности: “две” слишком много, несколько — в самый раз
Концепция “многозначной” релевантности впервые артикулированно была введена [5], [6] в области измерения и оценки (evaluation) качества поиска как противостоящая бинарной релевантности. Дело в том, что, в отличие от большинства теоретиков поиска информации, специалисты по измерению толкуют бинарную релевантность буквально — как принимающую ровно два значения. Напротив, теоретики поиска подходят к бинарной релевантности “релятивистски”: то как к двузначной (“собственно релевантность”, которой, естественно, не пользуются), то как к непрерывной (“вероятность быть релевантности с точки зрения пользователя”, которая и является объектом моделирования). Поэтому важнее подчеркнуть, что “многозначная” релевантность в действительности “малозначна” и в таком качестве противостоит непрерывной “бинарной релевантности”.
В настоящей статье мы показали, что число различных типов распределений релевантности очень невелико. Более многозначная релевантность выводилась нами из базового набора, включающего конфигурации 2- и 3-значной релевантности. Мы перечислили эти производные конфигурации, что важно не только для задач оценивания (evaluation), но также важно с практической точки зрения. Кроме того, мы описали возможные формы распределений оценок, соответствующих малозначным релевантностям.
Литература
1. Arampatzis, A., van Hameren, A. The score-distributional threshold optimization for adaptive binary classification tasks. Proceedings of 24th ACM SIGIR Conference (2001), 285-293
2. Buzikashvili, N. Metasearch. Properties of common documents distributions. Proceedings of 4th PAKM Conference (2002), LNAI 2569, Springer-Verlag, 226-231
3. Buzikashvili, N. Stable configurations of few-valued relevance. 20th BNCOD, 2003 (accepted but unpublished due to author’s refusal to pay any fee).
4. Dwork, C., Kumar, R., Naor, M., Sivakumar, D. Rank Aggregation Methods for the Web. Proceedings of WWW10 (20
5. Eguchi, K., Oyama, K., Ishida, E., Kando, N., Kuriyama, K. Overview of the Web retrieval task at the third NTCIR workshop. Technical report of National Institute of Informatics (2003)
6. Jansen, B., Spink, A., Saracevic, T. Real life, real users, and real needs: A study and analysis of user queries on the web. Information Processing and Management, 36(20
7. Järvelin, K., Kekäläinen, J. IR evaluation methods for retrieving highly relevant documents. Proceedings of the 23rd ACM SIGIR Conference (2000) 44–48
8. Järvelin, K., Kekäläinen, J. Using graded relevance assessments in IR evaluation. JASIST,,
9. Kando, M. NTCIR Workshop: Japanese - and Chinese-English Cross-Lingual Information Retrieval and Multi-grade Relevance Judgments. Proceedings of CLEF, (2000), LNAI 2069, Springer-Verlag, 24-35
10. Manmatha, R., Rath, T., Feng, F. Modeling score distributions for combining the outputs of search engines. Proceedings of the 24th ACM SIGIR Conference (20
11. Voorhes, E. Evaluation by highly relevant documents. Proceedings of the 24th ACM SIGIR Conference (20
12. Zhang, Yi, Callan, J. A Generative Model for Filtering Thresholds. Proceedings of the Workshop on Language Modeling and Information Retrieval (20

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
