

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1.4 Задачи диссертационной работы
В результате исследования особенностей задач аналитической обработки данных, возникающих в разных в разных прикладных областях, представляющих собой быстро расширяющуюся бизнес-сферу применения оперативной аналитической обработки данных, с учетом результатов анализа требований к OLAP-технологии и существующих OLAP-продуктов, сформулированы следующие задачи диссертационной работы:
1. Исследование проблемы применения OLAP-технологии как инструмента решения аналитических задач в разных предметных областях. Определение особенностей, ограничивающих область применения OLAP-продуктов. Обоснование необходимости развития технологии оперативной аналитической обработки и создания математического и программного обеспечения для расширения области применения за счет реализации комплексов OLAP-моделей, а также средств настройки OLAP-продуктов на решение прикладных задач и средств создания пользовательских приложений.
2. Реализация нового подхода в OLAP-технологии, ориентированного на решение сложных аналитических задач, использующих связные многошаговые расчеты с множеством информационных объектов, представленных многомерными кубами данных. Разработка языковых, алгоритмических и программных средств, обеспечивающих реализацию сложных аналитических расчётов путем создания комплексов OLAP-моделей, наследующих данные.
3. Разработка OLAP-машины, включая средства построения витрин данных, средства выполнения произвольных аналитических запросов, средства представления и обработки многомерных данных (многомерный куб, кросс-таблица, кросс-диаграмма), обладающих функциями работы с составными иерархиями со сложными оглавлением в качестве измерений. OLAP-машина должна быть разработана как совокупность инструментальных средств, которые могут встраиваться в разные приложения и работать с базами данных разных форматов.
4. Разработка программных средств для автоматизации создания OLAP-приложений в форме инструментального ядра, среды проектирования экранных форм пользовательского интерфейса и мастера быстрого создания приложений.
5. Разработка настольной OLAP-системы, которая представляет собой инструментальную программную среду, позволяющую выполнять комплексный анализ данных и построение прикладных OLAP-систем и поддерживает следующий набор функций:
- создание витрин данных, OLAP-моделей, сценариев аналитических расчетов, форм специализированных приложений и отчетных форм;
- выполнение комплексных OLAP-расчетов;
- выполнение OLAP-приложений со специализированным интерфейсом;
- прямой доступ к репозитариям баз данных систем статистического наблюдения и хранения данных.
6. Апробирование созданного программного обеспечения, а также методологических и технологических подходов в решении информационно-аналитических задач анализа медико-демографических данных, планирования медицинской помощи, поддержки принятия решений в области охраны материнства и детства, для расчета объемных и стоимостных показателей стационарной, социально-значимой, стационарно-замещающей, амбулаторно-поликлинической медицинской помощи в обязательном медицинском страховании, для медико-экономического анализа льготного лекарственного обеспечения.
7. Разработка средств взаимодействия инструментальной OLAP-системы и приложений, создаваемых на ее основе, с базами и хранилищами данных, а также с другими информационными системами, осуществляющими сбор, систематизацию и хранение данных.
Выводы к разделу 1
Показана актуальность проблемы развития и применения технологии оперативного анализа данных (OLAP) в разных прикладных областях, в том числе для решения сложных многошаговых аналитических задач.
Отмечены основные недостатки существующих OLAP-решений, основные из которых – недостаточное внимание к задачам комплексного анализа данных, связанным с реализацией сложных аналитических методов, а также к задаче построения OLAP-систем со специализированным интерфейсом пользователя.
По результатам сравнительного анализа функциональности информационных систем оперативной аналитической обработки данных показана необходимость реализации нового подхода, развивающего классические положения OLAP-технологии и обладающего набором оригинальных возможностей, требующихся для решения сложных аналитических задач.
Предложено создать оригинальное программное обеспечение для создания и выполнения комплексов аналитических расчетов, сочетающих в рамках одной задачи информацию множества многомерных кубов данных, а также инструментарий для построения OLAP-систем с адаптированным интерфейсов для специалистов предметной области.
Проведен обзор и тестирование предлагаемых на рынке OLAP-компонент для встраивания в информационные системы. Анализ компонент выявил слабую функциональность и низкую скорость работы предлагаемых решений.
В соответствии с результатами исследования перечисленных актуальных проблем сформулированы задачи диссертационной работы.
2 Технологические СРЕДСТВА оперативной аналитической обработки данных
2.1 Технология оперативной аналитической обработки данных
2.1.1 Особенности предлагаемого подхода
В данной работе предлагается новый подход к решению разнообразных задач с применением OLAP-технологии, основанный на построении так называемых OLAP-моделей [45,48,47].
OLAP-модель является описанием процесса расчета одной аналитической задачи. Структурно OLAP-модель состоит из исходных данных, витрины данных, информационного куба и операций над ним, способов представления результатов вычисления и средств сохранения результатов. Формальное определение OLAP-модели приводится ниже.
Важным моментом при построении OLAP-модели является возможность сохранения в источнике данных результатов расчета, что позволяет применять поэтапный процесс анализа данных, то есть анализировать ранее полученные результаты. Необходимость поэтапной обработки возникает в случаях, когда для получения конечных результатов требуется сложная обработка исходных данных, как например, для реализации задач планирования медицинской помощи, или социальных услуг.
Для автоматизации поэтапного анализа предлагается объединять OLAP-модели в комплексы. Перед созданием комплекса OLAP-моделей задачу необходимо декомпозировать на подзадачи, таким образом, чтобы каждая подзадача могла быть представлена аналитической моделью. В рамках одного расчета OLAP-модели образуют последовательно выполняемую цепочку, при этом данные, рассчитанные одной моделью, в дальнейшем используются другими моделями. Таким образом, OLAP-модели образуют комплекс, а их взаимосвязь реализуется через наследование информации.
Терминология оперативной аналитической обработки
Реляционная модель данных – традиционное представление информации в форме связанных нормализованных таблиц.
Многомерная модель данных – представление информации в форме многомерного информационного куба, измерения которого могут использоваться для анализа информации путем выбора интервалов значений по каждому измерению (срезов).
Смешанная модель данных – представление данных с одновременным использованием реляционной и многомерной модели данных. Используется в разрабатываемой системе для повышения эффективности обработки и анализа информации.
Хранилище данных – предметно-ориентированное, привязанное ко времени, пополняемое, но не изменяемое собрание данных для поддержки принятия управленческих решений. Данные в хранилище попадают из оперативных информационных систем, которые предназначены для автоматизации бизнес-процессов. Хранилище пополняется за счет внешних источников, например, статистических и финансово-экономических отчетов.
Витрина данных – подмножество хранилища данных ограниченного объема, используемое для построения некоторого заданного класса OLAP-моделей. В данной работе под витриной данных понимается набор взаимосвязанных таблиц, характеризующих исследуемый показатель или процесс, а также построенные на их основе аналитические объекты.
Аналитические объекты – набор аналитических показателей и измерений, образующих многомерный информационный куб. Синонимом данного понятия является понятие бизнес-объекты, или информационные объекты.
Аналитический показатель – показатель, значения которого представляются в пространстве многомерного информационного куба и доступны для анализа, как в абсолютном, так и в агрегированном виде.
Измерение – характеристика/шкала аналитических показателей. Измерения можно рассматривать как разные типы осей информационного куба: числовые, порядковые, качественные и др., значения которых характеризуют анализируемые показатели.
Фильтр – набор условий для выбора информации.
Операция агрегирования – операция вычисления относительных показателей из абсолютных, а также вычисления сумм, средних значений, максимальных и минимальных значений и др.
Таблица фактов – основной элемент OLAP-анализа; таблица, содержащая фактологическую информацию об анализируемой области, с указанием измерений, по которым факты оцениваются. Структура таблицы фактов находится, как правило, во второй нормальной форме.
Таблица агрегатов – содержит агрегированные данные, прошедшие предварительную обработку. Структура аналогична таблице фактов. Таблицы этого типа используются в качестве промежуточных этапов при выполнении сложных расчетов.
Кросс-таблица или перекрестная таблица – плоское отображение многомерного куба. Горизонтальная и вертикальные шапки кросс-таблицы имеют сложную иерархическую структуру представляющую измерения куба. Внутри кросс-таблицы представляются значения показателей. Обычно через кросс-таблицу осуществляется взаимодействие пользователя с многомерным представлением, для его ротации, формирования срезов, группировки и детализации информации, и других операций.
2.1.2 Принципы создания аналитической системы
Как уже отмечалось выше, в основе OLAP лежит идея обработки данных на многомерных структурах. Обычно при использовании термина OLAP подразумевают, что логически структура данных аналитического продукта многомерна. Другое дело, как именно это реализовано. Различают два основных вида аналитической обработки, к которым относят те, или иные продукты.
MOLAP. Собственно многомерная (multidimensional) OLAP. В основе продукта лежит нереляционная структура данных, обеспечивающая многомерное хранение, обработку и представление данных. Соответственно и базы данных называют многомерными. Продукты, относящиеся к этому классу, обычно используют сервер многомерных баз данных. Данные в процессе анализа выбираются исключительно из многомерной структуры. Подобная структура является высокопроизводительной.
ROLAP. Реляционная (relational) OLAP. Как и подразумевается названием, многомерная структура в таких инструментах реализуется реляционными таблицами. А данные в процессе анализа, соответственно, выбираются из реляционной базы данных аналитическим инструментом.
Недостатки и преимущества каждого подхода, в общем-то, очевидны. Многомерная OLAP обеспечивает лучшую производительность, но структуры данных нельзя использовать для обработки больших объемов данных, поскольку большая размерность требует больших аппаратных ресурсов, а вместе с тем разреженность гиперкубов может быть очень высокой и, следовательно, использование аппаратных мощностей не будет оправданным. Реляционная OLAP обеспечивает обработку на больших массивах хранимых данных, так как возможно обеспечение более экономичного хранения, но, вместе с тем, значительно проигрывает многомерной модели в скорости работы.
Подобные рассуждения привели к выделению нового класса аналитических инструментов – HOLAP. Это гибридная (hybrid) оперативная аналитическая обработка. Инструменты этого класса позволяют сочетать оба подхода – реляционного и многомерного. Доступ может вестись как к данным многомерных баз, так и к данным реляционных.
Наряду с серверной аналитической обработкой существует вид аналитической обработки на клиенте – DOLAP или «настольный» (desktop). Основное его отличие состоит в том, что создание многомерных структур происходит в оперативной памяти клиентского компьютера. В связи с этим DOLAP используют для обработки меньших информационных массивов.
OLAP-функциональность аналитической системы может быть реализована как серверными, так и клиентскими OLAP-средствами. Для выбора модели необходимо провести оценку ряда эксплуатационных характеристик, основными из которых являются объем обрабатываемых данных, скоростные характеристики, требования к аппаратуре и стоимость программного обеспечения [76].
Под объемом обрабатываемых данных понимается совокупность следующих характеристик: количество измерений, количество элементов измерений и количество фактов, а в случае реляционной модели хранения еще и количество таблиц и записей в таблицах. При равной мощности компьютера OLAP-сервер может обрабатывать большие объемы данных, чем Desktop OLAP (OLAP-клиент). Дело в том, что OLAP-клиент должен провести всю цепочку операций по извлечению данных из оперативной базы данных, провести расчет куба, в то время как OLAP-сервер хранит заранее вычисленные кубы и агрегаты по наиболее запрашиваемым срезам. Кроме того, OLAP-сервер обладает различные методами оптимизации производительности, среди которых кэширование запросов, параллельная обработка, предварительные вычисления и ряд других.
Клиентское программное обеспечение OLAP-сервера в момент выполнения OLAP-операций выполняет запросы к серверу на языке многомерных запросов (например, MDX), получая часть рассчитанного сервером куба, необходимую для отображения пользователю. Desktop OLAP в момент работы должен иметь в оперативной памяти весь куб. В случае работы с реляционной базой данных необходимо предварительно загрузить в память весь используемый для вычисления куба массив данных. Кроме того, при увеличении числа измерений, фактов или элементов измерений количество агрегатов растет в геометрической прогрессии. Таким образом, объем данных, обрабатываемых OLAP-клиентом, находится в прямой зависимости от объема оперативной памяти компьютера пользователя.
Тем не менее, большинство настольных OLAP-систем используют потенциал сервера базы данных для выполнения предварительного агрегирования фактов. Desktop OLAP-клиент формирует запрос к СУБД, в котором описываются условия фильтрации и алгоритм предварительной группировки первичных данных. Сервер возвращает компактную выборку для дальнейших OLAP-вычислений, размер которой может быть в десятки-сотни раз меньше объема первичных записей. Следовательно, потребность такого OLAP-клиента в ресурсах компьютера существенно снижается.
Кроме того, при оценке объема данных следует учитывать ограниченные возможности человеческого восприятия. Приводятся разные оценки среднего количества измерений, которыми может одновременно оперировать человек. Эта цифра лежит в пределах 5-8 измерений. Согласно требованиями, сформулированным Коддом [6] лишь небольшое число приложений нуждаются в более чем 10-ти измерениях.
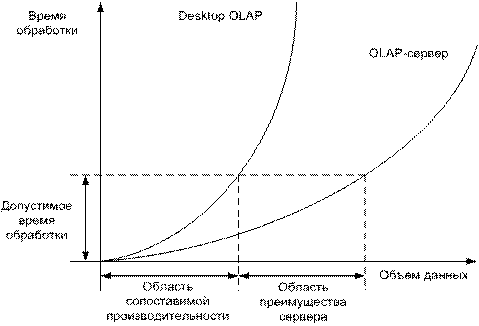
Рисунок 2 – Зависимость производительности от объема данных
Для оценки скоростных характеристик часто используется понятие производительности системы. В нашем случае под производительностью понимается объем обрабатываемых данных за единицу времени. Рост объемов данных снижает производительность как Desktop OLAP решений, так и OLAP-серверов, однако скорость снижения производительности у этих решений разная (рисунок 2).
Основной выигрыш OLAP-сервера достигается за счет работы с заранее рассчитанными кубами, в то время как на любой запрос Desktop OLAP-система должна выполнить весь путь расчета куба и только после этого предоставить результат. Важным параметром при оценке подходов является допустимое время обработки данных. Обычно считается, что обработка данных, требующая более пяти секунд, является недопустимой. Эта цифра связана с особенностями мыслительного процесса человека и составляет время одной транзакции. Более чем пятисекундные задержки получения результата приводят к потере живого интереса к выполняемому анализу.
Скоростные характеристики системы зависят не только от объема обрабатываемых данных, но также и от параметров используемого оборудования. В Desktop OLAP рост объемов данных ограничен количеством оперативной памяти пользовательского компьютера. Тем не менее, при большом количестве пользователей Desktop OLAP-решения используют мощности пользовательских компьютеров, в то время как серверное решение направит все запросы на один компьютер, вычислительные мощности которого тоже не бесконечны.
Не менее важным параметром оценки подходов является стоимость оборудования и программного обеспечения, требуемого для реализации аналитических задач. Если круг потенциальных пользователей лежит в пределах одной локальной сети, то более рациональным вариантом будет приобретение аппаратного и программного обеспечения для реализации OLAP-серверного подхода. Если же пользователи сильно распределены по большой территории (например, по области или краю), не имеют общей сетевой инфраструктуры, то единственным вариантом является использование Desktop OLAP решений.
Таким образом, если объемы обрабатываемых данных лежат в области сопоставимой производительности серверных и несерверных OLAP-систем, то при прочих равных условиях, экономически целесообразно будет использование Desktop OLAP-системы.
В случае использования, например, в системе здравоохранения пользователи, заинтересованные в решении аналитических задач, находятся как в органах управления, так и в медицинских учреждениях, расположенных в разных районах региона. Для реализации в разветвленной сети медицинских учреждений подхода с использованием OLAP-сервера, для каждого отдаленного учреждения необходимо приобретение программного обеспечения, требующего, помимо серьезной аппаратной платформы, постоянного администрирования (то есть дополнительного высококвалифицированного сотрудника). Таким образом, использование Desktop OLAP-системы является единственным возможным в данной структуре подходом построения аналитической системы. То же можно сказать и о других территориально-отраслевых структурах.
2.1.3 Архитектура и функционирование OLAP-машины
Ядром любой системы оперативной аналитической обработки данных является так называемая OLAP-машина, которая представляет собой механизм выполнения запросов пользователя на выборку многомерной информации и изменения ее представления.
От архитектуры OLAP-машины зависит и уровень решаемых аналитическим инструментом задач и степень свободы пользователя при решении этих задач. В случае использования OLAP-серверов, уровень свободы пользователя обычно ограничен заранее определенными и рассчитанными измерениями и показателями, но в тоже время пользователь получает более быстрый инструмент, позволяющий обрабатывать огромные информационные массивы.
Настольные OLAP-системы, в отличие от серверных, не связаны заранее рассчитанными многомерными структурами и в силу этого обстоятельства обладают большими возможностями для поддержки нерегламентированного анализа информации. Гибкость аналитического инструмента достигается путем включения механизма выполнения произвольных запросов (ad-hoc queries) в процесс OLAP-анализа информации.
На рисунке 3 схематично представлен процесс функционирования разработанной OLAP-машины. Поданный на вход OLAP-запрос проходит четыре уровня обработки прежде чем он будет представлен пользователю.
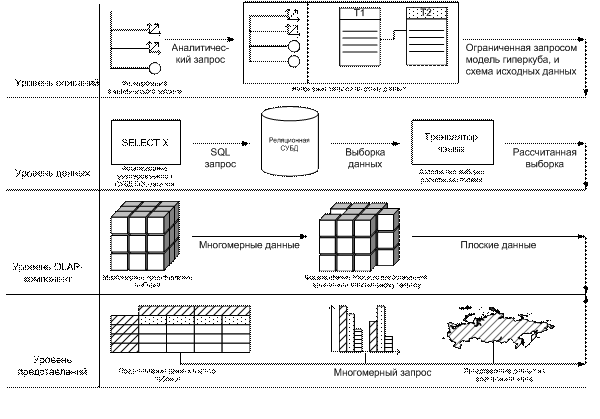
Рисунок 3 – Архитектура OLAP-машины
На первом уровне, который назван уровнем описаний, производится сбор описательной информации. В эту информацию включен сам запрос, то есть перечень интересующих пользователя аналитических объектов – измерений и показателей, схема данных, на которой эти аналитические объекты определены, а также функции определяющие измерения и показатели.
Собранная на первом уровне информация поступает на уровень данных OLAP-машины, в задачу которого входит получение линейного массива данных. Для этих целей на основе описательной информации OLAP-машина формирует, адекватный используемой СУБД, SQL-запрос. Несмотря на наличие стандартов SQL, у каждой СУБД существует свой диалект языка, часто отличающийся как по лексике, так и по синтаксическим конструкциям. В общем случае поддержка очередной СУБД требует модификации блока генерации SQL-запросов. После исполнения запроса СУБД в OLAP-машину поступает выборка данных, которая при необходимости дополняется расчетными элементами. Для выполнения расчета используется встроенный в OLAP-машину интерпретатор языка программирования. Наличие интерпретатора обеспечивает гибкость в определении измерений и показателей, а также практически полную независимость от функциональности конкретной СУБД.
На третьем уровне линейный массив данных загружается в многомерную структуру, которая в свою очередь обеспечивает выполнение OLAP-операций и формирования плоского OLAP-представления для отображения пользователю. Более подробно про работу OLAP-компонент написано в пункте 2.1.4.
Уровень представлений обеспечивает отображение информации и взаимодействие с пользователем. Посредством конкретного представления пользователь получает возможность воздействия на OLAP-машину для выполнения операций над многомерным массивом данных.
Разработанная OLAP-машина за счет использования встроенного генератора SQL-запросов поддерживает выполнение нерегламентированных запросов пользователя, а наличие интерпретатора языка программирования позволяет использовать как встроенные, так и собственные функции для расчета аналитических объектов.
2.1.4 Реализация OLAP-компонент
Центральным звеном OLAP-машины являются OLAP-компоненты, представляющие собой скрытый от пользователя механизм выполнения операций над многомерным массивом данных [6,7]. Взаимодействие пользователя с OLAP-компонентами осуществляется через специальные интерфейсные элементы – кросс-таблицу и кросс-диаграмму, которые являются табличным и графическим отображением многомерного куба.
Основными OLAP-операциями являются:
– Создание и загрузка многомерных структур;
– Создание и загрузка иерархических структур;
– Работа с измерениями:
o обработка иерархических измерений,
o изменение структуры измерений (изменение позиции как внутри, так и между осями куба, включение и исключение измерений),
o детализация и группировка значений измерений,
o сортировка и фильтрация значений измерений,
o построение сложных шапок (осей куба);
– Работа с показателями
o агрегация показателей,
o расчет вычисляемых показателей.
Представленные ниже IDEF0–диаграммы описывают основные процессы, происходящие внутри OLAP-компонент.
На диаграмме «Обработка OLAP-запросов» (рисунок 4) представлены основные составляющие процесса функционирования OLAP-компонент. Функциональную диаграмму составляют следующие блоки: создание многомерных структур, построение иерархий, построение осей (шапок), расчет фактов.
Диаграмма описывает процесс создания специальных структур для загрузки линейных данных из оперативных баз данных и их последующей обработки для получения готового визуального представления, с использованием OLAP-компонент и соблюдением требований, предъявляемых пользователями.
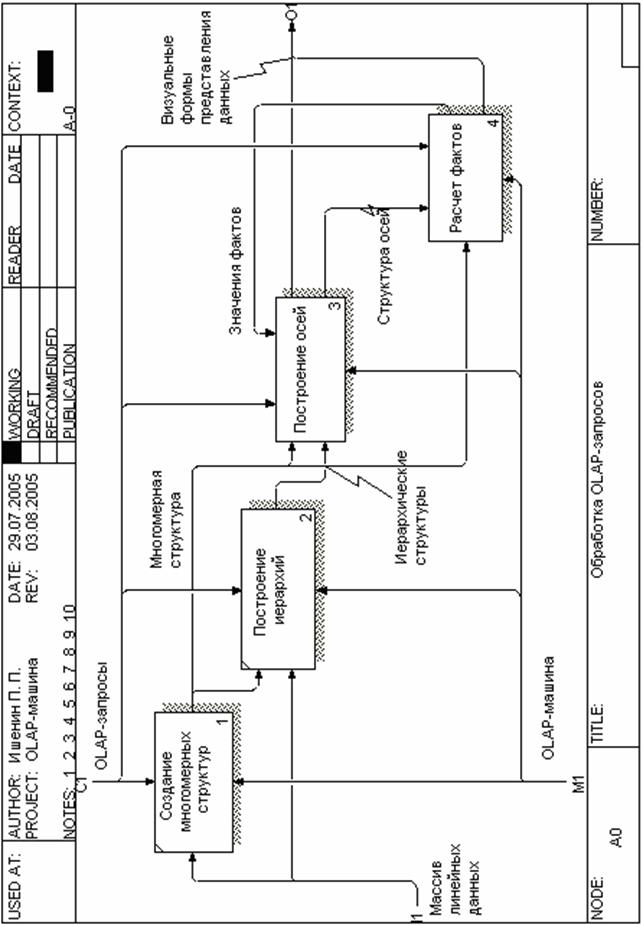

Рисунок 4 – Обработка OLAP-запросов
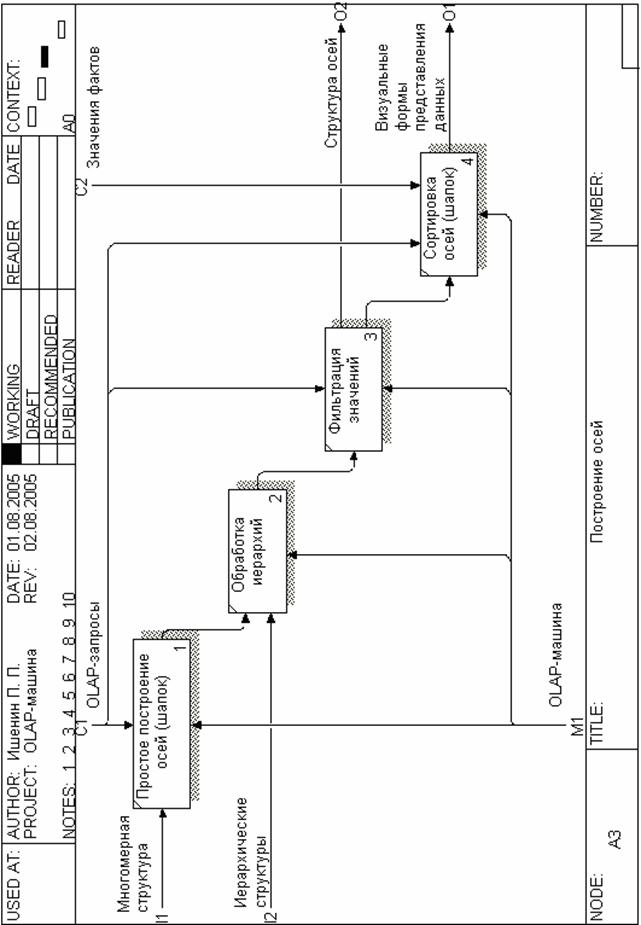

Рисунок 5 – Построение осей
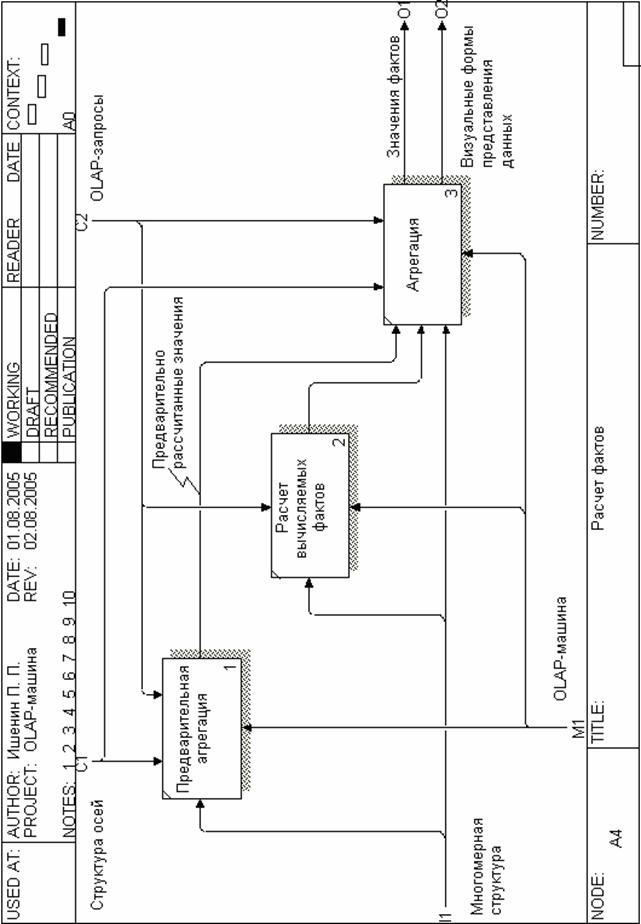

Рисунок 6 – Расчет фактов
На вход системы подаются линейные данные, находящиеся в базах данных различных программных продуктов. В качестве управляющего воздействия используются основные положения OLAP-технологии и требования пользователя, выражающиеся в виде OLAP-запроса. В качестве механизма рассматриваются OLAP-компоненты. На выходе системы образуется информация, принимающая специализированную форму, предназначенную для визуального представления.
Следующие диаграммы (рисунки 5 и 6) представляют декомпозицию первой диаграммы и описывают подробности выполнения некоторых функций высокого уровня. Более детальное рассмотрение процесса создания многомерных структур дается в этом пункте ниже, а процесс построения иерархий подробно описывается в следующем пункте.
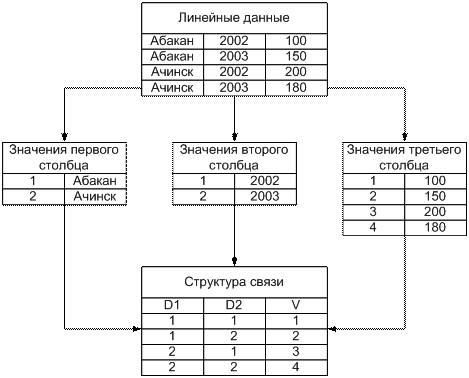
Рисунок 7 – Трансформация линейных данных
при загрузке в OLAP-компоненты
Процесс создания многомерных структур необходим для трансформации линейного массива данных в специальное представление, повышающее скорость выполнение основных многомерных операций [10]. Поскольку при построении осей, при фильтрации и сортировке измерений необходимо обрабатывать списки уникальных значений, на этапе загрузки данных требуется создать структуры, оптимальные для работы с этими списками. Таким образом, вместо линейного представления со значениями внутри ячеек внутреннее представление предполагает построение списков уникальных значений и структуры, связывающей эти уникальные значения. Схематично это представлено на рисунке 7.
Так как при реализации OLAP-компонент основными требованиями являются быстродействие и низкие затраты памяти, выбор структур и алгоритмов заполнения списков уникальных значений является довольно сложной задачей. Структура для такого списка должна поддерживать максимально быстрое выполнение операций вставки, поиска значений списка, а также получения значения по номеру.
В связи с этим возникла необходимость поиска такой структуры. В результате проведенного тестирования ряда структур было выявлено, что применение сортированного двумерного хеш-массива позволяет добиться максимального быстродействия при относительно небольших затратах памяти. Быстрое выполнение операции вставки осуществляется за счет применения хеширования значений. Значения хеш-функций позволяют разделить исходные данные на группы, внутри которых и производятся операции поиска и вставки. За счет меньшего количества элементов (часть элементов попадает в другие группы) существенно упрощается поиск места вставляемого элемента и соответственно временные затраты на саму операцию вставки.
2.1.5 Иерархии и измерения на основе иерархий
Одной из основ OLAP-анализа является работа с иерархическими измерениями, в основе которых лежат иерархии. Понятию дерева и иерархии дается определение в теории графов – области математики, оперирующей абстрактными структурами – графами. Граф G = (V, E) можно определить как совокупность двух множеств – множества точек V (узлов, вершин) и множества линий E (ребер), соединяющих узлы. Ребра моделируют некоторый вид потоков или отношений. Ребра могут быть ненаправленные или направленные (дуги) [30].
Деревом называется связный граф T=(V, E), не содержащий циклов. Связный граф – это граф, в котором существует путь между любыми двумя вершинами.
Дерево обладает рядом свойств:
1. Каждый узел является корнем поддерева. Тривиальным случаем является поддерево только с одним узлом.
2. Каждые два узла соединены в дереве одним (и только одним) путем.
3. Дерево – это связный граф, который имеет ребер на одно меньше, чем узлов.
Если в дереве удалить одно ребро (a, b), то в результате получится «лес» из двух несвязных деревьев: одно дерево содержит узел «a», а другое содержит узел «b».
Иерархия представляется ориентированным деревом с дополнительными свойствами: подчиненностью и наследованием. Традиционным применением иерархий являются организационные диаграммы. В организационной диаграмме полномочия проистекают из корневого узла (президента компании, главнокомандующего армией) вниз по иерархии. Причем в случае удаления ребра иерархия не распадается на две несвязанных иерархии (как это было бы с деревом), а за счет наследования сохраняет целостное состояние. Другой особенностью иерархий является то, что один и тот же узел может играть много разных ролей – так в организационной диаграмме один человек может занимать несколько разных должностей [3, 4, 5, 17, 9].
В OLAP-технологии, как и в технологии баз данных, иерархии используются для упорядочения справочно-классификационной информации. В технологии оперативной аналитической обработки наряду с традиционными измерениями, состоящими из одного уровня, используются иерархические (многоуровневые) измерения. Наиболее часто используются временная, организационная и географическая иерархии.
Работа с иерархиями как элементами OLAP-анализа не является новой. Например, в продуктах Microsoft Analysis Services [http://www. /sql/default. mspx] и Oracle Business Intelligence 10g [http://www. /solutions/business_intelligence/index. html] поддерживается создание и использование иерархических измерений, построенных на основе моделей «код/родитель» и составной иерархии. Что касается настольных OLAP-приложений и компонент, то работа с иерархическими измерениями возможна в приложениях, использующих OLAP-решения фирмы Microsoft (Microsoft Pivot Table) и Radar software [http://www. /] (HierCube). Кроме того, работа с иерархическими измерениями возможна в клиентских программах крупных OLAP-разработчиков – Cognos [http://www. ], Proclatity [http://www. ], Business Objects [56] и ряда других.
Существует ряд общепринятых моделей хранения иерархий, как и иерархических измерений, в базах данных [44, 29, 68, 40, 11]. Конечно, можно было бы использовать традиционные для графов матрицы смежности и инцидентности, но данные структуры не обладают компактностью хранения, ссылочной целостностью, а также удобством работы.
Рассмотрим модели иерархий, использующие для организации упорядоченной структуры данных таблицы справочников. Под справочником в данной работе понимается совокупность стандартизованных значений определенного признака информационного объекта. Справочники в OLAP-технологии обычно используются в качестве средства представления аналитических измерений.
Традиционной схемой представления иерархических данных является структура «код/родитель», представляющая собой расширение справочной структуры дополнительным полем ссылки на код предка. Область применения такого рода иерархий – упорядочение однотипных сущностей: географических названий, сотрудников организации, отраслевых учреждений и др.


Рисунок 8 – Модель «код/родитель»
Модель «код/родитель» (рисунок 8) имеет ряд ограничений: в подчинении используются значения только одного справочника, отсутствует возможность использования одного значения справочника в разных узлах иерархии и др. Поэтому в данной работе кроме модели «код/родитель» используются другие структуры.
Для организации подчинений между разными сущностями применяется модель «составной» иерархии, состоящей из несколько справочников, объединенных либо через ссылки, расположенные в справочных таблицах (рисунок 9), либо через специализированную таблицу связи, называемую оглавлением (рисунок 10).
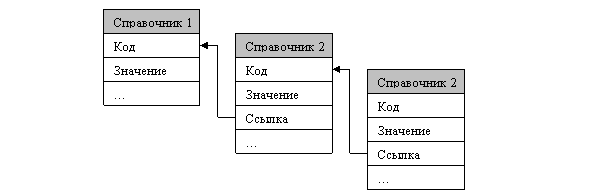

Рисунок 9 – Модель составной иерархии со ссылками внутри справочников


Рисунок 10 – Модель составной иерархии с применением оглавления
Составная иерархия позволяет избежать ограничения модели «код/родитель», включающей только один справочник, однако данный тип иерархии также обладает рядом ограничений – количество уровней вложенности ограничено количеством справочников и значения одного справочника могут располагаться только на одном определенном уровне дерева иерархии.
В Институте вычислительного моделирования СО РАН разработана модель составной иерархии со «сложным оглавлением» (рисунок 11), являющаяся расширением «составной» иерархии с применением оглавления [52, 53]. Иерархическая структура, построенная с использованием сложного оглавления, не имеет ограничений на количество уровней вложенности и позволяет размещать элементы справочников в любых узлах дерева.


Рисунок 11 – Модель иерархии с применением сложного оглавления
Особенностью модели сложного оглавления является вынос иерархических зависимостей в отдельную таблицу и установление для каждого узла дерева ссылки на один из справочников.
Использование иерархий (в том числе составной иерархии с применением сложного оглавления) в качестве измерений многомерного куба потребовало применения специальных структур данных и алгоритмов, направленных в первую очередь на уменьшение временных затрат. Самым узким местом при построении иерархий является загрузка исходных данных, поскольку они поступают из СУБД, проходя через множество интерфейсов и протоколов, в том числе сетевого обмена. Отсюда наиболее оправданным оказалось решение однопроходной загрузки данных из СУБД в динамический массив и дальнейшее построение на основе массива древовидной структуры. Также существенным моментом при построении деревьев является невозможность использования традиционных рекурсивных алгоритмов обхода деревьев из-за возможности существования иерархий с большим уровнем вложенности.
Структура узла иерархии содержит следующие поля:
Code | – код узла иерархии, |
Parent | – ссылка на родительский узел, |
Value | – значение узла иерархии (обычно строковое), |
LevelIndex | – индекс внутри уровня, |
TotalIndex | – индекс внутри массива, |
Level | – уровень, на котором расположен узел, |
FirstChildIndex | – индекс первого потомка данного узла, |
… | – набор дополнительных характеристик. |
Для хранения дерева иерархии была использована структура двумерного динамического массива, первым измерением которого является уровень вложенности.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
