

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рассмотрим предварительно сложность вспомогательной функции Find, вызываемой на шагах 12 и 29. Функция Find выполняет поиск делением пополам в заданном диапазоне, следовательно, сложность Find составляет O(N). Внутри главного цикла (шаги также присутствуют операторы перехода, приводящие к повтору некоторого числа шагов, причем максимальным числом повторов является количество уровней в иерархии – 1. Таким образом, сложность цикла составляет O(NЧисло уровней). Во второй части алгоритма максимальную сложность составляет цикл, представленный пунктами 45-55. Внутри цикла на шаге 51 вызывается вспомогательная функция SortLevel, использующая для сортировки алгоритм quicksort сложность которого составляет O(NlogN). Таким образом, сложность указанного цикла составляет O(N2logN). Общая сложность всего алгоритма в таком случае составляет O(NЧисло уровней).
Работа с разными моделями иерархий на практике отличается на этапе построения массива исходных данных. Таким образом, для программной реализации разных моделей хорошо подошел объектно-ориентированный подход, который позволил общую часть, касающуюся построения дерева и дальнейшие операции над ним поместить в базовый класс, а части, касающиеся заполнения массива исходных данных, разместить в классах-наследниках.
Реализация классов для работы с иерархиями позволила повторно использовать программный код в смежных продуктах: системе ведения справочников, менеджере хранилища данных [53], а также системе сбора статистической отчетности [50]. Ни один из представленных на рынке продуктов не обладает возможностью работы со структурой составной иерархии со сложным оглавлением. Возможность использования сложного оглавления позволяет естественным образом упорядочить значения измерений. Например, многоуровневый справочник медицинских учреждений может использоваться в качестве измерения при анализе объемов и видов медицинской помощи в территориях региона.
К сожалению, нет возможности сравнения производительности алгоритмов построения и использования иерархических измерений, поскольку в существующих системах они являются неотделяемыми от OLAP-продукта.
2.1.6 OLAP-модели и операции над ними
Процесс решения некоторой аналитической задачи заключается в определении исходных данных, проведении расчетов над этими данными, проведении аналитического эксперимента и в представлении результатов.
OLAP-модель в данной работе описывает процесс решения некоторой аналитической задачи на основе построения многомерного куба.
Рассмотрим формализацию основных понятий и операций для многомерной организации данных [42, 82, 31].
OLAP-модель M представляется в виде:
M=<X, G, Ψ(X, G), Q(G), P, O(G)>.
Здесь X – дискретное множество входных данных;
G=<Z, F> – гиперкуб – модель логического многомерного представления данных, характеризующаяся двумя наборами параметров: показателями и измерениями;
Z=<z1, z2, …,zm> – показатели гиперкуба: каждый показатель представляет собой множество значений, количественно характеризующих анализируемый процесс;
F=< f1, f2, …,fn > – измерения гиперкуба: каждое измерение представляет собой упорядоченное множество значений определенного типа. Измерения могут быть организованы в виде упорядоченной иерархической структуры. Множество измерений образует оси гиперкуба:
![]()
![]()
…………………………
![]() .
.
Ψ(X, G) – функции, описывающие построение элементов гиперкуба G: показателей Z и измерений F, исходя из множества входных данных Х.
Q(G) – операции над гиперкубом:
Q=< C(G, φ(Z, m(fi))), S(G, fi’), D(G, f1’…. fn’), R(G)>, где:
C(G, φ(Z, m(fi))) – агрегирование гиперкуба по иерархии атрибутов выбранного измерения. Агрегирование гиперкуба G – это преобразование G к гиперкубу меньшей мощности за счет агрегирования показателей φ(Z, m(fi)) с учетом отношения иерархической зависимости m(fi) атрибутов измерения fi. В качестве функции φ агрегирования показателей могут выступать, например, min, мах, сумма и др.
S(G, fi’) – срез гиперкуба G по измерению fi – операция получения подмножества гиперкуба в результате фиксации подмножества значений fi’ измерения fi: S(G, fi’) = <Z, F çfi’Í fi >.
D(G, f1’,...,fn’) – срез гиперкуба G по измерениям f1,...,fn – операция получения подмножества гиперкуба в результате фиксации
подмножеств значений f1’,...,fn’ измерений f1,...,fn соответственно:
D(G, f1’,...,fn’) = <Z, F çf1’Í f1,...,fn’Ífn >.
R(G) – операция поворота гиперкуба, которая изменяет порядок измерений в гиперкубе.
P=<T, K, L, M, γ(T, K, L, M)> – модель логического представления результатов вычисления OLAP-модели.
Она включает формы представления результатов модели: T – таблицы, K – кросс-таблицы, L – диаграммы, M – картограммы и γ(T, K, L, M) – операции над ними:
γ(T) Î {фильтрация, сортировка},
γ(K) Î {перемещение, ротация строк и столбцов таблицы, фильтрация, сортировка},
γ(L) Î {группировка данных, сортировка, разбиение на сегменты},
γ(L) Î {фильтрация}.
Фильтрация представляет собой ограничение выборки данных по условию или набору условий. Сортировка – условие, определяющее упорядочение выборки данных.
Перемещение строк и столбцов таблицы – операция изменения местоположения строк и столбцов. Ротация строк и столбцов представляет собой перенос строк и столбцов таблицы из горизонтальной шапки таблицы в вертикальную и наоборот.
Группировка данных диаграммы доступна в диаграмме кругового типа, операция предназначена для суммирования всех элементов, чья доля меньше или больше, чем заданное значение. Сортировка диаграммы предназначена для выявления наибольших и наименьших значений. Разбиение на сегменты для разбиения значений диаграммы на "большие чем" и "меньшие чем".
O(G) = <D, α(D)> – операция по сохранению гиперкуба в таблицу агрегатов. Операция применяется к одному из следующих видов представления:
D = <T, K>, где T – данные в табличном виде, K – данные в виде кросс-таблицы.
α(D) Î {преобразование наименований в код, наложение внешних ключей, удаление таблицы агрегатов перед вставкой данных} – операции по трансформации таблицы агрегатов.
К характеристикам OLAP-модели относятся: мощность измерения, мощность, размерность и объем гиперкуба. Количество элементов измерения есть мощность измерения. Мощность гиперкуба – произведение мощностей его измерений:
p= k1*k2*…*kn,
где k1,…, kn – мощности измерений f1,…,fn соответственно.
Число измерений гиперкуба определяет размерность гиперкуба.
Объемом гиперкуба будем называть мощность куба, умноженную на количество определенных для него показателей:
V= k1*k2*…*kn*m.
Аналитический эксперимент A(M) – последовательность операций, осуществляемых с помощью модели с целью определения, прогноза тех или иных состояний модели, анализа реакции на изменения элементов OLAP-модели, изменения исходных данных, расширения функционального состава задачи.
2.1.7 Комплексы OLAP-моделей
Решение сложных аналитических задач часто не может быть положено в структуру одной OLAP-модели. Задача предварительно декомпозируется на составные части – подзадачи, таким образом, чтобы каждая подзадача могла быть представлена аналитической моделью [31]. Каждая OLAP-модель в свою очередь решает отдельную подзадачу и сохраняет результаты расчетов в специализированную таблицу агрегатов. Выполняясь последовательно, OLAP-модели могут в качестве исходных данных получать результаты расчетов предыдущих моделей. Таким образом образуется комплекс OLAP-моделей, а их взаимосвязь реализуется через наследование информации.
Комплексы OLAP-моделей удобно записывать в виде программы на языке высокого уровня, при этом каждая OLAP-модель будет представлять набор действий, заключенных в языковую процедуру. При такой структуре комплексов моделей легко производить замену одного расчета другим, или осуществлять диалог с пользователем для выбора вариантов расчета.
Представленная на рисунке 13 IDEF0–диаграмма описывает основные процессы, проходящие при построении комплекса OLAP-моделей.
На диаграмме «Построение комплексов OLAP-моделей» представлены основные составляющие процесса создания комплекса OLAP-моделей. Функциональную диаграмму составляют следующие блоки:
- Определение источников информации;
- Создание витрин данных;
- Создание OLAP-моделей;
- Формирование программы комплекса.
Диаграмма описывает процесс преобразования сведений из оперативных баз данных и информации о предметной области в комплекс OLAP-моделей, выполняемый средствами OLAP-системы с соблюдением требований пользователей.
На вход подается исходная информация из оперативных баз данных. В качестве управляющего воздействия задействуются требования пользователей системы к составу информации. В качестве механизма выполнения рассматривается программное обеспечение OLAP-анализа. На выходе образуются комплексы OLAP-моделей, предназначенные для последующего аналитического эксперимента.
Выполнение комплексов OLAP-моделей схематично представлено на рисунке 12. На первом шаге в аналитический инструмент поступают исходные данные, которые обрабатывает «Модель 1». Далее идет последовательное выполнение шагов расчета, параметры которых записаны в виде OLAP-моделей.
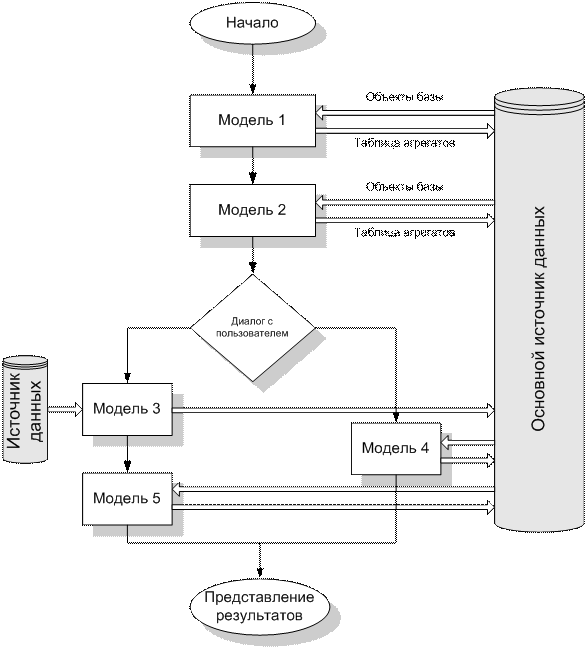
Рисунок 12 – Пример выполнения комплекса OLAP-моделей
Взаимодействие OLAP-моделей между собой происходит путем передачи через источник данных информации в виде таблиц агрегатов и данных репозитария этого источника. Следует обратить внимание на два момента. Во-первых, данный пример демонстрирует возможность совмещения информации из разных источников информации («модель 3» получает информацию из своего источника, но помещает результат расчета – в общий).
Во-вторых, пример демонстрирует возможность сделать расчет интерактивным за счет внесения блоков диалога с пользователем. Это добавляет удобства при существовании нескольких алгоритмов расчета, когда в зависимости от некоторых обстоятельств, или для сравнения результатов необходимо выбирать ту, или иную схему расчета.
Кроме того, выполнение комплекса OLAP-моделей сопровождается так называемым интерактивным аналитическим экспериментом, т. е. возможно вмешательство пользователя в выполнение расчета для модификации параметров и настройки любой модели.
В работе впервые введен новый технологический элемент OLAP-анализа. Таблица агрегатов – модифицируемый промежуточный результат сложных аналитических расчетов, выполняемых с помощью OLAP-инструмента. Для классических систем оперативной аналитической обработки данных не свойственна обратная запись в источник информации, но для сложных, многошаговых аналитических задач потребовалось обеспечение записи промежуточных результатов и их последующего использования.
Создание таблиц агрегатов, а следовательно, и само выполнение комплексов OLAP-моделей было бы не возможно без средств интеграции аналитической системы со специальными источниками информации. К таким источникам относятся базы данных системы сбора статистической отчетности [50] и системы обработки и хранения данных [53]. Указанные системы поддерживают создание и управление необходимых для многошаговых расчетов таблиц агрегатов.


Рисунок 13 – Процесс построения комплекса OLAP-моделей2.2 Языковые средства в оперативной аналитической обработке
2.2.1 Основные принципы и определения
Существенное расширение возможностей практически любой системы может быть достигнуто за счет применения языковых средств. В современном программном обеспечении скрипты (программы на встроенном в продукте языке программирования) часто используются для выполнения макросов и осуществления диалога с пользователем. Рынок программных продуктов предлагает множество решений для интеграции языковых средств в разрабатываемые системы. Одной из наиболее популярных интегрируемых языковых оболочек является Windows Script, позволяющей интегрировать в программный продукт языки Microsoft Visual Basic и Microsoft Jscript [http://msdn. /scripting/default. asp]. Пакет позволяет встроить и средства интерпретации, и средства отладки программ на указанных языках. Существуют также встраиваемые интерпретаторы языков Pascal – Pascal Script [http://www. /page. asp? id={9A30A672-62C8-4131-BA89-EEBBE7E302E6}], C, Python [http:///Products. aspx? ProductID =3] и ряд других.
Тем не менее, требования реализации многошагового OLAP-анализа и возможности реализации сложных аналитических алгоритмов потребовали создания собственных языковых средств. Основным назначением разработанных в данной диссертационной работе языковых средств является создание и выполнение сложных аналитических расчетов, требующих написания алгоритмов с ветвлениями и циклами, а также использованием математических, строковых и других функций. Кроме аналитических вычислений языковые средства необходимы и для осуществления диалога с пользователем в процессе выполнения алгоритма расчета аналитического комплекса. Следующим моментом использования языковых средств стало их применение в задачах построения адаптированных пользовательских интерфейсов, а именно для обработки событий и осуществления взаимодействия между элементами интерфейса.
Основной особенностью разработанного языка программирования высокого уровня является его ориентация на задачи оперативной аналитической обработки, а также полностью русская лексика и синтаксис.
Основные термины технологии формальных языков и трансляторов [69, 28]
Транслятор – обслуживающая программа, преобразующая исходную программу, предоставленную на входном языке программирования, в рабочую программу, представленную на объектном языке.
Интерпретатор – программа или устройство, осуществляющее пооператорную трансляцию и выполнение исходной программы. В отличие от компилятора, интерпретатор не порождает на выходе программу на машинном языке. Распознав команду исходного языка, он тут же выполняет ее.
Компилятор – это обслуживающая программа, выполняющая трансляцию на машинный язык программы, записанной на исходном языке программирования.
Синтаксис – совокупность правил некоторого языка, определяющих формирование его элементов. Иначе говоря, это совокупность правил образования семантически значимых последовательностей символов в данном языке.
Семантика – правила и условия, определяющие отношения между элементами языка и их смысловыми значениями, а также интерпретацию содержательного значения синтаксических конструкций языка.
Синтаксический анализатор – компонента транслятора, осуществляющая проверку исходных операторов на соответствие синтаксическим правилам и семантике данного языка программирования.
2.2.2 Структура и синтаксис языка
Рассматриваемый в данной работе язык является процедурным языком программирования, специально разработанным с учетом его использования как профессиональными программистами, так и специалистами предметной области. Одной из особенностей языка является то, что все операторы и встроенные процедуры/функции языка имеют русское написание.
Набор синтаксических конструкций языка позволяет строить достаточно сложные программы. Наряду с базовыми элементами, такими как операторы циклов, переходов, условия, в языке поддерживаются более сложные конструкции, позволяющие заключать фрагменты кода в процедуры и функции. В синтаксисе языка нет блочного оператора, однако его отсутствие компенсируется тем, что конструкции процедуры, функции, циклов и условия по своей структуре являются блочными. Язык обладает некоторыми объектно-ориентированными возможностями, например, правила доступа к свойствам и методам встроенных агрегатных типов данных подобны тем, что используются в объектно-ориентированных языках. Однако агрегатные типы данных не могут определяться средствами самого языка, а жестко определены в системе.
В языке нет явного назначения типа данных для переменной, то есть тип переменной определяется значением, которое она содержит. Например, при выполнении операции присваивания переменная автоматически приобретает тип аргумента. Кроме того, в языке не требуется явного описания переменных. Переменная создается при выполнении прямого (с помощью операции присваивания), или косвенного (в операторе цикла «для») присваивания ей значения аргумента. Отсутствие явного задания переменной и указания ее типа значительно упрощает работу с языком для рядовых пользователей.
Процесс интерпретации конструкций языка, реализованный в данной работе, производится в три фазы. Лексический анализ является первой фазой интерпретации и служит для группировки исходного потока символов программы в набор лексем. Для реализации лексического анализа была использована модель непрямого лексического анализатора [70, 28]. Во второй фазе синтаксический анализатор получает цепочку лексем и на ее основе осуществляет разбор, используя соответствующие правила. По ходу выполнения разбора синтаксический анализатор формирует взаимосвязанный список инструкций и операндов и строит таблицу имен. Построенные конструкции не имеют привязки к синтаксису языка и готовы к исполнению.
Лексический анализатор в процессе своей работы распознает следующие конструкции языка. Здесь и далее синтаксические конструкции языка описаны при помощи расширенных Бэкуса-Наура форм (РБНФ) [71].
<буква> | ::= | 'A'|'B'|..|'Y'|'Z'|'a'|'b'|..|'y'|'z'|'А'|'Б'|..|'Ю'|'Я'| 'а'|'б'|..|'ю'|'я'. |
<цифра> | ::= | '0'|'1'|'2'|'3'|'4'|'5'|'6'|'7'|'8'|'9'. |
<идентификатор> | ::= | (буква|'_'){буква|цифра|'_'}|'['{символ}']'. |
<число> | ::= | целое | действительное. |
<целое> | ::= | двоичное | восьмеричное | десятичное | шестнадцатеричное. |
<двоичное> | ::= | '2#' {/ '0' | '1' /}. |
<восьмеричное> | ::= | '8#' {/ '0'|'1'|'2'|'3'|'4'|'5'|'6'|'7' /}. |
<десятичное> | ::= | ['10#'] {/ цифра /}. |
<шестнадцатеричное> | ::= | '16#' {/ цифра |'A'|'B'|'C'|'D'|'E'|'F'|'a'|'b'|'c'|'d'|'e'|'f' /}. |
<действительное> | ::= | числовая_строка порядок | числовая_строка '.' числовая_строка [порядок]. |
<числовая_строка> | ::= | {/ цифра /}. |
<порядок> | ::= | ("E"|"e")['+'|'-'] числовая_строка |
<пробельный_символ> | ::= | {/ пробел | табуляция | перевод_строки | комментарий /}. |
<комментарий> | ::= | '/*' { символ } '*/' | '//' {символ} перевод_строки. |
<строка> | ::= | '"' { символ } '"'. |
<дата> | ::= | ''' {цифра | '.'} '''. |
<EQ> | ::= | '='. |
<NE> | ::= | '<>'. |
<LT> | ::= | '<'. |
<GT> | ::= | '>'. |
<LE> | ::= | '<='. |
Из приведенного выше описания видно, что в языке существует 4 типа данных для констант: целые, вещественные, строковые и типа «дата». Константы целого типа можно определять в двоичной, восьмеричной, десятичной и шестнадцатеричной системах счисления. Также в языке присутствует возможность определения идентификатора, содержащего пробелы, точки и прочие не входящие в алфавит языка символы, заключая набор символов в квадратные скобки. Подобные отхождения от традиционных правил существенно облегчают написание программ обычными пользователями.
Синтаксический анализатор производит анализ программного кода, используя входные лексемы, получившиеся в результате работы блока лексического анализа. На выходе блок синтаксического анализа формирует объектный код программы, предназначенный для исполнения. Синтаксический анализатор распознает следующие конструкции.
<программа> | ::= | [описание] {процедура | функция} операторы. |
<описание> | ::= | 'ПЕРЕМ' переменная {',' переменная}';'. |
<переменная> | ::= | идентификатор ['['ЦЕЛОЕ']']. |
<процедура> | ::= | 'ПРОЦЕДУРА' идентификатор '(' [{['ЗНАЧ'] идентификатор ['=' выражение]}] {',' ['ЗНАЧ'] идентификатор ['=' выражение]} ')' ['ЭКСПОРТ'] [описание] операторы ['ВОЗВРАТ'] [';' операторы] 'КОНЕЦ'. |
<функция> | ::= | 'ФУНКЦИЯ' идентификатор '(' [{['ЗНАЧ'] идентификатор ['=' выражение]}] {',' ['ЗНАЧ'] идентификатор ['=' выражение]} ')' ['ЭКСПОРТ'] [описание] Операторы 'ВОЗВРАТ' выражение [';' Операторы] 'КОНЕЦ'. |
<операторы> | ::= | оператор {";"оператор}. |
<оператор> | ::= | [метка] пустой | переход | условие | цикл | ЦиклДля | ПРЕРВАТЬ | ПРОДОЛЖИТЬ | присваивание | вызов. |
<метка> | ::= | идентификатор ':' |
<пустой> | ::= | . |
<ЦиклДля> | ::= | 'ДЛЯ' переменная '=' выражение ('ПО'|'ВНИЗПО') выражение 'ЦИКЛ' операторы 'КОНЕЦ'. |
<условие> | ::= | 'ЕСЛИ' выражение 'ТО' операторы { 'ИНАЧЕЕСЛИ' выражение 'ТО' операторы } {'ИНАЧЕ' операторы } 'КОНЕЦ'. |
<переход> | ::= | 'ПЕРЕЙТИ' идентификатор. |
<цикл> | ::= | 'ПОКА' выражение 'ЦИКЛ' операторы 'КОНЕЦ'. |
<вызов> | ::= | идентификатор '(' [выражение] {',' [выражение]} ')'. |
<присваивание> | ::= | переменная '=' выражение. |
<выражение> | ::= | слагаемое { (EQ|NE|LT|GT|LE|GE) слагаемое }. |
<слагаемое> | ::= | множитель { ('+' | '–') множитель }. |
<множитель> | ::= | унарное { ('*' | '/' | '%') унарное }. |
<унарное> | ::= | ['–'] терм. |
<терм> | ::= | переменная | число | строка | дата | '(' выражение ')' | вызов |
Для наглядности синтаксиса языка приведем следующую программу, вычисляющую факториал пяти, используя рекурсивную функцию «факториал».
Функция Факториал(Знач Н)
Если Н <= 1 То
Возврат 1;
Иначе
A = Н*Факториал(Н-1);
Возврат A;
Конец
Конец
А = Факториал(5);
Предупреждение(А);
Выполнение команд является заключительной фазой работы интерпретатора. На входе интерпретатор имеет списки инструкций и операндов. Инструкция в реализованном языке является конструкцией из кода инструкции и трех операндов. Целью работы интерпретатора является проход списка инструкций и их пошаговое выполнение. Интерпретатором языка поддерживаются следующие инструкции, представленные в таблице 2.
Таблица 2 – Инструкции интерпретатора языка
Группа математических инструкций | |
Add | Операция сложения. Результат сложения первых двух операндов помещается в третий операнд. |
Sub | Операция вычитания. Результат вычитания второго операнда из первого помещается в третий операнд. |
Div | Операция деления. Результат деления первого операнда на второй помещается в третий операнд. |
Mul | Операция умножения. Произведение первых двух операндов помещается в третий операнд. |
Mod | Операция целочисленного деления. Результат целочисленного деления первого операнда на второй помещается в третий операнд. |
Группа логических инструкций | |
Eq, Ne, Gt, Lt, Ge, Le | Операции равно, неравно, больше, меньше, больше или равно, меньше или равно. Результат сравнения первых двух операндов помещается в третий операнд. Значение ИСТИНА кодируется как 1, значение ЛОЖЬ как 0. |
CMP | Операция сравнения двух операндов. Результат записывается в третий операнд. Если значение первого операнда больше второго, то результат = 1, если меньше, то результат = -1, если операнды равны, то результат = 0. |
OR, AND, XOR | Операции ИЛИ, И, ИЛИ НЕ. Результат сравнения первых двух операндов помещается в третий операнд. Значение ИСТИНА кодируется как 1, значение ЛОЖЬ как 0. |
Другие базовые операции | |
If | Операция условного перехода. Если значение первого операнда = 0, то есть ложно, то осуществляется переход на метку, которая передается во втором операнде. Если же значение первого операнда <> 0, то есть истинно, то осуществляется переход к выполнению следующей инструкции. |
Goto | Операция безусловного перехода. Метка, на которую осуществляется переход, передается в первом операнде. |
LABEL | Инструкция метка. Служит для осуществления переходов. |
Index | Операция извлечения элемента массива. Первым операндом передается массив, вторым индекс. Результат извлечения присваивается третьему операнду. |
Minus, NOT | Унарные операции «минус» и «не». Результат применения операции к первому операнду записывается во второй операнд. |
AssIGN | Операция присваивания. На вход инструкции подаются 2 аргумента – источник и приемник. |
Inc, Dec | Операции инкремента и декремента. Результат применения операции к первому операнду записывается во второй операнд. |
Группа операций для поддержки функций | |
Push, Pop | Операции помещения и извлечения значения из стека операндов. Операции требуют наличия одного операнда, который либо помещается в стек, либо в него извлекается значение из стека в зависимости от операции. Данные операции используются для передачи параметров в функции/процедуры. |
Call | Операция вызова функции/процедуры. В качестве единственного операнда в данную инструкцию передается указатель на функцию/процедуру. Перед передачей управления вызванной функции/процедуры текущий указатель на инструкцию помещается в стек инструкций. |
Ret | Операция выхода из функции/процедуры. Из стека инструкций извлекается помещенная ранее туда инструкция и ей передается управление. |
ExtCall | Операция вызова внешней (библиотечной) функции/процедуры. В качестве операнда в данную инструкцию передается указатель на внешнюю функцию/процедуру. |
Set_EAX | Операция установки значения внутреннего регистра. Используется для возврата значений функциями. |
Наряду с инструкциями, выполняющими математические и логические операции, в представленном языке существует ряд инструкций условного и безусловного перехода. В качестве условного перехода в языке реализован блок инструкций, состоящий из операторов логического сравнения и оператора IF <операнд> <метка>, входным операндом которой является число 0 или 1. Инструкциями безусловного перехода являются инструкция GOTO <метка>, CALL <имя функции>, EXTCALL <имя внешней функции> и инструкция RET. Для осуществления переходов в языке введена специальная инструкция LABEL и тип операнда «метка». Интерпретатор завершает свою работу, когда в списке инструкций нет следующей инструкции.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
