
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Прежде всего, язык SQL сочетает средства SDL и DML, т. е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т. е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
24. Три уровня представления данных в автоматизированных информационных системах
Существует 3 уровня: логический уровень, уровень хранения и физический уровень.
На логическом уровне работают с логическими структурами данных, отражающими реальные отношения, которые существуют между объектами и их характеристиками, т. е. указывающими в каком виде данные представляются пользователю системы. Единицей информации на этом уровне является логическая запись. Каждый объект, описываемый соответствующей логической записью, характеризуется определёнными признаками, являющимися атрибутами записи. На логическом уровне устанавливается перечень признаков, полностью характеризующий описываемый класс объектов. Совокупность и их взаимосвязь определяют внутреннюю структуру логической записи.
На логическом уровне представления данных не учитывается техническое и математическое обеспечение данных.
На уровне хранения оперируют со структурами хранения - представления логической структуры данных в памяти ЭВМ. Структура хранения должна полностью отображать логическую структуру данных и поддерживать её в процессе функционирования АИС. Единицей информации на этом уровне также является логическая запись.
Поддержание структуры хранения осуществляется программными средствами.
На физическом уровне представление данных оперируют с физическими структурами данных. На этом уровне решаются задачи реализации структуры хранения непосредственно в конкретной памяти конкретной ЭВМ. Единицей информации на этом уровне является физическая запись, представляющая участок носителя на котором размещаются одна или несколько логических записей.
При разработке структур данных всех уровней должен обеспечиваться принцип независимости данных. Физическая независимость данных означает, что изменения в физическом расположении данных и в техническом обеспечении системы не должны отражаться на логических структурах и прикладных программах, т. е. не должны вызывать в них изменений.
Логическая независимость данных означает, что изменения в структурах хранения не должны вызывать изменений в логических структурах данных и в прикладных программах.
25. Обобщенный алгоритм декомпозиции
См. 11 вопрос
26. Правила преобразования ER-модели в реляционную модель данных
Алгоритм преобразования ER в РМД:
1. Каждой сущности ER соответствует отношение РМД.
2. Каждый атрибут сущности становится атрибутом соответствующего отношения.
3. Первичный ключ сущности становится первичным ключом соответствующего отношения.
4. В каждое отношение соответствующее подчиненной сущности добавляется набор атрибутов основной сущности, являющийся первичным ключом основной сущности
5. Для моделирования необязательного вида связи на физическом уровне у атрибутов, соответствующих внешнему ключу, устанавливается свойство допустимости неопределенных значений. При обязательном типе связи – наоборот.
6. Для отражения категоризации сущности при переходе в РМД возможны несколько вариантов представления. Возможно создать только одно отношение для всех подтипов супертипа. Достоинство – создается всего одно отношение. Недостаток – избыточность. Второй подход – свое отношение для каждого подтипа.
7. При втором способе для каждого подтипа и для супертипа воздаются свои отдельные отношения. Недостатком такого способа представления является то, что создается много отношений. Достоинством – работа только со значимыми атрибутами подтипа. Для возможности переходов к подтипам от супертипа необходимо в супертип включить идентификатор связи.
27. Виды аномалий в БД
Аномалия – такая ситуация в таблице БД, которая приводит к противоречиям в БД, либо существенно усложняет обработку данных.
Разновидности аномалий: 1. избыточность – одинаковые элементы информации повторяются многократно в нескольких кортежах. 2. аномалии изменения – один и тот же фрагмент данных изменяется в одном кортеже, но остается нетронутым в другом. 3. аномалия удаления – если множество значений становится пустым это может косвенным образом привести к потере некоторой другой информации.
Один из способов устранения аномалии – декомпозиция отношения. Декомпозиция отношения R предполагает разбиение множества атрибутов R c целью построения схем двух новых отношений с последующим занесением в эти отношения определенных в отношении R кортежей.
28. Файловые структуры, используемые для хранения информации в БД:
Ø Файлы прямого доступа
Ø Файлы последовательного доступа
Ø Файлы с плотным индексом (пример организации файла)
Ø Файлы с неплотным индексом (пример организации файла)
Ø Пример организации индексов в В-деревьях
Ø Пример организации индексов в проинвертированном списке
Ø Хэширование, разрешение коллизий.
Файловые структуры для хранения информации в базах данных
Классификация файлов:
- прямого доступа;
- последовательного доступа;
- индексные:
- плотный индекс (индексно-прямые) В-деревья неплотный индекс (индексно-последовательные)
Классификация файлов:
- инвертированные списки;
- взаимосвязанные файлы:
· с однонаправленными цепочками
· с двунаправленными цепочками
Файлы прямого и последовательного доступа
Файлы прямого доступа – файлы с постоянной длиной записи, расположенные на устройствах прямого доступа. Обеспечивают наиболее быстрый доступ к произвольным записям и их использование – наиболее перспективное в системах баз данных
Файлы последовательного доступа организованы на устройствах последовательного доступа.
Файлы последовательного доступа могут быть организованы двумя способами.
конец записи отмечается специальным маркером в начале каждой записи записывается ее длинаВ файлах последовательного доступа физический адрес расположения нужной записи может быть вычислен по номеру записи, но такой доступ в базах данных неэффективный.
Чаще всего необходим поиск по первичному ключу или выборка по внешним ключам. Во всех этих случаях известно значение ключа, но неизвестен номер записи. В некоторых случаях возможно построение функций, которые по значению ключа однозначно вычисляют адрес.
NZ=F(k)
NZ – номер записи
k – значение ключа
F - функция
Функция должна быть линейной, чтобы обеспечивать взаимнооднозначное соответствие.
Когда это не удается, применяются методы хэширования и создаются специальные хэш-функции.
Суть: берется значение ключа и используется для начала поиска, то есть вычисляется некоторая хэш-функция, и полученное значение берется в качестве адреса начала поиска. То есть не требуется такого соответствия, но для увеличения скорости ограничивается время этого поиска. Поэтому допускается, что нескольким разным ключам может соответствовать одно значение хэш-функции, то есть один адрес. Это коллизии. Значения ключей, которые имеют одно и то же значение хэш-функции – синонимы. При использовании хэширования как метода доступа необходимо выбрать хэш-функцию и метод разрешения коллизии.
Существуют разные методы:
использование сгенерированного адреса в качестве начальной точки для последовательного просмотра. С этого адреса начинается поиск свободного места в памяти сгенерированный адрес считается при этом адресом хранения не одной конкретной записи, а области памяти, в пределах которой размещаются все записи, получившие этот адрес. В пределах страницы записи могут размещаться в последовательном порядке поступления. Если со временем структура окажется заполненной, в памяти выделяется новая страница, связываемая с предыдущей указателем. Хэш-функция может генерировать абсолютный адрес страницы и ее номер.Плотный, неплотный индекс
Индексные файлы можно представить как файлы, состоящие из двух частей. Индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс. В зависимости от организации индексной и основной областей различают 2 типа файлов – с плотным индексом и неплотным.
Файлы с плотным индексом
В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, структура записи в ней имеет следующий вид:
![]()
Значение ключа – значение первичного ключа
Номер записи – порядковый номер записи в основной области.
В этих файлах для каждой записи в основной области существует запись одна запись из индексной области. Все записи в индексной области упорядочены по значениям ключа.
Схематично это можно представить следующим образом:
Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны 2 решения:
перестроить заново индексную область организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записиПервый способ требует дополнительного времени на переработку индексной области.
Второй способ увеличивает время на доступ к произвольной записи и требует организации дополнительных ссылок на область переполнения.
Файлы с неплотным индексом
Неплотный индекс строится для упорядочения файлов. Структура записей индекса для таких файлов имеет следующий вид
 |
В индексной области ищется блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет определить, в какой области находится искомая запись, а остальные действия происходят в основной области.
В случае плотного индекса после определения местонахождения искомой записи, доступ к ней осуществляется прямым способом, поэтому этот способ организации индекса называется индексно-прямым.
В случае неплотного индекса после нахождении блока, где расположен запись, поиск внутри блока требуемой записи происходит последовательным просмотром. Поэтому этот способ называется индексно-последовательным.
Организация индексов в виде В-деревьев
Построение В-деревьев связано с построением индекса над уже построенным индексом. Если построен неплотный индекс, то сама индексная область может быть рассмотрена как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым индексным полем строится следующий. И так до тех пор, пока не останется всего один индексный блок. В общем случае получают некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в этом блоке. Такие деревья называются сбалансированными. Отсюда и пошло название B (Balanced) деревья.
Инвертированные списки
Часто приходится проводить операции доступа по вторичным ключам. Для обеспечения ускорения доступа по вторичным ключам, используются структуры, называемые инвертированными списками.
Инвертированный список (в общем случае) – двухуровневая индексная структура. На первом уровне находится файл или часть файла, где упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значению вторичного ключа. На третьем уровне находится основной файл. Для одного основного файла может быть создано несколько инвертированных списков по разным значениям вторичного ключа.
Инвертированный список по номеру группы для списка студентов
1-ый уровень 2-ой уровень
Ключ | № блока |
100 |
|
200 |
|
300 | 5 |
 3
3Блок 1 |
|
4 |
21 |
25 |
Блок 2 |
31 |
34 |
40 |
Блок 3 |
|
|
 1
1№ записи | ФИО | № группы |
1 | Иванов | 100 |
2 | Петров | 300 |
3 | Сидоров | 300 |
4 | Андреев | 100 |
5 | Михайлов | 200 |
6 | Николаев | 300 |
7 | Борисов | 200 |
29. Модели клиент-сервер в технологии баз данных
Ø Модель файлового сервера, достоинства и недостатки
Ø Модель удаленного доступа к данным, достоинства и недостатки
Ø Модель сервера баз данных, достоинства и недостатки
Ø Модель сервера приложений, достоинства и недостатки
Основной принцип технологии «клиент-сервер»
Основной принцип технологии «клиент-сервер»,
применяемой к технологии баз данных – разделение
функций стандартного интерактивного приложения на 5
групп:
1. функция ввода и отображения данных
Presentation Logic - PL
2. прикладные программы, определяющие основные алгоритмы решения задач приложения
Business Logic - BL
3.функция обработки данных внутри приложения
Database Logic - DL
4.функция управления информационными ресурсами
Database Manager System
5.служебные функции, играющие роль связок между функциями групп 1..4
Структура типового приложения


Presentation Logic все интерфейсные экранные формы и все, что выводится на экран, как результат решения либо как справочная информация.
Основные задачи Presentation Logic
1. формирование экранных изображений
2. управление экраном
3. чтение/запись в экранной форме
4. обработка клавиатуры и мыши
Основная задача Business Logic - определяет алгоритм решения
В централизованной архитектуре эти части приложений располагаются в единой среде и
комбинируются внутри оной исполняемой программы. В децентрализованной архитектуре эти задачи по-разному распределены между сервером и клиентом.
В зависимости от характера распределения можно выделить следующие модели:
Распределенная презентацияDistribution Presentation – DP
Удаленная презентацияRemote presentation - RP
Распределенная бизнес-логикаDistribution Business Logic - DBL
Распределенное управление даннымиRemote Data Management
Считается, что удаленная бизнес-логика не может быть удалена полностью, но может быть распределена между разными процессами, которые могут выполняться на разных платформах, но должны корректно взаимодействовать друг с другом.
Модель файлового сервера
или модель DDM
File Server – FS
Здесь presentation logic и business-logic располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами находятся на клиенте. В этой модели файлы базы данных хранятся на сервере. Клиент обращается к серверу с файловыми командами, а механизм управляет всеми информационными ресурсами, база мета данных на клиенте.
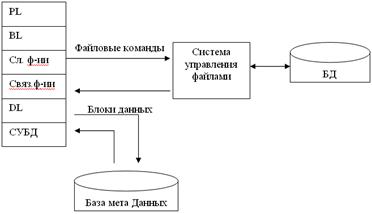
Достоинства: имеет разделение монопольного приложения на 2 взаимодействующих процесса. Сервер может обслуживать множество клиентов.
Недостатки: высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов. Небольшое количество операций манипуляций с данными, которые определяются только файловыми командами. Отсутствие средств безопасности доступа к данным. Защита только на уровне файловой системы.
Модель удаленного доступа к данным
(Remote Data Access)
База данных хранится на сервере. Там же находится ядро СУБД. На клиенте располагается Presentation Logic и Business Logic.

Стандарт – язык SQL
Достоинства: унификация интерфейса клиент-сервер. Резко уменьшается загруженность сети. Сервер базы данных загружается целиком операциями обработки данных запросов и транзакций.
Недостатки: так как в этой модели на клиенте располагается презентационная и бизнес логика, то при повторении аналогичных функций в разных приложениях код бизнес логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование информации. Сервер в этой модели пассивен.
Функции управления информационными ресурсами выполняются на клиенте, что усложняет клиентское приложение.
Запросы на SQL могут существенно загрузить сеть при интенсивной работе.
Модель активного сервера
Ее поддерживает большинство современных СУБД.
Основа этой модели – механизм хранения процедур, как средств программирования SQL сервера.
Механизм триггеров, как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры.
В этой модели BL разделен между клиентом и сервером. На сервере BL реализована в виде хранимых процедур. Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникать события, которые вызовут срабатывания других триггеров. В данной модели сервер является активным, так как не только клиент, но и сам сервер может быть инициатором обработки данных в базе данных. И хранимые процедуры и триггеры хранятся в словаре базы данных. Они могут быть использованы несколькими клиентами, что ведет к уменьшению дублирования алгоритмов обработки данных в разных клиентских программах. Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL в так называемый встроенный SQL.
Достоинства: трафик обмена информацией резко уменьшается.
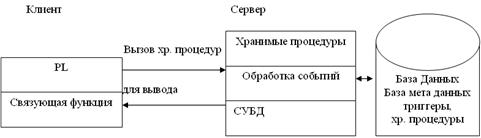
Недостатки: очень большая загрузка сервера.
Сервер выполняет следующие функции.
обеспечение автоматически срабатывающих триггеров при возникновении связанных с ним событий обеспечение внутренней программой каждого триггера запуск хранимых процедур мониторинг событий, связан с триггерами запуск хранимых процедур из триггеров обеспечение всех функций СУБДДальнейшее развитие:
 |
Таким образом, клиенты подключаются не к реальному серверу, а к промежуточному звену – диспетчеру и выполняют функции диспетчеризации запросов к серверу. Подобные системы относят к системам с виртуальным сервером. А их топологию к виду «несколько клиентов, несколько серверов»
Трехуровневая модель (сервер-приложение)
Application Server
AS – расширение двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот уровень содержит один или несколько серверов приложений. В этой модели компоненты – приложения делятся между тремя исполнителями.
Клиент – обеспечение логики представления (графический, пользовательский интерфейс). Клиент исполняет коммуникационную функцию, которая обеспечивает доступ клиенту в локальную или глобальную сеть. Когда клиент также является клиентом менеджера распределенных транзакций, он включает в себя управление
распределенными транзакциями.
Сервер приложений и использует наиболее общие правила BL, поддерживает каталог с данными. Обеспечивает обмен сообщениями и поддержку запросов (в распределенных транзакциях) – новый промежуточный уровень архитектуры. Сервер базы данных выполняет только функции СУБД. Поддерживает целостность
реляционной базы данных, обеспечивает функции хранилищ базы данных, функции создания и ведения баз данных, создает резервные копии баз данных, управляет выполнением транзакций.
Достоинства данной модели
разделение функций приложения на 3 независимые составляющие
Недостатки данной модели
более высокие затраты ресурсов компьютеров на обмен информацией между компонентами приложения по сравнению с двухуровневой.
30. Транзакции (свойства, журнал, способы завершения, типы синхронизированных захватов)
Модели транзакций. Журнал транзакций.
Транзакция – последовательность операций, производимых над базой данных и переводящих базу данных из одного непротиворечивого состояния в другое.
Типы транзакций:
Плоские (классические) Цепочечные ВложенныеПлоские:
Характеризуются четырьмя классическими свойствами.
Атомарность (Atomicity) Согласованность (Consistency) Изолированность (Isolation) Долговечность (Durability)Атомарность (Atomacity) выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
Согласованность (Consistency) гарантирует, что по мере выполнения транзакций, данные переходят из одного согласованного состояния в другое. Транзакции не разрушает взаимной согласованности данных.
Изолированность (Isolation) гарантирует, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно изолированно друг от друга, но для пользователя выглядят так, как будто выполняются параллельно.
Долговечность (Durability): если транзакция завершена успешно, то те изменения в данных, которые были произведены, не могут быть потеряны ни при каких обстоятельствах, даже в случае последующих ошибок.
Возможны 2 варианта завершения транзакции:
Фиксация – действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. Это значит, что результаты выполнения транзакции станут видимы другим пользователям. Откат – действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.Модель транзакции(рисунок):
Транзакция начинается с первого SQL оператора. Последующие составляют тело транзакции. Commit выполняется в случае успешного завершения обработки информации, объединенной в транзакцию. Его выполнение фиксирует изменения, внесенные в базу данных текущей транзакции. Roilback прерывает выполнение транзакции и осуществляет отмену изменений, проведенных в ходе выполнения транзакции.
Вопросы реализации в СУБД подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается журнал транзакций. Он предназначен для надежного хранения данных в базе данных. Это требование предполагает возможность восстановления согласованного состояния базы данных после любого рода программных или аппаратных сбоев.
Общие принципы восстановления
Результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных. Результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных.
Восстановление возможно при:
индивидуальный откат транзакции. Он должен быть применен в определенных ситуациях· аварийное завершение работы
· стандартная ситуация отката транзакции
· принудительный откат транзакции
· в случае взаимной блокировки при параллельном выполнении транзакции
мягкий сбойВосстановление после внезапной потери содержания оперативной памяти. В случае:
- аварийное отключение электропитания возникновения неустранимого сбоя процессора
Основа восстановления – архивная копия и журнал изменений базы данных.
В основе избыточное хранение данных.
2 вида ведения журнала:
1. для каждой транзакции поддерживается отдельный журнал изменений – локальный журнал
2. общий журнал изменений. Это приводит к дублированию информации в локальном и общем журнале. Поэтому используют только поддержку общего журнала изменений
Общая структура журнала может быть представлена в виде последовательного файла. Каждая запись помечается номером транзакции, к которой она относится и значением атрибутов, которые она меняет. Фиксируется команда начала и завершения транзакции. Журнал транзакций дублируется системными средствами СУБД.
Используют 2 варианта ведения журнала
протокол с отмеченными изменениями протокол с немедленными изменениямиПравила, которым должна удовлетворять процедура согласованного выполнения параллельных транзакций.
1. пользователь видит только согласованные данные
2. СУБД гарантировано поддерживает принцип независимого выполнения транзакций – сериализация транзакций.
Способ выполнения транзакций – сериальный, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Это осуществляется механизмом блокировок. Самый простой вариант – блокировка объекта на все время действия транзакции. После окончания транзакции объекты становятся доступны другим транзакциям.
В ряде СУБД организована блокировка на уровне страниц.
Блокировки, называемые синхронизационными захватами объектов, могут быть применимы к разным типам, в том числе и по всей базе данных.
Для повышения эффективности параллельного использования транзакций, используются комбинирования разных типов синхронизационных захватов.
Рассматриваются 2 основных типа:
Совместный режим блокировки – нежесткая или разделяемая блокировка (S, Shared). Это означает разделяемый захват объекта. Объекты не изменяются в процессе выполнения транзакций и доступны другим только для чтения. Монопольный режим – жесткая или эксклюзивная блокировка (X, Exclusive). Требуется для выполнения операций занесения, удаления, модификации и предполагает монопольный захват объекта. Объекты недоступны для других транзакций.Правила совместимости захвата одного объекта другим
Транзакция B |
| ||||
Разблокирована | Нежесткая | Жесткая | |||
Транзакция А | Разблокирована | Да | Да | Да |
|
Нежесткая | Да | Да | Нет |
| |
жесткая | Да | Нет | Нет |
| |
Предполагается, что первой блокирует объект транзакция А, потом пытается получить транзакция B. Нескольким транзакциям допускается читать один и тот же объект. Захват объекта одной транзакцией по чтению не совместим с захватом другой транзакции того же объекта по записи. Захваты одного объекта разными транзакциями по записи несовместимы. Применение разных типов блокировок приводит к проблеме тупиков. Количество взаимно заблокированных транзакций может быть большим. Эту ситуацию каждая из транзакций самостоятельно обнаружить не может. Ее должна разрешить СУБД. Основой обнаружения тупиковых ситуаций является построение графа ожидания транзакции. Разрушение тупика начинается с выбора в цикле транзакций, так называемой транзакции-жертвы, т. е. транзакции, которой разрешено пожертвовать ради обеспечения возможности выполнения другой транзакции.
Критерий выбора – стоимость транзакции. Жертвой выбирается самая дешевая. Стоимость выбирается многофакторной оценкой, в которую включаются с разными весами время выполнения, приоритет, число накопленных захватов. После выбора жертвы происходит ее откат. Освобождаются захваты, и может быть предложено выполнение других транзакций.
31. Многомерная модель данных
Можно выделить 2 направления:
1. системы оперативной транзакционной обработки.
2. системы аналитической обработки или системы поддержки принятия решений
Реляционные предназначались для информационных систем оперативной обработки информации. В области аналитической обработки информации более эффективны многомерные СУБД.
Основные понятия:
Агрегируемость: означает просмотр информации на различных уровнях. Ее обобщение. Степень детальности информации зависит от ее уровня.
Историчность: обеспечение высокого уровня статичности данных и их взаимосвязи, а также обязательность привязки данных ко времени. Статичность позволяет использовать при обработке данных специальные методы загрузки, хранения, индексации, выборки
Прогнозируемость: задание функции прогнозирования, и применение ее к различным временным интервалам.
Многомерность модели означает многомерное логическое представление структуры информации при описании и при операциях манипулирования данными. Обладает более высокой наглядностью и информативностью по сравнению с реляционной.
Данные представляют собой срезы из многомерного хранилища
Измерение: это множество однотипных данных, представляющих одну из граней гиперкуба. Например – временное измерение.
Ячейка: значение, которое однозначно определяется фиксированным набором измерений. Тип поля обычно цифровой. Поликубическую модель поддерживает Oracle.
Операции:
1. Формирование среза. Срез – подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений.
2. Вращение. Применяется при двумерном представлении данных. Суть заключается в изменении порядка измерения при визуальном представлении данных.
3. Агрегация и детализация. Переход к более общему или более детальному представлению данных.
Основное достоинство модели – эффективность аналитической обработки данных больших объемов, связанных со временем. В реляционной модели происходит нелинейный рост трудоемкости в зависимости от размера.
Недостаток: громоздкость модели для простых задач.
32. Постреляционная модель данных
Universe представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных в таблицах. Допускает многозначные поля (поля, значения которых состоят из подзначений). Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. Постреляционная модель поддерживает также многоуровневые ассоциированные поля. Совокупность ассоциированных полей называют ассоциацией. При этом первое значение одного столбца ассоциации соответствует первым значениям всех остальных столбцов ассоциации. Аналогичным образом связанны вторые значения. На длину полей и количество полей в записях не накладывается ограничение постоянства.
Достоинства: возможность представления совокупности связанных таблиц одной постреляционной таблицей.
Недостатки: сложность решения проблемы целостности и непротиворечивости данных.
34. Методы восстановления БД
См. в 30-ом вопросе.
33. Защита БД
35. Методы обеспечения защиты данных
36. Средства защиты информации БД
Для эффективного построения защиты необходимо:
- выделить уязвимые элементы вычислительной системы;
- выявить угрозы для выделенных элементов,
- сформировать требования к системе защиты;
- выбрать методы и средства удовлетворения предъявленным требованиям.
Под угрозой ИПО понимается возможность преднамеренного или случайного действия, которое может привести к нарушению безопасности хранимой и обрабатываемой в ВС информации.
Безопасность ВС нарушается вследствие реализации одной или нескольких потенциальных yгроз. Основными видами угроз в ВС являются следующие:
1 Несанкционированное использование ресурсов ВС:
- использование данных (копирование, модификация, удаление, печать и т. д. );
- копирование и модификация программ,
- исследование программ для последующего вторжения в систему.
2 Некорректное использование ресурсов ВС:
- случайный доступ прикладных программ для последующего вторжения в систему:
- случайный доступ к системным областям дисковой памяти;
- некорректное изменение баз данных (ввод неверных данных, нарушение ссылочной целостности данных),
- ошибочные действия пользователей и персонала
3 Проявление ошибок в программных и аппаратных средствах
4 Перехват данных в линиях связи и системах передачи
5 Несанкционированная регистрация электромагнитных излучений
6 Хищение устройств ВС, носителей информации и документов.
7 Несанкционированное изменение состава компонентов ВС, средств передачи инф. или их вывода из строя...
Возможными последствиями нарушения защиты являются следующие:
- получение секретных сведений;
- снижение производительности или остановка системы;
- невозможность загрузки операционной системы с жесткого диска;
- материальный ущерб;
- катастрофические последствия.
Исходя из возможных угроз безопасности можно выделить три основные задачи защиты:
- защита информации от хищения;
- защита информации от потери;
- защита ВС от сбоев и отказов.
Защита информации от хищения подразумевает предотвращение:
- физического хищения устройств и носителей хранения информации,
- несанкционированного получения информации (копирования, подсмотра, перехвата и т. д.),
- несанкционированного распространения программ.
Защита информации от потери подразумевает поддержание целостности и корректности информации, что означает обеспечение физической, логической и семантической целостности информации. Информация в системе может быть потеряна как из-за несанкционированного доступа в систему пользователей, программ (в т. ч. компьютерных вирусов), некорректных действий пользователей и их программ, обслуживающего персонала, так и в случаях сбоев и отказов в ВС.
Защита информации от сбоев и отказов аппаратно-программного обеспечения ВС является одним из необходимых условий нормального функционирования системы. При недостаточно надежных системных средствах защиту от сбоев следует предусматривать в прикладных программах. Под надежностью ПО понимается способность точно и своевременно выполнять возложенные на него функции. Степень надежности ПО определяется качеством и уровнем автоматизации процесса разработки, а также орг-ей его сопровождения.
Для орг. компл-ой защиты информации в ВС в общем случае может быть предусмотрено 4 защитных уровня.
1 Внешний уровень, охватывающий всю территорию расположения ВС.
2. Уровень отдельных сооружений или помещений расположения устройств ВС и линий связи с ними.
3. Уровень компонентов ВС и внешних носителей информации
4. Уровень технологических процессов хранения, обработки и передачи информации.
Первые три уровня обеспечивают в основном физическое препятствие доступу путем ограждения, системы сигнализации, организации пропускного режима, экранирования проводов л т. д.
Последний уровень предусматривает логическую защиту инф в том случае, когда физич доступ к ней имеется.
Существующие методы защиты можно разделить на четыре основных класса:
- физические.
- аппаратные;
- программные.
- организационные.
Физическая защита используется в основном на верхних уровнях защиты и состоит в физическом преграждении доступа посторонних лиц в помещения ВС на пути к данным и процессу их обработки.
Аппаратная защита реализуется аппаратурой в составе ЭВМ или с помощью специализированных устройств.
Программная защита реализуется с помощью различных программ: операционных систем, антивирусных пакетов, специализированных программ защиты и т. д.
Организационная защита реализуется совокупностью направленных на обеспечение защиты информации организационно-технических мероприятий, разработкой и принятием законодательных актов по вопросам защиты информации и т. д.
Для защиты от несанкционированного доступа (НСД) необходима эффективная система регистрации попыток доступа в систему со стороны пользователей и программ, а также своевременная сигнализация о них лицам, отвечающим за безопасность ВС.
Защита от НСД со стороны пользователей в современных системах в основном реализуется двумя основными способами парольной защитой, а также путем идентификации и аутентификации.
Для аутентификации, или проверки подлинности пользователя, используют следующие способы:
- запрос секретного пароля,
- запрос какой-либо информации сугубо индивидуального,
- применение микропроцессорных карточек;
- активные средства опознавания;
- биометрические средства
Примером электронного ключа является пластиковая карточка с магнитной полоской.
Более сложный вариант электронного ключа - специальный прибор, называемый жетоном и позволяющий генерировать псевдослучайные пароли. Каждый новый пароль имеет ограниченное время действия. Сами пароли постоянно изменяются. Каждый пароль пригоден для однократного входа в систему.
Микропроцессорные карточки позволяют формировать цифровые подписи.
Из множества существующих средств аутентификации наиболее надежными и дорогами считаются биометрические средства. В них опознавание личности осуществляется по отпечаткам пальцев, форме ладони, сетчатке глаза, подписи, голосу и другим физиологическим параметрам человека Основным достоинством систем такого класса является высокая надежность аутентификации. Недостатки систем включают в себя высокую стоимость оборудования, неудобство для пользователя и пр.
Вo многих системах защиты предусматривается разграничение доступа к ресурсам в течение сеанса.
Для защиты информационно-программных ресурсов ВС от несанкционированного использования применяются следующие варианты защиты от копирования, от исследования (программ), от просмотра (данных), от модификации и удаления.
Мощным средством защиты данных от просмотра является шифрование. Шифрование данных осуществляется в темпе поступления информации (On-line) и в автономном режиме (Off-line). Первый способ применяется в основном в системах приема-передачи информации, а второй - для засекречивания информации.
Средства защиты базы данных условно делятся на две группы: основные и дополнительные.
К основным средствам защиты информации можно отнести следующие средства:
- парольная защита;
- шифрование данных и программ;
- установление прав доступа к объектам баз данных;
- защита полей и записей таблиц базы данных.
Пароли устанавливаются администраторами базы данных. Учет и хранение паролей производится самой СУБД. Обычно пароли хранятся в зашифрованном виде. Шифрование исходных текстов и программ позволяет скрыть от несанкционированного доступа пользователя описание соответствующих алгоритмов. Права доступа определяют возможные действия над объектами. Владелец объекта и админ БД имеют все права доступа.
По отношению к таблицам могут устанавливаться следующие права доступа
- просмотр (чтение) данных
- изменение (редактирование) данных;
- добавление новых записей,
- добавление и удаление данных;
- все операции, в т. ч. и изменение структуры таблицы.
Применительно к защите данных в полях таблиц можно выделить следующие уровни прав доступа
- полный запрет доступа;
- только чтение
- разрешение всех операций.
К дополнительным средствам защиты относятся следующие средства:
- встроенные средства контроля значений данных в соответствии с типами;
- повышение достоверности вводимых данных;
- обеспечение достоверности связи таблиц;
- организация совместного использования объектов базы данных в сети
Наиболее совершенной формой организации контроля достоверности информации в базах данных является разработка хранимых процедур.
Хранимые процедуры представляют собой набор команд, состоящий из одного или нескольких операторов или функций и сохраняемый в базе данных в откомпилированном виде.
Выполнение в базе данных хранимых процедур вместо отдельных операторов дает пользователю следующие преимущества:
• необходимые операторы уже содержатся в базе данных;
• все они прошли этап синтаксического анализа и находятся в исполняемом формате;
• хранимые процедуры поддерживают модульное программирование, так как позволяют разбивать большие задачи на самостоятельные, более мелкие и удобные в управлении части;
• хранимые процедуры могут вызывать другие хранимые процедуры и функции;
• хранимые процедуры могут быть вызваны из прикладных программ других типов;
• как правило, хранимые процедуры выполняются быстрее, чем последовательность отдельных операторов;
• хранимые процедуры проще использовать: они могут состоять из десятков и сотен команд, но для их запуска достаточно указать всего лишь имя нужной хранимой процедуры. Это позволяет уменьшить размер запроса, посылаемого от клиента на сервер, а значит, и нагрузку на сеть.
Хранение процедур в том же месте, где они исполняются, обеспечивает уменьшение объема передаваемых по сети данных и повышает общую производительность системы.
Применение хранимых процедур упрощает сопровождение программных комплексов и внесение изменений в них. Для обеспечения целостности данных, а также в целях безопасности, приложение обычно не получает прямого доступа к данным - вся работа с ними ведется путем вызова тех или иных хранимых процедур.
Хранимые процедуры существуют независимо от таблиц или каких-либо других объектов баз данных. Они вызываются клиентской программой, другой хранимой процедурой или триггером. Разработчик может управлять правами доступа к хранимой процедуре, разрешая или запрещая ее выполнение. Изменять код хранимой процедуры разрешается только ее владельцу.
Триггер представляет собой специальный тип хранимых процедур, запускаемых сервером автоматически при попытке изменения данных в таблицах, с которыми триггеры связаны. Каждый триггер привязывается к конкретной таблице. Все производимые им модификации данных рассматриваются как одна транзакция. В случае обнаружения ошибки или нарушения целостности данных происходит откат этой транзакции. Тем самым внесение изменений запрещается. Отменяются также все изменения, уже сделанные триггером.
• Создает триггер только владелец базы данных. Это ограничение позволяет избежать случайного изменения структуры таблиц, способов связи с ними других объектов и т. п.м
С помощью триггеров достигаются следующие цели:
• проверка корректности введенных данных и выполнение сложных ограничений целостности данных, оторые трудно, если вообще возможно, поддерживать с помощью ограничений целостности, установленных для табл;
• выдача предупреждений, напоминающих о необходимости выполнения некоторых действий при обновлении таблицы, реализованном определенным образом;
• накопление аудиторской информации посредством фиксации сведении о внесенных изменениях и тех лицах, которые их выполнили;
Триггерные события состоят из вставки, удаления и обновления строк в таблице. В последнем случае для триггерного события можно указать конкретные имена столбцов таблицы.
При условии правильного использования триггеры могут стать очень мощным механизмом, Основное их преимущество заключается в том, что стандартные функции сохраняются внутри базы данных и согласованно активизируются при каждом ее обновлении. Это может существенно упростить приложения.
Тем не менее следует упомянуть и о присущих триггеру недостатках:
• сложность: при перемещении некоторых функций в базу данных усложняются задачи ее проектирования, реализации и администрирования;
• скрытая функциональность: перенос части функций в базу данных и сохранение их в виде одного или нескольких триггеров иногда приводит к сокрытию от пользователя некоторых функциональных возможностей. Это может стать причиной побочных эффектов, поскольку в этом случае пользователь не
в состоянии контролировать все процессы, происходящие в базе данных.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
