
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
С. С. НАРЫНОВ
Институт математики Национальной Академии Наук,
Алма-Ата, Республика Казахстан
*****@***kz, *****@***ru
АЛГОРИТМ РАСТУЩЕГО НЕЙРОННОГО ДЕРЕВА
Аннотация
В работе описывается принцип действия алгоритма «растущего нейронного дерева» (РНД). Алгоритм РНД использует принцип обучения без учителя и имеет иерархическую структуру. Отличается высокой скоростью и гибкостью классификации образов сложной формы в пространстве признаков.
Предложенный алгоритм растущего нейронного дерева (РНД) является модернизацией алгоритма WTA (k-means), обучающийся согласно правилу «Winner Takes All». Напомним, что сеть WTA представляют собой группу конкурирующих между собой нейронов. Нейроны WTA разделяют множество входных данных на подмножества, классы с близкими атрибутивными характеристиками. Элементы каждого подмножества находятся в пространстве признаков в пределах ячейки Вороного. Основное отличие алгоритма обучения РНД от WTA состоит в топологии разработанной нейронной сети. В рамках каждой ячейки Вороного разыгрывается фактически вложенные конкурентные сети. Множественная вложенность, и как следствие возможность построения несимметричных деревьев для более сильного разбиения «важных» участков пространства признаков вне зависимости от плотности векторов. Создан алгоритм несимметричного дерева, который сильнее ветвиться на границах между известными учителю классами, тем самым лучше аппроксимирует краевые особенности этих классов. Алгоритм хорошо решает задачу двух вложенных спиралей и разрывных классов. Фактически алгоритм решает оптимизационную задачу количества нейронов скрытого слоя в сети встречного распространения.
Критерий близости в РНД определяется иерархически, структурой дерева: нейроны обучаются на основе конкуренции тогда и только тогда, если они принадлежат ветвям, имеющим общую вершину.
Алгоритм нейронной сети РНД относится к классу сетей с динамической архитектурой, так как в процессе обучения нейронное дерево имеет свойство расти в параметрическом пространстве.
Пусть: ![]() – пространство признаков из n – размерностей; x – входной вектор;
– пространство признаков из n – размерностей; x – входной вектор; ![]() – вектор весов нейрона;
– вектор весов нейрона; ![]() – нейрон;
– нейрон; ![]() – обучаемая выборка, конечное множество в пространстве признаков (Серое облако, рис. 1):
– обучаемая выборка, конечное множество в пространстве признаков (Серое облако, рис. 1):
· 0-шаг: в пространстве признаков в случайно выбранную точку ![]() помещается один формальный нейрон
помещается один формальный нейрон ![]() . Назовем его «корневым» (рис. 1, а);
. Назовем его «корневым» (рис. 1, а);
· 1-шаг: на вход этого нейрона подается первая точка ![]() обучающей выборки. Корневой нейрон смещается вдоль вектора
обучающей выборки. Корневой нейрон смещается вдоль вектора ![]() по направлению к
по направлению к ![]() на величину
на величину ![]() , где
, где ![]() – коэффициент обучения, зависящий от номера итерации
– коэффициент обучения, зависящий от номера итерации ![]() . Последовательный перебор точек
. Последовательный перебор точек ![]() приводит к итерациям, приближающим положение корневого нейрона к точке
приводит к итерациям, приближающим положение корневого нейрона к точке ![]() – барицентру
– барицентру ![]() , при условии, что
, при условии, что ![]() – убывающая функция:
– убывающая функция: 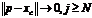 . На этом шаге обучение корневого нейрона прекращается (рис. 1, б);
. На этом шаге обучение корневого нейрона прекращается (рис. 1, б);
· 2-шаг: корневой нейрон выпускает две новых ветви в случайно выбранные точки ![]() . В этих точках возникают нейроны 1-го уровня:
. В этих точках возникают нейроны 1-го уровня: ![]() , которые делят
, которые делят ![]() на две части
на две части ![]() гиперплоскостью, трансверсальной соединяющему их вектору. Каждый из них (
гиперплоскостью, трансверсальной соединяющему их вектору. Каждый из них (![]() и
и ![]() ) получает пример из выборки
) получает пример из выборки ![]() , но побеждает тот из них, например,
, но побеждает тот из них, например, ![]() для которого
для которого ![]() . Победитель получает право выполнять действия корневого нейрона (шаг-1), т. сдвинуться в направлении точки
. Победитель получает право выполнять действия корневого нейрона (шаг-1), т. сдвинуться в направлении точки ![]() . После этого,
. После этого, ![]() предъявляется следующий пример и вновь определяется победитель. В результате дрейфа, нейроны 1-го уровня приближаются к барицентрам приближается к центру тяжести
предъявляется следующий пример и вновь определяется победитель. В результате дрейфа, нейроны 1-го уровня приближаются к барицентрам приближается к центру тяжести ![]() и
и ![]() . После этого обучение нейронов 1-го уровня завершается (рис. 1, в);
. После этого обучение нейронов 1-го уровня завершается (рис. 1, в);
· 3-шаг: каждый из нейронов ![]() выпускает две ветви с нейронами 2-го уровня:
выпускает две ветви с нейронами 2-го уровня: 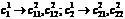 . Подвыборки
. Подвыборки ![]() разделяются на части следующего уровня
разделяются на части следующего уровня ![]() и
и ![]() . Для того, чтобы выбрать пару для последующего обучения, проверяется какой из нейронов предыдущего уровня, т. е.
. Для того, чтобы выбрать пару для последующего обучения, проверяется какой из нейронов предыдущего уровня, т. е. ![]() или
или ![]() ближе к поданному примеру, т. е. точки
ближе к поданному примеру, т. е. точки ![]() . После этого, активизируется пара, индуцированная именно этим нейроном. Для этого примера, вторая пара не активна (рис. 1, г);
. После этого, активизируется пара, индуцированная именно этим нейроном. Для этого примера, вторая пара не активна (рис. 1, г);
· ![]() шаг: повторение
шаг: повторение ![]() ;
;
· рост дерева прекращается по требованию оператора.
|
|
|
|
а) | б) | в) | г) |

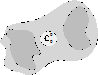
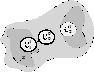
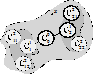
Рис. 1
Основным преимуществом алгоритма РНД очень высокая скорость распознавания связанная с тем, что при выборе ветви «победителя» у всех нейронов-ветвей иерархически связанных с «проигравшей» ветвью не проводиться вычисление близости к входному сигналу. Например, при 10 уровней дерева, количество классов (нейроны-листья) равно ![]() =1024, а количество нейронов участвующих в распознавании входного сигнала всего 20.
=1024, а количество нейронов участвующих в распознавании входного сигнала всего 20.
Возможно построение не только бинарного дерева, количество ветвей у одной вершины может быть более двух. Однако в этом случае возникает проблема с ветвями аутсайдерами, которые не будут попадать в облако признаков, а иерархически связанные с аутсайдером нейроны никогда не будут участвовать в распознавании. Есть два подхода решения проблемы. Первый заключается в запрете роста ветвей у нейронов аутсайдеров, второй в использовании существующих алгоритмов конкурентного обучения на уровне ветвей одной вершины, т. е. пространство признаков разбивается на небольшое количество классов, например, алгоритмом нейронного газа, затем в пределах каждого пространства обучается вложенная подсеть нейронного газа. В этом случае при поступлении входного сигнала сеть определяет принадлежность сигнала к некому классу, затем запускается подсеть этого класса, которая определяет подкласс. Благодаря отсечениям заведомо далеких от входящего сигнала образов подклассов достигается высокая скорость вычисления.
К числу недостатков РНД следует отнести большое количество этапов обучения, которое вызвано необходимостью проведения дополнительного обучения сети при добавлении новых ветвей. Обучение трех уровневого дерева требует, как минимум три прогона по обучающей выборке для достижения тех же результатов, который достигается алгоритмом конкурентного обучения за один проход (например, сеть Кохонена, растущий нейронный газ и др.). Тем не менее, благодаря низкому порядку конкурирующих отношений сеть РНД требует значительно меньших вычислительных затрат в процессе распознавания (после обучения) чем такие алгоритмы как сеть Кохонена, растущий нейронный газ и др.
На рис. 2 показано 6 этапов формирования дерева изображенные парными картинками. В верхнем изображении каждой пары показаны все сигналы (красные точки), поданные на вход сети, а также нейронное дерево (нейроны-ветви – белые кружки, нейроны-листья – черные кружки). В нижнем изображении каждой пары показано разбиение на классы при соответствующей архитектуре дерева.
В результате обучения двух нейронных деревьев со случайными начальными весовыми коэффициентами (рис. 3а) на одном множестве достигается почти идентичное разбиение. Эксперименты над разными распределениями векторов в пространстве признаков показали, что классификации сетью РНД слабо зависит от инициализирующих случайных весов.

Рис. 2. Динамика роста РНД в двухпараметрическом пространстве признаков,
на примере кольцеобразного распределения обучающей выборки
|
|
Рис. 3а. Обучение двух нейронных деревьев со случайными начальными весовыми коэффициентами. | Рис. 3б. Нейронное дерево в параметрическом пространстве трехмерных данных |

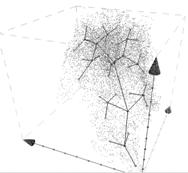
Эксперименты по классификации N-мерных данных
В качестве источника обучающей выборки было использовано изображение с напечатанными символами разного размера (рис. 4). Исходное изображение сканировалось окном размером 20х20 пикселей и записывалось в входную матрицу. Вырезанное окно разворачивалось в одномерный массив из 400 элементов. Этот массив подавался на вход нейронной сети РНД.
Любое изображение, поданное на входную матрицу 20х20, представляет собой точку в 400-мерном пространстве признаков. Разные написания одной и той же цифры в пространстве признаков представляют облако признаков сложной формы.
Поставленной целью было «вырастить» нейронное дерево, которое могло бы разделить все облака на отдельные классы. Для решения задачи классификации растровых изображений в 400-мерном пространстве использовалось 10 уровневое бинарное дерево. Количество нейронов в сети было ровно 2065 нейрона, количество результирующих классов равно 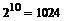 . Период появления нового уровня нейронов T =итераций. Общее количество итераций необходимых для обучения сети было равно 100 000.
. Период появления нового уровня нейронов T =итераций. Общее количество итераций необходимых для обучения сети было равно 100 000.
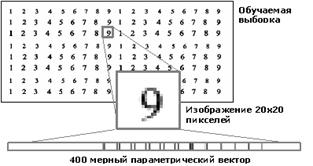
Рис. 4. Изображение источника обучающей выборки
Длительность обучения на компьютере Pentium 4 1500 мГц составила 30 с. В результате обучения нейронная сеть сумела классифицировать девять цифр разного масштаба, не центрированных относительно входной матрицы. Уровень ошибки классификации составил ~ 5 % на обучаемой выборке и ~ 15 % на данных с 35 % шумом (рис. 5).

Рис. 5. Лучшие результаты правильной классификации цифр
при уровне шума 35 %
Интересные результаты дал анализ полученного в процессе обучения нейронного дерева. Была произведена визуализация значений весов нейронов дерева. Если проследить изменения весов нейронов от корня до любого листка, видны различия в специализации нейронов (рис. 6). Корневой нейрон ввиду обучения на всех подаваемых на вход образах представляет обобщенный образ всего «увиденного». Нейроны более высоких уровней были более специализированы. Конечный нейрон имеет наиболее узкую специализацию.

Рис. 6. Матрицы весов промежуточных нейронов от корневого нейрона (первый столбец) до некоторых нейронов-листьев (девятый столбец). Видно, что образы цифр «5» и «8» имеют общих «предков» до четвертого уровня и распадаются на специфические подклассы (последний общий нейрон в красной рамке). В свою очередь, классы цифры «8» и «6» имеют общие нейроны до 8-го уровня. Цифры «2» и «7» имеют общих нейронов до 6-го уровня
Исходя из выше изложенного, можно сделать следующие выводы.
Преимущества РНД:
· высокая скорость определения принадлежности к классу;
· решена проблема мертвых нейронов;
· существует возможность управления степенью квантизации определенных областей пространства признаков путем несимметричного роста нейронного дерева;
· относительно низкое влияние инициализирующих весовых коэффициентов на итоговое разбиение.
Недостатки РНД:
· большое количество этапов обучения РНД, которое пропорционально количеству уровней дерева;
· количество результирующих классов, в случае построения симметричного дерева, должно быть кратно 2L, где L – колличество уровней.
Список литературы
1. Andrew W. Moore. The Anchors Hierarchy: Using the Triangle Inequality to Survive High Dimensional Data // Carnegie Mellon University. Pittsburgh, PA 15213.
2. Dan Pelleg, Andrew Moore. X-means: Extending K-means with Efficient Estimation of the Number of Cluster // School of Computer Science, Carnegie Mellon University. Pittsburg, PA 15213 USA.
