

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Целью дисциплины «Алгоритмы и структуры обработки данных» является изучение и исследование наиболее важных компьютерных алгоритмов, обучение фундаментальным технологиям решения задач.
Чтобы стать квалифицированным программистом, не достаточно овладеть элементарными приемами программирования и современными инструментальными системами программирования. Необходимо изучить большое количество наиболее важных алгоритмов, используемых при решении разнообразных задач.
При создании компьютерной программы обычно используется известный метод, который был разработан для решения какой-либо задачи. Часто этот метод не зависит от используемого компьютера. Поэтому для выяснения способа решения поставленной задачи, прежде всего, нужно выбрать и исследовать именно метод решения. В программировании метод решения носит термин «алгоритм».
Большинство представляющих интерес алгоритмов сопряжены с методами организации данных, участвующих в вычислениях. Созданные таким образом объекты называются «структурами данных». Структуры данных формируются и используются алгоритмами либо в качестве вспомогательного средства для реализации метода решения, либо как конечный результат. Простые алгоритмы могут порождать сложные структуры данных и, наоборот, сложные алгоритмы могут использовать простые структуры данных.
Поэтому структуры данных выступают в дисциплине как важный и самостоятельный объект изучения.
При реализации той или иной задачи, как правило, возможны несколько альтернативных методов решения. Если при решении простых задач выбор метода не имеет особого значения, то для сложных задач мы сталкиваемся с необходимостью выбора методов, при которых время и память используются с максимальной эффективностью. Казалось бы, этот момент не существенен, если мы можем использовать для решения задачи современный быстродействующий компьютер с большим объемом памяти.
Но в приложениях, в которых обрабатываются миллионы объектов, часто оказывается возможным ускорить работу программы в миллионы раз, используя хороший алгоритм. В это же время использование современного компьютера может ускорить работу программы всего в 10-100 раз.
Таким образом, тщательная обработка алгоритма – исключительно эффективная часть процесса решения сложной задачи в любой области применения.
Часто в связи с рассмотрением, анализом и разработкой фундаментальных алгоритмов обработки данных возникает вопрос: «Зачем нужно разрабатывать эти алгоритмы и программы, если можно использовать готовые программы?». Например, библиотека стандартных шаблонов (Standard Template Library - STL) языка С++ содержит реализации множества базовых алгоритмов.
Аргументов за реализацию несколько:
1. Реализация версий основных алгоритмов позволяет лучше их понять и, следовательно, эффективнее использовать и настраивать более совершенные библиотечные версии.
2. В связи с использованием новых вычислительных сред (аппаратных и программных) с новыми свойствами решается проблема переносимости программы с собственной реализацией алгоритмов.
3. Собственная реализация, как правило, больше приспособлена к особенностям конкретной задачи.
4. Механизм совместного использования стандартных программ зачастую недостаточно мощны и существенно снижают эффективность программы в целом.
Круг рассматриваемых тем в рамках этого курса:
1.Фундаментальные структуры данных: стеки, очереди, списки, деревья, словари графы.
2.Методы поиска, сортировки и кодирования данных, и соответствующие структуры данных: кодовые деревья, случайные и рандомизированные деревья поиска, сбалансированные деревья поиска, оптимизированные деревья поиска, деревья внешнего поиска.
3.Методы поиска решений: поиск с возвратом, исчерпываемый поиск, метод ветвей и границ, динамическое программирование, жадные алгоритмы.
4.Фундаментальные алгоритмы на ориентированных и неориентированных задачах: поиск в глубину и ширину, построение остовых деревьев, нахождение кратчайших путей.
Литература, на которой базируется курс:
1. Альфред Ахо, Холкфорд, Д. Ульман. Структуры данных и алгоритмы: - М., издательство «Вильямс», 2000г.
2. Алгоритмы + структуры данных = программы: - М., издательство «Мир», 1985г.
3. Алгоритмы и структуры данных: - М., издательство «Досса», 1997г.
4. Искусство программирования для ЭВМ. Т1 Основные алгоритмы: - М., издательство «Мир», 1976г.( переиздание: - М., издательство «Вильямс», 2000г.).
5. Искусство программирования для ЭВМ. Т3 Сортировка и поиск: - М., издательство «Мир», 1978г.( переиздание: - М., издательство «Вильямс», 2000г.).
6. Алгоритмы. Анализ и построение: - М., издательство «Бином», 2000г.
7. алгоритмы на С++. Части 1-4.: - Киев., издательство «ДлаСофт», 2001г.
8. Топп Уильям, Форд Уильям Структуры данных на С++.: - М., издательство «Бином», 2000г.
9. Искусство программирования на С. Фундаментальные алгоритмы, структуры данных и примеры приложений.: - Киев, издательство «ДиаСофт», 2001г.
В этом семестре вам предстоит выслушать 8 лекций, выполнить 4 лабораторные работы и сдать гос. экзамен. В следующем семестре вы прослушаете еще 8 лекций и выполните расчетно-графическую работу.
Лабораторные работы посвящены реализации и экспериментальному анализу эффективности алгоритмов для фундаментальных основных структур данных – списков, деревьев, сбалансированных деревьев, словарей. Методика реализации алгоритмов базируется на разработке абстрактного типа данных для предложенной структуры данных и реализации его в виде шаблонного класса на языке программирования С++. Реализация типа данных подвергается тестовым операциям с целью получения и анализа эмпирических характеристик эффективности основных операций. Для выполнения лабораторных работ предлагается электронное пособие с методическими указаниями к выполнению.
Псевдокод.
Чтобы не отвлекаться при изложении алгоритмов на особенности программирования на конкретном языке программирования, принято вести запись алгоритмов на псевдокоде. Действия алгоритма описываются полу формально. Можно опустить технические подробности программирования, затеняющие суть алгоритма.
Пример записи алгоритма сортировки вставками на псевдокоде.
Сортировка вставками удобнее для коротких последовательностей. Входом алгоритма является последовательность {а1, а2, …, аn }, представленная в виде массива А[1 … n]. Обозначим число элементов в массиве length[A]. Последовательность сортируется «на месте» без использования дополнительной памяти. После сортировки массив упорядочен по возрастанию.

![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()

![]()

Insertion_Sort(A)
for jОсновные правила и соглашения псевдокода:
Отступ от левого поля указывает на уровень вложенности. Это делает излишним использование блочных скобок ({ }- в Си, begin-end – в Паскале). Циклы while, for, repeat и условные операторы if-then-else имеют тот же смысл, что и в Си и Паскале. СимволАнализ алгоритмов.
Анализ алгоритмов – ключ к их пониманию в степени, достаточной для эффективности их применения при решении практических задач.
Существуют два основных способа анализа – проводить исчерпывающие эксперименты или предварительный математический анализ программы.
Целью анализа является получение характеристик производительности выбранного алгоритма.
Анализ играет определенную роль в каждой точке разработки и реализации алгоритмов. Прежде всего, можно сократить время выполнения на три-шесть порядков за счет правильного выбора алгоритма. Как правило, на этом этапе можно провести приближенный математический анализ. Точный предварительный математический анализ зачастую невозможен ввиду сложной структуры алгоритма и данных, непредсказуемого состава данных. Несмотря на все эти факторы часть, возможно, предсказать, сколько времени займет выполнение программы или понять, что один алгоритм будет иметь более эффективную реализацию, чем другой. Обычно такой анализ для фундаментальных структур производится в литературе, специально посвященной анализу алгоритмов. Задачей программиста является использование полученных результатов анализа при выборе алгоритма для разрабатываемого приложения.
Хотя в курсе лекций не будет рассматриваться математический анализ фундаментальных алгоритмов, а будут даваться только готовые результаты анализа, я приведу пример такого приближенного анализа для алгоритма сортировки вставками.
Очевидно, что время сортировки массива зависит от размера сортируемого массива и его упорядоченности. Время работы алгоритма определяется числом шагов, которые он выполняет. Будем считать, что строка псевдокода требует не более чем фиксированного количества элементарных операций, если строка не является формулировкой сложных действий. В последнем случае строка соответствует программной функции, а в основном алгоритме ей соответствует вызов той функции. Вызов функции и ее выполнение отличаются по времени.
При анализе около каждой строки будем отмечать ее стоимость – число элементарных операций Сi и число раз, которые эта строка выполняется.
Выведем основной параметр, используемый при анализе – размерность массива n, т. е. число элементов.
Insertion_Sort (A) | Стоимость | Число раз | |
1. | for j | С1 | n |
2. | do key | С2 | n-1 |
3. |
| ||
4. | i | С4 | n-1 |
5. | while i>0 and A[i]>key | С5 |
|
6. | do A[i+1] | С6 |
|
7. | i | С7 |
|
8. | A[i+1] | С8 | n-1 |
Для каждого j от 2 до n подсчитаем, сколько раз будет выполнена строка 5 и обозначим это число через tj.
Строка стоимостью С, повторенная n раз, вносит в общее время c*m операций.
Сложив все вклады строк, получим показатель:
![]()
Эффективность зависит не только от размерности массива, но и от его упорядоченности. Наиболее благоприятный случай, когда массив уже отсортирован. Тогда цикл в строке 5 завершается после первой проверки, т. к. A[i]![]() key при i= j-1 и tj =1.
key при i= j-1 и tj =1.
Тогда общее время равно:
![]()

![]() Таким образом, T(n) линейная функция и имеет вид Т(n)=a*n+b.
Таким образом, T(n) линейная функция и имеет вид Т(n)=a*n+b.
Если массив расположен в обратном порядке, убывающем порядке, время работы функции будет максимальным, т. к. каждый элемент A[j] придется сравнивать со всеми элементами A[1]…A[j-1]. При этом tj =j.
![]() Т. к.
Т. к. ![]() и
и ![]() , то в худшем случае получим:
, то в худшем случае получим:
![]()
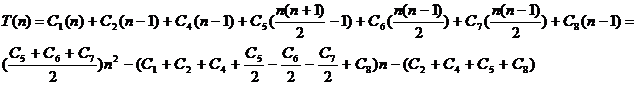 , т. е. функция T(n)- квадратичная и имеет вид T(n)=a*n2+b*n+c. Константы a, b, c определяются значениями С1, …. , С8.
, т. е. функция T(n)- квадратичная и имеет вид T(n)=a*n2+b*n+c. Константы a, b, c определяются значениями С1, …. , С8.
О(1) - | Большинство инструкций программы запускается один или несколько раз, независимо от n. Т. е. время выполнения программы постоянно. |
О(logn) - | Программа работает медленнее с ростом n. Такое время характерно для программ, которые сводят большую задачу к набору меньших подзадач, уменьшая на каждом шаге размер подзадачи на некоторый постоянный коэффициент. |
О(n) - | Время выполнения программы линейно. Каждый входной элемент подвергается небольшой обработке. |
О(nlogn) - | Время выполнения программы пропорционально nlogn возникает тогда, когда алгоритм решает задачу, разбивая ее на меньшие подзадачи, решая их независимо и затем объединяя решения. Можно применить к такой зависимости термин «линерифмический». |
О(n2) - | Время выполнения программы является квадратичным. Такие алгоритмы можно использовать для относительно небольших n. Такое время характерно, когда обрабатываются все пары элементов (в цикле двойного уровня вложенности). |
О(n3) - | Алгоритм обрабатывает тройки элементов (возможно, в цикле тройного уровня вложенности) и имеет кубическое время выполнения. Такой алгоритм практически применим только для малых задач. |
О(2n) - | Лишь несколько алгоритмов с экспоненциальным временем имеет практическое применение, хотя такие алгоритмы возникают естественным образом при попытке прямого решения задач. |
Обычно время выполнения в результате анализа выглядит как многочлен, где главным членом является один из вышеприведенных. Коэффициент при главном члене зависит от количества инструкций во внутреннем цикле. Поэтому так важно максимально упрощать количество инструкций во внутреннем цикле. При росте N начинает доминировать главный член, поэтому остальными слагаемыми в многочлене можно пренебречь.
![]()
