

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Можно сделать так, чтобы при добавлении или обновлении данных через простое представление можно было запрашивать добавленные или обновленные данные через представление. Можно сделать так, чтобы выполнение операции DML через представление было невозможно. Для этого представление создается с режимом WITH READ ONLY.
49. Снимки.
Снимки (SNAPSHOT)– объект БД представляющий из себя поименованную, динамически поддерживаемую сервером выборку из одной или нескольких таблиц или представлений. Обычно размещенных на удаленной БД. С помощью снимков администратор БД гарантирует доступ пользователя к тем частям БД, кот–е необходимы им для работы. Чтобы механизм снимков работал и на локальной и на удаленной БД на сервере должен быть установлен пакет DBMS SNAPSHOT, в кот размещены пакеты и процедуры для обновления снимков. CREATE SNAPSHOT имя [{PCTFREE целое число | PCTUSED целое| INITRANS целое| MAXITRANS целое| TABLESPACE имя табличной области| STORAGE размер] | [CLUSTER имя][USININDEX]...}] [[REFRESH COMPLETE/FAS/FOSSE] [START WITH data[NEXT data] ] [FOR UPDATE] AS <запрос>.
PCTFREE опр–ет размер блоков резервируемых для работы со снимком(в %, по умолчанию 10), PCTUSED–мин %исп–ия блока при кот в него вводятся данные (40). FREE+USED<=100. INITRANS – задает начальное число параллельных транзакций, кот–е вып–ся для модификации данных блока(1), MAXITRANS–макс число парал транзакций, TABLESPACE– опр–ет имя табличной обл–ти где должен храниться снимок. STORAGE – опр–ет объем внешней памяти. CLUSTER – связ–ет столбцы снимка с опр–ым кластером, USININDEX–задает создание индекса для данного снимка. REFRESH–опр–ет технологию обновления снимка, т. е complete означает полное обновление снимка, а значит фактически заново вып–ся запрос. FAST–при обновлении данных снимка исп–ся инфа об измененных данных в мастер таблице, хранящейся в логическом файле снимка. FORCE – решение о технологии обновления принимается самой системой. START WITH–опр–ет дату первого обновления снимка, если REFRESH отсутствует, то авто обновление данных не происходит. FOR UPDATE–указывает на возможность изменения данных снимка.
50. Последовательности.
Последовательности – объект БД, позволяющий автоматически генерировать неповторяющиеся целые числа. (Автоматически генерирует уникальные числа ; Является совместно используемым объектом; Обычно применяется для получения значений первичного ключа; Заменяет код в прикладной программе ; Ускоряет доступ к числам последовательности, если они находятся в сверхоперативной памяти (кэш–памяти) ). Числа последовательности хранятся и генерируются независимо от таблиц. Следовательно, одна и та же последовательность может быть применена одновременно к нескольким таблицам. Последовательность для автоматической генерации чисел создается командой CREATE SEQUENCE. CREATE SEQUENCE последовательность [INCREMENT BY n][START WITH n][{MAXVALUE n | NOMAXVALUE}][{MINVALUE n | NOMINVALUE}][{CYCLE | NOCYCLE}][{CACHE n | NOCACHE}]
INCREMENT BY n интервал между двумя последовательными номерами; n – целое. По умолчанию n=1. START WITH n первое генерируемое число в последовательности. По умолчанию это 1. MAXVALUE n максимальное значение, которое может генерировать последовательность. NOMAXVALUE максимальное значение по умолчанию, равное 1027. MINVALUE n минимальное значение последовательности. NOMINVALUE задает минимальное значение равное 1. CYCLE | NOCYCLE продолжается ли циклическая генерация чисел после достижения максимального или минимального значения. По умолчанию – NOCYCLE. CACHE | NOCACHE количество чисел, которое сервер Oracle распределяет предварительно и хранит в памяти. По умолчанию сервер хранит в кэш–памяти 20 значений. Псевдостолбец NEXTVAL используется для выборки следующего свободного числа последовательности. Имя NEXTVAL необходимо дополнить именем последовательности. Если вы ссылаетесь на последовательность. NEXTVAL, генерируется следующее число, и текущее число помещается в CURVAL. Псевдостолбец CURVAL используется для ссылки на число, только что сгенерированное текущим пользователем. Прежде, чем обращаться к CURVAL, необходимо использовать NEXTVAL для генерации числа в текущем сеансе пользователя. Имя CURVAL необходимо дополнить именем последовательности. При ссылке на последовательность. CURVAL выдается последнее значение, возвращенное процессу этого пользователя.
Хотя генераторы последовательностей выдают числа без пропусков, это действие выполняется независимо от операций COMMIT и ROLLBACK. Следовательно, при откате команды, содержащей ссылку на последовательность, это число теряется. Еще одна возможная причина пропусков в последовательности – это сбой системы. Значения последовательности, находящиеся в кэш–памяти, при сбоях теряются. Поскольку последовательности не связаны прямо с таблицами, одна и та же последовательность может использоваться в нескольких таблицах. В этом случае пропуски в последовательности чисел могут быть в каждой таблице. Увидеть следующее свободное значение последовательности, не увеличив его, можно только в случае, если последовательность создана с параметром NOCACHE. Для этого выполняется запрос к таблице USER_SEQUENCES. Если последовательность достигла верхнего предела (MAXVALUE), дополнительные значения не предоставляются, и возникнет ошибка. Чтобы продолжать пользоваться последовательностью, можно изменить ее параметры с помощью команды ALTER SEQUENCE. ALTER SEQUENCE последовательность [INCREMENT BY n] [{MAXVALUE n | NOMAXVALUE}] [{MINVALUE n | NOMINVALUE}] [{CYCLE | NOCYCLE}] [{CACHE n | NOCACHE}]
51. Библиотечные функции SQL. Числовые функции.
ROUND(столбец|выражение, n) – Округляет столбец, выражение или значение до n десятичных знаков. Если n опущено, то до целого. Если n отрицательно, округляется целая часть числа. TRUNC(столбец|выражение, n) – Усекает столбец, выражение ил значение до n десятичных знаков. Если n опущено, то до целого. Если n отрицательно, обнуляются разряды целой части числа. MOD(m, n) – Возвращает остаток от деления m на n.
52. Библиотечные функции SQL. Функции символьного типа.
LOWER(столбец|выражение)– Преобразование алфавитных символов в нижний регистр. UPPER – в верхний регистр. INITCAP(столбец|выражение) – Преобразование начальных символов в верхний регистр, остальные преобразуются в нижний регистр. CONCAT(столбец1|выражение1, столбец2|выражение2) – Конкатенация первого символьного значения со вторым. Эквивалентно оператору конкатенации (||). SUBSTR(столбец|выражение, m[,n]) – Возвращает n символов из символьного значения, начиная с позиции m. Если число m отрицательно, то отсчет начинается от конца символьного значения. LENGTH(столбец|выражение) – Возвращает количество символов в значении. NVL(столбец|выражение1, столбец|выражение2) – Возвращает второе значение, если первое NULL.
53. Библиотечные функции SQL. Функции для работы с датой и временем.
Даты в системе Oracle хранятся во внутреннем числовом формате, где представлено следующее:столетие, год, месяц, день, часы, минуты, секунды. SYSDATE – функция даты, возвращает текущие дату и время. Обычно выборка SYSDATE производится из фиктивной таблицы DUAL. Арифметические операции с датами: результатом прибавления числа к дате и вычитания числа из даты является дата; результатом вычитания одной даты из другой является количество дней, разделяющее эти даты; Прибавление часов к дате осуществляется путем деления количества часов на 24
MONTHS_BETWEEN(дата1,дата2) – Определяет количество месяцев между датами 1 и 2.
ADD_MONTHS(дата, n) – К дате прибавляет n календарных месяцев. N может быть отрицательным, но должно быть целым. NEXT_DAY(дата,’символ’) – Определение даты ближайшего дня недели, заданного «символом» после указанной даты. Символ может задавать порядковый номер или название дня недели. LAST_DAY(дата) – Определение последнего дня месяца, содержащего заданную дату. ROUND(дата[,’fmt’]) – При отсутствии аргумента ‘fmt’ – округляет до даты на момент полуночи (до целого числа суток).
54. Библиотечные функции SQL. Функции преобразования типов.
TO_CHAR(число|дата,[‘fmt’]) – Преобразует число или дату в строку с заданной моделью формата. TO_NUMBER(симв) – Преобразует строку, содержащую цифры, в число. TO_DATE(симв,[‘fmt’]) – Преобразует стоку символов с датой в дату с заданным форматом.
SCC или CC – Столетие. S означает, что даты до н. э. получают префикс «–». Годы в датах YYYY или SYYYY – Год. S означает, что даты до н. э. получают префикс «–». YYY или YY или Y – Последние 3, 2 или 1 цифра года. Y, YYY – Год с запятой в указанной позиции. IYYY, IYY, IY, I – 4,3,2 или 1 цифра года в соответствии сос стандартом ISO. SYEAR или YEAR – Год словами. S означает, что даты до н. э. получают префикс «–». BC или AD – Индикатор «до н. э./н. э.». B. C. или A. D. – Индикатор «до н. э./н. э.» с точками. Q – квартал. MM – Месяц в виде двузначного числа. MONTH – Название месяца, дополненное конечными пробелами до 9 символов. MON – Трехбуквенное сокращенное название месяца. RM – Номер месяца римскими цифрами. WW или W – Неделя года или месяца. DDD или DD или D – День года, месяца или недели. DAY – Название дня, дополненное конечными пробелами до 9 символов. DY – Трехбуквенное сокращенное название дня. J – Дата по Юлианскому календарю – количество дней после 31 декабря 4713г. до н. э.
AM или PM – Индикатор «до полудня/ после полудня». A. M. или P. M. – Индикатор «до полудня/ после полудня» с точками. HH или HH12 или HH24 – Время суток, час в 12–часковом или в 24–часовом диапазоне. MI – Минуты (0–59). SS – Секунды (0–59). SSSSS – Количество секунд после полуночи (0–86399).
55. Библиотечные функции SQL. Групповые функции.
работают над мн–ом сторок и выдают один результат на группу. Исп–ть в select и having.
AVG(DISTINCT|ALL|n) – Среднее значение n без учета неопределенных значений, COUNT(DISTINCT|ALL|выражение|*) – Количество строк только с определенными результатами вычисления выражения. По "*" подсчитываются все строки, включая повторяющиеся и строки с неопределенными значениями, MAX(DISTINCT|ALL| выражение) – Максимальное значения выражения, MIN(DISTINCT|ALL| выражение) – Минимальное значения выражения выражения, STDDEV(DISTINCT|ALL|n) – Стандартное отклонение n без учета неопределенных значений, SUM(DISTINCT|ALL|n) – Сумма значений n без учета неопределенных значений, VARIANCE(DISTINCT|ALL|n) – Дисперсия n без учета неопределенных значений.
56. Теория проектирования реляционных баз данных. Избыточность. Аномалии обновления, включения и удаления.
Рассмотрим отношение FIRST (S#, STATUS, CITY, P#, Q). отношение FIRST является «плохим» в смысле наличия избыточности и аномалий. Действительно рассмотрим произвольное тело отношения FIRST
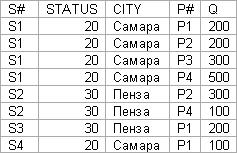
Очевидная избыточность в отношении FIRST приводит к различным аномалиям обновления. Для определенности рассмотри избыточность типа поставщик – город, которая очевидно вытекает из ФЗ S#–>CITY
1. INSERT (аномалия вставки)
Ограничение S#–>CITY означает, что нельзя вставить данные о том, что некоторый поставщик находится в некотором городе до тех пор, пока этот поставщик не поставит хотя бы один товар (P# не NULL).
2. DELETE. Если удалить один из кортежей для некоторого поставщика в связи с отменой поставки товара, то может удалиться не только поставка товара, но и поставщик.
3. UPDATE. Название города для одного поставщика повторяется множество раз, т. е. данное повторение приводит к возникновению проблем при обновлении данных. Например, если поставщик S1 переходит из Самары в Томск, система вынуждена переправлять все строки. Либо эту проблему нужно искать с помощью поисковой системы либо вручную. Таким образом, решение рассмотренных выше проблем заключается в декомпозиции исходного отношения FIRST на несколько проекций.
Например:
SECOND (S#, STATUS, CITY) <– FIRST –> SP (S#, P#, Q)
Действительно, если рассмотреть теперь тело отношения SECOND
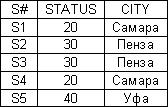
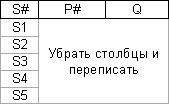
Легко проверить что отношение SECOND не испытывает тех проблем какие были отмечены в отношении FIRST. Действительно:
1. INSERT. Теперь любой поставщик, в любом городе может быть вставлен в SECOND без нарушения целостности.
2. DELETE. Можно любую поставку из SP удалить и это же отразится в SECOND.
3. UPDATE. – любой поставщик, переехавший в другой город, потребует редактирования только одной строки.
57. Функциональные зависимости. Примеры.
Многочисленные примеры реализации связей между отношениями типа многие–к–одному (один–ко–многим)это по сути взаимодействие между множествами атрибутов.
Любое отношение, по определению характеризуется заголовком и телом отношения. При этом одно из уникальных свойств отношения как структуры данных – это статичность и неизменность заголовка и динамичность тела, т е применительно к телу отношения необходимо различать значение этого отношения в какой то конкретный момент времени и набор всех возможных допустимых значений этого отношения. 2 случай – отношение–переменная. Тогда можно дать следующее определение. Пусть R(A1,A2...An) – произвольное отношение с атрибутами A1,A2...An. X, Y принадлежат подмножеству атрибутов A1,A2...An. Тогда Y функционально зависит от X, если каждое значение из множества X в точности связано только с одним значением из множества Y. Функциональная зависимость обозначается XàY : Y функционально зависит от X или X функционально определяет Y.
Например: отношение SCP(S#,City, P#,Q), тогда подмножества![]() , аналогично можно сказать что в этом отношении выполняются след фз:
, аналогично можно сказать что в этом отношении выполняются след фз:
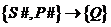
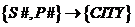
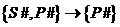
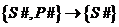
....................
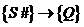
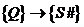
Определение функциональной зависимости говорит о том, что если 2 кортежа относительно R совпадают по атрибутам из Х, то они однозначно совпадают по атрибутам из Y. Связь между определением потенциального ключа и определением функциональной зависимости: левая и правая части функциональной зависимости принято называть детерминантом и зависимой частью. Неплохо было бы чтобы детерминант был ключом. В записи функциональной зависимости подмножество, которое включает один атрибут называется одноэлементный.
Определение 2. (отношения–переменные). Пусть R(A1,A2...An) –отношение–переменная, X, Y – произвольное подмножество атрибутов, тогда Х будет функционально зависеть от Y т и т т к для любого допустимого значения R каждое значение из Х в точности связано с одним значением из Y, т е для любого допустимого значения отношения R, если 2 кортежа совпадают по значению Х, они совпадают и по значению Y.
Из определения следует, если Х – потенциальный ключ, то все остальные атрибуты отношения R автоматически должны быть функционально зависимы от Х. учитывая это ФЗ фактически означает механизм задания ограничения целостности на отношение. Если отношение R удовлетворяет ФЗ АàВ и одновременно при этом А – не потенциальный ключ, то R однозначно характеризуется некоторой избыточностью данных.
Опр. ФЗ тривиальна т и т т к зависимая часть является подмножеством детерминанта.
58. Аксиомы Армстронга функциональных зависимостей.
Проблема размеров множества ФЗ усугубляется тем, что некоторые ФЗ могут означать другие ФЗ. Т е возникает вопрос: а как построить замыкание? Задача построения замыкания представляется достаточно сложной и громоздкой поэтому существует правило вывода Армстронга, которое позволяет по крайней мере ограничить множество ФЗ. Аксиомы:
![]()
А, В,С, D ![]()
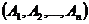
![]() , тогда справедливы следующие правила:
, тогда справедливы следующие правила:
рефлексивность. Если 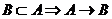
дополнение. Если 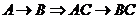
транзитивность. Если ![]() и
и ![]() то
то ![]()
Для упрощения вычислений замыкания ФЗ используется и следующие правила.
Самоопределение ![]()
декомпозиция. Если 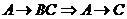 и
и ![]()
объединение. Если ![]() и
и ![]() то
то 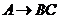
композиция. Если ![]() и
и 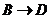 то
то 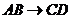
правило Дарвена. Если ![]() и
и 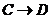 то
то 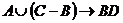
Вывод: 8 правил или аксиом Армстронга позволяют существенно упростить замыкание множества ФЗ.
Например: дано K(A, B,С, D,E, F).
S=![]()
Где А – табельный номер,
B – номер отдела
С – руководитель
D – название проекта
Е – название отдела
F – время, уделенное на проект
Тогда очевидно, что приведение ФЗ отражают реальные ограничения данного отношения:
Табельный номер однозначно определяет номер отдела и руководителя. Докажем что зависимость 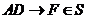 или
или ![]() .
.
Действительно, воспользуемся правилами Армстронга тогда 1) ![]() – дано, тогда согласно декомпозиции 2)
– дано, тогда согласно декомпозиции 2) ![]() согласно дополнению 3)
согласно дополнению 3) ![]() 4)
4) ![]() – дано тогда из 3),4)следует 5)
– дано тогда из 3),4)следует 5) ![]() ,6)
,6)![]()
59. Замыкания множества зависимостей. Примеры.
Проблема размеров множества ФЗ усугубляется тем, что некоторые ФЗ могут означать другие ФЗ. Т е возникает вопрос: а как построить замыкание? Задача построения замыкания представляется достаточно сложной и громоздкой поэтому существует правило вывода Армстронга, которое позволяет по крайней мере ограничить множество ФЗ. Аксиомы:
![]()
А, В,С, D ![]()
![]() , тогда справедливы следующие правила:
, тогда справедливы следующие правила:
рефлексивность. Если
дополнение. Если
транзитивность. Если ![]() и
и ![]() то
то ![]()
Для упрощения вычислений замыкания ФЗ используется и следующие правила.
Самоопределение ![]()
декомпозиция. Если и ![]()
объединение. Если ![]() и
и ![]() то
то
композиция. Если ![]() и то
и то
правило Дарвена. Если ![]() и то
и то
Вывод: 8 правил или аксиом Армстронга позволяют существенно упростить замыкание множества ФЗ.
Например: дано K(A, B,С, D,E, F).
S=![]()
Где А – табельный номер,
B – номер отдела
С – руководитель
D – название проекта
Е – название отдела
F – время, уделенное на проект
Тогда очевидно, что приведение ФЗ отражают реальные ограничения данного отношения:
Табельный номер однозначно определяет номер отдела и руководителя. Докажем что зависимость или ![]() .
.
Действительно, воспользуемся правилами Армстронга тогда 1) ![]() – дано, тогда согласно декомпозиции 2)
– дано, тогда согласно декомпозиции 2) ![]() согласно дополнению 3)
согласно дополнению 3) ![]() 4)
4) ![]() – дано тогда из 3),4)следует 5)
– дано тогда из 3),4)следует 5) ![]() ,6)
,6)![]()
60. Замыкания множества атрибутов. Примеры
Опр. Пусть дано 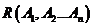 ,
, 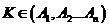
Тогда К – суперключ отношения R если содержит по крайней мере один потенциальный ключ этого отношения. Другими словами суперключом можно назвать такое подмножество атрибутов что 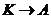 : выполняется для любого атрибута отношения R. тогда предположим, что известны некоторые ФЗ образующие множество S и требуется найти потенциальный ключи этого отношения. По определению потенциальным ключом называется неприводимые суперключи, т е суперключ состоит из одного потенциального ключа, тогда путем выяснения является ли данное подмножество атрибутов суперключом можно в конечном итоге найти и потенциальный ключ.. действительно, существует алгоритм, который позволяет вычислить замыкание произвольного суперключа определенного на множестве ФЗ S. Алгоритм построения замыкания множества атрибутов основан на понятии суперключа, те пусть нам дано произвольное отношение R(A, B,С, D,E, F). В этом отношении есть некоторое множество значений S и есть некоторое начальное значение
: выполняется для любого атрибута отношения R. тогда предположим, что известны некоторые ФЗ образующие множество S и требуется найти потенциальный ключи этого отношения. По определению потенциальным ключом называется неприводимые суперключи, т е суперключ состоит из одного потенциального ключа, тогда путем выяснения является ли данное подмножество атрибутов суперключом можно в конечном итоге найти и потенциальный ключ.. действительно, существует алгоритм, который позволяет вычислить замыкание произвольного суперключа определенного на множестве ФЗ S. Алгоритм построения замыкания множества атрибутов основан на понятии суперключа, те пусть нам дано произвольное отношение R(A, B,С, D,E, F). В этом отношении есть некоторое множество значений S и есть некоторое начальное значение ![]() , которое назовем начальным значением суперключа. Тогда алгоритм вычисления замыкания
, которое назовем начальным значением суперключа. Тогда алгоритм вычисления замыкания ![]() на множестве ФЗ S выглядит следующим образом:
на множестве ФЗ S выглядит следующим образом:
предположим, что замыканием ![]() является начальное значение суперключа
является начальное значение суперключа ![]()
выполним бесконечный цикл, в котором для каждой ФЗ из S проверим, является ли детерминант этой Фз подмножеством ![]() .
.
Если да, то новое значение итерационное замыкание = ![]() объединение зависимая часть данной ФЗ.
объединение зависимая часть данной ФЗ.
Если после выхода из внутреннего цикла итерационное значение замыкания не изменилось, то завершение алгоритма, иначе перейти на пункт 2.
Пример. Пусть отношение R(A, B,С, D,E, F), и множество ФЗ S=![]()
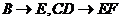
А в качестве начального значения суперключа ![]() =
=![]()
Найти замыкание ![]()
Алгоритм:
предположим, что 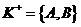
выполним цикл 4 раза, проверив для каждой фз принадлежит ли детерминант ![]() .
. ![]() ,
, ![]() поэтому
поэтому 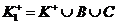
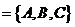
![]() ,
, ![]() ничего не делаем
ничего не делаем
![]() ,
, ![]() ,
, 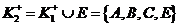
![]() ,
, ![]()
внутренний цикл завершен, но после выхода из цикла ![]() поэтому снова проверяем 4 раза все фз.
поэтому снова проверяем 4 раза все фз.
![]() ,
, ![]()
![]() , т к
, т к ![]() , то
, то ![]()
![]()
![]()
т к после выхода из цикла 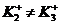 вновь выполняем внутренний цикл.
вновь выполняем внутренний цикл.
легко проверить, что очередная проверка 4 Фз не изменяет значения ![]() . Поэтому на этом и завершаем алгоритм. Замыканием множества атрибутов будет подмножество
. Поэтому на этом и завершаем алгоритм. Замыканием множества атрибутов будет подмножество ![]()
Вывод: из рассмотренного алгоритма можно сделать важное заключение о том, что для заданного множества ФЗ S можно указать будет ли произвольная зависимость ![]() следовать из S поскольку это возможно т и т т к правая часть этой зависимости является подмножеством замыкания
следовать из S поскольку это возможно т и т т к правая часть этой зависимости является подмножеством замыкания ![]() . Т о найден относительно простой способ определения будет ли произвольная ФЗ
. Т о найден относительно простой способ определения будет ли произвольная ФЗ ![]() принадлежать замыканию
принадлежать замыканию ![]() .
.
61. Неприводимое множество зависимостей.
Количество ФЗ в отношении может быть достаточно велико. И требуется свести их число к минимуму, т е к замыканию.
Опр. Пусть ![]() и
и ![]() являются произвольными множествами ФЗ на заданном отношении R. Тогда если любая Фз принадлежащая
являются произвольными множествами ФЗ на заданном отношении R. Тогда если любая Фз принадлежащая ![]() одновременно является ФЗ принадлежащей
одновременно является ФЗ принадлежащей ![]() , то говорят что
, то говорят что ![]() является покрытием для
является покрытием для ![]() .
.
Фактически это означает, что ![]() является подмножеством
является подмножеством ![]() . Возникает вопрос6 а какие множества Фз следует считать одинаковыми.
. Возникает вопрос6 а какие множества Фз следует считать одинаковыми.
Опр2. пусть даны множества ФЗ ![]() и
и ![]() , тогда если
, тогда если ![]() является покрытием для
является покрытием для ![]() , то эти множества называются эквивалентными.
, то эти множества называются эквивалентными.
Замечание: Если множество Фз ![]() и
и ![]() эквивалентны и наложенные на БД ограничения представимы зависимостями из множества
эквивалентны и наложенные на БД ограничения представимы зависимостями из множества ![]() , то эти же ограничения могут быть представлены и фз из
, то эти же ограничения могут быть представлены и фз из ![]() . Верно и обратное.
. Верно и обратное.
До каких пор мы можем сокращать ФЗ.
Опр. Множество ФЗ называется неприводимым т и т т к выполняются следующие свойства6
зависимая часть каждой фз множества S является одноэлементным множеством.
детерминант каждой фз из S является неприводимым, те ни один атрибут в детерминанте не может быть удален без изменения замыкания ![]() (неприводимый слева)
(неприводимый слева)
ни одна фз в S не может быть удалена без изменения замыкания ![]() .
.
Опираясь на определения можно сделать утверждение, что для каждого множества фз существует по крайней мере одно эквивалентное множество, которое является неприводимым.
62. Понятие нормальной формы. Иерархия НФ.
Под процессом нормализации понимается поэтапная декомпозиция исходных отношений, причем т о чтобы эти разбиения были корректными, те без потерь и без приобретения несуществующих данных. В качестве оператора декомпозиции можно использовать различные операции реляционной алгебры. Именно поэтому существуют различные подходы и нормальные формы. Мы будем рассматривать классический метод нормализации, в котором в качестве оператора декомпозиции используют проекцию а в качестве обратной операции – операцию объединения. Поэтому классический метод нормализации часто называют проекционно–соединительным. В результате классического метода нормализации и были получены следующие иерархически зависимые между собой нормальные формы: 1 нф, 2 нф, 3 нф, нФ Бойса–Кодда, 4 нф, 5 нф. Иерархия нФ подчеркивает что отношения в более старшей нФ автоматически находятся в более младших нФ. Разрыв в виде нфбк между 3 и 4 нф был вызван тем, что первоначально Кодд, который получил 3 нф рассуждал с жесткими ограничениями, что отношение может иметь только один потенциальный ключ. Поэтому оригинальное определение Кодда для нФ приводит к некоторой неадекватности, если отношение имеет 2 или более потенциальных ключей. В дальнейшем Фэйгином была описана новая 4 нф а затем и 5 нф. Т о общая идея нормализации заключается в том, чтобы при проектировании ис типа БД можно было использовать отношения в идеальной или окончательной нФ – 5нф. Однако эту рекомендацию нельзя трактовать как догму, т к известно, сто на пратике вполне достаточно получить отношения в нфбк и даже в 3 нф. Замечание связано стем что теория нормализации является не единственным методом проектирования er– диаграмм. Даже если вы используете er диаграммы, то вполне приемлемой является проверка полученных отношений на предмет идеализации.
63. Первая нормальная форма. Примеры.
Любое реляционное отношение автоматически находится в 1 нф, т к все его атрибуты по определению задаваемые на доменах принимают скалярное значение. Первая нормальная форма (1НФ) – это обычное отношение. Свойства отношений (это и будут свойства 1НФ):
В отношении нет одинаковых кортежей.
Кортежи не упорядочены.
Атрибуты не упорядочены и различаются по наименованию.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
