

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
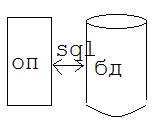
1. Общее представление о базе данных. Примеры.
При проектировании и разработке инфо систем (ис) – это проблема структуры данных, те как описать что нужно запомнить и хранить, а что не следует, те необходимо учесть серьезную специфику БД, огромные массивы данных, те легко можно сравнить ис стандартного типа (пп) и ис БД.
При работе с ис можно ограничиться структурами данных, кот предлагают яп, тем более оояп
Алгоритм + структура данных = прога
В частности ис позволяет хранить большие массивы инфы в файлах. Однако даже файлы не могут быть напрямую использованы в БД, тк обычные файловые системы исп–ся для хранения слабоструктурированных данных, когда детализацию структуры можно и целесообразно перевести в исполнительный код. Такой подход для ис типа БД явл–ся абсолютно неприемлемым.
2. Назначение и основные элементы БД.
Учитывая что БД должны хранить огромные массивы данных и одновременно обеспечивать мгновенный доступ к данным возникла необходимость в создании «спец» файлов БД. Особые фбд по классификации файловых систем относятся к обычным, а не к спец файлам => фбд входит в сост обычной фс и их легко можно увидеть, удалять, управлять с помощью обычных менеджеров файлов.
В чем отличие м/у файлами и ис
1) в отличии от ис, кот исп–ют данные единовременно или временно, ис типа БД предназначены для «вечного» хранения данных (данные кот обрабатывает обычная ис (пп) находятся в оп, а для БД на взу)
2) структура данных ис типа БД во много раз сложнее структуры данных обычных файлов => БД исп–щие сложноструктурированные данные приводит к необходимости создания и обслуживания файлов с чрезвычайно сложной структурой данных, кроме того эта сложная структура требует и оперативного доступа к данным => кроме самих данных БД вынуждена исп–ть огромные массивы метаданных
3) хотя сложная структура данных в разных БД и различна, тем не менее в них сущ–ет много общего по природе структуры, по хранению, по исп–ю => в отличии от обычных ис, ис типа БД применяют и исп–ют такие мощные механизмы ввода–вывода и обмена данных, как экспорт и импорт данных
4) уникальная особенность ис типа БД заключается в статичности структур данных, что позволяет исп–ть эти данные мн–ом различных пп
5) специфика сложных структур данных привела к необходимости создания и хранения на взу особых файлов БД, кот–е исп–ют особые механизмы для размещения, хранения и доступа к данным
Вывод: таким образом для ис типа БД необходимо организовать хранение сложнострук–х данных так, чтобы они были доступны различным БД.
БД–это спец тип ис, предназначенный для хранения больших массивов сложнострук–х данных, связанных м/у собой, предназначенных для описания состояния объектов опр–ой предметной обл–ти.
В кач–ве пользователей БД выступают как пп, так и конечные пользователи, кот–е явл–ся как источниками, так и потребителями данных.
3. Назначение, основные функции и понятие СУБД.
Сис управления БД – комплекс программных и языковых средств необходимых для проектир–я, создания, разработки и поддержки функционирования ис типа БД. Формально СУБД относят к классу пп, однако они имеют черты инструментальных систем. Напр многие СУБД имеют не только текстовый редактор, яп, отладчик, но и компилятор для создания независимых программных модулей.
Осн ф–ии прог типа СУБД:
1) интерфейс, те СУБД представляет спец интерфейс для ввода, редактирования, удаления и просмотра огромных массивов сложнострук–х данных
2) управление данными БД на взу, те именно СУБД обеспечивают реализацию механизмов для хранения сложнострук–х данных и доступа к ним на взу. СУБД «перехватывает» часть ф–ий ос, точнее СУБД взаимодействует с ос
3) управление транзакциями. Транзакция – осн механизм совр СУБД, кот–й позволяет обрабатывать данные БД с сохранением целостности данных
4) журнализация и восстановление данных БД. Феноменальная ф–ия СУБД, те с помощью журнала транзакций СУБД может восстановить любые данные за любой период. Журнал – по сути история сохранения всех операций, кот–е вып–ся над данными БД. Журнал транзакций – log file.
5) Защита данных от несанкционированного доступа. На совр этапе это одна из важнейших ф–ий СУБД, причем она поддерживает мн–во различных уровней, от простейшей авторизации до шифрования данных передаваемых по сети
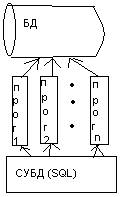
6) Поддержка языковых запросов. SQL – structure query language. Язык структурированных запросов реализует обращение к данным БД, причем в ранних СУБД в силу их специфики поддерживались несколько специализированных языков БД (напр 2) язык опр–ия схемы БД и язык манипулирования данными. SQL объединяет в себе возможности всех языков, более того содержит спец средства опр–ия ограничений целостности данных БД.
4. Логическая структура СУБД.
5. Трёхуровневая архитектура БД.
В соот со стандартом ANSI–SPARC ис БД следует рассм–ть как единую, но 3х уровневую структуру сост–ую из след эл–ов:
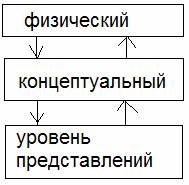
1) концептуальный(логический) уровень отвечает за концептуальную схему сост–ую из сложноструктурированных типов данных связанных м/у собой предназначенных(способных) с высокой степенью приближения описывать состояние и даже поведение конкретной предметной обл–ти, кроме этого логич модель часто дополняется функционалом присущим этой предметной обл–ти. Понятно что логическая модель опр–ет в конечном итоге и БД в целом и физ–ий и внешний уровень в частности
2) внутренний(физический) предназначен для физической реализации долговременного хранения больших массивов сложностук–ых данных => к физич уровню относят как файлы, так и взу, при этом фбд (файлы) имеют оч сложную структуру и поэтому оч сложную физич организацию хранения данных в них, более того, возможностей файловой подсистемы ос оказывается явно недостаточно для организации хранения таких файлов => эту ф–ию полностью берет на себя СУБД. Кроме самих файлов данных физич уровень вкл в себя файлы–метаданные (напр журнал транзакций или индексные файлы, временные файлы)
3) уровень представлений(внешний) служит для представления данных БД и результатов обработки данных БД на внешних устройствах (дисплеях, принтерах, плоттерах) => внешний уровень– интерфейсная часть БД, клиентская часть бД, причем для удобства пользователя внешнее представление может отличаться от структуры внутреннего хранения
6. Жизненный цикл базы данных.
Жизненный цикл БД – это совокупность этапов которые проходит база данных на своём пути от создания до окончания использования.
Часто встречаемые этапы
1. Исследование и анализ проблемы, для решения которой создаётся база данных.
2. Построение Инфологической и Даталогической модели.
3. Нормализация полученных Инфологических и Даталогических моделей. По окончанию этого этапа, как правило получают заготовки таблицы БД и набор связей между ними (первичные и вторичные ключи)
4. Проверка целостности БД (Целостность базы данных)
5. Выбор физического способа хранения и эксплуатации (тех. средства) базы данных.
6. Проектирование входных и выходных форм.
7. Разработка интерфейса приложения.
8. Функциональное наполнение приложения
9. Отладка: проверка на корректность работы функционального наполнения системы
10. Тестирование: тест на корректность ввода вывода данных, тест на максимальное количество активных сессий и т. д.
11. Ввод в эксплуатацию: отладка ИТ–инфраструктуры, обучение пользователей и ИТ–персонала.
12. При необходимости добавления выходных форм и дополнительной функциональности. В случае если необходимы более серьёзные изменения, следует повторить все шаги с первого.
13. Вывод из эксплуатации: перенос данных в новую БД.
7. Архитектура СУБД, как комплекса программ.
Т е возможностей СУБД зачастую недостаточно чтобы напрямую выполнить обработку или представление данных. Поэтому различают 2 принципиально отличные архитектуры БД
1. Двузвенный
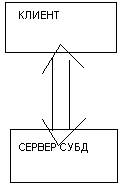
Классическая схема. На SQL большая большая нагрузка
2. трехзвенный
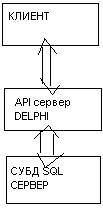
Среднее звено одновременно и клиент и сервер.
8. Краткий обзор dbf–ориентированных локальных СУБД.
DBF – формат хранения данных, используемый в качестве одного из стандартных способов хранения и передачи информации системами управления базами данных, электронными таблицами и т. д.
Достоверно неизвестно, имели ли файлы предшественников dBASE – Vulcan и JPLDIS это расширение, но dBASE II уже использовал DBF–файлы в качестве стандартного формата базы.
В новых версиях – dBASE III, dBASE IV формат файла модифицировался и расширялся. В связи с высокой популярностью этих программ были созданы их многочисленные клоны (обычно их называют общим термином xBASE), некоторые из которых использовали модифицированные версии DBF. То же самое происходило и с целым рядом прикладных пакетов и библиотек, использовавших DBF в различных целях – некоторые их авторы шли по пути добавления новых типов полей, некоторые – вносили серьёзные расширения. В связи с отсутствием какой–то официальной стандартизации в настоящее время достаточно сложно гарантировать, что разрабатываемая прикладная программа будет писать и читать произвольный DBF–файл, но базовая совместимость всё–таки сохраняется.
DBF–файл делится на заголовок, в котором хранится информация о структуре базы (в новых версиях – и о некоторых других характеристиках, например используемой кодовой таблице) и количестве записей и собственно – область данных, представляющую собой последовательно организованную таблицу из записей фиксированной длины. В свою очередь записи делятся на поля также фиксированной длины, которые хранятся в файле непосредственно друг за другом, образуя запись. Первое поле DBF–формата – пометка удаления. Длина поля – 1 символ. Если поле установлено в значение русское «х», то считается, что запись помечена на удаление. Удалённые записи могут быть восстановлены, или физически удалены при выполнении специальной операции, называемой упаковкой (команда PACK xBASE).
С DBF–файлами могут быть так же сопряжены другие файлы – .DBT (dBASE III, IV, Clipper), .FPT (FoxBASE/FoxPRO) и, в некоторых случаях, какие–то ещё, предназначенные для хранения больших объектов переменной длины. .DBT/.FPT–файлы не являются самостоятельными и не могут быть прочитаны без соответствующего им. DBF файла. В связи с этим их описание обычно включают в качестве составной части описания формата. DBF.
9. Краткий обзор серверов баз данных. Informix, Sybase, MS SQL, Oracle.
–Informix – семейство систем управления реляционными базами данных (СУБД), выпускаемых компанией IBM. Informix позиционируется как флагманский корабль IBM для онлайновой обработки транзакций (OLTP), также как и для интегрированных решений.
Informix – СУБД класса Enterprise (корпоративная), подходящая для управления данными в среднем и крупном бизнесе.
Отличается высокой надёжностью и быстродействием, встроенными средствами восстановления после отказов, наличием средств репликации данных и обеспечения высокой доступности, возможностью создания распределённых систем.
Поддерживаются почти все известные серверные платформы: IBM AIX, GNU/Linux (RISC and i86), HP UX, SGI Irix, Solaris, Windows NT (NT, 2000), Mac OS.
В линейку программных продуктов под общим названием «Informix» входят следующие СУБД:
IBM Informix Dynamic Server Enterprise Edition (IDS) Исключительно низкие эксплуатационные расходы, обеспечивающий высокую производительность транзакций в среде OLTP, сервер баз данных для предприятий и рабочих групп. Включает возможности для разработки приложений, обеспечения высокой производительности и доступности данных. Включает возможности улучшения производительности транзакций: гибкое выделение памяти, конфигурируемый размер страниц данных, безопасность данных, внешние директивы оптимизатора. Обеспечивает разные виды репликации между серверами на уровне таблиц (Enterprise Replication technology), а также репликацию c высокой доступностью всех данных сервера (HADR), которая позволяет использовать read_only сервер для отчетов одновременно с применением транзакций с основного сервера. Поддерживает стандартные и определенные пользователем типы данных, включая мультимедийные, графические и текстовые данные. Имеет возможности шифрования данных на уровне полей в таблицах, что соответствует таким стандартам, как Sarbanes–Oxley, Basel II and HIPAA.
IBM Informix Dynamic Server Enterprise Edition with J/Foundation – включает все возможности предыдущей архитектуры плюс возможность создавать пользовательские программы (UDR) на языке JAVA, выполняющиеся непосредственно на сервере Informix.
IBM Informix Extended Parallel Server (XPS) сервер управления базами данных уровня high–end, обеспечивает создание очень больших баз и хранилищ данных для критических бизнес–приложений. Позволяет проводить интеграцию традиционных и Web–based приложений. Включает возможности быстрой загрузки очень больших объёмов данных, и обеспечивает повышенную производительность в среде DSS. Обеспечивает масштабирование для работы с большими объёмами информации. Идеальное решение для объединения данных через среду Интернет, создания комбинированных хранилищ и витрин данных, с возможностью конкурентной загрузки и выполнения запросов.
IBM Informix Dynamic Server (IDS) Express создан для среднего и малого бизнеса, упрощенные процедуры создания и развертывания приложений на основе данного сервера делают его идеальным для небольших решений, когда требуется минимальный уровень администрирования. Включает возможности отказоустойчивости и повышенной производительности. Обеспечивает функции автоматизированного бэкапа и восстановления. Поддерживает широкий набор средств разработки приложений, таких как Eclipse, IBM Rational Application Developer и Microsoft Visual .
IBM Informix OnLine Extended Edition легкий в использовании, встраиваемый сервер управления базами данных для низких и средних нагрузок. Обеспечивает работу в среде OLTP, различные типы данных включая мультимедийные, поддерживает широкий спектр средств разработки приложений.
IBM Informix Standard Engine (SE) встраиваемый сервер баз данных, созданный для разработки небольших приложений, с минимальным администрированием.
IBM Informix Red Brick Warehouse реляционная СУБД для Business Intelligence приложений, объединяет e–business–окружение с легкими для развертывания, использования и администрирования а также низкой стоимостью владения, витринами и хранилищами данных Red Brick.
–Sybase Inc. – пионер среди компаний, специализирующихся на разработке реляционных баз данных, а также других продуктов, связанных со сбором, обработкой и хранением данных. Кроме названия компании, слово «Sybase» также часто используется как наименования наиболее широко известного её продукта – системы управления базами данных Adaptive Server Enterprise.
Основные продукты
Обработка данных
Adaptive Server Enterprise (ASE) – промышленная реляционная СУБД. Самый известный продукт компании
Sybase Adaptive Server Anywhere (ASA) – недорогая, но полнофункциональная реляционная СУБД, подходящая для работы на слабых и средних аппаратных ресурсах и мобильных устройствах (этот продукт является переработанной версией Watcom SQL–сервера). Между ASA и ASE обеспечивается совместимость по реализации SQL, но не на уровне двоичного интерфейса.
Sybase IQ – аналитическая СУБД, предназначена для построения хранилищ данных, принципиально отличается своей внутренней структурой от традиционных реляционных СУБД, что позволяет ей повышать скорость работы аналитических запросов в 50–100 раз
Sybase Replication Server (RS) – Сервер репликации данных между БД различных производителей
Средства разработки
PowerBuilder – собственная среда разработки приложений, с собственным скриптовым языком. Известен своей технологией DataWindow, при помощи которой очень быстро можно создавать формы взаимодействия с базой данных
PocketBuilder – собственная среда разработки мобильных приложений для платформ Pocket PC и Windows Mobile
Workspace – среда разработки сервис ориентированных приложений (SOA) на базе оболочки Eclipse.
Средства проектирования
PowerDesigner – средство проектирования. Включает модели: логические и физические модели данных (физическая модель с возможностями генерации и reverse engineering), анализ бизнес–процессов, анализ требований, объектно–ориентированный анализ с возможностями генерации и reverse engineering, XML–модель
Сервера приложений
Enterprise Application Server – сервер приложений от Sybase. Отличается тем, что в его основе лежит протокол CORBA. Это позволяет ему поддерживать не только J2EE компоненты, но и Java–CORBA, С, С++, ActiveX, .NET, PowerBuilder. Также содержит внутри себя Web–конейнер с поддержкой Servlet/JSP, встроенная JMS–шина, поддержка веб–сервисов.
Интеграция, портальные решения
Unwired Accelerator – портальное решение Sybase. Отличается возможностью разработки приложений для мобильных устройств, большинство действий выполняется без программирования
Unwired Orchestrator – среда для интеграции приложений. Интеграция осуществляется за счет визуального построения бизнес–процессов на базе сервисов. Сервисом может выступать не только веб–сервис, но и хранимая процедура базы данных, файл в файловой системе, сообщение в очереди сообщений и др.
Мобильные решения
OneBridge – Инструмент для защищенной доставки корпоративной почты, PIM данных и приложений на мобильные устройства. Совместим с Microsoft Exchange и Lotus Notes. Поддерживается синхронизация с мобильными устройствами, работающими на базе следующих операционных систем:Windows Mobile (Pocket PC, Pocket PC Phone Edition, и Smartphone), Palm OS 3.5 и выше, Symbian 6.0 и выше, OMA Data Sync (ранее SyncML) 1.0.1 и выше. OneBridge поддерживает более 150 типов мобильных устройств.
Afaria – Инструмент предназначен для администрирования парка мобильных устройств. Поддерживает широкий список типов устройств (Windows Mobile (Pocket PC, Windows Mobile 5.0, сматрфоны),Windows 32, RIM BlackBerry, Palm OS, Symbian), предназначен для работы в различных сетях передачи данных (GPRS/EDGE/3G, W–LAN, например, 802.11b/g, инфракрасные порты, Bluetooth). В функции администрирования включены возможности централизованной установки ПО, конфигурация устройств, инвентаризация, отслеживание лицензий, рассылка документов, backup, защита данных на устройствах и т. п.
–Microsoft SQL Server – система управления реляционными базами данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов – Transact–SQL, создан совместно Microsoft и Sybase. Transact–SQL является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями. Используется для небольших и средних по размеру баз данных, и в последние 5 лет – для крупных баз данных масштаба предприятия, конкурирует с другими СУБД в этом сегменте рынка.
Функциональность
Microsoft SQL Server в качестве языка запросов использует версию SQL, получившую название Transact–SQL (сокращённо T–SQL), являющуюся реализацией SQL–92 (стандарт ISO для SQL) с множественными расширениями. T–SQL позволяет использовать дополнительный синтаксис для хранимых процедур и обеспечивает поддержку транзакций (взаимодействие базы данных с управляющим приложением). Microsoft SQL Server и Sybase ASE для взаимодействия с сетью используют протокол уровня приложения под названием Tabular Data Stream (TDS, протокол передачи табличных данных). Протокол TDS также был реализован в проекте FreeTDS с целью обеспечить различным приложениям возможность взаимодействия с базами данных Microsoft SQL Server и Sybase.
Microsoft SQL Server также поддерживает Open Database Connectivity (ODBC) – интерфейс взаимодействия приложений с СУБД. Версия SQL Server 2005 обеспечивает возможность подключения пользователей через веб–сервисы, использующие протокол SOAP. Это позволяет клиентским программам, не предназначенным для Windows, кроссплатформенно соединяться с SQL Server. Microsoft также выпустила сертифицированный драйвер JDBC, позволяющий приложениям под управлением Java (таким как BEA и IBM WebSphere) соединяться с Microsoft SQL Server 2000 и 2005.
SQL Server поддерживает зеркалирование и кластеризацию баз данных. Кластер сервера SQL – это совокупность одинаково конфигурированных серверов; такая схема помогает распределить рабочую нагрузку между несколькими серверами. Все сервера имеют одно виртуальное имя, и данные распределяются по IP адресам машин кластера в течение рабочего цикла. Также в случае отказа или сбоя на одном из серверов кластера доступен автоматический перенос нагрузки на другой сервер.
SQL Server поддерживает избыточное дублирование данных по трем сценариям:
* Снимок: Производится «снимок» базы данных, который сервер отправляет получателям.
* История изменений: Все изменения базы данных непрерывно передаются пользователям.
* Синхронизация с другими серверами: Базы данных нескольких серверов синхронизируются между собой. Изменения всех баз данных происходят независимо друг от друга на каждом сервере, а при синхронизации происходит сверка данных. Данный тип дублирования предусматривает возможность разрешения противоречий между БД.
В SQL Server 2005 встроена поддержка. NET Framework. Благодаря этому, хранимые процедуры БД могут быть написаны на любом языке платформы. NET, используя полный набор библиотек, доступных для. NET Framework, включая Common Type System (система обращения с типами данных в Microsoft .NET Framework). Однако, в отличие от других процессов, .NET Framework, будучи базисной системой для SQL Server 2005, выделяет дополнительную память и выстраивает средства управления SQL Server вместо того, чтобы использовать встроенные средства Windows. Это повышает производительность в сравнении с общими алгоритмами Windows, так как алгоритмы распределения ресурсов специально настроены для использования в структурах SQL Server.
Разработка приложений
Microsoft и другие компании производят большое число программных средств разработки, позволяющих разрабатывать бизнес–приложения с использованием баз данных Microsoft SQL Server. Microsoft SQL Server 2005 включает в себя также Common Language Runtime (CLR) , позволяющий реализовывать хранимые процедуры и различные функции приложениям, разработанным на языках платформы. NET (например, или C#). Предыдущие версии средств разработки Microsoft использовали только API для получения функционального доступа к Microsoft SQL Server.
–Oracle Database или Oracle DBMS – объектно–реляционная система управления базами данных (СУБД).
Особенности
* MVCC (англ. MultiVersion Concurrency Control) Многоверсионность данных для управления параллельными транзакциями
* Секционирование – позволяет большие структуры базы данных (таблицы, индексы) разбить на меньшие кусочки.
* Автономные транзакции – представляют собой новый метод управления транзакциями. Автономные транзакции позволяют создавать новые подтранзакции (subtransaction), которые могут сохранять или отменять изменения вне зависимости от родительской транзакции.
* Automatic Storage Management Автоматическое управление хранением файлов БД
* Пакеты[2]
* sequence
* Аналитические функции – Ряд запросов, которые сложно сформулировать на обычном языке SQL, весьма типичны. С помощью аналитических функций подобные операции не только проще записываются, но и быстрее выполняются по сравнению с использованием чистого языка SQL.(подсчет сумм, подсчет процентов в группе и т. д)
* Profile manager
* Oracle Label Security[4]
* Streams[5]
* Advanced Queuing
* Flashback Query – ретроспективные запросы, функциональная возможность Oracle RDBMS, позволяющая запрашивать данные так, как если бы это было сделано в заданный момент времени в прошлом.
* RAC (англ. Real Application Clusters)
* Объектно–ориентированные свойства
* Automatic Database Diagnostic Monitoring – Автоматический мониторинг и диагностика БД для выявления проблем производительности и, возможно, автоматической корректировки (если таковая определена администратором)
10. Модель СУБД типа «Файл–Сервер». Распределение функций.
В файл–серверных СУБД файлы данных располагаются централизованно на файл–сервере. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком – высокая загрузка локальной сети.
На данный момент файл–серверные СУБД считаются устаревшими.
11. Модель СУБД типа «Клиент/Сервер». Распределение функций.
Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера (см. Клиент–сервер). Клиент–серверные СУБД, в отличие от файл–серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент–серверных СУБД в самом факте существования сервера (что плохо для локальных программ – в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Примеры: Firebird, Interbase, IBM DB2, MS SQL Server, Sybase, Oracle, PostgreSQL, MySQL, ЛИНТЕР.
12. Двухуровневая архитектура «Клиент/Сервер». "Толстый" и "тонкий" клиенты.
В двухуровневой архитектуре клиенты выполняют простые операции обработки данных, отрабатывают интерфейс взаимодействия с сервером, обращаются к нему с запросами. Большую же часть задач обработки выполняет сервер. Для этих целей он имеет базу данных. В трехуровневой архитектуре вместо единого сервера применяются серверы приложений и серверы баз данных. Их использование позволяет резко увеличивать производительность локальной сети. В абонентскую систему в зависимости от ее производительности загружается клиент, сервер либо сервер с группой клиентов.
Архитектура клиент–сервер постепенно превращается в архитектуру клиент–сеть, в которой используется не один, а множество серверов. Например, в сети Internet их сотни тысяч. Стремление дать возможность работы в сети клиентам, созданным различными производителями, привело к возникновению архитектуры любой клиент – сервер.
Тонкий клиент – снимаем нагрузку с рабочих станций, бизнес–правила сконцентрированы в одном месте и расположены близко к данным и, как следствие, при их исполнении нет бессмысленной пересылки информации между клиентом и сервером БД; отвязываем бизнес–правила от ЯП клиента – упрощается задача построения дополнительных GUI (WEB, Pocket). В минусах только то, что язык ХП СУБД сильно ориентирован на работу с массивами данных и не имеет никакого отношения к ООП.
13. Трехуровневая архитектура «Клиент/Сервер». API–компонент системы.
В двухуровневом клиент–серверном приложении, как правило, все функции по формированию пользовательского интерфейса реализуются на клиенте, все функции по управлению данными – на сервере, а вот бизнес–правила можно реализовать как на сервере используя механизмы программирования сервера (хранимые процедуры, триггеры, представления и т. п.), так и на клиенте. В трехуровневом приложении появляется третий, промежуточный уровень, реализующий бизнес–правила, которые являются наиболее часто изменяемыми компонентами приложения Наличие не одного, а нескольких уровней позволяет гибко и с минимальными затратами адаптировать приложение к изменяющимся требованиям бизнеса.
Попробуем все вышеизложенное проиллюстрировать на маленьком примере. Предположим, в некоей организации изменились правила расчета заработной платы (бизнес–правила) и требуется обновить соответствующее программное обеспечение.
1) В файл–серверной системе мы "просто" вносим изменения в приложение и обновляем его версии на рабочих станциях. Но это "просто" влечет за собой максимальные трудозатраты.
2) В двухуровневой клиент–серверной системе, если алгоритм расчета зарплаты реализован на сервере в виде правила расчета зарплаты, его выполняет сервер бизнес–правил, выполненный, например, в виде OLE–сервера, и мы обновим один из его объектов, ничего не меняя ни в клиентском приложении, ни на сервере баз данных.
Windows API (application programming interfaces) – общее наименование целого набора базовых функций интерфейсов программирования приложений операционных систем семейств Windows и Windows NT корпорации «Майкрософт». Является самым прямым способом взаимодействия приложений с Windows. Для создания программ, использующих Windows API, «Майкрософт» выпускает SDK, который называется Platform SDK и содержит документацию, набор библиотек, утилит и других инструментальных средств.
Версии
* Win16 – первая версия Windows API для 16–разрядных версий Windows. Изначально назывался просто Windows API, затем стал называться Win16 для отличия от Win32.
* Win32s – подмножество Win32, устанавливаемое на семейство 16–разрядных систем Windows 3.x и реализующее ограниченный набор функций Win32 API для этих систем.
* Win32 – 32–разрядный API для современных версий Windows. Самая популярная ныне версия. Базовые функции этого API реализованы в DLL kernel32.dll и advapi32.dll; базовые модули GUI – в user32.dll и gdi32.dll. Win32 появился вместе с Windows NT и затем был перенесён (в несколько ограниченном виде) в системы серии Windows 9x. В современных версиях Windows, происходящих от Windows NT, работу Win32 GUI обеспечивают два модуля: csrss. exe (Client/Server Runtime Subsystem), работающий в пользовательском режиме, и win32k. sys в режиме ядра. Работу же системных Win32 API обеспечивает ядро – ntoskrnl. exe
* Win64 – 64–разрядная версия Win32, содержащая дополнительные функции для использования на 64–разрядных компьютерах. Win64 API можно найти только в 64–разрядных версиях Windows XP, Windows Server 2003, Windows Vista, Windows Server 2008 и Windows 7.
14. Типы моделей БД. Иерархическая и сетевая модели данных.
Осн проблема проектирования и разработки любой БД это выбор структуры данных. Сущ–ет спец методика в основе кот–й лежит тип модели данных, включающий мн–во структур данных, связей м/у ними, ограничений целостности и операций манипулирования данными, причем необходимо помнить что процедура моделирования данных осущ–ся для конкретной предметной обл–ти, те модель данных позволяет представить объекты предметной обл–ти и реализовать сущ–ие м/у ними связи. Сейчас исп–ся 3 базовых модели и смешанные модели данных
1) иерархическая модель данных (ИМД) основана на математическом
аппарате. Теория графов. Метод мат моделирования – фундаментальный метод прикладной математики для проектирования и разработки ис
этапы: – анализ предметной обл–ти: выделение осн сущностей, параметров, свойств и тд. Оценка сложности задачи.
– выбор мат аппарата, соответствующего сложности задачи
– построение мат модели (сис ур–ий, инфо модель)
– «решение» полученной сис ур–ий, задачи (для этого необходимо исп–ть численные алгоритмы и проги)
– построить ис
– апробация внутренней модели
Те искомая предметная обл–ть, ее сущности, связи м/у ними отображаются в виде ориентированного графа или дерева. К основным понятиям имд относят уровень дерева, Эл–т или узел и связь. Узел – совокупность атрибутов (параметров), описывающих конкретный объект, на схеме имд узлы представляются вершинами графа. Дуги м/у вершинами обозначают связи м/у сущностями. В имд каждый дочерний узел связан только с одним родительским узлом (кроме вершины дерева), те зависимые и подчиненные узлы находятся на 2,3 и тд уровнях. Кол–во деревьев в БД опр–ся числом корневых записей
Имд имеет очевидные достоинства и недостатки
1) в имд автоматически поддерживается целостность ссылок м/у предками и потомками, те действует правило: никакой потом не может сущ–ть без своего родителя (тогда как в реляционных моделях все нужно задавать)
2) структура данного дерева позволяет реализовать мгновенный поиск данных
недостатки: 1) проблемы с удалением и вставкой новых узлов. Главный недостаток – катастрофическая избыточность данных, поэтому вместо иерархических моделей используют сетевые.
2) Сетевые. Тождественна имд. Но здесь любой потомок может иметь несколько родителей
3) Реляционная модель. 99,9% совр СУБД. В основе отношения и связи м/у ними.
15. Реляционная модель данных. Структура. Общее представления.
Введение в реляционные модели данных
Осн проблема при проектировании и разработке ис в частности БД состоит в выборе (проектировании) структур данных, кот способны не только хранить огромные массивы сложноструктурированных данных но и обеспечить мнгновенный доступ к ним, а значит и быструю обработку. => выбор реляционной модели данных должен быть обоснован и основан на строгом мат аппарате. В соот–ии с наиболее распространенной толковкой принадлежащей Дейту РМД следует рассматривать в 3х аспектах: а)структурном; б)целостном; в)манипуляционном.
структура реляционной модели данных
в основе рмд лежит идея о том что все исп–мые ею данные должны иметь простой тип(текстовый, числовой). Она не накладывает жестких ограничений, тк в теории рмд трактуется так: в реляц операциях не должна учитываться внутренняя структура данных, тем не менее, должны быть формализованы опр–ые операции над конкретными типами данных, напр известно что над числовыми данными разрешена операция арифм сложения, а над строковыми данными конкотинация. Осн структурным типом рмд явл–ся структура данных отношение, с кот тесно связано понятие домена. Домен характеризуется след св–ми: в пределах одной БД домен должен иметь уникальное имя; домен опр–ся на простом типе данных, либо на др домене; домен может иметь некоторое логическое условие (ограничение), позволяющее описать (конкретизировать) подмн–во данных простого типа; домен несет опр–ую смысловую нагрузку.
Пр. домен–номер месяца 1<=N_month<=13. ShortInt, Byte, I2
Отличие домена от подмн–ва простого типа сост в том что домен отражает семантику опр–ую предметной обл–тью, напр может быть несколько доменов совпадающих как подмн–во простого типа, но несущих различный смысл, конкретно возьмем домен 1<=«возраст сотрудника» I2<=99, 2ой домен 1<=«кол–во сотрудников» I2<=99, эти домены опр–ны на одном подмн–ве данных, но у них абс–но разный смысл, их нельзя складывать умножать сравнивать, те осн смысловое значение доменов сост в том что они ограничивают сравнение данных, в частности не корректно сравнивать значения из различных доменов, даже если они одного типа. Понятие домена позволяет корректно моделировать предметную обл–ть с помощью рмд.
Отношение как структура данных задается с помощью заголовка отношений и тела отношений. Заголовок структура вида R(A1, A2... An), где R–имя отношения Ai–атрибуты. Атрибутом отношения наз–ся пара (Ai, Di), где Di–домен, те каждый атрибут опр–ся на конкретном домене, можно считать что атрибут и домен одно и то же, но есть одно но в отличии от домена имя атрибута должно быть уникально только в пределах данного отношения. Тело отношения состоит из мн–ва кортежей, под кортежем понимается мн–во (A1Val1, A2Val2...). Кортеж – декартово произведение значений атрибутов. Число атрибутов в отношениях наз–ют степенью или арностью отношений. Напр. отнош–е Student(N_z, Fam, Im, D_r, Rost, N_gr, Photo); кортеж: («03,06», Иванов, Иван, 13,07,88, 1,95, 12201,10, :)). Мощность мн–ва кортежей отношения называют мощностью отношения. Отношения как структура данных обладает 2мя уникальными св–ми, на этом и основана работа всех БД: заголовок отн–ия статичен и не меняется никогда в данной БД, напр если в отн–ии изменить удалить добавить хотя бы один атрибут это по опр совсем др БД; тело отн–ия динамично и может изменяться во время работы БД сколько угодно. Вывод:рбд: набор отношений+связи м/у ними, схема рбд – набор заголовков и связь м/у ними.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
