
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Алгоритмы сохранения результатов оптического распознавания.
,
В статье рассматриваются алгоритмы сохранения и представления результатов распознавания, являющиеся важной составной частью программ оптического распознавания. Для известных форматов хранения данных поставлен ряд специфических задач, требующих согласования и преобразования результатов распознавания образа документа.
1. Алгоритмы сохранения результатов как составная часть OCR
Программы оптического распознавания (OCR) для преобразования отсканированного образа документа в текстовое представление содержат несколько последовательно выполняемых этапов [1], таких как:
- бинаризация полутонового изображения
- сегментация страницы (нахождение текстовых фрагментов, иллюстраций, разделительных линий, таблиц)
- формирование текстовых строк
- распознавание текстовых строк
- сохранение результатов (далее СР).
В то время как алгоритмы бинаризации, сегментации и распознавания страницы часто описываются в литературе [2,3,4], этап СР обычно не рассматривается в качестве существенной задачи обработки страницы для OCR. Между тем, СР в различных формах – это одна из важнейших задач ввода страницы. Во-первых, именно сохранение демонстрирует пользователю возможности OCR. Во-вторых, являясь финальным этапом, сохранение позволяет обработать всю накопленную информацию для получения оптимального представления распознанного документа в каком-либо текстовом формате.
Пользователь OCR может сохранять результаты для одной из следующих целей:
- переноса распознанной информации в другой электронный документ
- сохранение информации в отдельном электронном документе для последующего хранения
- сохранение информации в отдельном электронном документе для последующей распечатки.
Эти цели требуют различной степени распознавания и сохранения структуры документа.
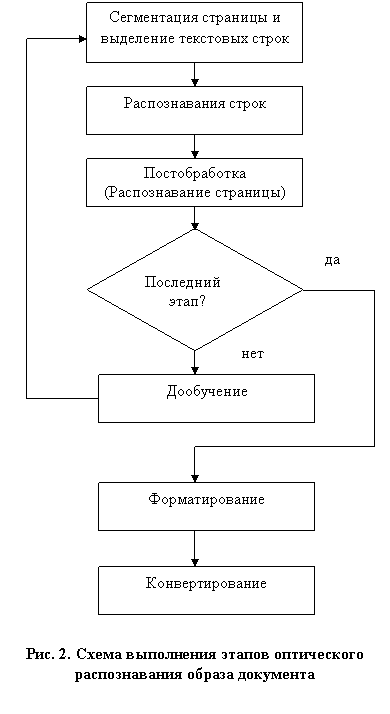
Мы будем разделять в СР три задачи: постобработку, форматирование и конвертирование. Конвертирование представляет собой технический этап формирования некоторого текстового формата (истинный текст, RTF, PDF) с помощью распознанных символов и их атрибутов. Под форматированием будем понимать алгоритмы преобразования распознанной информации с точки зрения оптимального конвертирования в конкретный формат. Очевидно, что конвертирование в различные форматы может потребовать различной подготовительной обработки результатов распознавания для использования возможностей разных текстовых форматов. Например, сохранение в текст таблицы, созданной в Microsoft Word стандартными шрифтами Windows (далее в работе без специальных оговорок будут рассматриваться только примеры текстов, созданных в этих же условиях) и адекватно распознанной, может потребовать согласования расположения текстовых строк, вообще говоря, неоднозначного (см. рис.1).
Таблица, | строки содержащая | + различных | шрифтов |
Таблица, содержащая | строки |
различных | шрифтов |
Таблица, | содержащая | строки + различных | шрифтов |
Рис. 1. Пример неоднозначного конвертирования строк таблицы в текстовом представлении
Постобработкой назовем процесс согласования характеристик различных объектов после выполнения некоторого этапа распознавания документа. Целью постобработки является улучшение атрибутов текстовых символов (типы шрифтов, размеры) и классификации объектов сегментации документа. Например, определение кегля (размера) символов в текстовых строках может выполняться для каждой строки отдельно, а впоследствии уточнено после окончания распознавания всех строк на этапе постобработки всех строк. Другим примером служит процесс отделения текстовых символов от элементов иллюстраций, выполняемый как до начала, так и после распознавания текстовых строк. В обоих случаях в процессе постобработки структура страницы может измениться.
На рис. 2 представлена упрощенная типичная схема многопроходного распознавания документов [5], в которой отражены также этапы СР. Из этой схемы понятно, что постобработку выполняется после завершения очередного этапа распознавания строк, а форматирование и конвертирование производятся в конце сессии оптического распознавания.
2. Постобработка
Вообще говоря, постобработка является частью распознавания страницы, которое в отличие от распознавания отдельных строк адаптируется к особенностям вводимого документа. Улучшение результатов распознавания достигается за счет анализа (например, кластерного анализа) и учета статистических характеристик объектов распознавания, таких как символы, слова, строки, группируемые в достаточно представительные последовательности.
Постобработка как составная часть алгоритмов СР, преследует цели согласования характеристик распознанных символов, обеспечивает возможность сохранения структуры документа, близкой к исходному документу. В процессе распознавания возможно определение различных характеристик символов таких как
- тип шрифта: серифный (Times New Roman), бессерифный (Arial), узкий (Arial Narrow)
- курсив
- жирность (полужирность)
- подчеркивание (перечеркивание)
- кегль (размер)
- приподнятость (верхний индекс) и опущенность (нижний индекс).
Как правило, характеристики предполагаются одинаковыми для всех символов одного слова, что, безусловно, справедливо для недекоративных шрифтов.
 |
 |
На примере признака курсива рассмотрим проблемы его определения и его связь с проблемами последующего форматирования. Обратим внимание на пример ошибочного определения курсива на рис. 3, из которого видно, как отсутствие атрибута курсива (а – исходная строка) либо расширяет границы строки (б), либо производит перенос строки при фиксированных границах (в).
Определение курсива символов печатного текста в многопроходной схеме распознавания нами производилось следующим образом. На самом первом проходе некоторые из уже распознанных образов символов подвергались экспертизе на предмет принадлежности множеству известных курсивных начертаний этого символа. Для этого применялись либо непосредственные алгоритмы-детекторы курсива, либо методы распознавания символов, обладающие способностью различения курсивных и прямых образов. Мы в качестве непосредственного детектора курсива применяли анализ наклонов линейных объектов в топологическом представлении образа, а в качестве методов распознавания курсивных символов - алгоритмы сопоставления с эталонами [4]. Далее курсивность распространяется на соседние в слове образы так, чтобы в одном слове не было прямых и курсивных образов одновременно. Таким образом, одна часть распознанных символов относятся к классу курсивных букв, другая – к классу прямых букв, оставшиеся образы составляют класс с неопределенным признаком курсива. Классификация образов с точки зрения курсива используется в обучении (переобучении) как для повышения точности обучения, так и для уточнения курсивности на последующих проходах распознавания. Последнее возможно из-за того, что символы, получившие признак курсивности не непосредственно, а по соображениям однородности курсива в слове, и подтвердившие этот признак в процессе обучения [5], образуют после обучения эталонный курсивный (или прямой) класс в построенном шрифте. На следующем проходе распознавания формирование признака курсива происходит с использованием построенных эталонных классов. Неопределенные с точки зрения признака курсива слова и группы символов могут быть отнесены к тому или иному классу впоследствии как по соображениям однородности, так и для целей форматирования (см. пример на рис. 3).
Формализуем описанные идеи. Пусть алгоритм распознавания символов представляет результаты в виде коллекции альтернатив
{ (S1,w1), … , (Sn,wn) } (1)
где Si – код символа, также называемый кодом альтернативы, 1 £ i £ n
wi – вероятностная оценка символа, также называемая оценкой альтернативы
n – объем коллекции, n ³ 0. Альтернативы упорядочены по убыванию оценок.
Пусть алгоритм классификации курсива образа, рассматриваемого как символ S, также в виде коллекции альтернатив
{ (H0(S), W0), (H1(S),W1), (HD(S),WD) } (2)
где H0(S) – признак прямого образа, H1(S) - признак курсивного образа, HD(S) - признак сомнительности, то есть невозможности отнесения образа символа S к классам прямых или курсивных букв, а Wi – вероятностные оценки соответствующих гипотез (2). Тогда первичная коллекция (1) может быть записана в виде
![]() (3)
(3)
где ![]() - гипотеза об отнесении образа к классу i символа Si и классу курсива jÎ{0,1,D} с оценкой
- гипотеза об отнесении образа к классу i символа Si и классу курсива jÎ{0,1,D} с оценкой ![]() = wi ·Wj. Затем, на основе коллекций (3) альтернатив для каждого символа производилась голосующая классификация слова, состоящего из последовательности символов между разделяющими знаками. Надежные случаи классификации определяются одним или несколькими символами слова с одинаковым признаком курсива при отсутствии символов с другим типом курсива. Оставшимся словам назначается не признак курсива, а эвристически вычисленные (с помощью
= wi ·Wj. Затем, на основе коллекций (3) альтернатив для каждого символа производилась голосующая классификация слова, состоящего из последовательности символов между разделяющими знаками. Надежные случаи классификации определяются одним или несколькими символами слова с одинаковым признаком курсива при отсутствии символов с другим типом курсива. Оставшимся словам назначается не признак курсива, а эвристически вычисленные (с помощью ![]() ) оценки соответствия всем трем классам: прямому, курсивному и неопределенному. Надежные случаи фиксируют признак курсива, как для целей обучения, так и для финального форматирования. Сомнительные слова получат признак курсива на более позднем этапе форматирования, который учтет оценки признака курсива.
) оценки соответствия всем трем классам: прямому, курсивному и неопределенному. Надежные случаи фиксируют признак курсива, как для целей обучения, так и для финального форматирования. Сомнительные слова получат признак курсива на более позднем этапе форматирования, который учтет оценки признака курсива.
Формирование других атрибутов в многопроходной схеме распознавания осуществляется аналогично. Для атрибута подчеркивания мы использовали результаты работы алгоритмов нахождения геометрических линий, а для определения кегля и типа индексов – алгоритмы нахождения базовых линий в текстовых строках [6]. Отметим важность определения декоративных полиграфических шрифтов, которые не могут быть адекватно отображены стандартными шрифтами Windows.
Этап постобработки по каждому из атрибутов распознанных слов обеспечивает разбиение на два множества, одно из которых обладает фиксированным значением атрибута, а другое, содержащее слова с оценкой сомнительного атрибута, который может быть уточнен на этапе форматирования.
Отметим, что сходные задачи распознавания страницы и постобработки, вообще говоря, не тождественны. Это видно из рассмотренного примера определения признака курсива. С точки зрения распознавания важна классификация образов символов как курсивных, так и некурсивных. Умение разделять символы на курсивные и некурсивные не является необходимым свойством распознающего механизма. Более того, результаты определения курсива могут быть представлены не во всех текстовых форматах, при сохранении результатов распознавания в простой текст определение курсива становится ненужным.
Скажем об отличие целей постобработки и форматирования. Уточнение и согласование характеристик распознанных образов, производимое на этапе постобработки, ориентируется только на индивидуальные и групповые геометрические свойства этих образов, в то время как на этапе форматирования может производиться изменение различных характеристик символов, связанное не с их собственными свойствами, а с потребностями отображения документа в каком-либо текстовом формате. В основном при форматировании меняются характеристики образов из слов, отнесенных к ненадежно определенному классу D.
3. Форматы хранения результатов распознавания
Результаты распознавания могут сохраняться в различном виде, определяемом стандартами существующих текстовых форматов. В настоящее время наиболее широко известны структурный формат RTF и простой текст, служащие для хранения и обмена информацией между приложениями, в том числе между OCR и потребителями распознанных документов.
Формат RTF предоставляет достаточные средства для представления документа, такие как шрифты и атрибуты символов, а также отображение структуры документа. В дальнейшем будем рассматривать именно этот формат как основной для СР. Рассмотрим формат RTF с точки зрения модели документа, обладающего структурой. Объекты формата RTF обладают иерархическим характером. Основные объекты с точки зрения форматирования - это секция, колонка и фрейм. Секция состоит из одного или более колонок и фреймов. Колонка в свою очередь состоит из одного или более терминальных фрагментов, являющихся текстовым блоком, картинкой или таблицей. Фрейм - это фрагмент, который находится внутри рамки и имеет собственные относительные (страницы, секции или колонки) координаты. Отметим некоторые отличия колонок и фреймов. При пересечении с фреймами колонки обтекают фреймы и таким образом содержимое колонок остаются видимыми. Размещение текста с помощью колонок обладает также отрицательными свойствами. Если исходное содержимое колонки в ней не умещается, то остаток переносится в следующую колонку, а при переполнении последней колонки остаток переносится на следующую страницу (рис 4). Тем самым текстовые строки могут и изменять свое местоположение в пределах одной страницы, и покидать ее пределы. В обоих случаях при использовании формата RTF с колонками структура результатов распознавания документа изменяется.
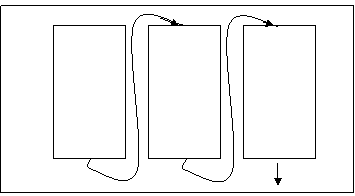 |
Рис. 4. Колонки формата RTF
Фреймы в отличие от колонок трудно просмотреть, редактировать и как окончательный результат использовать при печати документа. Допустим, наш документ состоит из двух текстовых фрагментов и одного фрагмента картинки (рис 5). Все фрагменты объявим фреймами. По двум соображениям результат нас не должно устраивать. Во-первых, картинка перекрывает содержимое текстовых фрагментов, поэтому для просмотра и редактирования картинку необходимо сместить в другое место. Во-вторых, если после просмотра и редактирования мы вернем картинку на свое место, то результат нельзя распечатать. Можно поступить иначе. Раздвинув все фреймы так, чтобы они не пересекались, мы облегчим редактирование, но исказим метрику документа.
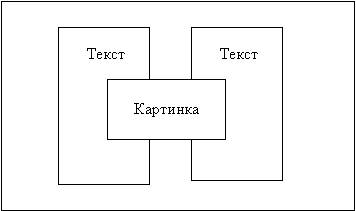 |
Рис. 5. Пересечение фреймов формата RTF
Поэтому с точки зрения удобства редактирования число использованных фреймов должно быть минимизировано.
Текстовый формат, появившись самым первым, является наиболее простым, состоя из последовательности текстовых символов в определенной кодировке, перемежаемых малым числом служебных символов, таких как перенос строки или табуляция. В текстовом формате отсутствуют структурные понятия, свойственные формату RTF, поэтому отобразить данные из формата RTF в обычный текстовый формат без потерь не всегда возможно, прежде всего из-за невозможности простого текста отображать немоноширинные шрифты различного кегля. Тем не менее, частичное сохранение структуры текста вполне возможно. Например, многоколоночный текст может быть преобразован из RTF в текстовое представление таким образом, чтобы соотношения между координатами левых верхних углов фрагментов сохранялись и в простом тексте. Возможно и сохранение выравнивания текстовых строк за счет использования пробелов. При этом соответствия между правыми нижними углами фрагментов могут быть утрачены, также как и метрические соотношения между отдельными фрагментами.
Для хранения результатов может быть использован внутренний формат хранения результатов OCR, проектируемый таким образом, чтобы сохранять свойства RTF формата и иметь возможность конвертирования в текстовый формат. Внутренний формат может наследовать свойства результатов распознавания, которые не могут быть сохранены в любых внешних форматах, в том числе в - формате RTF. Например, альтернативное распознавание символов, которое может использоваться в полнотекстовой индексации текстов, не поддерживается в RTF, но тривиально может быть реализовано во внутреннем формате данных OCR.
4. Форматирование
Сначала поясним цель форматирования в оптическом распознавании образа документа. К началу форматирования известны распознанные строки, привязанные к фрагментам документа, и фрагменты, привязанные к образу документа. Все фрагменты взаимосвязаны с точки зрения упорядоченности их координат. От сохраненных во внутреннем формате или в формате RTF мы ожидаем приближенного сохранения (приближенного) метрических отношений между объектами получившейся структуры, а также абсолютных размеров страницы и используемых шрифтов при печати распознанного документа. Под приближенным сохранением метрических отношений понимается то, что линейная характеристика (ширина, высота, расстояние до другого объекта) X исходного фрагмента соответствует близкая по величине характеристика X¢ в сохраненном фрагменте:
|X-X¢ |= d
где d - заранее заданная погрешность форматирования. Поясним, что измерение характеристики X¢ производится либо в приложении-редакторе, отображающем координаты элементов, составляющих документ, либо в распечатанном на бумаге образе. Аналогично оценивается сохранение размеров документа. Оценка сохранения шрифтов производится по их типам, характеристикам и абсолютным размерам.
Форматирование в структурный формат (RTF или внутренний) включает в себя алгоритмы преобразования результатов распознавания средствами используемого формата в одной или нескольких целях
- наилучшего показа документа
- сохранения метрических отношений получившейся структуры по отношению к исходной
сохранения максимума распознанных символов.
Очевидно, что при форматировании документов с достаточно сложной структурой для достижения целей требуется производить изменения в результатах. Но изменение в одном из фрагментов должно учитываться во всех остальных фрагментах. При сложных структурах образа документа учитывать взаимные связи каждого фрагмента с другими фрагментами без учета логической структуры документа превращается в очень трудоемкую задачу. Кроме того, ошибки распознавания вносят дополнительные искажения в формирование границ колонок и фреймов, вследствие чего мы можем потерять адекватность результата к образу документа.
Очевидно, что для решения задачи необходимо минимизировать зависимости фрагментов. Необходимо построить логическую структуру документа, то есть разбить фрагменты документа на автономные группы, соответствующие секциям и колонкам в структурных документах.
Именно на этапе форматирования решается задача окончательного определения логической структуры, в дальнейшем используемой на этапе конвертирования. Другими словами форматирование занимается оптимизацией количества фрагментов с точки зрения их оптимального показа и редактирования в разных условиях.
Итак, для хранения результатов распознавания необходимо, прежде всего, произвести структурный анализ документа, разбить фрагменты на взаимодействующие группы логически связанных единиц. Другими словами, упрощая структуру декомпозицией, мы уменьшаем трудоемкость задачи учета взаимосвязей внутри автономных групп по отношению ко всей странице. При использовании алгоритмической декомпозиции проблема разбивается на фундаментальные функциональные единицы (в нашей модели это сектора, колонки, фреймы). После этого каждая единица реализуется как набор связанных единиц.
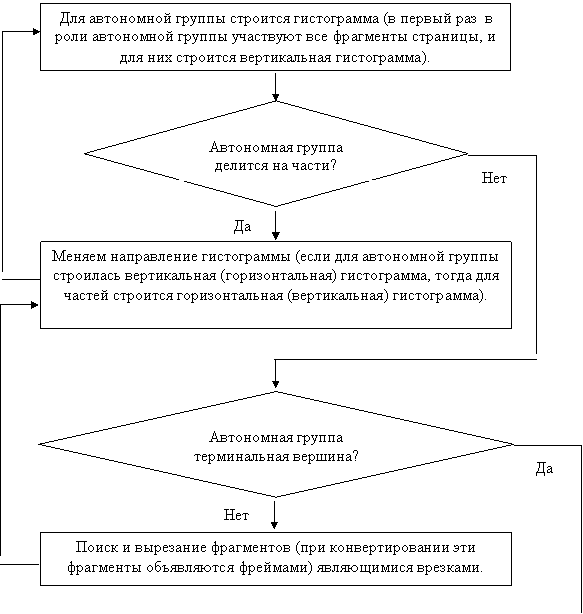
Для нахождения структуры страницы мы использовали метод "белых коридоров", восходящий к древовидным алгоритмам [9]. В процессе работы метода образуется дерево страницы, состоящее из автономных групп – ветвей дерева, состоящих из фрагментов. То есть фрагмент (текстовый блок, картинка или таблица) является терминальной вершиной построенного дерева.
Для нахождения точек ветвления дерева мы применяли горизонтальные и вертикальные гистограммы проекций автономных групп на горизонтальную и вертикальную ось. На одной гистограмме может быть один или несколько минимумов, соответствующих белым коридорам, также гистограмма может ни иметь одного минимума. В последнем случае происходит удаление одного или нескольких фрагментов, оптимальное с точки зрения минимума количества информации, содержащейся в них. Удаленные фрагменты не пропадают, а воспроизводятся в дальнейшем в качестве фреймов.
Блок-схема метода "белых коридоров" приведена на рис. 6. Приведем пример нахождения структуры страницы (см. рис. 7) с помощью метода "белых коридоров". Работа алгоритма состоит из нескольких этапов:
- Горизонтальное деление. Документ делится на три автономные группы. Назовем эти группы секторами. Первый и третий сектора содержат по одному терминальному фрагменту. Эти терминальные фрагменты соответственно объявим колонками. Второй сектор содержит не терминальный фрагмент. Поэтому в этом секторе производится вертикальное деление.
- Вертикальное деление. Фрагмент второго сектора делится на две части. Оба фрагмента не терминальные.
- Горизонтальное деление. Первый фрагмент(T0,1,0) не делится. Второй фрагмент делится на две части(T0,1,1,0 и T0,1,1,1). В дальнейшем T0,1,1,0 и T0,1,1,1 объединяются и T0,1,1 объявляется колонкой.
- Вертикальное деление. Вырезается фрагмент F. T0,1,0 делится на две части. T0,1,0,0 и T0,1,0,1 объявляется колонками.
В результате получим внутрисекторные и внутриколоночные зависимости фрагментов. Если по какой то причине размеры фрагмента T0,1,1,0 нам необходимо увеличить, тогда изменение параметров T0,1,1,0 необходимо учитывать при расчетах параметров колонки T0,1,1. В свою очередь изменение параметров T0,1,1 необходимо учитывать при расчетах параметров второго и третьего сектора. Изменения внутри одного сектора не затрагивают оставшиеся фрагменты. Это же свойство облегчает проецирование результата в RTF формат.
В процессе форматирование решается несколько задач, касающихся относительно оптимального размещения строк во фрагментах, таких как объединение строк в абзацы, соответствия типа и размера шрифта строки к реальным параметрам фрагментов, коррекция реальных координат строк относительно координат фрагмента. Остановимся на алгоритме выравнивания абзацев.
 |
 |
Рис. 6. Алгоритм «белых коридоров»
Выше мы рассмотрели межфрагментные связи. А теперь рассмотрим вопрос объединения строк в абзацы внутри текстовых фрагментов и табличных ячеек, и их тип выравнивания. Для этого используются два массива признаков. Первый массив признаков { C1, … ,Cn } необходим при разбиении текстовых фрагментов на абзацы. Обычно признаком начала нового абзаца в текстовых фрагментах является
- явное изменение типа выравнивания строки
- знаки пунктуации
- межстрочные расстояния
Иногда разделителем, то есть началом нового абзаца может быть строка, отличающаяся курсивным шрифтом, жирностью, подчеркиванием или размером шрифта. Перечисленные признаки Ci можно рассматривать в качестве точек ветвления текстового фрагмента на абзацы. Полученные абзацы необходимо выравнивать. Как известно абзацы выравниваются
- по левому краю
- по центру
- по правому краю
- по ширине
Для выравнивания используется второй массив признаков, свойственные разным типам выравнивания. Например, выровненный по ширине абзац от других типов отличает тот факт, что при этом выравнивании расстояния между словами могут быть больше чем двойная ширина буквы.
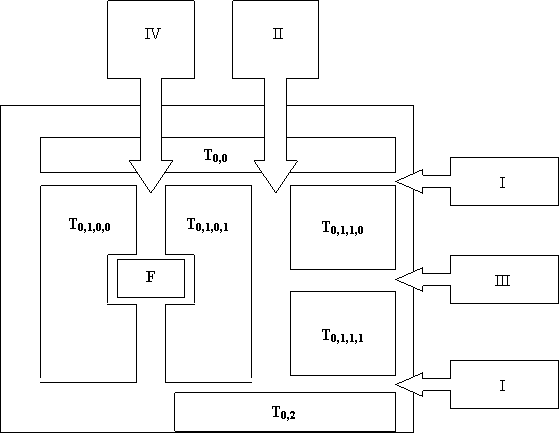 |
Рис. 7. Пример определения логической струкутуры документа по его фрагментации
При выравнивании абзацев в табличных ячейках основная трудность заключается в том, что в преобладающем большинстве табличные ячейки содержат по одной, две строки. Естественно, что такой информации недостаточно при формировании и выравнивании абзацев. Поэтому необходимо учитывать информацию о соседних ячейках. Наиболее продуктивен анализ вертикальных и горизонтальных групп, содержащих логически однородные ячейки таблицы.
Отметим связь алгоритмов выравнивания границ строк и найденных атрибутов текстовых символов (см. часть 2). Определенные в результате постобработки атрибуты слов, снабжены оценками, позволяющими манипулировать атрибутами слов в форматировании границ строк. В случае, когда строка не умещается в отведенных ей границах, возможен пересмотр стиля слов, признаков курсива, жирности и других атрибутов. При этом производится минимизация потерь пересмотренных атрибутов с точки зрения их оценок. Также отметим важность словарного подтверждения переноса слова, используемого при объединении двух строк в одну группу с общим выравниванием.
В отличие от RTF и внутреннего формата OCR простой текст не обладает средствами для отображения структуры документа. Тем не менее, и для простого текста возможно сохранить результаты распознавания документа со сложной структурой. В тексте принципиально невозможно сохранение иллюстраций (в нашей модели принципиально ничем не отличающихся от других фрагментов) и стиля символов, так как единственными средствами отображения в тексте являются буквы моноширинного шрифта и символы из некоторой кодовой страницы, вообще говоря, задаваемой внешним образом. Структура фрагментов и выравнивание строк реализуются при помощи пробелов между словами, при этом решается задача сохранения максимума логических (а не метрических, как это было ранее) отношений между координатами фрагментов, то есть отношениям вида
X1<X 2,
где Xi – какая либо координата левого верхнего угла (или ширина) одного из исходного фрагментов, должны соответствовать отношения
X¢1<X¢ 2
для координат образов левого верхнего угла (или ширины) соответствующих им сохраненных фрагментов. Отношения между высотами фрагментов не сохраняются, так как в текстовом формате нет средств управления межстрочными расстояниями. Средствами достижения поставленной цели является увеличение ширины строк и расстояний между фрагментами в получаемом тексте. Полученное текстовое представление структурного документа сложно для последующей коррекции из-за того, что любое изменение затрагивает оставшиеся части документа. В ряде случаев для дальнейшей коррекции целесообразно форматирование документа в виде последовательности тестовых и табличных фрагментов без сохранения структуры, при этом важен только порядок следования фрагментов. Отметим, что решению задач форматирования в простой текст помогает описанная выше иерархическая модель фрагментов.
Таким образом, форматирование решает задачи, которые невозможно решить на предыдущих этапах распознавания и постраспознавания. Алгоритмы форматирования используют в качестве исходных данных результаты распознавания с оценками, их результатом является представление этих результатов, пригодное для оптимального показа документа общеупотребительными форматами.
5. Конвертирование
В предложенной трехэтапной процедуре СР процесс конвертирования состоит в запоминании согласованных и отформатированных результатов в файл определенного формата или аналогичной передаче результатов с помощью некоторого протокола обмена, например, протокола ODBC. Конвертирование не изменяет структуру и содержание результатов распознавания.
Конвертирование обязательно содержит две функции:
- преобразование результатов из внутреннего формата в один из общеупотребительных текстовых форматов
- представление результатов в различных кодировках.
Перечень и полнота использования выходных текстовых форматов могут изменяться при неизменном внутреннем формате, то есть при неизменной программе OCR. Под кодировками подразумеваются различные кодовые страницы используемого алфавита, например, 866 кодовая страница (ASCII) и 1250 (ANSI) для русского языка. Также в кодировании учитываются внутренние обозначения символов, не входящие в кодовые страницы. Например, полиграфическая лигатура «ff» может быть распознана как единое целое, но символ двойного «f» отсутствует в кодовых страницах Microsoft Windows, в этом случае требуется дополнительное кодирование.
Таким образом, конвертирование выполняет технические функции отображения внутреннего формата хранения результатов во внешние форматы, являясь посредником между представлениями данных OCR и внешними представлениями текстовых результатов.
6. Характеристики алгоритмов сохранения результатов
Как было отмечено выше, алгоритмы СР, являясь финальными в программах OCR, с точки зрения пользователя характеризуют работу всего оптического распознавания в целом. Кроме характеристик алгоритмов сегментации страницы и распознавания строк, таких как точность, быстродействие, качество оценок, существуют аналогичные характеристики алгоритмов СР.
Эти характеристики разбиваются на две группы. Чаще всего в литературе обсуждается принципиальная возможность OCR отписывать текстовые форматы с определенными свойствами, такими как многоколоночный текст, сохраненными иллюстрациями, разделяющими линиями и атрибутами или стилем текстовых символов [1]. Во многом эти свойства определяются хронологически предшествующими алгоритмами сегментации страницы и распознавания текстовых строк, а СР воспроизводит накопленную информацию в текстовых форматах, перечень которых определяют характеристики конвертирования. Другая группа характеристик СР оценивает свойства именно алгоритмов и программ СР и соответствие их результатов оригинальному изображению документа.
Перечислим основные характеристики алгоритмов СР, считая их реализованными в составе комплекса программ OCR, допускающих проведение вычислительных экспериментов, состоящих в оптическом распознавании образов документов различной структуры и качества и последующего сопоставления результатов распознавания с оригиналами. Остановимся на характеристиках форматирования.
Интуитивно понятной является характеристика точности форматирования, состоящая в соответствии результатов оригинальной структуре документа. Однако, в отличие от точности алгоритма распознавания образов [7], точность форматирования является многофакторным критерием, базирующимся на комплексе элементарных характеристик. Мы использовали следующий перечень элементарных характеристик форматирования:
- точность воспроизведения числа колонок и заголовков текста, иллюстраций, разделительных линий, состоящая в соответствии количества результирующих сегментов исходным сегментам текста в отсканированном документе
- точность воспроизведения размеров сегментов документа
- точность выравнивания строк
- точность воспроизведения взаимного расположения сегментов документа.
Каждая из элементарных характеристик, вычисляемая по отношению к конкретному распознанному документу, оценивается суммой штрафов за расхождения. Общая точность форматирования A(I) образа документа I также оценивается суммарным штрафом по всем характеристикам S W(Mi)·D(Mi,I), где D(Mi,I) – штраф элементарной характеристики Mi, оценивающей распознавание образа I, а W(Mi) – вес этой характеристики. Для определения точности форматирования использовались наборы изображений, состоящие экземпляров документов различных классов (журнальные, газетные, рекламные страницы). Результаты усреднялись, образуя точность форматирования A. Отметим, что для некоторых документов, например, полиграфических, полное соответствие результатов форматирования и оригиналов становится невозможным. Поэтому точность форматирования, отличная от нуля и меньшая некоторого порогового значения считается приемлемой, а порог приемлемого штрафа за точность устанавливается экспериментально.
Другой важной характеристикой является устойчивость к вариациям образов, она представляет собой изменение точности
| A(I) - A(I*) |
при распознавании образа I*, полученного из исходного I каким-либо геометрическим преобразованием или искажением, например, поворотом или изменением яркости сканирования.
Также отметим такие характеристики форматирования как быстродействие и способность к обучению. Последнее свойство означает возможность отчуждения информации в процессе просмотра обучающей последовательности документов для использования полученных описаний в последующей работе алгоритмов СР с целью повышения точности форматирования. Быстродействие и способность к обучению необходимы в проектировании документарных систем, составной частью которых являются OCR.
Набор характеристик алгоритмов СР служит основой для их оптимизации и последующего тестирования.
7. Заключение
Алгоритмы СР, являясь финальным этапом распознавания образа документа, играют важную роль в работе системы ввода документов в целом. Предложенная нами классификация СР на три группы (постраспознавание, форматирование, конвертирование) позволяет при проектировании программ OCR тесно интегрироваться с сегментацией и распознаванием образов символов, а также гибко учитывать особенности различных текстовых форматов.
Постраспознавание решает задачу улучшения атрибутов и характеристик результатов распознавания страницы после очередного цикла распознавания текстовых строк. Процесс постраспознавания полезен как распознаванию страницы, так и последующему форматированию. Собственно алгоритмы форматирования (например, установление взаимосвязей между различными фрагментами или определение стиля выравнивания во фрагменте) не могут быть применены ранее окончания этапов распознавания и постраспознавания. Форматирование завершается сохранением результатов во внутренний формат OCR в виде, готовом для последующего конвертирования в общеупотребительные форматы текстов. Конвертирование не содержит содержательных алгоритмов обработки текстовой информации и сводится только к преобразованию в конкретные форматы с учетом особенностей их конкретных версий.
Алгоритмы СР решают задачи, которые не могут быть возложены на алгоритмы распознавания текстовых строк. Распознавание строк нацелено на наилучшее нахождение границ и классификацию символов, а алгоритмы СР, в особеннности, форматирование ориентированы на оптимальное отображение финального результата с точки зрения сохранения метрических отношений между фрагментами докмуента.
Представляет интерес дальнейшее развитие инструментария, передающего альтернативные результаты от этапа распознавания строк этапу форматирования.
Значительную помощь в разработке программ OCR предоставляет система характеристик (показателей) качества сохранения результатов, использованная в общей оптимизации системы, направленной как на достижение наибольшей точности распознавания, так и формирования наилучшей структуры текста.
Описанный в статье подход реализован в OCR Cuneiform 2000.
Литература
1. Kazem T., Borsack J., Condit A. Evaluation of Model-Based Retrieval Effectiveness with OCR Text // ACM Transactions on Information System, Vol. 14, № 1, 1996, pp. 64-93
2. White J. M., Rohrer G. D. Image Thresholding for Optical Character Recognition and Other Applications Requiring Character Image Extraction, IBMRD(27), № 4, 1983, pp. 400-411.
3. Klyahzkin V., Shchepin E., Zingerman K. Hierarchical analysis of multi-column texts, Pattern Recognition and Image Analysis, Vol.5, №.1, 1995, Interperiodica, pp. 1-12
4. , Алгоритмы распознавания и технологии ввода текстов в ЭВМ. - Информационные технологии и вычислительные системы № 1, 1996, 6, стр. 48-54
5. , , Адаптивное распознавание символов. В сб. "Интеллектуальные технологии ввода и обработки информации", 1998, с. 39-56
6. , , Линейный критерий в задачах OCR. - В сб. " Развитие безбумажных технологий в организациях ", 1999, с. 28-46
7. , , Методы распознавания грубых объектов. В сб. "Развитие безбумажных технологий в организациях", 1999, с. 331-355
8. , Структурные методы обработки эмпирических данных. М.: Наука, 1983, – 464 с.
