
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
FRОM имя [, <имя>…]
2 часть: [[in to <получатель>]/[to file <файл> [additiv]|[to printer]]
WHERE условия
SELECT – указание результатов выборки и исходных данных.
FROM – перед ним выбираемые выражения, после него – имена таблиц, откуда берутся данные
<выражение> может быть полем записи константой, функцией от переменной. If выражение является именем поля, то оно может быть составным.
Псевдонимом может быть любое имя, которое присваивается команде SELECT. If необходимо построить выборку из всех полей, вместо их перечня нужно указать «*».
Включение опции DISTINCT исключает возмоднось вывода одинаковых строк выборки.
2 часть – указание объекта (экран, принтер). Информация может быть передана в курсор. Курсор – временный набор данных, имеет режим чтение. Данные курсора могут буть использованы командой BROWSE, из неё же можно меню, другой SELECT обработан.
ARRAY – имя массива
TABLE – имя таблицы
CURSOR – имя курсора
If исп-ся слово ADDITIV, то выборка будет добавлена в конец существующего файла без его перезаписи.
Только при выдаче на экран:
- NOCONSOLE - выборка не выдается на экран
- PLAIN – заголовки колонок не выдаются
- NOWAIT – не делается паузы при заполнении экрана
WHERE – критерий отбора данных (все строки с условиями связи) применяется в случае когда выборка осуществляется из более чем одной таблицы и указывается критерий, которому должны отвечать поля из разных таблиц. Используются знаки отношений. Допускается задание нескольких критериев.
Условие отбора строится аналогично, но из выражений только одной таблицы (OK, NOT)
Условия могут содержать:
LIKE – позволяет построить условия сравнения по шаблонам.
BETWEEN - проверяет находится ли выражение в заданном диапазоне
IN – проверяет, находится ли выражение,, стоящее слева от IN среди перечисляемых справа от него: IN(выраж.1, выраж2,…)
GROUP BY <колонка> задаются колонки для группировки
HAVING – критерий отбора данных в каждую сформированную в процессе выборки группу
ORDER BY – упорядочивание по заданной колонке (по умолчанию по возрастанию) ASC – по возрастанию.
23. Индексы
Если нужно связать таблицы, не имеющие общих столбцов, необходимо использовать 3-ю таблицу, имеющую общие столбцы как с 1-ой, так и со 2-ой таблицами. Такая таблица - связующая. Связующую таблицу можно использовать для связывания как для таблиц с общими столбцами, так и для таблиц не имеющих общих столбцов.
Индекс - указатель на данные таблицы. Когда в таблицу добавляются данные, индексы также изменяются. При выполнении запроса, в котором либо в условии этого запроса, либо в выражении ключевого слова индекс представляет столбец, по которому выполнено индексирование. Сначала происходит поиск в индексе. Если подходящее значение (местоположение) будет найдено, то возвращается местоположение нужных данных в таблице.
Формат оператора
CREATE INDEX имя индекса ON имя таблицы.
Типы индексов:
-простые: индексирование по данным одного столбца таблицы.
CREATE INDEX имя индекса ON имя таблицы(имя столбца).
-уникальные: можно создать только по тому столбцу таблицы, данные которого уникальны.
CREATE UNIQUE INDEX имя индекса ON имя таблицы ( имя столбца )
- составные: составленные по значениям нескольких столбцов таблицы. При создании следует учитывать вопросы производительности, поскольку порядок столбцов в условии индекса может сильно влиять на скорость извлечения данных.
Общее правило для повышения производительности: Более ограниченное значение должно идти первым, однако первым должен указываться столбец, наличие которого всегда предполагается в условиях выборки.
Синтаксис оператора
CREATE INDEX имя индекса ON имя таблицы (имя столбца 1, имя столбца 2)
Использование составного индекса оказывается эффективным в том случае, когда соответствующий индекс таблицы одновременно используется в условиях запросов в выражениях ключевого запроса WHERE .
Неявные индексы - индексы, создаваемые автоматически сервером при создании объектов.
STUDENTS (SFAM, SNUM, STIP)
PREDMET (PNAME, PNUM, TNUM, HOURS)
TEACHER (TFAM, TNUM, TIMA)
USP (UNUM, OCENKA, SNUM, UDATE, PNUM).
Пусть необходимо поставить в соответствии преподавателю учебные предметы, которые он ведет:
SELECT TEACHER. TFAM, PREDMET. PNAME;
FROM TEACHER, PREDMET
WHERE TEACHER. TNUM=PREDMET. TNUM
Эти столбцы били соединены через поле TNUM - состояние справочной целостности.
Объединение многоблочных запросов, которые используют предикаты, объединяются по равенству.
- объединение по равенству
Вывести список оценок, выставляемых преподавателем:
SELECT A. TFAM, USP. OCAENKA;
FROM TEACHER A., PREDMET, USP
WHERE A. TNUM=PREDMET. TNUM AND PREDMET. PNUM=USP. PNUM
Эта же методика для объединения вместе 2-х копий одной таблицы.
Допускается изобразить объединение таблицы с собой, как объединение 2-х таблиц. ( она не копируется, но SQL выполняет команду так, как если это было сделано ). Осуществляется с помощью введения временных имен - псевдонимов.
Пример: пяти студентов, имеющих одинаковый размер стипендии
SELECT FIRST. SFAM, SECOND. SFAM, FIRST. STIP
FROM STUDENTS FIRST, STUDENTS SECOND
WHERE FIRST. STIP
Допускается использовать любое число псевдонимов для одной таблицы.
UNION - объединение результатов SELECT.
STUD1 - таблица, содержит поле, состоящее из 30 символов, содержащее имя и фамилию.
TE1 - отдельные поля для имени и фамилии (first name, last name). Сумма длин = 30 символам в STUD1 поле для хранения факультета. в TE1 этого поля нет.
SELECT STUD1.name, STUD1.fac
FROM STUD1
UNION
SELECT PADR(ALLTRIM(TE1,FIRSTNAME)+ ' ' + ALLTRIM (TE1.LASTNAME), 30 )
AS name
SPACE (10) AS fac
FROM TE1
PADR - содает поле длинной 30 символов
ALLTRIM - удаляет пробелы
SPACE (10) - играет роль заглушки, которая относится к полю, содержащему имя факультета.
Правило объединения с помощью UNION: любое поле, включенное в первый список полей должно быть представлено полем, либо заглушкой в последующих списках полей. Любое поле из последующих списков полей, которое не входит в первый список полей, должно быть представлено заглушкой в первом списке. В первом списке не должно быть вычисление полей.
Члены ORDER BY, INTO могут входить в любую инструкцию SELECT объединения, но только один раз и применяются ко всему результату. Член ORDER BY должен ссылаться на поля по их позициям в списке, а не имени. При условии ORDER BY для сортировки используется порядок следование полей в списке. С помощью UINIO нельзя объединять результаты подзапросов. При построении объединения можно использовать не более 10 членов UNION. Члены GROUP BY, HAVING могут присутствовать в каждой инструкции SELECT объединения образованного с помощью UNION, причем их влияние ограниченно только результатом данной инструкции SELECT. Воздействие UNION аналогично DISTING, каждое добовляемое результирующий набор данных проверяется.
24. Использование подзапросов
Какие дисциплины ведет Иванов
SELECT *FROM PREDMET
WHERE TNUM=(SELECT DISTINCT TNUM FROM TEACHER WHERE TEAM='Иванов'
В подзапросах допускается использование агрегатных функций, так как они автоматически производят одиночные значения для любого типа строк, которое может быть использовано в основном запросе.
Пример:
Вывести все оценки по дисциплинами, значения которых выше среднего
SELECT *FROM USP
WHERE OCENKA > (SELECT AVG ( OCENKA )
FROM USP)
В любой операции, где применяется оператор равенства, можно использовать IN
Соотнесенные подзапросы
Когда используются подзапросы в SQL имеется возможность обратиться к внутреннему запросу таблицы в предложении внешнего запроса с помощью соотнесенного подзапроса.
Подзапрос выполняется неоднократно, по одному разу для каждой записи таблицы основного запроса. Строка внешнего запроса, для которой внутренний запрос каждый раз будет выполнять текущая строка.
Процедура состоит в следующем: выбор строки из таблицы во внешнем запросе, сохранение значений текущей строки псевдонима, имя которого определено в предложении FROM внешнего запроса. Выполнение подзапроса при этом везде, где найден псевдоним из внешнего запроса используется значение из текущей строки - внешняя ссылка.
Оценка внешнего запроса на основе результата подзапроса последовательно повторяется для следующей строки из таблицы внешнего запроса и так до тех пор, пока все строки не будут проверены.
Псевдонимы необходимы для того, чтобы дать возможность ссылаться к той же самой таблице во внутреннем и внешнем запросе. Часто соотнесенный подзапрос используют на основе той же самой таблицы, что и основной запрос.
Пример: Найти все оценки по дисциплине с значением выше среднего по этой же дисциплине.
SELECT *FROM USP FIRST
WHERE OCENKA > ( SELLECT AVG (OCENKA)
FROM USP SECOND
WHERE SECOND. PNUM=FIRST. PNUM)
Соотнесенные запросы по своей сути близки к объединению. Обе конструкции включают проверку каждой записи одной таблицы с каждой записью другой таблицы или с псевдонимом.
Представление (VIEW) - некоторое подобие таблицы, содержание которого выбирается из других таблиц с помощью выполнения запроса, причем при изменении значения в этих таблицах данные автоматически меняются в их представлении. Иногда представления более эффективны, чем запросы.
Создается представление: CREATE VIEW, после которого указывается его имя, а далее следует запрос, формирующий тело представления. Поля представлений могут иметь свои имена полученные из имен полей основной таблицы. Представления могут использовать подзапросы, в т. ч. соотнесенные.
Пример:
Вывести все значения по дисциплине, значения которых выше среднего
CRATE VIEW AVGOC
AS SELECT *FROM USP FIRST
WHERE OCENKA > ( SELECT AVG (OCENKA )
FROM USP SECOND
WHERE SECOND. PNUM=FIRST. PNUM)
25. Презентационная логика. Бизнес логика.
Презентационная логика определяется тем, что пользователь видит на экране. К ней относятся все интерфейсы. Всё то, что выводится как результат решения промежуточных задач, либо как справочная информация.
Основные задачи:
· Формирование экранных изображений
· Чтение и запись в экранной форме информации
· Управление экраном
· Обработка нажатий клавиатуры и мыши
Бизнес логика – эта часть приложения определяется алгоритмы решения задачи.
Логика обработки данных – эта часть связана с обработкой данных внутри приложения, язык запросов SQL к данным.
Процессор управления данными обеспечивает хранение и управление БД-СУБД.
Типовое приложение:
Структура типового приложения
 |
В централизованной архитектуре находятся в единой разделяемой среде и комбинируются внутри одной исполняемой программы. В децентрализованной архитектуре задачи по-разному распределены между сервером и клиентами.
Можно выделить модели в зависимости от характера:
1. Распределенная презентация (distribution presentation - DP)
2. Удаленная презентация (remote presentation - RP)
3. Распределенная бизнес-логика (distribution business logic - DBL)
4. Распределенное управление данными (distribution data management)
5. Удалённое управление данными (remote data management)
26. Постреляционная модель данных
Расширенная реляционная модель, снимающая ограничение неделимости данных в записях таблиц. Допускает многозначные поля. Набор значений считается самостоятельной таблицей, встроенной в основную.
Достоинства: возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей – обеспечивает высокую наглядность представления.
Недостатки: сложность решения проблемы целостности и непротиворечивости данных.
Хранилище данных появились из систем поддержки. Хранилище получает данные из систем. Можно моделировать методами многомерного моделирования.
Факты - основные виды бизнес деятельности и факторы, влияющие на данный бизнес.
Измерения можно разбить на категории: вещи, места, время, люди. Нарушается звездообразная структура и создаётся таблица развертывания измерений.
Pata mining - - процесс выявления значимых корреляций, тенденций в больших объемах данных. OLAP: многомерный и реляционный.
27. Модель удалённого управления данными
Модель удалённого управления данными (модель файлового сервера(FS)) – в этой модели распределённая и бизнес логика располагается на клиенте. На сервере - файлы с данными, поддерживается доступ к файлам. Функции управления информационными ресурсами – на клиенте. Файлы базы – на сервере, клиент обращается с файловыми командами.
Достоинства: имеем разделение монопольного приложения на 2 процесса, при этом сервер может обслуживать множество клиентов. СУБД на клиенте.
Недостатки: высокий сетевой трафик, недостаточное количество операций манипулирования данными, которое определяется файловыми командами, отсутствие адекватных средств, защита на уровне файловой системы.
28. Модель удалённого доступа к данным.
База данных – на сервере. Ядро СУБД на сервере. На клиенте – презентационная и бизнес логика. Клиент обращается к серверу через SQL запрос.
Достоинства: унификация интерфейса клиент-сервер, стандартом при общении клиент-сервер является язык SQL. Резко уменьшается загрузка сети, так как по ней от клиента к серверу передаются не запросы на ввод/вывод файловой терминологии, а запросы SQL (объём меньше). В ответ на запрос клиент получает данные, а не блоки, как в FS-модели. Сервер БД загружается операциями обработки данных, запросов, транзакций.
Недостатки: запросы на SQL при интенсивной работе клиентских приложений могут загрузить сеть, так как в этой модели не клиенте располагаются и презентационная, и бизнес логика, то при повторении аналогичных функций в разных приложениях код повторяется в каждом клиентском приложении. Излишнее дублирование. Сервер - пассивная роль.
29. Модель активного сервера.
Данная модель поддерживает SQL, Oracle. Основа-механизм хранимых процедур как средство программирования SQL сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных как механизм поддержки доменной структуры. Бизнес логика разделена между клиентом и сервером. На сервере – в виде хранимых процедур. В данной модели сервер является активным. Не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в базе.
Достоинства: трафик уменьшается. Хранимые процедуры, триггеры используются несколькими клиентами, что уменьшает дублирование алгоритмов. Для написания логики триггеров – расширенный встроенный SQL.
Недостатки: очень большая загрузка сервера. Сервер обслуживает множество клиентов и выполняет следующие функции: обеспечивает автоматическое срабатывание триггеров при возникновении событий, обеспечивает выполнение внутренней программы триггера, запускает хранимые процедуры по запросам пользователей, запускает процедуры из триггеров, возвращает требуемые данные клиенту, обеспечивает все функции СУБД: контроль и поддержка.
30. Модель сервер-приложение (Application Server)
Модель – расширение двухуровневой модели. В ней вводится дополнительный уровень между клиентом и сервером. Уровень содержит один или несколько серверов приложений. Компоненты приложений делятся между тремя исполнителями:
Клиент обеспечивает логику представления (графический пользовательский интерфейс), может запускать локальный код приложения, исполняет коммуникационный функции.
Сервер приложений – новый уровень архитектуры, поддерживает сетевую доменную операционную среду, хранит и исполняет наиболее общие правила бизнес-логики, поддерживает каталоги с данными, обмен сообщениями и поддержку запросов. Серверы баз данных выполняют только функции СУБД: поддерживают целостность реляционной БД, обеспечивают функции хранилищ базы данных, функции создания и ведения баз данных, создают резервные копии БД, управляют выполнением транзакций.
Достоинства: модель обладает большей гибкостью, чем двухуровневая из-за разделения на 3 составляющие.
Недостатки: более высокие затраты ресурсов ПК на обмен информацией между компонентами приложения по сравнению с двухуровневыми моделями.
31. Модели транзакций
Транзакция-последовательность операций, производимых над БД и переводящих БД из одного согласованного состояния в другое согласованное состояние.
Транзакции:
- Плоские (классические) Цепочечные Вложенные
Классические характеризуются 4мя классическими свойствами:
- Атомарность Согласованность Изолированность Долговечность (ACID)
Свойство атомарности заключается в том, что транзакция выполнена в целом, либо невыполнена вовсе.
Свойство согласованности гарантирует, что по мере выполнения данные переходят из одного состояния в другое. Транзакция не разрушает взаимной согласованности данных.
Свойство изолированности означает, что конкурирующие за доступ к БД транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователя это выглядит так, как будто они выполняются параллельно.
Свойство долговечности: если транзакция завершена успешно, то те изменения в данных, которые были ей произведены, не могут быть потеряны ни при каких обстоятельствах.
2 варианта завершения транзакции:
Фиксация – действие, обеспечивающее запись на диск и изменение в БД. Откат – действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.В стандарте SQL модель транзакции выглядит следующим образом: (тут рисунок)
Транзакция начинается с первого SQL оператора. Последующие составляют тело транзакции. Commit выполняется в случае успешного завершения обработки информации, объединенной в транзакцию. Его выполнение фиксирует изменения, внесенные в базу данных текущей транзакции. Rollback прерывает выполнение транзакции и осуществляет отмену изменений, проведенных в ходе выполнения транзакции.
Вопросы реализации в СУБД подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается журнал транзакций. Он предназначен для надежного хранения данных в базе данных. Это требование предполагает возможность восстановления согласованного состояния базы данных после любого рода программных или аппаратных сбоев.
Общие принципы восстановления – возможность восстановления БД.
Результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных. Результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных.
Восстановление возможно при:
Индивидуальный откат транзакции Мягкий сбой - Восстановление после внезапной потери содержимого ОЗУ Жесткий сбой - Восстановление после поломки основного внешнего носителя БД.Основа восстановления – архивная копия и журнал изменений базы данных.
В основе избыточное хранение данных.
2 варианта ведения журнальной информации:
1. для каждой транзакции поддерживается отдельный журнал изменений – локальный журнал (для индивидуальных откатов транзакций)
2. общий журнал изменений. Это приводит к дублированию информации в локальном и общем журнале.
Общая структура журнала может быть представлена в виде некоторого последовательного файла, в котором фиксируется каждое изменение БД, которое происходит в ходе выполнения транзакций. Каждая запись помечается номером транзакции, к которой она относится и значением атрибутов, которые она меняет. Для каждой транзакции фиксируется команда начала и завершения транзакции. Для большей надежности журнал транзакций дублируется системными средствами СУБД.
Используют 2 варианта ведения журнала
протокол с отмеченными изменениями протокол с немедленными изменениямиПроцедура согласованного выполнения параллельных транзакций должна удовлетворять правилам:
1. в ходе выполнения транзакции пользователь видит только согласованные данные.
2. если 2 транзакции параллельно, то СУБД гарантировано поддерживает принцип независимого выполнения транзакций – сериализация транзакций.
Способ выполнения транзакций – сериальный, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Это осуществляется механизмом блокировок. Самый простой вариант – блокировка объекта на все время действия транзакции.
Рассматриваются 2 основных типа блокировок:
Совместный режим блокировки – нежесткая или разделяемая блокировка (Shared[S]) - означает разделяемый захват объекта. Объекты не изменяются в процессе выполнения транзакций и доступны другим только для чтения. Монопольный режим – жесткая или эксклюзивная блокировка (X, Exclusive). Требуется для выполнения операций занесения, удаления, модификации и предполагает монопольный захват объекта. Объекты недоступны для других транзакций до момента окончания работы данной транзакции.Правила совместимости захватов одного объекта разными транзакциями
Захваты объекта несколькими транзакциями по чтению совместимы, то есть нескольким транзакциям допускается читать один и тот же объект. Захват одной транзакции по чтению несовместимы с захватом другой транзакцией того же объекта по записи. Захваты одного объекта разными транзакциями по записи несовместимы. Применение разных типов блокировок приводит к проблеме тупиков, количество взаимно заблокированных транзакций может быть большим. Основа обнаружения тупиковых ситуаций – построение графа ожидания транзакции. Разрушение тупика начинается с выбора в цикле транзакций так называемой транзакции жертвы. Жертва – сама дешевая транзакция. Стоимость транзакции выбирается на основе многофакторной оценки, в которую с разными условиями входят: время выполнения, приоритет, число накопленных захватов. После выбора транзакции жертвы выполняется откат.
Транзакция B |
| ||||
Разблокирована | Нежесткая | Жесткая | |||
Транзакция А | Разблокирована | Да | Да | Да |
|
Нежесткая | Да | Да | Нет |
| |
жесткая | Да | Нет | Нет |
| |
32. Многомерные модели данных
Кодом сформулированы основные требования к классам OLAB (Online Analyte Process)
2 направления:
1. системы оперативной транзакционной обработки.
2. системы аналитической обработки или системы поддержки принятия решений
Реляционные предназначались для информационных систем оперативной обработки информации. В области аналитической обработки информации более эффективны многомерные СУБД.
Основные понятия в многомерных СУБД:
Агрегируемость: означает просмотр информации на различных уровнях обобщения. Степень детальности информации зависит от ее уровня.
Историчность: обеспечение высокого уровня неизменности данных и их взаимосвязи, а также обязательность привязки данных ко времени. Статичность позволяет использовать при обработке данных специальные методы загрузки, хранения, индексации, выборки
Прогнозируемость: задание функции прогнозирования, и применение ее к различным временным интервалам.
Многомерность модели данных означает многомерное логическое представление структуры информации при описании и в операциях манипулирования данных.
Основные понятия ММД (многомерной модели данных): Измерение и ячейка.
Измерение - это множество однотипных данных, образующих одну из граней гиперкуба. Например – временное измерение. В ММД измерения - роль индексов, служащих для идентификации конкретных значений ячейки гиперкуба.
Ячейка - поле, значение которого однозначно определяется фиксированным набором измерений. В зависимости от формирования ячейки, она либо переменная, либо формула. Тип поля обычно цифровой. Поликубическую модель поддерживает Oracle.
В существующих СУБД 2 организации данных: в случае гиперкубической схемы одним и тем же набором, при наличии гиперкубов - все одинаковые.
Операции:
1. Формирование среза. Срез – подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений.
2. Вращение. Применяется при двумерном представлении данных. Суть заключается в изменении порядка измерения при визуальном представлении данных.
3. Агрегация и детализация. Переход к более общему или более детальному представлению информации из гиперкуба.
Основное достоинство модели: эффективность аналитической обработки данных больших объемов, связанных со временем. В реляционной модели происходит нелинейный рост трудоемкости в зависимости от размера БД и существенное увеличение затрат в ОП на индексацию.
Недостаток: громоздкость модели для простых задач.
33. Файловые структуры, используемые для хранения в БД
Классификация:
Файлы прямого доступа Файлы последовательного доступа Найденные файлы Инвертированные списки Взаимосвязанные файлы- С однонаправленными цепочкам С двунаправленными цепочками
Индексные:
- Плотный индекс (индексно-прямые файлы) Неплотный индекс (индексно-последовательные файлы) B-деревья
Файлы прямого доступа – файлы с постоянной длиной записи, расположенные на устройствах прямого доступа. Обеспечивают наиболее быстрый доступ к произвольным записям и их использование – наиболее перспективное в системах баз данных
Файлы последовательного доступа организованы на устройствах последовательного доступа.
Файлы последовательного доступа могут быть организованы двумя способами.
конец записи отмечается специальным маркером в начале каждой записи записывается ее длинаСуть метода хэширования:
берется значение ключа и используется для начала поиска, то есть вычисляется некоторая хэш-функция, и полученное значение берется в качестве адреса начала поиска. То есть не требуется такого соответствия, но для увеличения скорости ограничивается время этого поиска. Поэтому допускается, что нескольким разным ключам может соответствовать одно значение хэш-функции, то есть один адрес. Возникают коллизии. Значения ключей, которые имеют одно и то же значение хэш-функции – синонимы. При использовании хэширования как метода доступа необходимо выбрать хэш-функцию и метод разрешения коллизии.
Существуют разные методы:
использование сгенерированного адреса в качестве начальной точки для последовательного просмотра. С этого адреса начинается поиск свободного места в памяти сгенерированный адрес считается адресом хранения не одной конкретной записи, а области памяти, в пределах которой размещаются все записи, получившие этот адрес. В пределах страницы записи могут размещаться в последовательном порядке поступления. Если со временем структура окажется заполненной, в памяти выделяется новая страница, связываемая с предыдущей указателем. Хэш-функция может генерировать абсолютный адрес страницы и ее номер.Индексные файлы можно представить как файлы, состоящие из двух частей. Индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс. В зависимости от организации индексной и основной областей различают 2 типа файлов – с плотным индексом и неплотным.
34. Файлы с плотным, неплотным индексом. Индексы в В-дереве.
Файлы с плотным индексом
В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, в структура записи в ней имеет следующий вид:
![]()
Значение ключа – значение первичного ключа
Номер записи – порядковый номер записи в основной области.
В этих файлах для каждой записи в основной области существует запись одна запись из индексной области. Все записи в индексной области упорядочены по значениям ключа.
Схематично это можно представить следующим образом:
Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны 2 решения:
перестроить заново индексную область организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записиПервый способ требует дополнительного времени на переработку индексной области.
Второй способ увеличивает время на доступ к произвольной записи и требует организации дополнительных ссылок на область переполнения.
Файлы с неплотным индексом
Неплотный индекс строится для упорядочения файлов. Структура записей индекса для таких файлов имеет следующий вид
 |
В индексной области ищется блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет определить, в какой области находится искомая запись, а остальные действия происходят в основной области. В случае плотного индекса после определения местонахождения искомой записи, доступ к ней осуществляется прямым способом, поэтому этот способ организации индекса называется индексно-прямым.
В случае неплотного индекса после нахождении блока, где расположен запись, поиск внутри блока требуемой записи происходит последовательным просмотром. Поэтому этот способ называется индексно-последовательным.
Организация индексов в виде В-деревьев
Построение В-деревьев связано с построением индекса над уже построенным индексом. Если построен неплотный индекс, то сама индексная область может быть рассмотрена как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым индексным полем строится следующий. И так до тех пор, пока не останется всего один индексный блок. В общем случае получают некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в этом блоке. Такие деревья называются сбалансированными. Отсюда и пошло название B (Balanced) деревья.
35. Инвертированные списки
Инвертированный список (в общем случае) – двухуровневая индексная структура. На первом уровне находится файл или часть файла, где упорядочено расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значению вторичного ключа. На третьем уровне находится основной файл. Для одного основного файла может быть создано несколько инвертированных списков по разным значениям вторичного ключа.
Инвертированный список по номеру группы для списка студентов
1-ый уровень 2-ой уровень
Ключ | № блока |
100 |
|
200 |
|
300 | 5 |
 3
3Блок 1 |
|
4 |
21 |
25 |
Блок 2 |
31 |
34 |
40 |
Блок 3 |
5 |
7 |
 1
1№ записи | ФИО | № группы |
1 | Иванов | 100 |
2 | Петров | 300 |
3 | Сидоров | 300 |
4 | Андреев | 100 |
5 | Михайлов | 200 |
6 | Николаев | 300 |
7 | Борисов | 200 |
Иногда бывает необходимо просмотреть цепочку записи в 2х направлениях: прямом и обратном. В этом случае применяют двойные указатели. В основном файле первый указатель равен номеру 1ой записи цепочки записей подчиненного файла, а 2о1 указатель равен номеру последней записи. В подчиненном файле первый указатель равен номеру следующей записи в цепочке, а другой указатель равен номеру предыдущей записи в цепочке. Для первой и последней записи в цепочке один из указателей пуст. Один файл может быть связан с несколькими. При этом для каждой связи моделируются свои указатели
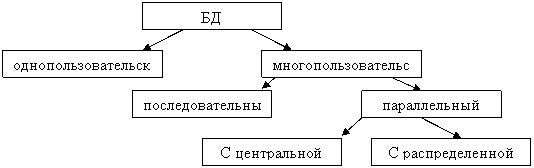
36. Распределенная обработка данных
Параллельный доступ к одной базе данных нескольких пользователей в том случае, если база данных расположена на одной машине, соответствует режиму распределенного доступа к централизованной базе данных – системы распределенной обработки данных.
Если база данных распределена по нескольким компьютерам, располагающимся в сети, и к ней возможен параллельный доступ нескольких пользователей, то это соответствует режиму параллельного доступа к распределенной базе данных.
Такие системы – системы распределенных баз данных.
Основной принцип технологии «клиент-сервер», применяемой к технологии баз данных – разделение функций стандартного интерактивного приложения на 5 групп.
1. функция ввода и отображения данных (presentation logic - PL)
2. прикладные программы, определяющие основные алгоритмы решения задач приложения (business logic - BL)
3. функция обработки данных внутри приложения (database logic - DL)
4. функция управления информационными ресурсами (Database Manager System)
5. служебные функции, играющие роль связок между функциями групп 1..4
37. Основные компоненты системы управления БД.
2 источника:
- Пользователи/приложения (запросы, команды транзакций) Администратор БД (Команды DDL, компилятор DDL)
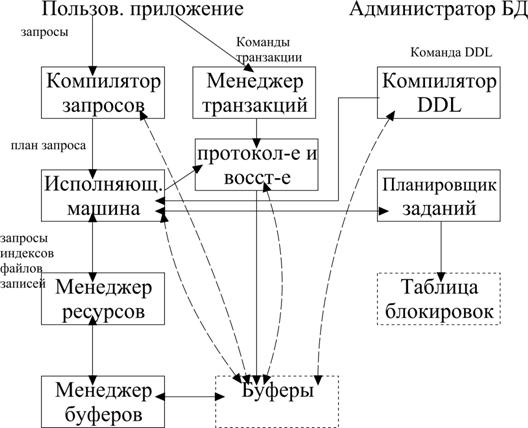
Процессор транзакций – протоколирование, управление параллельными заданиями, разрешение взаимоблокировок.
Компоненты: компилятор, исполняющая машина. Задача управления размещением информации на диске и обмена ею между диском и ОП решается менеджером хранения данных. Менеджер буфера является ответственным за разбиение доступной ОП на буферные участки страницы, куда может быть помещено содержание дисковых блоков.
Постреляционная модель данных
Расширенная реляционная модель, снимающая ограничение неделимости данных в записях таблиц. Допускает многозначные поля. Набор значений считается самостоятельной таблицей, встроенной в основную.
Достоинства: возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей – обеспечивает высокую наглядность представления.
Недостатки: сложность решения проблемы целостности и непротиворечивости данных.
Хранилище данных появились из систем поддержки. Хранилище получает данные из систем. Можно моделировать методами многомерного моделирования.
Факты - основные виды бизнес деятельности и факторы, влияющие на данный бизнес.
Измерения можно разбить на категории: вещи, места, время, люди. Нарушается звездообразная структура и создаётся таблица развертывания измерений.
Pata mining - - процесс выявления значимых корреляций, тенденций в больших объемах данных
OLAP: многомерный и реляционный.
38. Методы защиты информации.
Целью защиты является обеспечение безопасности.
Выделить уязвимые элементы, выявить угрозу, сформировать требования, выбрать методы и средства выполнения поставленных требований. Под угрозой – возможность преднамеренного или случайного действия, которое приведёт к нарушению безопасности хранимой и обработанной информации.
Виды угроз:
· Несанкционированное использование ресурсов ВС: использование данных, исследование программ.
· Некорректное использование: некорректное изменение (ввод неверных данных)
· Проявление ошибок в программных и аппаратных средствах.
· Перехват данных в линиях связи и системах передачи
· Несанкционированная регистрация
· Хищение устройств
· Несанкционированное нарушение защиты
Последствия нарушения защиты - получение секретных сведений, снижение производительности системы, невозможность загрузки ОС, материальный ущерб и другие последствия.
3 задачи защиты:
· Защита от хищения информации
· Защита информации от потери
· Защита ВС от сбоев и отказов
4 защитных уровня:
· Внешний уровень
· Уровень отдельных сооружений или помещений
· Уровень компонентов ВС
· Уровень технологических процессов.
Надежность – способность точно и своевременно выполнять функции.
Методы защиты делятся на 4 класса:
· Физические
· Аппаратные
· Программные
· Организационные
Защита от несанкционированного доступа, 2 способа:
· Парольная
· Путём идентификации и аутентификация (запрос секретного пароля, применение личных карт). Надежные – биометрические. Недостаток – дороговизна.
Средства защиты: основные и дополнительные
Основные (парольная, шифрование данных и программ, установление прав доступа, защита полей) - просмотр данных, изменение редактирование данных, добавление новых записей, изменение структуры таблицы. В полях таблицы уровни: полный запрет, только чтение, разрешение.
Дополнительные средства – встроенные средства контроля значений, повышение достоверности, обеспечение достоверности связей таблиц, организация совместного использования БД в сети, разработка процедур
39. Три уровня представления данных в ИС
Существует 3 уровня: логический уровень, уровень хранения и физический уровень.
На логическом уровне работают с логическими структурами данных, отражающими реальные отношения, которые существуют между объектами и их характеристиками, т. е. указывающими в каком виде данные представляются пользователю системы. Единицей информации на этом уровне является логическая запись. Каждый объект, описываемый соответствующей логической записью, характеризуется определёнными признаками, являющимися атрибутами записи. На логическом уровне устанавливается перечень признаков, полностью характеризующий описываемый класс объектов. Совокупность и их взаимосвязь определяют внутреннюю структуру логической записи.
На логическом уровне представления данных не учитывается техническое и математическое обеспечение данных.
На уровне хранения оперируют со структурами хранения - представления логической структуры данных в памяти ЭВМ. Структура хранения должна полностью отображать логическую структуру данных и поддерживать её в процессе функционирования АИС. Единицей информации на этом уровне также является логическая запись.
Поддержание структуры хранения осуществляется программными средствами.
На физическом уровне представление данных оперируют с физическими структурами данных. На этом уровне решаются задачи реализации структуры хранения непосредственно в конкретной памяти конкретной ЭВМ. Единицей информации на этом уровне является физическая запись, представляющая участок носителя на котором размещаются одна или несколько логических записей.
При разработке структур данных всех уровней должен обеспечиваться принцип независимости данных. Физическая независимость данных означает, что изменения в физическом расположении данных и в техническом обеспечении системы не должны отражаться на логических структурах и прикладных программах, т. е. не должны вызывать в них изменений.
Логическая независимость данных означает, что изменения в структурах хранения не должны вызывать изменений в логических структурах данных и в прикладных программах.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
