
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
КЛАССИФИКАЦИЯ ВЕБ-СТРАНИЦ С ПОМОЩЬЮ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ
1, 1, 2, 3
1) Санкт-Петербургский государственный университет, Санкт-Петербург
2) Школа Бизнеса Стенфордского университета, Стенфорд (США)
3) Университет Южной Калифорнии, Лос-Анжелес (США)
E-mail: *****@***com, polina. *****@***com
Классификация текстов – задача, традиционно решаемая с помощью алгоритмов, основанных на исследовании ключевых слов (key words). В случае русского языка этот подход вызывает трудности, связанные с особенностями языка и структуры слов, такими как: различные формы слов и окончания, плавающие гласные в корне и т. д. Кроме этого, веб-страницы, как известно, носят зашумленный характер. Это вызывает необходимость обращаться к алгоритмам, использующим другие классовые признаки. Такими являются решения, основанные на ядерных функциях (ядрах). Из последних это машины поддерживающих векторов (support vector machines), анализ главных компонентов и др. Построение строковых ядер (например, String Subsequence Kernel) и использование их в алгоритмах SVM и Voted Perceptron эффективно решает задачу классификации веб-страниц на русском языке.
Терминология. Ядром называется скалярное произведение в пространстве признаков. В нашем случае это пространство порождено всеми подстроками длины k. Именно в нем будут применены алгоритмы классификации.
SVM – это класс алгоритмов, которые сочетают в себе теорию статистического обучения с различными способами оптимизации и идеей отображений, построенных на ядрах. В простейшем виде они находят разделяющую гиперплоскость между двумя множествами точек, максимизирующую допуск (расстояние между плоскостью и ближайшей точкой одного из множеств). Это решение имеет несколько интересных статистических свойств. Одно из них – то, что решение (с максимальным допуском) не зависит от размерности пространства, в котором производится разделение. Таким образом, можно работать в пространствах с очень большой размерностью, например, порожденных ядрами, без проблемы слишком сильного приближения обучающей выборки (overfitting).
Задача классификации. Рассмотрим проблему классификации с двумя классами. Одна из возможных формализаций этой задачи – это построить функцию f:R^N ->{-1,+1}, используя обучающий набор реализаций независимых случайных величин, распределенных согласно неизвестному распределению вероятности P(x, y)
(x1,y1),...,(xn, yn) R^NxY, Y={-1,+1}
Экземпляр будет отнесен к классу '+1', если f(x)³0 и к классу '-1' в противном случае. Тестовые данные распределены согласно тому же распределению, что и обучающая выборка. Оптимальная функция f должна минимизировать ожидаемый риск: R[f]= òl(f(x),y)dP(x, y), где l -- это функция потерь, например 0/1. Так как исходное распределение вероятности P(x, y) неизвестно, то риск не может быть оптимизирован напрямую. Таким образом, необходимо определить функцию с минимальным эмпирическим риском
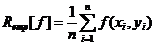 .
.
Алгоритм классификации. Существуют требования для алгоритма обучения, которые обеспечивают асимптотическую сходимость эмпирического риска к ожидаемому риску. Тем не менее, для маленьких выборок возможны большие отклонения и проблема слишком сильного приближения (overfitting). Один из способов избежать этого – ограничить класс функций F. В результате такого ограничения простым функциям, объясняющим большое количество данных, отдается предпочтение перед сложными функциями, приближающими данные лучше.
Алгоритмы в пространствах признаков используют следующую идею: с помощью нелинейного отображения Ф:R^N->F данные {x1},...,{xn}ÎR^N, x->Ф(x) отображаются в пространство с много большей размерностью F.
После этого для данной задачи обучения рассматривается тот же самый алгоритм в пространстве F вместо R^N, т. е. рассматривается выборка (Ф(x1),y1),...,(Ф(xn),yn)ÎFxY. В пространстве F ищется простое решение задачи классификации. Теория машинного обучения утверждает, что верно следующее: обучение в F может быть легче, если используется сравнительно простой класс функций (например, только линейные классификаторы). Все возможности для усложнения исходного класса функций заключены в отображении Ф. При оценке сложности задачи значение имеет не размерность пространства, а сложность класса функций.
Умея быстро считать скалярное произведение, легко классифицировать множества в пространстве-образе. Для этого и используются ядра:
(Ф(x1),Ф(x2)) = k(x1,x2)
Если функция k может быть вычислена без прямого обращения к координатам Ф(x1),Ф(x2), то этот алгоритм окажется эффективным даже в пространстве очень высокой размерности.
В случае алгоритмов SVM задача оптимизации будет выглядеть следующим образом:
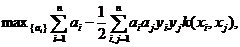
где 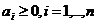 и
и 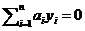 . То есть решение исходной задачи классификации может быть получено с помощью ядерной функции k, опирающейся только на скалярное произведение.
. То есть решение исходной задачи классификации может быть получено с помощью ядерной функции k, опирающейся только на скалярное произведение.
Ядро. Построим ядерную функцию SSK (String Subsequence Kernel) в случае классификации двух текстовых документов. Рассмотрим текст как последовательность символов, не учитывая их смысловой нагрузки. В этом случае пространство признаков порождается множеством всех подстрок длины m, упорядоченных, но необязательно строго последовательных, причем степень "разреженности" подстроки по тексту определяется весовой функцией l £ 1. Чем больше общих подстрок имеют два документа, тем более похожими они считаются (тем больше их скалярное произведение). Пространства признаков определим с помощью алфавита S и множества всех строк длины n ![]() . Отображение Ф для строки s – как u-координату Фu(s) для каждой подстроки u строки s. Тогда ядро для 2-х строк s и t дает сумму всех общих подстрок, взвешенных согласно частоте их появления и длине:
. Отображение Ф для строки s – как u-координату Фu(s) для каждой подстроки u строки s. Тогда ядро для 2-х строк s и t дает сумму всех общих подстрок, взвешенных согласно частоте их появления и длине:
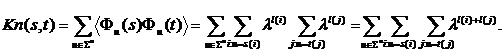
Вычисление такого ядра без обращения к Ф позволяет использовать его в различных кернел-алгоритмах, таких как описанный выше SVM.
