
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МИНистерство ОБРАЗОВАНИЯ И НАУКИ РФ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«ВОЛГОГРАДСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
КАМЫШИНСКИЙ ТЕХНОЛОГИЧЕСКИЙ ИНСТИТУТ (ФИЛИАЛ)
ГОУ ВПО «ВОЛГОГРАДСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
КАФЕДРА «АВТОМАТИЗИРОВАННЫЕ СИСТЕМЫ ОБРАБОТКИ
ИНФОРМАЦИИ И УПРАВЛЕНИЯ»
АЛГОРИТМЫ ПОИСКА
Методические указания к лабораторной работе по дисциплине
«Структуры и алгоритмы обработки данных»

Волгоград
2011
УДК 0
А 45
Алгоритмы поиска: методические указания к лабораторной работе по дисциплине «Структуры и алгоритмы обработки данных» / Сост. ; Волгоград. гос. техн. ун-т. – Волгоград, 2011. – 15 с.
Содержат необходимые материалы для поддержки лабораторных работ по изучению и применению алгоритмов сортировки данных с оценкой их эффективности.
Предназначены для студентов, обучающихся по направлению 654600 «Информатика и вычислительная техника».
Табл. 3. Библиогр.: 6 назв.
Рецензент
Печатается по решению редакционно-издательского совета
Волгоградского государственного технического университета
Ó Волгоградский
государственный
технический
университет, 2011

Лабораторная работа №5.
АЛГОРИТМЫ ПОИСКА
Цель работы: Освоить и закрепить приемы работы с алгоритмами поиска числовых и строковых данных. Получить навыки применения алгоритмов поиска для практических задач.
Ключевые понятия, которые необходимо знать: линейный (последовательный) поиск, бинарный поиск, интерполяционный поиск, алгоритм Кнута-Мориса-Пратта, алгоритм Боуера-Мура-Хорспула, алгоритм Рабина-Карпа.
Время выполнения лабораторного занятия: 3 часа.
Количество баллов (минимальное, максимальное): 6 – 9 баллов.
1 ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Одно из наиболее часто встречающихся в программировании действий – поиск. С точки зрения программирования различают поиск среди числовых и строковых данных.
Для числовых данных наиболее употребительны такие алгоритмы, как:
- последовательный (линейный) поиск,
- бинарный поиск,
- интерполяционный поиск.
Для поиска текстовых данных (поиск подстроки в тексте) наиболее используемы следующие алгоритмы:
- линейный (последовательный) поиск подстроки,
- алгоритм Кнута-Мориса-Пратта,
- алгоритм Боуера-Мура-Хорспула,
- алгоритм Рабина-Карпа.
1.1 Поиск числовых данных
Рассмотрим методы поиска числовых данных для следующей задачи: дан массив mas[N] численных значений (ключей) размером N элементов; необходимо найти позицию заданного ключа K в массиве mas, в случае успешного поиска, или сообщить о том, что К не содержится в mas.
1.1.1 Последовательный (линейный) поиск. «Начать с начала и продолжать, пока не будет найден искомый ключ (значение); затем остановиться» – эта последовательная процедура представляет собой очевидный и самый простой путь поиска [1]. Он применяется, если нет никакой дополнительной информации о разыскиваемых данных.
Пример последовательного поиска приведен в программном примере 1.
/*== Программный пример 1 – Последовательный поиск ==*/
int LineSearch(int[] mas, int k)
{ //k - искомое значение в массиве mas
//результат – позиция значения k в массиве mas
// или -1, если k не содержится в массиве mas
int N = mas. Length; //Длина массива
for (int i = 0; i < N; i++) //Цикл по всем элементам массива
{ if (mas[i] == k) //Проверка очередного элемента массива c k
return i; //Элемент k найден на позиции i
}
return -1; //Элемент k в массиве не найден
}
Когда размер массива небольшой, последовательный поиск работает достаточно быстро. Последовательный поиск достаточно прост, но время его работы прямо пропорционально количеству данных, которые нужно просмотреть; удвоение количества элементов приведет к удвоению времени на поиск, если искомого элемента в массиве нет.
1.1.2 Бинарный поиск. Хорошо известно, что поиск можно сделать значительно более эффективным, если данные будут упорядочены. Один из простых методов поиска в упорядоченном массиве является бинарный поиск (поиск делением пополам), который заключается в следующем:
а) проверяем средний элемент массива с искомым;
б) если это значение больше, чем искомое, то ищем далее в первой части; в противном случае ищем во второй части;
в) повторяем с п. а) до тех пор, пока не найдем нужный элемент или не убедимся, что его в массиве нет.
Пример бинарного поиска приведен в программном примере 2.
/*== Программный пример 2 – Бинарный поиск ==*/
int BinarySearch(int[] mas, int k)
{ //k - искомое значение в массиве mas
//результат – позиция значения k в массиве mas
// или -1, если k не содержится в массиве mas
int L = 0; //Нижняя граница рассматриваемого диапазона
//Верхняя граница рассматриваемого диапазона
int H = mas. Length - 1;
int m;
while (L <= H) //Пока рассматриваемый диапазон не будет пуст
{ m = (L + H) / 2;//Индекс среднего элемента
if(mas[m] == k) //Проверка очередного элемента массива c k
return m; //Элемент k найден на позиции m
if (mas[m] > k)
H = m - 1; //Сдвиг верхней границы
else
L = m + 1; //Сдвиг нижней границы
}
return -1; //Элемент k в массиве не найден
}
Максимальное число сравнений для бинарного поиска равно log2N, округленному до ближайшего целого. Таким образом, этот метод существенно выигрывает по сравнению с последовательным поиском, ведь там ожидаемое число сравнений – N/2.
Следует заметить, что предварительная сортировка массива (с временем порядка N2), требует времени большего чем для выполнения непосредственного поиска. Поэтому, бинарный поиск по сравнению с последовательным поиском дает выигрыш по времени только при многократном использовании.
1.1.3 Интерполяционный поиск. Интерполяционный поиск основан на принципе поиска в телефонной книге, словаре. Вместо сравнения каждого элемента с искомым как при линейном поиске, данный алгоритм производит предсказание местонахождения элемента: поиск происходит подобно бинарному поиску, но вместо деления области поиска на две равные части, интерполяционный поиск производит оценку новой области поиска по расстоянию между ключом и текущим значением элемента. Другими словами, бинарный поиск учитывает лишь знак разности между ключом и текущим значением, а интерполяционный ещё учитывает и модуль этой разности и по данному значению производит предсказание позиции следующего элемента для проверки.
Алгоритмически, отличие интерполяционного поиска от бинарного заключается в формуле расчета индекса элемента делящего область поиска на две части:
m = L + (k - mas[L]) / (mas[H] - mas[L]) * (H - L);
вместо аналогичной формулы для бинарного поиска
m = (L + H) / 2;
В среднем, интерполяционный поиск производит log(log(N)) операций. Число необходимых операций зависит от равномерности распределения значений среди элементов. В плохом случае (например, когда значения элементов экспоненциально возрастают) интерполяционный поиск может потребовать до N операций.
1.2 Поиск подстроки в тексте
Задача поиска подстроки в тексте (образца в тексте) очень часто встречается в программировании, например, при трансляции (при поиске лексем и распознавании операторов), поиске строки запроса в Интернете.
Задачу поиска образца в тексте определим следующим образом. Пусть задан массив S из N символов (текст) и массив P из M символов (образец, шаблон, отыскиваемое слово), причём 0 < M ≤ N. Если для некоторого значения K выполняется равенство S[K+j] = P[j], j = 0..M-1, то говорят, что образец P входит в текст S со сдвигом K.
Требуется найти значение сдвига K первого вхождения образца P в текст S. Будем считать результатом поиска значение К или значение -1, если строка не содержит образец.
1.2.1 Линейный (последовательный) поиск. Простейший алгоритм поиска состоит в непосредственной проверке всех возможных смещений. Проверка заключается в последовательном сравнении символов образца с символами текста (слева направо). При первом несовпадении образец сдвигается на одну позицию вправо и сравнение символов продолжается с первого символа образца.
Пример. Текст S = «АБГАБВ», образец P = «АБВ». Подчеркиванием показаны символы образца участвующие в сравнениях.
Итерация | Сравнения |
S = А Б Г А Б В | |
1 | P = А Б В |
2 | P = А Б В |
3 | P = А Б В |
4 | P = А Б В |
Пример линейного поиска подстроки приведен в программном примере 3. Для обозначения номеров (индексов) сравниваемых символов в строках S и P используются переменные i и j соответственно.
/*== Программный пример 3- Линейный поиск подстроки ==*/
int LineSearch(char[] S, char[] P)
{ int i, j, N, M;
N = S. Length;
M = P. Length;
i = -1;
do {
i++;
j = 0;
//Сравнение символов для смещения i
while(j < M && S[i+j] == P[j])
j++;
//Пока не найден образец и не закончится текст
}while(j < M && i <= N - M);
// Вывод результата поиска
if(j == M) //Образец найден по смещению i
return i;
else
return -1; //Образец не найден
}
Условие j = M соответствует результату «найден». Условие i > N-M соответствует тому, что нигде в строке совпадения с образцом нет. Достаточная эффективность этого алгоритма достигается, если всего лишь после нескольких сравнений пары символов во внутреннем цикле фиксируется их несовпадение Или, если образец расположен в строке, но не в конце текста. В худшем случае (если слово в тексте отсутствует или присутствует в самом конце текста) при поиске потребуется выполнить M*(N-M+1) сравнений.
1.2.2 Алгоритм Кнута-Морриса-Пратта. Алгоритм, изобретённый авторами приблизительно в 1970 году, требует порядка N+M сравнений символов даже в самом плохом случае. Основной принцип алгоритма – не уничтожать ценную информацию предыдущего сравнения. После частичного совпадения начальной части образа с символами строки при каждом несовпадении двух символов образец сдвигается на максимально возможное количество символов (d ≥ 1) и сравнение строки с образцом (с начала образца) продолжается.
КМП–алгоритм даёт выигрыш, только когда неудаче предшествовало некоторое число совпадений. Лишь в этом случае образец сдвигается более чем на одну позицию (см. рисунок 1).


Рисунок 1 – Идея алгоритма Кнута-Морриса-Пратта.
Символ * означает любое количество любых символов
Величина d[j] равна размеру самой длинной последовательности символов образца, непосредственно предшествующей j-му символу, которая совпадает с началом образца (для j=0 принимают d[j] = -1). Величина d[j] зависит только от образца и может быть вычислена заранее перед операцией поиска (см. пример в таблице 1).
Таблица 1 – Вычисление значений d[j] для образца P = «АБРАКАДАБРА»
Позиция несовпадающего символа – j | Совпавшая часть | Значение d[j] |
0 | - | -1 |
1 | А | 0 |
2 | АБ | 0 |
3 | АБР | 0 |
4 | АБРА | 1 |
5 | АБРАК | 0 |
6 | АБРАКА | 1 |
7 | АБРАКАД | 0 |
Окончание табл. 1
Позиция несовпадающего символа – j | Совпавшая часть | Значение d[j] |
8 | АБРАКАДА | 1 |
9 | АБРАКАДАБ | 2 |
10 | АБРАКАДАБР | 3 |
Пример. Поиск образца «АБРАКАДАБРА» в тексте «ЗААБРАКАДАБРИЛАСЬ_АБРАКАДАБРА». Подчеркиванием показаны символы образца участвующие в сравнениях.
j | Сдвиг j-d[j] | Сравнения |
З А А Б Р А К А Д А Б Р И Л А С Ь _ А Б Р А К А Д А Б Р А | ||
0 | 0 – (–1) = 1 | А Б Р А К А Д А Б Р А |
1 | 1 – 0 = 1 | А Б Р А К А Д А Б Р А |
10 | 10 – 3 = 7 | А Б Р А К А Д А Б Р А |
3 | 3 – 0 = 3 | А Б Р А К А Д А Б Р А |
0 | 0 – (–1) = 1 | А Б Р А К А Д А Б Р А |
0 | 0 – (–1) = 1 | А Б Р А К А Д А Б Р А |
1 | 1 – 0 = 1 | А Б Р А К А Д А Б Р А |
0 | 0 – (–1) = 1 | А Б Р А К А Д А Б Р А |
0 | 0 – (–1) = 1 | А Б Р А К А Д А Б Р А |
0 | 0 – (–1) = 1 | А Б Р А К А Д А Б Р А |
А Б Р А К А Д А Б Р А |
Пример алгоритма Кнута-Морриса-Пратта приведен в программном примере 4. Для обозначения номеров (индексов) сравниваемых символов в строках S и P используются переменные i и j соответственно.
/*== Программный пример 4 - Алгоритм Кнута-Морриса-Пратта ==*/
int KMPSearch(char[] S, char[] P)
{ int i, j, k, N, M;
int []d; //Массив сдвигов
N = S. Length;
M = P. Length;
d = new int[M];
// Заполнение массива сдвигов d
j = 0;
k = -1;
d[0] = -1;
while(j < M-1)
{ while(k >= 0 && P[j] != P[k])
k = d[k];
j++;
k++;
if(P[j] == P[k])
d[j] = d[k];
else
d[j] = k;
}
// Поиск слова P в тексте S
i = 0;
j = 0;
while(j < M && i < N)
{ while(j >= 0 && S[i] != P[j])
j = d[j]; //Сдвиг слова
i++;
j++;
}
// Вывод результата поиска
if(j == M)
return i - j; //Образец найден по смещению i-j
else
return -1; //Образец не найден
}
1.2.3 Алгоритм Боуера-Мура-Хорспула. Алгоритм Боуера-Мура-Хорспула (БМХ - поиск), не только улучшает обработку самого плохого случая, но и даёт выигрыш в промежуточных ситуациях.
В поиске БМХ сравнение символов начинает с конца образца. В случае частичного совпадения образец сдвигается на величину, зависящую от символа текста, стоящего напротив последнего символа образца (рисунок 2).
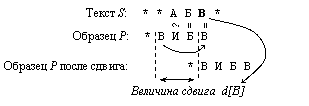
Рисунок 2 – Идея алгоритма Боуера-Мура_Хорспула.
Символ * означает любое количество любых символов
Величина сдвига d[x] – определяется как расстояние от самого правого в образце вхождения х до его конца (число букв в образце справа от последнего вхождения буквы). Для остальных символов d[x] = M, где M - длина образца. Если символ х содержится только в конце образца (и только один раз), то для него d[х] равно M.
Величина сдвига d[x] зависит только от образца и может быть рассчитана заранее перед фактическим поиском (см. пример в таблице 2).
Таблица 2 – Вычисление значений d[х] для образца P = «АБРАКАДАБРА»
Символ | А | Б | Р | К | Д | Остальные символы |
Сдвиг d[x] | 3 | 2 | 1 | 6 | 4 | 11 |
Пример. Поиск образца «АБРАКАДАБРА» в тексте «ЗААБРАКАДАБРИЛАСЬ_АБРАКАДАБРА». Подчеркиванием показаны символы образца участвующие в сравнениях, жирным начертанием выделены символы, стоящие напротив последней буквы образца и используемые для расчета сдвигов.
Сдвиг d[х] | Сравнения |
З А А Б Р А К А Д А Б Р И Л А С Ь _ А Б Р А К А Д А Б Р А | |
d[Б] = 2 | А Б Р А К А Д А Б Р А |
d[И] = 11 | А Б Р А К А Д А Б Р А |
d[А] = 3 | А Б Р А К А Д А Б Р А |
d[Б] = 2 | А Б Р А К А Д А Б Р А |
А Б Р А К А Д А Б Р А |
Пример алгоритма Боуера-Мура-Хорспула приведен в программном примере 5. Для обозначения номеров (индексов) сравниваемых символов в строках S и P используются переменные i и j соответственно.
/*== Программный пример 5 - Алгоритм Боуера-Мура-Хорспула ==*/
int BMHSearch(char[] S, char[] P)
{ int i, j, k, pos = -1, N, M;
int []d = new int[256];
N = S. Length;
M = P. Length;
// Формирование таблицы сдвигов d
for(i = 0; i < 256; i++)
d[i] = M;
for(i = 0; i < M - 1; i++)
d[P[i]] = M – i - 1;
// Поиск образца P в тексте S
i = M;
do{
k = i;
j = M;
do{
j--;
k--;
}while(j >= 0 && S[k] == P[j]);
if(j == -1)
pos = i - M;
else
i += d[S[i - 1]];
}while(i <= N && j >= 0);
if(j > -1)
pos = -1;
return pos;
}
Алгоритм требует O(N) сравнений. В самом благоприятном случае, когда последний символ образа попадает на несовпадающий символ, требуется N / M сравнений.
1.2.4 Алгоритм Рабина-Карпа. Алгоритм Рабина-Карпа основан на следующей идее. Вырежем окошечко длины M, будем двигать его по входному тексту и смотреть, не совпадёт ли текст в окошечке с заданным образцом. Сравнивать по буквам долго. Вместо этого создаём некоторую функцию, определённую на словах длины M. Если значение этой функции на тексте в окошечке и на образце различны, то совпадений нет. Если значения одинаковы, проверяем совпадение по буквам. Выигрыш возможен за счёт того, что при сдвиге окошечка текст в окошечке не меняется полностью, а лишь добавляется буква в конце и убирается в начале. Эти данные следует учитывать при изменении значения функции. При построении функции можно заменить все буквы их кодами. Тогда функция будет вычислять сумму этих чисел или значение многочлена степени M в точке х = 10 или в точке х = 2. В программном примере 6 использован последний вариант.
/*== Программный пример 6 - Алгоритм Рабина-Карпа ==*/
int RabinSearch(char[] S, char[] P)
{ int i, pos, c, N, M;
double a, b;
N=S. Length; //Длина текста
M=P. Length; //Длина образца
a=0;
for(i=0;i<M;i++) //Вычисление функции для образца
a=a*2+P[i];
b=0;
for(i=0;i<M;i++) //Вычисление функции для окошка в тексте
b=b*2+S[i];
i=M-1;
// Поиск образца в тексте
do{
i++;
c=S[i-M]; //первый (удаляемый) символ в окошечке
c=c<<(M-1); //функция для первого символа в окошечке
b=(b-c)*2+S[i]; //функция для сдвинутого окошечка в тексте
}while (i<N-1 && a!=b);
// Вывод результата
if(a==b)
return i-M+1;
else
return -1;
}
}
Данный программный пример проверяет только совпадение текстов в окошечке. Одной этой проверки в некоторых случаях может оказаться недостаточно.
Например, имеется строка «asdfgh» и образец «fgh». Коды используемых символов имеют следующие значения:
a s d f g h
65
Значение функции на образце «fgh» равно 494 и значение функции на тексте «asd» в окошечке также равно 494, а посимвольного совпадения нет («asd» ≠ «fgh»).
Для устранения этого недостатка, следует дополнить алгоритм посимвольной проверкой образца и текста в окошечке? в случае равенства функций (a = b).
2 ЗАДАНИЕ НА ЛАБОРАТОРНУЮ РАБОТУ
Задание 1 (6 баллов).
1. Сгенерировать массив целых случайных чисел размером N = 1000. (Для генерации случайных чисел используйте класс System.Random).
2. Отсортировать полученный массив любым методом сортировки.
3. Ввести с клавиатуры некоторое целое число.
4. Используя метод интерполяционного поиска, определить, позицию введенного числа в массиве, если оно в нем присутствует.
Задание 2 (+1 балла). Составить программу, которая в заданном текстовом файле ищет все вхождения, введенного пользователем слова, формируя список позиций (от начала файла) искомого слова. Метод поиска – любой, кроме линейного поиска подстроки.
Задание 3 (+2 балла). Составить программу, которая для заданного текстового файла создает файл-глоссарий. Файл-глоссарий содержит информацию обо всех словах, входящих в исходный текст и список ссылок на строки, в которых данное слово встречается. Файл-глоссарий должен иметь структуру, представленную в таблице 3.
Таблица 3 – Пример таблицы с результатами выполнения задания 3
Слово | Список ссылок на строки |
Слово1 | 1, 3, 67 |
Слово2 | 1, 2, 3 |
… |
3 КОНТРОЛЬНЫЕ ВОПРОСЫ
1. В чем заключается метод последовательного поиска?
2. В чем заключается метод бинарного поиска?
3. В чем заключается метод интерполяционного поиска?
4. В чем заключается метод поиска Кнута-Мориса-Пратта?
5. В чем заключается метод поиска Боуера-Мура-Хорспула?
6. В чем заключается метод поиска Рабина-Карпа?
Литература
1. Кнут, Д. Искусство программирования. В 3 т. Т. 3. Сортировка и поиск /Д. Кнут; 3-е изд.; пер. с англ. – М.: Издательский дом «Вильямс», 2000. – 800 с.
2. Седжвик, Р. Фундаментальные алгоритмы на С++. Анализ. Структуры данных. Сортировка. Поиск: Пер. с англ. / Р. Седжвик. – К.: Издательство «ДиаСофт», 2001. – 688 с.
3. Красиков, . Просто как дважды два / , . – М.: Эксмо, 2006. – 256 с.
4. Далека и структуры данных: учеб. пособие / , ко, , . – Харьков:ХГПУ, 2000. – 241 с.
5. Чекулаева, данных. Сортировка. Поиск: метод. указания для студентов вечернего и дневного отделения механико-математического факультета / . – Ростов-на-Дону: РГУ, 2001. – 26 с.
6. Википедия – свободная энциклопедия: поиск подстроки [Электронный ресурс]. – 2010. – http://ru. wikipedia. org/wiki/%D0%9F%D0%BE%D0%B8%D1%81%D0 %BA_%D0 %BF%D0%BE%D0%B4%D1%81%D1%82%D1%80%D0%BE%D0%BA%D0%B8.
СОДЕРЖАНИЕ
1 ТЕОРЕТИЧЕСКАЯ ЧАСТЬ.. 3
1.1 Поиск числовых данных. 3
1.2 Поиск подстроки в тексте. 5
2 ЗАДАНИЕ НА ЛАБОРАТОРНУЮ РАБОТУ.. 12
3 КОНТРОЛЬНЫЕ ВОПРОСЫ... 12
Литература. 13
Составитель: Александр Эдуардович Панфилов
Алгоритмы поиска
Методические указания к лабораторной работе по дисциплине
«Структуры и алгоритмы обработки данных»
Под редакцией автора
Темплан 2011 г., поз. № 24К.
Подписано в печать г. Формат 60×84 1/16.
Бумага листовая. Печать офсетная.
Усл. печ. л. 0,93. Уч.-изд. л. 0,86.
![]() Тираж 50 экз. Заказ №
Тираж 50 экз. Заказ №
Волгоградский государственный технический университет
г. Волгоград, пр. Ленина, 28, корп. 1.
Отпечатано в КТИ
, каб. 4.5
