


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Новосибирский государственный технический университет
Кафедра вычислительной техники
 |
Лабораторная работа №2
по дисциплине «Структуры и Алгоритмы»
«Коллекция данных - сбалансированное дерево поиска».
Вариант: 1 Преподаватель:
Группа: АМ-210
Студенты:
Новосибирск, 2004
1. Техническое задание.
Изучение и исследование методов балансировки двоичных деревьев поиска на примере АТД «Сбалансированное двоичное дерево поиска». Освоение методики модификации коллекций с помощью механизма наследования классов.
Задание:
Вар №1: АТД «АВЛ – дерево», как модификация АТД «BST-дерево». Алгоритмы операций АТД реализуются в рекурсивной форме.
2. Описание программы.
В файле BSTNode. h содержатся класс BSTnode – узел дерева,
В файле AVLNode. h содержатся класс AVLnode наследуемый от BSTnode – узел сбалансированного дерева,
В BSTTree. h содержатся класс BSTTree – дерево, не сбалансированное.
В AVLTree. h содержатся класс AVLTree наследуемый от BSTTree –сбалансированное дерево.
В stack. h содержатся класс TStack, который сохраняет все элементы дерева и Iterator, который позволяет иметь последовательный доступ к элементам дерева.
3. Формат АТД
3.1. АТД «АВЛ–дерево», как модификация АТД «BST-дерево».
Бинарные деревья поиска предназначены для быстрого доступа к данным. В идеале разумно сбалансированное дерево имеет высоту порядка O(log2n). Однако при некотором стечении обстоятельств дерево может оказаться вырожденным. Тогда высота его будет O(n), и доступ к данным существенно замедлится. Мы рассмотрим модифицированный класс деревьев, обладающих всеми преимуществами бинарных деревьев поиска и никогда не вырождающихся. Они называются сбалансированными или AVL-деревьями. Под сбалансированностью будем понимать то, что для каждого узла дерева высоты обоих его поддеревьев различаются не более чем на 1. Строго говоря, этот критерий нужно называть AVL-сбалансированностью в отличие от идеальной сбалансированности, когда для каждого узла дерева количества узлов в левом и правом поддеревьях различаются не более чем на 1. Здесь мы всегда будем иметь в виду AVL-сбалансированность.
Данные:
Параметры:
Указатель на корень дерева root
Операции:
Конструктор:
Вход: нет
Начальные значения: root = нулю
Процесс: нет
Постусловие: создано пустое дерево
Доступ к значению элемента с заданным ключом:
Вход: Значение, которое надо найти
Предусловия: нет
Процесс: просматриваем всё дерево на наличие элемента с заданным ключом
Выход: возвращает FALSE, если не нашли элемент TRUE если нашли
Постусловие: нет
Включение нового элемента с заданным ключом:
Вход: Новый элемент
Предусловия: нет
Процесс: Вставляет в дерево новый элемент
Выход: возвращает FALSE, если такой элемент есть в дереве TRUE, если вставили
Постусловие: После вставки осуществляется балансировка дерева
Удаление элемента с заданным ключом:
Вход: Удаляемый элемент
Предусловия: нет
Процесс: удаление элемента из дерева
Выход: возвращает FALSE, если такого элемента нет в дереве TRUE, если удалили
Постусловие: после удаления осуществляется балансировка дерева
Опрос размера дерева:
Вход: нет
Предусловия: нет
Процесс: нет
Выход: текущий размер
Постусловие: нет
Очистка дерева:
Вход: нет
Предусловия: нет
Процесс: очищаем список
Выход: нет
Постусловие: освобождается память, занимаемая деревом
Проверка дерева на пустоту:
Вход: нет
Предусловия: нет
Процесс: нет
Выход: возвращает FALSE, если дерево пусто TRUE, если дерево не пусто
Постусловие: нет
«АТД» Класс итератор сбалансированного дерева поиска.
Сканирование узлов дерева более сложно, чем сканирование массивов и последовательных списков, так как дерево является нелинейной структурой и существует несколько способов прохождения дерева. Мы уже разбирали эти способы выше. Проблема каждого из них состоит в том, что до завершения рекурсивного процесса из него невозможно выйти. Нельзя остановить сканирование, проверить содержимое узла, выполнить какие-нибудь операции с данными, а затем вновь продолжить сканирование со следующего узла дерева. Используя же итератор, клиент получает средство сканирования узлов дерева, как если бы они представляли собой линейный список, без обременительных деталей алгоритмов прохождения, лежащих в основе процесса.
Наш класс использует класс Stack и наследуется от базового класса итератора. Поэтому сначала опишем класс Stack и базовый класс итератора.
Спецификация класса Stack:
template <class T>
class TStack {
enum { ssize = 100 };
T stack[ssize];
int top;
public:
TStack() ;
void push(T i);
T pop();
bool is_empty();
bool is_full();
void reset();
};
Данные: указатель на вершину стека.
Конструктор:
Вход: нет
Начальные значения: пустой стек
Процесс: инициализация вершины стека.
Выход: нет
Постусловие: создан пустой стек
Поместить значение в стек:
Вход: помещаемое в стек значение
Предусловие: наличие в стеке свободного места
Процесс: помещение в стек значения
Выход: нет
Постусловие: добавлен новый элемент в стек.
Получить значение из стека:
Вход: нет
Предусловие: стек не должен быть пуст
Процесс: извлечение из стека значения
Выход: извлеченное значение
Постусловие: уменьшение размера стека на единицу
Проверка стека на пустоту:
Вход: нет
Предусловие: нет
Процесс: проверка указателя стека на значение ноль
Выход: true - Если стек пуст и false – если не пуст.
Постусловие: нет
Проверка стека на полноту:
Вход: нет
Предусловие: нет
Процесс: проверка указателя стека на значение ssize
Выход: true - Если стек полон и false – если не полон.
Постусловие: нет
Сброс вершины стека в ноль:
Вход: нет
Предусловие: нет
Процесс: установка указателя вершины стека в ноль
Выход: нет
Постусловие: стек полностью опустошён, доступ к значениям потерян.
Спецификация класса итератор сбалансированного дерева поиска
template <class T>
class Iterator{
private:
// поддерживать стек адресов узлов
Stack< AVLTreeNode <T> * > S;
// корень дерева и текущий узел
TreeNode<T> *root, *current;
// сканирование левого поддерева используется функцией Next
TreeNode<T> *GoFarLeft(AVLTreeNode<T> *t);
// сканирование левого поддерева используется функцией Next
TreeNode<T> *GoFarRight(AVLTreeNode<T> *t);
public:
// конструктор
Iterator(TreeNode<T> *tree);
// реализации базовых операций прохождения
void Next(void);
void Pred(void);
void Reset(void);
//доступ к данным:
T& Data(void);
};
Данные:
Указатель на вершину дерева и текущий узел этого дерева
Конструктор:
Вход: нет
Предусловие: указатель root должен быть настроен на вершину
Процесс: инициализация указателя дерева и текущего указателя
Выход: нет
Постусловие: создан объект класса «итератор сбалансированного дерева поиска» и прикреплён к соответствующему объекту класса AVLTree;
Переход к следующему элементу дерева:
Вход: нет
Предусловие: указатель current уже указывает на первый узел симметричного сканирования
Процесс: Если правая ветвь узла не пуста, перейти к его правому сыну и осуществить спуск по левым ветвям до узла с нулевым левым указателем, попутно запоминая в стеке адреса пройденных узлов.
Если правая ветвь узла пуста, то сканирование его левой ветви, самого узла и его правой ветви завершено. Адрес следующего узла, подлежащего обработке, находится в стеке. Если стек не пуст, удалить следующий узел. Если же стек пуст, то все узлы обработаны и сканирование завершено.
Выход: нет
Постусловие: указатель на текущий элемент дерева перешёл к следующему элементу
Сброс значения итератора на начальные значения:
Вход: нет
Предусловие: нет
Процесс: установка root на вершину дерева и cur на самого левого сына от этого узла.
Выход: нет
Постусловие: значения указателей обновлены и сканирование дерева поиска можно начать сначала.
Доступ к данным того узла дерева, на который в данный момент настроен текущий указатель
Вход: нет
Предусловие: указатель на текущий узел дерева
Процесс: возврат действительных данных по указателю
Выход: данные, которые мы извлекли из узла дерева
Постусловие: нет
4. Описание пользовательского интерфейса.
В программе имеется удобное меню для пользователя и для лучшего представления операций класса.
Print_tree(some versions)– просмотр дерева,
Insert –добавить элемент в дерево;
Insert N elements – добавление N элементов
Find value – найти элемент в дереве
To clear the tree – очистка дерева
Removing an Element with given value – удаление элемента по значению
Questioning a size of tree – размер дерева
Checking a tree on emptiness – проверка дерева на пустоту
Test – тестирование общей трудоёмкости
Iterator - имеет следующие варианты:
а) Iterator_next – переход к следующему элементу дерева;
б) Iterator_pred – переход к предыдущему элементу дерева;
в) First – переход к началу дерева;
г) Last – переход к концу дерева;
Exit – выход.
Statistic – Статистика трудоемкости при вставке, удаление, просмотре
To clear the statistic – очистка статистики
5. Описание методики тестирования трудоёмкости операций
Методику тестирования трудоёмкости операций начнём с объяснения самой сути. Перед началом тестирования пользователь должен ввести количество операций, которое он хочет проделать с объектами деревьев. В этом тесте мы должны сопоставить основные показатели трудоёмкости при операциях вставки, удаления и поиска для объектов двух классов: «Двоичное дерево поиска» и «Двоичное сбалансированное дерево поиска». Тем самым нашей задачей, в конечном счёте, является демонстрация превосходства АВЛ - деревьев над БСТ - деревьями.
В цикле мы последовательно производим операции вставки, удаления и поиска, причём мы должны учитывать многочисленные промашки, возникающие при выполнении этих операций. Поэтому методика тестирования строится на продавливающем тестировании, т. е. выполнении операций до тех пор, пока они не приведут к успеху. Таким образом, мы, конечно, контролируем размерность обоих деревьев, не позволяя опустеть и переполниться.
Важным моментом является создание промахов, оно делается специально. Это нужно также для тестирования и получения стохастических оценок трудоёмкости основных операций с деревьями.
6. Анализ теоретических показателей трудоемкости и их сопоставление с практическими результатами:
Теоретические показатели трудоемкости
Структура данных | Поиск элемента в среднем случае | Поиск элемента в худшем случае |
Сбалансированное дерево(AVL) | O(log2n). | O(log2n). |
Несбалансированное дерево (BST) | O(log2n). | O(N) |
Экспериментальные показатели трудоёмкости при вставке, удалении и поиске N элементов в дереве размера N (средний случай).
N | AVL (Рис. 1) | BST (Рис. 2) | ||||||
I | F | D | C | I | F | D | C | |
100 | 5 | 5 | 7 | 6 | 4 | 5 | 5 | 5 |
200 | 6 | 6 | 8 | 7 | 6 | 6 | 6 | 6 |
300 | 7 | 7 | 9 | 8 | 6 | 6 | 7 | 7 |
400 | 7 | 7 | 9 | 8 | 7 | 7 | 8 | 7 |
500 | 8 | 8 | 10 | 9 | 7 | 7 | 8 | 8 |
1000 | 9 | 9 | 11 | 10 | 9 | 9 | 10 | 9 |
2000 | 10 | 10 | 12 | 11 | 11 | 11 | 12 | 11 |
3000 | 10 | 10 | 12 | 11 | 10 | 10 | 10 | 10 |
4000 | 11 | 11 | 13 | 11 | 10 | 10 | 11 | 10 |
5000 | 11 | 11 | 13 | 12 | 12 | 12 | 12 | 12 |
10000 | 12 | 12 | 14 | 13 | 11 | 12 | 12 | 12 |
15000 | 12 | 12 | 14 | 13 | 13 | 13 | 14 | 13 |
20000 | 14 | 12 | 14 | 13 | 13 | 13 | 14 | 13 |
30000 | 14 | 12 | 15 | 14 | 15 | 15 | 15 | 15 |
Экспериментальные показатели трудоёмкости при вставке, удалении и поиске N элементов в дереве размера N (худший случай).
N | AVL(Рис. 3) | BST(Рис. 4) | ||||||
I | F | D | C | I | F | D | C | |
100 | 5 | 5 | 7 | 6 | 27 | 32 | 36 | 32 |
200 | 6 | 6 | 8 | 7 | 56 | 60 | 59 | 59 |
300 | 7 | 7 | 9 | 8 | 83 | 89 | 89 | 87 |
500 | 8 | 7 | 9 | 8 | 144 | 149 | 150 | 148 |
1000 | 9 | 9 | 12 | 10 | 280 | 291 | 279 | 283 |
5000 | 11 | 11 | 13 | 12 | 1396 | 1396 | 1414 | 1403 |
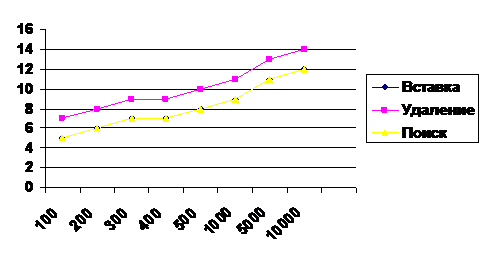
Рис.1 (AVL - дерево)
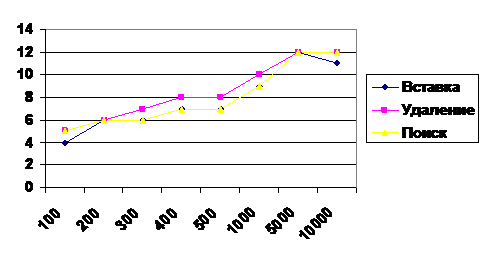
Рис. 2 (BST - дерево)
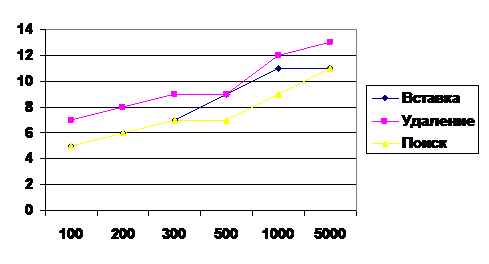
Рис.3 (AVL - дерево)
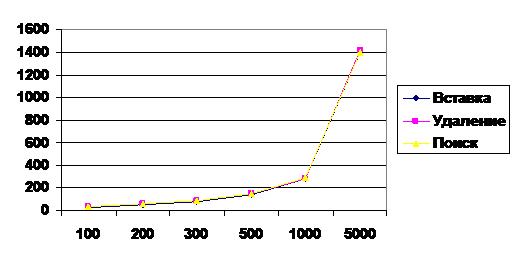
Рис. 4 (BST - дерево)
Перед началом сопоставления мы привели таблицу теоретических показателей трудоёмкости базовых операций вставки, удаления и поиска. Затем, исследуя экспериментальные показатели и сопоставляя их с теоретическими, мы пришли к выводу, что эти показатели совпадают. Анализ проводился при среднем состоянии АТД (как было указано в методических указаниях к лабораторной работе). Для большей наглядности приведен график: в виде диаграмм. Для худшего случая когда BST дерево вырождается в линейный список видно превосходство AVL дерева.
7. Вывод.
В процессе лабораторной работы:
1) Изучение и исследование методов балансировки двоичных деревьев поиска на примере АТД «Сбалансированное двоичное дерево поиска».
2) Освоение методики тестирования трудоёмкости множества операций для данного вида коллекции.
3) Повысили навыки программирования шаблонных классов.
4) Освоение методики модификации коллекций с помощью механизма наследования классов.
8. Список используемой литературы.
1) Фундаментальные алгоритмы на С++. Анализ/Структуры данных/Сортировка/Поиск: Пер. с английского/Роберт Сеждвик. – СПб. : , 2002. – 688 с.
2) Глушаков С. В.
Язык программирования С++ /Худож. – оформитель . – Харьков: Фолио, 2002 – 500.
3) Подбельский С. С.
Программирование на языке Си : Учебное пособие. 2 – е доп.
Изд. – М.: Финансы и статистика, 2002 – 600 с.
4) С++ язык программирования “И. В.К.-СОФТ” Москва 1991
5) Основной источник – Internet.
9. Описание работы программы на контрольных примерах
Шаблон дерева может хранить указатели на объекты типа lond, int, double, а также при небольшом изменение кода программы в списке могут хранится указатели на строчка (char *), но это будет доработано позже…
10. Тексты программных модулей (приложение).
Прилагается файл!!!
