

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Пусть целевая функция имеет вид
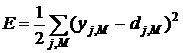 . (4)
. (4)
Коэффициент ½ выбран из соображений более короткой записи последующих формул. Задача обучения нейронной сети состоит в том, чтобы найти такие коэффициенты ![]() , при которых достигается минимум
, при которых достигается минимум ![]() (Е
(Е![]() 0). Обозначим q – номер произвольного внутреннего слоя нейронной сети, Q – номер выходного слоя.
0). Обозначим q – номер произвольного внутреннего слоя нейронной сети, Q – номер выходного слоя.
Для простоты индексации рассмотрим случай, когда на вход подается только один пример, и целевая функция
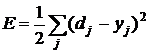 . (5)
. (5)


Рис.4.3. Схема связей между нейронами слоя ![]() и слоя
и слоя ![]() в сети прямого распространения
в сети прямого распространения
Приращение целевой функции при малом изменении параметров сети в результате суммирования вклада нейронов в каждом слое q составит
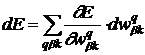 . (6)
. (6)
Индекс ![]() обеспечивает суммирование изменений по слоям, индекс
обеспечивает суммирование изменений по слоям, индекс ![]() обеспечивает суммирование по нейронам слоя с номером
обеспечивает суммирование по нейронам слоя с номером ![]() , а индекс
, а индекс ![]() обеспечивает суммирование по выходам нейронов из слоя с номером
обеспечивает суммирование по выходам нейронов из слоя с номером ![]() . Для движения в процессе обучения к минимуму величины
. Для движения в процессе обучения к минимуму величины ![]() необходимы такие изменения весов
необходимы такие изменения весов ![]() , чтобы было обеспечено изменение целевой функции
, чтобы было обеспечено изменение целевой функции ![]() <0. Подходящим является выбор
<0. Подходящим является выбор
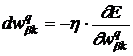 , (7)
, (7)
где малый параметр величины шага ![]() >0 гарантирует такое поведение. Тогда
>0 гарантирует такое поведение. Тогда
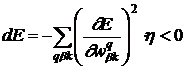 , (8)
, (8)
что обеспечивает уменьшение ![]() при достаточно малом значении
при достаточно малом значении ![]() . Из выражения (8) следует, что вклады каждого слоя, каждого нейрона и каждой связи нейрона в уменьшение величины
. Из выражения (8) следует, что вклады каждого слоя, каждого нейрона и каждой связи нейрона в уменьшение величины ![]() в этом случае независимы и аддитивны. Выходное значение каждого слоя определяется универсальной функцией активации.
в этом случае независимы и аддитивны. Выходное значение каждого слоя определяется универсальной функцией активации.
Рассмотрим зависимость ошибки на выходе сети от параметров-весов в слое с номером ![]() для нейрона с номером
для нейрона с номером ![]() и связи между нейроном предыдущего слоя с номером
и связи между нейроном предыдущего слоя с номером ![]() . Вычислим соответствующую частную производную
. Вычислим соответствующую частную производную
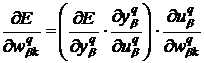 , (9)
, (9)
где 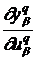 =
=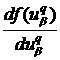 ,
, 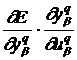 =
= ![]() , а в выходном слое
, а в выходном слое ![]() . В выходном слое со значениями на выходе
. В выходном слое со значениями на выходе ![]() имеем
имеем
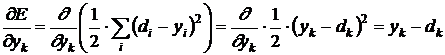 . (10)
. (10)
В произвольном текущем слое производная 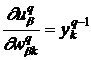 , где q – номер текущего слоя,
, где q – номер текущего слоя, ![]() - номер предыдущего слоя. Поскольку
- номер предыдущего слоя. Поскольку 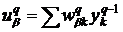 , то
, то 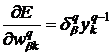 .
.
Рассмотрим изменение параметров отклика сети, перейдя к переменным слоя, отстоящего на один слой дальше от выходного слоя:
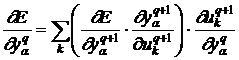 . (11)
. (11)
Умножим обе части на ![]() :
:
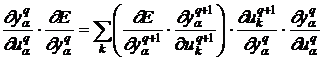 , (12)
, (12)
и далее обозначим
![]() =
=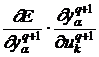 , (13)
, (13)
а
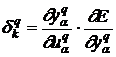 . (14)
. (14)
Тогда получим
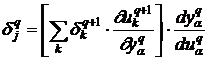 . (15)
. (15)
Для униполярной функции активации
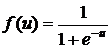 ,
,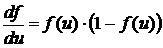 , (16)
, (16)
и параметры вычисляются в соответствии с формулами
![]() ;
; ![]() , (17)
, (17)
где ![]() - правильное значение на выходе последнего слоя сети. При этом
- правильное значение на выходе последнего слоя сети. При этом
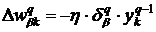 . (18)
. (18)
4.3. Алгоритм вычисления весов нейронов в соответствии с методом обратного распространения ошибки:
Шаг 1. Подать на входы сети один из примеров и вычислить все значения в сети от входа к выходу.
Шаг 2. Рассчитать ![]() .
.
Шаг 3. Рассчитать ![]() и
и ![]() .
.
Шаг 4. Вычислить скорректированные веса нейронов
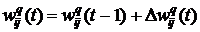 ,
,
где t – номер шага.
Шаг 5. Если ошибка сети существенна (мы сравниваем контрольный результат и то, что получили), то снова переходим к шагу 1. Иначе обучение прекращается.
Для лучшей сходимости алгоритма предпочтительно обучающие примеры подавать вразбивку.
Формулы, задающие порядок вычислений в соответствии с описанным алгоритмом имеют вид:
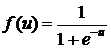 , (19)
, (19)
Для выходного слоя вычисляются вспомогательные величины
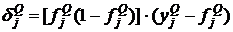 , (20)
, (20)
где j – номер нейрона в выходном слое. В последующих слоях
![]() , (21)
, (21)
. (22)
Для двухслойной сети с тремя нейронами, показанной на рис.4:
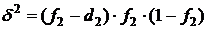 , (23)
, (23)
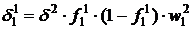 , (24)
, (24)
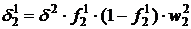 . (25)
. (25)
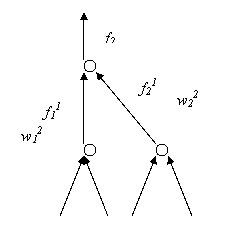

Рис.4.4. Двухслойная нейронная сеть прямого распространения
Искусственные нейронные сети прямого распространения весьма популярны в практических приложениях, поскольку имеют простую и наглядную структуру, способны решать довольно сложные задачи и имеют простые и эффективные алгоритмы обучения, в первую очередь алгоритм обратного распространения ошибки.
4.4. Градиентные методы обучения и метод наискорейшего спуска. Метод обратного распространения ошибки дает частный способ поиска минимума целевой функции обучения. В целом обучение мажет рассматриваться как задача о наикратчайшем спуске в самую глубокую долину рельефа целевой функции, зависящего от вектора весов сети ![]() .
.
Рассмотрим в начале простой двумерный случай, то есть пусть существуют веса w1, w2 , а отклонение от цели E=1/2(y-d)2 . Для наискорейшего спуска нужно идти по линии максимальной крутизны (для одной переменной - по касательной). Для этого требуется построить перпендикуляр к линии уровня, то есть вычислить градиент функции ![]() . Для метаматематической формулировки этого процесса разложим целевую функцию в ряд Тейлора в окрестности некоторой текущей точки:
. Для метаматематической формулировки этого процесса разложим целевую функцию в ряд Тейлора в окрестности некоторой текущей точки:
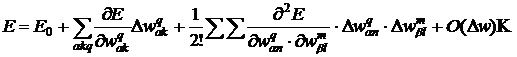 .(26)
.(26)
Введем единый индекс весов ![]() . Тогда
. Тогда
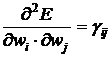 , (27)
, (27)
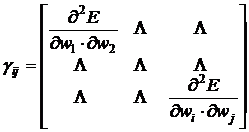 . (28)
. (28)
В точке экстремума все частные производные =0, а det![]() может быть любым по знаку:
может быть любым по знаку:
1) det![]() =0 – это точка перегиба (седло или перевал).
=0 – это точка перегиба (седло или перевал).
2) det![]() >0 – точка минимума,
>0 – точка минимума,
3) det![]() <0 – точка максимума.
<0 – точка максимума.
Для построения алгоритма обучения возьмем разложение функции в достаточно малой окрестности текущего значения весов нейронов сети, а остальные слагаемые ряда отбросим. В простом градиентном методе мы отбрасываем все, кроме первой поправки к значению функции:
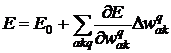 . (29)
. (29)
Дадим приращение весам
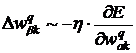 . (30)
. (30)
Здесь 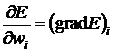 , то есть
, то есть ![]() является компонентой градиента.
является компонентой градиента.
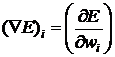 . (31)
. (31)
Отличие от метода обратного распространения ошибки состоит в том, что раньше производные вычислялись аналитически, а теперь целиком численно: то есть даем приращение ![]() и находим:
и находим: 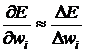 . Это один из самых распространенных методов, основанный на определении величины производной.
. Это один из самых распространенных методов, основанный на определении величины производной.
Отметим трудности данного метода обучения сети:
1. Если использовать большой шаг при спуске, то будет происходить колебание вокруг точки минимума, как показано нарис.4.5.
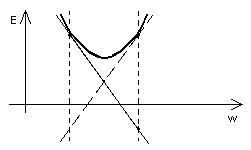
Рис.4.5. Иллюстрация плохой сходимости градиентного спуска при большом шаге в области минимума
2. В точке перегиба производные 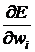 =0, поэтому обучение прекратится, не достигнув минимума. Чтобы этого избежать, используют метод моментов. Для прохождения области перегиба необходимо придать обучению некоторую инерцию, поэтому вводится дополнительная к (30) поправка
=0, поэтому обучение прекратится, не достигнув минимума. Чтобы этого избежать, используют метод моментов. Для прохождения области перегиба необходимо придать обучению некоторую инерцию, поэтому вводится дополнительная к (30) поправка
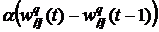
к величине ![]() , а параметр
, а параметр ![]() должен быть порядка 4%. Это позволяет проскочить «плато», то есть область медленного изменения целевой функции, в процессе обучения.
должен быть порядка 4%. Это позволяет проскочить «плато», то есть область медленного изменения целевой функции, в процессе обучения.
3. Проблема локального минимума. При обучении градиентным методом сеть может попасть в состояние локального минимума ![]() (рис.4.6).
(рис.4.6).

Рис.4.6. Пример функциональной зависимости с несколькими локальными минимумами
При попадании в локальный минимум для выхода из него нужно осуществить старт алгоритма с новых начальных значений весов сети. Для их задания можно использовать, в частности, алгоритм случайного блуждания в пространстве весов ![]() .
.
Глава 5. Радиальные нейронные сети
5.1. Функция Дирака. Введем так называемую δ – функцию Дирака. Рассмотрим функцию одной переменной, непрерывную и гладкую, и решим задачу ее аппроксимации с помощью ![]() -функции. Под аппроксимацией обычно понимают приближенное выражение одной функциональной зависимости с помощью другой функциональной зависимости.
-функции. Под аппроксимацией обычно понимают приближенное выражение одной функциональной зависимости с помощью другой функциональной зависимости.
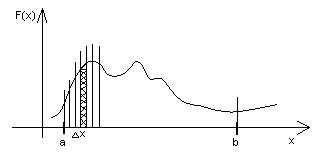
Рис.5.1. Разбиение интервалов при вычислении интеграла
Рассмотрим интеграл от функции ![]() . При интегрировании интервал интеграции [a,b] разбивается на малые отрезки длиной Δx. Функция
. При интегрировании интервал интеграции [a,b] разбивается на малые отрезки длиной Δx. Функция ![]() меняется мало на каждом из этих промежутков, и, если рассмотреть площадь каждого прямоугольника, то получим Si = fi ∆x, а
меняется мало на каждом из этих промежутков, и, если рассмотреть площадь каждого прямоугольника, то получим Si = fi ∆x, а 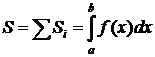 – площадь всей фигуры.
– площадь всей фигуры.
Рассмотрим подынтегральное выражение вида fi·∆x = (1/∆x)·∆x. В нем содержится некоторая функция 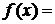 (1/∆x), которая зависит от длины интервала ∆x. За пределами интервала
(1/∆x), которая зависит от длины интервала ∆x. За пределами интервала ![]() произведение ∆x·f =0, а внутри интервала f = 1).
произведение ∆x·f =0, а внутри интервала f = 1).
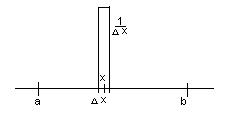
Рис.5.2. Вид узкой ступенчатой функции
Интеграл от такой функции равен единице, а сама функция называется дельта-функцией Дирака δ (x1 – x) :
∫ δ (x1 – x)d =1.
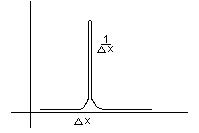
Рис.5.3. ![]() -функция Дирака
-функция Дирака
Полученная функция имеет очень узкий и высокий график. Отсюда следует точное соотношение для свертки ![]() -функции с произвольной непрерывной функцийей
-функции с произвольной непрерывной функцийей ![]() :
:
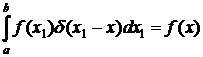 . (1)
. (1)
5.2. Приближение радиальными функциями. Возьмем произвольную непрерывную функцию и представим ее с помощью суммы колоколообразных функций, как показано на рис.5.4
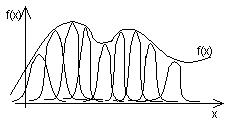
Рис.5.4. Представление гладкой функции одной переменной совокупностью колоколообразных функций
Такое представление означает некоторое ослабление условий разложения по ![]() -функциям. Аналитически это означает представление f(x) в виде разложения по стандартному набору пространственно локализованных функций:
-функциям. Аналитически это означает представление f(x) в виде разложения по стандартному набору пространственно локализованных функций:
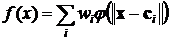 , (2)
, (2)
где ![]() - веса суммирования отдельных откликов,
- веса суммирования отдельных откликов, ![]() - центры базисных радиальных функций. Это формула нейронной сети на основе радиальной базисной радиальной функции. Расстояние
- центры базисных радиальных функций. Это формула нейронной сети на основе радиальной базисной радиальной функции. Расстояние ![]() определяется как расстояние в евклидовом пространстве (рис.5):
определяется как расстояние в евклидовом пространстве (рис.5):
![]() .
.
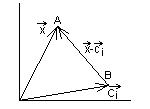
Рис.5.5. Расстояние между точками в евклидовом пространстве
Для функции одной переменной иллюстрацией разложения является рис.5.4. Функция двух переменных может быть изображена как поверхность в трехмерном пространстве (рис.5.6).
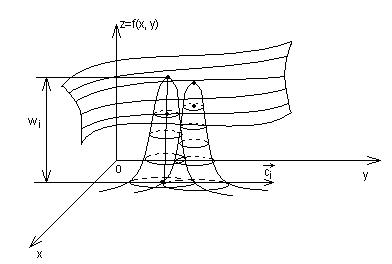
Рис.5.6. Представление гладкой функции двух переменных совокупностью колоколообразных функций
Если разбить поверхность плоскостью параллельной ZOX и параллельной ZOY, то получим сетку и можно построить для каждой ячейки «холмик». Базисная функция имеет характерный максимум и достаточно быстро убывает. Из совокупности таких функций можно набрать произвольную гладкую поверхность.
5.3. Обучение сети радиального типа. Рассмотрим задачу обучения нейронной сети радиальных базисных функций. Вид нейронной сети радиальной базисных функций показан на рис.5.7.
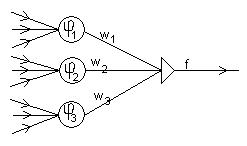
Рис.5.7.Сеть на основе радиальных базисных функций
Простейшая нейронная сеть радиального типа функционирует по принципу многомерной интерполяции, состоящей в отображении p различных входных векторов ![]() (j=1,2,…,p) из входного N-мерного пространства во множество из p рациональных чисел
(j=1,2,…,p) из входного N-мерного пространства во множество из p рациональных чисел ![]() (j=1,2,…,p). Для реализации этого процесса необходимо использовать p скрытых нейронов радиального типа и задать такую функцию отображения
(j=1,2,…,p). Для реализации этого процесса необходимо использовать p скрытых нейронов радиального типа и задать такую функцию отображения ![]() , для которой выполняется условие интерполяции
, для которой выполняется условие интерполяции
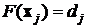 . (3)
. (3)
Рассмотрим радиальную сеть с одним выходом и p обучающими примерами 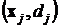 . Примем, что координаты каждого из p центров узлов сети определяются одним из векторов
. Примем, что координаты каждого из p центров узлов сети определяются одним из векторов ![]() , то есть
, то есть 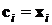 . В этом случае взаимосвязь между входными и выходными сигналами сети может быть определена системой уравнений, линейных относительно весов
. В этом случае взаимосвязь между входными и выходными сигналами сети может быть определена системой уравнений, линейных относительно весов ![]() . В матричной форме она имеет вид:
. В матричной форме она имеет вид:
 , (4)
, (4)
где ![]() определяет радиальную функцию с центром в точке
определяет радиальную функцию с центром в точке ![]() с входным вектором данных из примеров
с входным вектором данных из примеров ![]() . Если обозначить матрицу значений базисных функций
. Если обозначить матрицу значений базисных функций ![]() как
как ![]() и ввести векторные обозначения
и ввести векторные обозначения ![]() и
и ![]() , система уравнений (4) может быть представлена в редуцированной матричной форме
, система уравнений (4) может быть представлена в редуцированной матричной форме
![]()
![]() =
=![]() . (5)
. (5)
Доказано, что для определенных типов радиальных функций в случае ![]() квадратная интерполяционная матрица
квадратная интерполяционная матрица ![]() может быть обращена и уравнение имеет решение в виде:
может быть обращена и уравнение имеет решение в виде:
![]() =
=![]() , (6)
, (6)
что позволяет получить вектор весов выходного нейрона сети. Недостатком такого решения является адаптация при большом количестве обучающих выборок к различным шумам и нерегулярностям, сопровождающим обучающие выборки. Как следствие, интерполирующая эти данные гиперповерхность не будет гладкой, а обобщающие возможности окажутся очень слабыми.
5.4. Выбор центров. Главной проблемой обучения радиальных сетей остается подбор параметров нелинейных радиальных функций, особенно центров ![]() . Одним из простейших, хотя и не самым эффективным способом, является их случайный выбор. В этом случае центры
. Одним из простейших, хотя и не самым эффективным способом, является их случайный выбор. В этом случае центры ![]() базисных функций выбираются случайным образом на основе равномерного распределения. Такой подход допустим применительно к классическим радиальным сетям при условии, что равномерное распределение обучающих данных хорошо соответствует специфике задачи.
базисных функций выбираются случайным образом на основе равномерного распределения. Такой подход допустим применительно к классическим радиальным сетям при условии, что равномерное распределение обучающих данных хорошо соответствует специфике задачи.
При выборе гауссовской формы радиальных функций
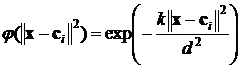 , (7)
, (7)
для i=1,2,…,k , где d обозначает максимальное расстояние между центрами ![]() . Ширина функции
. Ширина функции ![]() пропорциональна максимальному разбросу центров и уменьшается с ростом их количества.
пропорциональна максимальному разбросу центров и уменьшается с ростом их количества.
Неплохие результаты определения центров функций можно получить при использовании алгоритма самоорганизации. Данные группируются внутри кластера и представляются центральной точкой, определяющей среднее значение всех элементов этого кластера. Центр кластера в дальнейшем принимается за центр соответствующей радиальной функции (рис.5.8). По этой причине количество радиальных функций равно количеству кластеров и может корректироваться алгоритмам самоорганизации.
Если обучающие данные представляют непрерывную функцию, начальные значения центров в первую очередь размещают в точках, соответствующих всем максимальным и минимальным значениям функции (рис.5.8).
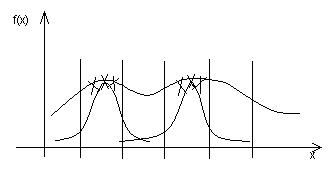
Рис.5.8. Исходное размещение радиальных функций
Данные об этих центрах и их ближайшем окружении впоследствии убирают из обучающего множества, а оставшиеся центры равномерно распределяются в множестве, образованном оставшимися элементами (рис.5.9). Удаление острых мест сделает функцию более гладкой.
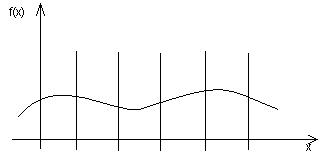
Рис.5.9. Функция после сглаживания
Хорошие результаты при выборе центров функций можно получить при использовании алгоритма самоорганизации. Данные формируются внутри кластера и представляются центральной точкой, определяющей среднее значение всех элементов этого кластера (рис.5.10).
Рис.5.10. Кластеризация данных
Для определения кластеров в ходе обучения после предъявления k-ого вектора ![]() , принадлежащего обучающему множеству, выбирается центр, ближайший к точке
, принадлежащего обучающему множеству, выбирается центр, ближайший к точке ![]() , относительно применяемой метрики. Этот центр подвергается уточнению в соответствии с алгоритмом
, относительно применяемой метрики. Этот центр подвергается уточнению в соответствии с алгоритмом
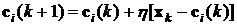 , (8)
, (8)
и центр радиальной функции смещается в направлении вектора обучающего примера, η - коэффициент обучения, имеющий малое значение (обычно η<<1), причем он уменьшается во времени. Существуют и иные алгоритмы определения центров, однако ни один алгоритм не гарантирует абсолютную сходимость к глобальному решению.
Если p≠n, то матрица не является квадратной. Это означает, что в линейных уравнениях для определения wi число уравнений может быть не равно числу переменных. Если уравнений больше (p >n), чем неизвестных, то система является несовместной (то есть либо слишком много решений, либо их нет вообще). Если (p<n), то число уравнений меньше числа неизвестных и невозможно однозначным образом определить коэффициенты wi.
Кроме трудности в определении центров функции могут возникать и трудности в определении коэффициентов ![]() в уравнении (5). Обратная матрица
в уравнении (5). Обратная матрица ![]() оказывается весьма чувствительным к точным значениям данных из примеров. Малые изменения в данных приводят к большим изменениям в значении определяемых коэффициентов
оказывается весьма чувствительным к точным значениям данных из примеров. Малые изменения в данных приводят к большим изменениям в значении определяемых коэффициентов ![]() . Подобные задачи в математике называются некорректными. Для устранения некорректности используются следующая замена:
. Подобные задачи в математике называются некорректными. Для устранения некорректности используются следующая замена:
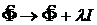 ,
,
где λ – малый параметр, I – единичная матрица. Такой метод устранения некорректности задачи называется регуляризацией Тихонова.
Трудность обучения сети радиальных базисных функций заключается также в подборе коэффициента обучения η. Чаще всего выбирается алгоритм
![]() , (10)
, (10)
где T- постоянная времени, индивидуальная для каждой задачи.
Глава 6. Сети Хопфилда
6.1. Структура сети. Американский исследователь Хопфилд в 80-х годах 20-го века предложил специальный тип нейросетей. Названные в его честь сети Хопфилда являются рекуррентными или сетями с обратными связями и были предназначены для распознавания образов. Обобщенная структура этой сети представляется, как правило, в виде системы с обратной связью выхода с входом. Сеть Хопфилда является однослойной.
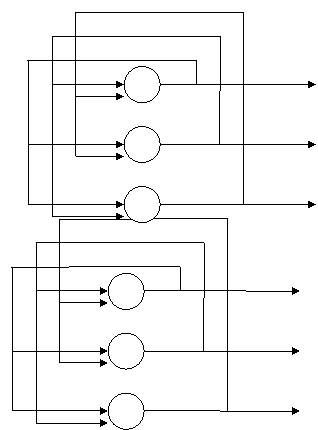
Рис.6.1. Схема сети Хопфилда
Характерная особенность такой сети состоит в том, что входные сигналы нейронов являются одновременно входными сигналами сети: xi(k)=yi(k-1), при этом возбуждающий вектор особо не выделяется. В классической системе Хопфилда отсутствует связь нейрона с собственным выходом, что соответствует 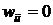 , а вся матрица весов является симметричной: wij=wji
, а вся матрица весов является симметричной: wij=wji
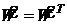 . (1)
. (1)
Симметричность матрицы весов гарантирует сходимость процесса обучения. Процесс обучения сети формирует зоны притяжения некоторых точек равновесия, соответствующих обучающим данным. При использовании ассоциативной памяти мы имеем дело с обучающим вектором ![]() , либо с множеством этих векторов, которые в результате проводимого обучения определяют расположение конкретных точек притяжения (аттракторов).
, либо с множеством этих векторов, которые в результате проводимого обучения определяют расположение конкретных точек притяжения (аттракторов).
Будем предполагать, что каждый нейрон имеет функцию активации сигнум со значениями ![]() :
:
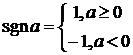 . (2)
. (2)
Это означает, что выходной сигнал i-го нейрона определяется функцией
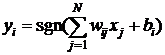 , (3)
, (3)
где N обозначает количество нейронов, N=n. Для упрощения дальнейших рассуждений предположим, что постоянная составляющая bi , определяющая порог срабатывания отдельных нейронов, равна 0. Тогда циклическое прохождение сигнала в сети Хопфилда можно представить соотношением
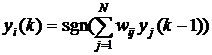 (4)
(4)
с начальным условием ![]() .
.
В процессе функционирования сети Хопфилда можно выделить два режима: обучения и классификации. В режиме обучения на основе известных обучающих выборок ![]() подбираются весовые коэффициенты wij .
подбираются весовые коэффициенты wij .
В режиме классификации при зафиксированных значениях весов и вводе конкретного начального состояния нейронов ![]() возникает переходный процесс, протекающий в соответствии с выражением (2) и заканчивающийся в одном из локальных минимумов, задаваемом биполярным вектором со значениями
возникает переходный процесс, протекающий в соответствии с выражением (2) и заканчивающийся в одном из локальных минимумов, задаваемом биполярным вектором со значениями ![]() , для которого
, для которого ![]() .
.
6.2. Обучение сети Хопфилда. Обучение не носит рекуррентного характера. Достаточно ввести значения (правило Хебба) весов, выразив их через проекции вектора точки притяжения эталонного образа:
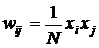 , (5)
, (5)
В соответствии с эти правилом сеть дает правильный результат при входном примере, совпадающим с эталонным образцом. Поскольку
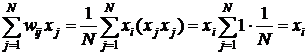 , (6)
, (6)
так как вследствие биполярности значений элементов вектора ![]() всегда
всегда ![]() .
.
При вводе большого количества обучающих выборок ![]() для k=1,2,…p веса wij подбираются согласно обобщенному правилу Хебба в соответствии с которым
для k=1,2,…p веса wij подбираются согласно обобщенному правилу Хебба в соответствии с которым
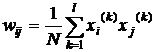 . (7)
. (7)
Благодаря такому режиму обучения веса принимают значения, определяемые усреднением множества обучаемых выборок. В случае множества обучаемых выборок актуальным становится вопрос о стабильности ассоциативной памяти.
Сети Хопфилда также относятся к классу сетей, которые могут быть описаны в терминах «энергии» сети. В такой интерпретации запомненные образы соответствуют локальным минимумам энергетической поверхности.
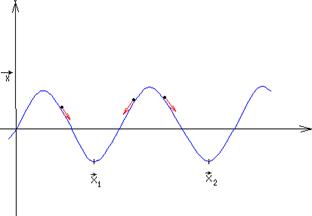
Рис.6.2. Движение по энергетической поверхности при работе сети Хопфилда
Физическая аналогия при этом состоит в следующем. Если шарик с трением начнет движение вблизи минимума потенциальной энергии, то он остановиться в локальном минимуме, соответствующем ближайшему образу в обучающей выборке.
6.3. Энергетический подход. Для сети Хопфилда «энергия» взаимодействия пары узлов
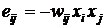 . (8)
. (8)
Полная энергия сети может быть найдена как сумма по всем парам узлов:
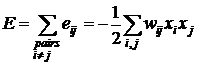 . (9)
. (9)
Коэффициент ½ учитывает, что каждая пара присутствует в сумме дважды как wijxixj и как wijxjxi , а также, что wij=wji, wii=0 . Рассмотрим теперь изменение энергии при изменении значения входа k-го узла. Выделим в полной энергии E слагаемое, соответствующее узлу с номером ![]() , в котором происходят изменения в процессе рекуррентного распознавания образа:
, в котором происходят изменения в процессе рекуррентного распознавания образа:
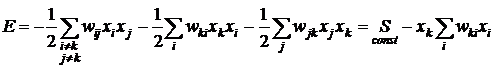 . (10)
. (10)
Иными словами
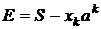 , (11)
, (11)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
