

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
где ![]() - аргумент функции активации узла с номером
- аргумент функции активации узла с номером ![]() ,
, ![]() - неизменная часть энергии при изменении только в узле
- неизменная часть энергии при изменении только в узле ![]() .
.
Пусть 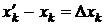 изменение проекции вектора с номером
изменение проекции вектора с номером ![]() в процессе одной итерации. Возможны два случая.
в процессе одной итерации. Возможны два случая.
1. 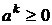 . Тогда выход принимает значение 1. В этом случае
. Тогда выход принимает значение 1. В этом случае ![]() , поскольку 1 - это максимальное значение на выходе. Следовательно,
, поскольку 1 - это максимальное значение на выходе. Следовательно, ![]() и
и ![]() .
.
2. 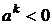 . Тогда выход принимает значение (-1). В этом случае
. Тогда выход принимает значение (-1). В этом случае ![]() , поскольку (-1) является минимальным значением на выходе, и снова
, поскольку (-1) является минимальным значением на выходе, и снова ![]() ,
, ![]() .
.
Отсюда следует невозрастание функции ![]() в процессе итераций, и алгоритм работы сети обеспечивает поступательное уменьшение функции качества, то есть ведет к нахождению ближайшего устойчивого минимума состояния сети.
в процессе итераций, и алгоритм работы сети обеспечивает поступательное уменьшение функции качества, то есть ведет к нахождению ближайшего устойчивого минимума состояния сети.
Глава 7. Сети Хэмминга
7.1. Распознающая сеть. В целом ряде задач не требуется воспроизводить распознаваемый образ, как это делают сети Хопфилда, а достаточно указать номер эталона, ближайшего к предъявленному входному вектору. Для этого может быть использована сеть Хэмминга. Преимуществами этой сети по сравнению с сетью Хопфилда являются меньшие затраты на память и объем вычислений.
Нейронная сеть Хэмминга показана на рис. 7.1 и состоит из трех слоев: входного, скрытого и выходного. Скрытый и выходной слои содержат по k нейронов, где k - это число эталонных образов.
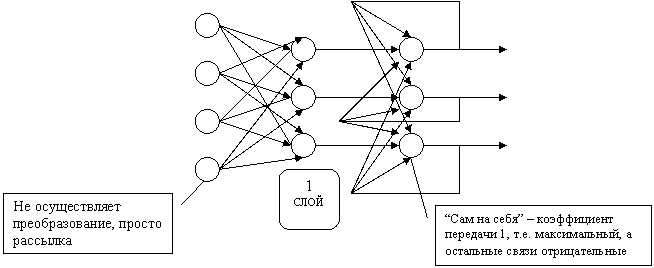
Рис.7.1. Схема сети Хемминга
Каждый из нейронов скрытого слоя соединен с выходами n-нейронов входного слоя. Выходы нейронов выходного слоя связаны со входами остальных нейронов этого слоя отрицательными обратными (ингибиторными или тормозящими) связями. Единственная положительная обратная связь подается с выхода для каждого нейрона выходного слоя на его же вход.
7.2. Расстояние или мера Хемминга. Сеть выбирает эталон, для которого расстояние Хэмминга от предъявленного входного вектора путем активации только одного выхода сети (нейрона выходного слоя), соответствующего этому эталону. Расстояние Хэмминга равно числу несовпадающих компонент (битов) двух бинарных векторов. Иначе говоря, при использовании двоичных значений (0,1) расстояние Хэмминга между двумя векторами
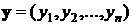 и
и 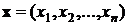
определяется в виде:
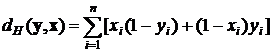 . (1)
. (1)
При биполярных значениях ![]() элементов обоих векторов расстояние Хэмминга рассчитывается по формуле
элементов обоих векторов расстояние Хэмминга рассчитывается по формуле
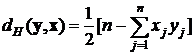 . (2)
. (2)
Мера Хэмминга равна нулю только когда ![]() . В противном случае она равна количеству битов, на которое различаются два вектора
. В противном случае она равна количеству битов, на которое различаются два вектора ![]() и
и ![]() Соотношение (2) доказывается легко непосредственно, а в качестве упражнения полезно проделать переход от выражения (2) к формуле (1).
Соотношение (2) доказывается легко непосредственно, а в качестве упражнения полезно проделать переход от выражения (2) к формуле (1).
7.3. Обучение сети. Фактически первый слой в сети Хэмминга отсутствует и она двухслойная. На стадии инициализации сети Хэмминга весовым коэффициентам первого слоя (в двухслойном рассмотрении ) присваиваются значения
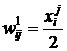 ,
, 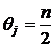 , (3)
, (3)
i=1,2,…,n; j=1,2,…,k; где ![]() - значение i-го признака (бита) для j-го образца. Весовые коэффициенты тормозящих обратных связей во втором слое полагают равными некоторой небольшой величине ε: 0<ε<1/k. Выход нейрона, связанный с его же входом, имеет в начале вес +1.
- значение i-го признака (бита) для j-го образца. Весовые коэффициенты тормозящих обратных связей во втором слое полагают равными некоторой небольшой величине ε: 0<ε<1/k. Выход нейрона, связанный с его же входом, имеет в начале вес +1.
7.4. Работа сети. Опишем и проанализируем алгоритм функционирования сети Хэмминга:
1. На входы сети подается неизвестный вектор ![]() , на основе которого рассчитываются выходы состояния нейронов первого слоя
, на основе которого рассчитываются выходы состояния нейронов первого слоя
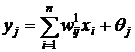 , j=1,…,k. (4)
, j=1,…,k. (4)
Для того, чтобы узнать, что представляет эта величина с точки зрения расстояния Хэмминга, подставим в формулу (4) весовые коэффициенты (3).
Тогда
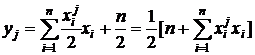 . (5)
. (5)
Сравнивая это выражение с формулой (2) для расстояния Хэмминга, мы получим
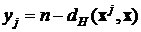 . (6)
. (6)
Если ввести нормированные значения выходных сигналов
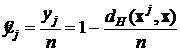 , (7)
, (7)
то ![]() , если
, если ![]() и
и ![]() , если
, если ![]() . В остальных случаях значения
. В остальных случаях значения ![]() располагаются в интервале [0,1].
располагаются в интервале [0,1].
Сигналы ![]() становятся начальными состояниями второго слоя MAXNET на второй фазе функционирования сети. Задача нейронов этого слоя состоит в определении победителя, то есть нейрона, уровень возбуждения которого наиболее близок к 1. Эта задача в алгоритмическом смысле вполне элементарна, но интересно ее решение с помощью нейронной сети. Нейрон - победитель указывает на вектор образа с минимальным расстоянием Хэмминга до входного вектора
становятся начальными состояниями второго слоя MAXNET на второй фазе функционирования сети. Задача нейронов этого слоя состоит в определении победителя, то есть нейрона, уровень возбуждения которого наиболее близок к 1. Эта задача в алгоритмическом смысле вполне элементарна, но интересно ее решение с помощью нейронной сети. Нейрон - победитель указывает на вектор образа с минимальным расстоянием Хэмминга до входного вектора ![]() . Процесс определения победителя - это рекуррентный процесс. Для его выполнения веса обратной связи второго слоя выбираются в виде
. Процесс определения победителя - это рекуррентный процесс. Для его выполнения веса обратной связи второго слоя выбираются в виде
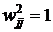 ,
,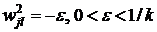 ,
, ![]() . (8)
. (8)
Рекуррентная формула, определяющая итерационный процесс, имеет вид
![]() . (9)
. (9)
Функция активации нейрона f(y) слоя MAXNET задается выражением
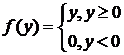 . (10)
. (10)
Уравнение (9) показывает, что значения на выходе нейронов будут уменьшаться, пока не достигнут 0 во всех кроме одного. Это достаточно очевидно, если занумеровать ![]() в порядке убывания. Тогда ясно, что «выживет» один нейрон с i=1, поскольку снижение значений у остальных нейронов будет происходить быстрее.
в порядке убывания. Тогда ясно, что «выживет» один нейрон с i=1, поскольку снижение значений у остальных нейронов будет происходить быстрее.
Проблема, связанная с сетью Хэмминга проявляется в случае, когда зашумленные образы находятся на одинаковом (в смысле Хэмминга) расстоянии от двух или более эталонов. В этом случае выбор сетью Хэмминга одного из этих эталонов становится совершенно случайным.
Глава 8. Двунаправленная ассоциативная память
или сеть Коско (ДАП)
8.1. Ассоциативность памяти. Память человека является ассоциативной: один предмет, напоминает нам о другом, а этот другой – о третьем. При свободном течении мыслей они перемещаются от предмета к предмету по цепочке умственных ассоциаций. Кроме того, возможно использование способности к ассоциациям для восстановления забытых образов. Если мы забыли где оставили какую-либо вещь, то пытаемся вспомнить, где видели ее в последний раз, с кем разговаривали и что делали. Посредством этого устанавливается некая цепочка ассоциаций, что позволяет нашей памяти соединить ассоциации для получения требуемого образа.
Ассоциативная память Хопфилда является, строго говоря, автоассоциативной, что означает, что образ, предъявляемый сети, может быть завершен или исправлен, но не может быть ассоциирован с другим образом. Данный факт является результатом одноуровневой структуры ассоциативной памяти, в которой вектор появляется на выходе тех же нейронов, на которые поступает входной вектор.
8.2. Двунаправленная ассоциативная память (Bidirectional Association Memory - BAM). Эта память является гетероассоциативной, - входной вектор поступает на один набор нейронов, а соответствующий выходной вектор вырабатывается на другом наборе нейронов. Как и сеть Хопфилда ДАП способна к обобщению, вырабатывая правильные реакции, несмотря на искаженные входы. Кроме того, могут быть реализованы адаптивные версии ДАП, выделяющие эталонный образец из зашумленных экземпляров. Эти возможности сильно напоминают процесс мышления человека и позволяют искусственным сетям сделать шаг в направлении моделирования мозга.
В сети ДАП сигналы распространяются в двух направлениях: от входа к выходу и обратно (рис.8.1). При этом размерности входных и выходных образов могут не совпадать. Функционирование имеет синхронный характер.
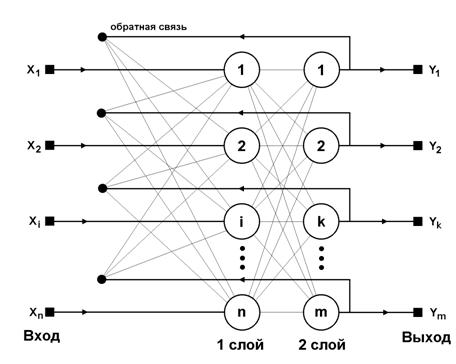
Рис.8.1. Нейронная сеть двунаправленной ассоциативной памяти
Это означает, что если в первом цикле сигналы вначале проходят в одну сторону для определения нейтронов-получателей, то в следующем цикле они сами становятся источниками, высылающими сигналы в обратную сторону. Этот процесс повторяется до достижения состояния равновесия.
8.3. Распознавание ассоциативных образов. Функция активации нейронов сети имеет пороговый или крутой сигмаидальный характер. При пороговом характере она может быть двоичной со значениями 1, 0 или биполярной со значениями ![]() . При нулевом сигнале возбуждения нейрона его текущее состояние остается равным предыдущему состоянию. Для обеспечения лучших характеристик сети в режиме распознавания на этапе обучения используются только биполярные сигналы. Матрица весов
. При нулевом сигнале возбуждения нейрона его текущее состояние остается равным предыдущему состоянию. Для обеспечения лучших характеристик сети в режиме распознавания на этапе обучения используются только биполярные сигналы. Матрица весов ![]() , связывающая обе части сети, является действительной и несимметричной. С учетом симметрии связей входного и выходного слоев сети при прямом распространении сигналов веса описываются матрицей W, а при обратном направлении – матрицей WT .
, связывающая обе части сети, является действительной и несимметричной. С учетом симметрии связей входного и выходного слоев сети при прямом распространении сигналов веса описываются матрицей W, а при обратном направлении – матрицей WT .
Пусть входные обучающие данные входов и выходов определены в виде множества размерностью 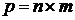 биполярных пар
биполярных пар ![]() , где
, где
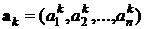 ,
, 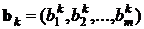
В соответствии с определением Коско матрица весов W формируется на основе правил
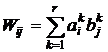 , (1)
, (1)
i=1,2,…,n; j=1,2,…,p , где r – число пар обучения. В векторном виде это записать не так просто, поскольку векторы ![]() и
и ![]() имеют разную длину. Соответственно матрица wij действует из пространства входных векторов одной размерности n в пространство выходных векторов другой размерности p.
имеют разную длину. Соответственно матрица wij действует из пространства входных векторов одной размерности n в пространство выходных векторов другой размерности p.
Если на первый слой подан сигнал ![]() , то второй слой после обработки выдаст значения
, то второй слой после обработки выдаст значения
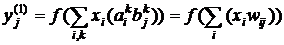 , (2)
, (2)
где
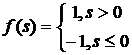 или
или 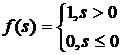
После выхода из второго слоя сигнал подается вновь на входы первого слоя. После прохождения этого слоя
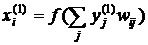 . (3)
. (3)
Далее следует вторая итерация, и процесс продолжается до достижения стабильного состояния сети. Каждому состоянию сети ![]() можно сопоставить энергетическую функцию
можно сопоставить энергетическую функцию
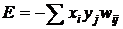 , (4)
, (4)
Доказано, что каждое очередное изменение состояния переходного процесса ведет к уменьшению значения энергетической функции сети вплоть до достижения локального минимума. Этот минимум достигается за конечное число итераций (для бинарных векторов) и имеет значение
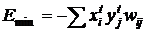 (5)
(5)
на конечных векторах ![]() и
и![]() . Иными словами, любое другое решение, в том числе и ближайшее отличающееся, хотя бы на 1 в смысле меры Хэмминга, от (
. Иными словами, любое другое решение, в том числе и ближайшее отличающееся, хотя бы на 1 в смысле меры Хэмминга, от (![]() ,
,![]() ), будет характеризоваться большим значением энергетической функции.
), будет характеризоваться большим значением энергетической функции.
При выполнении некоторых дополнительных условий парой (![]() ,
,![]() ) становится одна из обучающих пар, участвующих в формировании матрицы
) становится одна из обучающих пар, участвующих в формировании матрицы ![]() , которая наиболее подобна (наиболее близка по мере Хэмминга) паре, определившей начальное состояние
, которая наиболее подобна (наиболее близка по мере Хэмминга) паре, определившей начальное состояние ![]() .
.
Существуют различные модификации ДАП, улучшающие ее работу (распознавание образов при наличии шумов). Как и сеть Хопфилда, ДАП имеет ограничения на максимальное количество ассоциаций, которые она может точно воспроизвести. Если этот лимит превышен, то сеть может выработать неверный выходной сигнал, воспроизводя ассоциации, которым не обучена. Сделаны оценки, в соответствии с которыми количество запоминаемых ассоциаций не может превышать количества нейронов в меньшем слое. На самом деле возможности сети несколько меньше.
Глава 9. Сети Кохонена
9.1. Самоорганизующиеся топологические карты. Сети Кохонена, или самоорганизующиеся карты (Kohonen maps), предназначены для решения задач автоматической классификации, когда обучающая последовательность образов отсутствует (обучение без учителя). Соответственно невозможно и определение ошибки классификации, на минимизации которой построено обучение с учителем (например, в алгоритме обучения с обратным распространением ошибки).
Сеть Кохонена является двухслойной. Она содержит слой входных нейронов и собственно слой Кохонена. Слой Кохонена может быть одномерным, двумерным и трехмерным. В первом случае нейроны расположены в цепочку; во втором – они образуют двумерную сетку (обычно в форме квадрата или прямоугольника), а в третьем – трехмерную систему. Определение весов нейронов слоя Кохонена основано на использовании алгоритмов автоматической классификации (кластеризации или самообучения).
Пусть имеется сеть Кохонена, содержащая n входных нейронов и слой Кохонена из m выходных нейронов, расположенных в виде прямоугольника (рис. 9.1)
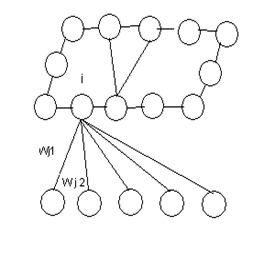
Рис.9.1. Структура сети Кохонена
9.2. Данные и нейроны. На вход сети подаются последовательно значения векторов ![]() , представляющих отдельные последовательные наборы данных для поиска кластеров, то есть различных классов образов, причем число этих кластеров заранее неизвестно. На рис.9.1 показаны связи всех входных нейронов лишь с одним нейроном слоя Кохонена. Каждый нейрон слоя Кохонена соединен также с соседними нейронами.
, представляющих отдельные последовательные наборы данных для поиска кластеров, то есть различных классов образов, причем число этих кластеров заранее неизвестно. На рис.9.1 показаны связи всех входных нейронов лишь с одним нейроном слоя Кохонена. Каждый нейрон слоя Кохонена соединен также с соседними нейронами.
Введем следующие определения. Нейроны входного слоя служат для ввода значений признаков распознаваемых образов. Активные нейроны слоя Кохонена предназначены для формирования областей векторов весовых коэффициентов j-го нейрона слоя Кохенена 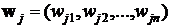 , (j=1,2,…,m), в то время как входной вектор или вектор значений признаков входного образца
, (j=1,2,…,m), в то время как входной вектор или вектор значений признаков входного образца ![]() .
.
На стадии обучения (точнее самообучения) сети входной вектор ![]() попарно сравнивается со всеми векторами
попарно сравнивается со всеми векторами ![]() всех нейронов сети Кохонена. Вводится некоторая функция близости d (например, в виде евклидова расстояния). Активный нейрон с номером c слоя Кохонена, для которого значение функции близости
всех нейронов сети Кохонена. Вводится некоторая функция близости d (например, в виде евклидова расстояния). Активный нейрон с номером c слоя Кохонена, для которого значение функции близости ![]() между входным вектором
между входным вектором ![]() , характеризующим некоторый образ, к векторам
, характеризующим некоторый образ, к векторам ![]() максимально, объявляется «победителем». При этом образ, характеризующийся вектором
максимально, объявляется «победителем». При этом образ, характеризующийся вектором ![]() , будет отнесен к классу, который представляется нейроном-«победителем».
, будет отнесен к классу, который представляется нейроном-«победителем».
9.3. Самообучение сетей Кохонена. Рассмотрим алгоритм самообучения сетей Кохонена. Обозначим функцию близости 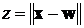 . Выигрывает нейрон c
. Выигрывает нейрон c
 . (1)
. (1)
Для многомерных данных можно (и желательно) использовать нормированные векторы 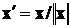 ,
, ![]() :
:
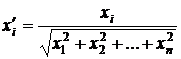 ,
, 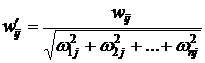 . (2)
. (2)
Близость ![]() и
и ![]() можно переделить, пользуясь скалярным произведением, как
можно переделить, пользуясь скалярным произведением, как
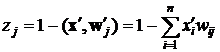 . (3)
. (3)
На стадии самообучения сети Кохонена осуществляется коррекция весового вектора не только нейрона-«победителя», но и весовых векторов остальных активных нейронов слоя Кохонена, однако, естественно, в значительно меньшей степени – в зависимости от удаления от нейрона-«победителя». При этом форма и величина окрестности вокруг нейрона-«победителя», весовые коэффициенты нейронов которой также корректируются, в процессе обучения изменяются. Сначала начинают с очень большой области – она, в частности, может включать все нейроны слоя Кохонена. Изменение весовых векторов осуществляется по правилу
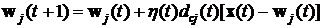 , j=1, 2,…, n, (4)
, j=1, 2,…, n, (4)
где ![]() - значение весового вектора на шаге t самообучения сети,
- значение весового вектора на шаге t самообучения сети, ![]() - функция близости между нейронами слоя Кохонена и
- функция близости между нейронами слоя Кохонена и ![]() - изменяемый во времени коэффициент шага коррекции. В качестве
- изменяемый во времени коэффициент шага коррекции. В качестве ![]() обычно выбирается монотонно убывающая функция (0<
обычно выбирается монотонно убывающая функция (0<![]() <1), то есть алгоритм самообучения начинается сравнительно большими шагами адаптации и заканчивается относительно малыми изменениями.
<1), то есть алгоритм самообучения начинается сравнительно большими шагами адаптации и заканчивается относительно малыми изменениями.
В результате n-мерное входное пространство ![]() отобразится на m-мерную сетку (слой Кохонена). Следует подчеркнуть, что это отображение реализуется в результате рекуррентной (итеративной) процедуры самообучения (unsupervised learning). Отличительная особенность этого отображения – формирование кластеров (clusters) или классов. По завершении процесса самообучения на стадии реального использования сети Кохонена неизвестные входные образы относятся к одному из выявленных кластеров (классов) по близости к некоторому весу, принадлежащему определенному кластеру, выявленному на стадии самообучения.
отобразится на m-мерную сетку (слой Кохонена). Следует подчеркнуть, что это отображение реализуется в результате рекуррентной (итеративной) процедуры самообучения (unsupervised learning). Отличительная особенность этого отображения – формирование кластеров (clusters) или классов. По завершении процесса самообучения на стадии реального использования сети Кохонена неизвестные входные образы относятся к одному из выявленных кластеров (классов) по близости к некоторому весу, принадлежащему определенному кластеру, выявленному на стадии самообучения.
9.4. Последовательность алгоритма Кохонена.
Шаг 1. Инициализация. Выбираются (случайным образом) начальные значения всех n-мерных весовых векторов слоя Кохонена, а также стартовые значения коэффициента коррекции ![]() и радиуса близости d.
и радиуса близости d.
Шаг 2. Выбирается некоторый образ, характеризующийся вектором значений признаков ![]() .
.
Шаг 3. Определяется нейрон-«победитель» с номером с.
Шаг 4. Для нейрона-«победителя» с номером с и для нейронов из радиуса близости вокруг него определяются новые значения весовых коэффициентов (векторов).
Шаг 5. Осуществляется модификация коэффициента коррекции и радиуса близости d.
Шаг 6. Отбирается критерий сходимости, согласно которому происходит «останов» или переход к шагу 2.
Функция близости можно выбрать в виде
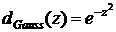 ,
,
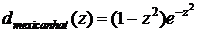
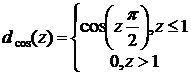
где z – расстояние между нейронами в обычном пространстве, например для двумерного пространства векторов
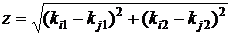 ,
,
где ![]() и
и ![]() – координаты по оси x и оси y нейрона i,
– координаты по оси x и оси y нейрона i, ![]() и
и ![]() – аналогично для нейрона j.
– аналогично для нейрона j.
Глава 10. Сети адаптивной резонансной теории (ART-сети)
10.1.Долговременная память. Проблема функционирования долговременной памяти человека не решена до настоящего времени. В ней все образы запоминаются в такой форме, что ранее запомненные не модифицируются и не забываются. Это создает дилемму: каким образом память остается пластичной, способной к восприятию новых образов, и в то же время сохраняет стабильность, то есть старые образы не стираются? Традиционные искусственные нейронные сети оказались не в состоянии решить проблему стабильности – пластичности. Часто обучение новому образу уничтожает или изменяет результаты предшествующего обучения.
В реальной ситуации функционирования сеть будет подвергаться постоянно изменяющимся воздействиям, так что она может иногда не увидеть один и тот же обучающий вектор дважды. При таких обстоятельствах обычная сеть часто не будет обучаться; она будет непрерывно изменять свои веса, не достигая удовлетворительных результатов. Более того, были найдены примеры, в которых только четыре обучающих вектора, предъявляемых циклически, заставляют веса сети непрерывно изменяться, никогда не сходясь к определенному устойчивому результату. Такая временная нестабильность заставила Гроссберга и его сотрудников исследовать радикально отличные конфигурации. Результатом стала адаптивная резонансная теория (ART), авторами которой являются Карпентер и Гроссберг (1986 г).
10.2. Сети и алгоритмы ART сохраняют пластичность необходимую для изучения новых образов, в то же время, предотвращается изменение ранее запомненных образов. Однако, ART в деталях довольно трудна для понимания, хотя основные идеи и принципы реализации достаточно просты. Мы ограничимся общим описанием ART.
Существуют различные модификации ART. Мы рассмотрим только первую из них ART‑1. Сеть ART представляет собой векторный классификатор. Входной вектор классифицируется в зависимости от того, на какой из множества ранее запомненных образов он похож. Свое классификационное решение сеть ART выражает в форме возбуждения одного из нейронов распознающего слоя. Если входящий вектор не соответствует ни одному из запомненных образов, создается новая категория, путем запоминания образа, идентичного новому входному вектору. Если определено, что входной вектор похож на один из ранее запомненных векторов с точки зрения определенного критерия сходства, то ранее запомненный вектор будет изменяться (обучаться) под воздействием нового входного вектора таким образом, чтобы стать более похожим на этот входной вектор.
Запомненный образ не будет изменяться, если текущий вектор не окажется достаточно похожим на него. Таким образом, решается дилемма стабильности - пластичности. Новый образ может создавать дополнительные классификационные категории, однако он не может заставить измениться существующую память.
10.3. Схема сети ART. На рис.10.1 показана упрощенная конфигурация сети ART, представленная в виде пяти функциональных модулей. Она включает два слоя нейронов: так называемый «слой сравнения» и «слой распознавания». Приемник 1, Приемник 2 и Сброс обеспечивают управляющие функции, необходимые для обучения и классификации.
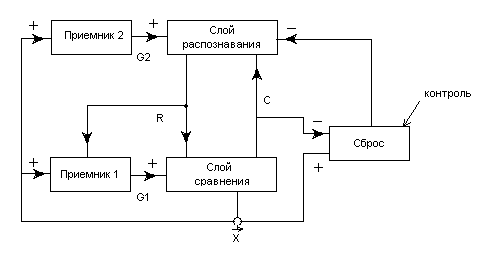
Рис.10.1. Сеть АРТ
Слой сравнения получает двоичный входной вектор ![]() и первоначально пропускает его неизменным для формирования выходного вектора
и первоначально пропускает его неизменным для формирования выходного вектора ![]() . На более поздней фазе в распознающем слое вырабатывается двоичный вектор
. На более поздней фазе в распознающем слое вырабатывается двоичный вектор ![]() , модифицирующий вектор
, модифицирующий вектор ![]() как описано ниже.
как описано ниже.
Каждый нейрон в слое сравнения получает три двоичных входа (0,1):
1) компонента xi входного вектора ![]() , где i – номер нейрона;
, где i – номер нейрона;
2) сигнал обратной связи Ri - взвешенная сумма выходов распознающего слоя;
3) выход из Приемника 1 (один и тот же символ подается на все входы этого слоя).
Чтобы получить на выходе нейрона единичное значение, как минимум два из трех его входов должны равняться единице; в противном случае его выход будет нулевым. Таким образом, реализуется так называемое привило двух третей. Первоначально выходной сигнал G1 приемника установлен на единицу, обеспечивая один из необходимых для возбуждения нейронов выходов, а все компоненты вектора ![]() установлены в 0. Следовательно, в этот момент вектор
установлены в 0. Следовательно, в этот момент вектор ![]() идентичен двоичному входному вектору
идентичен двоичному входному вектору ![]() .
.
10.4. Слой распознавания осуществляет классификацию входных векторов. Каждый нейрон в слое распознавания имеет соответствующий вектор весов ![]() . Только один нейрон с весовым вектором, наиболее соответствующим сходному вектору возбуждается; все остальные нейроны заторможены. По сути веса
. Только один нейрон с весовым вектором, наиболее соответствующим сходному вектору возбуждается; все остальные нейроны заторможены. По сути веса ![]() j представляют собой запомненный образ или экземпляр для категории входных векторов
j представляют собой запомненный образ или экземпляр для категории входных векторов ![]() j [(bj,Cj)- max]. Эти веса являются действительными числами, а не двоичными величинами. Двоичная версия этого образа также запоминается в соответствующем наборе весов слоя сравнения.
j [(bj,Cj)- max]. Эти веса являются действительными числами, а не двоичными величинами. Двоичная версия этого образа также запоминается в соответствующем наборе весов слоя сравнения.
Этот набор состоит из весов связей, соединяющих определенные нейроны слоя распознавания, один вес на каждый нейрон слоя сравнения. В процессе функционирования каждый нейрон слоя распознавания вычисляет скалярное произведение вектора собственных весов и входного вектора ![]() . Нейрон, имеющий веса, наиболее близкие к вектору
. Нейрон, имеющий веса, наиболее близкие к вектору ![]() , будут иметь самый большой выход, тем самым, выигрывая соревнования и одновременно затормаживая все остальные нейроны в слое распознавания.
, будут иметь самый большой выход, тем самым, выигрывая соревнования и одновременно затормаживая все остальные нейроны в слое распознавания.
10.5. Теоремы ART.
1. После стабилизации процесса обучения предъявление одного из обучающих векторов (или вектора с существенными характеристиками категории) будет активизироваться требуемый нейрон слоя распознавания без поиска. Это обеспечивает доступ к предварительно изученным образам.
2. Процесс поиска является устойчивым, то есть после определения выигравшего нейрона он остается и далее таковым. Обучение не будет вызывать переключения с одного возбужденного нейрона слоя распознавания на другой.
3. Процесс обучения конечен: завершается после конечного числа шагов.
Недостаток ART состоит в том, что она не обеспечивает распределенную память. Потеря одного узла означает потерю всей памяти.
Глава 11. Когнитрон и неокогнитрон
11.1. Когнитрон и строение зрительной коры мозга. Фукушима в 1975 году разработал когнитрон – гипотетическую модель биологической системы восприятия и распознавания зрительной информации. Эта система инвариантна к поворотам, перемещениям и изменениям масштабов образов. Возможности когнитрона к адаптивному распознаванию образов стимулировали в свою очередь исследования механизмов мозга.
Когнитрон организован подобно зрительной коре мозга человека, состоящей из нескольких слоев нейронов (рис.11.1). Несмотря на то, что слои организованы однотипно, каждый из них, подобно отдельным слоям зрительной коры, реализует различные уровни обобщения.
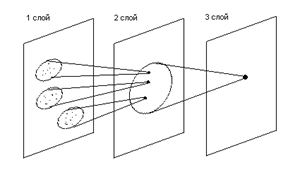
Рис.11.1. Схема последовательных проекций
Например, если входной слой нейронов распознает лишь простые образы (линии) и их ориентацию, то последующие слои способны ко все более сложному обобщению, качество которого не зависит от положений распознаваемых образов. Нейрон из последующего слоя связан с ограниченным набором нейронов предыдущего. Подобное правило организации при переходе от слоя к слою позволяет каждому нейрону выходного слоев нейронов.
Количество требуемых слоев может быть уменьшено за счет расширения области связи в последующих слоях. Однако, результатом такого расширения может стать значительное перекрытие областей связи, приводящее к одинаковой реакции нейронов выходного слоя. Для решения этой проблемы может быть усилена конкуренция между нейронами, так что влияние малой разницы в реакциях нейронов будет усиливаться.
Каждый слой когнитрона содержит два типа нейронов: возбуждающие и тормозящие (рис.10.2).
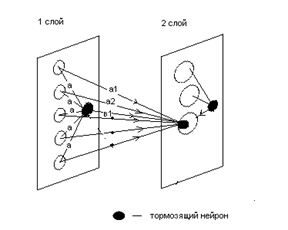
Рис.10.2. Тормозящие нейроны в проекционных слоях
Возбуждающие нейроны одного слоя стремятся вызвать активацию соединенного с ним нейрона следующего слоя. При этом на один нейрон второго слоя приходится целая группа нейронов первого слоя. Тормозящие нейроны получают сигналы от предыдущего слоя и нейтрализуют это возбуждение.
Возбуждение нейрона последующего (второго) слоя определяется значением нелинейной функции активации от взвешенной суммы его возбуждающих и тормозящих входов. Каждый возбуждаемый нейрон последующего слоя связан с ограниченным числом возбуждающих нейронов предыдущего слоя (из области связи), как и в головном мозге. Аналогично в предыдущем слое существует тормозящие нейроны, соответствующие тем же областям связи. Ясно, что когнитрон обеспечивает конвергенцию входов.
11.2. Конкуренция возбуждения и торможения. Рассмотрим работу возбуждающих и тормозящих нейронов. Возбуждающие нейроны, действуют так, что значение выхода возбуждающего нейрона определяется отношением взвешенных сумм возбуждающих и тормозящих входов:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
