


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Стандартизованная объектно-ориентированной модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group - группа управления объектно-ориентированными базами данных). Реализовать в полном объеме рекомендации ODMG-93 пока не удается.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними состоит в методах манипулирования данными.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма Ограниченно могут применяться операции, подобные командам SQL (например, для создания БД).
Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов (индексных таблиц), содержащих информацию для быстрого поиска данных.
Рассмотрим кратко понятия инкапсуляции, наследования и полиморфизма применительно к объектно-ориентированной модели БД.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта.
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект, называемый объектом-цёлью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Объект-цель, а также результат вьполнения запроса могут храниться в самой базе.
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
B 90-e годы существовали экспериментальные прототипы объектно-ориентированных систем управления базами данных. B настоящее время такие системы получили широкое распространение, в частности, К ним относятся следующие СУБД: POET (POET Software), Jasmine (Computer Associates), Versant (Versant Technologies), 02 (Ardent Software), ODB-Jupiter (научно-производственный центр «Интелтек Плюс»), а также Iris, Orion и Postgres.
Поведем некоторые итоги данного раздела.
Определение модели данных предусматривает указание множества допустимых информационных конструкций, множества допустимых операций над данными и множества ограничений для хранимых значений данных.
Модель данных, с одной стороны, представляет собой формальный аппарат для описания информационных потребностей пользователей, а с другой - большинство СУБД ориентируются на конкретную модель данных, и, таким образом, если информационные потребности удается точно выразить средствами одной из моделей данных, то соответствующая СУБД позволяет относительно быстро создать работоспособный фрагмент ЭИС.
Информационные конструкции, операции и ограничения моделей данных выбираются из достаточно небольшого множества вариантов, характеризующего «крупные» информационные объекты и операции. B частности, не допускается рассмотрение отдельных символов данных, операций сложения атрибутов, ограничения на соответствие типов данных и т. п., что характерно для языков программирования.
Классификация информационных конструкций (информационных объектов) тесно связана с областью их использования в ЭИС.
1. Объекты для технологии баз данных - отношения и веерные отношения.
2. Объекты для технологии искусственного интеллекта - предикаты, фреймы и семантические сети.
3. Объекты для технологии мультимедиа - тексты, графические изображения, фонограммы и видеофрагменты.
Информационные объекты послужили основой для объектно-ориентированного проектирования систем, когда фиксируется множество информационных объектов и действий над объектами. Типичный список действий включает в себя создание/уничтожение объекта, редактирование объекта, фиксацию одного объекта в качестве части другого объекта, связывание объектов, синхронизацию действий над объектами.
Довольно-таки часто все названные объекты встраиваются в структуру отношений, которые можно считать простейшими универсальными объектами.
На окончательный выбор модели данных влияют многие дополнительные факторы, например, наличие хорошо зарекомендовавших себя СУБД, квалификация прикладных программистов, размер базы данных и др.
B последнее время реляционные СУБД заняли преимущественное положение как средство разработки ЭИС. Недостатки реляционной модели компенсируются ростом быстродействия и ресурсов памяти современных ЭВМ. Вследствие процессов децентрализации управления в экономике многие базы данных ЭИС имеют простую структуру, которая легко трансформируется в понятные системы таблиц (отношений).
Таблица 1.1 – Обзор популярных СУБД
Дореляционные системы | ||
Категория | Название продукта | Фирма-изготовитель |
Инвертированные списки | CA-DATACOM/DB | Computer Associates Internatonal |
Иерархические системы | IMS | IBM |
Сетевые системы | CA-IDMS/DB | Computer Associates Internatonal |
Реляционные системы | ||
Реляционные | DB 2 | IBM |
Oracle | Oracle | |
Ingres | Ingres Division of the Ask Group Inc. | |
Sybase | Sybase | |
Access | ||
Paradox | Borland |
3 Основные понятия теории баз данных
3.1 Терминология БД
База данных (БД) – это единое хранилище данных, которое однократно определяется, а затем используется многими пользователями. В СУБД определение данных отделено от приложения. Добавление и изменение данных никак не влияет на приложение.
Система управления БД (СУБД) – программный комплекс, с помощью которого пользователи могут определять и поддерживать БД, а также осуществлять контролируемый доступ к данным (рисунок 2.1)
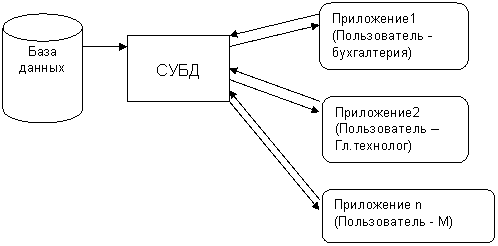

Рисунок 2.1 – Структура СУБД
Для определения БД (тип данных, структура, ограничения и т. д.) используется язык DDL (Data Definition Language).
Для манипулирования данными (вставка, обновление, извлечение информации по определенному условию) используется язык DML (Data Manipulation Language).
Существует две разновидности языка DML: процедурный и непроцедурный. Процедурные языки обычно обрабатывают информацию в БД последовательно – запись за записью. Непроцедурные языки оперируют целыми наборами данных. Наиболее распространенным типом непроцедурного языка, который сегодня является стандартом при работе с реляционными БД, является язык SQL.
Программы, с помощью которых пользователи работают с БД, называются приложениями. С одной БД может работать несколько приложений параллельно и независимо друг от друга. Например, если БД моделирует работу предприятия в целом, то для работы с ней могут быть созданы разные приложения:
- приложение по учету кадров;
- приложение для складского учета;
- приложение по планированию производственного процесса и т. д.
И именно СУБД призвана обеспечить работу множества приложений с единой БД таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в БД, вносимые другими приложениями.
Банк данных (БнД) – это система специальным образом организованных данных – баз данных, программных, технических, языковых и других средств. Банки данных позволяют обобщать информацию и извлекать новые знания по заложенным формализованным правилам, например, по правилам логики. Иногда Банки данных называют Базами знаний.
3.2 Архитектура СУБД
Проект базы данных начинается с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных), т. е. сначала создается обобщенное неформальное описание создаваемой базы данных.
Описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (рисунок 3.1).
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов, этой средой может быть память человека, а не компьютер. Остальные модели, показанные на рисунке. 3.1, являются компьютеро-ориентированными.
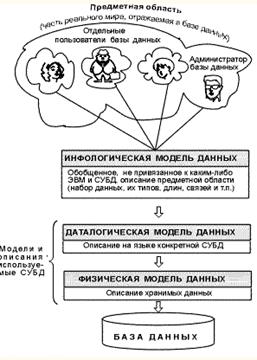
Рисунок 3.1 – Архитектура СУБД
Описание на языке конкретной СУБД, создаваемое по инфологической модели данных, называют даталогической моделью данных (c указанием типов данных).
Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. Например, данные, сохраненные в виде таблиц в программе Microsoft Excel, можно экспортировать в программу Microsoft Access, и пользоваться ими, создавая необходимые запросы и формы. В свою очередь, доступ к данным таблиц, созданных в Microsoft Access, можно организовать с помощью приложений (программ), созданных в Delphi и т. д. Кроме того, специальные программы (Oracle, SyBase, InterDase и др.) позволяют спроектировать базы данных, позволяющие подключить к системе любое число новых пользователей (новых приложений), организовав удаленный доступ к базам данных.
3.3 Основные функции СУБД
Рассмотрим основные функции систем управления базами данных:
1. Непосредственное управление данными во внешней памяти.
Эта функция обеспечивает возможность сохранения данных, непосредственно входящих в БД, а также выполнение некоторых служебных функций, например ускорение доступа к данным с использованием индексов. В развитых СУБД пользователи не обязаны знать, как эти функции реализуются в системе.
2. Управление буферами оперативной памяти.
СУБД обычно работают с БД значительного размера. СУБД имеет собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. Для ускорения работы необходимая выборка данных помещается в буфер оперативной памяти (кэш), над ними производятся действия, и только потом модифицированные данные сохраняются в БД.
Заметим, что существует отдельное направление СУБД, которое ориентировано на постоянное присутствие в оперативной памяти всей БД. Это направление основывается на предположении, что в будущем объем оперативной памяти компьютеров будет настолько велик, что позволит не беспокоиться о буферизации. Пока эти работы находятся в стадии исследований.
3. Управление транзакциями.
Транзакция – это последовательность операций над БД, рассматриваемых СУБД как единое целое и переводящее БД из одного состояния в другое. Транзакция либо успешно выполняется, и СУБД фиксирует изменение БД, либо происходит откат транзакции, и ни одно из изменений не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД.
Понятие транзакции очень важно в многопользовательских СУБД. Например, резервирование и приобретение билетов в ж/д и авиа кассах, бронирование номеров в гостиницах и т. д.
4. Журнализация.
Одним из основных требований к СУБД является обеспечение надежности хранения данных во внешней памяти, т. е. СУБД должна быть в состоянии восстановить данные после аппаратного сбоя или программного прерывания.
Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной.
Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и в которую поступают записи обо всех изменениях основной части БД. Эта часть поддерживается с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках),
5. Поддержка языков БД.
Языки БД позволяют понятными пользователю символами, близкими к обычному английскому языку создавать, модифицировать и управлять данными в БД.
В ранних СУБД использовались два языка:
- язык определения схемы (логической структуры) БД – SDL Schema Definition Language;
- язык манипулирования данными – DML Data Manipulation Language.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. В реляционных СУБД используется язык структурированных запросов SQL, который сочетает возможности языков SDL и DML.
3.4 Типовая организация современных СУБД
Логически в современной реляционной СУБД можно выделить внутреннюю часть – ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД.
1. Внутренняя часть - ядро СУБД (Database Engine).
Ядро отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями, журнализацию. Ядро обладает собственным интерфейсом, недоступным пользователям напрямую.
2. Компилятор языка БД (обычно SQL).
Основной функцией является преобразование операторов языка БД в выполняемую программу, представленную в машинных кодах.
3. Набор утилит (вспомогательных служебных программ).
Утилиты БД обычно выполняют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и выгрузка БД, сбор статистики, глобальная проверка целостности БД и т. д.
4 Реляционные модели данных
4.1 Основные понятия
В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных моделей данных, т. е. возможности использования привычных и естественных способов представления данных. Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Эдгара Кодда (Codd E. F., A Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), где, вероятно, впервые был применен термин "реляционная модель данных".
Будучи математиком по образованию Э. Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.).
Основными понятиями реляционных БД являются:
- отношение,
- тип данных,
- домен,
- атрибут,
- кортеж,
- первичные и вторичные ключи,
- целостность данных.
На рисунке 6.1 приведен пример реляционной таблицы с иллюстрацией основных терминов, используемых в теории баз данных.
Отношение – это таблица.
Типы данных. Понятие тип данных в реляционной модели данных полностью совпадает с понятием типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). В нашем примере мы имеем дело с данными трех типов: строки символов, логический тип и целочисленный тип формата "деньги".
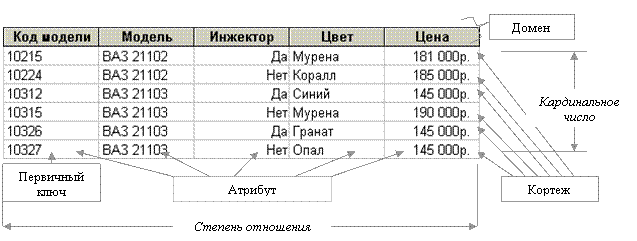

Рисунок 6.1 – Отношение (двумерная таблица)
Домен. Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. Домен - допустимое потенциальное множество значений данного типа в определенной предметной области. Например, домен "Цвет" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать название цвета (в частности, такие строки не могут начинаться с мягкого знака).
Смысловая нагрузка понятия домен: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов "Модель" и "Цвет" относятся к типу символьных строк, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle V.7 оно уже поддерживается.
Атрибут – это столбец, поле оношения. Количество атрибутов образует степень отношения. Степень отношения «Таблица1» – 5, степень отношения «Таблица2» - 4.
Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа)}. Например:{Код модели Integer}, {Модель Varchar(20)}, {Цвет Varchar(20)}, {Цена Currency}.
Степень (арность) отношения - количество атрибутов или полей. Степень отношения Прайс-лист равна четырем, то есть оно является 4-арным.
Кортеж - это множество пар {имя атрибута, значение}. Например:
Код модели 10215, Модель ВАЗ 21102, Цвет Коралл, Цена 200000р.
Количество кортежей называют кардинальным числом отношения или мощностью отношения. Кардинальное число отношения изменяется во времени в отличие от его степени.
Схема БД (в структурном смысле) - это набор именованных схем отношений. Например (рисунок 6.2):
1. Прайс-лист (Код модели Integer, Модель Varchar(20), Цвет Varchar(20), Цена Currency)
2. Продажа (Номер договора Integer, Фамилия Varchar(20), Модель Varchar(20))
3. Динамика продаж(…………………)

Рисунок 6.2 – Схема базы данных
Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения". Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД.
Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
Первичный ключ (primary key) - это поле (или несколько полей), однозначно идентифицирующее запись.
Вторичный или внешний ключ (foreign key) - это поле таблицы, используемое для связи с другой таблицей, в которой оно является первичным ключом. Связующие поля должны иметь одинаковые типы и, как правило, одинаковые названия. На рисунке 6.2 в таблице 1 первичным ключом является поле Код модели. В таблице 2 поле Номер ПТС является первичным ключом, а поле Код модели – вторичным ключом, который позволяет связать между собой две таблицы и пользоваться выборками данных из двух таблиц одновременно.
Целостность данных - это ряд правил, сохраняющих в неприкосновенности связи между таблицами. Целостность данных функционирует строго на основе ключевых полей. Из двух связанных таблиц одну обычно называют родительской, а другую дочерней. Целостность данных гарантирует отсутствие записей-сирот (т. е. дочерней записи без родительской). В нашем примере (рисунок 6.2) при удалении записи из родительской таблицы 1 (снятие автомобиля с производства) с определенного момента не должно быть записей в дочерней таблице 2 (в продажу не могут поступать автомобили, не производящиеся на заводе).
Еще один классический пример важности поддержания целостности из банковской деятельности.
Допустим, в одной из таблиц содержатся сведения обо всех клиентах банка (имена, паспортные данные и т. д.), а в другой – сведения о взятых клиентами кредитах. Удаление записи о клиенте с непогашенным кредитом может закончиться большими неприятностями. По правилам поддержания целостности должно быть предусмотрено предупреждение типа «Прежде чем удалить запись о клиенте, убедитесь, что его кредит погашен!».
4.2 Фундаментальные свойства отношений
Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого отношения первичного ключа – набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения, по крайней мере, полный набор его атрибутов обладает этим свойством. Однако на практике его делают "минимальным". Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных.
Отсутствие упорядоченности кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных.
Отсутствие упорядоченности атрибутов. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения. Например, обратиться к столбцу таблицы можно по его порядковому номеру.
Атомарность значений атрибутов. Значения всех атрибутов являются атомарными (неделимыми).
Итак, таблица обладает следующими свойствами:
1. В таблице нет двух одинаковых строк
2. Порядок строк в таблице произвольный
3. Порядок столбцов в таблице произвольный
4. На пересечении столбца и строки находится единственное значение.
4.3 Проектирование баз данных с использованием нормализации
Процесс проектирования БД в немалой степени зависит от опыта и интуиции разработчика, однако некоторые его моменты можно формализовать. Одним из таких формальных требований является нормализация.
Процесс нормализации имеет своей целью устранение избыточности данных. Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса-Кодда (BCNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
- каждая следующая нормальная форма в некотором смысле лучше предыдущей;
- при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
При нормализации происходит декомпозиция (разбиение) отношения, находящегося в предыдущей нормальной форме, в два или более отношений, удовлетворяющих требованиям следующей нормальной формы.
4.3.1 Первая нормальная форма
Первая нормальная форма (1НФ) требует, чтобы каждое поле таблицы БД было неделимым (атомарным) и не содержало повторяющихся групп.
Рассмотрим порядок нормализации на примере автоматизации процесса отпуска товаров со склада по накладной, которая имеет вид, представленный на рисунке 7.1.
Накладная № 000 | ||||
Дата | 14.11.2002 | |||
Покупатель | ||||
Адрес покупателя | Г. Тольятти, ул. Тополиная, д.12 | |||
Товар | ||||
Наименование | Ед. изм. | Цена за ед изм. | Количество | Общая стоимость |
Цемент | кг | 5 | 500 | 2500 |
Доска 10 мм | м3 | 50 | 100 | 5000 |
Рисунок 7.1 – Примерный вид документа «Накладная»

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
