


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() ОБРАЗОВАТЕЛЬНАЯ АВТОНОМНАЯ НЕКОММЕРЧЕСКАЯ ОРГАНИЗАЦИЯ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
ОБРАЗОВАТЕЛЬНАЯ АВТОНОМНАЯ НЕКОММЕРЧЕСКАЯ ОРГАНИЗАЦИЯ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«ВОЛЖСКИЙ УНИВЕРСИТЕТ ИМ. В. Н. ТАТИЩЕВА»
(ИНСТИТУТ)
Кафедра «Информатика и системы управления»
Курс лекций
«Введение в теорию баз данных»
Ст. преподаватель кафедры ИиСУ
г. о. Тольятти, 2012
Содержание
Ведение. 4
1 История развития БД.. 7
1.1 Файловые системы.. 8
1.2 Классические модели данных. 9
1.2.1 Инвертированные списки. 10
1.2.2 Иерархические системы.. 10
1.2.3 Сетевые системы.. 11
1.2.4 Реляционные системы.. 12
1.3 Сравнение классических моделей данных. 12
1.3.1 Достоинства и недостатки реляционной модели. 12
1.3.2 Достоинства и недостатки иерархической модели. 13
1.3.3 Достоинства и недостатки сетевой модели. 13
1.4 Неклассические модели данных. 14
1.4.1 Постреляционная модель данных. 14
1.4.2 Многомерная модель данных. 15
1.4.3 Объектно-ориентированная модель данных. 18
2 Основные понятия теории баз данных. 22
2.1 Терминология БД.. 22
2.2 Архитектура СУБД.. 23
2.3 Основные функции СУБД.. 25
2.4 Типовая организация современных СУБД.. 27
3 Реляционные модели данных. 28
3.1 Основные понятия. 28
3.2 Фундаментальные свойства отношений. 31
3.3 Проектирование баз данных с использованием нормализации. 33
3.3.1 Первая нормальная форма. 33
3.3.2 Вторая нормальная форма. 34
3.3.3 Третья нормальная форма. 36
3.3.4 Нормализация – за и против. 36
3.4 Реляционная алгебра. 37
3.4.1 Основные операции. 37
3.4.2 Синтаксис теоретико-множественных операций. 38
3.4.3 Синтаксис специальных операций. 42
Заключение. 45
Список литературы.. 47
Ведение
Обычная информация хранится в бумажном виде. Документы размещаются в папках, папки на полках и т. д. Для поиска требуемой информации требуется перебрать множество документов. Вводятся различные указатели для обеспечения более быстрого поиска (напр., картотеки в библиотеках, в отделах кадров, в деканатах). Тем не менее, ручной способ обработки информации очень трудоемок и длителен.
С самого начала развития вычислительной техники (ВТ) образовались два направления её использования:
1. Применение ВТ для выполнения численных расчетов, которые слишком долго проводить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию языков программирования.
2. Использование средств ВТ в автоматизированных информационных системах (ИС)
Информационная система - система, реализующая автоматизированный сбор, обработку и манипулирование данными и включающая технические средства обработки данных, программное обеспечение и соответствующий персонал.
Классическими примерами являются банковские системы, системы резервирования ж/д и авиа билетов, мест в гостиницах и т. д.
Основой любой информационной системы является база данных (БД).
База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)(Гражданский кодекс РФ, ст. 1260).
База данных - структурированный набор данных, хранящийся в электронном виде.
Другие определения из авторитетных монографий и стандартов:
База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей.
База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.
База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия.
База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
Существует множество других определений, отражающих скорее субъективное мнение тех или иных авторов о том, что означает база данных (БД) в их понимании, однако общепризнанная единая формулировка отсутствует. Наиболее часто используются следующие отличительные признаки:
1. БД хранится и обрабатывается в вычислительной системе. Таким образом, любые внекомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются.
2. Данные в БД логически структурированы (систематизированы) с целью обеспечения возможности их эффективного поиска и обработки в вычислительной системе. Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика и допустимые операции.[6]
3. БД включает метаданные, описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью). В соответствии с ГОСТ Р ИСО МЭК ТО , «постоянные данные в среде базы данных включают в себя схему и базу данных. Схема включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных. База данных включает в себя набор постоянных данных, определенных с помощью схемы. Система управления данными использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных».
Из перечисленных признаков только первый является строгим, а другие допускает различные трактовки и различные степени оценки. Можно лишь установить некоторую степень соответствия требованиям к БД.
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы, Интернет-порталы илиэлектронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
Многие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий
2 История развития БД
История возникновения и развития технологий баз данных может рассматриваться как в широком, так и в узком аспекте.
В широком аспекте понятие истории баз данных обобщается до истории любых средств, с помощью которых человечество хранило и обрабатывало данные. В таком контексте упоминаются, например, средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.), узелковая письменность инков — кипу, клинописи, содержащие документы Ассирийского царства и т. п. Следует помнить, что недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».
История баз данных в узком аспекте рассматривает базы данных в традиционном (современном) понимании. Эта история начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных COBOL была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Кодда. Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику Кодд также получил премию Тьюринга.
Сам термин database (база данных) появился в начале 1960-х годов, и был введён в употребление на симпозиумах, организованных фирмой SDC (System Development Corporation) в 1964 и 1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошёл лишь в 1970-е годы.
Одним из первых шагов в развитии информационных систем явилось создание централизованных систем управления файлами.
2.1 Файловые системы
Файловые системы были разработаны для получения более быстрого доступа к данным.
С точки зрения прикладной программы, файл – это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным зависят от конкретной системы управления файлами. Система управления берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным.
Но файловые системы имеют существенные недостатки:
1. Изоляция данных. Когда данные изолированы в разных файлах, существенно возрастает время доступа к требуемым данным.
2. Несовместимость форматов данных. При выборке данных из нескольких файлов, созданных в различных программах, требуется специальное программное обеспечение, преобразующее данные в общий формат.
3. Дублирование данных. Из-за децентрализованной работы, проводимой каждым подразделением на предприятии, в различных файлах может содержаться одинаковая информация, что ведет к непроизводительному использованию ресурсов.
4. Нарушение целостности. В разных файлах данные могут быть противоречивыми.
Для эффективной работы с данными был разработан совершенно новый подход к управлению информацией. Новые программные системы были названы Системами Управления Базами Данных, а сами хранилища информации, назывались Базами данных. Историю развития СУБД принято делить на три периода: дореляционные, реляционные и постреляционные СУБД.
2.2 Классические модели данных
Классические модели принято условно разделять на дореляционные и реляционные системы
Дореляционные системы можно разделить на 3 большие категории:
1. Инвертированные списки
2. Иерархические системы
3. Сетевые системы
Необходимо иметь о них представление по нескольким причинам:
- во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь о их предшественниках;
- во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем;
- в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо из реляционных СУБД. Некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
2.2.1 Инвертированные списки
Инвертированные списки представляют собой список таблиц и список индексов, позволяющих осуществлять доступ к данным, хранимым в таблицах, используя поиск по вторичному ключу. База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам). Пример инвертированного списка показан на рисунке 1.1.
I уровень II уровень III уровень
№ гр | № блока | Блок1 | № п/п | ФИО | № гр | ||
201 |
| 3 |
| 1 | Аронов | 202 | |
202 | 2 | 4 | 2 | Ботов | 203 | ||
203 | 3 | Блок2 |
| 3 | Викулова | 201 | |
Индексный файл с упорядоченными вторичными ключами | 1 | 4 | Громов | 201 | |||
5 | 5 | Дроздов | 202 | ||||
Блок3 | Блоки 2 уровня упорядочены по значениям вторичного ключа | ||||||
2 |
Рисунок 1.1 – Пример инвертированного списка
2.2.2 Иерархические системы
Иерархическая БД состоит из упорядоченного набора деревьев.
Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). В иерархических структурах запись-потомок должна иметь одного предка. Пример иерархической системы хранения данных показан на рисунке 1.2.
Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
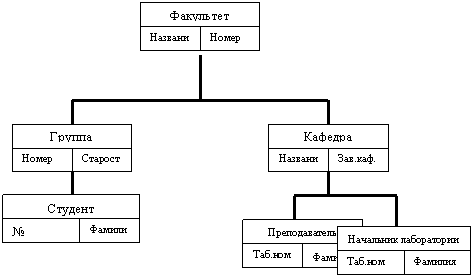

Рисунок 1.2 – Пример иерархической структуры организации хранения данных
Типичным примером иерархической модели является организация хранения данных в операционной системе Windows. Это особенно хорошо видно, если открыть программу Проводник.
2.2.3 Сетевые системы
Сетевой подход к организации данных является расширением иерархического (рисунок 1.3).
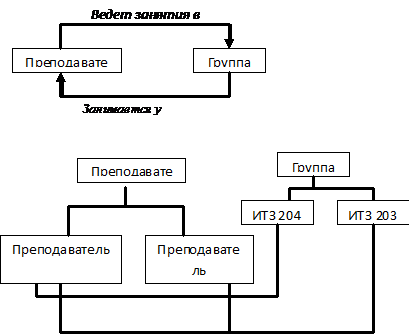
Рисунок 1.3 – Пример сетевой структуры организации хранения данных
В сетевой структуре данных потомок может иметь любое число предков. Между ветвями дерева могут существовать горизонтальные связи. Это достаточно сложные структуры, состоящие из "наборов”. "Наборы" соединяются с помощью "записей-связок", образуя цепочки и т. д. Один из разработчиков операционной системы UNIX сказал: "Сетевая база – это самый верный способ потерять данные".
Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных.
2.2.4 Реляционные системы
Почти все программные продукты, созданные с конца 70-х годов, основаны на реляционном подходе:
1. Данные представлены в двумерных таблицах.
2. Пользователю предоставляются операторы для выборки данных, с помощью которых генерируются новые таблицы на основе исходных.
Более подробное описание реляционной модели представлено в разделе 3.
2.3 Сравнение классических моделей данных
При сравнении моделей данных очень трудно отделить факторы, характеризующие принципиальные особенности модели, от факторов, связанных с реализацией этих моделей данных средствами конкретных СУБД.
2.3.1 Достоинства и недостатки реляционной модели
Рассматривая преимущества и недостатки известных моделей данных, следует отметить ряд несомненных достоинств реляционного подхода:
1. Простота. B реляционной модели всего одна информационная конструкция, которая формализует табличное представление данных, привычное для пользователей экономистов.
2. Теоретическое обоснование. Наличие теоретически обоснованных методов нормализации отношений и проверки ацикличности структуры позволяет получать базы данных с заданными характеристиками.
3. Независимость данных. Когда необходимо изменить структуру реляционной БД, это, как правило, приводит к минимальным изменениям в прикладных программах.
Среди недостатков реляционной модели данных необходимо назвать следующие.
1. Низкая скорость при выполнении операции соединения.
2. Большой расход памяти для представления реляционной БД. Хотя проектирование в ЗНФ рассчитано на минимальную избыточность (каждый факт представляется в БД один раз), другие модели данных обеспечивают меньший расход памяти для представления тех же фактов.
2.3.2 Достоинства и недостатки иерархической модели
Достоинствами иерархической модели данных являются следующие.
1. Простота. Хотя модель использует три информационные конструкции, иерархический принцип соподчиненности понятий является естественным для многих экономических задач (например, организация статистической отчетности).
2. Минимальный расход памяти. Для задач, допускающих реализацию с помощью любой из трех моделей данных, иерархическая модель позволяет получить представление с минимально требуемой памятью.
Недостатки иерархической модели.
1. Неуниверсальность. Многие важные варианты взаимосвязи данных невозможно реализовать средствами иерархической модели, или реализация связана с повышением избыточности в базе данных.
2. Допустимость только навигационного принципа доступа к данным.
3. Доступ к данным производится только через корневое отношение.
2.3.3 Достоинства и недостатки сетевой модели
Необходимо отметить следующие преимущества сетевой модели данных.
1. Универсальность. Выразительные возможности сетевой модели данных являются наиболее обширными в сравнении с остальными моделями.
2. Возможность доступа к данных через значения нескольких отношений (например, через любые основные отношения).
В качестве недостатков сетевой модели данных можно назвать.
1. Сложность, т. е. обилие понятий, вариантов их взаимосвязей и особенностей реализации.
2. Допустимость только навигационного принципа доступа к данным.
Результаты, полученные для ациклических баз данных, позволяют говорить о равноценных возможностях представления информации у ациклических реляционных БД, двухуровневых сетевых БД и иерархической БД без логических связей.
При анализе моделей данных не затрагивалась проблема упорядоченности значений в отношениях баз данных. Для реляционной модели данных эта упорядоченность с теоретической точки зрения необязательна, а в двух других моделях она широко используется для повышения эффективности реализации запросов.
2.4 Неклассические модели данных
2.4.1 Постреляционная модель данных
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме. Существует ряд случаен, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
По сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеет большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
2.4.2 Многомерная модель данных
Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. C середины 90-х годов интерес к ним стал приобретать массовый характер.
Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э. Кодда. B ней сформулированы 12 основных требований к системам класса OLAP (OnLine Analytical Processing - оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения.
B развитии концепций ИС можно выделить следующие два направления:
- системы оперативной (транзакционной) обработки;
- системы аналитической обработки (системы поддержки принятия решений).
Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области были весьма эффективны. B системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (МСУБД).
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных.
Агрегируемостъ данных означает рассмотрение информации на различных уровнях ее обобщения. B информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель.
Историчностъ данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются.
Прогнозируемостъ данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования дынными.
По сравнению с реляционной моделью многомерная, организация данных обладает более высокой наглядностью и информативностъю.
Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех - и более мерных гиперкубов). Пользователю и в этих случаях более удобно иметь дело с двухмерными таблицами или графиками. Данные при этом представляют собой «вырезки» (точнее, «срезы») из многомерного хранилища данных, выполненные с разной степенью детализации.
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающих многомерные модели данных, являются Essbase (Arbor Software), Media Mu1ti-matгix (Speedware), Oracle Express Server (Огас1е) и Cache (InterSystems). Некоторые программные продукты, например Media/M R (Speedware), позволяют одновременно работать с многомерными и с реляционными БД. B СУБД Cache, и которой внутренней моделью данных является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
2.4.3 Объектно-ориентированная модель данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
