

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Практическое занятие:
Обобщенное программирование. Шаблоны. Контейнеры и алгоритмы стандартной библиотеки.
Структуры данных и алгоритмы
могут работать вместе только потому,...
что они ничего не знают друг о друге.
-Алекс Степанов
1. Обобщенное программирование. Шаблоны.
При создании программ на С++ довольно часто приходится писать множество почти одинаковых фрагментов кода для обработки разных типов данных. С помощью ключевого слова template можно задать компилятору образец кода для некоторого обобщенного типа данных - шаблон. Используя «скелет» кода, компилятор сам сгенерирует конечный код для конкретного типа данных.
1.1. Объявление шаблона:
Замечание: при объявлении шаблона (кроме explicit) компилятор не создает никакого кода, шаблон является просто заготовкой для компилятора. Только встретив обращение к данному шаблону в тексте программы, компилятор сгенерирует соответствующий код.
template < список_параметров_шаблона > объявление_функции_или_класса
,где список_параметров_шаблона – это разделенные запятой параметры шаблона. Параметры шаблона обозначают в общем случае «отличающиеся» части того кода, который будет сгенерирован компилятором по данному шаблону (это могут быть обобщенные типы данных, константы, а также «вложенные» шаблоны).

Замечание1: не пугайтесь слова class – в качестве типа “T” можно задать как имя такого сложного типа данных как класс, так и простой (базовый) тип языка С!
Замечание2: при объявлении один из параметров шаблона может быть использован для определения последующих параметров шаблона. Например:
template< class T, T* pT> ...
1.2. Функционально шаблоны делятся на:

1.3. Инстанцирование шаблона.
Процесс генерации компилятором как функции, так и объявления класса по шаблону и списку параметров шаблона называется инстанцированием. Версия шаблона для конкретного набора аргументов называется специализацией.
стр 381
стр 393
1.4. Проверка типов
стр 383
2. Шаблоны функций
2.1. Способы обобщения функций, выполняющих одинаковые действия, но оперирующих данными разных типов.
Если функция, оперируя данными разного типа, выполняет одинаковые по смыслу действия, удобно и логично для такой функции иметь одно и то же имя. Такую возможность можно реализовать двумя способами (рассмотрим на примере функции, возвращающей минимальное из двух заданных значений):
1) с помощью «перегрузки» функций. При этом программист должен объявить и определить нужное количество функций с одним и тем же именем, которые в нашем примере отличаются только типом параметров:
// min for ints
int min( int a, int b ) {return ( a < b ) ? a : b;}
// min for doubles
double min( double a, double b ) {return ( a < b ) ? a : b;}
// min for chars
char min( char a, char b ) {return ( a < b ) ? a : b;}
//etc...
При этом компилятор сгенерирует в точке вызова функции min() вызов одной из определенных функций в зависимости от типа параметров:
{
int iX=1000, iY=500;
int iResult = min(iX, iY); //вызов min(int, int)
double dX=1.0, dY = 3;
double dResult = min(dX, dY); //вызов min(double, double)
char cX=’S’, cY=60;
char cResult = min(cX, cY); //вызов min(char, char)
}
2) с помощью шаблона функции можно уменьшить количество «дублируемого» кода, определив только один шаблон, оперирующий с некоторым обобщенным типом данных – «T»:
2.2. Объявление шаблона функции:

2.3. Создание и вызов функции по заданному шаблону:
Вызов функции-шаблона ничем не отличается от вызова обычной функции. Когда компилятор в тексте программы встретит вызов функции, он создаст конкретную реализацию функции, исходя из заданного шаблона и конкретных типов параметров, использованных при вызове функции:
{
int iX=1000, iY=500;
int iResult = min(iX, iY); //компилятор создаст и вызовет min(int, int)
double dX=1.0, dY = 3;
double dResult = min(dX, dY); //компилятор создаст и вызовет //min(double, double)
char cX=’S’, cY=60;
char cResult = min(cX, cY); //компилятор создаст и вызовет min(char, char)
iResult = min(iX, cY); //ошибка компилятора! – параметры разного типа
}
Таким образом, один раз определив в приведенном примере шаблон функции min(), можно вызывать ее для любых сколь угодно сложных типов данных (для которых определена операция сравнения – «<» ). Это существенно снижает объем Вами написанного кода и в то же время повышает его «гибкость» без уменьшения надежности.
Замечание1: при вызове функций-шаблонов, разрешено явное приведение типов аргументов шаблонов. Например:
{
iResult = min<int>(iX, cY);//компилятор преобразует «char cY» в «int cY», и вызовет min(int, int)
}
Замечание2: для функций-шаблонов также существует возможность перегрузки и правила, по которым компилятор определяет порядок...
3. Шаблоны классов.
Шаблоны классов называют также «обобщенными классами» (generic classes). Шаблон класса описывает, как компилятору сгенерировать класс (то есть выделить память под данные и сгенерировать код методов класса) по соответствующему набору аргументов шаблона и «скелету» класса. (Объявление шаблона является заготовкой класса, по которой компилятор создаст конкретные классы, основываясь на конкретных типах используемых данных.)
Для примера рассмотрим шаблон класса, с помощью которого можно реализовать «стек» для элементов любого типа (обобщенный тип Т) и максимальной глубиной стека ( int i ):
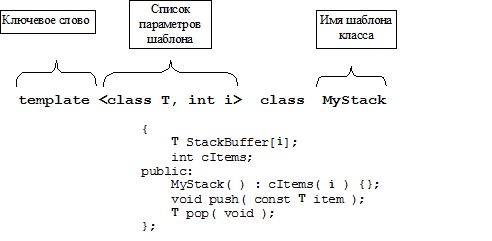
Методы шаблона класса определяются следующим образом:
template <class T, int i> void MyStack< T, i >::push( const T item )
{
if( cItems > 0 )
StackBuffer[--cItems] = item;
else
printf("Stack overflow error.\n");
return;
}
template <class T, int i> T MyStack< T, i >::pop( void )
{
if( cItems < i )
return StackBuffer[cItems++];
else
printf("Stack underflow error.\n");
}
Создание объектов конкретного типа на базе шаблона:
void main()
{
MyStack< int, 5 > stack1; //создает «стек» для 5 элементов int
stack1.push(55); //сохранить в стеке 55
int iTmp = stack1.pop(); //извлечь из стека
MyStack< char, 6 > stack2; //создает «стек» для 6 элементов char
MyStack< MyClass, 7 > stack3; //создает «стек» для 7 элементов типа MyClass
...
}
Замечание1: так как шаблоны являются механизмом времени компиляции, все параметры списка параметров базовых типов шаблона (такие как “int i”) должны быть константами:
int iJ = 5;
MyStack< MyClass, iJ > stack4; //ошибка компилятора (iJ не является константой!)
4. Ключевое слово typename и шаблоны.
Ключевое слово typename используется только при определении шаблона. Это ключевое слово говорит компилятору, что неизвестный идентификатор является типом. Например:
template<class T> class X {
typename T::Y; //указание компилятору обращаться с Y как с типом
Y m_y;
};
Ключевое слово typename можно также использовать в списке параметров шаблона вместо слова class. Следующие объявления шаблона являются эквивалентными:
template< class T1, class T2 > class X{...};
template< typename T1, typename T2 > class X{...};
стр 500
5. Обобщенное программирование. Обобщенные алгоритмы.
Допустим, имеются шаблоны для реализации векторов, списков и других сложных структур хранения данных. Естественными операциями при любом способе организации совокупности данных являются поиск данного по какому-то условию, сортировка данных, копирование данных... Оказывается, если организовать шаблоны, руководствуясь некоторыми общими принципами, можно и алгоритмы работы с ними (поиск, сортировку, копирование...) сделать обобщенными (то есть такой обобщенный алгоритм должен обрабатывать любой построенный по принятым правилам шаблон одинаково, «не задумываясь» с каким именно шаблоном он работает).
Подход, принятый для организации шаблонов и нечисловых алгоритмов в стандартной библиотеке С++, состоит во введении понятия последовательности и манипулирования последовательностями посредством итераторов. Техника последовательностей и итераторов основывается на следующих представлениях: любую совокупность данных можно представить в виде последовательности и установить закон перемещения по этой последовательности от одного элемента к другому с помощью итератора. Графически последовательность (при любой организации данных) можно представить следующим образом:
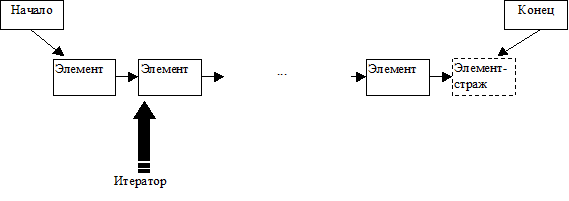
Последовательность имеет начало и конец. Началом является итератор, ссылающийся на первый элемент последовательности. Физическим представлением конца может быть «элемент-страж», но это не обязательно (обычно концом последовательности является итератор, который ссылается на элемент, следующий за последним). Для обращения к элементам последовательности служит итератор. Итератор в простейшем случае можно представить себе как указатель на элемент последовательности. С помощью итератора программист должен иметь возможность: а) получить желаемый элемент, б) переместить итератор на следующий элемент последовательности. Очевидными операциями, поддерживающими а) и б) являются оператор разыменования ( «*» ) и оператор инкремента ( «++» ). Тогда будет справедлив следующий код:
template<class In, class Out> void Copy( In from, In too_far, Out to)
{
while(from!= too_far)
{
*to = *from; //копируем элемент, на который указывает итератор //from, в элемент, на который указывает итератор to
to++; //итератор to сдвигается на следующий элемент
from++; //итератор from сдвигается на следующий элемент
}
}
Приведенный пример будет копировать любые совокупности данных, для которых определены итераторы, поддерживающие операторы «*» и «++». Например, для массивов копирование элементов будет выглядеть следующим образом:
{
char mas1[200];
char mas2[500];
...
Copy(&mas1[0], &mas1[200], &mas2[0]); //скопирует 200 элементов mas1 в mas2, заполняя mas2 с нулевого элемента
}
В рассмотренном примере и источник, и приемник имеют один и тот же способ хранения элементов - массив, но это вовсе не обязательно. Обратите внимание: для указания типов источника и приемника используются два (а не один) параметра шаблона: In и Out. Поэтому в общем случае копирование может производиться из последовательности типа In в последовательность типа Out. Забегая вперед, приведем пример копирования последовательности одного типа в последовательность другого типа:
{
...
double dMas[200]; //массив 200 элементов double
vector<double> dVect(300); //шаблон стандартной библиотеки шаблонов типа «вектор» для последовательности из 300 элементов double
list<double> dList(500); //шаблон стандартной библиотеки шаблонов типа “список” для последовательности из 500 элементов double
...
Copy( &dMas[0], &dMas[200], dVect. begin() ); //скопировать массив в вектор, начиная с первого элемента вектора
Copy( dVect. begin(), dVect. end(), dList. begin() ); // скопировать вектор в список, начиная с первого элемента списка
}
6. Стандартная библиотека шаблонов. Контейнеры, алгоритмы и итераторы.
На мой взгляд, одним из девизов программиста должен быть: «Не стоит изобретать велосипед!», поэтому прежде чем изобретать что-то, подумайте – нельзя ли то же самое получить даром (главное знать: что и где можно позаимствовать). Следовательно, после того, как Вы поняли, в чем заключается механизм шаблонов и что такое обобщенные алгоритмы, логично познакомиться со стандартной библиотекой шаблонов (Standart Template Library - STL).
Шаблоны классов стандартной библиотеки также называют контейнерами (container), так как основное назначение таких шаблонов – хранить и обрабатывать данные любого типа. Все контейнеры стандартной библиотеки поддерживают технику итераторов и последовательностей. Ключевая идея для стандартных контейнеров заключается в следующем: каждый контейнер содержит стандартный базовый “интерфейс” для общения с “внешним миром ”, который позволяет программисту оперировать таким объектом-контейнером, не особо задумываясь над его внутренней организацией. Для обобщенной обработки контейнеров разработчиками STL созданы стандартные алгоритмы. Связующим звеном между контейнерами и алгоритмами являются итераторы стандартной библиотеки (алгоритмы посредством итераторов получают доступ к элементам последовательности).
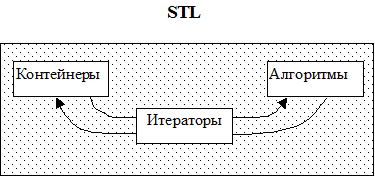
Замечание: шаблоны STL определены в пространстве имен std, поэтому для использования шаблона недостаточно включить соответствующий заголовочный файл, а следует также “разрешить область видимости” посредством префикса std:: или директивой using namespace std;
6.1. Виды контейнеров STL.
Основными контейнерами STL являются:
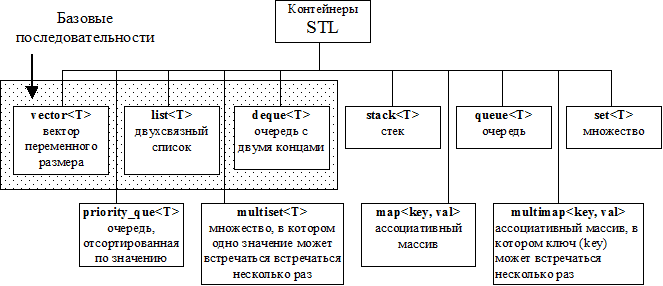
Контейнеры vector, list и deque не построить один из другого без потерь эффективности, поэтому принято их считать базовыми. При помощи этих трех базовых контейнеров можно изящно и эффективно реализовать стеки (stack) и очереди (queue)... Поэтому классы stack и queue определены не как отдельные контейнеры, а как адаптеры базовых контейнеров.
6.2. Структура стандартного контейнера.
Для обеспечения обобщенного программирования каждый контейнер STL реализует стандартный интерфейс “общения с внешним миром”, то есть стандартный набор базовых операций со стандартными именами и смыслом (а дополнительные операции обеспечиваются для частных контейнерных типов по мере необходимости). Дополнительная общность использования обеспечивается посредством стандартных итераторов, обеспечивающих доступ к элементам контейнера. (Для повышения эффективности для частных контейнерных типов наряду со стандартными могут быть введены дополнительные итераторы);
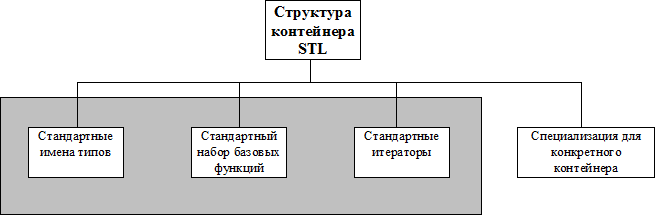
6.3. Обзор членов стандартного шаблона.
Ниже перечислены общие (для всех контейнеров) и «почти» общие (для группы контейнеров) члены стандартных контейнеров. Для того, чтобы получить полную информацию по каждому контейнеру, загляните в Help или соответствующий заголовочный файл стандартной библиотеки (<vector>, <list>, <map>...).
Замечание: заглядывая в заголовочные файлы, обратите внимание: многие члены контейнеров STL в свою очередь также являются шаблонами (не пугайтесь такой сложной «вложенности» - на первых порах гораздо важнее уметь пользоваться контейнерами, чем вникать в тонкости их организации).
Стандартные типы
value_type тип элемента контейнера
allocator_type тип распределителя памяти
size_type тип индексов, счетчика элементов и т. п. (эквивалент sizeof() элемента)
difference_type тип результата вычитания адресов двух элеметов
iterator ведет себя подобно value_type*
const_iterator ведет себя подобно const value_type*
reverse_iterator просматривает контейнер в обратном порядке ведет себя как value_type*
const_reverse_iterator просматривает контейнер в обратном порядке ведет себя как const value_type*
reference ведет себя подобно value_type&
const_ reference ведет себя подобно const value_type&
key_type тип ключа (только для ассоциативных контейнеров)
mapped_type тип mapped_value – отображенного значения (только для ассоциативных контейнеров)
key_compare тип критерия сравнения (только для ассоциативных контейнеров)
Каждый контейнер с помощью typedef дает стандартные имена типам своих членов класса. Каждый контейнер определяет эти типы своим способом, наиболее подходящим для реализации.
Итераторы
Каждый контейнер обеспечивает тип под названием iterator и const_iterator для указания на свои элементы. Фактические типы итераторов контейнера определяются при реализации. При помощи итераторов программист может управлять контейнерами, не зная фактических типов элементов. Несколько ключевых методов стандартных контейнеров позволяют найти концы последовательности элементов:
begin() возвращаемое значение указывает на первый (нулевой) элемент
end() указывает на элемент, следующий за последним
rbegin() указывает на первый (нулевой) элемент
rend() указывает на элемент, следующий за последним, в обратной последовательности
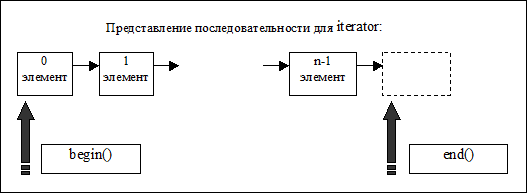
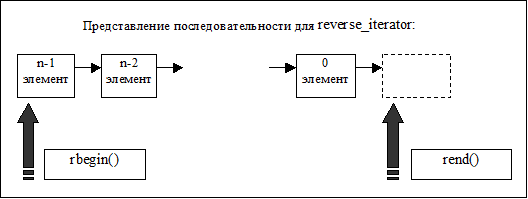
Доступ к элементам
К некоторым элементам можно обратиться прямо:
front() первый элемент
back() последний элемент
[] обращение по индексу, доступ без проверки выхода за пределы (не для списка)
at() “обращение по индексу”, доступ с проверкой (не для списка)
Операции вставки-удаления первых и последних элементов
push_back() добавление в конец
pop_back() удаление последнего элемента
push_front() добавление нового первого элемента (только для списков и очередей с двумя концами)
pop_front() удаление первого элемента (только для списков и очередей с двумя концами)
Операции вставки-удаления произвольных элементов
insert(p,x) добавление x перед p
insert(p,n,x) добавление n копий x перед p
insert(p,first,last) добавление элементов из [first, last[ перед p
erase(p) удаление элемента в позиции p
erase (first, last) удаление [first, last[
clear() удаление всех элементов
Другие операции
Все контейнеры обеспечивают операции, связанные с получением информации о числе элементов, и несколько других операций.
size() число элементов
empty() контейнер пуст?
max_size() размер самого большого возможного контейнера
capacity() память, выделенная под вектор (только для векторов)
reserve() выделяет память под вектор (только для векторов)
resize() изменяет размер контейнера (для векторов, списков и очередей с двумя концами)
swap() обмен местами элементов двух контейнеров
get_allocator() получает копию контейнерного распределителя памяти
== содержимое двух контейнеров совпадает?
!= содержимое двух контейнеров различается?
< один контейнер лексиграфически меньше второго?
Конструкторы и деструктор
container() пустой контейнер
container(n) n элементов со значением по умолчанию (не для ассоциативных контейнеров)
container(n, x) n копий x (не для ассоциативных контейнеров)
container(first, last) инициализирует элементы из [first, last[
container(x) копирующий конструктор (инициализирует элементами из контейнера x)
~container() уничтожает контейнер и все его элементы
Присваивания
operator=(x) копирующее присваивание (берутся элементы из контейнера x)
assign(n,x) присваивание n копий x (не для ассоциативных контейнеров)
assign(first, last) присваивание из [first, last[
Ассоциативные операции
operator[](k) доступ к элементу с ключом k (для контейнеров с уникальным ключом)
find(k) находит элемент с ключом k
lower_bound(k) находит первый элемент с ключом k
upper_bound(k) находит первый элемент с ключом больше k
equal_range(k) находит нижнюю границу (lower_bound) и верхнюю границу (upper_bound) элементов с ключом k
key_comp() копирует объект с совпавшим ключом
value_comp() копирует объект с совпавшим mapped_value (отображенным значением)
6.4. Что же такое итераторы?
Каждый конкретный итератор должен содержать информацию для обеспечения манипулирования элеменами конкретного контейнера. Например, для вектора (vector) хорошо подходит обыкновенный указатель, хотя итератор вектора можно организовать и в виде пары: указатель на начало массива и индекс элемента. Итератор для списка (list) должен быть сложнее, так как элементы списка в общем случае расположены в памяти не последовательно, а согласно некоторым связям между ними, таким образом итератор списка может быть указателем на такую связь. Еще сложнее обстоят дела с ассоциативными массивами и т. д.
Важно, что общим для всех итераторов является их смысл и имена операций. Например, применение «++» к любому итератору приведет к тому, что итератор будет ссылаться на следующий элемент последовательности. Аналогично, операция «*» применительно к итератору дает элемент, на который ссылается итератор. Следует отметить, что программисту редко требуется знать тип конкретного итератора. Каждый контейнер сам «знает» тип своего итератора и обеспечивает его взаимодействие с «внешним миром» через стандартные имена iterator и const_iterator.
6.5. Распределители памяти - шаблон allocator.
Объявление любого контейнера STL включает параметр, который обеспечивает корректное обращение с памятью для конкретного контейнера:
template<class T, class A = allocator<T>,[...] > class имя_контейнера{};
- второй параметр списка по умолчанию является объектом типа allocator (allocator в свою очередь является также шаблоном), который предоставляет контейнеру средства для манипулирования памятью при захвате и освобождении памяти для элементов типа T.
7. Краткий обзор стандартных контейнеров.
7.1. Вектор (vector).
Основным агрегатным типом языка С является массив. Работать с массивом удобно, если на момент его создания известен его размер (при этом все равно: отводим ли память под массив статически или динамически). Если же мы заранее не знаем, сколько потребуется элементов данного типа, приходится прибегать к различным ухищрениям: запрашивать память под массив «с запасом», задавая некоторый максимальный размер (а грамотный программист при этом еще обязан следить за тем, чтобы массив все-таки не переполнился). Для того, чтобы для таких задач, с одной стороны, использовать память эффективно (разумно), а с другой стороны избежать бесконечных проверок на переполнение, STL предоставляет шаблон одномерного массива переменного размера– vector. Стандартный вектор – это шаблон, определенный в пространстве имен std и представленный в заголовочном файле <vector>.
Контейнер vector описывает объект, манипулирующий последовательностью элементов Т непостоянной длины. Последовательность хранится как массив элементов Т. Поэтому контейнер vector обеспечивает итераторы с произвольным доступом.
Vector reallocation occurs when a member function must grow the controlled sequence beyond its current storage capacity. Other insertions and erasures may alter various storage addresses within the sequence. In all such cases, iterators or references that point at altered portions of the controlled sequence become invalid.
7.2. Список (list)
Список – это последовательность, оптимизированная для вставки и удаления элементов (реализуется в форме двухсвязного списка). По сравнению с вектором обращение к элементу списка по индексу оказалось бы чрезвычайно медленным, поэтому оно для него не предоставляется. И поэтому список предоставляет двунаправленные итераторы, а не итераторы с произвольным доступом.
7.2.1. Удаление, вставка, сортировка и слияние
В добавление к основным операциям с последовательностями list предоставляет операции, специально приспособленные для манипулирования списками:
template<class T, class A = allocator<T> > class list {
public:
//типы и операции, похожие на типы и операции для векторов, кроме
// [], at(), capacity() и reserve()
...
//операции, специфичные для списков:
void splice(iterator it, list& x); //перемещение всех элементов из x на место перед элементом, на который указывает it в данном списке без копирования (удаление-вставка)
void splice(iterator it, list& x, iterator first); //перемещение элемента, на который указывает first, из последовательности x перед it в данном списке
void splice(iterator it, list& x, iterator first, iterator last); //перемещение элементов [first, last) из последовательности x перед it в данном списке
//сортировка списка:
void sort(); //отсортировывает список согласно следующему правилу: для любого i < j должно выполняться: *Pi < *Pj, то есть список сортируется в порядке возрастания
template<class Pred> void sort(greater<T> pr); // для i < j должно выполняться! pr(*Pj, *Pi)
//объединение отсортированных списков:
void merge(list& x); //объединяет два отсортированных списка, удаляя элементы из одного списка и вставляя в другой с сохранением порядка
void merge(list& x, greater<T> pr);
...
};
7.2.2. Операции с начальными элементами.
Операции с первыми элементами списков созданы в дополнение к операциям с последнеми элементами, которые обеспечиваются любыми последовательностями.
template<class T, class A = allocator<T> > class list {
public:
...
reference front(); //ссылка на первый элемент
const_reference front() const;
void push_front(const T& x); //добавление нового первого элемента
void pop_front(); //удаление первого элемента
...
}
Замечание: если существует вероятность того, что Ваша программа, использующая списки, со временем разовьется в обобщенный алгоритм, применимый к разным типам контейнеров, лучше не использовать операции с началом последовательности, а пользоваться общими для контейнеров разного типа операциями с концами последовательностей.
7.2.3. Другие специализированные операции для list.
template<class T, class A = allocator<T> > class list {
public:
...
//Для любого списка особенно эффективными являются операции вставки и //удаления элементов:
void remove(const T& x); //удаляет из последовательности все элементы, равные x
void remove_if(binder2nd<not_equal_to<T> > pr); //удаляет из последовательности те элементы, которые отвечают заданному критерию. (то есть для которых pr(*P) возвращает true (где P – это итератор))
void unique(); //удаляет один из двух последовательно расположенных одинаковых элементов
void unique(not_equal_to<T> pr); //если требуется удалить только определеннные дубликаты, можно ввести логическое условие, чтобы указать: какие именно дубликаты следует удалить
//Дополнительные операции для list:
void reverse(); //изменить порядок следования элементов на обратный
...
}
7.3. Очереди с двумя концами - deque.
Deque – это последовательность, оптимизированная таким образом, что операции с обоими концами так же эффективны, как в списке, в то время как операция обращения по индексу приближается по своей эффективности к вектору.
template<class T, class A = allocator<T> > class deque {
//типы и операции, такие же как vector
//плюс операции с началами как в list
...
}
8. Почти контейнеры: встроенные массивы, string, valarray, bitset.
Встроенные массивы, строки (string) массивы (valarray) и битовые наборы (bitset) содержат элементы и, следовательно, во многих отношениях могут считаться специализированными контейнерами. Однако все они имеют недостатки в отношении стандартного контейнерного интерфейса, так как эти «почти контейнеры» не совсем взаимозаменяемы со стандартными (полностью разработанными) контейнерами STL.
8.1. string
Стандартные библиотечные возможности работы со строками базируются на шаблоне basic_string, который предоставляет типы членов и операции, схожие с теми, что обеспечиваются стандартными контейнерами. Шаблон basic_string и все связанные с ним средства определены в пространстве имен std и представлены в заголовочном файле <string>. Тип string определяется следующим образом:
typedef basic_string<char> string;
обеспечивает следующие операции над строками: индексация, присваивание, сравнение, добавление, конкатенация, поиск подстрок. Хотя этот библиотечный класс не идеален, рекомендуется (Страуструп) применять опрерации с string вместо вызова фукций, предназначенных для манипуляций с С-строками.
стр 550
9. Обобщенные алгоритмы и стандартная библиотека.
Идея обращения с различными видами контейнеров (а в более общем случае со всеми видами источников информации) унифицированным способом является ключевой идеей обобщенного программирования. Для поддержки этой идеи стандартная библиотека содержит множество обобщенных алгоритмов. Такие алгоритмы избавляют программиста от необходимости знать подробности отдельных контейнеров. В контексте стандартной библиотеки С++ алгоритм – это шаблон функции, которая умеет работать с последовательностями. Алгоритмы определены в пространстве имен std и представлены в заголовочном файле <algorithm>. Если Вы загляните в указанный заголовочный файл, Вы увидите десятки шаблонов функций, но в рамках данной темы рассмотрены (кратко) будут только наиболее полезные:
Наиболее популярные стандартные алгоритмы | ||
Алгоритмы, не модифицирующие последовательности | for_each() | Вызвать функцию для каждого элемента |
find() | Найти первое вхождение аргументов | |
find_if() | Найти первое соответствие предикату | |
count() | Сосчитать число вхождений элемента | |
count_if() | Сосчитать число соответствий предикату | |
replace() | Заменить элемент новым значением | |
replace_if() | Заменить элемент, соответствующий предикату, новым значением | |
copy() | Скопировать элементы | |
unique_copy() | Скопировать только различные элементы | |
sort() | Отсортировать элементы | |
equal_range() | Найти диапазон всех элементов с одинаковым значением | |
merge() | Слияние отсортированных последовательностей |
Замечание: эти и многие другие алгоритмы можно применять к контейнерам, строкам (string) и встроенным массивам языка С.
стр 100
9.1. for_each()
Одним из преимуществ, которые получает программист, пользуясь стандартными алгоритмами, - является возможность не писать явные циклы.
template<class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function F)
{
while(first!= last) F(*first++);
return F;
}
Алгоритм for_each() простейший среди алгоритмов в том смысле, что он ничего не делает, кроме того, что вызывает функцию F для каждого элемента последовательности из диапазона [first, last) и возвращает указатель на ту же самую функцию F.
Замечание: прежде чем прибегать к for_each(), подумайте, нет ли более специализированного алгоритма, который больше Вам подойдет.
9.2. find(), find_if()
Замечание: семейство алгоритмов find... содержит разнообразные алгоритмы поиска не только в одной, но также и в двух последовательностях. В данном разделе рассмотрены только простейшие алгоритмы семейства.
template<class InputIterator, class T>
InputIterator find(InputIterator first, InputIterator last, const T& value)
Алгоритм find() просматривает последовательность в пределах [first, last) и возвращает итератор, указывающий на первый элемент последовательности, значение которого равно value. Если же элемента с таким значением в заданном промежутке последовательности не существует, то итератор - last.
template<class InputIterator, class T, class Predicate>
InputIterator find_if(InputIterator first, InputIterator last, Predicate predicate)
Алгоритм find_if() просматривает последовательность в пределах [first, last) и ищет первый элемент последовательности, для которого функция-предикат (predicate) вернет true. Если такой элемент найден, то find_if() возвращает итератор на него, если же такого элемента не существует, то last.
9.3. count(), count_if()
Алгоритм count() считает число вхождений в заданный диапазон последовательности элементов с заданным значением (value)
template<class InputIterator, class T>
size_t count(InputIterator first, InputIterator last, const T& value)
Алгоритм count_if() считает число вхождений в заданный диапазон последовательности элементов, удовлетворяющих некоторому условию (для которых предикат возвращает true).
template<class InputIterator, class Predicate>
size_t count_if(InputIterator first, InputIterator last, Predicate P)
9.4. copy()
Алгоритм copy() обеспечивает дублирование элементов одной последовательности в другую:
template<class In, class Out> Out copy(In first, In last, Out res)
{
while(first!= last) *res++ = *first++;
return res;
}
Замечание: при копировании будьте бдительны – не выйдите за границы последовательности Out!
стр 593 – back_inserter
9.5. unique(), unique_copy()
При сборе информации часто происходит дублирование данных. Алгоритмы unique() и unique_copy() удаляют соседние одинаковые значения последовательности
9.6. replace(), replace_if()
10. Предикаты.
Довольно часто возникает потребность выполнения какого-то действия а) для каждого элемента последовательности или б) наоборот, только для тех элементов последовательности, которые удовлетворяют некоторому условию. Конечно, с помощью итератора всегда можно написать явный цикл по всем элементам и для каждого элемента вызывать функцию, реализующую заданное действие или осуществляющую заданную проверку. Но STL освобождает Вас от такого рутинного кодирования, предоставляя средство вызова такой функции, не требующее написания явного цикла, – предикат. Предикат может быть реализован как глобальная функция, объект-функция или как метод класса для полиморфных типов
10.1. Предикат – глобальная функция
Например, найдем в векторе целых элементов количество чисел, больших чем 10:
#include <algorithm>
#include <vector>
//Функция-предикат, проверяющая: целое больше 10?
bool Greater10( const int& number)
{
return ( number>10 );
}
void main()
{
vector<int> iVect; //создали пустой вектор элементов типа int
//Заполнили вектор значениями:
iVect. push_back(3);
iVect. push_back(11);
iVect. push_back(20);
iVect. push_back(1);
//сосчитали количество элементов
int result = count_if(iVect. begin(),iVect. end(), Greater10); //в нашем случае функции Greater10() передается в качестве аргумента текущий элемент последовательности – вектора iVect
// Исходя из наших данных получили : result=2
}
10.2. Объекты-функции
Функции типа Greater10(), рассмотренные в качестве примера в разделе (Предикат – глобальная функция) могут быть самыми разными: арифметические операции, логические, извлечение информации и т. д. Писать каждый раз отдельные функции для каждого случая (например, Greater7()) неудобно и неэффективно. Для того, чтобы можно было в данном примере использовать «предикат с параметром», то есть в качестве параметра задавать число, с которым мы хотим сравнить все члены последовательности, хорошо подходит объект «функции-подобного» класса:
template<class T> class GreaterX{
T m_valueToCompare;
public:
GreaterX(T x) : m_valueToCompare(x){} //конструктор. При конструировании объекта инициализируется встроенная переменная m_valueToCompare значением x
bool operator()(T current){ return current>m_valueToCompare; } //переопределение оператора (). При вызове предиката для каждого элемента проверяемой последовательности будет выполняться сравнение текущего значения с встроенной переменной класса m_valueToCompare и возвращаться результат этого сравнения
};
void main()
{
vector<int> vI;
vI. push_back(1);
vI. push_back(2);
vI. push_back(3);
vI. push_back(4);
int result=count_if(vI. begin(), vI. end(), GreaterX<int>(2));
}
Суть такого подхода состоит в том, что стандартный алгоритм (в нашем случае count_if() ) в действительности не считает, что его третьим аргументом должен быть обязательно указатель на функцию. Третий аргумент можно рассматривать как нечто такое, что можно вызвать с аргументом – текущим членом данной последовательности.
10.3. Базовые классы для объектов-функций
Стандартная библиотека предоставляет множество полезных объектов-функций. Для таких функций библиотека определяет несколько базовых классов:
10.3.1. Для унарной функции:
template<class Arg, class Result>
struct unary_function {
typedef Arg argument_type;
typedef Result result_type;
};
Такой шаблон служит в качестве базы для переопределения оператора «()» в Вашем классе следующим образом:
result_type operator()(argument_type)
Таким образом, все унарные функции могут обращаться к своему единственному аргументу стандартным образом как к argument_type, а возвращать значение как result_type.
Пример:
class MatchString : public unary_function<string, bool>{
string m_string;
public:
MatchString(const string& ss) : m_string(ss){}
bool operator()(const string& str) const {return m_string==str;}
};
void main()
{
vector<char*> strVect;
strVect. push_back("She");
strVect. push_back("Sells");
strVect. push_back("Sea");
strVect. push_back("Shells");
strVect. push_back("by");
strVect. push_back("the");
strVect. push_back("Sea");
strVect. push_back("Shore");
//С помощью алгоритма count_if() сосчитаем количество строк,
//которые совпадают с заданной
int result = count_if(strVect. begin(), strVect. end(), MatchString("Sea"));
}
10.3.2. Для бинарной функции:
template<class Arg1, class Arg2, class Result>
struct binary_function {
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
};
Такой шаблон служит в качестве базы для переопределения оператора «()» в Вашем классе следующим образом:
result_type operator()(first_argument_type, second_argument_type)
Таким образом, все бинарные функции могут обращаться к своему первому аргументу как к first_argument_type, ко второму как second_argument_type, а возвращать значение как result_type.
Пример:
10.4. Предикат – метод класса
Часто последовательности состоят из сложных объектов (экземпляров класса или указателей на объекты типа класс). При этом естественно определить функцию-предикат тоже как метод данного класса (для того, чтобы предикат мог оперировать с данными-членами независимо от их спецификатора доступа). И для такого случая разработчики STL облегчили Вам жизнь – создали стандартные библиотечные шаблоны : mem_fun() и mem_fun_ref(). Первый шаблон – для последовательностей указателей на объекты, второй – для последовательностей объектов.
Пример:
class Point{
public:
Point(int x, int y){iX = x, iY = y}
...
bool Range0_5(){ return (iX>0 && iX<5 && iY>0 && iY<5); } //функция возвращает true только тогда, когда обе координаты принадлежат интервалу (0,5)
private:
int iX;
int iY;
};
void main()
{
//mem_fun()
list<Point*> ptList; //объявили список объектов Point
//Сформировали значения элементов списка
ptList. push_back(new Point(1,2));
ptList. push_back(new Point(3,4));
ptList. push_back(new Point(5,6));
//посчитаем количество точек, координаты которых лежат в диапазоне (0,5)
int num = count_if(ptList. begin(),ptList. end(),mem_fun(&Point::Range0_5) );
//mem_fun_ref()
vector<Point> ptVect;
ptVect. push_back( Point(1,1) );
ptVect. push_back( Point(2,2) );
ptVect. push_back( Point(3,3) );
num = count_if(ptVect. begin(), ptVect. end(), mem_fun_ref(&Point::Range0_5));
}
11. Шаблон класса, производный от шаблона класса.
стр 89
12. Когда следует использовать шаблоны.
Templates are often used to:
· Create a type-safe collection class (for example, a stack) that can operate on data of any type.
· Add extra type checking for functions that would otherwise take void pointers.
· Encapsulate groups of operator overrides to modify type behavior (such as smart pointers).
Most of these uses can be implemented without templates; however, templates offer several advantages:
· Templates are easier to write. You create only one generic version of your class or function instead of manually creating specializations.
· Templates can be easier to understand, since they can provide a straightforward way of abstracting type information.
· Templates are type-safe. Because the types that templates act upon are known at compile time, the compiler can perform type checking before errors occur.
