

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Поначалу шина PCI вводилась как пристройка (mezzanine bus) к системам с основной шиной ISA, став позже центральной шиной: она соединяется с системной шиной процессора высокопроизводительным мостом («северным»), входящим в состав чипсета системной платы. Остальные шины расширения ввода-вывода (ISA/EISA или МСА), а также локальная ISA-подобная шина X-BUS и интерфейс LPC, к которым подключаются микросхемы системной платы (ROM BIOS, контроллеры прерываний, клавиатуры, DMA, портов СОМ и LPT, НГМД и прочие «мелочи»), подключаются к шине PCI через «южный» мост. В современных системных платах с хабовой архитектурой шину PCI Отодвинули на периферию, не ущемляя ее в мощности канала связи с процессором и памятью, но и не нагружая транзитным трафиком устройств других шин.
Шина является синхронной — фиксация всех сигналов выполняется по положительному перепаду (срронту) сигнала CLK. Номинальной частотой синхронизации считается 33 МГц, при необходимости частота может быть понижена (на машинах с процессором 486 использовали частоты 20-33 МГц). Во многих случаях частоту успешно разгоняют и до 41,5 МГц (половина типовой частоты системной шины 83 МГц). Начиная с версии 2.1 допускается повышение частоты до 66 МГц при согласии всех устройств на шине.
Номинальная разрядность шины данных — 32 бита, спецификация определяет и расширение разрядности до 64 бит. При частоте шины 33 МГц теоретическая пропускная способность достигает 132 Мбайт/с для 32-битной шины и 264 Мбайт/с для 64-битной; при частоте синхронизации 66 МГц — 264 и 528 соответственно. Однако эти пиковые значения достигаются лишь во время передачи пакета, а из-за протокольных накладных расходов реальная средняя суммарная.(для всех задат-чиков) пропускная способность шины оказывается ниже.
С устройствами PCI процессор может взаимодействовать командами обращения к памяти и портам ввода-вывода, адресованным к областям, выделенным каждому такому устройству при конфигурировании. Устройства могут вырабатывать запросы маскируемых и немаскируемых прерываний. Понятия каналов DMA для шины PCI нет, но агент шины может сам выступать в роли зада'тчика, поддерживая высокопроизводительный обмен с памятью (и не только), не занимая ресурсов центрального процессора. Таким образом, к примеру, может быть реализован обмен в режиме DMA с устройствами AT А, подключенными к контролеру PCI
IDE (см. п. 9.2.1). Спецификация PCI требует от устройств способности перемещать все занимаемые ресурсы в пределах доступного пространства адресации. Это позволяет обеспечивать бесконфликтное распределение ресурсов для многих устройств (функций). Для управления устройствами рекомендуется вместо портов ввода-вывода по возможности использовать ячейки памяти. Одно и то же функциональное устройство может быть сконфигурировано по-разному, отображая свои регистры либо на пространство памяти, либо на пространство ввода-вывода. Драйвер может определить текущую настройку, прочитав содержимое регистра базового адреса устройства, — признаком пространства ввода-вывода будет единичное значение бита 0 (см. п. 6.2.12). Драйвер также может определить и номер запроса прерывания, который используется устройством.
39.Протокол шины PCI
В каждой транзакции (обмене по шине) участвуют два устройства — инициатор (initiator) обмена, он же ведущее (master) устройство, и целевое (target) устройство (ЦУ), оно же ведомое (slave). Шина PCI все транзакции трактует как пакетные: каждая транзакция начинается фазой адреса, за которой может следовать одна или несколько фаз данных. Состав и назначение интерфейсных сигналов шины приведены в табл. 6.11.
| Глава 6. | Шины и карты расширения | ||
Таблица 6. | 11. | Сигналы шины PCI | ||
Сигнал | Назначение |
 178
178AD[31:0] Address/Data — мультиплексированная шина адреса/данных. В начале транзакции передается адрес, в последующих тактах —данные
С/ВЕ[3:0]# Command/Byte Enable — команда/разрешение обращения к байтам. Команда, определяющая тип очередного цикла шины, задается четырехбитным кодом в фазе адреса „
FRAME* Кадр. Введением сигнала отмечается начало транзакции (фаза адреса), снятие сигнала указывает на то, что последующий цикл передачи данных является последним в транзакции
DEVSEL* Device Select — устройство выбрано (ответ ЦУ на адресованную к нему транзакцию)
IRDY* Initiator Ready — готовность ведущего устройства к обмену данными
TRDY* Target Ready — готовность ЦУ к обмену данными
STOP* Запрос ЦУ к ведущему устройству на остановку текущей транзакции
LOCK* Сигнал захвата шины для обеспечения целостного выполнения операции. Используется мостом, которому для выполнения одной операции требуется выполнить несколько транзакций PCI
REQ# Request — запрос от ведущего устройства на захват шины
GNT# Grant — предоставление ведущему устройству управления шиной
PAR Parity — общий бит паритета для линий AD[31:0] и С/ВЕ[3:0]#
PERR* Parity Error — сигнал об ошибке паритета (для всех циклов, кроме специальных). Вырабатывается любым устройством, обнаружившим ошибку
РМЕ# Power Management Event — сигнал о событиях, вызывающих изменение режима
потребления (дополнительный сигнал, введенный в PCI 2.2)
CLKRUN* Clock running — шина работает на номинальной частоте синхронизации. Снятие сигнала означает замедление или остановку синхронизации с целью снижения потребления (для мобильных применений)
PRSNT[1,2]# Present — индикаторы присутствия платы, кодирующие запрос потребляемой мощности. На карте расширения одна или две линии индикаторов соединяются с шиной GND, что воспринимается системной платой
RST# Reset — сброс всех регистров в начальное состояние
IDSEL Initialization Device Select — выбор устройства в циклах конфигурационного
считывания и записи
SERR# System Error — системная ошибка. Ошибка паритета адреса данных в специальном цикле или иная катастрофическая ошибка, обнаруженная устройством. Активизируется любым устройством PCI и вызывает NMI
REQ64* Request 64 bit — запрос на 64-битный обмен. Сигнал вводится 64-битным
инициатором, по времени он совпадает с сигналом FRAME*. Во время окончания сброса (сигналом RST*) сигнализирует 64-битному устройству о том, что оно подключено к 64-битной шине. Если 64-б. итное устройство не обнаружит этого сигнала, оно должно переконфигурироваться на 32-битный режим, отключив буферные схемы старших байтов
АСК64* Подтверждение 64-битного обмена. Сигнал вводится 64-битным ЦУ, опознавшим свой адрес, одновременно с DEVSEL*. Отсутствие этого подтверждения заставит инициатор выполнять обмен с 32-битной разрядностью
INTA#, INTB*, Interrupt А, В, С, D — линии запросов прерывания, чувствительность к уровню, INTC#, INTD* активный уровень — низкий, что допускает разделяемость (совместное использование)линий
CLK Clock — тактовая частота шины. Должна лежать в пределах 20—33 МГц,
вPCI2.1— до 66 МГц
M66EN 66MHz Enable — разрешение частоты синхронизации до 66 МГц
Сигнал Назначение
SDONE Snoop Done — сигнал завершенности цикла слежения для текущей транзакции. Низкий уровень указывает на незавершенность цикла слежения за когерентностью памяти и кэша. Необязательный сигнал, используется только устройствами шины с кэшируемой памятью
SBO# Snoop Backoff — попадание текущего обращения к памяти абонента шины
в модифицированную строку кэша. Необязательный сигнал, используется только абонентами шины с кэшируемой памятью при алгоритме обратной записи
ТСК Test Clock — синхронизация тестового интерфейса JTAG
TDI Test Data Input — входные данные тестового интерфейса JTAG
TOO Test Data Output — выходные данные тестового интерфейса JTAG
TMS Test Mode Select — выбор режима для тестового интерфейса JTAG
TRST Test Logic Reset — сброс тестовой логики
В каждый момент времени шиной может управлять только одно ведущее устройство, получившее на это право от арбитра. Каждое ведущее устройство имеет пару сигналов — REQ# для запроса на управление шиной и GNT* для подтверждения предоставления управления шиной. Устройство может начинать транзакцию (устанавливать сигнал FRAME*) только при активном полученном сигнале GNT*. Снятие сигнала GNT* не позволяет устройству начать следующую транзакцию, а при определенных условиях (см. ниже) заставляет прекратить начатую транзакцию. Арбитражем запросов на использование шины занимается специальный узел, входящий в чипсет системной платы. Схема приоритетов (фиксированный, циклический, комбинированный) определяется программированием арбитра.
Для адреса и данных используются общие мультиплексированные линии AD. Четыре мультиплексированные линии С/ВЕ[3:0] обеспечивают кодирование команд в фазе адреса и разрешения байт в фазе данных. В начале транзакции ведущее устройство активизирует сигнал FRAME*, по шине AD передает целевой адрес, а по линиям С/ВЕ# — информацию о типе транзакции (команде). Адресованное ЦУ отзывается сигналом DEVSEL*. Ведущее устройство указывает на свою готовность к обмену данными сигналом IRDY#, эта готовность может быть выставлена и раньше получения DEVSEL*. Когда к обмену данными будет готово и ЦУ, оно установит сигнал TRDY*. Данные по шине AD передаются только при одновременном наличии сигналов IRDY# и TRDY*. С помощью этих сигналов ведущее устройство и ЦУ согласуют свои скорости, вводя такты ожидания. На рис. 6.7 приведена временная диаграмма обмена, в которой и ведущее устройство, и ЦУ вводят такты ожидания. Если бы они оба ввели сигналы готовности в конце фазы адреса и не снимали их до конца обмена, то в каждом такте после фазы адреса передавались бы по 32 бита данных, что обеспечило бы выход на предельную производительность обмена.
Количество фаз данных в пакете явно не указывается, но перед последней фазой данных ведущее устройство при введенном сигнале IRDY* снимает сигнал FRAME*. В одиночных транзакциях сигнал FRAME* активен лишь один такт. Если устройство не поддерживает пакетные транзакции в ведомом режиме, то оно должно потребовать прекращения пакетной транзакции во время первой фазы данных (введя сигнал STOP* одновременно с TRDY*). В ответ на это ведущее устройство завершит данную транзакцию и продолжит обмен последующей транзакцией с новым значением адреса. После последней фазы данных ведущее устройство снимает сигнал IRDY#, и шина переходит в состояние покоя (PCI Idle) — оба сигнала FRAME* и IRDY# находятся в пассивном состоянии. Инициатор может начать следующую транзакцию и без такта покоя, введя FRAME* одновременно со снятием IRDY#. Такие быстрые смежные транзакции (Fast Back-to-Back) могут быть обращены как к одному, так и к разным ЦУ. Первый тип поддерживается всеми устройствами PCI, выступающими в роли ЦУ. На поддержку второго типа (она необязательна) указывает бит 7 регистра состояния (см. п. 6.2.12). Инициатору разрешают (если он умеет) использовать быстрые смежные транзакции с разными устройствами (битом 9 регистра команд), только если все агенты шины допускают быстрые обращения.
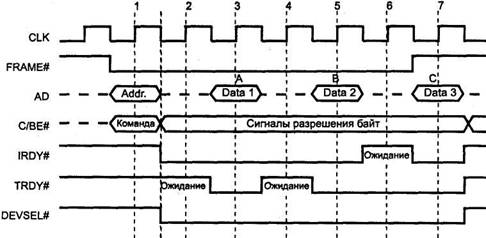
Рис. 6.7. Цикл обмена на шине PCI
Шина позволяет уменьшить мощность (ток), потребляемую устройствами, ценой снижения производительности, применяя пошаговое переключение линий AD[31:0] и PAR (address/data stepping). Здесь возможны два варианта.
♦ Плавный шаг (continuous stepping) — начало формирования сигналов слабо
точными формирователями за несколько тактов до введения сигнала-квалифи-
катора действительной информации (FRAME# в фазе адреса, IRDY# или TRDY# в фазе данных). За эти несколько тактов сигналы «доползут» до требуемого значения при меньшем токе.
♦ Дискретный шаг (diskrete stepping) — нормальные формирователи срабатывают не все сразу, а группами (например, побайтно), в каждом такте по группе. При этом снижаются броски тока, поскольку одновременно переключается меньше формирователей.
Устройство само может и не пользоваться этими возможностями (см. бит 7 регистра команд), но должно «понимать» такие циклы. Задерживая сигнал FRAME*, устройство рискует потерять право доступа к шине, если арбитр получит запрос от более приоритетного устройства.
Протокол квитирования обеспечивает надежность обмена — ведущее устройство всегда получает информацию об отработке транзакции ЦУ. Средством повышения надежности (достоверности) является применение контроля паритета: линии AD[31:0] и С/ВЕ[3:0]# и в фазе адреса, и в фазе данных защищены битом паритета PAR (количество единичных бит этих линий, включая PAR, должно быть четным). Действительное значение PAR появляется на шине с задержкой в один такт относительно линий AD и С/ВЕ#. При обнаружении ошибки ЦУ вырабатывается сигнал PERR* (со сдвигом на такт после действительности бита паритета). В подсчете паритета при передаче данных учитываются все байты, включая и недействительные (отмеченные высоким уровнем сигнала С/ВЕх#). Состояние бит, даже и в недействительных байтах данных, во время фазы данных должно оставаться стабильным.
Каждая транзакция на шине должна быть завершена планово или прекращена, при этом шина должна перейти в состояние покоя (сигналы FRAME* и IRDY# пассивны). Завершение транзакции выполняется либо по инициативе ведущего устройства, либо по инициативе ПУ. Ведущее устройство может завершить транзакцию одним из следующих способов.
♦ Нормальное завершение ( Camletiori) выполняется по окончании обмена данными.
♦ Завершение по тайм-ауту (Time-out) происходит, когда во время транзакции у ведущего устройства отбирают право на управление шиной (снятием сигнала GNT#) и истекает время, указанное в его таймере Latency Timer. Это может случиться, если адресованное ЦУ оказалось непредвиденно медленным или запланирована слишком длинная транзакция. Короткие транзакции (с одной - двумя фазами данных) даже в случае снятия сигнала GNT# и срабатывания таймера завершаются нормально. Транзакция отвергается (Master-Abort), когда в течение заданного времени ведущее устройство не получает ответа ЦУ (DEVSEL*).
Транзакция может быть прекращена по инициативе ЦУ; для этого оно может ввести сигнал STOP*. Возможны три типа прекращения.
♦ Повтор (Retry) — сигнал STOP* вводится при пассивном сигнале TRDY* до первой фазы данных. Эта ситуация возникает, когда ЦУ из-за внутренней занятости не успевает выдать первые данные в положенный срок (16 тактов). Повтор является указанием ведущему устройству на необходимость нового запуска той же транзакции.
♦ Отключение (Disconnect) — сигнал STOP* вводится во время или после первой фазы данных. Если сигнал STOP* введен при активном сигнале TRDY* очередной фазы данных, то эти данные передаются и на том транзакция завершается. Если сигнал STOP* введен при пассивном сигнале TRDY*, то транзакция завершается без передачи данных очередной фазы. Отключение производится, когда ЦУ неспособно своевременно выдать или принять очередную порцию данных пакета.
♦ Отказ (Target-Abort) — сигнал STOP* вводится одновременно со снятием сигнала DEVSEL* (в предыдущих случаях во время появление сигнала STOP* сигнал DEVSEL* был активен). После этого данные уже не передаются. Отказ вводится, когда ЦУ обнаруживает фатальную ошибку или иные условия, по которым оно уже никак не сможет обслужить данный запрос. Использование трех типов прекращения вовсе не обязательно для всех ЦУ, однако любое ведущее устройство должно быть готово к завершению транзакций по любой из этих причин
40.Адресация устройств PCI
Для шины PCI принята иерархия понятий адресации: шина, устройство, функция. Эти понятия фигурируют только при обращении к регистрам конфигурационного пространства (см. п. 6.2.12). К этим регистрам обращаются на этапе конфигурирования — переучета обнаруженных устройств, выделения им непересекающихся ресурсов (областей памяти и пространства ввода-вывода) и назначения номеров аппаратных прерываний. При дальнейшей регулярной работе устройства будут отзываться на обращения по назначенным им адресам памяти и ввода-вывода, доведенным до сведения связанных с ними модулей ПО. Эти адреса принимаются с шины AD в начале каждой транзакции. Для доступа к конфигурационному пространству используются отдельные линии IDSEL
Устройством PCI называется микросхема или карта расширения, подключенная к одной из шин PCI и использующая для идентификации выделенную ей линию IDSEL, принадлежащую этой шине. Устройство может быть многофункциональным, то есть состоять из множества (от 1 до 8) так называемых функций. Каждой функции отводится конфигурационное пространство в 256 байт (см. п. 6.2.12). Многофункциональные устройства должны отзываться только на конфигурационные циклы с номерами функций, для которых имеется конфигурационное пространство. При этом функция с номером 0 должна быть обязательно, номера остальных функций назначаются разработчиком устройства произвольно (в диапазоне 1-7). Простые (однофункциональные) устройства, в зависимости от реализации, могут отзываться либо на любой номер функции, либо только на номер функции 0.
Шина PCI — набор сигнальных линий (см. п. 6.2.2), непосредственно соединяющих интерфейсные выводы группы устройств (слотов, микросхем на системной плате). В системе может присутствовать несколько шин PCI, соединенных мостами PCI (см. п. 6,2.10). Мосты электрически отделяют интерфейсные сигналы одной шины от другой, соединяя их логически; главный мост соединяет главную шину с ядром системы (процессором и памятью). Каждая шина имеет свой номер шины (PCI bus number). Шины нумеруются последовательно; главная шина имеет нулевой номер.
С точки зрения конфигурирования, минимальной адресуемой единицей этой иерархии является функция; ее полный адрес состоит из трех частей: номера шины, номера устройства и номера функции. Короткая форма идентификации вида РСЮ:1:2 (например, в сообщениях ОС Unix) означает функцию 2 устройства 1, подключенного к главной (0) шине PCI.
В шине PCI принята географическая адресация — номер устройства определяется местом его подключения. Номер устройства (device number или dev) определяется той линией шины AD, к которой подключена линия сигнала IDSEL данного слота: kADU - devO(MOCT),AD12-devl,...AD31 - dev20. В соседних слотах PCI, как правило, задействуются соседние номера устройств; их нумерация определяется разработчиком системной платы (или пассивной кросс-платы в промышленных компьютерах). Часто для слотов используются убывающие номера устройств, начиная с 20. Группы соседних слотов могут подключаться к разным шинам; на каждой шине PCI нумерация устройств независимая (могут быть и устройства с совпадающими номерами dev, но разными номерами шин). Устройства PCI, интегрированные в системную плату, используют ту же систему адресации. Их номера «запаяны намертво», в то время как адреса карт расширения можно изменять перестановкой их в разные слоты. Одна карта PCI может содержать только одно устройство шины, к которой она подключается, поскольку ей в слоте выделяется только одна линия IDSEL Если на карте размещают несколько устройств (например, 4-портовая карта Ethernet), то на ней приходится устанавливать мост — тоже устройство PCI, к которому и обращаются по линии IDSEL, выделенной данной карте. Этот мост организует на карте дополнительную шину PCI, к которой можно подключить множество устройств.
С точки зрения обращения к пространствам памяти и ввода-вывода, географический адрес (номер шины и устройства) безразличен (не принимая во внимание разницу в производительности, связанную с подключением устройств к разным шинам PCI). Однако номер устройства определяет номер линии запроса прерывания, которой может пользоваться устройство. Подробнее об этом см. в п. 6.2.6, здесь же отметим, что на одной шине устройства с номерами, отличающимися друг от друга на 4, будут использовать одну и ту же линию прерывания. Возможность развести их по разным линиям прерывания может появиться лишь, если они находятся на разных шинах (это зависит от системной платы).
Разобраться с нумерацией устройств и полученных ими линий прерываний на конкретной плате можно просто: устанавливать одну карту PCI поочередно в каждый из слотов (отключая питание) и смотреть на сообщения об обнаруженных устройствах PCI, выводимых на дисплей в конце теста POST. В этих сообщениях будут фигурировать и устройства PCI, установленные непосредственно на системной плате (и не отключенные параметрами CMOS Setup).
Но чтобы не было иллюзий простоты и прозрачности, отметим, что «особо умные» операционные системы (Windows) не довольствуются полученными назначениями номеров прерывании и изменяют их по своему усмотрению (что никак не может отразиться на разделяемости линий).
В шине PCI принята географическая адресация — номер устройства определяется местом его подключения. Номер устройства (device number или dev) определяется той линией шины AD, к которой подключена линия сигнала IDSEL данного слота: kADU - devO(MOCT),AD12-devl,...AD31 - dev20. В соседних слотах PCI, как правило, задействуются соседние номера устройств; их нумерация определяется разработчиком системной платы (или пассивной кросс-платы в промышленных компьютерах). Часто для слотов используются убывающие номера устройств, начиная с 20. Группы соседних слотов могут подключаться к разным шинам; на каждой шине PCI нумерация устройств независимая (могут быть и устройства с совпадающими номерами dev, но разными номерами шин). Устройства PCI, интегрированные в системную плату, используют ту же систему адресации. Их номера «запаяны намертво», в то время как адреса карт расширения можно изменять перестановкой их в разные слоты. Одна карта PCI может содержать только одно устройство шины, к которой она подключается, поскольку ей в слоте выделяется только одна линия IDSEL Если на карте размещают несколько устройств (например, 4-портовая карта Ethernet), то на ней приходится устанавливать мост — тоже устройство PCI, к которому и обращаются по линии IDSEL, выделенной данной карте. Этот мост организует на карте дополнительную шину PCI, к которой можно подключить множество устройств.
С точки зрения обращения к пространствам памяти и ввода-вывода, географический адрес (номер шины и устройства) безразличен (не принимая во внимание разницу в производительности, связанную с подключением устройств к разным шинам PCI). Однако номер устройства определяет номер линии запроса прерывания, которой может пользоваться устройство. Подробнее об этом см. в п. 6.2.6, здесь же отметим, что на одной шине устройства с номерами, отличающимися друг от друга на 4, будут использовать одну и ту же линию прерывания. Возможность развести их по разным линиям прерывания может появиться лишь, если они находятся на разных шинах (это зависит от системной платы).
Разобраться с нумерацией устройств и полученных ими линий прерываний на конкретной плате можно просто: устанавливать одну карту PCI поочередно в каждый из слотов (отключая питание) и смотреть на сообщения об обнаруженных устройствах PCI, выводимых на дисплей в конце теста POST. В этих сообщениях будут фигурировать и устройства PCI, установленные непосредственно на системной плате (и не отключенные параметрами CMOS Setup).
Но чтобы не было иллюзий простоты и прозрачности, отметим, что «особо умные» операционные системы (Windows) не довольствуются полученными назначениями номеров прерывании и изменяют их по своему усмотрению (что никак не может отразиться на разделяемости линий).
41.Команды шины PCI
Команды шины PCI определяются значениями бит С/ВЕ# в фазе адреса (табл. 6.12).
♦ Команда подтверждения прерывания предназначена для чтения вектора пре
рываний. По протоколу она выглядит как команда чтения, неявно адресован
ная к системному контроллеру прерываний. Здесь в фазе адреса по шине AD полезная информация не передается, но ее инициатор (главный мост) должен обеспечить стабильность сигналов и корректность паритета. В PC 8-битный вектор передается в байте 0 по готовности контроллера прерываний (по сигналу TRDY#). Подтверждение прерываний выполняется за один цикл (первый холостой цикл, который процессоры х86 делают в дань совместимости со стариной, мостом подавляется).
♦ Специальный цикл отличается от всех других тем, что является широковеща
тельным. Однако ни один агент на него не отвечает, а главный мост или иное
устройство, вводящее этот цикл, всегда завершает его способом Master Abort (на него требуется 6 тактов шины). Специальный цикл предназначен для генерации широковещательных сообщений — их могут читать любые «заинтересованные» агенты шины. Тип сообщения декодируется содержимым линий AD[15:0], на линиях AD[31:16] могут помещаться данные, передаваемые в сообщении. Фаза адреса в этом цикле для обычных устройств отсутствует, но мосты используют ее информацию для управления распространением сообщения. Сообщения с кодами OOOOh, 000lh и 0002h требуются для указания на отключение (Shutdown), остановку (Halt) процессора или специфические функции процессора х8б, связанные с кэшем и трассировкой. Коды 0003-FFFFh зарезервированы. Специальный цикл может генерироваться тем же аппаратно-программным механизмом, что и конфигурационные циклы (см. п. 6.2.11),но со специфическим значением адреса.
♦ Команды чтения и записи ввода-вывода служат для обращения к пространству
портов. Линии AD содержат адрес байта, причем декодированию подлежат и биты ADO и AD1 (несмотря на то, что имеются сигналы ВЕх#). Порты PCI могут быть 16- или 32-битными. Для адресации портов на шине PCI доступны все 32 бита адреса, но процессоры х86 могут использовать только младшие 16 бит.
♦ Команды обращения к памяти, кроме обычного чтения и записи, включают чте
ние строк кэш-памяти, множественное чтение (нескольких строк), запись с ин-
валидацией.
♦ Команды конфигурационного чтения и записи адресуются к конфигурационному
пространству устройств (см. п. 6.2.12). Обращение производится только двойными словами. Структура содержит идентификатор устройства и производите для, состояние и команду, информацию о занимаемых ресурсах и ограничения на использование шины. Для генерации данных команд требуется специальный аппаратно-программный механизм (см. п. 6.2.11).
♦ Чтение строк памяти применяется, когда в транзакции планируется более двух
32-битных передач (обычно это чтение до конца строки кэша).
♦ Множественное чтение памяти используется для транзакций, пересекающих
границы строк кэш-памяти.
♦ Запись с инвалидацией применяется к целым строкам кэша и позволяет оптимизировать циклы обратной записи «грязных» строк кэша.
♦ Двухадресный цикл позволяет по 32-битной шине обращаться к устройствам с 64-битной адресацией. В этом случае младшие 32 бита адреса передаются в цикле данного типа, а за ним следует обычный цикл, определяющий тип обмена и несущий старшие 32 бита адреса. Шина PCI допускает 64-битную адресацию портов ввода-вывода (для х86 это бесполезно, но PCI существует и на других платформах).
42.Прерывания в интерфейсе PCI
В PC-совместимых компьютерах прерывания от устройств PCI обслуживаются с помощью традиционной связки пары контроллеров 8259А, расположенных на системной плате (см. п. 12.4), к которым обращается команда «подтверждение прерывания». Прерывания на шине PCI свободны от одной из нелепостей системы прерываний ISA. Устройство PCI вводит сигнал прерывания низким уровнем (выходом с открытым коллектором или стоком) на выбранную линию INTA#, INTB#, INTC# или INTD*. Этот сигнал должен удерживаться до тех пор, пока программный драйвер, вызванный по прерыванию, не сбросит запрос прерывания, обратившись по шине к данному устройству. Если после этого контроллер прерываний снова обнаруживает низкий уровень на линии запроса, это означает, что запрос на ту же линию ввело другое устройство, разделяющее данную линию с первым, и оно тоже требует обслуживания. Линии запросов от слотов PCI и PCI-устройств системной платы коммутируются на входы контроллеров прерываний относительно произвольно. Конфигурационное ПО может определить и указать занятые линии запросов и номер входа контроллера прерываний обращением к конфигурационному пространству устройства (см. п. 6.2.12). Программный драйвер, прочитав конфигурационные регистры, тоже может определить эти параметры для того, чтобы установить обработчик прерываний на нужный вектор и при обслуживании сбрасывать запрос с требуемой линии. К сожалению, в конфигурационных регистрах не нашлось стандартного места для бита, индицирующего введение запроса прерывания данным устройством, — тогда бы в прерываниях для PCI не было бы проблем с унификацией поддержки разделяемых прерываний.
Каждая функция устройства PCI может задействовать свою линию запроса прерывания, но должно быть готовым к ее разделению (совместному использованию) с другими устройствами. Если устройству требуется только одна линия запроса, то оно должно занимать линию INTA#, если две — INTA# и INTB#, и так далее. С учетом циклического сдвига линий запроса это правило позволяет установить в 4 сосед - них слота 4 простых устройства, и каждое из них будет занимать отдельную линию запроса прерывания. Если какой-то карте требуется две линии, то для монопольного использования прерываний нужно оставить соседний слот свободным. PCI-устройства системной платы тоже задействуют прерывания с той же закономерностью (кроме контроллера IDE, который, к счастью, держится особняком).
Назначение прерываний устройствам (функциям) выполняет процедура POST, и этот процесс управляем лишь частично. Параметрами CMOS Setup (PCI/PNP Configuration) пользователь определяет номера запросов прерываний, доступных шине PCI. В зависимости от версии BIOS это может выглядеть по-разному: либо каждой линии INTA#...INTD# явно назначается свой номер, либо ряд номеров отдается «на откуп» устройствам PCI вместе с устройствами ISA PnP (в противоположность устройствам «Legacy ISA»). В итоге POST определяет соответствие линий INTA#...INTD# номерам запросов контроллера и соответствующим образом программирует коммутатор запросов. По воле пользователя может оказаться так, что не каждой линии запроса шины PCI достается отдельный вход контроллера прерываний. Тогда коммутатор организует объединение нескольких линий запросов PCI на один вход контроллера, то есть разделяемые прерывания. В самом худшем случае устройствам PCI не достанется ни одного входа контроллера прерываний. Заметим, что BIOS вряд ли отдаст шине PCI прерывания 14 и 15 (их забирает контроллер IDE, если он не отключен), а также 3 и 4 (СОМ-порты).
Драйвер (или иное ПО), работающий с устройством PCI, определяет вектор прерывания, доставшийся устройству (точнее, функции), чтением конфигурационного регистра Interrupt Line. В этом регистре указывается номер входа контроллера прерывания (255 — номер не назначен), и по нему определяется вектор (см. п. 12.4). Номер входа каждому устройству заносит тест POST. Для этого он считывает регистр Interrupt Pin каждой обнаруженной функции и по адресу устройства (!) определяет, какая из линий (РС1_И...РС1_4) используется. Заметим, что правила, по которым на системной плате определяется соответствие между Interrupt Pin и входными линиями коммутатора запросов в зависимости от номера устройства, строго не регламентированы (деление номера устройства на 4 — это всего лишь рекомендация), но их твердо знает версия BIOS данной системной платы. К этому моменту тест POST уже определил таблицу соответствия этих линий номерам входов; пользуясь этой таблицей, он записывает нужное значение в конфигурационный регистр Interrupt Line. Определить, есть ли еще претенденты на тот же номер прерывания, можно, лишь просмотрев конфигурационные регистры функций всех устройств, обнаруженных на шине (это не так уж сложно сделать, пользуясь функциями PCI BIOS).
Спасением от бед «разделяемости» может быть перестановка карт в подходящий слот. Однако попадаются «подарки разработчиков» интегрированных плат, у которых из нескольких слотов PCI неразделяемая линия прерывания есть только у одного (а то и нет вообще). Такие недуги без скальпеля и паяльника, как правило, не лечатся.
На шине PCI имеется и иной механизм оповещения об асинхронных событиях, основанный на передаче сообщений (PCI Message-Based Interrupts). Для сигнализации запроса прерывания устройство запрашивает управление шиной и, получив его, выполняет запись номера прерывания по заранее оговоренному адресу Этот механизм может использоваться на системных платах, имеющих «продвинутый» контроллер прерываний APIC. Запись номера запроса производится в соответствующий регистр APIC. Для системных плат на чипсете с хабом ICH2 82801 этот регистр находится по адресу памяти FEC00020h, а номер прерывания может быть в диапазоне 0-23L Однако одновременно оба механизма работать не могут; если разрешена работа APIC, то логика контроллеров 8259 не используется, и наоборот
43. Эволюция интерфейса ATA
Предварительное название интерфейса было PC/AT Attachment ("Соединение с PC/AT"), так как он предназначался для подсоединения к 16-битной шине ISA, известной тогда как шина AT. В окончательной версии название переделали в «AT Attachment» для избежания проблем с торговыми марками.
Первоначальная версия стандарта была разработана в 1986 году фирмой Western Digital и по маркетинговым соображениям получила название IDE (Integrated Drive Electronics, «Электроника, встроенная в привод»). Оно подчеркивало важное нововведение: контроллер привода располагается в нём самом, а не в виде отдельной платы расширения, как в предшествующем стандарте ST-506 и существовавших тогда интерфейсах SCSI и ST412. Это позволило а)улучшить характеристики накопителей (засчет меньшего расстояния до контроллера), б)упростить управление им (т. к. контроллер канала IDE абстрагировался от деталей работы привода) и в)удешевить производство (контроллер привода мог быть рассчитан только на "свой" привод, а не на все возможные; контроллер канала же вообще становился стандартным). Следует отметить, что контроллер канала IDE правильнее называть хост-адаптером, поскольку он перешел от прямого управления приводом к обмену данными с ним по протоколу.
В стандарт АТА определен интерфейс между контроллером и накопителем, а также передаваемые по нему команды.
Интерфейс имеет 8 регистров, занимающих 8 адресов в пространстве ввода-вывода. Ширина шины данных составляет 16 бит. Количество каналов, присутствующих в системе, может быть больше 2. Главное, чтобы адреса каналов не пересекались с адресами других устройств ввода-вывода. К каждому каналу можно подключить 2 устройства (master и slave), но в каждый момент времени может работать лишь одно устройство. Принцип адресации CHS заложен в названии. Сперва блок головок устанавливается позиционером на требуемую дорожку (Cylinder), после этого выбирается требуемая головка (Head), а затем считывается информация из требуемого сектора (Sector).
Стандарт EIDE (Enhanced IDE, т. е. «расширенный IDE»), появившийся вслед за IDE, позволял использование приводов ёмкостью, превышающей 528 МБ (504 МиБ), вплоть до 8,4 ГБ. Хотя эти аббревиатуры возникли как торговые, а не официальные названия стандарта, термины IDE и EIDE часто употребляются вместо термина ATA. После введения в 2003 году стандарта Serial ATA («Последовательный ATA»), традиционный ATA стали именовать Parallel ATA, имея в виду способ передачи данных по 40-жильному кабелю.
Поначалу этот интерфейс использовался с жёсткими дисками, но затем стандарт был расширен для работы и с другими устройствами, в основном — использующими сменные носители. К числу таких устройств относятся приводы CD-ROM и DVD-ROM, ленточные накопители, а также дискеты большой ёмкости, такие, как ZIP и магнитооптические диски (LS-120/240). Этот расширенный стандарт получил название Advanced Technology Attachment Packet Interface (ATAPI), в связи с чем полное наименование стандарта выглядит как ATA/ATAPI.
Первоначальные расширения ATA для работы с приводами CD-ROM не обладали полной совместимостью, являлись фирменными. В результате, для подключения CD-ROM было необходимо устанавливать отдельную плату расширения, специфичную для конкретного производителя, например для Panasonic (существовало не менее 5 специфичных вариантов ATA, предназначенных для подключения CD-ROM). Некоторые варианты звуковых карт, например Sound Blaster, оснащались именно такими портами.
Другим важным этапом в развитии ATA стал переход от PIO (Programmed input/output, Программный ввод/вывод) к DMA (Direct memory access, Прямой доступ к памяти). При использовании PIO считыванием данных с диска управлял центральный процессор компьютера (CPU), что приводило к повышенной нагрузке на процессор и замедлению работы в целом. По причине этого компьютеры, использующие интерфейс ATA, обычно выполняли операции, связанные с диском, медленнее, чем компьютеры, использующие SCSI и другие интерфейсы. Введение DMA существенно снизило затраты процессорного времени на операции с диском. В данной технологии потоком данных управляет сам накопитель, считывая даные в память или из памяти почти без участия CPU, который выдает лишь команды на выполнение того или иного действия. При этом жесткий диск выдает сигнал запроса DMARQ на операцию DMA контроллеру. Если операция DMA возможна, контроллер выдает сигнал DMACK и жесткий диск начинает выдавать данные в 1-й регистр (DATA), с которого контроллер считывает данные в память без участия процессора. Операция DMA возможна, если режим поддерживается одновременно BIOS, контроллером и операционной системой, в противном случае возможен лишь режим PIO.
В дальнейшем развитии стандарта (АТА-3) был введен дополнительный режим UltraDMA 2 (UDMA 33). Этот режим имеет временные характеристики DMA Mode 2, однако данные передаются и по переднему, и по заднему фронту сигнала DIOR/DIOW. Это вдвое увеличивает скорость передачи данных по интерфейсу. Также введена проверка на четность CRC, что повышает надёжность передачи информации.
В истории развития ATA был ряд барьеров, связанных с организацией доступа к данным. Большинство из этих барьеров, благодаря современным системам адресации и технике программирования, были преодолены. К их числу относятся ограничения на максимальным размер диска в 504 МиБ, ~8 ГиБ, ~32 ГиБ, и 128 ГиБ. Существовали и другие барьеры, в основном связанные с драйверами устройств, и организацией ввода/вывода в операционных системах, не соответствующих стандартам ATA.
Оригинальная спецификация АТА предусматривала 28-битный режим адресации. Это позволяло адресовать ) секторов по 512 байт каждый, что давало максимальную ёмкость в 137 ГБ (128 ГиБ). В стандартных PC BIOS поддерживал до 7,88 ГиБ (8,46 ГБ), допуская максимум 1024 цилиндра, 256 головок и 63 сектора. Это ограничение на число цилиндров/головок/секторов CHS (Cyllinder-Head-Sector) в сочетании со стандартом IDE привело к ограничению адресуемого пространства в 504 МиБ (528 МБ). Для преодоления этого ограничения была введена схема адресации LBA (Logical Block Address), что позволило адресовать до 7,88 ГиБ. Со временем и это ограничение было снято, что позволило адресовать сначала 32 ГиБ, а затем и все 128 ГиБ, используя все 28 разрядов (в АТА-4) для адресации сектора. Запись 28-битного числа, организована путем записи его частей в соответствующие регистры накопителя (с 1 по 8 бит в 4-й регистр, 9-16 в 5-й, 17-24 в 6-й и 25-28 в 7-й).
Адресация регистров организована при помощи трех адресных линий DA0-DA2. 1-й регистр с адресом 0 является 16-разрядный, и используется для передачи данных между диском и контроллером. Остальные регистры 8-битные и используются для управления.
Новейшие спецификации ATA предполагают 48-битную адресацию, расширяя таким образом возможный предел до 128 ПиБ (144 петабайт). Однако файловые системы большинства современных операционных систем поддерживают диски объёмом лишь до 2 ТиБ.
Эти ограничения на размер могут проявляться в том, что система думает, что объём диска меньше его реального значения, или вовсе отказывается загружаться и виснет на стадии инициализации жёстких дисков. В некоторых случаях проблему удаётся решить обновлением BIOS. Другим возможным решением является использование специальных программ, таких, как Ontrack DiskManager, загружающих в память свой драйвер до загрузки операционной системы. Недостатком таких решений является то, что используется нестандартная разбивка диска, при которой разделы диска оказываются недоступны, в случае загрузки, например, с обычной DOS-овской загрузочной дискеты. Впрочем, многие современные операционные системы (начиная от Windows NT4 SP3) могут работать с дисками большего размера, даже если BIOS компьютера этот размер корректно не определяет).
44. Назначение контактов разъема IDE
45. Прием и передача данных хостом в режиме PI

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
