
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
22. Виды доступа в INTERNET. Доступ по вызову, UUCP, доступ через другие сети.
Виды доступа отличаются схемами подключения, используемыми линиями связи и протоколами, которые, в конечном счёте, и определяют предоставляемые возможности. Чем больше возможностей предоставляет вид доступа и чем более он быстр, тем, естественно, он более дорог.
Dialup
Вы становитесь пользователем, какой-нибудь большой машины (получаете логическое имя, доступ к системе и права пользователя на работу), которая имеет прямой или хотя бы РРР доступ в Сеть и допускает подключение удалённого терминала по телефонной линии (по модемному протоколу). Теперь вы просто используете свой домашний компьютер (модем) для удалённого входа в эту машину по телефонным линиям связи и уже на ней работаете в сети. Такой вид доступа называется dial-up ("по звонку" или "по вызову").
Доступ по вызову почти так же хорош, как и собственное подключение, и он существенно проще и дешевле. В этом случае компьютер клиента на самом деле вообще не подключается к сети, он просто работает как терминал другой ЭВМ, которая подключена к Сети. Одна такая ЭВМ может одновременно иметь огромное количество пользователей и все будут удовлетворены.
Если провайдер достаточно умён, он будет стараться предоставить вам максимальное количество услуг и для этого установит на своём сетевом компьютере всё, что сможет — тогда большее количество клиентов будет привлечено на один и тот же компьютер и они будут дольше работать, что означает, при тех же вложениях он будет получать большую отдачу, а значит и большую прибыль.
Доступ UUCP
Все системы UNIX поддерживают сервис, называемый UUCP, который позволяет пересылать данные по стандартным телефонным линиям. UUCP — это UNIX to UNIX Copy Program — программа копирования с UNIX на UNIX. Изначально эта программа, сама реализующая все операции по передаче данных без использования стандартных протоколов, кроме модемных, использовалась только для связи компьютеров, работающих под управлением систем типа UNIX.
Однако, позже аналогичные программы, использующие те же методы передачи и, таким образом, реализующие работу по тому же "UUCP-протоколу", были созданы и для многих других операционных систем, что позволило передавать данные между различными системами.
В??? изначально заложена возможность использования UUCP для доставки почты, для этого даже создан специальный тип компьютерных имён, не имеющих соответствующего IР-адреса. Письмо, отправленное в такой адрес, идёт по QvUrtel средствами протоколов семейства TCP/IP до некоторого сетевого компьютера, который далее переправляет его конечному получателю средствами UUCP, возможно даже не прямо, а опосредованно - через цепочку компьютеров, общающихся друг с другом посредством этого протокола.
Поэтому можно пользоваться электронной почтой, не имея вообще доступа к сетевому компьютеру, ни непосредственно, ни по SLIP/PPP, ни посредством Dial-Up.
При таком виде доступа, как явствует из приведённого выше описания, ваша система использует UUCP, чтобы связываться с удалённой системой и пересылать вашу почту и ваши послания в телеконференции, а также получать пришедшую вам почту и послания других участников телеконференций, в которых вы участвуете.
К Internet вы подключения не имеете, просто ваш компьютер названивает другому, который подключён к Internet и обменивается с ним файлами.
UUCP-доступ пользуется огромной популярностью, поскольку он достаточно дешев и доступен, для него требуется лишь программа поддержки протокола UUCP и модем. UNIX совсем необязателен, но если вы на своей домашней персоналке используете именно UNIX, то вам вообще ничего кроме модема не нужно.
Доступ через другие сети
Сейчас каждая сеть стремится подключиться к Internet. Однако, не все технологии допускают полное подключение. Разные сети, подключённые к Internet в разной степени интегрированы в неё. Большинство сетей, таких как FIDOnet или BITnet, имеют специальные сетевые почтовые шлюзы и маршрутизаторы, обеспечивающие обмен электронной почтой между этими системами и Internet. Все эти службы относятся к базовым средствам сети Internet.
23. Основные программы поиска ресурсов сети INTERNET. Информационно –поисковая система Google. Понятие Page Rank/
PageRank
В 1998 году два студента Стэндфордского университета Сергей Брин и Ларри Пэйдж уже получили признание. PageRank, используемая в Google в основном основана на link popularity. Т. е. при вычислении релевантности страницы наибольший вклад имеет количество и качество ссылок на страницы с других страниц. Сейчас link popularity используется во всех основных поисковых системах мира (в той или иной степени). Кстати, в русскоязычных поисковых системах также используется этот параметр, например, в Яндекс, этот параметр называется индекс цитирования.
Google добился успеха благодаря этой технологии. Его трафик устойчиво увеличивается за последние 2 года. В июне 2000 г., такой Интернет-гигант, как Yahoo!, выбрал Google, как поставщика результатов поиска, вместо Inktomi.
Название поисковой системы Google было образовано в результате игры букв в слове "googol". Этим компания хочет подчеркнуть их намерение индексировать и обрабатывать большие объемы информации.
Размер страниц. По заявлению Google, на данный момент их база данных насчитывает более 1,346,966,000 проиндексированных
Международная поддержка. Вы можете искать в Google на 10 различных языках. Вы также можете настроить интерфейс на нужный вам язык. Например, если вы ищите немецкий сайт, то вы можете вводить запрос на немецком языке, и все вспомогательные надписи интерфейса будут на немецком языке. Посмотреть список доступных языков вы можете здесь.
Отличительные особенности. Очень удобной функцией является "cache". Благодаря этой функцией пользователь может просмотреть проиндексированную страницу, даже если эта страница удалена или сервер, на котором расположена страница, недоступен. Вы также можете использовать эту функцию для исследования ваших конкурентов, это также помогает лучше понять принцип индексирования страницы поисковым пауком (роботом).
С помощью Google можно найти страницы, которые не содержаться в его базе данных. Это возможно, потому что поисковый паук индексирует текст ссылок со страниц.
Как известно, статус сайта в Интернете измеряется в двух величинах: Яндекс тИЦ и Google PageRank. Про первую есть отдельная статья, а вот с тем, что за зверь такой - Google PageRank - мы сейчас постараемся разобраться.
Прежде всего, стоит сказать, что PR высчитывается по достаточно сложному алгоритму, который, как и в случае с тИЦ, известен только работникам самого поисковика, в нашем случае - Google - крупнейшей и популярнейшей поисковой машины в мире.
Основная задача поисковой машины, как известно, не просто найти все страницы, содержащие нужную информацию, а упорядочить найденные документы так, чтобы наиболее полезная информация отображалась выше, чем менее важная. К тому же те алгоритмы ранжирования, которые были разработаны для коллекций документов, используемых поисковиками при поиске, оказались беззащитны перед простейшими способами воздействия на них, когда для обеспечения хорошего результата достаточно было просто скопировать порядок расположения ключевых слов из текста, хорошо ранжируемого по этому запросу документа. Появилась необходимость разделять информацию на более и менее достоверную, учитывать важность, авторитетность и уникальность данных на ресурсах, предоставляющих ее. Остаётся выбрать оптимальный способ для этого. Лучше всего на основе данных о популярности страницы у пользователей, например посещаемости. Но тогда потребуется устанавливать какой-либо счетчик на каждую страницу (А именно так и сделал, к примеру, Rambler со своим счётчиком Rambler top100). Такой вариант для глобального поиска не подходит - всё-таки Рамблер - это исключение из правила. Тогда в качестве критерия была выбрана теоретическая посещаемость страницы.
Была разработана модель, эмулирующая движение пользователя по документам сети путем перехода по ссылкам с документа на документ, подразумевающая, что пользователь с равной долей вероятности перейдет по любой из ссылок, содержащихся в документе, который он в данный момент просматривает. То есть вероятность пользователя попасть на конкретный документ зависит от количества ссылок на него с других документов и от того, насколько вероятно нахождение пользователя на одном из ссылающихся документов и сколько уникальных исходящих ссылок содержит этот ссылающийся документ. Именно эта вероятность и была принята за показатель авторитетности или ранг страницы (PageRank):
PR a = (1-d) + d * ([Сумма от i=1 до n] PRi/Ci), где
PR a – PageRank рассматриваемой страницы,
d – коэффициент затухания (означает вероятность того, что пользователь, зашедший на страницу, перейдет по одной из ссылок, содержащейся на этой странице, а не прекратит путешествие по сети, обычно устанавливается равным 0,85),
PR i – PageRank i-й страницы, ссылающейся на страницу a,
C i – общее чисто ссылок на i-й странице.
Одним из самых распространенных заблуждений, связанных с PageRank является то, что можно вычислить PageRank по этой формуле для отдельно взятого документа, используя уже известные значения PageRank для документов, ссылающихся на него. На самом деле всё намного сложнее. Чтобы подсчитать PageRank одного документа, надо составить систему из N линейных уравнений данного вида для каждого из документов из поисковой базы, где число N – количество документов в поисковой базе. Эта система будет содержать N неизвестных. Решив ее, получим значения PageRank для каждого документа, известного поисковой машине. В поисковой базе крупнейших поисковых машин содержится огромнейшее число документов. Несмотря на то, что матрица, соответствующая системе уравнений будет сильно разряжена, численное решение этой системы требует огромных вычислительных мощностей. Поэтому поисковая система должна постараться максимально упростить процесс расчета, вводя некоторые допущения. Вот эти конкретные особенности реализации классической формулы PageRank, увы, составляют коммерческую тайну поисковых машин.
Возникает логичный вопрос: "А как узнать свой PageRank или PageRank какого-либо сайта? Узнать PageRank можно с помощью Google Toolbar - надстройки для браузера от крупнейшего мирового поисковика.
Ange1's fall - специально для . ru
Основная статья: PageRank
Google использует алгоритм расчёта авторитетности PageRank. PageRank является одним из вспомогательных факторов приранжировании сайтов в результатах поиска. PageRank не единственный, но очень важный способ определения положения сайта в результатах поиска Google. Google использует показатель PageRank найденных по запросу страниц, чтобы определить порядок выдачи этих страниц посетителю в результатах поиска.
24. Основные программы поиска ресурсов сети INTERNET. Информационно –поисковая система Яndex. Понятие ТиЦ.
www. ***** - текстовая версия
На сегодняшний день имеет самую большую базу данных, которая имеет кластерную структуру и размещена на нескольких серверах.
В 1996 году компанией CompTek, созданной со стопроцентным американским участием, на выставке Internetcom было официально объявлено о существовании "Яндекса". Это была морфологическая приставка к "Альтависте", которую отличало быстродействие и умение строить гипотезы. Пословный индекс для незнакомых слов организован также, как и для словарных - этим "Яндекс" отличается от других поисковиков.
23 сентября 1997 года "Яндекс" стал интернет-проектом. Релевантность документов вычислялась в зависимости от частотных характеристик искомых слов, веса слова или выражения, близости искомых слов в тексте документа друг к другу и так далее. В октябре 1999 года в интервью "ИнфоБизнесу" Аркадий Волож указал: "Финансирование "Яндекса" всегда было не ниже сегодняшнего финансирования "Апорта". В результате, 6 июня 2000 года была представлена вторая версия системы, а нынешняя версия функционирует с 23 мая 2001 года. Ее главное нововведение, которое потребовало неизбежной перестройки ядра, - ранжирование по ссылкам. Другие нововведения относятся, главным образом, к переформулированию системой запросов пользователя: "что такое предмет" преобразуется в "предмет - это...", а если запрос начинается на слово "как", то в результатах в первую очередь пытаются выдать FAQ или иной справочный документ. Новый "Яндекс" стал "понимать" альтернативную лексику, которая входит в 5 процентов запросов. Только в последней версии Яндекса индекс цитируемости стал непосредственно использоваться поисковой машиной.
В настоящее время "Яндекс" обладает самой полной базой документов среди русских поисковиков, а также самой узнаваемой маркой.
Сравнение качества поиска. Поисковая машина характеризуется двумя важнейшими параметрами: точностью и полнотой (полнота есть отношение количества найденных релевантных документов к полному количеству релевантных документов в базе данных).
Пример. Пусть по запросу найдено 50 документов. После просмотра их всех пользователь принимает решение, что 30 документов релевантны запросу, а 20 нерелевантны. Сплошной просмотр всей базы данных показывает, что в ней содержится 100 документов, релевантных запросу. Отсюда получаем, что полнота 30/100 = 0,3; точность 30/50 = 0,6. Как правило, улучшая один из названных параметров, ухудшаешь другой.
Используется также такая обобщенная характеристика, как техническая эффективность поисковых машин, включающая скорость поиска по запросу, объем базы, удобство представления результатов, скорость индексирования информации и так далее. Но особое место среди этих параметров занимают показатели качества поиска - в этом сходятся мнения всех создателей поисковых машин.
Отечественная компьютерная пресса, которая так любит устраивать тестирование лингвистических программ (например, систем оптического распознавания), пока ни разу не организовала ни одного тестирования отечественных поисковиков (в отличие от ZDnet). Научные тестирования поисковиков также представляются недостаточно объективными, так как используют, к примеру, всего четыре типа запросов (без учета реальной частоты этих запросов на некоторую поисковую машину). Поэтому остановимся на исследованиях для оценки точности по методике Н. Харина. Она используется во время периодических внутрифирменных тестирований поисковых машин в " Rambler " группой приглашенных экспертов-лингвистов (обычно, в течение двух недель каждое). Можно считать это тестирование независимым, так как его результат не используется заказчиком в маркетинговых целях. Исследования проводились путем оценки результатов поиска различных поисковиков по одним и тем же 100 популярным запросам, состоящим из одного, двух, трех и четырех слов. Важным условием всех исследований были четкие формулировки, какие именно документы считать релевантными смыслу каждого из запросов (без этого были бы получены сильно завышенные оценки технической эффективности). Часто встречающиеся запросы, содержащие ненормативную лексику, не учитывались.
Результаты исследований представлены ниже. Значения годичной давности оставлены, чтобы показать изменения эффективности при переходе "Яндекса" на более совершенную версию поисковой машины в июне 2000 года и изменение точности "Рамблера", вследствие того, что с ноября 2000 года некоторые нововведения стали последовательно внедряться в старый движок.
Результаты для "Апорта", по словам его создателя Евгения Киреева, качественно похожи на правду, потому что за прошедший год ничего в технологиях повышения релевантности в этой системе не менялось, так как, по его мнению, ничего уже и невозможно принципиально изменить. По его словам, команда "Апорта" спокойно ждет, пока "Яндекс" и "Рамблер" подтянутся до такого же уровня, и это будет уровнем развития отрасли. Фактически, результаты последнего исследования от 01.01.01 года, проведенные на следующий день после представления новой версии "Яндекса", показывают, что с нынешнего лета уровень отрасли определяется им.
Хотя данные советы даны в качестве "советов по поиску в Яндексе", тем не менее, они применимы к подавляющему большинству поисковых систем, так как все современные поисковые системы, в своих функциях и возможностях для поиска, очень похожи.
Проверяйте орфографию
Если поиск не нашел ни одного документа, то вы, возможно, допустили орфографическую ошибку в написании слова. Проверьте правильность написания. Если вы использовали при поиске несколько слов, то посмотрите на количество каждого из слов в найденных документах (перед их списком после фразы "Результат поиска"). Какое-то из слов не встречается ни разу? Скорее всего, его вы и написали неверно.
Используйте синонимы
Если список найденных страниц слишком мал или не содержит полезных страниц, попробуйте изменить слово. Например, вместо "рефераты" возможно больше подойдет "курсовые работы" или "сочинения". Попробуйте задать для поиска три-четыре слова-синонима сразу. Для этого перечислите их через вертикальную черту (|). Тогда будут найдены страницы, где встречается хотя бы одно из них. Например, вместо "фотографии" попробуйте "фотографии | фото | фотоснимки".
Ищите больше, чем по одному слову
Слово "психология" или "продукты" дадут при поиске поодиночке большое число бессмысленных ссылок. Добавьте одно или два ключевых слова, связанных с искомой темой. Например, "психология Юнга" или "продажа и покупка продовольствия". Рекомендуем также сужать область вашего вопроса. Если вы интересуетесь автомобилями ВАЗа, то запросы "автомобиль Волга" или "автомобиль ВАЗ" выдадут более подходящие документы, чем "легковые автомобили".
Не пишите большими буквами
Начиная слово с большой буквы, вы не найдете слов, написанных с маленькой буквы, если это слово не первое в предложении. Поэтому не набирайте обычные слова с Большой Буквы, даже если с них начинается ваш вопрос Яндексу. Заглавные буквы в запросе рекомендуется использовать только в именах собственных. Например, "группа Черный кофе", "телепередача Здоровье".
Найти похожие документы
Если один из найденных документов ближе к искомой теме, чем остальные, нажмите на ссылку "найти похожие документы". Ссылка расположена под краткими описаниями найденных документов. Яndex проанализирует страницу и найдет документы, похожие на тот, что вы указали. Но если эта страница была стерта с сервера, а Яндекс еще не успел удалить ее из базы, то вы получите сообщение "Запрошенный документ не найден".
Используйте знаки "+" и "-"
Чтобы исключить документы, где встречается определенное слово, поставьте перед ним знак минуса. И наоборот, чтобы определенное слово обязательно присутствовало в документе, поставьте перед ним плюс. Обратим внимание, что между словом и знаком плюс-минус не должно быть пробела. Например, запрос "частные объявления продажа велосипедов" выдаст вам много ссылок на сайты с разнообразными частными объявлениями. А запрос с "+" "частные объявления продажа +велосипедов" покажет объявления о продаже именно велосипедов. Если вам нужно описание Парижа, а не предложения многочисленных турагентств, имеет смысл задать такой запрос "путеводитель по Парижу - агентство - тур".
Попробуйте использовать язык запросов
С помощью специальных знаков вы сможете сделать запрос более точным. Например, укажите, каких слов не должно быть в документе, или что два слова должны идти подряд, а не просто оба встречаться в документе. (Описание синтаксиса языка запросов - http://www. *****/info/syntax. html)
Искать без морфологии
Вы можете указать Яндексу не перебирать все словоформы слов из запроса при поиске. Например, !лукоморья найдет только страницы, цитирующие строчку из стихотворения Пушкина ("У лукоморья дуб зеленый").
Поиск картинок и фотографий
Яндекс умеет искать не только в тексте документа, но и отыскивать картинки по названию файла или подписи. Для этого на первой странице ***** нажмите ссылку "расширенный поиск". Для поиска картинки предусмотрены два поля. В поле "Название картинки" вписываются слова для поиска по названиям картинок, обычно появляющихся, когда к картинке подводится курсор. Например, название картинки "Венера" выдаст все страницы с картинками Венеры (всего, что можно понимать под этим словом).
В поле "Подпись к картинке" вписывается название файла, содержащего картинку. Например, запрос dog найдет в Интернете все картинки, в имени файла которых встречается слово "dog". С большой вероятностью эти картинки связаны с собаками.
Словосочетание "Индекс Цитирования" или просто тИЦ - что же скрывается за этим понятием?
Согласно словарям, индекс цитирования - это общее количество доменов, ссылающихся на сайт, для которого высчитывается индекс цитирования. Как правило, тИЦ устанавливается кратным десяти до , 20, 30, ..., 290, 300), кратным 50 до 1, 400, ..., 950).
тИЦ высчитывается Яндексом. При его подсчёте также используются многие другие правила, которые, пожалуй, известны только работникам Яндекса.
На данный момент, как утверждает Яндекс, тИЦ абсолютно никак не влияет на порядок сайтов в выдаче поиска. Он служит лишь для расстановки сайтов в Яндекс. Каталоге. Но косвенное значение в расстановке сайтов на странице поиска он имеет - для упорядочения сайтов в результатах поиска служит ВИЦ - Взвешенный Индекс Цитирования, так сказать, аналог PageRank от Яндекса. Его значение до 2002 года можно было увидеть, посмотрев на Яндекс. Бар показывает, что тИЦ - гораздо менее важный показатель. При расчёте ВИЦ учитывается не только количество ссылок, но и их "Качество", то есть ВИЦ - ресурсов, на которых они стоят. Это - довольно сложный алгоритм, и опять-таки с точностью об этом вам могут рассказать только сотрудники Яндекса.
Чем больше ваш тематический индекс цитирования, тем выше будет цена ссылки с главной страницы вашего сайта, да и вообще к вашему сайту будет более уважительное отношение. Но для увеличения тИЦ следует пользоваться только легальными, "белыми" методами.
Разрешено в мире поисковой оптимизации всё, что не запрещено поисковиками. А запрещено ими: создавать страницы, бесполезные для пользователя, служащие для перенаправления на другой сайт (Дорвеи - DoorWay), скрывать ссылки от пользователя (Cloaking - Клоакинг), поисковой спам, некоторые другие методы. Покупка-продажа ссылок также не приветствуется поисковиками. Поэтому недопустимо прибегать к вышеперечисленным методам, а пользоваться другими, легальными методами.
Краткое резюме
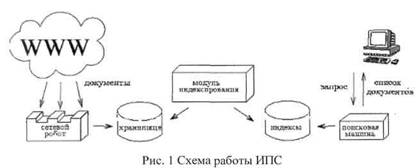
Поисковая система - это сумма следующих компонент:
1. Web server (веб-сервер) – сервер поисковой машины, который осуществляет взаимодействие между пользователем и остальными компонентами системы.
2. Spider (паук)- программа, написанная по принципу браузера, предназначена для скачивания веб-страниц. Браузер предназначен для визуального использования страниц, а паук работает с HTML кодом напрямую. Чтобы посмотреть "сырой" исходник, нажмите в меню браузера: Вид - Просмотр HTML кода
3. Crawler («путешествующий» паук) – программа, которая автоматически уходит по всем внешним ссылкам страницы. Ее задача - поиск не известных (или измененных) документов и в расстановке приоритетов, куда дальше должен идти Spider.
4. Indexer (индексатор) - программа-анализатор скаченных пауками веб-страниц. Она "разбирает" на части скачанную страницу и анализирует ее элементы, такие как текст, служебные html-теги, заголовки, особенности стилистики и структурные формы
5. Database (база данных) – хранилище для скачанных и обработанных страниц - общая база данных поисковой машины.
6. Search engine results engine (система выдачи результатов) – извлекает результаты поиска из базы данных поисковой системы. Именно она решает, какие страницы более соответствуют запросу пользователя и отсортировывает их в нужном порядке. Модуль работает согласно заданным поисковой системой алгоритмам ранжирования
Так же в поисковые системы встроены различные модули: определение IP-хоста сайта, WHOIS - определение имени владельца и сроков регистрации, copyscape - проверка "заимственности" содержания сайта и многое-многое другое.
В мире Интернет-технологий, как и в научном мире, есть понятие «индекс цитирования». Но если в науке принимаются во внимание ссылки на монографию, статью, то в Сети существует свой ИЦ, учитывающий ссылки на ресурс с других веб-сайтов. ТИЦ – тематический индекс цитирования поисковой системы Яндекс, по нему определяют авторитетность сайтов.
ТИЦ позволяет оценить значимость веб-ресурсов по качеству («весу») ссылок, а не только по их количеству. Поскольку поисковая машина Яндекс на данный момент наиболее популярна среди российских пользователей и различных коммерческих организаций, которым в работе необходим Интернет, тематический индекс цитирования играет одну из главных ролей в погоне за новыми посетителями сайта и потенциальными покупателями. Данный показатель учитывается также, когда проводится раскрутка сайта . Индекс цитирования при определении значимости ресурса учитывает его тематическую близость к ссылающимся на него сайтам. Уровень ТИЦ будет гораздо выше, если ссылка – с ресурса той же тематики. Отследить рост значения этого показателя можно, установив специальную «кнопку» на странице, при клике на которую указывается значение. Обновляется информация в среднем один раз в три недели.
Мнение о том, что ТИЦ влияет на поисковую выдачу, ошибочно. Он не влияет на место ресурса в результатах поиска, так как не зависит от самого текста ссылок, имеющего преимущественное значение для таких действий, как продвижение и оптимизация сайта . Учитывается только количество тематических ссылок. Значимым рассматриваемый показатель является для позиции сайта в Яндекс. Каталоге – одном из самых крупных каталогов Рунета, в котором ресурсы сортируются как раз-таки по значению ТИЦ. Данный каталог даёт веб-ресурсам большой поток посетителей, особенно тем, которые находятся ближе к первым позициям. Попасть в каталог очень даже не просто. Влияет индекс цитирования на цену ссылок с сайта и, соответственно, может приносить прибыль. Чтобы повысить этот показатель, лучше всего работать с тематическими ссылками с других веб-ресурсов.
Купить или продать ссылки можно на специальных биржах. Однако стоит помнить, что не все ссылки могут увеличить тематический индекс цитирования. На него не влияют (а иногда и вредят) ссылки с Интернет-ресурсов, которые были исключены из индекса поисковика. Не всегда высокий ТИЦ приводит большое количество посетителей, зато хороший сайт, который регулярно проводит маркетинговый аудит и следит за качеством контента, может рассчитывать на высокое значение данного показателя.Yandex тИЦ (CY) — тематический индекс цитирования поисковой системы Яndex , особенностью которого является то, что он рассчитывается по отношению к тематически близким ресурсам.
Logarithmic Yandex тИЦ (LCY) — величина, вычисляемая из тематического индекса цитирования. Шкала LCY может изменяться от 0 до 100, что на данный момент соответствует тИЦ от 01.01.2001. У сайтов, лишённых или не имеющих тематического индекса цитирования, лИЦ равен -1. (© Сергей Холод, 2007).
25. Организация интеллектуального поиска. Интеллектуальный агент.
- функции ИА
- поиск информации;
- автономное выполнения заданий;
- доставка информации на компьютер пользователя;
- фильтрация информации;
- отслеживание изменений той части информации, которая постоянно интересует пользователя.
- основные свойства ИА
- Автономность (большинство всей работы агент должен выполнять сам, без участия человека).
- Коммуникабельность (агент должен уметь общаться с пользователем, принимая от него задания и предоставляя результаты).
- Адаптируемость (агент должен настраиваться под привычки, предпочтения конкретного пользователя).
- Универсальность (поиск должен осуществляться не только в сети Интернет, но и на локальных ресурсах - по указанию пользователя, причем поиск не должен ограничиваться использованием одного языка).
- Рациональность поведения (агент в процессе поиска своими действиями должен вести к поставленной задаче, а не препятствовать ей).
- Восприимчивость (агент, находясь в окружающей его среде, должен адекватно реагировать на изменения этой среды).
- Упреждающий поиск (агент должен отслеживать изменение той части информации, которая постоянно интересует пользователя).
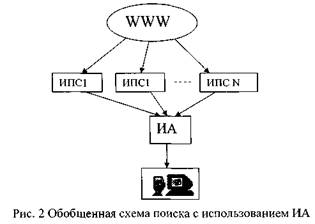
- Достоинства ИА по сравнению с ИПС
- Большая широта охвата поисковой зоны Интернет.
- Дополнительный анализ найденных документов.
- Возможность задания пользовательских предпочтений.
- Стабильность (если какая-то ИПС в сети не доступна, то ИА может не использовать ее для текущего поиска).
26. Организация интеллектуального поиска. Интерактивный процессор диалога на естественном языке.
Большинство подходов к поиску в Сети с использованием технологии NLP воплощены в виде систем, отвечающих на вопросы. Они используют лингвистическую обработку и дополнительные средства (такие как специальная разметка и устранение смысловой неоднозначности) для поиска документов, которые содержат абзацы с ответами на вопросы, сформулированные на естественном языке. Однако в них отсутствует диалог, а потому усилия сосредоточены на получении подходящих абзацев в пределах документа, а не на выявлении потребности пользователя. В некоторых случаях недостаточно совершенные лингвистические методы могут оказаться бесполезными, а поисковые запросы трудно сформулировать. Однако ориентация диалогов и запросов на определенные задачи и области применения поможет справиться с этими трудностями.
Наш подход к интеллектуальному поиску и фильтрации в Сети включает в себя технологию интеллектуальных агентов и методы NLP. Благодаря этому в адаптивном диалоге можно применять знание, как контекста, так и интересов, целей и поведения пользователя. Основу модели интерактивной системы поиска составляют зависящие от задачи средства построения беседы и анализа диалога. Вместо предоставления образцов или обследования Сети для выявления нужной информации поиск на основе диалога позволяет сосредоточиться на требованиях пользователя путем изучения его конкретных интересов. Благодаря этому поисковая система может получать неявные знания и задействовать их для уточнения и фильтрации результатов поиска в ходе диалога. Такая система должна быть способна быстро определять нужды пользователя на основе предоставленной им информации и обратной связи при взаимодействии на естественном языке.
На Рис.2 проиллюстрирован общий подход к поиску и фильтрации с использованием обратной связи на естественном языке.
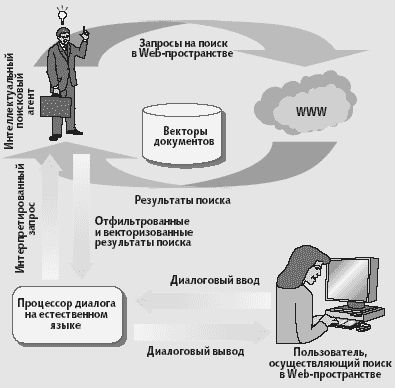
Рис. 2 Поисковый агент с управлением на естественном языке. В процессе
диалога пользователь формулирует запросы, которые передаются для обработки
в процессор диалога. В ходе взаимодействия с пользователем процессор
диалога уточняет запросы и направляет их поисковому агенту
Действие начинается с запроса на естественном языке, который формулируется пользователем. Запросы проходят обработку, при которой осуществляются диалоговые взаимодействия в форме высказываний на естественном языке, направленные на доработку и уточнение поискового запроса. В ходе диалога система уточняет запрос, а затем направляет его поисковому агенту.
Для разработки и проверки моделей диалога была выбрана экспериментальная технология Wizard of Oz. Используя WoZ для сбора лингвистических данных, мы получили объемный свод диалогов. Мы записали его, проаннотировали и проанализировали, чтобы создать структурную модель, поддерживающую планирование и генерацию интерактивной объяснительной и описательной беседы. Система моделирует человеко-машинное взаимодействие на естественном языке, причем интерактивный процесс продолжается до тех пор, пока модель не достигнет ожидаемых результатов.
Группа из 22 испытуемых-неспециалистов использовала имитатор WoZ для поиска информации в Web-пространстве. Ее разделили на четыре подгруппы: три были укомплектованы случайным образом, а четвертая состояла из аспирантов. Чтобы определить, возникают ли различия при проведении бесед (объяснения, описания и т. д.) в зависимости от текущей коммуникативной ситуации, нескольких «продвинутых» студентов попросили выполнить разные задания в одном и том же сеансе. Взаимодействия пользователей с системой (точнее со скрытым экспертом, который играл ее роль) были записаны и послужили для лингвистического анализа. Процесс уточнения продолжался до полного удовлетворения потребностей пользователя (был установлен 20-минутный порог для проверки достижения пользователем коммуникативной цели). После поиска испытуемых просили описать, что именно они получили в результате поиска в Web. Это было сделано для создания компьютерной модели, которая применяет извлеченные из Сети документы для генерации описаний и объяснений на естественном языке.
Интерактивный генератор диалогов
Генератор диалогов на естественном языке состоит из нескольких компонентов, в том числе контекста, сведений об участниках (пользователь и система) и ситуации, к которой относится анализируемый диалог (например, взаимодействие для поиска информации в Web).
На Рис.3 предложенная модель NLG «ведет беседу» по результатам библиографического поиска в Web.
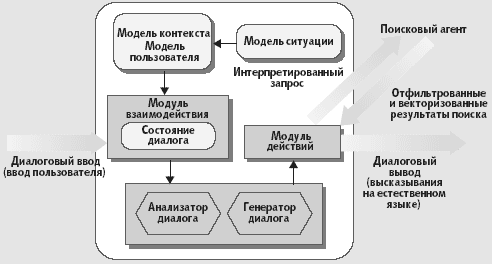
Рис. 3 Интерактивный процессор диалога на естественном языке. Процесс
начинается с ввода пользовательского запроса, который порождает либо
обмен сообщениями на естественном языке, либо направление
интерпретированного запроса поисковому агенту
Процесс начинается с ввода пользователем запроса на естественном языке, продолжается в виде обмена сообщениями для его уточнения, а в заключительной фазе диалога создается поисковый запрос для передачи поисковому агенту.
Модель контекста имеет дело с информацией, которая касается участников диалога, — «пользователя», нуждающегося в информации из Сети, и «системы», выполняющей поиск. Модель определяет вид социальной ситуации («Библиографические запросы в Web») и цели участников: «Найти информацию по некоторой теме» (для пользователя) и «Помочь пользователю в достижении заявленной цели путем поиска и диалога» (для поисковой системы). Модель пользователя учитывает знания о нем.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
