
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Глядя на таблицу переходов, изображенную на рис. 2.23, мы замечаем, что не надо делать различия между ролями Л1 и Л2, а также a1 и A2. Алгоритм позволяет нам не заботиться об этом при создании исходного распознавателя.
|
|
{Л1, Л2} {a1, A2} {Н} {C1} {C2} {О} {Ь} |
Рис. 2.23.
Хотя процедура гарантирует, что детерминированный автомат не содержит недостижимых состояний, детерминированный автомат может оказаться не минимальным. В последнем примере состояния {О} и {Ь} явно эквивалентны и могут быть объединены.
Тема3. Реализация конечных автоматов
3.1 Введение
В предыдущей главе мы обсуждали конечные автоматы с чисто теоретической точки зрения, лишь слегка касаясь их предполагаемого применения в качестве одного из основных составных блоков компилятора. В этой главе мы рассмотрим некоторые проблемы, связанные с реализацией конечного автомата или процессора как программы или подпрограммы для вычислительной машины. Этот материал относится также к реализации более общих моделей автоматов, обсуждаемых в последующих главах, так как конечный автомат используется в этих моделях как центральное управляющее устройство.
На протяжении этой главы рассматриваются три взаимосвязанных вопроса:
1. как представлять входы, состояния и переходы конечного автомата, чтобы удовлетворить зачастую противоречивые требования, предъявляемые к реализации: быстродействие и небольшие затраты памяти,
2. как справиться с некоторыми специфическими проблемами, постоянно возникающими при компиляции,
3. как расчленить задачу построения компилятора, чтобы получить автоматы, допускающие простую реализацию.
Некоторые задачи, решаемые с помощью конечных автоматов, заключаются всего лишь в распознавании конечного множества слов. Суть этих проблем в том, что компилятор должен обнаружить появление некоторого слова из такого множества и затем действовать в зависимости от того, какое это слово. Операторы MINI-BASIC'a, например, могут начинаться с одного из девяти слов (LET, IF, GOTO и т. д.), и для компилятора важно установить, с какого из них (если оно есть) начинается строка, и предпринять действия, соответствующие данному типу оператора. Задачу такого характера мы называем проблемой «идентификации», так как действия компилятора зависят от идентичности некоторому известному слову данного слова, включенного в входную цепочку автомата. Так как для решения задач идентификации может потребоваться огромное число состояний, в подобных случаях часто приходится пользоваться специальными методами реализации. По этой причине нередко рекомендуется строить компилятор так, чтобы проблема идентификации решалась отдельным подпроцессором, специально предназначенным для этого.
Существуют проблемы идентификации, которые, строго говоря, не могут быть решены с помощью конечного автомата. Обратимся к часто встречающейся проблеме распознавания переменных или идентификаторов некоторого языка и соотнесения их с соответствующими элементами таблицы имен. Решение этой проблемы обычным методом с помощью конечного автомата потребует нескольких состояний и элемента таблицы имен для каждого допустимого идентификатора. Однако множество допустимых идентификаторов в большинстве языков бесконечно или так велико, что его вполне можно считать бесконечным. В Алголе, например, где идентификатор может состоять из произвольного числа символов, множество допустимых идентификаторов бесконечно, тогда как в Фортране, где длина идентификатора не больше шести, число допустимых идентификаторов конечно, но астрономически велико, так что на практике считается бесконечным. (В противоположность этому идентификаторы MINI-BASIC'a могут состоять не более чем из двух символов, поэтому число допустимых идентификаторов конечно и поддается обработке.)
Понятно, что для языков, где число допустимых идентификаторов бесконечно или практически бесконечно, невозможно отвести место в памяти или элемент таблицы имен для каждого возможного идентификатора. Это затруднение преодолевается с помощью понятия расширяющегося конечного автомата. При считывании своей входной цепочки этот автомат отводит для идентификатора необходимое место в памяти и элемент в таблице, как только тот впервые встречается в программе. Если этот идентификатор встречается в программе снова, то, чтобы идентифицировать его, автомат использует технику идентификации слов с помощью конечного автомата. Когда появляется какой-то новый идентификатор, автомат снова расширяется и так далее. Хотя этот автомат не является, строго говоря, конечным, к нему применимы многие принципы построения и анализа конечных автоматов.
Большинство методов идентификации потенциально полезны при идентификации как фиксированных множеств, для которых память отводится заранее, так и расширяющихся множеств. Поэтому при обсуждении этих специальных методов идентификации, помимо обычных требований, предъявляемых к времени и объему памяти, мы должны учитывать относительную легкость расширения.
3.2. Представление входных символов
 Чтобы смоделировать конечный автомат, мы должны каким-нибудь подходящим способом закодировать его входное множество. Наиболее гибкое решение состоит в представлении входного множества с помощью набора последовательных целых чисел, начиная с 0 или 1. Это кодирование хорошо работает во всех рассматриваемых далее способах реализации переходов автомата. Однако некоторые из этих способов работают также и при произвольном кодировании входного множества.
Чтобы смоделировать конечный автомат, мы должны каким-нибудь подходящим способом закодировать его входное множество. Наиболее гибкое решение состоит в представлении входного множества с помощью набора последовательных целых чисел, начиная с 0 или 1. Это кодирование хорошо работает во всех рассматриваемых далее способах реализации переходов автомата. Однако некоторые из этих способов работают также и при произвольном кодировании входного множества.
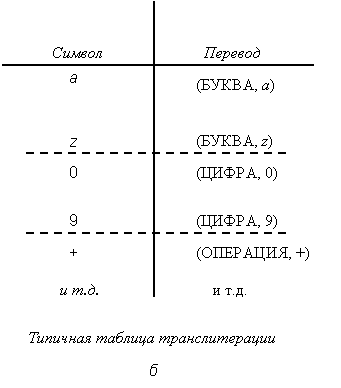 |
Рис. 3.1.
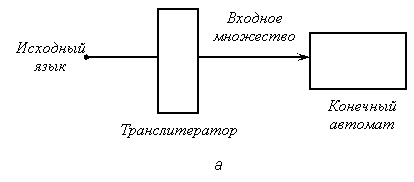
Если входом конечного автомата является выход какого-то другого блока компилятора, то обычно нетрудно построить этот блок так, чтобы он подавал на вход конечного автомата цепочки в наиболее удобном для него виде. Единственное место при построении компилятора, где может возникнуть проблема кодировки,— это процедура чтения символов исходной программы. В оставшейся части данного раздела мы займемся этим вопросом.
Если бы множество символов исходной программы непосредственно служило входом для некоторого конечного процессора, содержащего много состояний, то автомат имел бы большую таблицу переходов, так как одни только цифры и латинские буквы образуют множество из 36 символов, обычно же множество символов в несколько раз больше. Удобный способ уменьшения размера таблицы переходов заключается в обработке исходных символов двумя последовательно соединенными автоматами: первый автомат — это транслитератор, единственная задача которого — сократить входное множество до приемлемых размеров; второй автомат выполняет остальную часть работы. Этот вид взаимодействия показан на рис. 3.1, а.
Зависимость между входом и выходом транслитератора можно выразить с помощью таблицы, например, такой, как на рис. 3.1, б, которая содержит перевод каждого символа исходного языка. Выход этого транслитератора будем называть символьной лексемой. Такая лексема обычно состоит из двух частей: класса и значения. Так, буква а будет иметь класс БУКВА и значение а, тогда как знак операции + имеет класс ОПЕРАЦИЯ и значение +. Класс лексемы должен служить входом для второго автомата, а ее значение доступно процедурам переходов этого автомата. Потребность в такой предварительной обработке упоминалась в гл. 2. (Вспомним, например, обработку констант).
Транслитератор — это просто процессор с одним состоянием, хотя вряд ли имеет смысл рассматривать его именно в этом качестве. Разумеется, он реализуется как процедура, которая находит в таблице перевод для каждого входного символа. На многих машинах это можно сделать одной или двумя командами. Множество классов символьных лексем обычно представляется с помощью последовательных натуральных чисел, так как они являются возможными входными символами для второго автомата.
3.3. Представление состояний
Есть два основных способа, с помощью которых программа, моделирующая конечный автомат, может запоминать состояние моделируемого автомата. Первый заключается в запоминании номера, соответствующего текущему состоянию, в некотором регистре или ячейке памяти вычислительной машины. Этот способ мы называем явным, так как состояние явно задается некоторой переменной. Второй основной метод заключается в том, что для каждого состояния имеется отдельная часть программы. Поэтому тот факт, что моделируемый автомат находится в заданном состоянии, «запоминается» тем, что моделирующая программа исполняет часть кода, которая «принадлежит» этому состоянию. Такой метод называется неявным.
Явный или неявный метод выбирается исходя просто из удобства программирования. Важно отметить, что слово «состояние» не подразумевает никакой особой техники реализации.
3.4. Выбор переходов
Суть программы, моделирующей конечный процессор, состоит в способе выбора переходов, так как для заданного состояния и очередного входного символа программа должна выполнить переход, указанный в таблице переходов. Поэтому информация, содержащаяся в таблице переходов, должна где-то храниться, или же ее надо включить в моделирующую программу.
|
A1 B3 A6 C2 C3 A4 B6 C1 B5 |
|
Адрес А1 | Адрес процедуры обработки ошибки | Адрес процедуры обработки ошибки | Адрес B3 | Адрес процедуры обработки ошибки | Адрес А6 | Адрес процедуры обработки ошибки | Адрес процедуры обработки ошибки |
|
|
|
1 | A1 |
6 | B6 |
4 | B3 |
Переход по неудаче = Процедура обработки ошибки
|
Рис. 3.2. (а) Построение процессора, (б) вектор переходов, (в) список переходов.
Предположим пока, что состояние запоминается неявно. В этом случае косвенно известна нужная строка таблицы переходов, и задача сводится к нахождению перехода только по входному символу.
Эта задача должна, разумеется, решаться для каждого состояния в отдельности.
Рассмотрим два метода решения задачи выбора перехода для заданного входного символа. Мы называем их методом «вектора переходов» и методом «списка переходов».
Согласно методу вектора переходов, адреса или метки тех процедур переходов, на которые должно передаваться управление, хранятся в виде вектора в последовательных ячейках памяти, по одной ячейке для каждого входного символа. Очередной входной символ служит индексом, по которому выбирается элемент вектора, дающий нужный переход. Чтобы этот метод работал, входное множество должно быть представлено каким-нибудь подходящим образом, например в виде множества последовательных целых чисел. Пример такого вектора приведен на рис. 3.2, б, где изображен вектор переходов для состояния А на рис. 3.2, а. Достоинство метода в том, что нужную процедуру перехода можно выбрать очень быстро. Затраты памяти •— по ячейке на каждый элемент строки. В большинстве языков программирования высокого уровня этот метод можно реализовать, используя переключатель или вычисляемый переход.
Согласно методу списка переходов, входные символы делятся на два класса: каждому входному символу первого класса приписывается индивидуальный переход, а все символы второго класса имеют общий переход (обычно процедуру, обрабатывающую ошибку). Для первого класса соответствие между входным символом и адресом процедуры перехода задается в виде списка упорядоченных пар. Общий переход для символов из второго класса запоминается отдельно и называется переходом по неудаче.
При поступлении нового входного символа происходит поиск в списке этого символа и соответствующего ему перехода. Если поиск заканчивается неудачей, делается переход на процедуру, соответствующую неудаче. Этот метод можно применять, даже если входной символ не является индексом.
На рис. 3.2, б показан список переходов для состояния А процессора, изображенного на рис. 3.2, а. Переход по неудаче вызывают входные индексы 2, 3, 5, 7 и концевой маркер, тем самым пять элементов таблицы объединяются в один переход.
Среднее время, необходимое для выбора перехода методом списка переходов, зависит от длины списка и относительной частоты, с которой входные символы встречаются в исходной программе. Естественно, более выгодно помещать пары, содержащие наиболее часто встречающиеся входные символы, в начале списка. Тем не менее этот метод всегда работает медленнее, чем метод вектора переходов, а при увеличении длины списка становится еще медленнее. Метод списка требует совсем незначительных затрат памяти, когда список короткий, однако при длинном списке затраты памяти для этого метода больше, чем для метода вектора, так как память отводится и для метки процедуры перехода, и для символа, вызывающего этот переход. Таким образом, этим методом лучше всего пользоваться, когда память дорога, а таблица переходов содержит много стандартных переходов, связанных с ошибкой.
Разумеется, при моделировании автомата можно пользоваться смешанным методом. В примере на рис. 3.2, а при выборе переходов из состояния В был бы предпочтителен метод вектора переходов, тогда как для состояния С метод списка переходов сэкономил бы много места.
Если состояние моделируемого автомата хранится в явном виде, то в этом случае принципы указанных методов векторов и списков по-прежнему применимы, но возможны многочисленные варианты. Одна из возможностей состоит в том, чтобы пользоваться состоянием как индексом для передачи управления одной из уже описанных процедур. Другая заключается в том, чтобы хранить таблицу переходов как единый двумерный массив, индексы которого — это состояния и входные символы. Можно также использовать метод списка для выбора элементов из столбцов, а не из строк таблицы переходов. Мы не будем говорить о преимуществах того или иного метода, разработчику рекомендуется самому выбирать метод в соответствии со своей конкретной задачей и особенностями вычислительной машины.
3.5. Идентификация слов: метод автомата
Это первый из шести разделов, в которых пойдет речь об идентификации. Мы начнем с проблемы идентификации слов. Предположим, что заданы конечное множество слов в некотором входном алфавите и некоторое входное слово и нужно установить, какой элемент заданного множества (если такой существует) совпадает с входным словом. В данном разделе мы решаем эту проблему путем построения конечного процессора, который по предъявленному входному слову с концевым маркером устанавливает его идентичность некоторому элементу множества. В последующих разделах рассматриваются другие методы.
Наиболее широкое применение автомат, идентифицирующий слова, находит в лексическом блоке компиляторов. Один из способов использования такого автомата в гипотетическом лексическом блоке показан на рис. 3.3. Управляющая программа знает, что некоторая цепочка букв, появившаяся в некотором месте программы, должна быть словом, и подает эти буквы по одной на вход автомата, идентифицирующего слова, для анализа. Когда управляющий автомат обнаруживает, что слово кончилось, он посылает на вход идентифицирующего автомата концевой маркер. Предположим, что буквы уже переведены транслитератором в символьные лексемы типа БУКВА с соответствующими значениями. Под действием входного символа БУКВА управляющий автомат подает значение этой буквы на вход идентифицирующего автомата, и сам совершает определенный переход.
Если идентифицирующий автомат использовать таким образом, то язык должен быть таким, чтобы управляющий автомат узнавал, какие входные символы, следуя друг за другом, образуют слово. Некоторые проблемы идентификации не так просты, как эта.
 |
Рис. 3.3. Возможная организация лексического блока.
В разд. 3.10 мы обсудим применение техники идентификации слов к некоторым задачам, решение которых менее очевидно.
Автомат, идентифицирующий некоторое множество слов, можно построить путем введения в него состояния для каждой подцепочки, которая может быть префиксом какого-либо слова из этого множества. Множество префиксов включает в себя пустую цепочку, которая служит
префиксом любого слова, а также сами заданные слова, так как каждое слово является своим префиксом. Так как эту процедуру легче проделать, чем описать ее словами, продемонстрируем ее на следующем примере.
Рассмотрим задачу построения конечного процессора, имеющего входной алфавит {О, Б, С, К, А} плюс концевой маркер и предназначенного для идентификации множества {ОСА, БОК, БОКА, БАК}. Процессор для этого множества изображен на рис. 3.4. Имена состояний автомата соответствуют цепочкам входных символов, просмотренных к этому моменту. Так, начальное состояние названо е, что соответствует пустой цепочке, которая считается просмотренной до того, как используется первый входной символ, а цепочка БО переведет автомат в состояние БО. Такие элементы таблицы, как «ОСА», означают, что автомат идентифицировал соответствующее слово. Пустые ячейки указывают выходы, означающие, что встретилась ошибка, при этом печатается что-нибудь вроде ВХОДНОЕ СЛОВО НЕ ПРИНАДЛЕЖИТ МНОЖЕСТВУ. Автомат может также переходить в состояние ошибки, которое откладывает сообщение об ошибке до тех пор, пока ошибочное слово не будет просмотрено полностью. При этом переходы не сопровождаются никакими действиями, кроме изменения состояния.
|
О Б С К А —|
О Б ОС БО БА ОСА БОК БАК “ОСА” БОКА ”БОК” “БАК” “БОКА” |
Рис. 3.4.
Поэтому таблица переходов содержит тысячи элементов, и от реализации с помощью метода вектора переходов приходится отказаться из-за недостатка места.
Обратившись к методу списка переходов, мы замечаем, что подавляющее большинство элементов таблицы являются переходами в состояние ошибки. Это характерно для большинства задач идентификации слов, встречающихся на практике, и объясняется тем фактом, что каждое состояние представляет собой префикс слова и поэтому может быть достигнуто только одним путем. Состояние БОК, например, может быть достигнуто только из состояния БО и только для входного символа К. Число переходов из некоторого состояния равно или меньше числа слов множества, имеющих префикс, соответствующий этому состоянию. Так, есть два перехода из состояния БОК, один — в состояние БОКА, а другой — в состояние «БОК», тогда как из состояния БО — только один переход, в состояние БОК, хотя имеется два слова с префиксом БО. Таким образом, метод списка переходов можно эффективно применять для решения довольно больших задач идентификации слов независимо от объема входного алфавита.
Так как рассматриваемые процедуры переходов просты, автомат можно
Б 3 ОШИБКА | ||
С 4 ОШИБКА | ||
О 5 А 6 ОШИБКА | ||
А 7 ОШИБКА | ||
К 8 ОШИБКА | ||
К 9 ОШИБКА | ||
—| ОСА ОШИБКА | ||
А 10 —| БОК ОШИБКА | ||
—| БАК ОШИБКА | ||
—| БОКА ОШИБКА |
реализовать еще проще, чем предлагалось ранее при обсуждении метода списка переходов. В случаях, подобных нашему, где переходы — это не процедуры переходов, а просто изменения состояния, удобно представлять состояние в виде указателя на его список переходов. Так как здесь нет процедур переходов, то нет и необходимости снабжать каждый переход меткой процедуры перехода. Вместо этого, используя списки переходов, свяжем с каждым неошибочным входным символом указатель на список переходов для следующего состояния. Переход состоит в простой замене указателя списка переходов для текущего состояния на полученный по таблице указатель списка переходов для следующего состояния. Элементы списков переходов, соответствующие концевому маркеру, должны содержать индекс или указатель таблицы имен, который указывает, какое слово найдено.
|
Предположим теперь, что мы хотим расширить таблицу на рис. 3.5 так, чтобы соответствующий ей автомат распознавал также слово ОКО. Пришлось бы добавить еще два списка переходов — для состояния ОК и для состояния ОКО. Кроме того, список 2 увеличился бы за счет внесения в него перехода из состояния О в состояние ОК. Такое расширение легко произвести при построении, но очень трудно — во время компиляции. Поэтому такой способ реализации применим лишь к распознаванию фиксированного множества слов и не может быть эффективно использован для распознавания расширяющегося множества. Имеется, однако, разновидность реализации метода списков, которая идеально подходит для таких расширений во время компиляции.
Чтобы реализовать расширяющиеся списки, заметим, что каждому символу в прежних списках на самом деле соответствуют два списка. Один из них — это список переходов, который используется, если этот символ совпадает с входным символом, а другой — список дополнительных символов, которые надо проверять, если входной символ не совпал с рассматриваемым символом таблицы. Адрес первого списка задается соответствующим указателем, а второй список считается начинающимся со следующей ячейки. Чтобы добиться расширяемости, нужно поменять эти соглашения. Будем считать, что список переходов для следующего состояния начинается в следующей ячейке, а начало списка дополнительных символов, которые надо проверять, будет запоминаться указателем. Набор новых списков для нашего примера показан на рис. 3.6, а.
В этой новой реализации каждому символу соответствует либо указатель на следующую проверку, либо пустой элемент. Этот пустой элемент указывает, что больше нет символов, с которыми нужно производить сравнение, и что произошла ошибка. Например, если первый символ С, то процессор сравнивает С с О в списке 1. Так как С не совпадает с О и символу О соответствует указатель на список 2, процессор затем сравнивает С с Б из списка 2. Символы опять не совпадают, но на сей раз символу таблицы соответствует пустой элемент.
С А —| ОСА | ||
Б О 4 К —| 3 БОК | ||
А —| БОКА | ||
А К —| БАК |
О 2 С 5 А —| ОСА |
Б О 4 К —| 3 БОК |
А —| БОКА |
А К —| БАК |
К О —| ОКО |
|

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
