
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис. 3.6.
Процессор заключает, что нет слова, начинающегося с С, и выполняет процедуру обработки ошибки. В отличие от рис. 3.5 концевому маркеру также может соответствовать указатель списка (как, например, в списке 2) или пустой элемент (как, например, в списке 1). Когда обнаруживается совпадение с концевым маркером, то входное слово идентифицируется со следующим словом списка. Заметим, что эта списочная структура содержит по одному элементу для каждого перехода, отличного от перехода в состояние ошибки, и по одному элементу для каждого слова из распознаваемого множества.
Теперь посмотрим, что происходит, когда мы хотим расширить наш автомат, чтобы он мог обрабатывать слово ОКО. Это значит, что после входного символа О допускается не только символ С, но и символ К. Для запоминания того, что должно следовать после К, добавляется новый список, а символ пробела, соответствующий в исходной структуре символу С, заменяется на указатель этого списка. Результат показан на рис. 3.6, б. Заметим, что для того, чтобы расширить список, дополнительную память можно добавить к концу уже использованной области памяти, т. е. это изменение не повлечет за собой перестройку всей исходной структуры. Поэтому такая реализация допускает расширение во время компиляции.
3.6. Идентификация слов: метод индексов
В предыдущем разделе мы обсуждали решение проблемы идентификации слов с помощью конечного автомата. Теперь мы рассмотрим ряд методов решения этой проблемы без моделирования автомата. Все эти методы основаны на том, что распознаваемое множество слов хранится в виде некоторого списка или таблицы, а затем, когда на вход поступает какое-то слово, выясняется, есть ли данное слово в списке. В этом разделе мы рассмотрим возможность вычисления по входной цепочке индекса, который обеспечивает прямой доступ к таблице.
В качестве примера рассмотрим проблему идентификации переменных языка MINI-BASIC. В данном случае переменная — это либо одна английская буква, либо буква, за которой следует цифра.
Всего имеется точно 286 допустимых в MINI-BASIC'e переменных. Так как это число невелико, можно позволить себе завести по одному элементу таблицы для каждой допустимой переменной. Тогда проблема идентификации переменных сводится к преобразованию переменной в индекс, который указывает ее место в таблице. Один из способов заключается в присваивании индексу значения от 1 до 26 для каждой входной буквы английского алфавита. Далее, если следующий входной символ — произвольная цифра d, то к индексу прибавляется число 26*(d+l). Это значит, например, что переменная Z получит номер 26, переменная АО — номер 27, а Z9 — номер 286.
Предположим в общем случае, что распознаватель может иметь дело лишь с конечным числом допустимых входных слов. Предположим также, что нам хочется выделить память для каждого допустимого слова. И наконец, предположим, что для каждого из допустимых слов мы можем быстро вычислять однозначно соответствующее ему число, скажем от 1 до М. Это число называется индексом слова. Тогда таблицу можно хранить в последовательных ячейках памяти так, чтобы /-и элемент таблицы отводился для слова с индексом /. Такую таблицу называют иногда индексированной таблицей, она аналогична одномерному массиву, причем индекс слова служит индексом компоненты массива. Обработка входного слова состоит в вычислении его индекса и нахождении элемента таблицы, соответствующего этому индексу.
Этот индексный метод можно применять, если выполнены три условия. Во-первых, число слов не должно быть слишком большим. Это условие исключает, например, множество переменных Фортрана, так как последнее содержит более миллиарда элементов. Во-вторых, индекс должен легко вычисляться. Это условие может исключить даже небольшие множества зарезервированных слов, для которых нет хорошего способа построения индекса. В-третьих, объем множества слов фиксируется при построении, так как метод вычисления индекса неудобно изменять во время компиляции. Если учесть эти три условия, становится очевидным, что рассматриваемым методом можно воспользоваться нечасто. Однако, когда он применим, идентификация осуществляется с минимальными затратами времени.
Если цель идентификации — связать слово с элементом таблицы имен, то соответствия между индексами и элементами таблицы имен можно достичь, по крайней мере, двумя способами:
1.Индекс можно использовать для непосредственного доступа к таблице имен. В этом случае слово с индексом i соответствует i - му элементу таблицы имен.
2. Индекс может указывать на таблицу указателей, содержащую указатели на таблицу имен. Чтобы найти элемент таблицы имен для слова с индексом i, нужно взять указатель из i -го элемента таблицы указателей.
Второй метод позволяет заводить элементы таблицы имен только для тех слов, которые действительно имеются в данной программе. Чтобы достичь этого, таблицу указателей инициализируют нулями, которые означают, что ни один элемент в таблице имен еще не отведен. Когда слово встречается впервые, об этом свидетельствует нуль в соответствующей ячейке таблицы указателей. Для этого слова заводится элемент таблицы имен, а указатель на него помещается в таблицу указателей.
Исходя из обычно правдоподобных предположений о том, что элементы таблицы имен занимают больше места, чем элементы таблицы указателей, а слова, используемые в конкретной компилируемой программе, составляют лишь небольшую часть всех допустимых слов, можно заключить, что второй метод требует меньше
памяти. С другой стороны, он может увеличить время доступа к таблице имен. Этот метод позволяет также заводить элементы таблиц переменного размера.
3.7. Идентификация слов: метод линейного списка
Вероятно, наиболее прямой метод идентификации слов заключается в том, чтобы, построив копию входного слова, сравнивать ее с каждым элементом хранимого в памяти списка до тех пор, пока не произойдет совпадение (если оно возможно). Этот метод легко приспособить к случаю расширяющихся множеств, так как все, что нужно< сделать в подобных случаях,— это добавить в список еще одно слово. Требование, предъявляемое к памяти, состоит только в том, чтобы хватило места для размещения списка слов. У этого метода есть лишь один недостаток: поиск по длинному списку занимает много времени. Предполагая, что слова из списка появляются с примерно одинаковыми вероятностями, можно ожидать, что для обнаружения заданного слова потребуется просмотреть в среднем половину списка. Точнее, если имеется М слов, то ожидаемое число сопоставлений, необходимых для нахождения одного случайно выбранного слова, равно (М+1)/2.
Есть два основных способа хранения списков слов — последовательное хранение и связанное хранение. В первом случае, чтобы найти следующий элемент списка, нужно перейти к следующей ячейке памяти. Свободное место для расширения резервируется в конце списка. Во втором случае, согласно методу связанного списка, каждое слово снабжается указателем на следующее слово. Для расширения списка отводится некоторая свободная область, но она не обязана физически располагаться в конце имеющегося списка. Одна и та же свободная область может одновременно обслуживать несколько связанных списков.
3.8. Идентификация слов: метод упорядоченного списка
Время поиска по длинному списку значительно уменьшается, если элементы списка упорядочены — например, лексикографически, т. е. по алфавиту. Пусть у нас имеется список из М слов, расположенных в алфавитном порядке и хранящихся в последовательных ячейках памяти, и пусть мы хотим по некоторому входному слову найти ячейку списка (если таковая существует), в которой содержится это слово. Согласно методу, описанному в предыдущем разделе, Для нахождения слова потребуется в среднем (М + 1)/2 сравнений, а для слова, которого нет в списке,— М сравнений. Воспользовавшись упорядоченностью списка, мы можем уменьшить число сравнений примерно до log M. Это делается следующим образом:
1.Поиск начинается сравнением входного слова со словом, расположенным в середине списка. Если число слов списка четно, то сравнение делается с любым из двух элементов списка, расположенных посредине. Если входное слово и элемент списка совпадают, поиск окончен. В противном случае вследствие упорядоченности списка сравнение показывает, где следует искать входное слово — до или после середины списка.
2. Если, согласно заданному порядку, входное слово предшествует середине списка, то имеются две возможности. Если среднее слово является также и первым словом, что может случиться в списках длины 1 или 2, то мы заключаем, что входного слова в списке нет. Если среднее слово не первое в списке, то поиск должен продолжаться в новом списке, а именно в списке, начинающемся с первого слова и кончающемся словом, расположенным непосредственно перед серединой исходного списка. Длина этого нового списка не превышает половины длины исходного списка, таким образом, сделав всего одно сравнение, мы сократили задачу вдвое. Теперь мы снова применяем шаг 1, осуществляя поиск в этом новом списке.
3. Если, согласно данному порядку, входное слово расположено после середины, то список слов, стоящих после середины, подвергается такому же анализу, что и на шаге 2. К этому подсписку снова применяется шаг 1.
В качестве примера на рис. 3.7 показан поиск слова STEP в списке из 18 идентификаторов, который успешно завершается на пятом сравнении. Так как в списке 18 элементов, серединой можно считать девятое или десятое слово. Мы произвольно выбираем девятое слово INTEGER и сравниваем его с входным словом. Поскольку входное слово «больше» среднего слова в смысле алфавитного порядка, мы переходим к анализу нового списка — с девятого по восемнадцатое слово. Теперь мы сравниваем входное слово со словом STRING, серединой нового списка. Так как входное слово «меньше», мы переходим к новому списку, состоящему из слов с десятого по тринадцатое. Таким образом, каждое последующее сравнение уменьшает список в два раза, и поиск продолжается до тех пор, пока после пятого сравнения не обнаруживается слово STEP.
Если вместо этого входного слова взять слово STOP, процедура будет работать таким же образом с той лишь разницей, что, когда мы переходим к последнему списку длины 1 (состоящему из слова STEP), входное слово оказывается «больше» среднего слова этого списка. Так как среднее слово является также и последним, нового списка не будет. Отсюда мы заключаем, что этого входного слова нет в исходном списке.
Разумеется, некоторые слова могут быть найдены в списке менее чем за пять сравнений. Слово INTEGER, например, будет найдено при первом же сравнении.
Вообще на шаге 1 либо обнаруживается совпадение, либо список, в котором надо продолжать поиск, сокращается вдвое.
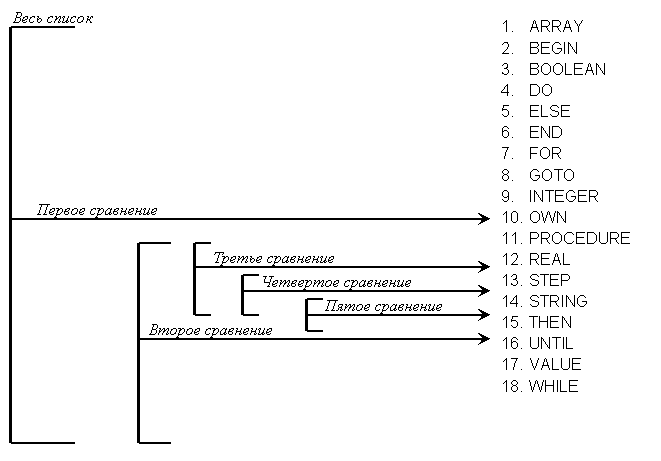 |
Рис. З.7.
Пусть исходный список состоит из М слов, тогда можно уменьшать его вдвое не более чем log2М раз, при этом получится список, состоящий из одного элемента. Понятно, что к этому моменту либо слово будет найдено, либо выяснится, что его нет в списке.
Точная граница числа сравнений равна
1 + наибольшее целое число, которое меньше или равно log2M. Эту процедуру называют методом логарифмического поиска. Ее часто называют также методом бинарного поиска.
При реализации этой процедуры требуются некоторые действия для вычисления середины списка. Поэтому на каждом шаге уходит несколько больше времени, чем в случае непосредственного доступа к списку. Однако благодаря тому, что вместо М или М/2 шагов надо выполнить лишь log2М шагов, логарифмический метод работает быстрее даже при не очень большом М.
Основной недостаток логарифмической процедуры состоит в том, что неудобно расширять список. Дело в том, что новые слова нужно не просто добавлять к концу списка, а вставлять их туда, где они обязаны находиться в соответствии с выбранным порядком.
Эту процедуру легко применить к связным спискам, если снабдить каждое слово двумя указателями. Один из них указывает на середину списка слов, которые идут после данного слова, а другой — на середину списка слов, которые предшествуют ему. Такое представление списка рис. 3.7 показано на рис. 3.8.
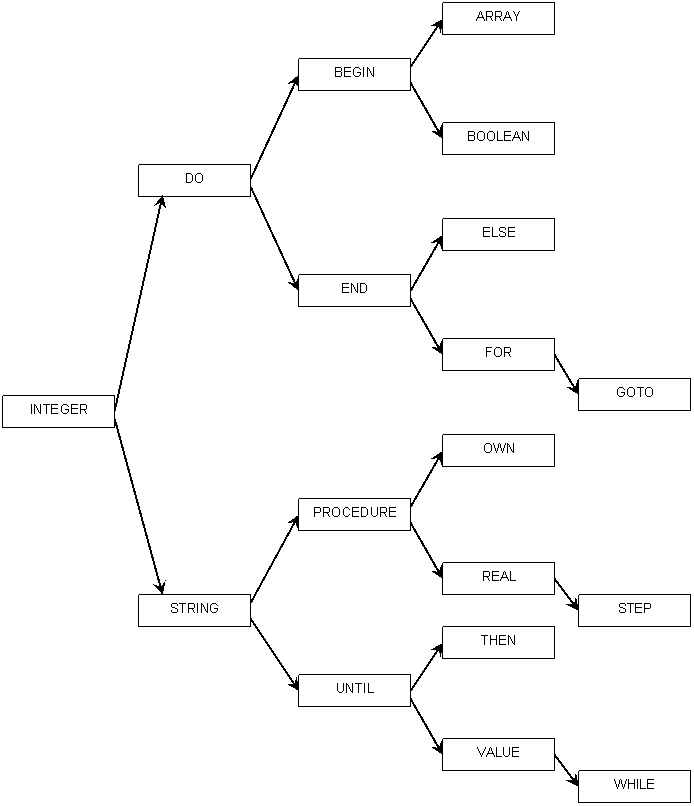 |
Рис. 3.8.
Заметим, что этот список размещается в памяти в виде дерева. При поиске слова FOR оно сравнивается со словами INTEGER, DO, END и FOR именно в этом порядке.
Разместив список в памяти в виде дерева, можно добавлять к нему слова, не нарушая этого размещения. Слово ASK, например, присоединяется к ARRAY, а слово FOX, присоединяется к GOTO. К сожалению, результирующее время поиска может превышать логарифмическую границу. Для слова FOX, например, потребуется 6 сравнений. Если желательно расширить множество слов, сохранив логарифмическое время поиска, нужно провести реорганизацию всей структуры дерева, так как в середине помещаются другие слова. Таким образом, такой метод использования связанных упорядоченных списков допускает расширение только в некотором ограниченном смысле.
3.9. Идентификация слов: метод расстановки
Идеальным методом решения проблем идентификации больших и расширяющихся множеств слов был бы такой, который позволял легко расширять множества, требовал умеренных затрат памяти и гарантировал обнаружение заданного слова (в среднем) при небольшом числе сравнений. Каждый из методов, описанных в трех предыдущих разделах, не удовлетворяет хотя бы одному из этих требований. Сейчас будет рассмотрен некоторый гибридный метод, обладающий всеми указанными достоинствами. Из множества методов, называемых методами расстановки (хеширования) или перемешанных таблиц, мы рекомендуем именно этот.
Идентификация осуществляется за два шага следующим образом:
1.По входному слову вычисляется индекс, как в разд. 3.6, где описан индексный метод. Однако в данном случае многие слова могут иметь один и тот же индекс. Этот индекс затем используется для нахождения указателя списка в таблице указателей списков. Если этот указатель равен нулю, т. е. указывает на нулевой список, то входное слово не принадлежит множеству. В противном случае применяется шаг 2.
2. Найденный элемент таблицы указателей списков указывает на некоторый связанный список слов, а именно тех слов, индекс которых совпадает с вычисленным индексом. Поиск в этом списке происходит до тех пор, пока не произойдет совпадение входного слова с элементом списка или будет достигнут конец списка. В последнем случае множество не содержит входного слова, и это слово можно добавить, просто связав его с последним элементом списка.
В литературе метод расстановки (хеширования) иногда описывается в терминах «гроздей» (buckets). Говорят, что каждый индекс указывает на некоторую гроздь, и все слова, имеющие этот индекс, принадлежат одной грозди.
Для примера мы взяли слова из списка на рис. 3.7 и изобразили возможную реализацию методом расстановки на рис. 3.9. Для того чтобы вычислить индекс, в этом примере нужно сложить номера (в алфавитном порядке) двух первых букв и взять остаток от деления результата на 7. Например, индекс слова ARRAY получается сложением 1(=A) и 18(=R) и последующим делением результата (19) на 7, остаток равен 5. Это значит, что указатель списка, содержащего слово ARRAY (если такой список существует), находится в ячейке 5 таблицы указателей списков.
Вообще реализация этой процедуры расстановки зависит от:
1) метода вычисления индекса,
2) объема таблицы указателей списков.
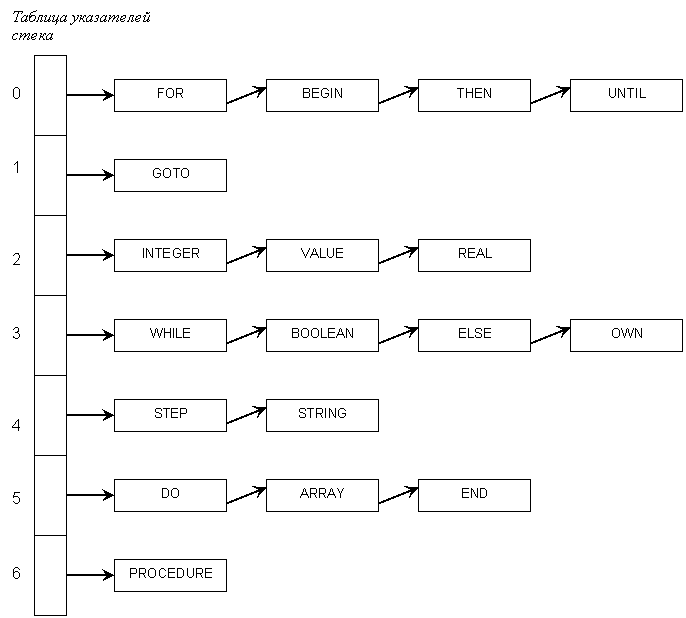
Рис. 3.9.
Поскольку эти факторы могут оказать существенное влияние на скорость и затраты памяти процедуры (а фактически и всего компилятора), мы остановимся на этих вопросах подробнее.
Единственная цель вычисления индекса — это уменьшение длины списков, в которых должен производиться поиск, В идеале нам
хотелось бы, чтобы списки были одинаковой длины. К сожалению, разработчик должен выбрать метод вычисления индекса до того, как он узнает, какие слова появятся в списке в ходе данной компиляции. Поэтому единственное, на что можно рассчитывать,— это что новые слова будут попадать в заданные списки с одинаковой вероятностью, и выбор списков не зависит от каких бы то ни было соглашений, использованных при написании исходной программы. Перед разработчиком стоит задача найти метод выбора индекса, удовлетворяющий этим свойствам псевдослучайности.
В качестве примера процедуры не такого уж случайного выбора индекса посмотрим, что происходит, если при обработке идентификаторов мы относим каждое слово к одному из 26 списков по первой букве слова. Так как в английском языке гораздо больше слов, которые начинаются с буквы R, чем слов, начинающихся с буквы О, следует ожидать, что R-список будет содержать гораздо больше элементов, чем O-список. Такая неравномерность еще более усилится, если программирующий на Фортране решит, что в его программе все идентификаторы целых переменных будут начинаться с буквы I. Хотя с точки зрения разбиения по спискам этот метод получения индекса не является идеальным, в некоторых приложениях им можно пользоваться, так как индекс легко вычислять.
Метод индексации по двум буквам, примененный в примере на рис. 3.9, лучше, чем метод индексации по одной букве, так как он ведет к более равномерному заполнению списков. Однако программист может употреблять имена с одинаковым началом (например, ALPHA 1, ALPHA 2, ALPHA 3 и т. д.), что отрицательно влияет на работу компилятора. Можно добиться более быстрого поиска, если вычислять индекс по сумме всех букв. Однако затраты при вычислении индекса могут перекрыть выигрыш во времени поиска. Таким образом, нужно найти компромисс между временем поиска и временем вычисления индекса.
На практике процедуры наиболее случайного выбора индекса получают, интерпретируя двоичный код входного слова как одно число или (для длинных слов) как ряд чисел, которые каким-нибудь образом комбинируются (например, складываются), чтобы получилось одно число. Затем это число каким-нибудь способом уменьшают, чтобы получить индекс желаемого размера. Один из способов состоит в использовании остатка от деления числа на некоторую константу. Так как деление на небольшие числа может давать в какой-то степени предсказуемые остатки (например, все они могут быть четными), важно, чтобы делитель, с помощью которого осуществляется рандомизация, не был кратным какому-нибудь маленькому числу. Поэтому в качестве рандомизирующего делителя обычно выбирают простое число. Другой метод получения индекса состоит в возведении числа в квадрат и выделении средних двоичных разрядов. Средние разряды используются для того, чтобы гарантировать участие в вычислении всех разрядов исходного числа. Методы вычисления индекса, подобные указанным и обладающие свойствами псевдослучайности, называются иногда методами функции расстановки.
Теперь мы переходим к вопросу о том, насколько большой нужно делать таблицу указателей списков. Считая, что слова на самом деле помещаются в списки некоторым случайным образом, можно изучить вопрос об объеме таблицы чисто количественными методами. Пусть в таблице указателей есть место для С указателей, и пусть случайным образом введены М слов. Если входное слово случайно выбрано из М слов, то ожидаемое число сравнений, необходимых для нахождения входного слова, равно
1+(М-1)/2С
(Чтобы установить, что некоторого нового слова в множестве нет, нужно произвести М/С сравнений.) Если нам известно число слов, с которыми придется иметь дело, эта формула говорит нам, как именно число сравнений зависит от объема таблицы.
Число слов, М
20 | 100 | 500 | 1000 | 5000 | |
10 | 1.95 | 5,95 | 25,95 | 50,95 | 250,95 |
50 | 1.19 | 1.99 | 5,99 | 10,99 | 50,99 |
100 | 1,10 | 1,50 | 3,50 | 5,60 | 26,00 |
200 | 1,05 | 1,25 | 2,25 | 3,50 | 13,50 |
500 | 1.02 | 1,10 | 1,50 | 2,00 | 6,00 |
1000 | 1.01 | 1.05 | 1.25 | 1,50 | 3,50 |
Рис. 3.10. Значения функции 1+(М—1)/2С.
На рис. 3.10 помещены результаты вычисления формулы для некоторых значений М и С.
Пусть нас интересует эффективность обработки 500 разных слов, и мы хотим узнать, сколько списков выгоднее завести: 500 или 100. Преимуществом 100 списков является то, что экономится место, необходимое для хранения еще 400 указателей, а недостатком — то, что для идентификации слова необходимо (в среднем) большее число сравнений. На рис. 3.10 можно видеть, что эта разница равна точно 2 сравнениям (т. е. 3.50 минус 1.50). Решение сводится к выбору между 400 дополнительными указателями или 2 дополнительными сравнениями, необходимыми для идентификации каждого слова.
Дополнительные сравнения должны, разумеется, оцениваться временем, необходимым для их выполнения на вычислительной машине, на которой будет реализован компилятор. Выигрыш во времени будет иметь место при каждом поиске в ходе компиляции, который осуществляется зачастую по нескольку раз для каждой строки программы. Сэкономленное время вполне может составлять значительную часть всего времени компиляции. Выигрыш будет, конечно, меньше, когда число слов меньше 500, и больше для большего множества слов. Поэтому рекомендуется проделывать указанный анализ для нескольких разных чисел слов, чтобы посмотреть, какой выигрыш во времени можно получить в разных случаях. Вообще говоря, неизбежно напрашивается вывод, что на размере таблицы экономить не нужно.
Автоматы с магазинной памятью
5.1. Определение автомата с магазинной памятью
Конечный автомат может решать лишь такие вычислительные задачи, которые требуют фиксированного и конечного объема памяти. В компиляторе, однако, возникает много задач, которые не могут быть решены при таком ограничении, и поэтому нам нужна модель более сложного автомата. Рассмотрим, например, задачу обработки скобок в арифметических выражениях. Арифметическое выражение может начинаться с любого количества левых скобок, и компилятор должен проверять, имеется ли в выражении точно такое же число соответствующих правых скобок. Каждый раз самая левая из скобок в выражении будет иметь особую «роль», так как каждая из таких ролей требует разного числа соответствующих правых скобок для завершения выражения. Другими словами, компилятор должен эффективно подсчитывать левые скобки, чтобы сбалансировать их. Разумеется, конечное множество состояний не годится для запоминания числа необходимых правых скобок, так как множество этих чисел бесконечно. Для систематического решения этой проблемы, связанной с выражениями, а также для решения многих других проблем компиляции необходимо использовать в компиляторе модели более мощных автоматов.
Чтобы получить более мощный автомат, память конечного автомата расширяется за счет дополнительного механизма хранения информации. Один из методов хранения информации, который оказался весьма полезным в компиляции и просто реализуется,— это использование магазина или стека1). Основная особенность магазинной памяти с точки зрения работы с нею состоит в том, что символы можно помещать в магазин и удалять из него по одному, причем удаляемый символ — это всегда тот, который был помещен в магазин последним. Последовательность символов в магазинной памяти можно сравнить со стопкой тарелок в кафетерии. Служащие кафетерия ставят чистые тарелки на верх стопки, и посетители затем берут их тоже сверху. Таким образом, посетитель всегда берет из стопки тарелку, поставленную туда последней. В подобных же терминах можно описать и функционирование магазинной памяти. Когда информация помещается в магазин, мы говорим, что она «вталкивается» в магазин. Когда информация удаляется из магазина, мы говорим, что она «выталкивается» из него.
В данной книге и очень часто вообще в программировании эти термины считаются синонимами, хотя в литературе по теории автоматов они различаются, причем стек имеет более широкий смысл. Мы пошли на компромисс, в более «автоматных» разделах употребляя термин магазин, а в более «программистских» переходя на стек.— Прим. ред.
Говорят, что информация, только что поступившая в магазин, находится в его верхушке или наверху. Хотя такое представление о работе с магазином полезно, оно мало что говорит о том, как реализовать магазин в компиляторе.
 |
Рис. 5.1.
Мы изобразили магазин на рис. 5.1, а. На дне магазина находится символ s, а на верху — символ С. Символы расположены в том порядке, в каком они поступали в магазин. Сначала поступил символ s, затем нижнее А, затем В, затем верхнее А и наконец символ С. Если втолкнуть в магазин символ D, то магазин будет выглядеть так, как показано на рис. 5.1, б, где D — верхний символ магазина. Если же, наоборот, вытолкнуть из магазина верхний символ С, то верхним символом окажется А, и магазин будет выглядеть, как показано на рис. 5.1, b. В обоих случаях изменениям подвергается только верх магазина, а остальные символы остаются неизменными, Символ s — это специальный символ, который помечает начало или «дно» магазина и называется маркером дна. Он используется только как метка дна и никогда не выталкивается из магазина. Так, если s— верхний символ магазина, как на рис. 5.1, г, то мы знаем, что других символов в магазине нет. В этом случае говорят, что магазин пуст. Магазин на рис. 5.1, а можно также изобразить в виде цепочки одним из следующих способов:
1.С А В А s
2. s А В А С
Представление магазина в первой строке соответствует соглашению о том, что его «верхний символ находится слева», а во второй строке — что «верхний символ справа». Которое из двух соглашений использовано, можно определить по маркеру дна.
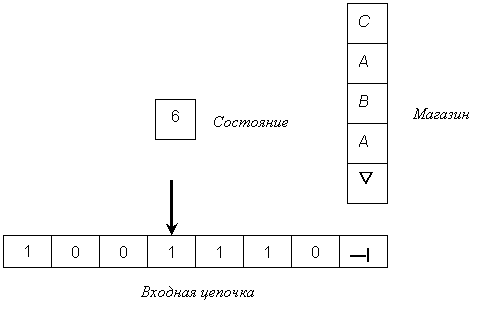 |
Рис. 5.2.
Одной из моделей автомата, в которых используется магазинный принцип организации памяти, является автомат с магазинной памятью (или сокращенно МП-автомат). В нем очень просто комбинируется память конечного автомата и магазинная память. МП-автомат может находиться в одном из конечного числа состояний и имеет магазин, куда он может помещать и откуда может извлекать информацию.
Как и в случае конечного автомата, обработка входной цепочки осуществляется за ряд мелких шагов. На каждом шаге действия автомата конфигурация его памяти может измениться за счет перехода в новое состояние, а также вталкивания символа в магазин или выталкивания из него. Однако в отличие от конечного автомата. МП-автомат может обрабатывать один входной символ в течение нескольких шагов. На каждом шаге управляющее устройство автомата решает, пора ли закончить обработку текущего входного символа и получить, если это так, новый входной символ или продолжить .обработку текущего символа на следующем шаге. На рис. 5.2 изображена одна из конфигураций, которая может возникнуть при обработке некоторым гипотетическим МП-автоматом входной цепочки 100110. Для большей наглядности входная цепочка изображена записанной в ячейках файла или ленты с указателем на входной символ, подвергающийся в данный момент обработке.
Каждый шаг процесса обработки задается множеством правил, использующих информацию трех видов:
1) состояние,
2) верхний символ магазина,
3) текущий входной символ.
Это множество правил называется управляющим устройством или механизмом управления. На рис. 5.2 информация, поступающая в управляющее устройство, такова: состояние 6, верхний символ магазина С, текущий входной символ 0.
В зависимости от получаемой информации, управляющее устройство выбирает либо выход из процесса (т. е. прекращает обработку), либо переход в новое состояние. Переход состоит из трех операций: над магазином, над состоянием и над входом. Возможные операции таковы:
Операции над магазином
1.Втолкнуть в магазин определенный магазинный символ.
2. Вытолкнуть верхний символ магазина.
3. Оставить магазин без изменений.
Операция над состоянием
1. Перейти в заданное новое состояние.
Операции над входом
1.Перейти к следующему входному символу и сделать его текущим входным символом.
2. Оставить данный входной символ текущим, иначе говоря, держать его до следующего шага.
Обработку входной цепочки МП-автомат начинает в некотором выделенном состоянии при определенном содержимом магазина, а текущим входным символом является первый символ входной цепочки. Затем автомат выполняет операции, задаваемые его управляющим устройством. Если происходит выход из процесса, обработка прекращается. Если происходит переход, то он дает новый верхний магазинный символ, новый текущий символ, автомат переходит в новое состояние и управляющее устройство определяет новое действие, которое нужно произвести.
Чтобы управляющие правила имели смысл, автомат не должен требовать следующего входного символа, если текущим символом является концевой маркер, и не должен выталкивать символ из магазина, если это маркер дна. Поскольку маркер дна может находиться исключительно на дне магазина, автомат не должен также вталкивать его в магазин.
Заметим, что описываемая здесь и используемая до конца этой книги модель в теории автоматов называется детерминированным МП-автоматом, тогда как МП-автомат в общем случае может быть недетерминированным. Теперь подытожим, как задается МП-автомат. Он определяется следующими пятью объектами:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
